一种混合在线数据流场景下的半监督算法
文献发布时间:2023-06-19 18:49:33
技术领域
本发明涉及在线学习和半监督学习技术领域,具体为一种混合在线数据流场景下的半监督算法。
背景技术
从双重流输入的在线学习是最近兴起的一种新的数据流分析范式。与传统的在线学习不同的是,这种新的学习范式只能处理驻留在固定特征空间的数据流,努力建立与流数据和流特征有关的增量模型。这允许一个更灵活的学习环境,在这个环境中,新的特征可以任意出现并加入模型训练过程,而预先存在的特征可能在不同的时间跨度中变得不可观察或从模型中消失。
在这种灵活性的学习范式下,各种领域的应用开始以双流的形式对其数据进行建模。例如,考虑到一个人群感应应用,其中移动用户集体提交他们的数据来训练一个增量模型,检测当地的空气污染。双重流的特性从人群感应的数据流中体现出来--新的用户带着升级的或全新的设备(如手机、传感器套件)加入感应工作,将产生新的特征,而任何离开的用户(或一些设备由于网络问题导致掉线)都会引起特征的不可观察性。为了从这样的数据流中学习,以前的研究中常见的做法是建立特征之间的相关性,这样增量模型可以1)使用有根据的猜测初始化任何新特征的学习系数,当这些新特征没有被足够的数据实例描述时,用一个跳跃性的开始加速收敛;2)运用未观察到的特征的重建信息,利用其学习系数,通过在线集合提高预测性能。
首先,增量模型是在完全监督下训练的,这意味着每个到达的数据实例都必须有一个类别标签。不幸的是,由于有限的人力和时间被大量和高速的数据流拉长,注释标签一般来说是很困难的。第二,所有流入模型的特征都被规定为共享相同的数据类型,这在实际应用中经常被违反。例如,各种类型的传感器设备捕获的特征自然是不同的数据类型,包括布尔型(如下雨或不下雨)、序数型(如PM2.5水平)和连续型(如室外温度)。在这种混合类型的特征之间建立相关关系是非常具有挑战性的,并且不能通过事先假定高斯相关矩阵的在线参数模型来实现。
针对离线数据训练的成本高、时效性低及数据标签少等问题,本文针对性提出一种任意数据流场景下的半监督算法,该算法结合了在线学习和半监督学习的优点,在使用有标签数据的同时能够兼顾大量的无标签的数据,还可以很好的处理在线混合数据流。
发明内容
(一)解决的技术问题
针对现有技术的不足,本发明提供了一种混合在线数据流场景下的半监督算法,具备能够在利用标记和未标记样本的同时,又具有在线学习的特点,将二者的优点结合起来,解决了针对离线数据训练的成本高、时效性低及数据标签少等问题,本文针对性提出一种任意数据流场景下的半监督算法,该算法结合了在线学习和半监督学习的优点,在使用有标签数据的同时能够兼顾大量的无标签的数据,还可以很好的处理在线混合数据流的问题。
(二)技术方案
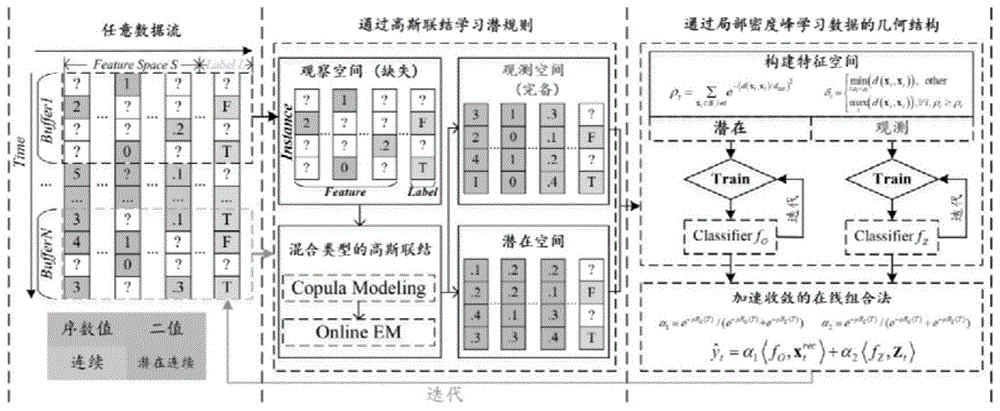
为实现上述能够在利用标记和未标记样本的同时,又具有在线学习的特点,将二者的优点结合起来目的,本发明提供如下技术方案:一种在线任意数据流场景下的半监督算法,包括任意数据流构建、通过高斯联结GC学习潜规则、通过局部密度峰值Local-DPC学习数据的几何结构特征、加速收敛的在线组合算法。其特征在于:所述任意数据流构建是针对在线数据应用场景(混合、缺失的数据流)下,构建对应的任意类型的数据集;通过GC学习潜规则是利用GC模型从观测空间(缺失)中学习各个不同变量之间的边缘分布特征,并通过在线最大期望Online-EM,找到观测空间(缺失)中缺失值的填充值;通过Local-DPC学习数据的几何结构特征是利用Local-DPC学习观测空间(完备)及潜在空间的数据几何结构分布特征;加速收敛的在线组合算法是针对观测空间(完备)及潜在空间不同分布特征空间,构建一个快速收敛的在线学习组合算法。
优选的,任意数据流构建是针对在线数据应用场景(混合、缺失的数据流)下,构建对应的任意类型的数据集,本算法所指任意数据流的特征包括有序数值(ordinal)、二值(binary)、连续值(continue)、离散值(discrete)等数据类型,此外,对于任意数据流中还存在有缺失的数值,缺失比例存在不确定性等问题。
优选的,通过GC学习潜规则是利用GC模型从观测空间(缺失)中学习各个不同变量之间的边缘分布特征,并通过在线最大期望Online-EM,找到观测空间(缺失)中缺失值的填充值。其中所涉及到的内容有未观察到的特征重建、Online-EM参数评估。未观察到的特征重建是指观测数值中缺失数值的重构。Online-EM参数评估目的是为了保证缺失值的填充空间与原始观测数据分布空间的最大相似性。
优选的,通过Local-DPC学习数据的几何结构特征是利用Local-DPC学习观测空间(完备)及潜在空间的数据几何结构分布特征;Local-DPC是通过不同簇构建选择不同类别的中心点,并利用中心点到其他周围节点的距离,构建不同类别的簇,形成对应类别的几何空间分布结构。
优选的,加速收敛的在线组合算法是针对观测空间(完备)及潜在空间不同分布特征空间,构建一个快速收敛的在线学习组合算法。单一数据空间分布无法满足数据的快速收敛,考虑不同空间下模型的权重,动态调整不同空间下的模型权重,从而加快模型的收敛速度。
(三)有益效果
与现有技术相比,本发明提供了一种混合在线数据流场景下的半监督算法,具备以下有益效果:
该混合在线数据流场景下的半监督算法,能够解决面对在在线学习中由离散型和连续型组成的混合数据特征难以建模的问题,通过GC由混合数据流组成的观测空间进行建模,映射到连续的隐空间中。利用Local-DP去探索数据空间的真实结构,将这个过程整合到半监督学习中去,充分利用未标记的数据。
附图说明
图1为本发明整体模型的示意图;
图2为本发明整体流程的示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-2,本发明提供一种技术方案:一种混合在线数据流场景下的半监督算法,
包括任意数据流构建、通过高斯联结GC(Gaussian Copula)学习潜规则、通过局部密度峰值Local-DPC(Local Density Peaks Clustering)学习数据的几何结构特征、加速收敛的在线组合算法。其特征在于:所述任意数据流构建是针对在线数据应用场景(混合、缺失的数据流)下,构建对应的任意类型的数据集;通过GC(Gaussian Copula)学习潜规则是利用GC模型从观测空间(缺失)中学习各个不同变量之间的边缘分布特征,并通过在线最大期望Online-EM(Online Expectation-Maximization),找到观测空间(缺失)中缺失值的填充值;通过Local-DPC学习数据的几何结构特征是利用Local-DPC学习观测空间(完备)及潜在空间的数据几何结构分布特征;加速收敛的在线组合算法是针对观测空间(完备)及潜在空间不同分布特征空间,构建一个快速收敛的在线学习组合算法。
同时包括以下步骤:
S1、任意数据流构建
所包括的数据类型有序数值、离散值、二值、连续值;
任意数据流构建是针对在线数据应用场景(混合、缺失的数据流)下,构建对应的任意类型的数据集,本算法所指任意数据流的特征包括有序数值(ordinal)、二值(binary)、连续值(continue)、离散值(discrete)等数据类型,此外对于任意数据流中还存在有缺失的数值,缺失比例存在不确定性(即存在随机性);
任意数据流构建中的数据流中涉及到二值、序数值、连续值、离散值等数据类型,任意数据流本身存在有不确定的缺失情况。
S2、潜在空间学习
利用GC模型从观测空间(缺失)中学习各个不同变量之间的边缘分布特征,并通过在线最大期望Online-EM,找到观测空间(缺失)中缺失值的填充值;
通过GC学习潜规则是利用GC模型从观测空间(缺失)中学习各个不同变量之间的边缘分布特征,并通过在线最大期望Online-EM,找到观测空间(缺失)中缺失值的填充值。其中所涉及到的内容有未观察到的特征重建、Online-EM参数评估。未观察到的特征重建是指观测数值中缺失数值的重构。Online-EM参数评估目的是为了保证缺失值的填充空间与原始观测数据分布空间的最大相似性;
潜在空间学习是观测空间(缺失)使用GC及Online-EM反复多轮迭代构建潜在空间,从而最终得到观测空间(完整)数据。
所包括的内容有:
1)定义在线混合数据流场景下的GC模型:
其中,cutoff(.)为截断函数,z∈R是连续正态,累积分布函数(CDF)为Fz和
2)缺失数据空间重构
其中,z
3)Online-EM参数评估
定义
其中,规模H=|B|/(|B|+1)保证了一个有限的输出,B为在线混合数据流的缓冲区大小;对于离散特征,将截止点S
其中,x
其中,Σ
S3、几何结构学习;
采用两个指标来描述每个到达的实例x
其中,d(x
通过Local-DPC学习数据的几何结构特征是利用Local-DPC学习观测空间(完备)及潜在空间的数据几何结构分布特征;Local-DPC是通过不同簇构建选择不同类别的中心点,并利用中心点到其他周围节点的距离,构建不同类别的簇,形成对应类别的几何空间分布结构;
几何结构学习是针对数据各个不同节点的相互关系,构建不同类别的簇,选取类中心节点,并计算类中心节点与其他节点的距离,构建各个不同节点之间的空间几何结构。
S4、集成算法
让y
其中,
加速收敛的在线组合算法是针对观测空间(完备)及潜在空间不同分布特征空间,提出的一个快速收敛的在线学习组合算法。单一数据空间分布无法满足数据的快速收敛,考虑不同空间下模型的权重,动态调整不同空间下的模型权重,从而加快模型的收敛速度;
集成算法是针对数据空间中不同数据分布空间下所学习的模型,采用动态自适应的模型权重调优,动态调整不同数据分布空间的模型权重,加速模型对于数据的拟合及收敛的速度。
尽管已经表示和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变形,本发明的范围由所附权利要求及其等同物限定。