一种指令处理方法、指令处理装置和芯片
文献发布时间:2023-06-19 09:26:02
技术领域
本发明涉及处理器技术领域,具体涉及一种指令处理方法、指令处理装置和芯片。
背景技术
顺序指令流水线是一种处理器微架构,用来提高处理器指令执行的效率。顺序指令流水线将一条指令的执行过程分为若干个子过程(阶段),也称为级(stage),每个子过程和其他子过程并行进行。由于这种工作方式与工厂中的生产流水线十分相似,因此称为流水线。一种常见的顺序指令流水线通常分为五级:取指令(Fetch)、解析指令(Decode)、执行指令(Execute)、读写内存(Memory Access)、结果写回寄存器(Write-back)。顺序指令流水线不局限于五级,可以拥有更少或更多级数。在每个时钟周期内,顺序指令流水线中可存在一条或多条指令,指令流水线中的每一级负责其中一条指令。当指令通过所有级时,指令完成执行。然而,有的指令在顺序指令流水线中需要超过一个周期才能通过执行指令(Execute)这一级(称之为多周期指令),这意味着在该指令会在执行指令(Execute)这一级停留超过一个周期,因此整个顺序指令流水线需要暂停,从而导致后续的其他指令也需要暂停在各自的级中,直到该指令完成,由此可知,当指令流水线频繁执行多周期指令时,指令流水线需要频繁的暂停,等待多周期指令完成,由此导致指令流水线的运行效率低下。
发明内容
有鉴于此,本发明提供一种指令处理方法、指令处理装置和芯片,能够解决现有技术中指令流水线在执行多周期指令使需要频繁暂停而导致的运行效率低下的问题。
为解决上述技术问题,本发明采用以下技术方案:
本发明一方面实施例提供了一种指令处理方法,包括:
在执行第一指令时,记录所述第一指令携带的目标运算单元标识值;
在执行第二指令时,比较所述第二指令启用的运算单元的运算单元标识值与所述目标运算单元标识值是否相同,其中,所述第二指令为在所述第一指令后执行的指令,所述第二指令在指令流水线中的执行阶段停留超过一个周期;
在所述第二指令启用的运算单元的运算单元标识值与所述目标运算单元标识值相同的情况下,将所述第二指令的操作数送至所述运算单元进行计算,记录所述第二指令的结果寄存器地址,并继续执行后续指令。
可选的,所述继续执行后续指令的步骤包括:
在执行写内存指令时,若所述写内存指令的源寄存器地址和所述第二指令的结果寄存器地址相同,则将所述写内存指令的写地址存入先进先出地址队列,同时清空记录的所述第二指令的结果寄存器地址。
可选的,所述将所述第二指令的操作数送至所述运算单元进行计算的步骤之后,还包括:
在所述运算单元完成计算后,将运算结果存入先进先出数据队列;
若所述先进先出地址队列和所述先进先出数据队列的出口均有有效值,则将所述先进先出数据队列的出口的值和所述先进先出地址队列的出口的值进行配对,并将配对的数据写入对应的地址中。
可选的,所述继续执行后续指令的步骤还包括:
执行第三指令;
若所述先进先出地址队列和所述先进先出数据队列未被清空,则利用所述第三指令暂停所述指令流水线,直至所述先进先出地址队列和所述先进先出数据队列被清空;
若所述先进先出地址队列和所述先进先出数据队列均已被清空,则利用所述第三指令清空记录的所述第一指令携带的目标运算单元标识值。
本发明另一方面实施例提供了一种指令处理装置,包括:
记录模块,用于在执行第一指令时,记录所述第一指令携带的目标运算单元标识值;
比较模块,用于在执行第二指令时,比较所述第二指令启用的运算单元的运算单元标识值与所述目标运算单元标识值是否相同,其中,所述第二指令为在所述第一指令后执行的指令,所述第二指令在指令流水线中的执行阶段停留超过一个周期;
处理模块,用于在所述第二指令启用的运算单元的运算单元标识值与所述目标运算单元标识值相同的情况下,将所述第二指令的操作数送至所述运算单元进行计算,记录所述第二指令的结果寄存器地址,并继续执行后续指令。
可选的,所述处理模块包括:
第一处理单元,用于在执行写内存指令时,若所述写内存指令的源寄存器地址和所述第二指令的结果寄存器地址相同,则将所述写内存指令的写地址存入先进先出地址队列,同时清空记录的所述第二指令的结果寄存器地址。
可选的,还包括:
存储模块,用于在所述运算单元完成计算后,将运算结果存入先进先出数据队列;
配对模块,用于若所述先进先出地址队列和所述先进先出数据队列的出口均有有效值,则将所述先进先出数据队列的出口的值和所述先进先出地址队列的出口的值进行配对,并将配对的数据写入对应的地址中。
可选的,还包括:
执行模块,用于执行第三指令;
第二暂停模块,用于若所述先进先出地址队列和所述先进先出数据队列未被清空,则利用所述第三指令暂停所述指令流水线,直至所述先进先出地址队列和所述先进先出数据队列被清空;
清空模块,用于若所述先进先出地址队列和所述先进先出数据队列均已被清空,则利用所述第三指令清空记录的所述第一指令携带的目标运算单元标识值。
本发明再一方面实施例还提供了一种芯片,所述芯片包括处理器和通信接口,所述通信接口和所述处理器耦合,所述处理器用于运行程序或指令,实现如上所述的指令处理方法。
本发明再一方面实施例还提供了一种可读存储介质,所述可读存储介质上存储程序或指令,所述程序或指令被处理器执行时实现如上所述的指令处理方法的步骤。
本发明上述技术方案的有益效果如下:
根据本发明实施例的指令处理方法,通过引入非阻塞的执行方式来处理多周期指令,从而极大的缩短了指令的执行时间,提高了指令流水线处理多周期指令的效率。
附图说明
图1为本发明实施例提供的指令流水线中的各指令的示意图;
图2为本发明实施例提供的指令在指令流水线中的执行情况的示意图;
图3为本发明实施例提供的一种指令处理方法;
图4为本发明实施例提供的指令流水线采用非阻塞的执行方式的示意图;
图5为本发明实施例提供的多个伪汇编指令的示意图;
图6为本发明实施例提供的指令流水线采用非阻塞式执行方式的示意图;
图7为本发明实施例提供的一种指令处理装置的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例的附图,对本发明实施例的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于所描述的本发明的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
请参考图1,为本发明实施例提供的指令流水线中的各指令的示意图。如图1所示,指令流水线可以执行各种不同的指令,例如整数减法SUB、按位与AND、浮点乘法FP.MUL、存储指令STORE、按位异或XOR等等。
请参考图2,为本发明实施例提供的指令在指令流水线中的执行情况的示意图。如图2所示,指令流水线将一条指令的执行过程分为若干个子过程(阶段),也称为级,每个子过程和其他子过程并行进行。通常,指令流水线可以分为五个阶段:取指令(Fetch);解析指令(Decode);执行指令(Execute);读写内存(Memory Access)以及结果写回寄存器(Write-back),当然,指令流水线不局限于五个阶段,可以拥有更少或更多阶段。图2中,在每个时钟周期内,指令流水线中可存在一条或多条指令,指令流水线中的每一级(阶段)负责其中一条指令。例如,在第一个时钟周期时,指令SUB进入指令流水线第一级(即取指令阶段);在第二个时钟周期,指令SUB进入指令流水线第二级(即解析指令阶段),同时新的指令AND进入指令流水线第一级;在第三个时钟周期,指令SUB进入指令流水线第三级,指令AND进入指令流水线第二级,新的指令XOR进入指令流水线第一级……以此类推,直到指令进入第五级并从指令流水线中退出。当指令通过所有级时,指令完成执行。
请继续参考图2,可以看到,大部分指令只需要一个时钟周期就可以通过指令流水线中的某一级(某一阶段),例如整数减法SUB、按位与AND等等,但是有些指令,例如复杂的算数指令,通常不能在一个时钟周期内完成,需要在第三级(执行阶段)停留多个周期才能完成,如图2中的指令FP.MUL,其对应启用的运算单元需要4个时钟周期才能完成计算,因此指令FP.MUL需要4个周期才能通过第三级(即执行阶段)。
由于在指令流水线中,指令的执行顺序与编译器产生的汇编指令顺序一致,当指令流水线中的某条指令暂停在某一级时,整个指令流水线也需要暂停,直到该指令恢复运行。例如,算数指令通常在第三级(Execute,执行阶段)送入运算单元(Function Unit)进行计算;若运算单元需要若干个周期才能完成计算,则指令流水线必须暂停若干个时钟周期(见图2),此时流水线不能接收新的指令且每一级中的指令也被暂停在各自的级中,直到运算单元完成计算,指令流水线才能恢复运行,运算单元和指令流水线串行执行,指令流水线通常采用这种阻塞式的执行方式来处理多周期指令。因此,当指令流水线频繁执行多周期指令时,指令流水线需要频繁的暂停,等待多周期指令完成,这无疑导致了指令流水线的运行效率低下。
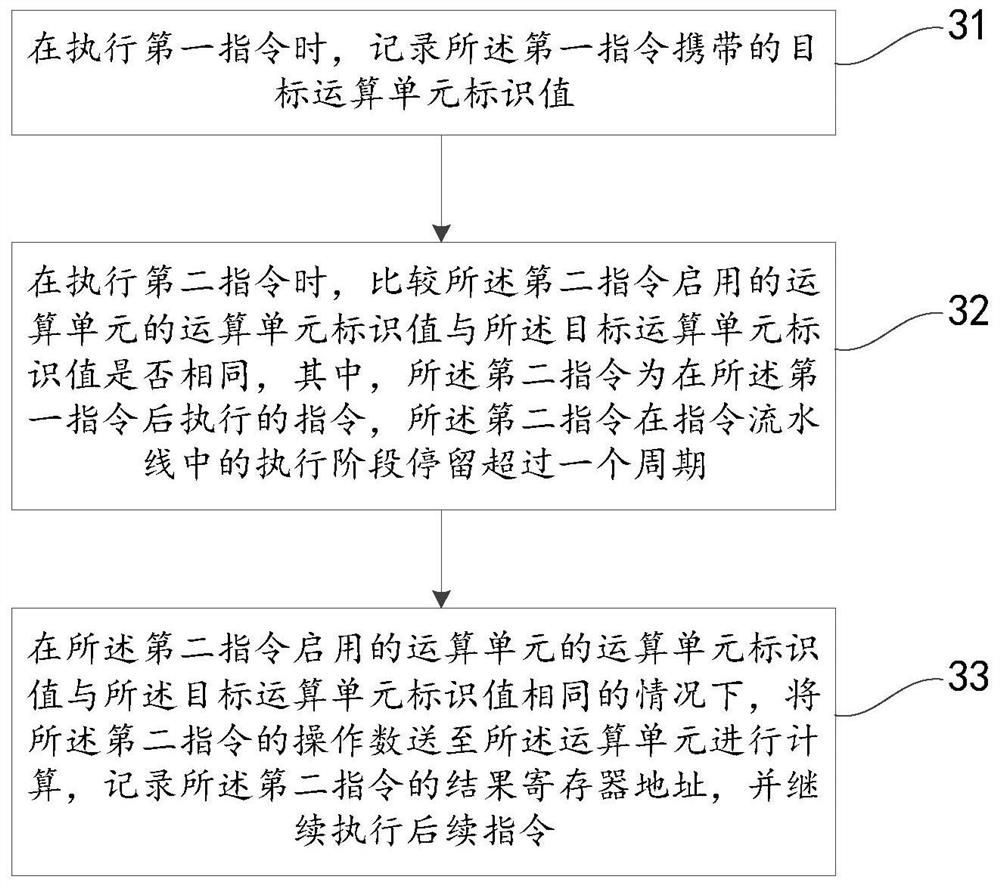
由此,请参考图3,为本发明实施例提供的一种指令处理方法。如图3所示,本发明实施例中的指令处理方法可以包括:
步骤31:在执行第一指令时,记录所述第一指令携带的目标运算单元标识值。
本步骤中,第一指令进入指令流水线,则指令流水线将获取并记录第一指令中携带的目标运算单元标识值;由于每种多周期运算单元都有固定的运算单元标识值,即fncid值,例如整数乘法的fnc id为1,整数除法的fnc id为2,因此,利用第一指令携带目标运算单元标识值,通过所述目标运算单元标识值使得指令流水线在处理后续指令时,只要后续指令启用的运算单元的运算单元标识值与目标运算单元标识值相同,即可使指令流水线采用非阻塞的执行方法来处理该指令,以提高指令流水线的运行效率。
步骤32:在执行第二指令时,比较所述第二指令启用的运算单元的运算单元标识值与所述目标运算单元标识值是否相同,其中,所述第二指令为在所述第一指令后执行的指令,所述第二指令在指令流水线中的执行阶段停留超过一个周期。
本发明实施例中,第二指令进入指令流水线后,例如为算数指令时,通常会在第三级(Execute,执行阶段)送入运算单元(Function Unit)进行计算,则可以将第二指令启用的运算单元的运算单元标识值与步骤31中记录的目标运算单元标识值进行比较,以判断第二指令是否需要采用非阻塞的执行方式;其中,第二指令是在第一指令后进入同一指令流水线的指令,并且,第二指令在指令流水线中的执行阶段停留超过一个周期;当然,可以知道的是,在第一指令后进入指令流水线中的指令若在执行阶段停留不超过一个周期,也就不会导致指令流水线暂停,因而也就不会导致指令流水线阻塞,因此,指令流水线只需要按照正常流程逐一阶段处理这类指令即可。
步骤33:在所述第二指令启用的运算单元的运算单元标识值与所述目标运算单元标识值相同的情况下,将所述第二指令的操作数送至所述运算单元进行计算,记录所述第二指令的结果寄存器地址,并继续执行后续指令。
本步骤中,在第二指令启用的运算单元的运算单元标识值与指令流水线记录的目标运算单元标识值相同的情况下,即确定该第二指令需要采用非阻塞式的执行方式;具体的,将第二指令的操作数送至对应的运算单元中进行计算,由上述内容可知,第二指令启用的运算单元将需要超过一个时钟周期的时间完成计算,同时,指令流水线也将记录第二指令的结果寄存器地址,该结果寄存器地址用于存储第二指令的计算结果,此时,指令流水线继续执行后续指令,也就是说,第二指令在执行阶段将操作数送至对应的运算单元后,无需继续停留在指令流水线的执行阶段,而是直接进入到下一阶段,即指令流水线中的各阶段中的指令将顺次进入下一阶段,由此,指令流水线可以不用暂停,将继续取下一条指令进行处理,此时,运算单元和指令流水线为并行执行,从而有效提高指令流水线的效率。
请参考图4,图4为本发明实施例提供的指令流水线采用非阻塞的执行方式的示意图。如图4所示,SUB指令、AND指令等,由于这些指令启用的运算单元的运算单元标识值与指令流水线记录的目标运算单元标识值不相同,因此这些指令不需要采用非阻塞式的执行方式;而FP.MUL指令启用的运算单元的运算单元标识值与指令流水线记录的目标运算单元标识值相同,即需要采用非阻塞式的执行方式,此时,FP.MUL指令无需继续停留在指令流水线的执行阶段,而是将操作数送至对应的运算单元后,直接进入到下一阶段,即指令流水线中的各阶段中的指令将顺次进入下一阶段。
本发明实施例中,所述指令处理方法还可以包括:
在所述第二指令启用的运算单元的运算单元标识值与所述目标运算单元标识值不相同的情况下,暂停所述指令流水线,直至所述运算单元完成计算。
也就是说,若第二指令启用的运算单元的运算单元标识值与指令流水线记录的第一指令的目标运算单元标识值不相同,则指令流水线依旧是采用阻塞式的执行方式来执行第二指令,也就是说,需要暂停指令流水线,直到所述运算单元完成计算,才能使第二指令继续进入下一阶段,后续指令才能继续执行。实际上,第一指令的作用相当于用来规定哪种多周期运算单元需要采用非阻塞式的执行方式,指令流水线在处理启用规定的多周期运算单元的指令时需要采用非阻塞式的执行方式,至于指令流水线在处理启用的多周期运算单元的标识值与目标运算单元标识值不相同的指令时,由于会造成阻塞,因此需要暂停流水线,直到所述运算单元完成计算。
本发明实施例中,所述继续执行后续指令的步骤包括:
在执行写内存指令时,若所述写内存指令的源寄存器地址和所述第二指令的结果寄存器地址相同,则将所述写内存指令的写地址存入先进先出地址队列,同时清空记录的所述第二指令的结果寄存器地址。
其中,写内存指令在第二指令后进入执行阶段,若写内存指令的源寄存器地址和上述的第二指令的结果寄存器地址相同,则表示写内存指令需要将第二指令产生的结果写入内存中,此时,可以将写内存指令的写地址存入一个先进先出地址队列中,该先进先出地址队列专门用于存放地址,由于写内存指令的源寄存器地址和第二指令的结果寄存器地址相同,因此也可以同时清除掉记录的第二指令的结果寄存器地址。通常来说,第二指令是算数指令时,后续会有与之对应的写内存指令,用于存储计算结果。
本发明实施例中,所述将所述第二指令的操作数送至所述运算单元进行计算的步骤之后,还包括:
在所述运算单元完成计算后,将运算结果存入先进先出数据队列;
若所述先进先出地址队列和所述先进先出数据队列的出口均有有效值,则将所述先进先出数据队列的出口的值和所述先进先出地址队列的出口的值进行配对,并将配对的数据写入对应的地址中。
具体来说,第二指令将操作数送至运算单元后,运算单元在经超过一个时钟周期之后完成计算,然后将运算结果存入到一个先进先出数据队列中,该先进先出数据队列专门用于存放数据,则当先进先出地址队列和先进先出数据队列的出口均有有效值,将先进先出数据队列的出口的值和先进先出地址队列的出口的值进行配对,并将配对的数据写入对应的地址中。其中,先进先出地址队列和先进先出数据队列均为先进先出的特性,而第二指令和后续的写内存指令一一配对,因此可以实现数据和地址的正确配对,可以知道的是,第二指令和写内存指令不一定是连续的两个指令,在第二指令和对应的写内存指令之间还可以插入其他指令,但是第二指令需要和对应的写内存指令成对,先后进入指令流水线中。
本发明实施例中,所述继续执行后续指令的步骤还包括:
执行第三指令;
若所述先进先出地址队列和所述先进先出数据队列未被清空,则利用所述第三指令暂停所述指令流水线,直至所述先进先出地址队列和所述先进先出数据队列被清空;
若所述先进先出地址队列和所述先进先出数据队列均已被清空,则利用所述第三指令清空记录的所述第一指令携带的目标运算单元标识值。
在流水线继续执行后续指令的步骤中,在执行第三指令时,若所述先进先出地址队列和所述先进先出数据队列未被清空,则意味着前面成对的指令中的计算结果和写地址还没有全部配对写入寄存器中,因此第三指令将会暂停指令流水线,直至所述先进先出地址队列和所述先进先出数据队列被清空;而若所述先进先出地址队列和所述先进先出数据队列均已被清空,则表明计算结果已与对应的写地址完成配对并已写入寄存器中,所有的需要采用非阻塞操作均已完成,则指令流水线正常继续执行后续指令,同时第三指令将清空记录的目标运算单元标识值,也就表明后续指令流水线在执行指令的过程中,将不再采用上述非阻塞式的执行方式。
可以知道,第一指令用于使指令流水线在处理后续启用的运算单元的运算单元标识值与第一指令中携带的目标运算单元标识值相同的指令时,采用上述非阻塞式的执行方式,而第三指令则用于使指令流水线在处理后续指令时不再采用上述非阻塞式的执行方式,也就是说,在第一指令和第三指令之间进入指令流水线的所有指令(包括多周期的第二指令和其他非多周期的指令)中,只要其启用的运算单元的运算单元标识值与第一指令中携带的目标运算单元标识值相同,就采用上述的非阻塞式的执行方式,以提高指令流水线的效率,而若启用的运算单元的运算单元标识值与第一指令中携带的目标运算单元标识值不相同,则不采用上述非阻塞式的执行方式,即采用正常的处理方式;需要特别指出的是,在第一指令和第三指令之间进入指令流水线的所有指令中,指令流水线在处理启用单周期运算单元的指令时不会造成阻塞,即执行阶段停留不会超过一个周期,因此也无需采用非阻塞式的执行方式,而可以按照前述常规的指令处理流程执行。若要使指令流水线在后续执行复杂的运算指令时再次采用非阻塞式的执行方式,则重新设置第一指令的目标运算单元标识值并使指令流水线再次记录第一指令中携带的目标运算单元标识值即可。
本发明实施例中,第一指令和第三指令之间可以有多个采用非阻塞式的执行方式进行执行的第二指令,每一个第二指令将有一个与之对应的写地址指令,从而有多个数据存入到先进先出数据队列,并且有多个写地址存入到先进先出地址队列中,后续进行配对即可。
本发明实施例中,通过引入非阻塞的执行方式来处理多周期指令,从而极大的缩短了指令的执行时间,提高了指令流水线处理多周期指令的效率。
下面进一步举例说明本发明实施例中的指令处理方法。
请参考图5和图6,图5为本发明实施例提供的多个伪汇编指令的示意图,图6为本发明实施例提供的指令流水线采用非阻塞式执行方式的示意图。如图5、图6所示,引入自定义指令NONBLK,该指令携带一个目标运算单元标识值,即nonblk fnc id值,目标运算单元标识值规定了哪种多周期运算单元需要进行非阻塞操作,例如指令NONBLK.FP.MUL,携带的nonblk fnc id值为1,表示浮点乘法FP.MUL需要采取非阻塞的执行方式。
下面介绍各伪汇编指令在指令流水线的具体执行过程:
①当指令流水线执行NONBLK.FP.MUL指令时,记录下其携带的目标运算单元标识值,即nonblk fnc id值,即规定了FP.MUL启用的多周期运算单元需要进行非阻塞操作;
②当指令流水线执行多周期指令FP.MUL时,比较指令FP.MUL的运算单元的fnc id值和之前记录的目标运算单元标识值,若一致,则表示指令FP.MUL需采取非阻塞的执行方式,即指令流水线不暂停,继续执行下一条指令,并将指令FP.MUL的操作数送入运算单元,运算单元和指令流水线并行执行,并且指令流水线记录指令FP.MUL的结果寄存器地址nonblk dst;
③当指令流水线执行写内存指令STORE时,若该指令的源寄存器地址和之前记录的结果寄存器地址nonblk dst相同,则表示写内存指令STORE需要将指令FP.MUL产生的结果写入内存,此时,将写内存指令STORE的写地址存入先进先出地址队列FIFO B中,同时清空上述步骤中记录的结果寄存器地址nonblk dst;
④当运算单元完成计算时,将运算结果写入先进先出数据队列FIFO A中;
⑤若FIFO B和FIFO A的出口都有有效值,则将FIFO A出口的值和FIFO B出口的值配对,写入内存(其中,FIFO A的值为数据,FIFO B的值为写地址),此时指令FP.MUL和写内存指令STORE就执行完成了;
⑥引入自定义指令NONBLK.WAIT指令,该指令依实际情况暂停指令流水线,即:若FIFO A和FIFO B均已被清空,则指令流水线不暂停;若FIFO A和FIFO B未清空,则NONBLK.WAIT指令会暂停指令流水线,直到FIFO A和FIFO B清空;当若两个FIFO都为空则表示所有非阻塞操作均已完成,指令流水线恢复执行;同时,NONBLK.WAIT指令会清空第一步骤中记录的目标运算单元标识值,即nonblk fnc id值。
若需要再次启动非阻塞操作,则需要重新执行NONBLK指令,NONBLK指令中携带的nonblk fnc id值可以重新设置。
本发明实施例中,通过引入非阻塞的执行方式来处理多周期指令,从而极大的缩短了指令的执行时间,提高了指令流水线处理多周期指令的效率。
请参考图7,为本发明实施例提供的一种指令处理装置的结构示意图。如图7所示,本发明另一方面实施例还提供了一种指令处理装置,所述指令处理装置70可以包括:
记录模块71,用于在执行第一指令时,记录所述第一指令携带的目标运算单元标识值;
比较模块72,用于在执行第二指令时,比较所述第二指令启用的运算单元的运算单元标识值与所述目标运算单元标识值是否相同,其中,所述第二指令为在所述第一指令后执行的指令,所述第二指令在指令流水线中的执行阶段停留超过一个周期;
处理模块73,用于在所述第二指令启用的运算单元的运算单元标识值与所述目标运算单元标识值相同的情况下,将所述第二指令的操作数送至所述运算单元进行计算,记录所述第二指令的结果寄存器地址,并继续执行后续指令。
本发明实施例中的指令处理装置为与上述实施例中指令处理方法相对应的装置,能够实现上述指令处理方法中的各个步骤,且能够达到相同的技术效果,为避免重复,在此不再赘述。
可选的,还包括:
第一暂停模块,用于在所述第二指令启用的运算单元的运算单元标识值与所述目标运算单元标识值不相同的情况下,暂停所述指令流水线,直至所述运算单元完成计算。
可选的,所述处理模块73包括:
第一处理单元,用于在执行写内存指令时,若所述写内存指令的源寄存器地址和所述第二指令的结果寄存器地址相同,则将所述写内存指令的写地址存入先进先出地址队列,同时清空记录的所述第二指令的结果寄存器地址。
可选的,还包括:
存储模块,用于在所述运算单元完成计算后,将运算结果存入先进先出数据队列;
配对模块,用于若所述先进先出地址队列和所述先进先出数据队列的出口均有有效值,则将所述先进先出数据队列的出口的值和所述先进先出地址队列的出口的值进行配对,并将配对的数据写入对应的地址中。
可选的,还包括:
执行模块,用于执行第三指令;
第二暂停模块,用于若所述先进先出地址队列和所述先进先出数据队列未被清空,则利用所述第三指令暂停所述指令流水线,直至所述先进先出地址队列和所述先进先出数据队列被清空;
清空模块,用于若所述先进先出地址队列和所述先进先出数据队列均已被清空,则利用所述第三指令清空记录的所述第一指令携带的目标运算单元标识值。
本发明实施例中,通过引入非阻塞的执行方式来处理多周期指令,从而极大的缩短了指令的执行时间,提高了指令流水线处理多周期指令的效率。
本发明再一方面实施例还提供了一种芯片,所述芯片包括处理器和通信接口,所述通信接口和所述处理器耦合,所述处理器用于运行程序或指令,实现如上实施例中所述的指令处理方法,且能够达到相同的技术效果,为避免重复,在此不再赘述。
本发明又一方面实施例还提供了一种可读存储介质,所述可读存储介质上存储程序或指令,所述程序或指令被处理器执行时实现如上所述的指令处理方法的步骤,且能够达到相同的技术效果,为避免重复,在此不再赘述。
以上所述是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种指令处理方法、指令处理装置和芯片
- 指令处理方法、指令处理系统及处理器、芯片