用于文本到代码变换的双贝叶斯编码-解码技术
文献发布时间:2023-06-19 19:28:50
技术领域
本申请总地涉及自然语言处理,并且更具体地涉及用于文本到代码变换的双贝叶斯编码-解码技术。
背景技术
用于自然语言处理(NLP)的方法和机器学习(ML)框架已在过去十年中呈现显著进步。特别地,深度学习(DL)技术已在诸如含义提取、命名实体识别、问答和机器翻译之类的NLP任务上显示了性能的提高。然而,收到较少关注的自然语言(NL)的一个子域是NL到源代码的变换。
编写无错误的源代码是极其困难的任务,对复杂软件系统来说尤其如此。甚至最有经验的程序员和开发者也可能在编写源代码时遇到困难。来自在线论坛的使用的统计信息提供了困难有多么普遍的证据。例如,Stack Overflow的1600万个用户已张贴了2200万个问题,提供了3200万个回答,并且每天访问站点1100万次(最近的平均值)。通常,用户需要询问其他人或者搜索网络以查找适当的语法或者查找已知代码实现方式的解决方案。
搜索像GitHub或Stack Overflow(及其他)一样的大代码数据库常常非常耗时;因此,使用DL和概率模型来自动化源代码生成正在赢得关注。需要准确且降低计算成本的技术,以便为依赖软件/固件开发的公司提供优势,以缩短其软件和硬件产品的上市时间。
发明内容
根据本申请的一方面,提供了一种用于从自然语言NL输入生成源代码的方法,包括:处理所述NL输入以生成源代码SC词元序列中的SC词元的概率分布PD;处理所述NL输入以生成抽象句法树AST词元序列中的AST词元的PD;标识要修复的一个或多个SC词元;以及对被标识的所述一个或多个SC词元应用一个或多个修复规则,其中用于给定SC词元的修复规则是基于所述SC词元的PD和与所述SC词元相关联的AST词元的PD中的至少一个来选择的。
根据本申请的另一方面,提供了一种非暂时性机器可读介质,其上存储有指令,所述指令被配置为在计算系统上的一个或多个处理器上执行以从自然语言(NL)输入生成源代码,其中所述指令的执行使得所述计算系统:处理所述NL输入以生成源代码SC词元序列中的SC词元的概率分布PD;处理所述NL输入以生成抽象句法树AST词元序列中的AST词元的PD;标识要修复的一个或多个SC词元;以及对被标识的所述一个或多个SC词元应用一个或多个修复规则,其中用于给定SC词元的修复规则是基于所述SC词元的PD和与所述SC词元相关联的AST词元的PD中的至少一个来选择的。
根据本申请的又一方面,提供了一种计算系统,包括:一个或多个处理器,存储器,所述存储器耦合到所述一个或多个处理器,在所述存储器中存储有指令,所述指令被配置为在所述一个或多个处理器中的至少一个上执行以使得所述系统能够:处理自然语言NL输入以生成源代码SC词元序列中的SC词元的概率分布PD;处理所述NL输入以生成抽象句法树AST词元序列中的AST词元的PD;标识要修复的一个或多个SC词元;以及对被标识的所述一个或多个SC词元应用一个或多个修复规则,其中用于给定SC词元的修复规则是至少部分地基于所述SC词元的PD和与所述SC词元相关联的AST词元的PD中的至少一个来选择的。
附图说明
本发明的上述方面和许多附带优点将变得更容易理解,因为当结合附图时,通过参考以下详细描述,它们变得更好理解,其中除非另外指定,否则相似的附图标记在各个视图中自始至终指代相似的部分:
图1a是根据一个实施例的多模态概率源代码模型和示例性输出表的框图,该示例性输出表包括从处理输入自然语言(NL)请求生成的源代码(SC)词元(token)和抽象语法树(AST);
图1b是示出由图1a的多模态概率源代码模型生成的更多词元和概率的图;
图2是图示用于确定性和不确定性的解码源代码修复准则和关联符号的图;
图3是图示用于响应语法错误并且基于来自源代码和AST词元的概率分布数据来选择要应用的修复规则的伪代码逻辑的图;
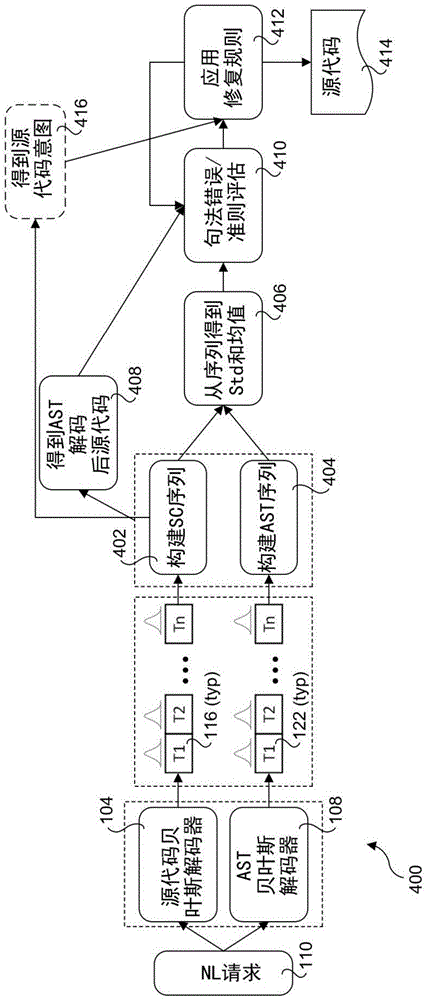
图4是图示根据一个实施例的使用图1a的多模态概率源代码模型的端到端过程流程的示意图;
图5示出与确定性语法词典(dgd)、源代码词汇列表(svl)和未定义列表(ndl)相对应的Python代码片段;
图6是图示根据一个实施例的由图4的端到端过程流程图用来从NL请求生成源代码的操作和逻辑的流程图;
图7是示出经由处理CoNaLa数据集获得的各种数据和字段的Pandas数据帧的一部分;
图8是图示用于Text2AST变换的贝叶斯编码器-解码器深度学习(DL)模型的拓扑的图;
图9是图示用于Text2Code变换的贝叶斯编码器-解码器深度DL模型的拓扑的图;以及
图10是可以用于实现本文描述和图示的实施例的各方面的计算平台或服务器的图。
具体实施方式
本文描述了用于实现用于文本到代码变换的双贝叶斯编码-解码的方法、设备和软件的实施例。在以下描述中,阐述了许多具体细节以提供对本发明的实施例的透彻理解。然而,相关领域的技术人员将认识到,能够在没有一个或多个具体细节的情况下或者用其他方法、组件、材料等来实践本发明。在其他情况下,未详细地示出或描述公知结构、材料或操作以避免使本发明的各方面混淆。
贯穿本说明书对“一个实施例”或“实施例”的引用意味着连同该实施例一起描述的特定特征、结构或特性被包括在本发明的至少一个实施例中。因此,短语“在一个实施例中”或“在实施例中”贯穿本说明书在各个地方中的出现不一定全部指代相同实施例。此外,可以在一个或多个实施例中以任何合适的方式组合特定特征、结构或特性。
为了清楚,本文图中的各个组件也可以通过它们在附图中的标签而不是通过特定附图标记来指代。另外地,指代特定类型的组件(与特定组件不同)的附图标记可以用后面有意指“典型”的“(typ)”的附图标记来示出。应理解,这些组件的配置将是可能存在但为了简单和清楚而在图中未示出的类似组件或未用单独的附图标记所标记的其他类似组件的典型配置。相反地,“(typ)”不应被解释为意味着组件、元素等被通常用于其公开的功能、实现方式、目的等。
源代码的结构可能变得极其复杂并且可以使用广泛开放的词汇。为了应对这个问题,大多数当前的模型(DL或概率)往往通过实现像抽象语法树(AST)/图形、开放词汇模型和注意力机制一样的结构表示来简化其范围。遗憾的是,这些方法的实施方式可能仍然导致计算密集型解决方案或者生成可能无法解析、编译、执行和/或解决问题的代码。
在本文描述和图示的实施例中,提出了一种根据由对应的贝叶斯编码器-解码器模型同时生成的两个(或任何数量的)概率分布序列来合并统计准则(均值和标准偏差)的方法,以大幅度地缩短文本到代码变换时间并且提高所得的代码准确性。在一个实施例中,包括文本到AST和文本到代码的同时变换被实现,以使用来自两个模型的预测的像“不确定性”和“确定性”之类的置信度度量来减少来自生成的源代码的语法和句法不一致。该方法使得我们能够减少用于修复经变换的代码的词汇和确定性规则。
该解决方案通过定义提供具有置信度水平的增强预测的深度学习模型来开始。为了实现这个,我们构建两个编码器-解码器模型,其中在解码器的最后层处具有密集翻转估计层,从而使得该模型能够近似解码后序列的每个词元的分布。
该解决方案具有两个贝叶斯编码器-解码器模型。贝叶斯编码器-解码器模型之一用于提取输入NL句子的含义并且提供包括源代码词元序列的解码输出。第二贝叶斯编码器-解码器模型将相同的NL句子解码成AST词元序列。此外,意图是为了并行实现这两个模型,因为训练阶段和推理阶段两者可以是独立的并且并行运行的。另外,通过对于源代码和AST词元具有分开的词元序列,这允许我们对于两个输出具有两组置信度。期望是关于AST词元序列具有较高的置信度水平,因为其与源代码词汇相比具有较小的词汇,意味着AST解码器将以较高的置信度在较小的解决方案域中泛化NL输入。
在一个实施例中,来自模型的置信度水平是通过从两个(源代码和AST)解码序列的每个词元预测计算认知不确定性(标准偏差)和确定性(均值)来测量的。
图1a的上部示出根据一个实施例的多模态概率源代码模型100的框图。模型100包括LSTM(长短期记忆)编码器102、源代码贝叶斯LSTM解码器104、LSTM编码器106和AST贝叶斯LSTM解码器108。LSTM编码器102和106使用三个词元序列(单词、词性(Parts of Speech,PoS)、和词元之间的依赖关系)来训练。LSTM编码器102和源代码贝叶斯LSTM解码器104被实现为文本到源代码(Text2Code)贝叶斯编码器-解码器(ED)模型109,而LSTM编码器106和AST贝叶斯LSTM解码器108被实现为文本到AST(Text2AST)贝叶斯ED模型111。
多模态概率源代码模型100被设计来接收NL请求(也称为NL输入或NL要求)并且将它们转换成源代码词元序列和AST词元序列。源代码贝叶斯LSTM解码器104(或更简单地称为源代码贝叶斯解码器104)和AST贝叶斯(LSTM)解码器108共同地包括用于源代码和AST的双贝叶斯解码器。由于仅Text2Code和Text2AST贝叶斯ED模型的解码器部分是贝叶斯模型,所以模型复杂性降低了。
LSTM编码器102和106中的每一个接收NL请求110,其在此示例中是“concatenateelements of a list x of multiple integers to a single integer(将多个整数的列表x的元素串接成单个整数)”。LSTM编码器102产生一组隐藏状态112,它们表示被传递给源代码贝叶斯LSTM解码器104的NL输入序列的上下文或含义。如所示,隐藏状态112包括隐藏状态(State_H)向量和单元状态(State_C)向量。隐藏状态向量和单元状态向量被源代码贝叶斯LSTM解码器104访问,如在下面说明的。源代码贝叶斯LSTM解码器104还包括含有目标源代码词元114的输入。源代码贝叶斯LSTM解码器104输出源代码词元序列116,每个源代码词元具有相应的概率分布(PD)。
LSTM编码器106产生一组隐藏状态118,该组隐藏状态包括隐藏状态向量和单元状态向量,它们被AST贝叶斯LSTM解码器108访问。AST贝叶斯LSTM解码器108还包括含有目标AST词元120的输入。AST贝叶斯LSTM解码器104输出AST词元序列122,每个AST词元具有相应的概率分布。
源代码贝叶斯LSTM解码器104和AST贝叶斯LSTM解码器108以类似方式操作。它们考虑到先前的编码器状态(State_H和State_C)以及表示训练数据的目标源代码和AST词元,基于当前词元来预测在它们相应的目标序列中的下一个词元。训练目标序列具有起始词元,所以解码器将从这个词元(起始词元)加上先前的编码器状态(State_H和State_C)预测第一源代码/AST词元。
表124示出Text2Code和Text2AST模型的输出。在序列中,每个目标词元是基于其在序列中的概率分布的最佳候选。对于源代码贝叶斯LSTM解码器,行包括片段目标行和片段解码行,以及概率确定性行和概率不确定性行。类似地,对于AST贝叶斯LSTM解码器,行包括AST目标行和AST解码行以及概率确定性和不确定性行。第二部分或源代码以及包括表126的AST词元序列和概率值被示出在图1b中。片段目标行描绘系统在应用“修复规则”之后的输出,如在下面讨论的。
片段目标行和片段解码行中的每一个包括源代码词元序列以及确定性和不确定性概率(置信度水平)。同时,AST目标行和AST解码行中的每一个包括AST词元(例如‘var’(变量)、‘opr’(操作)、‘mul’(乘法)、ndt(未定义词元)等)的序列。同样地,每个AST词元包括确定性和不确定性置信度水平。
由于AST词汇(包括目标AST词元120)小于源代码词汇(包括目标源代码词元114),所以AST解码序列具有更好的(较高的)置信度值。这是用于定义“修复准则”和关联规则的关键方面,如下。
根据从两个模型的置信度中提取的确定性和不确定性度量,定义了修复准则。图2图式地描述如何使用用于修复序列词元200的概率分布准则来将修复准则应用于源代码词元的修复规则。本质上,在AST词元预测下得到高置信度水平(低不确定性和高确定性)并且在源代码词元预测下得到低置信度水平(高不确定性和低确定性)提供系统应该将修复规则应用于此类源代码词元的清晰指示。如进一步图示的,在一些情况下基于规则修复源代码词元,然而在其他情况下基于遗传编程(GP)程序来修复源代码词元。
另外,如果源代码词元正在生成错误(例如,由解释器或编译器检测到的句法错误)并且源代码模型和AST模型都具有良好的置信度水平但是来自解码源代码的AST与解码后的AST词元不匹配,则搜索确定性语法词典来替换词元。必要时,可以重复此操作。
在图3中示出了用于考虑句法错误实现解码后源代码修复规则的伪代码300的示例。修复规则允许系统仅对具有较低置信度水平的源代码词元而不是对它们中的全部应用一小组确定性规则。因此,此方法可以大幅度地减少用于得到更准确结果的时间。
规则本质上是对输出序列置信度水平的解释,该解释在所生成的源代码由编译器或解释器抛出句法错误时开始,然后系统应用以下规则(在一个实施例下):
1.语法替换:当解码后AST词元具有高置信度并且解码后源代码词元具有低置信度时,使用“确定性语法词典”来查找替换。
2.词汇替换:当解码后AST词元值指代变量类型(var)词元时,那么用来自“词汇列表”的随机值替换它。作为选项,可以在单词之间应用余弦相似度来对替换进行优先级排序。
3.未知替换:当解码后AST词元值指代未知词元(ndt:未定义词元)时,那么从“未定义列表”的随机值替换词元。可选地,可以应用单词相似度算法来对替换迭代进行优先级排序。
4.贪婪替换:当解码后AST词元置信度低时,那么将所生成的源词元传递给贪婪程序;例如,这可能是遗传编程过程。这些种类的程序能够利用从结果中提取的度量而高度地获益。
图4示出根据一个实施例的用于实现解决方案的系统架构400。前端组件与图1a所示的相同,但是已被简化以节省空间,其中所图示的组件包括NL请求110、源代码贝叶斯(LSTM)解码器104和AST贝叶斯(LSTM)解码器108,它们分别输出各自具有相应的概率分布的源代码词元序列116和AST词元序列122。
源代码词元序列116被作为输入提供给在其中构建源代码序列的框402。类似地,AST词元序列122被作为输入提供给在其中构建AST序列的框404。为了构建PD,每个模型为每个词元生成具有不同不确定性水平(标准偏差(std))和确定性(均值)的一组输出序列。单个序列是用具有概率分布的最大概率值的词元从每个模型(一个用于源代码而另一个用于AST)输出构建的。
框402和404的输出被作为输入提供给框406,在框406中从与源代码和AST词元相关联的概率分布数据导出std和均值。如上所述,来自每个词元序列的std和均值被用作修复准则。来自框404的输出也用于得到AST解码后源代码,如框408中描绘的。来自输出源代码序列的AST被用于对照来自AST贝叶斯模型的输出序列进行比较。
来自框406和408的输出被作为输入提供给框410,在框410中酌情检测句法错误并且/或者应用准则评估。如上所述,如果编译器或解释器找到句法错误,则在框412中应用适当的修复规则。如果不存在句法错误但是来自解码后源代码的AST与来自解码后AST模型的AST不匹配,则可以在框412中同样地应用适用规则。如由从框412到框410的环回示出的,在应用修复规则之后可以重新评估所得的更新后的源代码以优化输出。也可能用遗传编程来执行此优化过程。在一个实施例中,重复框410和412中的操作,直到未检测到句法错误并且准则评估指示将不应用变化为止。系统的此输出是源代码414。
在一些实施例中,还可以使用源代码意图(也称为“开发者意图”),如可选框416中描绘的。例如,为了有构建更有选择性的词汇,可以将具有类似开发意图的代码用作当在框412中应用修复规则时要考虑的附加输入。
在一个方面中,开发者意图包括基于代码和(可选地)注释中的关键词和实体来确定代码片段、方法、函数或其他代码块的意图。此技术从代码中提取方法名称、方法调用、枚举、字符串文字和注释。此技术使用文本嵌入来生成所提取的特征的向量表示。如果两个向量表示的单词经常出现在类似上下文中,则它们在向量空间中靠近在一起。此技术将代码的意图确定为嵌入向量的加权平均值。此技术通过为NL查询生成嵌入向量、确定NL查询的意图(例如,经由加权平均值)、并且针对方法的加权平均值执行相似度搜索来返回用于给定自然语言查询的代码。
图5示出被用于替换源代码词元的确定性语法词典(dgd)500、源代码词汇列表(svl)502和未定义列表(ndl)504的示例。Dgd500包含包括文本值和源代码词元的成对集合。在适用的seq2seq模型中源代码词元(其可以包括运算符[列举其他选项])被取代以替换文本值。例如,文本“add”用“+”运算符替换,文本“sub”用“-”运算符替换,文本“div”用“/”运算符替换等。
Svl 502包括含有可能存在于源代码中的词元(例如‘False(假)’、‘None(无)’、‘True(真)’、‘and(与)’等)的源代码词汇列表。源代码词汇列表将取决于要生成的源代码的类型。注意,svl 502是相对小的示例性列表—在实践中,用于给定类型的源代码的svl可以大得多。
ndl 504示出了未被包括在dgd 500或svl 502中的未定义值的列表。在此示例中,ndl 504包括[‘5’,‘,’,‘.’]。再次,这个列表出于说明性目的而被简化了,因为实际的ndl可能大得多。
图6示出根据一个实施例的图示用于实现编码-解码过程的操作和逻辑的流程图600。在开始框602之后,过程从NL请求110开始,所述NL请求110被作为输入提供给Text2Code seq2seq模型109和Text2AST seq2seq模型111,如以上图1a中图示的。如由判定框604描绘的,在所图示的实施例中,包括Text2Code seq2seq模型109的输出源代码词元序列116的预测被评估和重新评估5次,其中5是示例性迭代次数。类似地,如由判定框604描绘的,包括Text2AST seq2seq模型111的输出AST词元序列122的预测被评估和重新评估5次。
源代码seq2seq模型109和AST seq2seq模型111的经修订后的词元序列输出被作为输入提供给框608,在框608中序列用具有较高的概率水平的词元来构建。接下来,在框610中来自预测的标准偏差和均值被获取并用于在框612中从预测得到AST词元。
在判定框614中做出是否存在任何句法错误并且是否满足匹配准则的判定。如果回答为否,则逻辑进行到框616,在框616中从来自判定框614的错误消息输出中获取“坏”词元索引并且在框618中应用适用的修复规则。在应用修复规则之后,经修订后的词元序列被反馈给框612并且重复判定框614以及框616和618的操作,直到对判定框614的回答为是为止,此时输出源代码并且过程完成,如由结束框620所指示的。
作为选项,可以对过程应用利用开发者意图和/或类似源代码片段的一个或多个优化。例如,这可以包括如框622所示的那样使用上述方式来得到源代码意图。另一优化在本体(ontology)中搜索类似的代码片段,如框624所示。在框626中,从在框624中标识的类似的代码片段构建词元替换结构。从框626输出的经修订后的词元序列被作为输入提供给框618。
实验结果和示例模型
作为概念的证明,使用Keras/TensorFlow来实现两个贝叶斯Seq2Seq源代码和AST模型。模型使用“代码/自然语言质询”(CoNaLa)数据集来训练。包括在https://conala-corpus.github.io/处可获得的JSON文件的此数据集包含从Stack Overflow问题导出的NL样本及其对应的Python片段。图7示出了包括通过处理JSON文件所获得的Pandas数据帧700的CoNaLa数据集的小部分的示例。
数据帧700中的列包括词元列702、PoS(词性)列704、Deps(从属单元)列706、代码列708和PoC(代码部分)列710。词元列702包含由逗号划定的NL词元序列。相应词元被变换成词性,如PoS列704中所示。
Deps列706中的每个条目是包括输入要求中的每个词元的句法关系依赖关系的一组标签的输入序列。Deps输入序列像判别特征向量一样与单词词元和词性相结合地使用,以使得编码器能够更好地表示NL句子的含义。Deps输入序列是贝叶斯ED模型的三个输入序列之一。
代码列708包含用于源代码解码器的目标序列(例如,图1a中的目标源代码词元114)。PoC列710包含作为用于AST解码器的目标的对应AST的序列表示。
图8示出了用于由AST贝叶斯ED模型111实现的Text2AST变换的贝叶斯编码器-解码器DL模型拓扑。在该拓扑中,‘?’值是可变的并且取决于在输入层处提供的输入。同时,诸如‘3’、‘700’和‘19’的整数值指定沿着关联维度的节点的数目。在TensorFlow下,通过假设核和/或偏差是从分布提取的,DenseFlipout层实现与密集层类似的贝叶斯变分推理。默认情况下,该层经由从核和偏差后验采样来实现随机前向传递。此层使用Wen,Yeming等人的“Flipout:Efficient pseudo-independent weight perturbations on mini-batches.”arXiv preprint arXiv:1803.04386(2018)中描述的Flipout估计器,其对在核和偏差上积分的分布执行蒙特卡洛近似。
图9示出了由Text2Code贝叶斯ED模型109实现的用于Text2Code变换的贝叶斯编码器-解码器DL模型拓扑。如将认识到的,除了因为AST词汇小于源代码词汇所以DenseFlipout层的输出的维度基本上较小(19对196)之外,用于Text2Code变换的贝叶斯编码器-解码器DL模型拓扑与用于Text2AST变换的贝叶斯编码器-解码器DL模型拓扑基本上相同。
示例结果
在图1b中示出了针对输入序列“concatenate elements of a list xofmultiple integers to a single integer”的示例结果。使用图1a、图2-4和图6的流程图600中图示的过程,由于由Python解释器抛出的某个数量的句法错误(六个错误),系统将在所预测的源代码序列上迭代6次。在第7列中,尽管SC解码词元‘for’的确定性和不确定性值指示高置信度,但是解释器将在这里抛出错误,导致修复规则被应用。基于AST解码词元的高置信度,修复规则是用‘**’替换‘for’,所述‘**’对应于来自图5中的确定性语法词典(dgd)500的pow(幂)AST词元。显然,只需6次迭代即可从贝叶斯编码器-解码器模型的输出生成可解释的代码。相比之下,当前的实施方式可能进行23次迭代(每个AST词元各一次)来遍历整个AST序列表示。因此,此实验结果突出显示了使用本文公开的创新方法的4倍加速。
示例平台/服务器
图10描绘可以在其中实现以上公开的实施例的各方面的计算平台1000,诸如服务器或类似的计算系统。计算平台1000包括一个或多个处理器1010,其为计算平台1000提供指令的处理、操作管理和运行。处理器1010可以包括任何类型的微处理器、中央处理单元(CPU)、图形处理单元(GPU)、处理核心、多核心处理器或为计算平台1000提供处理的其他处理硬件、或处理器的组合。处理器1010控制计算平台1000的整体操作,并且可以是或者包括一个或多个可编程通用或专用微处理器、数字信号处理器(DSP)、可编程控制器、专用集成电路(ASIC)、可编程逻辑器件(PLD)等,或此类装置的组合。
在一些实施例中,可以在CPU与GPU之间分割处理。例如,常见的是在包括CPU和GPU的计算平台上实现TensorFlow。在一些实施例中,CPU和GPU是单独的组件。在其他实施例中,可以在片上系统(SoC)中或在多芯片模块等中实现CPU和GPU。
在一个示例中,计算平台1000包括耦合到处理器1010的接口1012,其可以表示用于需要较高带宽连接的系统组件(如存储器子系统1020或可选的图形接口组件1040或可选的加速器1042)的较高速度接口或高吞吐量接口。接口1012表示可以为独立组件或被集成到处理器管芯上的接口电路。在存在的情况下,图形接口1040对接到图形组件以用于向计算平台1000的用户提供视觉显示。在一个示例中,图形接口1040可以驱动向用户提供输出的高清晰度(HD)显示器。高清晰度可以指代具有大约100PPI(每英寸像素)或更大的像素密度的显示器并且可以包括诸如全HD(例如,1080p)、视网膜显示器、4K(超高清晰度或UHD)或其他的格式。在一个示例中,显示器可以包括触摸屏显示器。在一个示例中,图形接口1040基于存储在存储器1030中的数据或者基于由处理器1010运行的操作或兼而有之来生成显示。在一个示例中,图形接口1040基于存储在存储器1030中的数据或者基于由处理器1010运行的操作或兼而有之来生成显示。
在一些实施例中,加速器1042可以是能够由处理器1010访问或使用的固定功能卸载引擎。例如,加速器1042当中的加速器能够提供数据压缩能力、诸如公钥加密(PKE)、密码、散列/认证能力、解密的密码服务,或其他能力或服务。在一些实施例中,另外或可替换地,加速器1042当中的加速器提供如本文描述的现场选择控制器能力。在一些情况下,加速器1042能够被集成到CPU插口(例如,到包括CPU并且提供与CPU的电接口的主板或电路板的连接器)中。例如,加速器1042可以包括单或多核心处理器、图形处理单元、逻辑运行单元单级或多级缓存、可用于独立地运行程序或线程的功能单元、专用集成电路(ASIC)、神经网络处理器(NNP)、可编程控制逻辑和可编程处理元件,诸如现场可编程门阵列(FPGA)。加速器1042可以提供多个神经网络、CPU、处理器核心、通用图形处理单元,或者可以提供图形处理单元以供AI或ML模型使用。例如,AI模型可以使用或包括以下项中的任一个或组合:强化学习方案、Q学习方案、深度Q学习或异步优势演员-评论员(A3C)、组合神经网络、循环组合神经网络、或其他AI或ML模型。可以提供多个神经网络、处理器核心或图形处理单元以供AI或ML模型使用。
存储器子系统1020表示计算平台1000的主存储器并且为要由处理器1010运行的代码或要在运行例程时使用的数据值提供存储。存储器子系统1020可以包括一个或多个存储器装置1030,诸如只读存储器(ROM)、闪速存储器、一种或多种随机存取存储器(RAM)如DRAM、或其他存储器装置,或此类装置的组合。存储器1030尤其存储并托管操作系统(OS)1032以提供用于在计算平台1000中运行指令的软件平台。另外地,应用1034可以在来自存储器1030的OS 1032的软件平台上运行。应用1034表示具有它们自己的操作逻辑来执行一个或多个功能的运行的程序。进程1036表示向OS 1032或一个或多个应用1034或组合提供辅助功能的代理或例程。OS1032、应用1034和进程1036提供软件逻辑来为计算平台1000提供功能。在一个示例中,存储器子系统1020包括存储器控制器1022,其是用于生成并向存储器1030发出命令的存储器控制器。应理解,存储器控制器1022可能是处理器1010的物理部分或接口1012的物理部分。例如,存储器控制器1022可以是与处理器1010一起集成到电路上的集成存储器控制器。
虽然未具体地图示,但是应理解,计算平台1000可以包括装置之间的一个或多个总线或总线系统,诸如存储器总线、图形总线、接口总线或其他。总线或其他信号线可以将组件通信地或电力地耦合在一起,或者既通信地又电力地耦合组件。总线可以包括物理通信线、点对点连接、桥接器、适配器、控制器或其他电路系统或组合。总线可以包括例如以下项中的一个或多个:系统总线、外围组件互连(PCI)总线、超级传输或工业标准架构(ISA)总线、小型计算机系统接口(SCSI)总线、通用串行总线(USB)或电气与电子工程师协会(IEEE)标准1394总线(Firewire)。
在一个示例中,计算平台1000包括接口1014,其可以耦合到接口1012。在一个示例中,接口1014表示接口电路,其可以包括独立组件和集成电路系统。在一个示例中,多个用户接口组件或外围组件或两者耦合到接口1014。网络接口1050为计算平台1000提供通过一个或多个网络与远程装置(例如,服务器或其他计算装置)进行通信的能力。网络接口1050可以包括以太网适配器、无线互连组件、蜂窝网络互连组件、USB(通用串行总线)或其他基于有线或无线标准的或专有接口。网络接口1050可以向位于同一数据中心或机架中的装置或远程装置传送数据,这可以包括发送存储在存储器中的数据。网络接口1050可以从远程装置接收数据,这可以包括将接收到的数据存储到存储器中。可以连同网络接口1050、处理器1010和存储器子系统1020一起使用各种实施例。
在一个示例中,计算平台1000包括一个或多个IO接口1060。IO接口1060可以包括用户通过其与计算平台1000交互的一个或多个接口组件(例如,音频、字母数字、触觉/触摸或其他接口)。外围接口1070可以包括上面未具体地提及的任何硬件接口。外围装置通常指代依赖地连接到计算平台1000的装置。依赖连接是计算平台1000提供操作在其上运行并且用户与之交互的软件平台或硬件平台或两者的连接。
在一个示例中,计算平台1000包括存储子系统1080来以非易失性方式存储数据。在一个示例中,在某些系统实施方案中,存储装置1080的至少某些组件可以与存储器子系统1020的组件重叠。存储子系统1080包括存储装置1084,其可以是或者包括用于以非易失性方式存储大量数据的任何常规介质,诸如一个或多个磁盘、固态盘或光盘,或组合。存储装置1084将代码或指令和数据1086保持在持久状态下(即,即使到计算平台1000的电力中断也保留值)。存储装置1084通常可以被认为是“存储器”,但是存储器1030通常是向处理器1010提供指令的运行或工作存储器。虽然存储装置1084是非易失性的,但是存储器1030可以包括易失性存储器(即,如果对计算平台1000中断电力则数据的值或状态是不确定的)。在一个示例中,存储子系统1080包括要与存储装置1084接口的控制器1082。在一个示例中,控制器1082是接口1014或处理器1010的物理部分或者可以包括处理器1010和接口1014两者中的电路或逻辑。
易失性存储器是其状态(以及因此存储在其中的数据)在对装置中断电力的情况下不确定的存储器。动态易失性存储器需要刷新存储在装置中的数据以维持状态。动态易失性存储器的一个示例包括DRAM(动态随机存取存储器)或诸如同步DRAM(SDRAM)的某个变体。如本文描述的存储器子系统可以与诸如以下项的许多存储器技术兼容:DDR3(双倍数据速率版本3,由JEDEC(联合电子装置工程委员会)于2007年6月27日最初发布)、DDR4(DDR版本4,由JEDEC于2012年9月发布的初始规范)、DDR4E(DDR版本4)、LPDDR3(由JEDEC于2013年8月发布的低功耗DDR版本3,JESD209-3B,)、LPDDR4(由JEDEC于2014年8月最初发布的LPDDR版本4,JESD209-4)、WIO2(由JEDEC于2014年8月最初发布的宽输入/输出版本2,JESD229-2)、HBM(由JEDEC于2013年10月发布最初的高带宽存储器,JESD325)、DDR5(DDR版本5)、LPDDR5、HBM2E、HBM3和HBM-PIM或其他或存储器技术的组合,以及基于此类规范的衍生物或扩展的技术。JEDEC标准可在www.jedec.org处获得。
非易失性存储器(NVM)装置是即使对装置中断电力的情况下其状态也是确定性的存储器。在一个实施例中,NVM装置可以包括块可寻址存储装置,诸如NAND技术,或更具体地,多阈值级NAND闪速存储器(例如,单级单元(“SLC”)、多级单元“MLC”、四级单元(“QLC”)、三级单元(“TLC”)或某个其他NAND)。NVM装置还可以包括字节可寻址的就地写入的三维交叉点存储器装置,或其他字节可寻址的就地写入NVM装置(也称为持久存储器),诸如单级或多级相变存储器(PCM)或带开关的相变存储器(PCMS)、使用硫族化物相变材料(例如,硫族化物玻璃)的NVM装置、包括金属氧化物基、氧空位基和导电桥随机存取存储器(CB-RAM)的电阻式存储器、纳米线存储器、铁电随机存取存储器(FeRAM、FRAM)、并入忆阻器技术的磁阻式随机存取存储器(MRAM)、自旋转移矩(STT)-MRAM、基于自旋电子磁结存储器的装置、基于磁隧道结(MTJ)的装置、基于DW(域壁)和SOT(自旋轨道转移)的装置、基于晶闸管的存储器装置、或上述中的任一个的组合、或其他存储器。
在示例中,计算平台1000可以使用处理器、存储器、存储装置、网络接口和其他组件的互连计算部件来实现。可以使用高速互连,诸如:以太网(IEEE802.3)、远程直接存储器存取(RDMA)、InfiniBand、互联网广域RDMA协议(iWARP)、快速UDP互联网连接(QUIC)、基于融合以太网的RDMA(RoCE)、外围组件互连快速(PCIe)、
除了具有CPU的系统之外,本文公开的教导和原理还可以被应用于包括以下项中的一个或多个的其他处理单元(统称为XPU):图形处理器单元(GPU)或通用GPU(GP-GPU)、张量处理单元(TPU)、数据处理器单元(DPU)、基础设施处理单元(IPU)、人工智能(AI)处理器或AI推理单元和/或其他加速器、FPGA和/或其他可编程逻辑(用于计算目的)等。虽然本文的一些图示出CPU的使用,但是这仅仅是示例性的而非限制性的。通常,在所图示的实施例中可以使用任何类型的XPU代替CPU。此外,如以下权利要求中使用的,术语“处理器”用于通常涵盖CPU和各种形式的XPU。
如本领域的技术人员将认识到的,ML框架的实施方案,诸如但不限于TensorFlow,可以采用单个机器(计算平台、服务器、计算节点等)或者可以采用分布式机器集合。因此,用于实现本文描述和图示的ML模型的系统可以包括用于单个计算平台/服务器/节点或一组互连的计算平台、服务器或节点的计算资源(例如,处理器、存储器等)。此外,进程可以分布在单个机器中的一组计算资源之上,诸如跨越多核心处理器中的CPU核心分布、分布在CPU与GPU之间、分布在多个GPU当中、或更一般地跨越包括CPU和XPU的多个处理器分布。
在一些实施例中,用于训练ML模型的系统可以不同于用于实现训练后的模型的计算平台。例如,由于训练通常比使用训练后的模型消耗更多的计算资源,所以可以使用一组分布式计算节点等来执行训练,而训练后的模型可能在单个计算节点/平台/服务器等上实现。
尽管已经参考特定实施方式描述了一些实施例,但是根据一些实施例其他实施方式也是可能的。另外,不需要以所图示和描述的特定方式布置在本附图中图示和/或在本文中描述的元素或其他特征的布置和/或次序。根据一些实施例,许多其他布置是可能的。
在图中所示的每个系统中,元素在一些情况下可以分别具有相同的附图标记或不同的附图标记以提示所表示的元素可能是不同的和/或类似的。然而,元素可以足够灵活以具有不同的实施方式并且与本文示出或描述的一些或所有系统一起工作。图中所示的各种元素可以是相同的或不同的。哪个元素被称为第一元素并且哪个元素被称作第二元素是任意的。
在说明书和权利要求书中,可以使用术语“耦合”和“连接”以及它们的派生词。应该理解,这些术语不旨在作为彼此的同义词。相反,在特定实施例中,“连接”可以用于指示两个或更多个元素彼此直接物理或电接触。“耦合”可能意味着两个或多个元素直接物理或电接触。然而,“耦合”也可能意味着两个或多个元素彼此不直接接触,但又仍然彼此合作或交互。另外地,“通信地耦合”意味着可能或可能不彼此直接接触的两个或更多个元素被实现为彼此通信。例如,如果组件A连接到组件B,组件B又连接到组件C,则组件A可以使用组件B作为媒介组件通信地耦合到组件C。
实施例是发明的实施方式或示例。在说明书中对“实施例”、“一个实施例”、“一些实施例”或“其他实施例”的引用意味着结合该实施例一起描述的特定特征、结构或特性被包括在发明的至少一些实施例而不一定是所有实施例中。各种出现“实施例”、“一个实施例”或“一些实施例”不一定全部指代相同的实施例。
并非本文描述和图示的所有组件、特征、结构、特性等都需要被包括在一个或多个特定实施例中。例如,如果说明书陈述组件、特征、结构或特性“可以”、“也许”、“能够”或“可能”被包括,则不要求包括该特定组件、特征、结构或特性。如果说明书或权利要求提及“一”或“一个”元素,则这不意味着只有一个元素。如果说明书或权利要求提及“附加”元素,则不排除存在一个以上附加元素。
如以上讨论的,本文的实施例的各个方面可以通过对应的软件和/或固件组件和应用(例如由嵌入式处理器等运行的软件和/或固件)来促进。因此,本发明的实施例可以被用作或用于支持在某种形式的处理器、处理核心或嵌入式逻辑上运行的软件程序、软件模块、固件和/或分布式软件、在处理器或核心上运行或者在非暂时性计算机可读或机器可读存储介质上或之内以其他方式实施或实现的虚拟机。非暂时性计算机可读或机器可读存储介质包括用于以可由机器(例如,计算机)读取的形式存储或传送信息的任何机制。例如,非暂时性计算机可读或机器可读存储介质包括以可由计算机或计算机器(例如,计算装置、电子系统等)访问的形式提供(即,存储和/或传送)信息的任何机制,诸如可记录/不可记录介质(例如,只读存储器(ROM)、随机存取存储器(RAM)、磁盘存储介质、光学存储介质、闪速存储器装置等)。内容可以是直接可运行的(“对象”或“可运行的”形式)、源代码或差异代码(“增量”或“补丁”代码)。非暂时性计算机可读或机器可读存储介质还可以包括能够从其下载内容的存储装置或数据库。非暂时性计算机可读或机器可读存储介质还可以包括在销售或交付时在其上存储有内容的装置或产品。因此,交付具有存储的内容的装置或提供内容以用于通过通信介质下载可以被理解为提供包括本文描述的具有这种内容的非暂时性计算机可读或机器可读存储介质的制品。
由本文描述的各种组件执行的操作和功能可以通过在处理元件上运行的软件、经由嵌入式硬件等或硬件和软件的任何组合来实现。可以将此类组件实现为软件模块、硬件模块、专用硬件(例如,专用硬件、ASIC、DSP等)、嵌入式控制器、硬接线电路系统、硬件逻辑等。软件内容(例如,数据、指令、配置信息等)可以经由包括非暂时性计算机可读或机器可读存储介质的制品来提供,该非暂时性计算机可读或机器可读存储介质提供表示能够被运行的指令的内容。该内容可以导致计算机执行本文描述的各种功能/操作。
如本文所使用的,通过术语“……中的至少一个”接合的项目的列表可以意指所列举的术语的任何组合。例如,短语“A、B或C中的至少一个”可以意指A;B;C;A和B;A和C;B和C;或A、B和C。
对本发明的图示实施例的以上描述,包括在说明书摘要中描述的内容,不旨在为详尽的或者将本发明限于所公开的精确形式。虽然在本文中出于说明性目的描述了本发明的特定实施例和示例,但是如相关领域的技术人员将认识到那样,在本发明的范围内各种等效修改都是可能的。
可以根据以上详细描述对本发明做出这些修改。以下权利要求中使用的术语不应该被解释为将本发明限于在说明书和附图中公开的特定实施例。相反,本发明的范围将完全由以下权利要求确定,以下权利要求将依照权利要求解释的既定原则来解释。
- 一种用于对象检测器的使用贝叶斯双自编码器的可解释性主动学习的方法和使用其的主动学习设备
- 结合编码深度估计和贝叶斯判决的SHVC快速编码方法