一种电磁直驱式AMT变速器无传感器位置检测方法
文献发布时间:2023-06-19 12:25:57
技术领域
本发明涉及AMT变速器控制技术,尤其涉及一种电磁直驱式AMT变速器无传感器位置检测方法。
背景技术
随着工业的不断发展,环境与能源问题日益凸显,车辆在提升性能的同时需要实现绿色环保,由于电动汽车对环境友好且具有优良的动力性能,目前已经得到了广泛应用,逐渐成为汽车技术研究的热点。变速系统对提高电动汽车动力性、延长电动汽车续驶里程、优化电动汽车驱动系统总成性能等都具有重要作用,因此变速器技术在电动汽车动力传动技术的发展中占据着核心地位。AMT变速器结构简单,且集合AT和MT变速器两者的优点于一体,因此得到了广泛的应用。
直驱技术是将执行器与负载直接相连,取消动力传递装置,直接驱动机械部件完成工作;可以有效提高系统的传递效率和结构紧凑性,使系统获得更快的响应速度与更高的控制精度;换挡过程中需要位移传感器获取动子的位移值作为换挡控制策略的反馈信号;高精度位移传感器提高控制精度的同时,也导致成本升高,结构紧凑型变差;动圈式电磁直线驱动装置运动过程具有速度变化大,位移呈现强非线性的特点,人工神经网络不依赖于精确数学模型,对外界变化具有较好的响应,可以实现非线性控制;但传统方法由于未实现全速预测,需要对算法进行加权结合,导致算法难以快速设计,计算时间长,导致换挡平顺性低,顿挫感明显;因此出现了利用RBF神经网络算法等方法进行动子位移预测的无传感器位置检测方法,但RBF神经网络算法对聚类初始条件敏感,初始中心选择不恰当会使聚类效果很差;且宽度求取过程未考虑数据样本的分布,应用中易出现不稳定性。
发明内容
发明目的:本发明的目的是提供一种准确高效的电磁直驱式AMT变速器无传感器位置检测方法。
技术方案:本发明基于电磁直驱式AMT变速器的动子位移模型建立神经网络估算用于控制驱动电机的动子位移,包括如下步骤:
(1)对动子位移模型的输出受输入影响的程度以及模型本身受输入的影响程度进行灵敏度分析,确定神经网络预测的信号输入维数;
(2)根据步骤(1)中确定的信号输入维数采集用于训练神经网络的样本数据;
(3)建立用于估算动子位移的RBF神经网络并对其进行优化;
(4)训练步骤(3)中建立的神经网络,并使用准确性评价指标对训练结果进行准确性评价;
(5)利用步骤(4)中训练的神经网络估算动子位移,用于控制驱动电机。
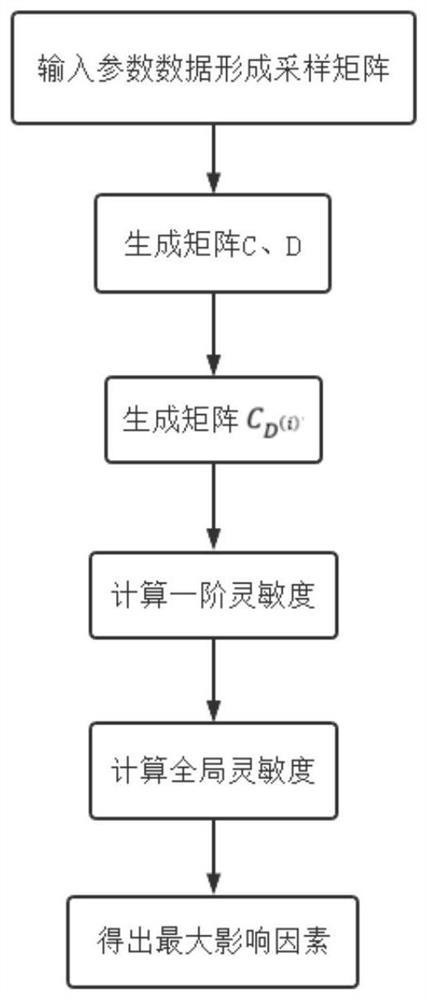
步骤(1)中采用Sobol法进行非线性灵敏度分析,包括如下步骤:
(1.1)设定模型中需要分析的参数数量为n,给定一个n维空间I
上式中f
其中p
(1.2)对f(x)进行方差分解:
f(x)的总方差以下式表达:
f(x)的各阶偏方差以下式表达:
根据总方差和各阶偏方差的关系,将总方差D表示为D=∑D
(1.3)求解各阶灵敏度,衡量单个参数对模型的影响,
各参数灵敏度之和满足
(1.4)求解全局灵敏度,衡量参数的耦合对模型的影响;
利用蒙特卡洛法进行数值积分估计输出结果的方差,
式中
x
步骤(2)中的样本数据通过实验采集,在确定输入信号维数后,搭建实验台架来获取样本数据,所述实验台架由动力装置、传动装置、负载惯量模拟装置、控制系统和传感器装置组成;具体步骤如下:
(2.1)启动电机,将电机调整至预定转速,
(2.2)负载惯量模拟装置启动模拟车辆行驶情况,
(2.3)达到预定负载后,进行模拟换挡操作;
(2.4)电机停车模拟换挡动力中断,换挡控制器控制电流输出,以不同换挡力执行换挡操作,通过传感器采集位移信号,在换挡同步阶段采集输入轴转速;
(2.5)换挡过程结束后,重复试验,将采集到的数据形成数据集;并将其作为位置预测模型的训练集与测试集。
步骤(3)包括以下步骤:
(3.1)采用MKM++算法求取神经网络的隐含层节点的k个聚类中心及其数据密度;
(3.2)根据数据密度适配相应的缩放因子,使聚类中心的宽度符合数据的空间分布;
(3.3)使用最小二分法基于中心centref
步骤(3)中的RBF神经网络包括输入层、隐含层和输出层,其中隐含层节点的神经元激励函数如下所示:
式中,
步骤(3)中RBF神经网络的数学模型函数如下所示:
其中y
步骤(3.1)中在K-means++算法中引入MMOD算法用密度最大的样本代替 K-means++算法中的随机选择样本,MMOD算法采用样本点的数据密度估算算法,区分正常数据点、离群数据点的密度,如下式:
式中k表示近临点数量,d(p,x
步骤(3.2)包括如下步骤:
(3.21)计算聚类中心之间的平均距离:
其中μ
(3.22)计算聚类的类内方差:
式中centref
(3.23)计算中心宽度的缩放因子:
(3.24)按下式计算聚类中心的宽度:
σ
步骤(4)中准确性评价指标包括精确度、最大绝对误差E
有益效果:与现有技术相比,本发明具有如下显著优点:使用无传感器控制技术,应用人工神经网络对电磁直驱装置进行反馈控制,提高到动子位移预测的精确性,提升了驱动装置的结构紧凑性和系统鲁棒性,降低了电磁直线驱动装置的结构复杂度和使用成本;使用灵敏度分析方法获取对位移影响最大的输入参数,同时使用改进型神经网络检测方法提高算法的逼近效果和泛化能力以提升算法的速度与准确性使得无传感位置检测方法更加稳定。使用改进型RBF算法,重新确定合适的网络初始中心;考虑数据分布和缩放因子的自适应选择,采用方差度量优化法求取隐含层神经元基函数的宽度,使得RBF网络具有较好的非线性逼近能力和收敛速度;同时针对目前无传感器检测方法中输入参数随意选取的不足,使用灵敏度分析模型,获得了对位移影响最大的参数,使得位置预测更加准确高效。
附图说明
图1为本发明的流程图;
图2为输入参数的确定流程图;
图3为本发明的位移检测原理图;
图4为本发明建立的神经网络结构图。
具体实施方式
下面结合附图对本发明的技术方案作进一步说明。
本发明电磁直驱式AMT变速器无传感器位置检测方法的工作原理如图1所示,通过以激励电流、电压和变速器输入轴转速输入训练好的人工神经网络来预测动子线圈的位移,用于换挡控制;其流程如图1所示,包括如下步骤:
(1)使用灵敏度分析模型的输出受输入影响的程度以及模型本身受输入的影响程度,确定神经网络预测的信号输入维数并进行实时调整;
(2)根据步骤(1)中确定的信号输入维数采集用于训练神经网络的样本数据;
(3)建立用于估算动子位移的RBF神经网络并对其进行优化;
(4)训练步骤(3)中建立的神经网络,并使用准确性评价指标对训练结果进行准确性评价;
(5)利用步骤(4)中训练的神经网络估算动子位移,用于控制驱动电机。
输入信号维数的灵敏度反映了参数变化对数学模型响应的影响程度,灵敏度较大的参数对模型拥有更强的调整能力,可视为主导参数用于直接反映模型的变化情况。因此在选取参数时,时刻考虑实际因素的影响。使用灵敏度分析模型的输出受输入影响的程度以及模型本身受输入的影响程度,这样在选取输入维数时根据灵敏度分析可以进行实时调整。作为优选,选择全局灵敏度中的Sobol法进行非线性分析,参数的各阶灵敏度均可以使用各阶偏方差与总方差的比值得到。
灵敏度的分析包括如下步骤:
(1)使用灵敏度分析模型的输出受输入影响的程度以及模型本身受输入的影响程度,确定神经网络预测的信号输入维数;
电磁直驱装置的动子位移的数学模型为:
式中k
(1.1)设定模型中需要分析的参数数量为n,给定一个n维空间I
上式中f
其中(p
(1.2)对f(x)进行方差分解:
f(x)的总方差以下式表达:
f(x)的各阶偏方差以下式表达:
根据总方差和各阶偏方差的关系,将总方差D表示为D=∑D
(1.3)求解各阶灵敏度,衡量单个参数对模型的影响,
各参数灵敏度之和满足
(1.4)求解全局灵敏度,衡量参数的耦合对模型的影响;
利用蒙特卡洛法进行数值积分估计输出结果的方差,
式中上标(1)与(2)表示
对于动子位移数学模型而言,灵敏度计算过程中的n=5,经过灵敏度计算后,最终得出位移影响最大的变量为电流和电压,因此选择电磁直驱装置的电流和电压作为关于人工神经网络的输入信息,考虑到在无位移同步阶段驱动装置仍通电产生电流与电压,在采集数据代入模型计算后会出现误差,因此将速度信号作为特殊的反馈值,且换档前后,输入轴的转速会发生变化,因此变速器输入轴的速度也被作为输入信号,以提高网络预测结果的准确性。最终所述输入信号包括电磁直驱装置的激励电流、电压和输入轴的转速,本发明的动子位移预测流程原理如图3所示。
(2)在确定输入信号维数后,搭建实验台架来获取样本数据,所述实验台架由动力装置、传动装置、负载惯量模拟装置、控制系统和传感器装置组成;具体步骤如下:
(2.1)启动电机,将电机调整至预定转速,
(2.2)负载惯量模拟装置启动模拟车辆行驶情况,
(2.3)达到预定负载后,进行模拟换挡操作;
(2.4)电机停车模拟换挡动力中断,换挡控制器控制电流输出,以不同换挡力执行换挡操作,通过传感器采集位移信号,在换挡同步阶段采集输入轴转速;
(2.5)换挡过程结束后,重复试验,将采集到的数据形成数据集;并将其作为位置预测模型的训练集与测试集。
(3)建立用于估算动子位移的RBF神经网络并对其进行优化;
如图4所示,本发明的RBF神经网络包括输入层、隐含层和输出层,其中隐含层节点的神经元激励函数如下所示:
式中,
RBF神经网络的数学模型函数如下所示:
其中y
RBF神经网络聚类效果受初始中心选择和宽度影响导致不稳定进而导致泛化性能、非线性逼近能力和收敛速度低下,因此需对其进行优化,对RBF神经网络的优化包括以下步骤:
(3.1)采用MKM++算法求取神经网络的隐含层节点的k个聚类中心;
MKM++算法是指引入MMOD算法的改进型K-means算法,MMOD算法是基于密度差异的离群点检测方法。通过在K-means++算法中引入MMOD算法用密度最大的样本代替K-means++算法中的随机选择样本,MMOD算法采用样本点的数据密度估算算法,区分正常数据点的密度如下式:
式中k表示近临点数量,d(p,x
(3.2)根据数据密度适配相应的缩放因子,使聚类中心μ={μ
(3.21)计算聚类中心之间的平均距离;聚类中心之间的平均距离按下式计算:
(3.22)计算每个聚类的类内方差S
式中centref
(3.23)计算聚类中心的缩放因子ε
所述中心宽度按下式计算:
σ
(3.3)使用最小二分法基于中心centref
(4)训练步骤(3)中建立的神经网络,并使用准确性评价指标对训练结果进行准确性评价;
为验证算法的鲁棒性,对训练结果需要进行准确性评价,基于实际值与预测值之间的误差;选择精确度、最大绝对误差E
精确度表征数据整体的预测准确程度,
描述预测误差的离散程度的均方根误差RMSE,即网络的误差性能函数,其值与预测数据量级相关,
MAPE是从均值角度描述误差与真实值之间的比例的平均绝对百分比误差,能够更加准确描述误差的偏离程度,该指标越小预测效果越好,其表达式如下:
各准确性评价指标的阈值根据实际需求设定,当训练结果的准确性达到阈值后停止训练。
(5)利用步骤(4)中训练的神经网络估算动子位移,用于控制驱动电机。