一种基于深度学习的视频头发颜色转换方法
文献发布时间:2023-06-19 13:29:16
技术领域
本发明属于计算机视觉领域,尤其涉及一种基于深度学习的视频头发颜色转换方法。
背景技术
头发是肖像描绘中最重要的组成部分之一,这也引发了计算机视觉领域大量优秀的工作,然而现有的工作都只停留在静态头发上,对于视频序列的相关工作仍然不足,此外,与人脸的大部分部位不同,头发非常精致、多变和复杂。它由数以千计的细线组成,并受到光照、运动和遮挡的影响,因此难以分析、表示和生成。现有的研究都利用gabor filter提取发丝的生长方向作为头发的几何并与颜色解耦,然而这种做法的一个常见缺点是:gabor filter会损失许多细节信息,导致生成的视频序列不保真且容易抖动。
发明内容
本发明针对现有技术的不足,提出了一种基于深度学习的视频头发颜色转换方法,利用标准化后的luminance map表示头发的几何结构,针对头发各个属性设计了三个条件模块,将头发属性高度解耦并重组达到头发颜色转换的效果,整个训练流程无需任何成对数据。提出了循环一致性损失(cycle consistency loss)并使用判别器(discriminator)去除生成过程中可能造成的抖动,并增强了生成结果与参考图像的一致性。
本发明是通过以下技术方案来实现的:
一种基于深度学习的视频头发颜色转换方法,包括以下步骤:
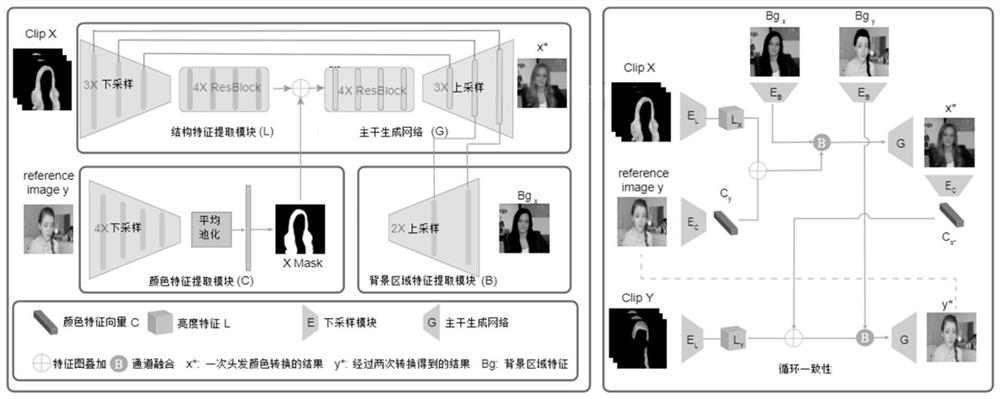
步骤一:将包含待转换头发颜色的目标图像的视频中每一帧从RGB空间转换为LAB空间,提取L空间并在时间和空间上做标准化,并利用结构特征提取模块获取目标图像包含头发结构和光照的特征图。
其中,L空间(luminance map)代表亮度,亮度的强弱即可表达发丝的结构并保留原有的光照,最重要的一点是Luminance map能保留所有微小的细节,以重建出更真实的图像。由于亮度也关系到颜色的深浅,为了弥补不同图像不同光照条件带来的影响,本发明提出在时间和空间上对luminance map进行标准化并用标准化后的结果来表示头发的几何结构,这样既能保证发丝的结构又能保证原有的光照条件,生成更真实的结果。
步骤二:选取带有预转换头发颜色的参考图像并利用颜色特征提取模块提取参考图像的头发颜色特征,并将头发颜色特征叠加至目标图像的头发掩模上获得头发颜色掩模;
步骤三:根据目标图像头发掩模利用背景区域特征提取模块提取目标图像除头发以外的背景区域特征图;
步骤四:将步骤一提取到的目标图像包含头发结构和光照的特征图、步骤二中提取到的头发颜色掩模及步骤三提取到的背景区域特征图输入至一个主干生成网络整合生成具有参考图像头发颜色的目标图像。
其中,所述结构特征提取模块、颜色特征提取模块、背景区域特征提取模块、主干生成网络通过收集的视频训练获得。
进一步地,所述步骤1中,将包含待转换头发颜色的目标图像的视频中每一帧从RGB空间转换为LAB空间,提取L空间并在时间和空间上做标准化,具体为:
(1.1)将包含待转换头发颜色的目标图像的视频中每一帧图像从CIE RGB转化到CIE XYZ颜色空间再从CIE XYZ转换到LAB颜色空间。
(1.2)提取L空间并计算一整个视频序列所有像素点的L值的均值及方差,利用公式L
进一步地,所述步骤(1.2)中,计算一整个视频序列中头发区域对应像素点的L值的均值及方差。
进一步地,所述颜色特征提取模块包括4层下采样的部分卷积网络(partialconvolution)和一个实例级平均池化层(instance-wise average pooling)。
通过使用partial convolution基于mask提取特征这一优势来提取参考图像头发区域的特征,避免头发区域以外的特征干扰,并使用实例级平均池化层将特征压缩为一个特征向量,得到参考图像的全局颜色特征。
进一步地,所述结构特征提取模块包括依次连接的多个上采样模块和残差块,所述主干生成网络包括依次连接的多个残差块和下采样模块,结构特征提取模块与主干生成网络呈对称结构,。所述步骤四中,将步骤一提取到的目标图像包含头发结构和光照的特征图、步骤二中提取到的头发颜色掩模在特征通道上连接后输入主干生成网络的多个残差块提取特征后,输入至上采样模块,上采样模块与结构特征提取模块的下采样模块通过跳跃连接获得多尺度特征,并且在最后n个下采样模块中结合步骤三提取到的背景区域特征图最终获得具有参考图像头发颜色的目标图像,n为背景区域特征图的数量。
进一步地,当包含连续的多帧待转换头发颜色的目标图像时,将当前待转换头发颜色的目标图像的前k帧目标图像转换结果反馈至结构特征提取模块与当前待转换头发颜色的目标图像作为共同输入以保证生成视频序列的时间相干性。
进一步地,所述训练采用的损失函数包括:生成的具有参考图像头发颜色的目标图像与真值的L1损失和感知损失、网络的生成对抗损失、生成的具有参考图像头发颜色的目标图像与真值的特征匹配损失、时间相干性损失和循环一致性损失,表示为:
其中,
进一步地,所述循环一致性损失训练具体为对于两个视频序列X和Y,首先以视频序列Y作为参考图像,使用本发明方法上述步骤将视频序列X的头发颜色转换生成视频序列X*,再以视频序列X*作为参考图像,视频序列Y作为待转换头发颜色的视频序列,重复上述步骤生成新的视频序列Y*,损失函数如下:
其中,I是目标图像,I
循环一致性损失进一步保证了生成结果的颜色与参考图像的一致性。
本发明的突出贡献是:
本发明提出了iHairRecolorer,第一个基于深度学习将参考图像的头发颜色转换到视频中的方法,第一次提出使用LAB空间中的L空间替代传统的orientation map作为头发的结构并对其进行了时间和空间上的标准化,使luminance map不仅能保留细微的结构特征及原有光照条件还能与头发的色彩高度结构。此外采用了一种新颖的循环一致性损失来更好地匹配生成结果和参考图像之间的颜色。该发明不依赖任何成对数据即可训练并能在测试数据上依然鲁棒稳定。该发明还引入了discriminator以保证生成视频序列的时间一致性,得到更真实更平滑的结果,优于目前已有的所有方法。
附图说明
图1是本发明的网络管线结构图;
图2是本发明的头发颜色转换结果图。
具体实施方式
由于头发非常精致、多变和复杂。它由数以千计的细线组成,并受到光照、运动和遮挡的影响,因此难以分析、表示和生成。本发明的目标是得到头发结构高度还原原始视频且发色与参考图像保持一致的新的视频序列。这需要结构与颜色高度解耦,一般来说采用gabor filter计算。本发明针对上述问题,提出使用luminance map表示头发的结构并对齐进行时间和空间上的标准化。并利用partial convolution等三个精心设计的条件模块及所提出的损失函数完成视频头发颜色转换模型的训练。具体包括如下步骤:
步骤一:将包含待转换头发颜色的目标图像的视频中每一帧从RGB空间转换为LAB空间,提取L空间并在时间和空间上做标准化,并利用结构特征提取模块获取目标图像包含头发结构和光照的特征图。
步骤二:选取带有预转换头发颜色的参考图像并利用颜色特征提取模块提取参考图像的头发颜色特征,并将头发颜色特征叠加至目标图像的头发掩模上获得头发颜色掩模;
步骤三:根据目标图像头发掩模利用背景区域特征提取模块提取目标图像除头发以外的背景区域特征图;
步骤四:将步骤一提取到的目标图像包含头发结构和光照的特征图、步骤二中提取到的头发颜色掩模及步骤三提取到的背景区域特征图输入至一个主干生成网络整合生成具有参考图像头发颜色的目标图像。
其中,所述结构特征提取模块、颜色特征提取模块、背景区域特征提取模块、主干生成网络通过收集的视频训练获得。
图1说明了本发明中网络的结构及数据流通方向。下面,结合一个具体的实施例对本发明方法作进一步说明:
对于一个给定T帧的视频序列I(T)={I
其中结构特征的提取使用了LAB空间独有的亮度与颜色的高度解耦性,并且将L空间使用如下公式进行标准化:
其中M表示目标图像头发区域的掩模mask,
针对带有预转换头发颜色的参考图像,利用如图1所示的颜色特征提取模块(Color Module),所述颜色特征提取模块包括4层下采样的部分卷积网络(partialconvolution)和一个实例级平均池化层(instance-wise average pooling),首先使用头发分割网络获得参考图像头发区域的头发掩模,经过4层下采样的partial convolution,每层下采样都会使图像分辨率降低,相应的,每次头发掩模也会随之更新以避免头发以外特征的干扰。经过4次下采样后获得的特征图(feature map)进一步的使用一个实例级平均池化层压缩为一个512维的特征向量(feature vector)。这不仅保留了头发颜色的全局信息还去除了头发形状及结构差异带来的影响。进一步地,将提取到的特征向量通过以下公式与目标图像的头发掩模叠加:
其中A′
进一步地,利用如图1所示背景区域特征提取模块(Background Module)提取目标图像除头发以外的背景区域特征图,具体地,首先使用分割获得的目标图像头发掩模去除头发区域,保留其余区域不变,将剩余区域输入神经背景区域特征提取模块,经过两次下采样获得不同粒度的特征并在主干生成网络(backbone Generator)的最后两层与新生成的头发特征组合。
如图1所示,主干生成网络,包括4个resBlock和3层上采样,与Luminance Module具有对称的网络结构,其输入为获取目标图像包含头发结构和光照的特征图与头发颜色掩模在特征通道上连接后的组合特征,经过4个resBlock进一步提取特征后通过skipconnection结合Luminance Module中的下采样中多尺度的特征,并且在最后2层与背景特征组合生成具有参考图像头发颜色的图像。
作为一优选方案,若是需要连续转换视频中的多张目标图像的头发颜色,可以将待转换目标图像的前k帧图像经头发颜色转换后的生成的图像一同作为网络的输入即可生成更加平滑,时间相干性更强的视频序列。其中,为了保证输入一致,第一张、第二张的输入为相同的三张图像。
其中,结构特征提取模块、颜色特征提取模块、背景区域特征提取模块、主干生成网络通过通过如下方法根据收集的视频训练获得:
如图1循环一致性所示,对于两个视频序列X和Y,首先以视频序列Y作为参考图像,使用本发明方法上述步骤将视频序列X的头发颜色转换生成视频序列X*,再以视频序列X*作为参考图像,视频序列Y作为待转换头发颜色的视频序列,重复上述步骤生成新的视频序列Y*,Y*应当与视频序列Y相同,因此可以利用以下损失函数约束:
其中,
I是目标图像,I
λ为对应损失的权重,本实施例中分别取值λ
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其他不同形式的变化或变动。这里无需也无法把所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变动仍处于本发明的保护范围。