一种众核系统的片上网络互联结构和数据传输方法
文献发布时间:2023-06-19 11:54:11
技术领域
本发明涉及人工智能技术领域,具体而言,涉及一种众核系统的片上网络互联结构和数据传输方法。
背景技术
众核系统由一个或多个处理器组成,并且一个处理器中通常集成多个完整的计算引擎(内核),一个处理器内或多个处理器间的内核可以相互协同工作。因此,板级芯片和芯片之间,芯片内部的信号、数据等的交互,对于众核架构十分重要,结构对整个众核架构的性能起着至关重要的作用。相关技术中,众核系统中各核间通信基本是固定线路传输数据,核接收数据并处理,由收发模块将数据传输出去。这种传输方式模式固定,众核系统中各核间通信的数据路由选择单一,在一些时刻,会造成数据通路在某一结点出现拥堵,数据会处于等待中,数据不能及时的接收和发送。对于众核架构来说,采用这种方式不能最大限度的将核的计算利用起来,在数据传输通路上耗费时间较长,这样会导致数据吞吐量降低,性能下降。
发明内容
为解决上述问题,本发明的目的在于提供一种众核系统的片上网络互联结构和数据传输方法,在多核间数据的传输过程中,可以选择多种路由形式,提高数据的吞吐量,避免众核架构中出现数据拥堵。
本发明提供了一种众核系统的片上网络互联结构,众核系统由至少一个芯片组成,每个芯片集成多核,所述片上网络互联结构包括:
位于芯片上的至少两个区块;
与每个区块对应设置的片间路由模块且配置为交互相邻区块;以及,
配置为与各片间路由模块交互及交互各核间数据的片上网络。
作为本发明进一步的改进,所述片上网络互联结构配置为实现外部数据的接收处理及处理后的数据在单个芯片各核间的传输。
作为本发明进一步的改进,与数据接口相连区块对应设置的片间路由模块,用于接收并处理所述数据接口传递的数据,并将处理后的数据传递至目的核所在区块内的片上网络节点;
所述目的核所在区块内的片上网络节点,用于接收所述处理后的数据,并将所述处理后的数据传递至目的核;
其中,所述与数据接口相连区块为目的核所在区块。
作为本发明进一步的改进,与数据接口相连区块对应设置的片间路由模块,用于接收并处理所述数据接口传递的数据,并将处理后的数据传递至其他片间路由模块,直至目的核所在区块相邻区块对应设置的片间路由模块;
所述目的核所在区块相邻区块对应设置的片间路由模块,用于接收所述处理后的数据,并将所述处理后的数据传递至目的核所在区块相邻区块内的片上网络节点;
所述目的核所在区块内的片上网络节点,用于接收所述处理后的数据,并将所述处理后的数据传递至目的核;
其中,所述与数据接口相连区块为目的核所在区块。
作为本发明进一步的改进,与数据接口相连区块对应设置的片间路由模块,用于接收并处理所述数据接口传递的数据,并将处理后的数据传递至与数据接口相连区块内的片上网络节点;
所述与数据接口相连区块内的片上网络节点,用于接收所述处理后的数据,并将所述处理后的数据传递至目的核所在区块内的片上网络节点;
所述目的核所在区块内的片上网络节点,用于接收所述处理后的数据,并将所述处理后的数据传递至目的核;
其中,所述与数据接口相连区块为非目的核所在区块。
作为本发明进一步的改进,与数据接口相连区块对应设置的片间路由模块,用于接收并处理所述数据接口传递的数据,并将处理后的数据传递至其他片间路由模块,直至目的核所在区块对应设置的片间路由模块;
所述目的核所在区块对应设置的片间路由模块,用于接收所述处理后的数据,并将所述处理后的数据传递至目的核所在区块内的片上网络节点;
所述目的核所在区块内的片上网络节点,用于接收所述处理后的数据,并将所述处理后的数据传递至目的核;
其中,所述与数据接口相连区块为非目的核所在区块。
作为本发明进一步的改进,
所述目的核包括:
路由接收模块,用于接收数据;
计算模块,用于根据接收到的数据进行计算。
作为本发明进一步的改进,所述片上网络互联结构配置为实现数据在多个芯片各核间的传输。
作为本发明进一步的改进,第一芯片的源核,用于将数据传递至所述第一芯片的源核所在区块内的片上网络节点;
所述第一芯片的源核所在区块内的片上网络节点,用于接收所述数据并将所述数据传递至所述第一芯片的源核所在区块对应设置的片间路由模块;
所述第一芯片的源核所在区块对应设置的片间路由模块,用于接收所述数据并将所述数据传递至第一芯片的其他片间路由模块,直至与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块;
所述与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块,用于接收所述数据并将所述数据传递至所述第二芯片的目的核所在区块对应设置的片间路由模块;
所述第二芯片的目的核所在区块对应设置的片间路由模块,用于接收所述数据并将所述数据传递至所述第二芯片的目的核所在区块内的片上网络节点;
所述第二芯片的目的核所在区块内的片上网络节点,用于接收所述数据并将所述数据传递至所述第二芯片的目的核。
作为本发明进一步的改进,第一芯片的源核,用于将数据传递至所述第一芯片的源核所在区块内的片上网络节点;
所述第一芯片的源核所在区块内的片上网络节点,用于接收所述数据并将所述数据传递至第一芯片的其他区块内的片上网络节点;
所述第一芯片的其他区块内的片上网络节点,用于接收所述数据并将所述数据传递至与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块;
所述与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块,用于接收所述数据并将所述数据传递至所述第二芯片的目的核所在区块对应设置的片间路由模块;
所述第二芯片的目的核所在区块对应设置的片间路由模块,用于接收所述数据并将所述数据传递至所述第二芯片的目的核所在区块内的片上网络节点;
所述第二芯片的目的核所在区块内的片上网络节点,用于接收所述数据并将所述数据传递至所述第二芯片的目的核。
本发明还提供了一种数据传输方法,应用于众核系统,所述众核系统包括至少一个芯片,每个芯片集成多核,每个芯片设置至少两个区块,每个区块对应设置片间路由模块,所述方法包括:
通过所述片间路由模块实现相邻区块间的数据传输,通过片上网络实现与片间路由模块的数据传输及数据在各核间的传输。
作为本发明进一步的改进,通过与数据接口相连区块对应设置的片间路由模块接收外部数据并处理,通过片上网络和/或其他片间路由模块将处理后的数据传输至目的核,实现外部数据的接收处理及处理后的数据在单个芯片各核间的传输。
作为本发明进一步的改进,通过与数据接口相连区块对应设置的片间路由模块接收外部数据并处理,通过片上网络和/或其他片间路由模块将处理后的数据传输至目的核,包括:
通过与数据接口相连区块对应设置的片间路由模块接收所述外部数据并处理;
通过所述与数据接口相连区块对应设置的片间路由模块将处理后的数据传递至目的核所在区块内的片上网络节点;
通过所述目的核所在区块内的片上网络节点将所述处理后的数据传递至目的核;
其中,所述与数据接口相连区块为目的核所在区块。
作为本发明进一步的改进,通过与数据接口相连区块对应设置的片间路由模块接收外部数据并处理,通过片上网络和/或其他片间路由模块将处理后的数据传输至目的核,包括:
通过与数据接口相连区块对应设置的片间路由模块接收所述外部数据并处理;
通过所述与数据接口相连区块对应设置的片间路由模块将处理后的数据传递至其他片间路由模块,直至目的核所在区块相邻区块对应设置的片间路由模块;
通过所述目的核所在区块相邻区块对应设置的片间路由模块将所述处理后的数据传递至目的核所在区块相邻区块内的片上网络节点;
通过所述目的核所在区块相邻区块内的片上网络节点将所述处理后的数据传递至目的核所在区块内的片上网络节点;
通过所述目的核所在区块内的片上网络节点将所述处理后的数据传递至目的核;
其中,所述与数据接口相连区块为目的核所在区块。
作为本发明进一步的改进,通过与数据接口相连区块对应设置的片间路由模块接收外部数据并处理,通过片上网络和/或其他片间路由模块将处理后的数据传输至目的核,包括:
通过与数据接口相连区块对应设置的片间路由模块接收所述外部数据并处理;
通过所述与数据接口相连区块内的片上网络节点将处理后的数据传递至目的核所在区块内的片上网络节点;
通过所述目的核所在区块内的片上网络节点将所述处理后的数据传递至目的核;
其中,所述与数据接口相连区块为非目的核所在区块。
作为本发明进一步的改进,通过与数据接口相连区块对应设置的片间路由模块接收外部数据并处理,通过片上网络和/或其他片间路由模块将处理后的数据传输至目的核,包括:
通过与数据接口相连区块对应设置的片间路由模块接收所述外部数据并处理;
通过所述与数据接口相连区块对应设置的片间路由模块将处理后的数据传递至其他片间路由模块,直至目的核所在区块对应设置的片间路由模块;
通过所述目的核所在区块对应设置的片间路由模块将所述处理后的数据传递至目的核所在区块内的片上网络节点;
通过所述目的核所在区块内的片上网络节点将所述处理后的数据传递至目的核;
其中,所述与数据接口相连区块为非目的核所在区块。
作为本发明进一步的改进,目的核内的路由接收模块接收数据,并由目的核内的计算模块进行计算。
作为本发明进一步的改进,通过各片间路由模块和片上网络将数据从一芯片的源核传输至另一芯片的目的核,实现数据在多个芯片各核间的传输。
作为本发明进一步的改进,通过各片间路由模块和片上网络将数据从一芯片的源核传输至另一芯片的目的核,包括:
通过第一芯片的源核将数据传递至所述第一芯片的源核所在区块内的片上网络节点;
通过所述第一芯片的源核所在区块内的片上网络节点将所述数据传递至所述第一芯片的源核所在区块对应设置的片间路由模块;
通过所述第一芯片的源核所在区块对应设置的片间路由模块将所述数据传递至第一芯片的其他片间路由模块;
通过所述第一芯片的其他片间路由模块将所述数据传递至与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块;
通过所述与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块将所述数据传递至第二芯片的目的核所在区块对应设置的片间路由模块;
通过所述第二芯片的目的核所在区块对应设置的片间路由模块将所述数据传递至第二芯片的目的核所在区块内的片上网络节点;
通过所述第二芯片的目的核所在区块内的片上网络节点将所述数据传递至第二芯片的目的核。
作为本发明进一步的改进,通过各片间路由模块和片上网络将数据从一芯片的源核传输至另一芯片的目的核,包括:
通过第一芯片的源核将数据传递至所述第一芯片的源核所在区块内的片上网络节点;
通过所述第一芯片的源核所在区块内的片上网络节点将所述数据传递至第一芯片的其他区块内的片上网络节点;
通过所述第一芯片的其他区块内的片上网络节点将所述数据传递至与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块;
通过所述与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块将所述数据传递至第二芯片的目的核所在区块对应设置的片间路由模块;
通过所述第二芯片的目的核所在区块对应设置的片间路由模块将所述数据传递至第二芯片的目的核所在区块内的片上网络节点;
通过所述第二芯片的目的核所在区块内的片上网络节点将所述数据传递至第二芯片的目的核。
作为本发明进一步的改进,数据在传输过程中,以顺时针方向依次通过其他片间路由模块。
本发明还提供了一种板卡,所述板卡上集成有所述的片上网络互联结构。
本发明还提供了一种电子设备,包括存储器和处理器,其特征在于,所述存储器用于存储一条或多条计算机指令,其中,所述一条或多条计算机指令被处理器执行以实现所述的数据传输方法。
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储计算机程序指令,所述计算机程序指令在被处理器执行时实现所述的的数据传输方法。
本发明的有益效果为:
在多芯片、多核间的数据交互过程中,当数据通路在某一结点出现拥堵时,采用本发明的片上互联结构进行片内核间和片间核间通信时,可以自由选择路由,避免数据长时间处于等待,以至于不能及时接收和发送,充分利用了核计算,解决了数据拥堵带来的性能下降问题,同时多种路由选择还可以减少数据传输的时间。
附图说明
为了更清楚地说明本公开实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
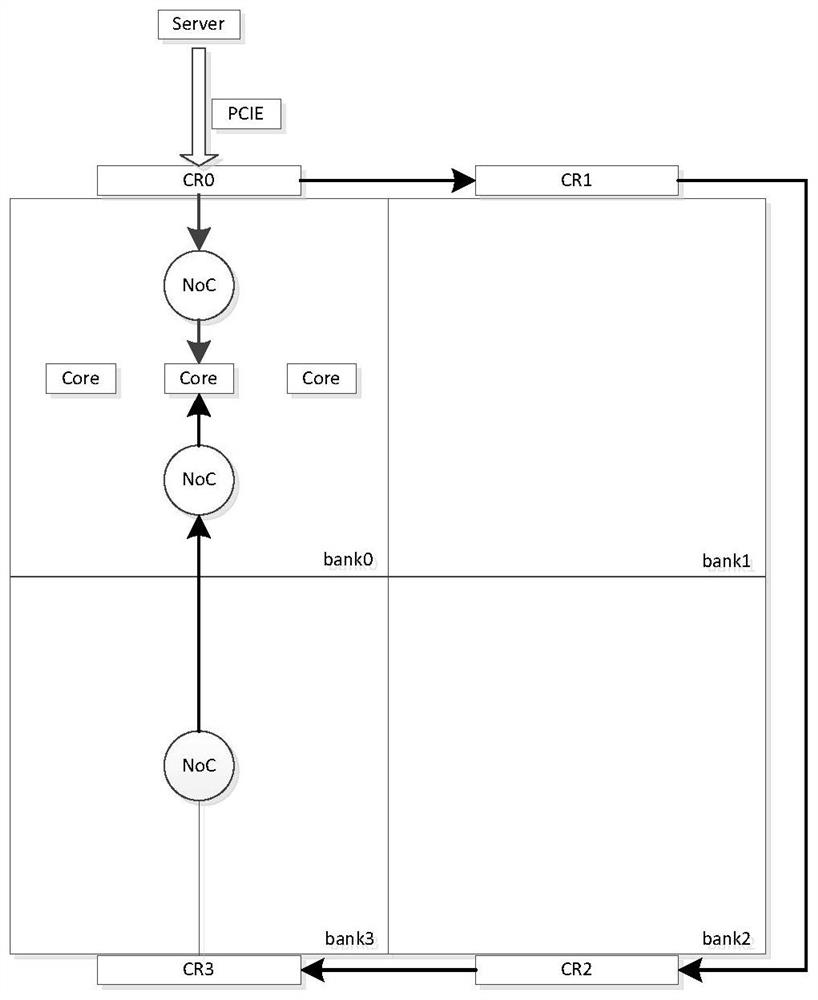
图1为本公开实施例所述的单个芯片各核间数据传输的路由示意图,其中,目的核与PCIE接口相连;
图2为本公开实施例所述的单个芯片各核间数据传输的路由示意图,其中,目的核不与PCIE接口相连;
图3为本公开实施例所述的多个芯片各核间数据传输的路由示意图。
具体实施方式
下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本公开一部分实施例,而不是全部的实施例。基于本公开中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。
需要说明,若本公开实施例中有涉及方向性指示(诸如上、下、左、右、前、后……),则该方向性指示仅用于解释在某一特定姿态(如附图所示)下各部件之间的相对位置关系、运动情况等,如果该特定姿态发生改变时,则该方向性指示也相应地随之改变。
另外,在本公开的描述中,所用术语仅用于说明目的,并非旨在限制本公开的范围。术语“包括”和/或“包含”用于指定所述元件、步骤、操作和/或组件的存在,但并不排除存在或添加一个或多个其他元件、步骤、操作和/或组件的情况。术语“第一”、“第二”等可能用于描述各种元件,不代表顺序,且不对这些元件起限定作用。此外,在本公开的描述中,除非另有说明,“多个”的含义是两个及两个以上。这些术语仅用于区分一个元素和另一个元素。结合以下附图,这些和/或其他方面变得显而易见,并且,本领域普通技术人员更容易理解关于本公开所述实施例的说明。附图仅出于说明的目的用来描绘本公开所述实施例。本领域技术人员将很容易地从以下说明中认识到,在不背离本公开所述原理的情况下,可以采用本公开所示结构和方法的替代实施例。
本公开实施例的一种众核系统的片上网络互联结构,众核系统包括至少一个芯片,每个芯片集成多核,片上网络互联结构包括:位于芯片上的至少两个区块;与每个区块对应设置的片间路由模块且配置为交互相邻区块;以及,配置为与各片间路由模块交互及交互各核间数据的片上网络。
在一种可选的实施方式中,片上网络互联结构可以配置为实现外部数据的接收处理及处理后的数据在单个芯片各核间的传输,即实现外部数据的接收处理并传输至芯片内部,以及芯片内部的信号、数据等的交互。
针对于不同的AI模型,会训练出最优的数据路由,实现性能最优的数据传输,尽量减少数据传输所消耗的时间。为此,对于一个Chip(芯片),优选采用四个bank(区块),每一个bank对应一个CR(片间路由模块),bank内的路由片上网络节点(NoC,Network on chip)网络完成拓扑,数据可以通过两种形式传输和发送到目的核上。其中,NoC网络采用现有技术完成匹配设计即可,为包括多个片上网络节点的矩阵网络,不是本公开所设计的重点,这里不再详述。
第一种路由:
CR->NoC(bank内)->Core,该路由是使用CR发往bank内的NoC上,通过不同层级的NoC传递到目的核中,进行计算。
在一种可选的实施方式中,当目的核与数据接口(PCIE接口)相连时,与数据接口相连区块对应设置的片间路由模块,用于接收并处理数据接口传递的数据,并将处理后的数据传递至目的核所在区块内的片上网络节点;目的核所在区块内的片上网络节点,用于接收处理后的数据,并将处理后的数据传递至目的核。
路径可以为:数据首先通过与目的核所在区块对应设置的片间路由模块,然后传递至目的核所在区块内的片上网络节点,最后传递至目的核中,进行计算。
在一种可选的实施方式中,当目的核不与PCIE接口相连时,与数据接口相连区块对应设置的片间路由模块,用于接收并处理数据接口传递的数据,并将处理后的数据传递至与数据接口相连区块内的片上网络节点;与数据接口相连区块内的片上网络节点,用于接收处理后的数据,并将处理后的数据传递至目的核所在区块内的片上网络节点;目的核所在区块内的片上网络节点,用于接收处理后的数据,并将处理后的数据传递至目的核。
路径可以为:数据首先通过与数据接口相连区块对应设置的片间路由模块,然后通过该区块内的片上网络节点传递至目的核所在区块内的片上网络节点,最后传递至目的核中,进行计算。
第二种路由:
CR->CRx->NoC(bank内)->Core,该路由采用loop CR(即数据依次通过片间路由模块)的形式进行传输,通过loop CR将数据传送到目的Core所在的bank中,再由bank内的NoC进行传输。其中,CRx表示其中一片间路由模块。
在一种可选的实施方式中,当目的核与PCIE接口相连时,与数据接口相连区块对应设置的片间路由模块,用于接收并处理数据接口传递的数据,并将处理后的数据传递至其他片间路由模块,直至目的核所在区块相邻区块对应设置的片间路由模块;目的核所在区块相邻区块对应设置的片间路由模块,用于接收处理后的数据,并将处理后的数据传递至目的核所在区块相邻区块内的片上网络节点;目的核所在区块内的片上网络节点,用于接收处理后的数据,并将处理后的数据传递至目的核。
路径可以为:数据首先通过与目的核所在区块对应设置的片间路由模块,然后依次通过其他片间路由模块,直至目的核所在区块相邻区块对应设置的片间路由模块,再通过目的核所在区块相邻区块内的片上网络节点传递至目的核所在区块内的片上网络节点,最后传递至目的核中,进行计算。
在一种可选的实施方式中,当目的核不与PCIE接口相连时,与数据接口相连区块对应设置的片间路由模块,用于接收并处理数据接口传递的数据,并将处理后的数据传递至其他片间路由模块,直至目的核所在区块对应设置的片间路由模块;目的核所在区块对应设置的片间路由模块,用于接收处理后的数据,并将处理后的数据传递至目的核所在区块内的片上网络节点;目的核所在区块内的片上网络节点,用于接收处理后的数据,并将处理后的数据传递至目的核。
路径可以为:数据首先通过与数据接口相连区块对应设置的片间路由模块,然后依次通过其他片间路由模块,直至目的核所在区块对应设置的片间路由模块,最后通过目的核所在区块内的片上网络节点传递至目的核中,进行计算。
两种路由的方案,都可以将数据发送到目的核,这样可以解决数据拥堵带来的性能下降的问题,同时多种路由选择还可以减少数据传输的时间。
上述实施方式中,数据传输至目的核后,由目的核内的路由接收模块接收数据,并由目的核内的计算模块进行计算。
由于是众核架构,还可以实现片间核间通信。在一种可选的实施方式中,片上网络互联结构也可以配置为实现数据在多个芯片各核间的传输,即芯片和芯片之间信号和数据等的交互。
此时,对于每一个Chip(芯片),优选采用四个bank(区块),每一个bank对应一个CR(片间路由模块),bank内的路由NoC网络完成拓扑,bank间的路由CR完成。数据可以通过两种形式传输和发送到目的核中。
第一种路由:
Core(Chip0 src)->NoC(Chip0 bank内)->CRx(Chip0)->…CRx(Chip0)->CRx(Chip1)->NoC(Chip1 bank内)->Core(Chip1 dst)。其中,CRx表示其中一片间路由模块,chip0为第一芯片,Chip1为第二芯片,Core(src)表示源核,Core(dst)表示目的核。
在一种可选的实施方式中,第一芯片的源核,用于将数据传递至第一芯片的源核所在区块内的片上网络节点;第一芯片的源核所在区块内的片上网络节点,用于接收数据并将数据传递至第一芯片的源核所在区块对应设置的片间路由模块;第一芯片的源核所在区块对应设置的片间路由模块,用于接收数据并将数据传递至第一芯片的其他片间路由模块,直至与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块;与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块,用于接收数据并将数据传递至第二芯片的目的核所在区块对应设置的片间路由模块;第二芯片的目的核所在区块对应设置的片间路由模块,用于接收数据并将数据传递至第二芯片的目的核所在区块内的片上网络节点;第二芯片的目的核所在区块内的片上网络节点,用于接收数据并将数据传递至第二芯片的目的核。
路径可以为:数据首先通过第一芯片(Chip0)的源核传递至该源核所在区块内的片上网络节点,然后通过源核所在区块对应设置的片间路由模块后,依次通过第一芯片(Chip0)的其他片间路由模块,直至与第二芯片(Chip1)目的核所在区块邻近的第一芯片(Chip0)上区块对应设置的片间路由模块,再通过第二芯片(Chip1)的目的核所在区块对应设置的片间路由模块后,最后通过目的核所在区块内的片上网络节点传递至目的核中,进行计算。
第二种路由:
Core(Chip0 src)->NoC(Chip0 bank内)->…->NoC(Chip0 bank内)->CRx(Chip0)->CRx(Chip1)->NoC(Chip1 bank内)->Core(Chip1(dst)。其中,CRx表示其中一片间路由模块,chip0为第一芯片,Chip1为第二芯片,Core(src)表示源核,Core(dst)表示目的核。
在一种可选的实施方式中,第一芯片的源核,用于将数据传递至第一芯片的源核所在区块内的片上网络节点;第一芯片的源核所在区块内的片上网络节点,用于接收数据并将数据传递至第一芯片的其他区块内的片上网络节点;第一芯片的其他区块内的片上网络节点,用于接收数据并将数据传递至与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块;与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块,用于接收数据并将数据传递至第二芯片的目的核所在区块对应设置的片间路由模块;第二芯片的目的核所在区块对应设置的片间路由模块,用于接收数据并将数据传递至第二芯片的目的核所在区块内的片上网络节点;第二芯片的目的核所在区块内的片上网络节点,用于接收数据并将数据传递至第二芯片的目的核。
路径可以为:数据首先通过第一芯片(Chip0)的源核传递至该源核所在区块内的片上网络节点,然后通过第一芯片(Chip0)其他区块内的片上网络节点传递至与第二芯片(Chip1)目的核所在区块邻近的第一芯片(Chip0)上区块对应设置的片间路由模块,再通过第二芯片(Chip1)的目的核所在区块对应设置的片间路由模块后,最后通过目的核所在区块内的片上网络节点传递至目的核中,进行计算。
本公开实施例的一种数据传输方法,应用于众核系统,众核系统包括至少一个芯片组成,每个芯片集成多核,每个芯片设置至少两个区块,每个区块对应设置片间路由模块,方法包括:通过片间路由模块实现相邻区块间的数据传输,通过片上网络实现与片间路由模块的数据传输及数据在各核间的传输。
本公开的一种数据传输方法,通过前述的片上网络互联结构,通过与数据接口相连区块对应设置的片间路由模块接收外部数据并处理,通过片上网络和/或其他片间路由模块将处理后的数据传输至目的核,实现外部数据的接收处理及处理后的数据在单个芯片各核间的传输。在传输的过程中,单个芯片核与核之间的通信,可以通过不同层级之间的片上网络节点互联实现核之间的数据通信和交互。数据传输过程中有两种路由可以选择,会设置一个默认方式,拥堵则换另外一条,也能根据不同的AI模型选择相应的训练结果,训练出最优的数据路由,进而知道最优路径,实现性能最优的数据传输,尽量减少数据传输所消耗的时间。
第一种路由:
CR->NoC(bank内)->Core,该路由是使用CR发往bank内的NoC上,通过不同层级的NoC传递到目的核中,进行计算。
在一种可选的实施方式中,如图1所示,当目的核与PCIE接口相连时,通过与数据接口相连区块对应设置的片间路由模块接收外部数据并处理;通过与数据接口相连区块对应设置的片间路由模块将处理后的数据传递至目的核所在区块内的片上网络节点;通过目的核所在区块内的片上网络节点将处理后的数据传递至目的核。
路径可以为:数据首先通过与目的核所在区块对应设置的片间路由模块,然后传递至目的核所在区块内的片上网络节点,最后传递至目的核中,进行计算。
在一种可选的实施方式中,如图2所示,当目的核不与PCIE接口相连时,通过与数据接口相连区块对应设置的片间路由模块接收外部数据并处理;通过与数据接口相连区块内的片上网络节点将处理后的数据传递至目的核所在区块内的片上网络节点;通过目的核所在区块内的片上网络节点将处理后的数据传递至目的核。
路径可以为:数据首先通过与数据接口相连区块对应设置的片间路由模块,然后通过该区块内的片上网络节点传递至目的核所在区块内的片上网络节点,最后传递至目的核中,进行计算。
第二种路由:
CR->CRx->NoC(bank内)->Core,该路由采用loop CR即数据依次通过片间路由模块)的形式进行传输,通过loop CR将数据传送到目的Core所在的bank中,再由bank内的NoC进行传输。其中,CRx表示其中一片间路由模块。
在一种可选的实施方式中,如图1所示,当目的核与PCIE接口相连时,通过与数据接口相连区块对应设置的片间路由模块接收外部数据并处理;通过与数据接口相连区块对应设置的片间路由模块将处理后的数据传递至其他片间路由模块,直至目的核所在区块相邻区块对应设置的片间路由模块;通过目的核所在区块相邻区块对应设置的片间路由模块将处理后的数据传递至目的核所在区块相邻区块内的片上网络节点;通过目的核所在区块相邻区块内的片上网络节点将处理后的数据传递至目的核所在区块内的片上网络节点;通过目的核所在区块内的片上网络节点将处理后的数据传递至目的核。
路径可以为:数据首先通过与目的核所在区块对应设置的片间路由模块,然后依次通过其他片间路由模块,直至目的核所在区块相邻区块对应设置的片间路由模块,再通过目的核所在区块相邻区块内的片上网络节点传递至目的核所在区块内的片上网络节点,最后传递至目的核中,进行计算。
在一种可选的实施方式中,如图2所示,当目的核不与PCIE接口相连时,通过与数据接口相连区块对应设置的片间路由模块接收外部数据并处理;通过与数据接口相连区块对应设置的片间路由模块将处理后的数据传递至其他片间路由模块,直至目的核所在区块对应设置的片间路由模块;通过目的核所在区块对应设置的片间路由模块将处理后的数据传递至目的核所在区块内的片上网络节点;通过目的核所在区块内的片上网络节点将处理后的数据传递至目的核。
路径可以为:数据首先通过与数据接口相连区块对应设置的片间路由模块,然后依次通过其他片间路由模块,直至目的核所在区块对应设置的片间路由模块,最后通过目的核所在区块内的片上网络节点传递至目的核中,进行计算。
优选的,数据在传输过程中,以顺时针方向依次通过其他片间路由模块。这样,按照单一方向布线,可以有效节省芯片面积,突破制程的限制,CR之间的路由方式优选采用顺时针进行loop,消除这一限制将会更进一步的提升性能。本公开对片间路由模块之间的路由方式不做限制。
上述实施方式中,数据传输至目的核后,由目的核内的路由接收模块接收数据,并由目的核内的计算模块进行计算。
本公开的一种数据传输方法,针对的是众核架构,还可以实现数据在多个芯片各核间的传输,数据通过各片间路由模块和片上网络从一芯片的源核传输至另一芯片的目的核,这就需要片间的路由,片间的路由是通过CR来实现的。同样,数据在传输过程中有两种路由可以选择,会设置一个默认方式,拥堵则换另外一条,也能根据不同的AI模型选择相应的训练结果,训练出最优的数据路由,进而知道最优路径,实现性能最优的数据传输,尽量减少数据传输所消耗的时间。
第一种路由:
Core(Chip0 src)->NoC(Chip0 bank内)->CRx(Chip0)->…CRx(Chip0)->CRx(Chip1)->NoC(Chip1 bank内)->Core(Chip1 dst)。其中,CRx表示其中一片间路由模块,chip0为第一芯片,Chip1为第二芯片,Core(src)表示源核,Core(dst)表示目的核。
在一种可选的实施方式中,通过第一芯片的源核将数据传递至第一芯片的源核所在区块内的片上网络节点;通过第一芯片的源核所在区块内的片上网络节点将数据传递至第一芯片的源核所在区块对应设置的片间路由模块;通过第一芯片的源核所在区块对应设置的片间路由模块将数据传递至第一芯片的其他片间路由模块;通过第一芯片的其他片间路由模块将数据传递至与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块;通过与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块将数据传递至第二芯片的目的核所在区块对应设置的片间路由模块;通过第二芯片的目的核所在区块对应设置的片间路由模块将数据传递至第二芯片的目的核所在区块内的片上网络节点;通过第二芯片的目的核所在区块内的片上网络节点将数据传递至第二芯片的目的核。
路径可以为:数据首先通过第一芯片(Chip0)的源核传递至该源核所在区块内的片上网络节点,然后通过源核所在区块对应设置的片间路由模块后,依次通过第一芯片(Chip0)的其他片间路由模块,直至与第二芯片(Chip1)目的核所在区块邻近的第一芯片(Chip0)上区块对应设置的片间路由模块,再通过第二芯片(Chip1)的目的核所在区块对应设置的片间路由模块后,最后通过目的核所在区块内的片上网络节点传递至目的核。
第二种路由:
Core(Chip0 src)->NoC(Chip0 bank内)->…->NoC(Chip0 bank内)->CRx(Chip0)->CRx(Chip1)->NoC(Chip1 bank内)->Core(Chip1(dst)。其中,CRx表示其中一片间路由模块,chip0为第一芯片,Chip1为第二芯片,Core(src)表示源核,Core(dst)表示目的核。
在一种可选的实施方式中,通过第一芯片的源核将数据传递至第一芯片的源核所在区块内的片上网络节点;通过第一芯片的源核所在区块内的片上网络节点将数据传递至第一芯片的其他区块内的片上网络节点;通过第一芯片的其他区块内的片上网络节点将数据传递至与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块;通过与第二芯片的目的核所在区块邻近的第一芯片的区块对应设置的片间路由模块将数据传递至第二芯片的目的核所在区块对应设置的片间路由模块;通过第二芯片的目的核所在区块对应设置的片间路由模块将数据传递至第二芯片的目的核所在区块内的片上网络节点;通过第二芯片的目的核所在区块内的片上网络节点将数据传递至第二芯片的目的核。
路径可以为:数据首先通过第一芯片(Chip0)的源核传递至该源核所在区块内的片上网络节点,然后通过第一芯片(Chip0)其他区块内的片上网络节点传递至与第二芯片(Chip1)目的核所在区块邻近的第一芯片(Chip0)上区块对应设置的片间路由模块,再通过第二芯片(Chip1)的目的核所在区块对应设置的片间路由模块后,最后通过目的核所在区块内的片上网络节点传递至目的核中,进行计算。
优选的,数据在传输过程中,以顺时针方向依次通过其他片间路由模块。这样,按照单一方向布线,可以有效节省芯片面积,突破制程的限制,CR之间的路由方式优选采用顺时针进行loop,消除这一限制将会更进一步的提升性能。本公开对片间路由模块之间的路由方式不做限制。
本公开所述的一种数据传输方法,数据的流向主要分为两个部分:AI训练模型部分和板卡数据处理部分;
AI训练模型部分:AI训练模型的工作在服务器或者是计算机中完成,会根据一定的规则训练出路由模型。在服务器端会根据训练的结果,即将要通过PCIE接口传送到板卡中的数据依据工具链的编译规则将发送的包组合成“数据部分(128bits)”+“数据头(128bit)”的形式,最终经由服务器端的PCIE接口,发往到板卡中。其中“数据头”包含了训练出来的路由信息。
板卡数据处理部分:板卡接收到服务器传送过来的数据,经过板卡端的PCIE接口接收数据,转化为板卡中片间路由模块(CR)可以接收和处理的数据,CR接收数据会进行解包和打包数据的工作,然后进行下一步的数据传输,传送给片上网络节点(NoC)或者是下一级片上网络节点(NoC),最终路由到板卡的核中(目的核)去处理,具体路由路径参考前述所述。
本公开还涉及一种板卡,板卡上集成有本公开实施例所述的片上网络互联结构。板卡上还集成有数据接口(PCIE接口),板卡接收到服务器传送过来的数据,经过板卡的PCIE接口接收数据,转化为板卡中片上网络互联结构的片间路由模块可以接收和处理的数据,与PCIE接口相连的片间路由模块接收数据后进行解包和打包工作,然后进行下一步的数据传输,传送给片上网络节点或者是下一级片上网络节点,最终路由到板卡的核中(目的核)去处理,路由路径参考前述所述。
本公开还涉及一种电子设备,包括服务器、终端等。该电子设备包括:至少一个处理器;与至少一个处理器通信连接的存储器;以及与存储介质通信连接的通信组件,所述通信组件在处理器的控制下接收和发送数据;其中,存储器存储有可被至少一个处理器执行的指令,指令被至少一个处理器执行以实现上述实施例中的众核系统的数据传输方法。
在一种可选的实施方式中,存储器作为一种非易失性计算机可读存储介质,可用于存储非易失性软件程序、非易失性计算机可执行程序以及模块。处理器通过运行存储在存储器中的非易失性软件程序、指令以及模块,从而执行设备的各种功能应用以及数据处理,即实现上述众核系统的数据传输方法。
存储器可以包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需要的应用程序;存储数据区可存储选项列表等。此外,存储器可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。在一些实施例中,存储器可选包括相对于处理器远程设置的存储器,这些远程存储器可以通过网络连接至外接设备。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
一个或者多个模块存储在存储器中,当被一个或者多个处理器执行时,执行上述任意方法实施例中的众核系统的数据传输方法。
上述产品可执行本申请实施例所提供的众核系统的数据传输方法,具备执行方法相应的功能模块和有益效果,未在本实施例中详尽描述的技术细节,可参见本申请实施例所提供的众核系统的数据传输方法。
本公开还涉及一种计算机可读存储介质,用于存储计算机可读程序,所述计算机可读程序用于供计算机执行上述部分或全部的众核系统的数据传输方法的实施例。
用于执行的计算机程序可以采用一种或多种编程语言的任意组合来编写,所述编程语言包括:面向对象的编程语言如C++等;以及常规过程编程语言如“C”编程语言或类似的汇编语言。
即,本领域技术人员可以理解,实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本申请各实施例所述方法的全部或部分步骤。而前述的存储介质包括:片上内存或Flash等各种可以存储程序代码的介质。
下面将通过三个具体实施例并结合附图,对本公开进行进一步说明。
实施例1,采用本公开的片上网络互联结构实现片内核间通信,如图1所示,数据可以通过两种路由传输和发送到目的核中。
第一种:PCIE->CR0->NoC(bank0)->目标Core。具体的,服务器Server的数据包(PCIE协议)通过区块bank0对应设置的片间路由模块CR0,再通过区块bank0内的片上网络节点传递至目的核Core中,进行计算。
第二种:PCIE->CR0->CR1->CR2->CR3->NoC(bank3)->NoC(bank0)->目标Core。具体的,服务器Server的数据包(PCIE协议)首先通过区块bank0对应设置的片间路由模块CR0,然后依次通过区块bank1、区块bank2和区块bank3对应设置的片间路由模块CR1、片间路由模块CR2和片间路由模块CR3,再通过区块bank3内的片上网络节点传递至bank0内的片上网络节点,最后传递至目的核Core中,进行计算。
如前述所述,服务器会根据AI训练模型训练的结果,在两种路由中选择一种,将数据通过PCIE接口将数据发往到板卡中,例如AI模型训练结果默认选择第一种路由,然而当第一种路由中例如某一片上网络节点数据需要等待才能传输,此时,数据会通过第二种路由传输至目的核中。
实施例2,采用本公开的片上网络互联结构实现片内核间通信,如图2所示,数据可以通过两种路由传输和发送到目的核中。
第一种:PCIE->CR0->NoC(bank0)->NoC(bank3)->目标Core。具体的,服务器Server的数据包(PCIE协议)通过区块bank0对应设置的片间路由模块CR0,再通过区块bank0内的片上网络节点传递至区块bank3的片上网络节点,最后传递至目的核Core中,进行计算。
第二种:PCIE->CR0->CR1->CR2->CR3->NoC(bank3)->目标Core。具体的,服务器Server的数据包(PCIE协议)首先通过区块bank0对应设置的片间路由模块CR0,然后依次通过区块bank1、区块bank2和区块bank3对应设置的片间路由模块CR1、片间路由模块CR2和片间路由模块CR3,最后通过区块bank3内的片上网络节点传递传递至目的核Core中,进行计算。
实施例3,采用本公开的片上网络互联结构实现片间核间通信,如图3所示,数据可以通过两种路由传输和发送到目的核中。
第一种:Core(Chip0 src)->NoC(Chip0 bank0)->CR0(Chip0 bank0)->CR1(Chip0bank1)->CR2(Chip0 bank2)->CR3(Chip1 bank3)->NoC(Chip1bank3)->Core(Chip1 dst)。具体的,Chip0的核数据首先通过Chip0的区块bank0内的片上网络节点传递至Chip0的区块bank0所对应设置的片间路由模块CR0,然后依次通过Chip0的区块bank1和区块bank2所对应设置的片间路由模块CR1和片间路由模块CR2,再通过Chip1的区块bank3所对应设置的片间路由模块CR3,最后通过Chip1的区块bank3内的片上网络节点传递至Chip1的目的核Core中,进行计算。
第二种:Core(Chip0 src)->NoC(Chip0 bank0)->NoC(Chip0 bank3)->NoC(Chip0bank2)->CR2(Chip0 bank2)->CR3(Chip1 bank3)->NoC(Chip1bank3)->Core(Chip1 dst)。具体的,Chip0的核数据首先通过Chip0的区块bank0内的片上网络节点传递至Chip0的区块bank3内的片上网络节点,然后传递至Chip0的区块bank2内的片上网络节点,再传递至Chip0的区块bank2所对应设置的片间路由模块CR2,再传递至Chip1的区块bank3所对应设置的片间路由模块CR3,最后通过Chip1的区块bank3内的片上网络节点传递至Chip1的目的核Core中,进行计算。
在此处所提供的说明书中,说明了大量具体细节。然而,能够理解,本公开的实施例可以在没有这些具体细节的情况下实践。在一些实例中,并未详细示出公知的方法、结构和技术,以便不模糊对本说明书的理解。
此外,本领域普通技术人员能够理解,尽管在此所述的一些实施例包括其它实施例中所包括的某些特征而不是其它特征,但是不同实施例的特征的组合意味着处于本公开的范围之内并且形成不同的实施例。例如,在权利要求书中,所要求保护的实施例的任意之一都可以以任意的组合方式来使用。
本领域技术人员应理解,尽管已经参考示例性实施例描述了本公开,但是在不脱离本公开的范围的情况下,可进行各种改变并可用等同物替换其元件。另外,在不脱离本公开的实质范围的情况下,可进行许多修改以使特定情况或材料适应本公开的教导。因此,本公开不限于所公开的特定实施例,而是本公开将包括落入所附权利要求范围内的所有实施例。
- 一种众核系统的片上网络互联结构和数据传输方法
- 基于片上网络的众核芯片管理结构容错的方法