一种基于自蒸馏的少样本图像分类方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及图像数据处理的技术领域,尤其涉及一种基于自蒸馏的少样本图像分类方法。
背景技术
近年来,深度学习技术广泛应用于推荐系统、自动驾驶、智能医疗等领域,为科研发展、经济发展和社会发展带来了巨大推动。但是,深度学习在实际应用过程中面临两大挑战。首先,深度学习取得的巨大成就在相当程度上得益于大规模高质量的训练数据的使用,由于数据隐私、法律法规等问题,在现实场景中的一些数据集往往很难直接获取。其次,为了更好的应对错综复杂的学习任务,现有模型复杂度极高,训练和部署需要消耗大量的计算资源和存储资源,难以直接应用在流行的嵌入式设备和移动设备中。
近年来随着研究人员的努力,人们设计了许多有效的方法来探索在只有少量训练样本的情况下提升模型的预测能力,但现有的方法仍然存在模型性能与复杂度之间的矛盾。少样本学习中目前的主流模型为Conv64和ResNet12,Conv64模型复杂度低,但其分类能力远低于ResNet12;ResNet12可以获得更优的预测效果,但其存在模型复杂度高、推理速度过慢的问题,无法应用在资源受限设备中。
发明内容
本发明的目的在于提供一种基于自蒸馏的少样本图像分类方法,不仅能够降低模型部署所需计算资源和存储资源,而且能够在只有少量数据的情况下显著提升模型的分类效果。
本发明采用的技术方案是:
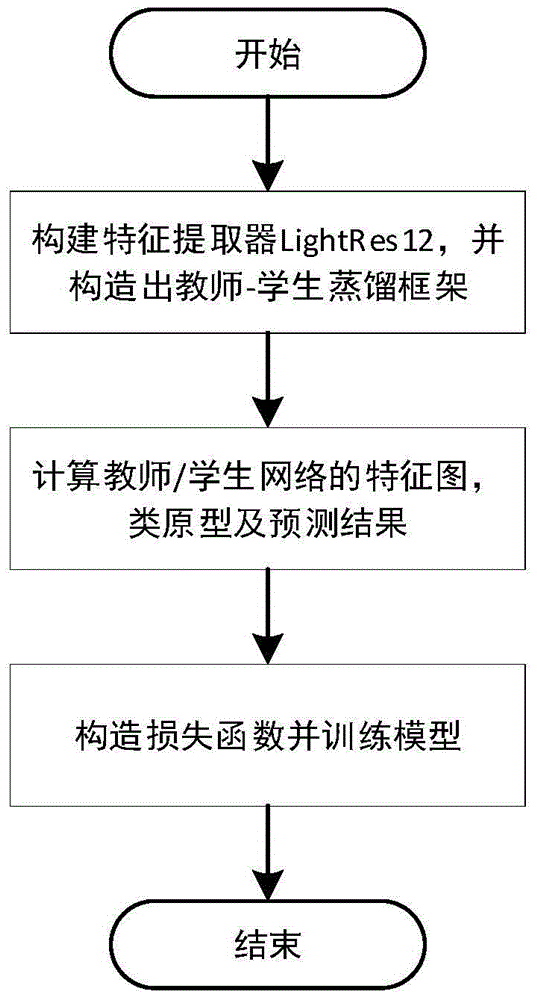
一种基于自蒸馏的少样本图像分类方法,包括以下步骤:
步骤1:构建少样本图像分类训练集;从训练数据集中随机抽取C类数据;每一类随机抽取K张样本,作为支持集
步骤2:构建轻量级特征提取网络LightRes12并构造出教师-学生蒸馏框架;特征提取网络LightRes12包括依次连接的4个残差块和特征图拼接层,每个残差块包括3个深度可分离卷积层,前三个浅层网络的残差块作为学生模型,最后一个最深层网络的残差块作为教师模型;在每个残差块后面构建一个双重注意力DAM模块,双重注意力DAM模块包括并行计算的空间注意力和通道注意力;通过特征图拼接操作得到总体注意力图;
步骤3:将支持集和查询集作为教师-学生蒸馏框架的输入,基于自蒸馏和原型网络思想分别算教师网络的特征图、类原型和预测结果以及学生网络的特征图、类原型和预测结果;
步骤4:构造模型训练的总损失函数,对教师-学生蒸馏框架的LightRes12进行训练,直至网络收敛;
步骤5:将测试集的图像输入到训练好的LightRes12模型中,获取测试集图像的特征向量,即可获得图像的分类预测结果。
进一步地,步骤1中并对抽取的支持集和查询集中样本进行顺时针旋转变换、水平翻转实现数据增强。
进一步地,步骤2中每个双重注意力DAM模块的输出端拼接一个距离度量模块。
进一步地,步骤3的具体步骤包括:
步骤31:将支持集S和查询集Q输入到残差网络中,经过特征提取得到不同的特征向量,支持集S中样本X
步骤32:将F
其中,i表示不同分支网络的计算结果,n表示支持集中的第n个类,F
进一步地,步骤4的具体步骤包括:
步骤41:构建不同分支得到的特征映射之间的损失函数L
其中,F
步骤42:基于知识蒸馏的思想构建不同分支预测得到的类概率分布损失函数L
其中,T表示蒸馏温度,p
步骤43:构造不同分支与真实标签的交叉熵损失函数L
其中,i表示不同的学生网络,p
步骤44:构建的残差网络模型的总损失函数为:
loss=L
本发明采用以上技术方案,与现有技术相比,本发明具有以下有益效果:1、基于深度可分离卷积构建一个轻量级的特征提取模型LightRes12,大幅度减少模型训练所需的计算资源和存储资源。2、将特征提取模型划分为几个分支,在每个分支后添加一个双重注意力模型,提高浅层分支对图像的特征提取能力,所有浅层的双重注意力模块均仅在模型训练时使用,不额外增添模型的参数量。3、所提方案基于自蒸馏思想和元学习思想,在仅有少量数据可用的条件下增强模型对图像的特征提取能力,提高模型的图像分类效用。
附图说明
以下结合附图和具体实施方式对本发明做进一步详细说明;
图1为本发明优选实施例的实现流程图;
图2为本发明优选实施例的轻量级特征提取网络LightRes12结构示意图;
图3为本发明优选实施例的双重注意力DAM结构示意图;
图4为本发明优选实施例的整体方案结构示意图。
实施方式
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图对本申请实施例中的技术方案进行清楚、完整地描述。
本发明为了解决模型训练及部署需要大量资源的问题,提出一个轻量级特征提取网络LightRes12、为了解决训练需要大量数据样本的问题,在原型网络的思想上,提出基于自蒸馏的单阶段端到端模型训练方法。本发明通过自监督学习训练得到具有特征提取能力的嵌入网络模型,将嵌入网络模型应用到元学习框架中进行分类训练,最后使用自蒸馏方法对模型进行精简。本发明只包含一个轻量级的网络LightRes12,其既是教师网络也是学生网络。本发明的训练属于单阶段端到端训练,直接在特征提取模型上构建自蒸馏框架,并引入注意力机制来增强模型的特征提取能力,不需要增加额外运算也不需要额外的存储空间。本发明中进行蒸馏的知识包括:特征图信息,教师网络输出的软标签信息。
如图1至图4之一所示,本发明公开了一种基于自蒸馏的少样本图像分类方法,包括以下步骤:
步骤1:构建轻量级特征提取网络LightRes12,并构造出教师-学生蒸馏框架;
(1.1):构建一个轻量级的特征提取网络LightRes12,由4个残差块组成,每个残差块包含3个深度可分离卷积层。根据深度和原始结构,残差网络前三个浅层网络视为学生模型,最深层网络视为教师模型;
(1.2):在每个残差块后面构建一个双重注意力DAM,所述DAM包括空间注意力和通道注意力,两者并行计算,最终通过特征图拼接操作得到总体注意力图;
(1.3):每个DAM模块后面拼接一个距离度量模块;
步骤2:从训练数据集中选取支持集和查询集作为模型的输入,基于自蒸馏和原型网络思想计算教师网络和学生网络的特征图,类原型和预测结果;
(2.1):从训练数据集中随机抽取C类数据;每一类随机抽取K张样本,作为支持集
(2.2):将支持集S和查询集Q输入到残差网络中,经过特征提取得到不同的特征向量,支持集S中样本X
(2.3):将F
其中,i表示不同分支网络的计算结果,n表示支持集中的第n个类,F
步骤3:构造模型训练的总损失函数,对步骤1构建的LightRes12进行训练,直至网络收敛;
(3.1):构建不同分支得到的特征映射之间的损失函数L
(3.2):基于知识蒸馏的思想,构建不同分支预测得到的类概率分布损失函数L
其中,T表示蒸馏温度,p
(3.3):构造不同分支与真实标签的交叉熵损失函数L
(3.4):构建的残差网络模型的总损失函数为:
loss=L
下面结合实验示例,对本发明的效果作进一步的说明。
实验配置:
我们在miniImageNet数据集上进行实现,miniImageNet数据集由100类彩色图像组成,每类包含600张图像(共有60000张)。在我们的实验中,我们将这100个类划分为64、16和20个类,分别用于训练、验证和测试。所有实验都使用pytoch-1.13在12th Gen Intel(R)Core(TM)i9-12900 CPU和NVIDIA RTX A5000 GPU上进行。实验过程中,我们使用SGD作为优化器,学习率为0.01,动量参数为0.9,学习衰减率为6e-5。实验过程中,我们进行了5way1shot和5way5shot的分类任务,即C=5,K=1,5,每类有15个查询样本,最终的分类准确性为1000次测试结果的均值,并以95%的置信区间报告。
实验结果与结论:
为证明本发明的优越性,我们在miniImageNet数据集上与4种基线方法进行对比,实验结果如表1所示。
表1不同方案的分类准确率
从以上实验结果可以得出:本发明所提方法可以获得更优的分类效能,这是因为我们引入了注意力机制,使得特征提取器可以更好的关注图像种的重要特征,忽略不必要的信息,提升模型的判断能力。利用自蒸馏的方法训练模型,也能够提高特征提取器浅层网络的特征提取能力。
本发明的另一目的是在保持模型准确率的同时,降低模型的计算成本和复杂度,为此,我们与少样本图像分类中常用的两个特征提取器Conv64和ResNet12进行模型复杂度比较,表2展示了本发明在不同特征提取器上的分类准确率和复杂度。
表2不同特征提取器下,本发明的测试精度和模型复杂度
从以上实验结果可以得出:本发明提出的LightRes12网络参数量仅比Conv64网络高0.44M,但比ResNet12网络低11.88M;FLOPs数量比Conv64高15806.02M~19765.03M,比ResNet12低258063.39M~322579.24M。但LightRes12模型训练得到的精度结果仅比ResNet12模型训练得到的精度结果低0.07%~1.49%,比Conv64模型训练得到的精度高6.20%~7.66%。实验结果表明,LightRes12网络可以在损失极少精度的情况下,大幅度减少模型的参数数量和浮点运算数,使得模型可以运行在资源受限的设备中。
本发明采用以上技术方案,与现有技术相比,本发明具有以下有益效果:1、基于深度可分离卷积构建一个轻量级的特征提取模型LightRes12,大幅度减少模型训练所需的计算资源和存储资源。2、将特征提取模型划分为几个分支,在每个分支后添加一个双重注意力模型,提高浅层分支对图像的特征提取能力,所有浅层的双重注意力模块均仅在模型训练时使用,不额外增添模型的参数量。3、所提方案基于自蒸馏思想和元学习思想,在仅有少量数据可用的条件下提高模型的分类效用。
显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。通常在此处附图中描述和示出的本申请实施例的组件可以以各种不同的配置来布置和设计。因此,本申请的实施例的详细描述并非旨在限制要求保护的本申请的范围,而是仅仅表示本申请的选定实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
- 一种基于异常点暴露的少样本图像分类方法及系统
- 一种基于特征转换的少样本图像分类方法