抗ROR-2抗体和使用方法
文献发布时间:2023-06-19 19:30:30
相关申请交叉引用
本申请要求于2019年11月18日提交的美国临时申请第62/936,900号的优先权,所述美国临时申请特此通过引用整体并出于所有目的并入。
就联邦资助的研究和开发下的发明权利的声明
本发明是根据美国国立卫生研究院(National Institutes of Health)授予的CA236361和CA81534在政府支持下进行的。政府享有本发明的某些权利。
对序列表、表格或作为ASCII文本文件提交的计算机程序列表附录的引用
写入创建于2020年11月18日、字节数为122,880、机器格式为IBM-PC、采用MSWindows操作系统的文件48537-632001WO_ST25.TXT中的序列表特此通过引用并入。
背景技术
受体酪氨酸激酶样孤儿受体2(ROR2)是Wnt5a的发育限制受体。人ROR2是计算分子量为104.8kDa的943氨基酸单程I型膜蛋白。其跨若干物种是高度保守的,其中在小鼠与人蛋白之间具有92%氨基酸同一性。ROR2可以通过多价螯合标准Wnt配体来阻遏Wnt靶基因的转录并且调节Wnt信号传导,由此在不同的细胞环境中充当肿瘤抑制因子。最近,ROR2已经涉及多种癌症的进展,所述多种癌症包含乳腺癌、卵巢癌、胰腺癌、宫颈癌、胃癌、肾癌、头颈癌、骨癌、皮肤癌和前列腺癌。因此,需要特异性靶向人ROR2、抑制其功能并且由此充当有效治疗和诊断的抗体、抗体片段、双特异性抗体和嵌合抗原受体。本文所提供的组合物和方法满足了本领域的这些和其它要求。
发明内容
在一方面提供了一种抗酪氨酸激酶样孤儿受体2(ROR2)抗体,其包含重链可变结构域和轻链可变结构域,其中所述重链可变结构域包含:如SEQ ID NO:25中所示的CDR H1、如SEQ ID NO:26中所示的CDR H2和如SEQ ID NO:27中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ ID NO:28中所示的CDR L1、如SEQ ID NO:29中所示的CDR L2和如SEQID NO:30中所示的CDR L3。
在一方面提供了一种抗酪氨酸激酶样孤儿受体2(ROR2)抗体,其包含重链可变结构域和轻链可变结构域,其中所述重链可变结构域包含:如SEQ ID NO:31中所示的CDR H1、如SEQ ID NO:32中所示的CDR H2和如SEQ ID NO:33中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ ID NO:34中所示的CDR L1、如SEQ ID NO:35中所示的CDR L2和如SEQID NO:36中所示的CDR L3。
在另一方面提供了一种抗酪氨酸激酶样孤儿受体2(ROR2)抗体,其包含重链可变结构域和轻链可变结构域,其中所述重链可变结构域包含:如SEQ ID NO:37中所示的CDRH1、如SEQ ID NO:38中所示的CDR H2和如SEQ ID NO:39中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ ID NO:40中所示的CDR L1、如SEQ ID NO:41中所示的CDR L2和如SEQ ID NO:42中所示的CDR L3。
在另一方面提供了一种抗酪氨酸激酶样孤儿受体2(ROR2)抗体,其包含重链可变结构域和轻链可变结构域,其中所述重链可变结构域包含:如SEQ ID NO:43中所示的CDRH1、如SEQ ID NO:44中所示的CDR H2和如SEQ ID NO:45中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ ID NO:46中所示的CDR L1、如SEQ ID NO:47中所示的CDR L2和如SEQ ID NO:48中所示的CDR L3。
在一方面提供了一种治疗有需要的受试者的癌症的方法,所述方法包含向受试者施用治疗有效量的本文提供的抗体(包含其实施例)。
在一方面提供了一种抑制有需要的受试者的表达ROR2的癌症的转移的方法,所述方法包含向受试者施用治疗有效量的本文提供的抗体(包含其实施例)。
在另一方面提供了一种检测表达ROR2的细胞的方法,所述方法包含(i)使表达ROR2的细胞与本文提供的抗体(包含其实施例)接触;以及(ii)检测所述抗体与由所述细胞表达的ROR2蛋白的结合。
在另一方面提供了一种向表达ROR2的细胞递送治疗剂的方法,所述方法包含使表达ROR2的细胞与本文提供的抗体(包含其实施例)接触,其中所述抗体附着到治疗剂。
在另一方面提供了一种抑制表达ROR2的细胞的迁移的方法,所述方法包含使表达ROR2的细胞与本文提供的抗体(包含其实施例)接触。
在一方面提供了一种抗ROR2抗体,其中所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:重链可变结构域,所述重链可变结构域包含:如SEQ ID NO:25中所示的CDRH1、如SEQ ID NO:26中所示的CDR H2和如SEQ ID NO:27中所示的CDR H3;以及轻链可变结构域,所述轻链可变结构域包含:如SEQ ID NO:28中所示的CDR L1、如SEQ ID NO:29中所示的CDR L2和如SEQ ID NO:30中所示的CDR L3。
在一方面提供了一种抗ROR2抗体,其中所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:SEQ ID:2的重链可变结构域;以及SEQ ID NO:4的轻链可变结构域。
在一方面提供了一种抗ROR2抗体,其中所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:由SEQ ID:1的核酸序列编码的重链可变结构域;以及由SEQ ID:3的核酸序列编码的轻链可变结构域。
在一方面提供了一种抗ROR2抗体,其中所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:重链可变结构域,所述重链可变结构域包含:如SEQ ID NO:31中所示的CDRH1、如SEQ ID NO:32中所示的CDR H2和如SEQ ID NO:33中所示的CDR H3;以及轻链可变结构域,所述轻链可变结构域包含:如SEQ ID NO:34中所示的CDR L1、如SEQ ID NO:35中所示的CDR L2和如SEQ ID NO:36中所示的CDR L3。
在一方面提供了一种抗ROR2抗体,其中所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:SEQ ID:6的重链可变结构域;以及SEQ ID NO:8的轻链可变结构域。
在一方面提供了一种抗ROR2抗体,其中所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:由SEQ ID:5的核酸序列编码的重链可变结构域;以及由SEQ ID:7的核酸序列编码的轻链可变结构域。
在一方面提供了一种抗ROR2抗体,其中所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:重链可变结构域,所述重链可变结构域包含:如SEQ ID NO:37中所示的CDRH1、如SEQ ID NO:38中所示的CDR H2和如SEQ ID NO:39中所示的CDR H3;以及轻链可变结构域,所述轻链可变结构域包含:如SEQ ID NO:40中所示的CDR L1、如SEQ ID NO:41中所示的CDR L2和如SEQ ID NO:42中所示的CDR L3。
在一方面提供了一种抗ROR2抗体,其中所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:SEQ ID:10的重链可变结构域;以及SEQ ID NO:12的轻链可变结构域。
在一方面提供了一种抗ROR2抗体,其中所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:由SEQ ID:9的核酸序列编码的重链可变结构域;以及由SEQ ID:11的核酸序列编码的轻链可变结构域。
在一方面提供了一种抗ROR2抗体,其中所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:重链可变结构域,所述重链可变结构域包含:如SEQ ID NO:43中所示的CDRH1、如SEQ ID NO:44中所示的CDR H2和如SEQ ID NO:45中所示的CDR H3;以及轻链可变结构域,所述轻链可变结构域包含:如SEQ ID NO:46中所示的CDR L1、如SEQ ID NO:47中所示的CDR L2和如SEQ ID NO:48中所示的CDR L3。
在一方面提供了一种抗ROR2抗体,其中所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:SEQ ID:14的重链可变结构域;以及SEQ ID NO:16的轻链可变结构域。
在一方面提供了一种抗ROR2抗体,其中所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:由SEQ ID:13的核酸序列编码的重链可变结构域;以及由SEQ ID:15的核酸序列编码的轻链可变结构域。
在另一方面提供了一种嵌合抗原受体,其包含:(i)抗体区,所述抗体区包含:(a)轻链可变结构域,所述轻链可变结构域包含如SEQ ID NO:28中所示的CDR L1、如SEQ IDNO:29中所示的CDR L2和如SEQ ID NO:30中所示的CDR L3;以及{7}(b)重链可变区结构域,所述重链可变区结构域包含如SEQ ID NO:25中所示的CDR H1、如SEQ ID NO:26中所示的CDR H2和如SEQ ID NO:27中所示的CDR H3;以及(ii)跨膜结构域。
在一方面提供了一种嵌合抗原受体,其包含:(i)抗体区,所述抗体区包含:(a)轻链可变结构域,所述轻链可变结构域包含如SEQ ID NO:34中所示的CDR L1、如SEQ ID NO:35中所示的CDR L2和如SEQ ID NO:36中所示的CDR L3;以及{7}(b)重链可变区结构域,所述重链可变区结构域包含如SEQ ID NO:31中所示的CDR H1、如SEQ ID NO:32中所示的CDRH2和如SEQ ID NO:33中所示的CDR H3;以及(ii)跨膜结构域。
在一方面提供了一种嵌合抗原受体,其包含:(i)抗体区,所述抗体区包含:(a)轻链可变结构域,所述轻链可变结构域包含如SEQ ID NO:40中所示的CDR L1、如SEQ ID NO:41中所示的CDR L2和如SEQ ID NO:42中所示的CDR L3;以及{7}(b)重链可变区结构域,所述重链可变区结构域包含如SEQ ID NO:37中所示的CDR H1、如SEQ ID NO:38中所示的CDRH2和如SEQ ID NO:39中所示的CDR H3;以及(ii)跨膜结构域。
在一方面提供了一种嵌合抗原受体,其包含:(i)抗体区,所述抗体区包含:(a)轻链可变结构域,所述轻链可变结构域包含如SEQ ID NO:46中所示的CDR L1、如SEQ ID NO:47中所示的CDR L2和如SEQ ID NO:48中所示的CDR L3;以及{7}(b)重链可变区结构域,所述重链可变区结构域包含如SEQ ID NO:43中所示的CDR H1、如SEQ ID NO:44中所示的CDRH2和如SEQ ID NO:45中所示的CDR H3;以及(ii)跨膜结构域。
在另一方面提供了一种治疗有需要的受试者的癌症的方法,所述方法包含向受试者施用治疗有效量的本文提供的嵌合抗原受体(包含其实施例)。
在另一方面提供了一种抗受体酪氨酸激酶样孤儿受体2(ROR2)抗体,其能够与包含SEQ ID NO:22的氨基酸序列的ROR2的胞外结构域结合。
附图说明
图1:人和小鼠ROR2的胞外区的比较。示出了人(上部序列)和小鼠(下部序列)ROR2的胞外区的氨基酸序列的比对。小圆点指示所述位置处的同源性,而差异由单字母氨基酸密码子指定。Ig样、CRD和kringle结构域由序列上方的线标记和指示。
图2A-2D:针对四个小鼠抗人ROR2杂交瘤中的每个小鼠抗人ROR2杂交瘤描绘的氨基酸序列和与最接近的小鼠IGHV(上部序列)或IGKV(下部序列)种系基因的比对,所述四个小鼠抗人ROR2杂交瘤指定为(图2A)6E6、(图2B)4G9、(图2C)5C11和(图2D)5G3。对于每个比对,上部序列描绘了重链或轻链可变区的氨基酸序列,其起始于第一框架区的第一个密码子并且终止于第四框架区的最后一个密码子。下部序列描绘了最同源的小鼠IGHV或IGKV种系基因的重链或轻链可变区的氨基酸序列。在所述序列上方标记框架区(FR)和互补决定区(CDR),并且在所比对序列下方标注两个序列之间的差异,并且以粗体指定为单字母氨基酸密码子。
图3:在不同量的固定蛋白和不同浓度的可溶性mAb下,评估抗ROR2 mAb与重组人ROR2的结合。将孔用27nM、9nM、3nM和1nM的重组人ROR2胞外结构域(ROR2-ECD)包被过夜,洗涤并用样品缓冲液(1X BBS+1% BSA)在37℃下封闭90分钟。将在500-31ng/ml范围内的6E6、4G9、5C11或5G3 mAb的连续稀释液添加到孔中,在环境温度下温育60分钟,洗涤并用HRP缀合的山羊抗小鼠IgG检测,并且用TMB微孔过氧物酶底物显色。通过添加1M O-磷酸终止显色,并且在SpectraMax340酶标仪上读取450nM处的吸光度。相对于横坐标上的mAb浓度(ng/ml),吸光度值绘制在纵坐标上。在较低的板包被浓度和较少量的可溶性mAb下的较高吸光度值表明与5C11和5G3相比,对6E6和4G9的结合亲和力相对较高。
图4A和4B:6E6和4G9 mAb与重组ROR2蛋白的结合的亲和力测量。(图4A)使用KinExA 3200仪器进行分析。示出了对于6E6(上图)和4G9(下图),在存在递增摩尔(M)浓度的可溶性ROR2竞争剂(x轴)的情况下,与用ROR2蛋白包被的颗粒结合的抗人ROR2 mAb的比例(y轴)。(图4B)用于与人ROR2结合的6E6(上图)和4G9(下图)的所测量Kd的95%置信区间的图解。
图5:通过评估与嵌合人/小鼠重组ROR2蛋白结合来鉴定抗人ROR2 mAb的结合区。左图示出了用于绘制四种ROR2 mAb中的每种ROR2 mAb的结合区的ROR2的胞外部分的嵌合构建体的示意图。每个构建体的暗区指示人ROR2并且阴影部分区指示小鼠ROR2。h1-111和h1-160分别是指人ROR2的前111和160个氨基酸。hCRD和hKringle含有人ROR2的半胱氨酸富集结构域和Kringle结构域。将每种重组蛋白转移到尼龙膜上,用6E6、4G9、5C11、5G3或抗his标签mAb进行探测,并且用与辣根过氧化物酶缀合的抗小鼠IgG抗体进行检测,如右图所示。6E5和5C11mAb与含有人kringle结构域的ROR2重组蛋白结合。4G9和5G3 mAb与在人ROR2的前111aa内的ROR2重组蛋白结合,其包含Ig样结构域。
图6:鉴定用于将抗人ROR2 mAb与人ROR2的Kringle结构域结合所需的氨基酸。使用重组人ROR2蛋白来评估6E6、4G9和5C11 mAb的结合,其中在kringle结构域内的人与小鼠ROR2之间不同的一个氨基酸被小鼠ROR2的对应氨基酸替代。将每种重组蛋白转移到尼龙膜上,用6E6、4G9或5C11 mAb进行探测,并且用与辣根过氧化物酶缀合的抗小鼠IgG抗体进行检测,如上图所示。下图中示出了人和小鼠ROR2的kringle结构域的蛋白质序列的比对,并且框出的氨基酸指示针对每种重组蛋白进行的氨基酸改变。
图7A和7B:6E6和4G9抗人ROR2 mAb与人ROR2特异性结合。(图7A)通过流式细胞术染色和分析已知表达ROR2的若干细胞系来评估6E6和4G9 mAb与人ROR的结合。将细胞在冰上用10ug/ml 6E6或4G9抗人ROR2-Alexa647缀合的mAb(阴影直方图)或等量的同种型匹配的对照mAb(空心直方图)染色20分钟,洗涤并分析。直方图描绘了如通过光散射特性确定的活细胞的相对荧光强度(x轴)。(图7B)通过与HCT116结肠直肠癌细胞和HEK293细胞的结合的缺乏来验证特异性,其中与亲本细胞系相比,使用CRISPR-cas9来消除ROR2表达。
图8:6E6和4G9抗人ROR2 mAb与由BR1936乳腺癌PDX细胞表达的ROR2结合。将BR1936和BR1367(ROR2阴性)乳腺癌PDX细胞用10ug/ml 6E6或4G9抗人ROR2-Alexa647缀合的mAb(阴影直方图)或等量的同种型匹配的对照mAb(空心直方图)染色。将细胞在冰上染色20分钟,洗涤并通过流式细胞术进行分析。直方图描绘了如通过光散射特性确定的活细胞的相对荧光强度(x轴)。6E6和4G9两者均与BR1936细胞结合,但不与不表达人ROR2的BR1367细胞结合。
图9:6E6和4G9抗人ROR2 mAb不与从健康供体分离的外周血单核细胞(PBMC)或淋巴细胞结合。通过ficoll密度离心从经健康供体同意获得的全血中分离PBMC。将细胞在冰上用5ug/ml 6E6或4G9抗人ROR2-Alexa647缀合的mAb(阴影直方图)或等量的同种型匹配的对照mAb(空心直方图)染色20分钟,洗涤并通过流式细胞术进行分析。直方图描绘了如通过光散射特性确定的活的可存活单核细胞或淋巴细胞的染色。将K562细胞的染色作为阳性对照进行。
图10A和10B:6E6和4G9抗人ROR2 mAb被K562而非JEKO细胞内化。将K562和JEKO(ROR2阴性)细胞在冰上用10ug/ml 6E6或4G9抗人ROR2-pHrodo缀合的mAb染色30分钟,洗涤并等分成四个部分。将一个板保持在冰上,并且将其它三个板转移到37℃,持续30、60或120分钟。温育之后,将细胞洗涤并通过流式细胞术进行分析。(图10A)直方图描绘了如通过光散射特性确定的活细胞的相对荧光强度(x轴)。阴影直方图描绘了在37℃下温育120分钟的染色细胞,虚线直方图描绘了在4℃下温育120分钟的染色细胞,并且空心直方图描绘了在37℃下温育120分钟的未染色细胞。与在4℃下温育120分钟的染色细胞或在37℃下温育120分钟的未染色细胞相比,注意到对于表达ROR2但不表达ROR2阴性JEKO细胞的K562细胞,6E6(上图)和4G9(下图)pHrodo缀合的mAb两者的相对荧光增加。(图10B)6E6或4G9 pHrodo缀合的mAb在K562细胞上的平均荧光(y轴)随时间(x轴)推移增加的图示。ΔMFI是用在37℃下温育的pHrodo缀合的mAb染色的K562细胞的平均荧光强度减去在4℃下温育等量时间的相同染色细胞的等分试样的平均荧光强度。
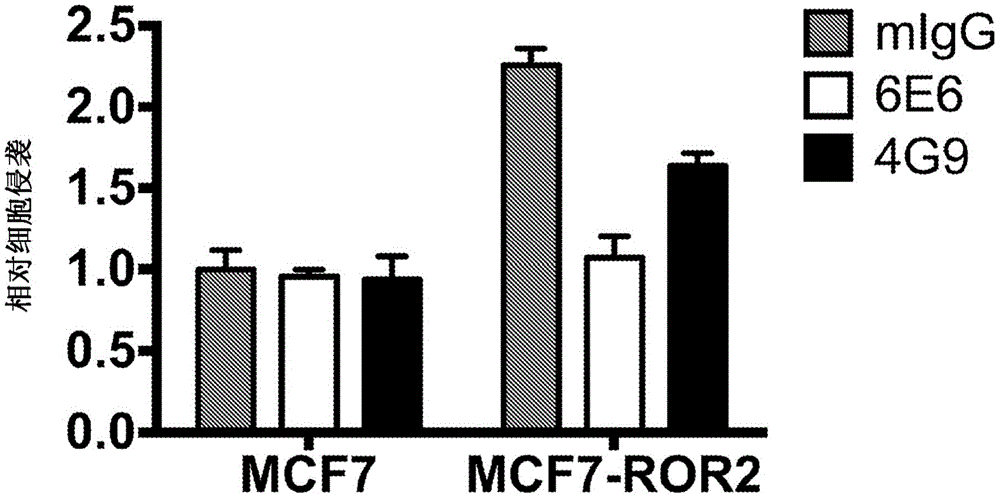
图11A和11B:6E6和4G9抗人ROR2 mAb抑制Wnt5a诱导的MCF7-ROR乳腺癌细胞的侵袭。将用对照载体或ROR2表达载体转染的MCF7乳腺癌细胞在补充有0.5%牛胎儿血清(FBS)而没有生长因子的杜尔贝科改良伊格尔培养基(Dulbecco's modified Eagle's medium,DMEM)中培养过夜。第二天,去除细胞并且将10
图12A和12B:6E6单链可变片段(scFv)对人ROR2的亲和力测量和结合特异性。使用KinExA 3200仪器进行分析。(图12A)示出了在存在递增摩尔(M)浓度的可溶性ROR2竞争剂(x轴)的情况下,与用重组ROR2蛋白包被的颗粒结合的6E6抗人ROR2 scFv的比例(y轴)。(图12B)用于与重组人ROR2结合的6E6scFv的所测量Kd的95%置信区间的图解。(图12C)通过流式细胞术染色和分析K562(ROR2阳性)和JEKO(ROR2阴性)细胞来评估6E6 scFv与ROR2的结合。将细胞在冰上用约1ug/ml 6E6抗人ROR2 scfv染色20分钟,洗涤,在冰上用藻红蛋白(PE)缀合的抗人IgG1抗体染色另外20分钟,洗涤并通过流式细胞术进行分析。阴影直方图描绘了与仅用抗人IgG1-PE抗体染色的活细胞(空心直方图)相比,如通过光散射特性确定的用6E6 scfv染色的活细胞的相对荧光强度(x轴)。6E6 scFv与K562细胞结合,但不与不表达人ROR2的JEKO细胞结合。
图13:6E6和4G9抗人ROR2嵌合抗原受体(CAR)与重组人ROR2蛋白特异性结合。将HEK293细胞用6E6或4G9抗人ROR2嵌合抗原受体构建体或抗人ROR1CAR构建体进行转染。48小时后,通过流式细胞术评估所有细胞与由人IgG1的ROR2胞外结构域和CH2-CH3恒定区结构域构成的重组人ROR2-Ig蛋白的结合。将细胞在冰上用1ug/ml重组ROR2-Ig(上图)或1ug/ml对照ROR1-Ig(下图)染色20分钟,洗涤,在冰上用藻红蛋白(PE)缀合的抗人IgG1抗体染色另外20分钟,洗涤并通过流式细胞术进行分析。阴影直方图描绘了与仅用抗人IgG1-PE抗体染色的细胞(空心直方图)相比,如通过光散射特性确定的用ROR2-Ig或ROR1-Ig染色的活细胞的相对荧光强度(x轴)。用6E6或4G9 CAR构建体转染的HEK293细胞与ROR2-Ig(上图)结合,但不与由与人ROR1的胞外区融合的相同人IgG结构域构成的ROR1-Ig结合。与之相反,ROR1 CAR转染的细胞仅与ROR1-Ig结合。
具体实施方式
虽然在本文中示出和描述了本发明的各个实施例和方面,但是本领域的技术人员将清楚的是仅作为举例而提供此类实施例和方面。在不脱离本发明的情况下,本领域的技术人员现在将意识到许多变化、改变和替代。应该理解的是,本文所描述的本发明的各实施例的不同替代方案可以用于实践本发明。
本文所使用的章节标题仅出于组织目的,而不应被解释为对所描述的主题进行限制。在本申请中引用的所有文件或文件的部分,包含但不局限于专利、专利申请、论文、书籍、手册和专著,均特此出于任何目的通过引用整体明确地并入。
本文所使用的缩写具有其在化学领域和生物学领域内的常规含义。本文所阐述的化学结构和式是根据化学领域中已知的化学价的标准规则构建的。
除非另有定义,否则本文所使用的所有技术术语和科学术语具有与本领域普通技术人员通常理解的含义相同的含义。参见例如,Singleton等人,《微生物学和分子生物学词典(DICTIONARY OF MICROBIOLOGY AND MOLECULAR BIOLOGY)》第2版,威利父子杂志出版社(J.Wiley&Sons)(纽约州纽约市,1994);Sambrook等人,《分子克隆:实验室手册(MOLECULARCLONING,A LABORATORY MANUAL)》,冷泉港出版社(Cold Springs Harbor Press)(纽约冷泉港,1989)。与本文所描述的方法、装置和材料类似或等效的任何方法、装置和材料均可以用于实践本发明。提供以下定义以便于理解本文中频繁使用的某些术语,并且不意味着限制本公开的范围。
“核酸”是指核苷酸(例如,脱氧核糖核苷酸或核糖核苷酸)和其呈单链、双链或多链形式的聚合物或其补体;或核苷(例如,脱氧核糖核苷或核糖核苷)。在各实施例中,“核酸”不包含核苷。术语“多核苷酸”、“寡核苷酸”、“低聚核苷酸”等在通常和习惯意义上是指核苷酸的线性序列。术语“核苷”在通常和惯用意义上是指包含核碱基和五碳糖(核糖或脱氧核糖)的糖基胺。核苷的非限制性实例包含胞苷、尿苷、腺苷、鸟苷、胸苷和肌苷。术语“核苷酸”在通常和习惯意义上是指多核苷酸的单个单元,即,单体。核苷酸可以是核糖核苷酸、脱氧核糖核苷酸或其经过修饰的版本。本文所设想的多核苷酸的实例包含单链和双链DNA、单链和双链RNA以及具有单链和双链DNA和RNA的混合物的杂交分子。本文所设想的核酸的实例,例如多核苷酸包含任何类型的RNA,例如mRNA、siRNA、miRNA和指导RNA以及任何类型的DNA、基因组DNA、质粒DNA和微环DNA以及其任何片段。在多核苷酸的上下文中,术语“双链体”在通常和习惯意义上是指双链型。核酸可以是线性或支化的。例如,核酸可以是核苷酸的直链或核酸可以是支化的,例如,使得所述核酸包括核苷酸的一个或多个臂或分支。任选地,支化核酸重复分支以形成更高级结构,如树状物等。
核酸,包含例如具有硫代磷酸酯主链的核酸,可以包含一个或多个反应性部分。如本文所使用的,术语反应性部分包含能够通过共价、非共价或其它相互作用与另一分子,例如,核酸或多肽进行反应的任何基团。举例来说,核酸可以包含通过共价、非共价或其它相互作用与蛋白质或多肽上的氨基酸进行反应的氨基酸反应性部分。
术语涵盖含有已知核苷酸类似物或经过修饰的主链残基或键的核酸,所述核酸是合成的、天然存在的和非天然存在的,所述核酸具有与参考核酸类似的结合性质并且所述核酸以与参考核苷酸类似的方式代谢。此类类似物的实例包含但不限于磷酸二酯衍生物,所述磷酸二酯衍生物包含例如氨基磷酸酯、二氨基磷酸酯、硫代磷酸酯(也被称为硫代磷酸,其具有双键硫置换的含氧的磷酸盐)、二硫代磷酸酯、膦酰羧酸、膦酰羧酸酯、膦酰基乙酸、膦酰甲酸、甲基膦酸酯、硼膦酸酯或O-甲基亚磷酰胺键(参见Eckstein,《寡核苷酸以及类似物:实用方法(OLIGONUCLEOTIDES AND ANALOGUES:A PRACTICAL APPROACH)》,牛津大学出版社(Oxford University Press)),以及如在5-甲基胞苷或假尿苷中对核苷酸碱基的修饰;以及肽核酸主链和键。其它类似核酸包含具有正主链的核酸;非离子主链、经过修饰的糖和非核糖主链(例如,本领域已知的磷酰二胺吗啉代寡核苷酸或锁核酸(LNA)),包含美国专利第5,235,033号和第5,034,506号以及第6章和第7章,《ASC研讨会系列580(ASCSymposium Series 580)》,《反义研究中的碳水化合物修饰(CARBOHYDRATE MODIFICATIONSIN ANTISENSE RESEARCH)》,Sanghui和Cook编辑中描述的那些。含有一个或多个碳环糖的核酸也包含在核酸的一个定义内。出于多种原因,可以进行核糖-磷酸主链的修饰,例如,增加此类分子在生理环境中,或作为生物芯片上的探针的稳定性和半衰期。可以制备天然存在的核酸和类似物的混合物;可替代地,可以制备不同核酸类似物的混合物,以及天然存在的核酸和类似物的混合物。在各实施例中,DNA中的核苷酸间键是磷酸二酯、磷酸二酯衍生物或两者的组合。
核酸可以包含非特异性序列。如本文中所使用的,术语“非特异性序列”是指含有未被设计成与任何其它核酸序列互补或与任何其它核酸序列仅部分互补的一系列残基的核酸序列。举例来说,非特异性核酸序列是在与细胞或生物体接触时不起抑制性核酸的作用的核酸残基的序列。
多核苷酸通常由四种核苷酸碱基的特定序列构成:腺嘌呤(A);胞嘧啶(C);鸟嘌呤(G);和胸腺嘧啶(T)(当多核苷酸是RNA时,胸腺嘧啶(T)的尿嘧啶(U))。因此,术语“多核苷酸序列”是多核苷酸分子的字母表示;可替代地,所述术语可以应用于多核苷酸分子本身。此字母表示可以输入到具有中央处理单元的计算机中的数据库中,并且用于生物信息学应用,如功能基因组学和同源性搜索。多核苷酸可以任选地包含一种或多种非标准核苷酸、核苷酸类似物和/或经过修饰的核苷酸。
如本文所使用的术语“补体”是指能够与互补核苷酸或核苷酸序列进行碱基配对的核苷酸(例如,RNA或DNA)或核苷酸序列。如本文所描述的和本领域公知的,腺苷的互补(匹配)核苷酸是胸苷,并且鸟苷的互补(匹配)核苷酸是胞嘧啶。因此,补体可以包含与第二核酸序列的对应互补核苷酸碱基配对的核苷酸序列。补体的核苷酸可以部分或完全匹配第二核酸序列的核苷酸。当补体的核苷酸与第二核酸序列中的每个核苷酸完全匹配时,补体与第二核酸序列中的每个核苷酸形成碱基对。当补体的核苷酸与第二核酸序列的核苷酸部分匹配时,补体中的仅一些核苷酸与第二核酸序列的核苷酸形成碱基对。互补序列的实例包含编码和非编码序列,其中非编码序列含有编码序列的互补核苷酸,并且因此形成编码序列的补体。互补序列的另外的实例是正义序列和反义序列,其中正义序列含有反义序列的互补核苷酸,并且因此形成反义序列的补体。
如本文所描述的,序列的互补性可以是部分的,其中仅一些核酸根据碱基配对匹配,或是完全的,其中所有核酸根据碱基配对匹配。因此,彼此互补的两个序列可以具有相同的指定百分比的核苷酸(即,在指定区域内约60%同一性,优选地65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更高同一性)。
术语“氨基酸”是指天然存在的和合成的氨基酸,以及以与天然存在的氨基酸类似的方式起作用的氨基酸类似物和氨基酸模拟物。天然存在的氨基酸是由基因密码编码的氨基酸以及之后被修饰的那些氨基酸,例如,羟基脯氨酸、γ-羧基谷氨酸和O-磷酸丝氨酸。氨基酸类似物是指具有与天然存在的氨基酸相同的基本化学结构的化合物,即,与氢、羧基、氨基和R基结合的α碳,如,高丝氨酸、正亮氨酸、甲硫氨酸亚砜、甲硫氨酸甲基锍。此类类似物具有经过修饰的R基团(例如,正亮氨酸)或经过修饰的肽主链,但是保留与天然存在的氨基酸相同的基本化学结构。氨基酸模拟物是指具有与氨基酸的通式化学结构不同的结构但以与天然存在的氨基酸类似的方式起作用的化学化合物。术语“非天然存在的氨基酸”和“非天然氨基酸”是指自然界中未发现的氨基酸类似物、合成氨基酸和氨基酸模拟物。
氨基酸在本文中可以通过其通常已知的三字母符号或通过IUPAC-IUB生物化学命名法委员会(the IUPAC-IUB Biochemical Nomenclature Commission)推荐的单字母符号来指代。同样,核苷酸可以通过其普遍接受的单字母代码来指代。
术语“多肽”、“肽”和“蛋白质”在本文中可互换使用,以指代氨基酸残基的聚合物,其中在各实施例中,所述聚合物可以与不由氨基酸组成的部分缀合。所述术语适用于其中一个或多个氨基酸残基是对应天然存在的氨基酸的人造化学模拟物的氨基酸聚合物,以及适用于天然存在的氨基酸聚合物和非天然存在的氨基酸聚合物。“融合蛋白”是指编码重组地表达为单个部分的两个或更多个单独蛋白质序列的嵌合蛋白。
氨基酸或核苷酸碱基的“位置”由编号表示,所述编号基于其相对于N末端(或5'端)的位置顺序地鉴定参考序列中的每个氨基酸(或核苷酸碱基)。由于在确定最佳比对时必须考虑的缺失、插入、截短、融合等,因此,通常测试序列中的通过仅从N末端进行计数而确定的氨基酸残基的编号不一定与其在参考序列中的对应位置的编号相同。例如,在变体相对于比对的参考序列具有缺失的情况下,变体中将不存在与参考序列中的缺失位点处的位置相对应的氨基酸。在比对的参考序列中存在插入的情况下,所述插入将不与参考序列中的经过编号的氨基酸位置相对应。在截短或融合的情况下,参考序列或比对序列中可能存在不与对应序列中的任何氨基酸相对应的氨基酸段。
当在对给定氨基酸或多核苷酸序列进行编号的上下文中使用时,术语“相对于…进行编号”或“对应于…进行编号”是指在将给定氨基酸或多核苷酸序列与参考序列进行比较时,对指定参考序列的残基进行编号。当蛋白质中的氨基酸残基占据与给定残基相同的蛋白质内的基本结构位置时,所述氨基酸残基与给定残基“相对应”。本领域的技术人员将立即认识到残基的与具有不同编号系统的其它蛋白质中的蛋白质(例如,ROR-1)中的特定位置相对应的同一性和位置。例如,通过用蛋白质(例如,ROR-1)进行简单的序列比对,在与蛋白质比对的其它蛋白质序列中鉴定了与蛋白质的特定位置相对应的同一性和位置。例如,当所选择残基占据与位置138处的谷氨酸相同的基本空间或其它结构关系时,所选择蛋白质中的所选择残基与位置138处的谷氨酸相对应。在对于最大同源性而言将所选择蛋白质与蛋白质进行比对的一些实施例中,与谷氨酸138比对的所比对的所选择蛋白质中的位置与谷氨酸138相对应。代替一级序列比对,还可以使用三维结构比对,例如,其中针对与位置138处的谷氨酸的最大对应性而对所选择蛋白质的结构进行比对,并且对总体结构进行比较。在这种情况下,在结构模型中占据与谷氨酸138相同的基本位置的氨基酸与谷氨酸138残基相对应。
“经过保守修饰的变体”适用于氨基酸序列和核酸序列两者。关于特定核酸序列,“经过保守修饰的变体”是指编码相同或基本上相同的氨基酸序列的那些核酸。因为遗传密码的简并,所以多个核酸序列将编码任何给定的蛋白质。例如,密码子GCA、GCC、GCG和GCU全部编码氨基酸丙氨酸。因此,在由密码子指定丙氨酸的每个位置处,密码子可以在不改变经过编码的多肽的情况下改变成所描述的对应密码子中的任何一个。此类核酸变化为“沉默变化”,所述沉默变化是经过保守修饰的变化的一个物质。本文中编码多肽的每个核酸序列还描述核酸的每种可能的沉默变化。技术人员将认识到,核酸中的每个密码子(除通常是用于甲硫氨酸的唯一密码子的AUG和通常是用于色氨酸的唯一密码子的TGG之外)可以被修饰以产生功能上相同的分子。因此,编码多肽的核酸的每种沉默变化隐含在每个所描述的序列中。
关于氨基酸序列,技术人员将认识到改变、添加或缺失经过编码的序列中的单个氨基酸或小百分比的氨基酸的核酸、肽、多肽或蛋白质序列的单独取代、缺失或添加是其中改变会引起氨基酸被化学上类似的氨基酸取代的“经过保守修饰的变体”。提供功能上类似的氨基酸的保守取代表在本领域中是众所周知的。此类经过保守修饰的变体除了本公开的多晶型变体、种间同源物和等位基因并且不排除所述多晶型变体、种间同源物和等位基因。
以下八个基团各自含有彼此保守取代的氨基酸:
1)丙氨酸(A)、甘氨酸(G);
2)天冬氨酸(D)、谷氨酸(E);
3)天冬酰胺(N)、谷氨酰胺(Q);
4)精氨酸(R)、赖氨酸(K);
5)异亮氨酸(I)、亮氨酸(L)、甲硫氨酸(M)、缬氨酸(V);
6)苯丙氨酸(F)、酪氨酸(Y)、色氨酸(W);
7)丝氨酸(S)、苏氨酸(T);以及
8)半胱氨酸(C)、甲硫氨酸(M)
(参见例如,Creighton,《蛋白质(Proteins)》(1984))。
在两个或更多个核酸或多肽序列的上下文中,术语“相同”或“同一性”百分比是指如使用利用以下描述的默认参数的BLAST或BLAST 2.0序列比较算法或通过手动比对和视觉检查测量的相同的或具有指定百分比的相同氨基酸残基或核苷酸的两个或更多个序列或子序列(即,当在比较窗口或指定区之上针对最大对应性进行比较和比对时,在指定区之上约60%同一性,优选地65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更高同一性)(参见例如,NCBI网站http://www.ncbi.nlm.nih.gov/BLAST/等)。此类序列然后被称为“基本上相同”。此定义还涉及或可以应用于测试序列的补体。所述定义还包含具有缺失和/或添加的序列,以及具有取代的序列。如下所述,优选的算法可以解释间隙等。优选地,在长度为至少约25个氨基酸或核苷酸的区域之上,或更优选地在长度为50-100个氨基酸或核苷酸的区域之上存在同一性。
“序列同一性百分比”是通过在比较窗口之上比较两个最佳比对的序列确定的,其中比较窗口中的多核苷酸序列或多肽序列的部分可以包括如相比于用于两个序列的最佳比对的参考序列(其不包括添加或缺失)的添加或缺失(即,间隙)。百分比通过以下计算:确定两个序列中出现相同核酸碱基或氨基酸残基的位置数以得到匹配的位置数,将匹配的位置数除以比较窗口中的总位置数并且将结果乘以100以得到序列同一性百分比。
如本文所使用的,“比较窗口”包含对选自由例如全长序列或20个到600个、约50个到约200个或约100个到约150个氨基酸或核苷酸组成的组的连续位置数中的任一个的区段的指代,其中在两个序列进行最佳比对后,序列可以与具有相同数量的连续位置的参考序列进行比较。用于比较的序列比对方法在本领域中是众所周知的。用于比较的序列的最佳比对可以例如通过以下进行:Smith和Waterman的局部同源性算法(1970)《高等应用数学(Adv.Appl.Math.)》2:482c,通过Needleman和Wunsch的同源性比对算法(1970)《分子生物学杂志(J.Mol.Biol.)》48:443,通过Pearson和Lipman的相似性搜索方法(1988)《美国国家科学院院刊(Proc.Nat'l.Acad.Sci.USA)》85:2444,通过这些算法的计算机化实施方案(威斯康星州麦迪逊科学大道575号遗传学计算机组的威斯康星遗传学软件包(WisconsinGenetics Software Package,Genetics Computer Group,575Science Dr.,Madison,WI)中的GAP、BESTFIT、FASTA和TFASTA);或通过手动比对和视觉检查(参见例如,Ausubel等人,《当代分子生物学实验指南(Current Protocols in Molecular Biology)》(1995年增刊))。
适用于确定序列同一性和序列相似性百分比的算法的一个实例是分别在以下中描述的BLAST和BLAST 2.0算法:Altschul等人,(1977)《核酸研究(Nuc.Acids Res.)》25:3389-3402以及Altschul等人(1990)《分子生物学杂志》215:403-410。用于执行BLAST分析的软件可通过美国国家生物技术信息中心(National Center for BiotechnologyInformation)(http://www.ncbi.nlm.nih.gov/)公开获得。这个算法涉及首先通过鉴定查询序列中长度为W的短字来鉴定高得分序列对(HSP),当与数据库序列中相同长度的字进行比对时,所述短字匹配或满足某一正值阈值得分T。T被称作邻域字得分阈值(Altschul等人,同上)。这些初始邻域字命中充当用于启动搜索的种子以找到含有所述初始邻域字命中的较长HSP。字命中沿每个序列在两个方向上扩展,直到累积比对得分可以增加为止。对于核苷酸序列,使用参数M(一对匹配残基的奖励得分;总是>0)和N(错配残基的罚分;总是<0)来计算累积得分。对于氨基酸序列,使用得分矩阵来计算累积得分。在以下情况下,中止字命中在每个方向上的扩展:累积比对得分从其最大实现值减小了数量X;由于一个或多个负得分残基比对的累积,累积得分变为零或更低;或到达任一序列的末端。BLAST算法参数W、T和X确定比对的灵敏度和速度。BLASTN程序(对于核苷酸序列)使用字长(W)为11、期望值(E)为10、M=5、N=-4以及对两条链的比较作为默认值。对于氨基酸序列,BLASTP程序使用字长为3并且期望值(E)为10和BLOSUM62得分矩阵(参见Henikoff和Henikoff(1989)《美国国家科学院院刊》89:10915)比对(B)为50、期望值(E)为10、M=5、N=-4,以及两条链的比较作为默认值。
BLAST算法还对两个序列之间的相似性进行统计分析(参见例如,Karlin和Altschul(1993)《美国国家科学院院刊》90:5873-5787)。由BLAST算法提供的一种相似性量度是最小总和概率(P(N)),其提供了两个核苷酸或氨基酸序列之间偶然发生匹配的概率的指示。例如,如果在测试核酸与参考核酸的比较中最小总和概率小于约0.2、更优选地小于约0.01并且最优选地小于约0.001,则核酸被认为与参考序列类似。
两个核酸序列或多肽基本上相同的指示是由第一核酸编码的多肽与针对由第二核酸编码的多肽产生的抗体发生免疫交叉反应,如下所述。因此,多肽通常与第二多肽基本上相同,例如其中两个肽仅保守取代不同。两个核酸序列基本上相同的另一个指示是两个分子或其补体在严格条件下彼此杂交,如下所述。两个核酸序列基本上相同的又另一个指示是可以使用相同的引物来扩增序列。
抗体是具有复杂的内部结构的大的复杂的分子(分子量为约150,000或约1320个氨基酸)。天然抗体分子含有两对相同的多肽链,每对具有一条轻链和一条重链。每条轻链和重链进而由两个区组成:涉及与靶抗原结合的可变(“V”)区以及与免疫系统的其它组分相互作用的恒定(“C”)区。轻链和重链可变区(本文中还分别被称为轻链可变(VL)结构域和重链可变(VH)结构域)在3维空间中聚在一起以形成与抗原(例如,细胞表面上的受体)结合的可变区。在每个轻链或重链可变区内,存在称为互补决定区(“CDR”)的三个短区段(长度平均为10个氨基酸)。抗体可变结构域中的六个CDR(三个来自轻链并且三个来自重链)在3维空间中折叠在一起以形成对接至靶抗原的实际抗体结合位点。CDR的位置和长度已经由以下准确定义:Kabat,E.等人,《具有免疫学意义的蛋白质序列(Sequences of Proteinsof Immunological Interest),美国卫生与公众服务部(U.S.Department of Health andHuman Services),1983,1987。不包含在CDR中的可变区的部分被称为框架(“FR”),其形成用于CDR的环境。
如本文所提供的“抗体变体”是指能够与抗原结合并且包含抗体或其片段的一个或多个结构域(例如,轻链可变结构域、重链可变结构域)的多肽。抗体变体的非限制性实例包含单结构域抗体或纳米抗体、单特异性Fab
如本文所提供的术语“CDR L1”、“CDR L2”和“CDR L3”是指抗体的可变轻(L)链的互补决定区(CDR)1、2和3。在各实施例中,本文所提供的可变轻链在N末端到C末端方向上包含CDR L1、CDR L2和CDR L3。同样地,如本文所提供的术语“CDR H1”、“CDR H2”和“CDR H3”是指抗体的可变重(H)链的互补决定区(CDR)1、2和3。在各实施例中,本文所提供的可变重链在N末端到C末端方向上包含CDR H1、CDR H2和CDR H3。
如本文所提供的术语“FR L1”、“FR L2”、“FR L3”和“FR L4”根据其在本领域中的常用含义使用,并且是指抗体的可变轻(L)链的框架区(FR)1、2、3和4。在各实施例中,本文所提供的可变轻链在N末端到C末端方向上包含FR L1、FR L2、FR L3和FR L4。同样地,如本文所提供的术语“FR H1”、“FR H2”、“FR H3”和“FR H4”根据其在本领域的常用含义使用,并且是指抗体的可变重(H)链的框架区(FR)1、2、3和4。在各实施例中,本文所提供的可变重链在N末端到C末端方向上包含FR H1、FR H2、FR H3和FR H4。
示例性免疫球蛋白(抗体)结构单元包括四聚体。每个四聚体由两对相同的多肽链构成,每对具有一条“轻”链(约25kD)和一条“重”链(约50-70kD)。每条链的N末端限定了约100个到110个或更多个氨基酸的主要负责抗原识别的可变区。术语可变轻链(VL)、可变轻链(VL)结构域或轻链可变区和可变重链(VH)、可变重链(VH)结构域或重链可变区分别是指这些轻链和重链区。如本文所提及的术语可变轻链(VL)、可变轻链(VL)结构域和轻链可变区可以互换使用。如本文所提及的术语可变重链(VH)、可变重链(VH)结构域和重链可变区可以互换使用。Fc(即,片段可结晶区)是免疫球蛋白的“碱基”或“尾部”并且通常由取决于抗体的类别贡献两个或三个恒定结构域的两条重链构成。通过与特异性蛋白结合,Fc区确保每种抗体针对给定抗原产生适当的免疫应答。Fc区还与如Fc受体等各种细胞受体以及如补体蛋白等其它免疫分子结合。
术语“抗体”根据其在本领域的通常已知含义使用。抗体例如以完整的免疫球蛋白或以通过用各种肽酶消化产生的许多充分表征的片段形式存在。因此,例如,胃蛋白酶消化铰链区中二硫键下方的抗体从而产生Fab二聚体F(ab)'
为了制备单克隆或多克隆抗体,可以使用本领域已知的任何技术(参见例如,Kohler和Milstein,《自然》256:495-497(1975);Kozbor等人,《今日免疫学(ImmunologyToday)》4:72(1983);Cole等人,第77-96页,《单克隆抗体与癌症疗法(MonoclonalAntibodies and Cancer Therapy)》(1985))。“单克隆”抗体(mAb)是指源自单个克隆的抗体。用于产生单链抗体的技术(美国专利第4,946,778号)可以适于产生针对本发明的多肽的抗体。而且,转基因小鼠或如其它哺乳动物等其它生物体可以用于表达人源化抗体。可替代地,噬菌体展示技术可以用于鉴定与所选择抗原特异性结合的抗体和异聚Fab片段(参见例如,McCafferty等人,《自然》348:552-554(1990);Marks等人,《生物技术(Biotechnology)》10:779-783(1992))。
单链可变片段(scFv)通常是免疫球蛋白的重链(VH)和轻链(VL)的可变区的融合蛋白,其与10个到约25个氨基酸的短连接子肽连接。连接子通常可以富含甘氨酸用于柔性,以及富含丝氨酸或苏氨酸用于溶解度。连接子也可以将VH的N末端与VL的C末端连接,或反之亦然。
mAb的表位是mAb所结合的抗原区。如果两种抗体各自竞争性地抑制(阻断)另一种抗体与抗原的结合,则所述两种抗体与相同或重叠的表位结合。换言之,一种抗体的1x、5x、10x、20x或100x过量将另一种抗体的结合抑制至少30%,但优选地50%、75%、90%或者甚至99%,如在竞争性结合测定中所测量的(参见例如,Junghans等人,《癌症研究(CancerRes.)》50:1495,1990)。可替代地,如果在抗原中减少或消除一种抗体的结合的基本上所有氨基酸突变减少或消除另一种抗体的结合,则两种抗体具有同一表位。如果减少或消除一种抗体的结合的一些氨基酸突变减少或消除另一种抗体的结合,则两种抗体具有重叠表位。
为了制备本发明的合适抗体和根据本发明的使用,例如重组、单克隆或多克隆抗体,可以使用本领域已知的许多技术(参见例如,Kohler和Milstein,《自然》256:495-497(1975);Kozbor等人,《今日免疫学》4:72(1983);Cole等人,第77-96页,《单克隆抗体与癌症疗法》,Alan R.Liss公司(Alan R.Liss,Inc.)(1985);Coligan,《当代免疫学实验指南(Current Protocols in Immunology)》(1991);Harlow和Lane,《抗体:实验室手册(Antibodies,A Laboratory Manual)》,(1988);以及Goding,《单克隆抗体:原理和实践(Monoclonal Antibodies:Principles and Practice)》(第2版,1986))。编码所关注抗体的重链和轻链的基因可以从细胞中克隆,例如,编码单克隆抗体的基因可以从杂交瘤中克隆并且用于产生重组单克隆抗体。编码单克隆抗体的重链和轻链的基因文库也可以从杂交瘤或浆细胞中制备。重链和轻链基因产物的随机组合产生具有不同抗原特异性的大抗体池(参见例如,Kuby,《免疫学(Immunology)》(第3版1997))。用于产生单链抗体或重组抗体的技术(美国专利4,946,778、美国专利第4,816,567号)可以适于产生针对本发明的多肽的抗体。而且,转基因小鼠或如其它哺乳动物等其它生物体可以用于表达人源化抗体或人抗体(参见例如,美国专利第5,545,807号;第5,545,806号;第5,569,825号;第5,625,126号;第5,633,425号;第5,661,016号,Marks等人,《生物技术》10:779-783(1992);Lonberg等人,《自然》368:856-859(1994);Morrison,《自然》368:812-13(1994);Fishwild等人,《自然生物技术(Nature Biotechnology)》14:845-51(1996);Neuberger,《自然生物技术》14:826(1996);以及Lonberg和Huszar,《国际免疫学评论(Intern.Rev.Immunol.)》13:65-93(1995))。可替代地,噬菌体展示技术可以用于鉴定与所选择抗原特异性结合的抗体和异聚Fab片段(参见例如,McCafferty等人,《自然》348:552-554(1990);Marks等人,《生物技术》10:779-783(1992))。还可以将抗体制备成双特异性的,即,能够识别两种不同的抗原(参见例如,WO 93/08829,Traunecker等人,《欧洲分子生物学学会杂志(EMBO J.)》10:3655-3659(1991);以及Suresh等人,《酶学方法(Methods in Enzymology)》121:210(1986))。抗体也可以是异源缀合物,例如,两种共价连接的抗体或免疫毒素(参见例如,美国专利第4,676,980号、第WO 91/00360号;第WO 92/200373号;以及EP 03089)。
用于使非人抗体人源化或灵长化的方法在本领域中是众所周知的(例如,美国专利第4,816,567号;第5,530,101号;第5,859,205号;第5,585,089号;第5,693,761号;第5,693,762号;第5,777,085号;第6,180,370号;第6,210,671号;和第6,329,511号;第WO 87/02671号;欧洲专利申请0173494;Jones等人(1986)《自然》321:522;以及Verhoyen等人(1988)《科学(Science)》239:1534)。在例如Winter和Milstein(1991)《自然》349:293中进一步描述了人源化抗体。通常,人源化抗体具有从非人的来源引入到其的一个或多个氨基酸残基。这些非人氨基酸残基通常被称为输入(import)残基,所述输入残基通常取自输入可变结构域。人源化可以基本上在Winter和其同事的方法(参见例如,Morrison等人,《美国国家科学院院刊(PNAS USA)》81:6851-6855(1984);Jones等人,《自然》321:522-525(1986);Riechmann等人,《自然》332:323-327(1988);Morrison和Oi,《免疫学进展(Adv.Immunol.)》,44:65-92(1988);Verhoeyen等人,《科学》239:1534-1536(1988)和Presta,《结构生物学的当代观点(Curr.Op.Struct.Biol.)》2:593-596(1992);Padlan,《分子免疫学(Molec.Immun.)》,28:489-498(1991);Padlan,《分子免疫学》,31(3):169-217(1994))之后通过用啮齿动物CDR或CDR序列取代人抗体的对应序列来进行。因此,此类人源化抗体是嵌合抗体(美国专利第4,816,567号),其中已由来自非人物种的对应序列取代基本上少于完整的人可变结构域。在实践中,人源化抗体通常是其中一些CDR残基和可能的一些FR残基被来自啮齿动物抗体中的类似位点的残基取代的人抗体。例如,包括编码人源化免疫球蛋白框架区的第一序列和编码期望免疫球蛋白互补决定区的第二序列集的多核苷酸可以合成地或通过组合适当的cDNA和基因组DNA片段来产生。人恒定区DNA序列可以根据众所周知的程序从多种人细胞中分离。
“嵌合抗体”是抗体分子,其中(a)恒定区或其部分被改变、替代或交换,使得抗原结合位点(可变区)连接到不同或改变的类、效应功能和/或物种、或赋予嵌合抗体新性质的完全不同的分子,例如酶、毒素、激素、生长因子、药物等的恒定区;或(b)可变区或其部分用具有不同或改变的抗原特异性的可变区改变、替代或交换。本发明的并且用于根据本发明使用的优选抗体包含人源化和/或嵌合单克隆抗体。
当提及蛋白质或肽时,短语与抗体“特异性(或选择性)结合”或“特异性(或选择性)免疫反应性”是指决定蛋白质通常在蛋白质和其它生物制剂的异质群体中的存在的结合反应。因此,在指定免疫测定条件下,特定抗体与特定蛋白质的结合是背景的至少两倍,并且更通常是背景的10到100倍以上。在此类条件下,与抗体的特异性结合需要选择对特定蛋白质具有特异性的抗体。例如,可以选择多克隆抗体以仅获得与所选择抗原而不与其它蛋白质发生特异性免疫反应的抗体的子集。这一选择可以通过减去与其它分子交叉反应的抗体来实现。可以使用多种免疫测定方式来选择与特定蛋白进行特异性免疫反应的抗体。例如,常规地使用固相ELISA免疫测定来选择与蛋白质特异性免疫反应的抗体(参见例如,Harlow和Lane,《使用抗体:实验室手册(Using Antibodies,A Laboratory Manual)》(1998),以描述可以用于确定特异性免疫反应性的免疫测定方式和条件)。
“配体”是指能够与受体或抗体、抗体变体、抗体区或其片段结合的药剂,例如多肽或其它分子。
用于将治疗剂与抗体缀合的技术是众所周知的(参见例如,Arnon等人,“用于在癌症疗法中免疫靶向药物的单克隆抗体(Monoclonal Antibodies For Immunotargeting OfDrugs In Cancer Therapy)”,《单克隆抗体与癌症疗法》;Reisfeld等人(编辑),第243-56页(Alan R.Liss公司1985);Hellstrom等人,“用于药物递送的抗体(Antibodies For DrugDelivery)”,《受控药物递送(Controlled Drug Delivery)》(第2版);Robinson等人(编著),第623-53页(马塞尔德克尔公司(Marcel Dekker,Inc.)1987)中;Thorpe,“癌症疗法中细胞毒剂的抗体载体:综述(Antibody Carriers Of Cytotoxic Agents In CancerTherapy:A Review)”,《单克隆抗体'84:生物学和临床应用(Monoclonal Antibodies'84:Biological And Clinical Applications)》;Pinchera等人(编著),第475-506页(1985);以及Thorpe等人,“抗体毒素缀合物的制备和细胞毒性性质(The Preparation AndCytotoxic Properties Of Antibody-Toxin Conjugates)”,《免疫学综述(Immunol.Rev.)》,62:119-58(1982))。如本文所使用的,术语“抗体药物缀合物”或“ADC”是指与抗体缀合或以其它方式共价结合的治疗剂。
如本文所使用的术语“ROR2蛋白”或“ROR2”包含任何重组或天然存在形式的受体酪氨酸激酶样孤儿受体2,也称为酪氨酸蛋白激酶跨膜受体ROR2、神经营养型酪氨酸激酶受体相关2或其维持ROR2活性(例如,与ROR2相比在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的变体或同源物。在一些方面,与天然存在的ROR2蛋白相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在各实施例中,ROR2蛋白与由SEQ ID NO:18鉴定的蛋白质基本上相同。在各实施例中,ROR2蛋白与由UniProt参考编号Q01974鉴定的蛋白质或与其基本上相同的变体或同源物基本上相同。在各实施例中,ROR2蛋白与由UniProt参考编号A1L4F5鉴定的蛋白质或与其基本上相同的变体或同源物基本上相同。在各实施例中,ROR2蛋白与由UniProt参考编号Q8C3W2鉴定的蛋白质或与其基本上相同的变体或同源物基本上相同。
对于本文所描述的特异性蛋白质,所命名蛋白质包含维持蛋白质转录因子活性(例如,与天然蛋白质相比在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的蛋白质的天然存在的形式、变体或同源物中的任何一种。在一些实施例中,与天然存在的形式相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在其它实施例中,蛋白质是通过其NCBI序列参考鉴定的蛋白质。在其它实施例中,蛋白质是通过其NCBI序列参考鉴定的蛋白质、其同源物或功能片段。
术语“基因”意指涉及产生蛋白质的DNA区段;其包含编码区之前和之后的区(前导和尾)以及单个编码区段(外显子)之间的插入序列(内含子)。前导、尾以及内含子包含基因转录和翻译期间必需的调节元素。另外,“蛋白质基因产物”是由特定基因表达的蛋白质。
术语“质粒”、“载体”或“表达载体”是指编码基因和/或基因表达所必需的调节元件的核酸分子。来自质粒的基因表达可以顺式发生或反式发生。如果基因以顺式表达,则基因和调节元件由同一质粒编码。反式表达是指其中基因和调节元件由单独的质粒编码的情况。
术语“转染(transfection)”、“转导(transduction)”、“转染(transfecting)”或“转导(transducing)”可以互换使用并且被定义为将核酸分子或蛋白质引入细胞的过程。使用非病毒或基于病毒的方法将核酸引入细胞。核酸分子可以是编码完整蛋白或其功能部分的基因序列。非病毒转染方法包含不使用病毒DNA或病毒颗粒作为递送系统将核酸分子引入到细胞中的任何适当的转染方法。示例性非病毒转染方法包含磷酸钙转染、脂质体转染、核转染、声孔效应、通过热休克的转染、磁性转染和电穿孔。在一些实施例中,遵循本领域众所周知的标准程序使用电穿孔将核酸分子引入到细胞中。对于基于病毒的转染方法,任何有用的病毒载体可以用于本文所述的方法中。病毒载体的实例包含但不限于逆转录病毒、腺病毒、慢病毒和腺相关病毒载体。在一些实施例中,遵循本领域众所周知的标准程序使用逆转录病毒载体将核酸分子引入到细胞中。术语“转染”或“转导”还指将蛋白质从外部环境引入到细胞中。通常,蛋白质的转导或转染依赖于能够穿过细胞膜的肽或蛋白质与所关注蛋白质的附着。参见例如,Ford等人(2001)《基因疗法(Gene Therapy)》8:1-4和Prochiantz(2007)《自然方法(Nat.Methods)》4:119-20。
“标记”或“可检测部分”是可通过光谱、光化学、生物化学、免疫化学、化学或其它物理手段检测的组合物。例如,有用的标记包含32P、荧光染料、电子致密试剂、酶(例如,如在ELISA中通常使用的)、生物素、地高辛(digoxigenin)或半抗原和蛋白质或可以例如通过将放射性标记掺入到与靶肽特异性反应的肽或抗体中而变得可检测的其它实体。可以使用本领域已知的用于将抗体与标记缀合的任何适当方法,例如使用以下描述的方法:Hermanson,《生物缀合物技术(Bioconjugate Techniques)》1996,圣地亚哥的学术出版社公司(Academic Press,Inc.,San Diego)。
当标记或可检测部分是放射性金属或顺磁性离子时,药剂可以与另一种长尾试剂发生反应,所述另一种长尾试剂具有长尾部,所述长尾部具有附着到长尾部以与这些离子结合的一个或多个螯合基团。长尾部可以是聚合物,如聚赖氨酸、多糖,或具有侧基的其它衍生的链或可衍生链,金属或离子可以被添加到所述侧基上进行结合。根据本公开可以使用的螯合基团的实例包含但不限于乙二胺四乙酸(EDTA)、二乙烯三胺五乙酸(DTPA)、DOTA、NOTA、NETA、TETA、卟啉、聚胺、冠醚、双缩氨基硫脲、聚肟以及类似基团。螯合物通常通过基团与PSMA抗体或功能抗体片段连接,所述基团能够在免疫反应性损失最小并且聚集和/或内部交联最小的情况下与分子形成键。当与本文所述的抗体和载体一起使用时,与非放射性金属,如锰、铁和钆络合的相同螯合物可用于MRI。如NOTA、DOTA和TETA等大环螯合物与各种金属和放射性金属一起使用,所述各种金属和放射性金属分别包含但不限于镓、钇和铜的放射性核素。可以使用对于稳定结合核素感兴趣的其它环型螯合物,如大环聚醚,如用于RAIT的
“接触”根据其普通一般含义使用,并且是指允许至少两个不同的物种(例如,抗体和抗原)变得足够接近以进行反应、相互作用或物理接触的过程。然而,应理解,所得反应产物可以由所添加试剂之间的反应直接产生,或由来自所添加试剂中的一种或多种试剂的可以在反应混合物中产生的中间体产生。
术语“接触”可以包含允许两个物种反应、相互作用或物理接触,其中所述两个物种可以是例如本文所提供的药物化合物和细胞。在各实施例中,接触包含例如允许如本文所描述的药物化合物与细胞相互作用。
如本文所使用的“细胞”是指执行足以保持或复制其基因组DNA的代谢功能或其它功能的细胞。细胞可以通过本领域众所周知的方法来鉴定,包含例如完整膜的存在、通过特定染料染色、产生子代的能力或在配子的情况下与第二配子组合以产生活的后代的能力。细胞可以包含原核细胞和真核细胞。原核细胞包含但不限于细菌。真核细胞包含但不限于酵母细胞和源自植物和动物的细胞,例如哺乳动物细胞、昆虫(例如,夜蛾(spodoptera))细胞和人细胞。
当关于例如细胞、核酸、蛋白质或载体使用时,术语“重组”表示细胞、核酸、蛋白质或载体已经通过引入异源核酸或蛋白质或改变天然核酸或蛋白质而被修饰,或者细胞源自如此修饰的细胞。因此,例如,重组细胞表达在天然(非重组)形式的细胞内未发现的基因,或表达以其它方式异常表达、表达不足或根本不表达的天然基因。转基因细胞和植物是通常由于重组方法而表达异源基因或编码序列的转基因细胞和植物。
当应用于核酸或蛋白质时,术语“分离的”表示所述核酸或蛋白质基本上不含在天然状态下与其缔合的其它细胞组分。例如,其可以处于均匀状态并且可以处于干燥或水溶液中。纯度和均匀性通常使用分析化学技术,如聚丙烯酰胺凝胶电泳或高效液相色谱确定。作为制剂中存在的主要物种的蛋白质是基本上纯化的。
当关于核酸的部分使用时,术语“异源的”表明核酸包括在自然界中未发现彼此之间的相同关系的两个或更多个序列。例如,核酸通常是重组地产生的,具有来自不相关基因的布置成产生新的功能核酸的两个或更多个序列,例如来自一个来源的启动子和来自另一个来源的编码区。类似地,异源蛋白质指示蛋白质包括在自然界中未发现彼此之间的相同关系的两个或更多个子序列(例如,融合蛋白)。
术语“外源的”是指来源于给定细胞或生物体外部的分子或物质(例如,化合物,核酸或蛋白质)。例如,如本文所提及的“外源启动子”是并未来源于其所表达的细胞或生物体的启动子。相反,术语“内源的”或“内源启动子”是指给定细胞或生物体原生的或来源于给定细胞或生物体内的分子或物质。
如本文所定义的,关于细胞增殖(例如,癌细胞增殖)的术语“抑制(inhibition)”、“抑制(inhibit)”、“抑制(inhibiting)”等意指负面影响细胞(例如,减少增殖)或杀伤细胞。在一些实施例中,抑制是指疾病或疾病症状(例如,癌症、癌细胞增殖)的减少。因此,抑制至少部分地包含部分或完全阻断刺激、降低、预防或延迟激活或灭活、脱敏或下调信号转导或酶活性或蛋白质(例如,ROR2蛋白)的量。类似地,“抑制剂”是例如通过结合、部分或全部阻断、降低、预防、延迟、灭活、脱敏或下调活性(例如,受体活性或蛋白活性)来抑制受体或另一种蛋白质的化合物或蛋白质。
如本文所定义的,关于蛋白质抑制剂相互作用的术语“抑制”、“抑制”、“抑制”等意指相对于不存在抑制剂的蛋白质的活性或功能,负面影响(例如,降低)蛋白质(例如,ROR2蛋白)的活性或功能。在各实施例中,抑制意指相对于不存在抑制剂的蛋白质的浓度或水平,负面影响(例如,降低)ROR2的浓度或水平。在各实施例中,抑制是指疾病或疾病症状减少。在各实施例中,抑制是指ROR2的活性降低。因此,抑制至少部分地包含部分或完全阻断刺激、降低、预防或延迟激活或灭活、脱敏或下调信号转导或酶活性或ROR2的量。在各实施例中,抑制是指由直接相互作用(例如,抑制剂与ROR2结合)引起的ROR2的活性降低。在各实施例中,抑制是指由间接相互作用(例如,抑制剂与激活ROR2的蛋白质结合,由此防止靶蛋白激活)的ROR2的活性降低。
因此,可互换的术语“抑制剂(inhibitor)”、“阻遏物(repressor)”或“拮抗剂(antagonist)”或“下调剂(downregulator)”是指能够可检测地降低给定基因或蛋白质(例如,ROR2蛋白)的表达或活性的物质。与在不存在拮抗剂的情况下的对照相比,拮抗剂可以使ROR2表达或活性降低10%、20%、30%、40%、50%、60%、70%、80%、90%或更多。在某些情况下,ROR2表达或活性为不存在拮抗剂的情况下的表达或活性的1/1.5、1/2、1/3、1/4、1/5、1/10或甚至更低。
术语“表达”包含涉及多肽产生的任何步骤,包含但不限于转录、转录后修饰、翻译、翻译后修饰和分泌。可以使用用于检测蛋白质的常规技术(例如,ELISA、蛋白印迹、流式细胞术、免疫荧光、免疫组织化学等)来检测表达。
“生物样品”或“样品”是指获自或源自受试者或患者的材料。生物样品包含组织切片,如活检和尸检样品,以及用于组织学目的的冷冻切片。此类样品包含体液,如血液和血液级分或产物(例如,血清、血浆、血小板、红细胞等)、痰、组织、经培养细胞(例如,原代培养物、外植体以及经转化细胞)、粪便、尿液、滑液组织、关节组织、滑膜组织、滑膜细胞、成纤维细胞样滑膜细胞、巨噬细胞样滑膜细胞、免疫细胞、造血细胞、成纤维细胞、巨噬细胞、T细胞等。生物样品通常获自真核生物体,如哺乳动物,如灵长类动物,例如黑猩猩或人;牛;狗;猫;啮齿动物,例如豚鼠、大鼠、小鼠;兔;或鸟类;爬行动物;或鱼。
“对照”或“标准对照”是指用作参照物,通常是已知参照物,以与测试样品、测量或值进行比较的样品、测量或值。例如,测试样品可以从疑似患有给定疾病(例如,癌症)的患者获取,并且与已知正常(未患病)个体(例如,标准对照受试者)进行比较。标准对照还可以表示从未患有给定疾病的类似个体(例如,标准对照受试者)(例如,具有类似医疗背景、相同年龄、体重等的健康个体)的群体(即,标准对照群体)收集的平均测量或值。标准对照值还可以从同一个体,例如从在疾病发作之前的患者的早前获得的样品获得。例如,可以设计对照,以基于药理学数据(例如,半衰期)或治疗措施(例如,副作用的比较)比较治疗益处。对照物对于确定数据的显著性也很有价值。例如,如果对照物中给定参数的值广泛变化,那么测试样品的变化将不被视为显著的。技术人员将认识到,可以设计标准对照用于评估任何数量的参数(例如,RNA水平、蛋白质水平、特定细胞类型、特定体液、特定组织等)。
本领域的技术人员将理解,在给定情形下哪种标准对照是最适合的,并且能够基于与标准对照值的比较来分析数据。标准对照对于确定数据的显著性(例如,统计显著性)也是有价值的。例如,如果标准对照中给定参数的值广泛变化,那么测试样品的变化将不被视为显著的。
“患者”或“有需要的受试者”是指患有或易于患有可以通过施用如本文所提供的组合物或药物组合物进行治疗的疾病或病状的活生物体。非限制性实例包含人、其它哺乳动物、牛科动物、大鼠、小鼠、狗、猴、山羊、绵羊、牛、鹿和其它非哺乳动物。在一些实施例中,患者是人。
术语“疾病”或“病状”是指能够用本文所提供的化合物或方法治疗的患者或受试者所处的状态或健康状况。所述疾病可以是癌症。所述癌症可以是指实体瘤恶性肿瘤。实体瘤恶性肿瘤包含可能缺乏流体或囊肿的恶性肿瘤。例如,实体瘤恶性肿瘤可以包含乳腺癌、卵巢癌、胰腺癌、宫颈癌、胃癌、肾癌、头颈癌、骨癌、皮肤癌或前列腺癌。在一些另外的实例中,“癌症”是指人癌症和癌、肉瘤、腺癌、淋巴瘤、白血病等,包含实体和淋巴癌、肾癌、乳腺癌、肺癌、膀胱癌、结肠癌、卵巢癌、前列腺癌、胰腺癌、胃癌、脑癌、头颈癌、皮肤癌、子宫癌、睾丸癌、神经胶质瘤、食道癌和肝癌(包含肝癌(hepatocarcinoma))、淋巴瘤(包含B急性淋巴母细胞淋巴瘤、非霍奇金氏淋巴瘤(Non-Hodgkin's Lymphoma)(例如,伯基特氏淋巴瘤(Burkitt's lymphoma)、小细胞淋巴瘤和大细胞淋巴瘤)、霍奇金氏淋巴瘤(Hodgkin'slymphoma))、白血病(包含急性髓性白血病(AML)、ALL和CML)或多发性骨髓瘤。
如本文所使用的,术语“癌症”是指在哺乳动物(例如,人)中发现的所有类型的癌症、赘生物或恶性肿瘤,包含白血病、癌和肉瘤。可以用本文所提供的化合物或方法治疗的示例性癌症包含乳腺癌、结肠癌、肾癌、白血病、肺癌、黑色素瘤、卵巢癌、前列腺癌、胰腺癌、脑癌、肝癌、胃癌或肉瘤。
术语“白血病”广义上是指血液形成器官的渐进性恶性疾病,并且通常特征在于白细胞及其前体在血液和骨髓中的增殖和发育畸变。白血病通常在临床上基于以下进行分类:(1)急性病或慢性病的持续时间和特性;(2)所涉及的细胞的类型;髓性(骨髓性的)、淋巴的(淋巴性的)或单核细胞的;以及(3)异常细胞在血液中的数量的增加或非增加-白血病性或非白血病性(亚白血病性)。可以用本文所提供的化合物或方法治疗的示例性白血病包含例如急性髓性白血病、急性非淋巴细胞白血病、慢性淋巴细胞白血病、急性粒细胞白血病、慢性粒细胞白血病、急性早幼粒细胞白血病、成人T细胞白血病、非白血性白血病(aleukemic leukemia)、白血病性白血病(a leukocythemic leukemia)、嗜碱粒细胞白血病、母细胞白血病、牛白血病、慢性髓细胞性白血病、皮肤白血病、胚胎性白血病、嗜酸性粒细胞白血病、格罗氏白血病(Gross'leukemia)、毛细胞白血病、成血细胞性白血病(hemoblastic leukemia)、成血细胞性白血病(hemocytoblastic leukemia)、组织细胞性白血病、干细胞白血病、急性单核细胞白血病、白细胞减少性白血病、淋巴性白血病、成淋巴细胞性白血病、淋巴细胞性白血病、淋巴球性白血病(lymphogenous leukemia)、淋巴样白血病、淋巴肉瘤细胞白血病、肥大细胞白血病、巨核细胞性白血病、微成髓细胞性白血病(micromyeloblastic leukemia)、单核细胞性白血病、成髓细胞性白血病、髓细胞性白血病、髓样粒细胞性白血病、髓单核细胞白血病、内格利氏白血病(Naegeli leukemia)、浆细胞白血病、多发性骨髓瘤、浆细胞性白血病、早幼粒细胞白血病、里德尔氏细胞白血病(Rieder cell leukemia)、希林氏白血病(Schilling's leukemia)、干细胞白血病、亚白血病性白血病和未分化细胞白血病。
术语“肉瘤”通常是指由类似于胚胎结缔组织的物质组成并且通常由包埋在纤丝状或均质物质中的紧密压积细胞构成的肿瘤。可以用本文所提供的化合物或方法治疗的肉瘤包含软骨肉瘤、纤维肉瘤、淋巴肉瘤、黑色素肉瘤、粘液肉瘤、骨肉瘤、阿贝西氏肉瘤(Abemethy's sarcoma)、脂肉瘤、脂肪肉瘤、腺泡状软组织肉瘤、成釉细胞肉瘤、葡萄样肉瘤、绿色癌肉瘤、绒毛膜癌、胚胎肉瘤、威尔姆斯氏肿瘤肉瘤(Wilms'tumor sarcoma)、子宫内膜肉瘤、间质肉瘤、尤因氏肉瘤(Ewing's sarcoma)、筋膜肉瘤、成纤维细胞肉瘤、巨细胞肉瘤、粒细胞肉瘤、霍奇金氏肉瘤、特发性多发性色素沉着出血性肉瘤、B细胞的免疫母细胞肉瘤、淋巴瘤、T细胞的免疫母细胞肉瘤、詹恩逊氏肉瘤(Jensen's sarcoma)、卡波西氏肉瘤(Kaposi's sarcoma)、库普弗细胞肉瘤(Kupffer cell sarcoma)、血管肉瘤、白血病性肉瘤、恶性间质瘤肉瘤、骨膜外肉瘤、网状细胞肉瘤、劳斯氏肉瘤(Rous sarcoma)、浆液性囊肿肉瘤(serocystic sarcoma)、滑膜肉瘤或毛细血管扩张性肉瘤。
术语“黑色素瘤”意指由皮肤和其它器官的黑色素细胞系统引起的肿瘤。可以用本文所提供的化合物或方法治疗的黑色素瘤包含例如肢端雀斑样痣黑色素瘤、无黑色素性黑色素瘤、良性幼年黑色素瘤、克劳德曼黑色素瘤(Cloudman's melanoma)、S91黑色素瘤、哈丁-帕西黑色素瘤(Harding-Passey melanoma)、青少年黑色素瘤、恶性雀斑样痣、恶性黑色素瘤、结节性黑色素瘤、甲下黑色素瘤或浅表扩散性黑色素瘤。
术语“癌”是指由上皮细胞构成的恶性新生长,所述上皮细胞倾向于浸润周围组织并引起转移。可以用本文所提供的化合物或方法治疗的示例性癌包含例如甲状腺髓样癌、家族性甲状腺髓样癌、腺泡癌、腺泡状癌、腺性囊性癌、腺样囊性癌、腺癌、肾上腺皮质癌、肺泡癌、肺泡细胞癌、基底细胞癌、基底样细胞瘤、基底细胞样癌、基底鳞状细胞癌、细支气管肺泡癌、细支气管癌、支气管癌、脑状癌、胆管细胞癌、绒毛膜癌、胶样癌、粉刺癌、子宫体癌、筛状癌、铠甲状癌、癌疮(carcinoma cutaneum)、柱状癌、柱状细胞癌、管癌、硬癌、胚胎性癌、髓样癌、表皮样癌、腺样上皮细胞癌、外植癌、溃疡性癌(carcinoma ex ulcere)、纤维癌、胶状癌(gelatiniforni carcinoma)、胶样癌(gelatinous carcinoma)、巨大细胞癌、巨细胞癌、腺癌、粒层细胞癌、发母质癌(hair-matrix carcinoma)、多血癌(hematoidcarcinoma)、肝细胞癌、许特尔氏细胞癌(Hurthle cell carcinoma)、玻质状癌(hyalinecarcinoma)、肾上腺样癌、幼稚型胚胎性癌、原位癌、表皮内癌、上皮内癌、克龙派切尔氏癌(Krompecher's carcinoma)、库尔奇茨基细胞癌(Kulchitzky-cell carcinoma)、大细胞癌、豆状癌(lenticular carcinoma)、豆状癌(carcinoma lenticulare)、脂肪瘤癌(lipomatous carcinoma)、淋巴上皮癌、髓样癌(carcinoma medullare)、髓样癌(medullary carcinoma)、黑色素癌、软癌、粘液癌、粘液性癌、粘液细胞癌(carcinomamucocellulare)、粘液表皮样癌、粘液质癌(carcinoma mucosum)、粘液样癌、粘液瘤样癌、鼻咽癌、燕麦细胞癌、骨化性癌(carcinoma ossificans)、骨样癌(osteoid carcinoma)、乳头状癌、门静脉周癌、浸润前癌、棘细胞癌、软糊状癌(pultaceous carcinoma)、肾脏肾细胞癌、储备细胞癌、肉瘤样癌、施奈德癌(schneiderian carcinoma)、硬癌、阴囊癌(carcinomascroti)、印戒细胞癌、单纯癌、小细胞癌、马铃薯状癌、球状细胞癌、梭形细胞癌、髓状癌(carcinoma spongiosum)、鳞状癌、鳞状细胞癌、绳捆癌、血管扩张性癌(carcinomatelangiectaticum)、毛细管扩张癌(carcinoma telangiectodes)、移行细胞癌、块状癌(carcinoma tuberosum)、结节性皮癌(tuberous carcinoma)、疣状癌或绒毛状癌。
如本文所使用的,术语“转移”、“转移性”和“转移性癌症”可互换使用,并且指代增殖性疾病或病症(例如,癌症)从一个器官向另一个不相邻器官或身体部分的扩散。癌症出现在起始部位,例如乳房,这一部位被称为原发性肿瘤,例如原发性乳腺癌。原发性肿瘤或起始部位的一些癌细胞获得了穿透和渗透局部区域周围正常组织的能力和/或穿透通过系统循环到体内的其它部位和组织的淋巴系统或血管系统壁的能力。由原发性肿瘤的癌细胞形成的第二种临床可检测肿瘤被称为转移性或继发性肿瘤。当癌细胞转移时,推测转移性肿瘤及其细胞与原发性肿瘤类似。因此,如果肺癌转移到乳房,则乳房部位的继发性肿瘤由异常肺细胞而非异常乳腺细胞组成。乳房中的继发性肿瘤被称为转移性肺癌。因此,短语转移性癌症是指其中受试者患有或曾经患有原发性肿瘤并患有一种或多种继发性肿瘤的疾病。短语非转移性癌症或患有非转移性癌症的受试者是指其中受试者患有原发性肿瘤但不患有一种或多种继发性肿瘤的疾病。例如,转移性肺癌是指患有原发性肺肿瘤或具有原发性肺肿瘤病史并且具有在第二位置或多个位置(例如,在乳房中)的一种或多种继发性肿瘤的受试者的疾病。
在与疾病(例如,蛋白相关疾病、与ROR2活性相关的癌症、ROR2相关的癌症、ROR2相关的疾病(例如,癌症、炎性疾病、自身免疫性疾病或感染性疾病))相关的物质或物质活性或功能的上下文中,术语“相关”或“与…相关”意指疾病(例如,癌症、炎性疾病、自身免疫性疾病或感染性疾病)是由(全部或部分)物质或物质活性或功能引起的,或疾病症状是由(全部或部分)物质或物质活性或功能引起的。如本文所使用,如果病原体可以是治疗疾病的靶标,则其被描述为与疾病相关。例如,与ROR2活性或功能相关的癌症或ROR2相关的疾病(例如,癌症、炎性疾病、自身免疫性疾病或感染性疾病)可以用ROR2调节剂或ROR2抑制剂治疗,在这种情况下,ROR2活性或功能增加(例如,信号传导途径活性)引起疾病(例如,癌症、炎性疾病、自身免疫性疾病或感染性疾病)。例如,与ROR2活性或功能相关的炎性疾病或ROR2相关的炎性疾病可以用ROR2调节剂或ROR2抑制剂治疗,在这种情况下,ROR2活性或功能增加(例如,信号传导途径活性)引起疾病。
如本文所使用的,术语“信号传导途径”是指细胞与任选的细胞外组分(例如,蛋白质、核酸、小分子、离子、脂质)之间的一系列相互作用,所述相互作用将一个组分中的变化传递给一个或多个其它组分,进而可以将变化传递给另外的组分,所述变化任选地被传播到其它信号传导途径组分。
如本文所使用的,术语“异常”是指与正常不同。当用于描述酶促活性时,异常是指大于或小于正常对照或正常非患病对照样品的平均的活性。异常活性可以指代引起疾病的活性的量,其中使异常活性返回到正常或非疾病相关的量(例如,通过使用如本文所描述的方法)会导致疾病或一种或多种疾病症状减少。
如本文所提及的“治疗剂”是可用于治疗或预防如癌症(例如,白血病)等疾病的组合物。在各实施例中,治疗剂是抗癌剂。“抗癌剂”按照其普通一般含义使用,并且是指具有抗肿瘤性质或抑制细胞生长或增殖的能力的组合物(例如,化合物、药物、拮抗剂、抑制剂、调节剂)。在各实施例中,抗癌剂是化疗剂。在各实施例中,抗癌剂是本文鉴定的在治疗癌症的方法中具有效用的药剂。在各实施例中,抗癌剂是由FDA或除美国以外国家的类似监管机构批准的用于治疗癌症的药剂。
如本文所使用的“抗癌剂”是指用于通过破坏或抑制癌细胞或组织来治疗癌症的分子(例如,化合物、肽、蛋白质、核酸、0103)。抗癌剂对于某些癌症或某些组织可以具有选择性。在各实施例中,本文中的抗癌剂可以包含表观遗传抑制剂和多激酶抑制“抗癌剂”,并且“抗癌剂”按照其普通一般含义使用,并且是指具有抗肿瘤性质或抑制细胞生长或增殖的能力的组合物(例如,化合物、药物、拮抗剂、抑制剂、调节剂)。在一些实施例中,抗癌剂是化疗剂。在一些实施例中,抗癌剂是本文鉴定的在治疗癌症的方法中具有效用的药剂。在一些实施例中,抗癌剂是由FDA或除美国以外国家的类似监管机构批准的用于治疗癌症的药剂。抗癌剂的实例包含但不限于MEK(例如,MEK1、MEK2或MEK1和MEK2)抑制剂(例如,XL518、CI-1040、PD035901、司美替尼(selumetinib)/AZD6244、GSK1120212/曲美替尼(trametinib)、GDC-0973、ARRY-162、ARRY-300、AZD8330、PD0325901、U0126、PD98059、TAK-733、PD318088、AS703026、BAY 869766)、烷基化剂(例如,环磷酰胺、异环磷酰胺、苯丁酸氮芥(chlorambucil)、白消安(busulfan)、美法仑(melphalan)、甲氮芥(mechlorethamine)、尿喃唳氮芥(uramustine)、噻替哌(thiotepa)、亚硝基脲、氮芥(例如,氯乙胺、环磷酰胺、苯丁酸氮芥、美法仑)、亚乙基亚胺和甲基三聚氰胺(例如,六甲基三聚氰胺、噻替哌)、烷基磺酸盐(例如,白消安)、亚硝基脲(例如,卡莫司汀(carmustine)、洛美司汀(lomusitne)、司莫司汀(semustine)、链佐星(streptozocin)、三氮烯(氨烯咪胺(decarbazine))、抗代谢物(例如,5-硫唑嘌呤、亚叶酸、卡培他滨(capecitabine)、氟达拉滨(fludarabine)、吉西他滨(gemcitabine)、培美曲塞(pemetrexed)、雷替曲塞(raltitrexed)、叶酸类似物(例如,甲氨蝶呤)或嘧啶类似物(例如,氟尿嘧啶、氟尿苷(floxouridine)、阿糖胞苷)、嘌呤类似物(例如,巯基嘌呤、硫代鸟嘌呤、喷司他丁(pentostatin)等)、植物生物碱(例如、长春新碱(vincristine)、长春花碱(vinblastine)、长春瑞滨(vinorelbine)、长春地辛(vindesine)、鬼臼毒素(podophyllotoxin)、紫杉醇(paclitaxel)、多西他赛(docetaxel)等)、拓扑异构酶抑制剂(例如,伊立替康(irinotecan)、拓扑替康(topotecan)、安吖啶(amsacrine)、依托泊苷(etoposide)(VP16)、磷酸依托泊苷(etoposide phosphate)、替尼泊苷(teniposide)等)、抗肿瘤抗生素(例如,多柔比星(doxorubicin)、阿霉素(adriamycin)、柔红霉素(daunorubicin)、表柔比星(epirubicin)、放线菌素(actinomycin)、博来霉素(bleomycin)、丝裂霉素(mitomycin)、米托蒽醌(mitoxantrone)、普卡霉素(plicamycin)等)、铂基化合物(例如,顺铂(cisplatin)、奥沙利铂(oxaloplatin)、卡铂(carboplatin))、蒽醌(例如,米托蒽醌)、经取代的尿素(例如,羟基脲)、甲基肼衍生物(例如,丙卡巴肼(procarbazine))、肾上腺皮质激素抑制剂(例如,米托坦(mitotane)、氨鲁米特(aminoglutethimide))、表鬼臼毒素(epipodophyllotoxin)(例如,依托泊苷)、抗生素(例如,柔红霉素、多柔比星、博来霉素)、酶(例如,L-天冬酰胺酶)、促分裂原活化蛋白激酶信号传导的抑制剂(例如,U0126、PD98059、PD184352、PD0325901、ARRY-142886、SB239063、SP600125、BAY 43-9006、渥曼青霉素(wortmannin)或LY294002、Syk抑制剂、mTOR抑制剂、抗体(例如,利妥昔单抗(rituxan))、棉子酚(gossyphol)、更纳森(genasense)、多元酚E、氯夫辛(Chlorofusin)、全反式视黄酸(ATRA)、苔藓抑素、肿瘤坏死因子相关的凋亡诱导配体(TRAIL)、5-氮杂-2'-脱氧胞苷、全反式视黄酸、多柔比星、长春新碱、依托泊苷、吉西他滨、伊马替尼(imatinib)(Gleevec.RTM.)、格尔德霉素(geldanamycin)、17-N-烯丙基氨基-17-去甲氧基格尔德霉素(17-AAG)、夫拉平度(flavopiridol)、LY294002、硼替佐米(bortezomib)、曲妥珠单抗(trastuzumab)、BAY 11-7082、PKC412、PD184352、20-epi-1、25二羟维生素D3;5-乙炔基尿嘧啶;阿比特龙(abiraterone);阿柔比星(aclarubicin);酰基富烯(acylfulvene);腺环戊醇(adecypenol);阿多来新(adozelesin);阿地白介素(aldesleukin);ALL-TK拮抗剂;六甲蜜胺(altretamine);氨莫司汀(ambamustine);阿米多克斯(amidox);氨磷汀(amifostine);氨基乙酰丙酸(aminolevulinic acid);氨柔比星(amrubicin);安吖啶(amsacrine);阿那格雷(anagrelide);阿那曲唑(anastrozole);穿心莲内酯(andrographolide);血管生成抑制剂;拮抗剂D;拮抗剂G;安雷利克斯(antarelix);抗背侧化形态发生蛋白-1;抗雄激素,前列腺癌;抗雌激素;抗瘤酮(antineoplaston);反义寡核苷酸;甘氨酸阿非迪霉素(aphidicolin glycinate);细胞凋亡基因调节剂;细胞凋亡调节剂;脱嘌呤核酸;ara-CDP-DL-PTBA;精氨酸脱氨酶;阿宿拉克林(asulacrine);阿他美坦(atamestane);阿莫司汀(atrimustine);阿西那斯它汀1(axinastatin 1);阿西那斯它汀2(axinastatin 2);阿西那斯它汀3(axinastatin 3);阿扎司琼(azasetron);阿扎脱辛(azatoxin);重氮酪氨酸;浆果赤霉素III衍生物(baccatin III derivative);巴拉诺尔(balanol);巴马司他(batimastat);BCR/ABL拮抗剂;苯并二氢卟吩(benzochlorins);苯甲酰星形孢菌素(benzoylstaurosporine);β内酰胺衍生物;β-阿列辛(beta-alethine);亚阿克拉霉素B(betaclamycin B);桦木酸;bFGF抑制剂;比卡鲁胺(bicalutamide);必桑郡(bisantrene);双吖丙啶基精胺(bisaziridinylspermine);双萘法德(bisnafide);双脱汀尼A(bistratene A);比折来新(bizelesin);布赖氟雷(breflate);溴匹立明(bropirimine);布朵替坦(budotitane);丁胱亚磺酰亚胺(buthionine sulfoximine);钙泊三醇(calcipotriol);钙磷酸蛋白C;喜树碱衍生物;金丝雀痘IL-2(canarypox IL-2);卡培他滨;甲酰胺-氨基-三唑(carboxamide-amino-triazole);羧基胺基三唑(carboxyamidotriazole);CaRest M3;CARN 700;软骨衍生的抑制剂;卡折来新(carzelesin);酪蛋白激酶抑制剂(ICOS);粟树精胺(castanospermine);杀菌肽B(cecropin B);西曲瑞克(cetrorelix);卟酚(chlorins);磺酰胺氯代喹喔啉(chloroquinoxaline sulfonamide);西卡前列素(cicaprost);顺卟啉(cis-porphyrin);克拉屈滨(cladribine);氯米芬类似物;克霉唑(clotrimazole);柯林斯霉菌素A;柯林斯霉菌素B;康普瑞汀A4(combretastatin A4);康普瑞汀类似物;康那格林(conagenin);克拉泊西汀816(crambescidin 816);克立那托(crisnatol);念珠藻素8(cryptophycin 8);念珠藻素A衍生物;克由若辛A(curacin A);环戊蒽醌(cyclopentanthraquinones);环钼(cycloplatam);环青霉素(cypemycin);阿糖胞苷烷磷酯(cytarabine ocfosfate);溶细胞因子;磷酸己烷雌酚(cytostatin);达昔单抗(dacliximab);地西他滨(decitabine);脱氢膜海鞘素B(dehydrodidemnin B);德舍瑞林(deslorelin);地塞米松(dexamethasone);第西佛斯米(dexifosfamide);右雷佐生(dexrazoxane);右维拉帕米(dexverapamil);亚丝醌(diaziquone);膜海鞘素B(didemnin B);第多克斯(didox);二乙基去甲精胺;二氢-5-氮杂胞苷;9-二氧杂霉菌素;联苯螺莫司汀;二十二醇;多拉司琼(dolasetron);去氧氟尿苷(doxifluridine);屈洛昔芬(droloxifene);屈大麻酚(dronabinol);多卡米辛SA(duocarmycin SA);依布硒啉(ebselen);依考莫司汀(ecomustine);依地福新(edelfosine);依决可单抗(edrecolomab);依氟鸟氨酸(eflornithine);榄香烯(elemene);乙嘧替氟(emitefur);表柔比星;爱普列特(epristeride);雌莫司汀(estramustine)类似物;雌激素(estrogen)激动剂;雌激素拮抗剂;依他硝唑(etanidazole);磷酸依托泊苷(etoposide phosphate);依西美坦(exemestane);法倔唑(fadrozole);法扎拉滨(fazarabine);芬维A胺(fenretinide);非格司亭(filgrastim);非那雄胺(finasteride);氟拉沃匹瑞多(flavopiridol);氟卓斯汀(flezelastine);福噜斯特酮(fluasterone);氟达拉滨;氟代柔红霉素盐酸盐;福酚美克(forfenimex);福美司坦(formestane);福司曲星(fostriecin);福莫司汀(fotemustine);钆替沙林(gadoliniumtexaphyrin);硝酸镓;加洛他滨(galocitabine);加尼瑞克(ganirelix);白明胶酶抑制剂(gelatinase inhibitor);吉西他滨;谷胱甘肽抑制剂;合普素凡(hepsulfam);调蛋白(heregulin);六亚甲基二乙酰胺(hexamethylene bisacetamide);金丝桃素(hypericin);伊班膦酸(ibandronic acid);伊达比星(idarubicin);艾多昔芬(idoxifene);伊决孟酮(idramantone);伊莫福新(ilmofosine);伊洛马司他(ilomastat);咪唑并吖啶酮(imidazoacridones);咪喹莫特(imiquimod);免疫增强药肽;胰岛素样生长因子-1受体抑制剂;干扰素激动剂;干扰素;白介素;碘苄胍;碘多柔比星(iododoxorubicin);甘薯黑斑霉醇(ipomeanol),4-;伊罗普拉;伊索拉定;异本伽唑(isobengazole);异高软海绵素B(isohomohalicondrin B);伊他司琼(itasetron);亚普拉可诺林(jasplakinolide);卡哈拉莱F(kahalalide F);三乙酸片螺素N(lamellarin-N triacetate);兰瑞肽(lanreotide);莱那米辛(leinamycin);来格司亭(lenograstim);硫酸香菇多糖(lentinansulfate);莱普妥斯新(leptolstatin);来曲唑(letrozole);白血病抑制因子;白细胞干扰素α;亮丙瑞林+雌性激素+黄体酮;抑那通(leuprorelin);左旋咪唑;利阿唑;线性聚胺类似物;亲脂性二糖肽;亲脂性铂化合物;例索克林安7(lissoclinamide 7);洛铂(lobaplatin);蚯蚓磷脂(lombricine);洛美曲索(lometrexol);氯尼达明(lonidamine);洛索蒽醌(losoxantrone);洛伐他汀(lovastatin);洛索立宾(loxoribine);勒托替康(lurtotecan);特可萨啡林镏(lutetium texaphyrin);力索啡林(lysofylline);裂解肽;美坦辛(maitansine);吗诺斯它汀A(mannostatin A);马立马司他(marimastat);马索罗酚(masoprocol);乳腺丝抑蛋白(maspin);基质溶解因子抑制剂;基质金属蛋白酶抑制剂;美诺立尔(menogaril);美巴伦(merbarone);美特莱林(meterelin);甲硫氨酸酶;胃复安(metoclopramide);MIF抑制剂;米非司酮(mifepristone);米替福新(miltefosine);米立司亭(mirimostim);错配的双链RNA;米托胍腙(mitoguazone);二溴卫矛醇(mitolactol);丝裂霉素类似物;米托萘胺(mitonafide);丝裂毒素成纤维细胞生长因子——皂草素;米托蒽醌;莫法罗汀(mofarotene);莫格拉莫斯提(molgramostim);单克隆抗体、人绒毛膜促性腺激素;单磷酰脂质A+分枝杆菌细胞壁sk;莫哌达醇(mopidamol);多重耐药基因抑制剂;基于多肿瘤抑制剂1的疗法;芥末抗癌剂(mustard anticancer agent);米卡泊氧化物B(mycaperoxide B);分枝杆菌细胞壁提取物;密瑞泊伦(myriaporone);N-乙酰基地那林(N-acetyldinaline);N取代的苯甲酰胺;那法瑞林(nafarelin);那格瑞斯第(nagrestip);纳洛酮+戊唑辛(naloxone+pentazocine);纳帕林(napavin);纳啡特品(naphterpin);那托司亭(nartograstim);奈达铂(nedaplatin);奈莫柔比星(nemorubicin);奈立膦酸(neridronic acid);中性肽链内切酶(neutral endopeptidase);尼鲁米特(nilutamide);尼萨米辛(nisamycin);一氧化氮调节剂;硝基氧抗氧化剂;尼图林(nitrullyn);O6-苄基鸟嘌呤;奥曲肽(octreotide);奥可森诺(okicenone);寡核苷酸;奥那司酮;昂丹司琼(ondansetron);昂丹司琼;奥罗新(oracin);口服细胞因子诱导剂;奥马铂(ormaplatin);奥沙特隆(osaterone);奥沙利铂(oxaliplatin);奥克萨霉素(oxaunomycin);帕劳霉素(palauamine);棕榈酰根瘤菌素(palmitoylrhizoxin);帕米膦酸(pamidronic acid);人参炔三醇(panaxytriol);帕诺米芬(panomifene);帕拉巴汀(parabactin);泊泽尼普定(pazelliptine);培门冬酶;培地辛(peldesine);木聚硫钠(pentosan polysulfatesodium);喷司他丁;朋脱若唑(pentrozole);全氟溴烷(perflubron);培磷酰胺(perfosfamide);紫苏醇(perillyl alcohol);芬那兹诺辛(phenazinomycin);乙酸苯酯;磷酸酶抑制剂;毕西巴尼(picibanil);盐酸毛果芸香碱(pilocarpine hydrochloride);吡柔比星(pirarubicin);吡曲克辛(piritrexim);普莱斯汀A(placetin A);普拉斯汀B;纤溶酶原激活物抑制剂(plasminogen activator inhibitor);铂复合物;铂化合物;铂-三胺复合物;卟吩姆钠(porfimer sodium);甲基丝裂霉素(porfiromycin);强的松(prednisone);丙基双茚酮(propyl bis-acridone);前列腺素J2(prostaglandin J2);蛋白酶体抑制剂;基于蛋白A的免疫调节剂;蛋白激酶C抑制剂;蛋白激酶C抑制剂、微藻;蛋白质酪氨酸磷酸酶抑制剂;嘌呤核苷磷酸化酶抑制剂;红紫素(purpurins);吡唑吖啶(pyrazoloacridine);吡哆酸化血红蛋白聚氧乙烯缀合物;raf拮抗剂;雷替曲塞(raltitrexed);雷莫司琼(ramosetron);ras法尼斯基蛋白转移酶抑制剂;ras抑制剂;ras-GAP抑制剂;脱甲基化瑞替普汀(retelliptine demethylated);依替膦酸铼Re 186(rhenium Re 186etidronate);根霉素(rhizoxin);酶性核酸(ribozymes);RII维甲酰胺(RII retinamide);罗谷亚胺(rogletimide);罗希吐碱(rohitukine);罗莫肽(romurtide);罗喹美克(roquinimex);噜必吉诺B1(rubiginone B1);噜泊基(ruboxyl);沙芬戈(safingol);萨因脱匹(saintopin);SarCNU;萨考啡脱A(sarcophytol A);沙格司亭(sargramostim);Sdi 1模拟物;司莫司汀;衰老衍生的抑制剂1;正义寡核苷酸;信号转导抑制剂;信号转导调节剂;单链抗原结合蛋白;西佐喃(sizofuran);索布佐生(sobuzoxane);硼卡钠(sodium borocaptate);苯基乙酸钠(sodium phenylacetate);索沃绕(solverol);生长调节素结合蛋白;索纳明(sonermin);斯帕磷酸(sparfosic acid);霉素D(spicamycin D);螺莫司汀(spiromustine);斯耐潘定(splenopentin);软海绵素1;角鲨胺(squalamine);干细胞抑制剂;干细胞分裂抑制剂;斯第匹氨(stipiamide);溶基质素抑制剂;素飞诺辛(sulfinosine);超活性血管活性肠肽拮抗剂;苏拉第斯塔(suradista);苏拉明(suramin);苦马豆素(swainsonine);合成粘多糖(synthetic glycosaminoglycans);他莫司汀(tallimustine);他莫昔芬甲碘化物(tamoxifen methiodide);牛磺莫司汀(tauromustine);他扎罗汀(tazarotene);替可加兰钠(tecogalan sodium);喃氟啶(tegafur);呔鲁拉利(tellurapyrylium);端粒酶抑制剂;替莫卟吩(temoporfin);替莫唑胺(temozolomide);替尼泊苷(teniposide);四氯十氧化物(tetrachlorodecaoxide);四唑胺(tetrazomine);萨力巴拉斯汀(thaliblastine);西奥考拉林(thiocoraline);促血小板生成素;促血小板生成素模拟物;胸腺法新(thymalfasin);促胸腺生成素受体激动剂;胸腺曲南(thymotrinan);促甲状腺激素(thyroid stimulating hormone);乙基初卟啉锡(tinethyl etiopurpurin);替拉扎明(tirapazamine);二氯二茂钛(titanocene bichloride);脱普森汀(topsentin);托瑞米芬(toremifene);全能干细胞因子;翻译抑制剂;维甲酸(tretinoin);三乙酰尿苷(triacetyluridine);曲西立滨(triciribine);三甲曲沙(trimetrexate);曲普瑞林(triptorelin);托烷司琼(tropisetron);妥罗雄脲(turosteride);酪氨酸激酶抑制剂;酪氨酸磷酸化抑制剂(tyrphostin);UBC抑制剂;乌苯美司(ubenimex);泌尿生殖窦源性生长抑制因子;尿激酶受体拮抗剂;伐普肽(vapreotide);瓦瑞奥林B(variolin B);载体系统、红细胞基因疗法;维拉雷琐(velaresol);藜芦胺(veramine);维尔丁斯(verdins);维替泊芬(verteporfin);长春瑞滨;长春花碱;维他辛(vitaxin);伏氯唑(vorozole);扎诺特隆(zanoterone);折尼铂(zeniplatin);亚苄维C(zilascorb);净司他丁斯酯(zinostatin stimalamer)、阿霉素、更生霉素(Dactinomycin)、博来霉素、长春花碱、顺铂、阿西维辛(acivicin);阿柔比星;盐酸阿可达佐(acodazole hydrochloride);阿克罗宁(acronine);阿多来新;阿地白介素;六甲蜜胺;安波霉素(ambomycin);醋酸阿美坦醌(ametantrone acetate);氨鲁米特;安吖啶;阿那曲唑;氨茴霉素(anthramycin);天冬酰胺酶;曲林菌素(asperlin);阿扎胞苷(azacitidine);阿扎替派(azetepa);阿佐霉素(azotomycin);巴马司他;苄替哌(benzodepa);比卡鲁胺;盐酸必桑郡(bisantrene hydrochloride);二甲磺酸双奈法德(bisnafide dimesylate);比折来新;硫酸博来霉素(bleomycin sulfate);布喹那钠(brequinar sodium);溴匹立明;白消安;放线菌素(cactinomycin);卡普睾酮(calusterone);卡醋胺(caracemide);卡贝替姆(carbetimer);卡铂;卡莫司汀;盐酸卡米诺霉素(carubicin hydrochloride);卡折来新;西地芬戈(cedefingol);瘤可宁(chlorambucil);西罗霉素(cirolemycin);克拉屈滨;甲磺酸克立那托(crisnatolmesylate);环磷酰胺;阿糖胞苷;达卡巴嗪;盐酸柔红霉素(daunorubicinhydrochloride);地西他滨;右奥马铂(dexormaplatin);地扎胍宁(dezaguanine);甲磺酸地扎胍宁(dezaguanine mesylate);亚丝醌;多柔比星;盐酸多柔比星;屈洛昔芬;柠檬酸屈洛昔芬(droloxifene citrate);丙酸屈他雄酮(dromostanolone propionate);达佐霉素(duazomycin);依达曲沙(edatrexate);盐酸依氟鸟氨酸(eflornithine hydrochloride);依沙芦星(elsamitrucin);恩洛铂(enloplatin);恩普氨酯(enpromate);依匹哌啶(epipropidine);盐酸表柔比星(epirubicin hydrochloride);厄布洛唑(erbulozole);盐酸依索比星(esorubicin hydrochloride);雌莫司汀;雌莫司汀磷酸钠;依他硝唑;依托泊苷;磷酸依托泊苷;艾托卜宁(etoprine);盐酸法屈唑(fadrozole hydrochloride);法扎拉滨;芬维A胺;氟尿苷;磷酸氟达拉滨(fludarabine phosphate);氟尿嘧啶;氟环胞苷(fluorocitabine)磷喹酮(fosquidone);福司曲星钠(fostriecin sodium);吉西他滨;盐酸吉西他滨(gemcitabine hydrochloride);羟基脲;盐酸伊达比星(idarubicinhydrochloride);异环磷酰胺;伊莫拉明(iimofosine);白介素I1(包含重组白介素II,或rlL.sub.2),干扰素α-2a;干扰素α-2b;干扰素α-n1;干扰素α-n3;干扰素β-1a;干扰素γ-1b;异丙铂(iproplatin);盐酸伊立替康(irinotecan hydrochloride);醋酸兰瑞肽(lanreotide acetate);来曲唑;醋酸亮丙瑞林;盐酸利阿唑(liarozole hydrochloride);洛美曲索钠(lometrexol sodium);洛莫司汀(lomustine);盐酸洛索蒽醌(losoxantronehydrochloride);马索罗酚;美登素(maytansine);盐酸氮芥(mechlorethaminehydrochloride);醋酸甲地孕酮(megestrol acetate);醋酸美仑孕酮(melengestrolacetate);美法仑;美诺立尔;巯基嘌呤;甲氨蝶呤;甲氨蝶呤钠;氯苯氨啶(metoprine);美妥替哌(meturedepa);米丁度胺(mitindomide);米托卡星(mitocarcin);密脱克罗明(mitocromin);丝裂菌褶素(mitogillin);丝裂马菌素(mitomalcin);丝裂霉素;米托司培(mitosper);米托坦;盐酸米托蒽醌(mitoxantrone hydrochloride);霉酚酸(mycophenolic acid);诺考达唑(nocodazoie);诺加霉素(nogalamycin);奥马铂;奥昔舒仑(oxisuran);培门冬酶;培利霉素(peliomycin);戊氮芥(pentamustine);硫酸培洛霉素(peplomycin sulfate);培磷酰胺;哌泊溴烷;哌泊舒凡(piposulfan);盐酸吡罗蒽醌(piroxantrone hydrochloride);普卡霉素(plicamycin);普洛美坦(plomestane);卟吩姆钠;甲基丝裂霉素;泼尼莫司汀;盐酸丙卡巴肼(procarbazine hydrochloride);嘌呤霉素(puromycin);盐酸嘌呤霉素(puromycin hydrochloride);吡唑霉素(pyrazofurin);利波腺苷(riboprine);罗谷亚胺;沙芬戈;盐酸沙芬戈(safingol hydrochloride);司莫司汀;辛曲秦(simtrazene);磷乙酰天冬氨酸钠(sparfosate sodium);司帕霉素(sparsomycin);盐酸螺旋锗(spirogermanium hydrochloride);螺莫司汀;螺铂(spiroplatin);链黑菌素(streptonigrin);链脲菌素(streptozocin);磺氯苯脲(sulofenur);他利霉素(talisomycin);替可加兰钠;喃氟啶;盐酸替洛蒽醌(teloxantrone hydrochloride);替莫卟吩;替尼泊苷;替罗昔隆(teroxirone);睾内酯(testolactone);硫咪嘌呤(thiamiprine);硫鸟嘌呤(thioguanine);噻替派;噻唑羧胺核苷(tiazofurin);替拉扎明;枸橼酸托瑞米芬(toremifene citrate);醋酸曲托龙(trestolone acetate);磷酸曲西瑞宾(triciribine phosphate);三甲曲沙;葡萄糖醛酸三甲曲沙(trimetrexateglucuronate);曲普瑞林;盐酸妥布氯唑(tubulozole hydrochloride);乌拉莫司汀(uracil mustard);乌瑞替派(uredepa);伐普肽;维替泊芬;硫酸长春碱;硫酸长春新碱;长春地辛;硫酸长春地辛;硫酸长春匹定;硫酸长春甘酯(vinglycinate sulfate);硫酸长春罗新(vinleurosine sulfate);酒石酸长春瑞滨(vinorelbine tartrate);硫酸长春罗定(vinrosidine sulfate);硫酸长春利定(vinzolidine sulfate);伏氯唑;折尼铂;净司他丁(zinostatin);盐酸佐柔比星(zorubicin hydrochloride)、将细胞阻止在G2-M期和/或调节微管的形成或稳定性的药剂(例如,Taxol.TM(即,紫杉醇)、Taxotere.TM、包括紫杉烷骨架的化合物、Erbulozole(即,R-55104)、尾海兔素10(即,DLS-10和NSC-376128)、羟乙基磺酸米伏布尔(Mivobulin isethionate)(即,如CI-980)、长春新碱、NSC-639829、圆皮海绵内酯(Discodermolide)(即,如NVP-XX-A-296)、ABT-751(雅培(Abbott),即,E-7010)、奥图来尔亭(Altorhyrtin)(例如,奥图来尔亭A和奥图来尔亭C)、海绵抑制素(Spongistatin)(例如,海绵抑制素1、海绵抑制素2、海绵抑制素3、海绵抑制素4、海绵抑制素5、海绵抑制素6、海绵抑制素7、海绵抑制素8和S海绵抑制素9)、盐酸西马多丁(Cemadotinhydrochloride)(即,LU-103793和NSC-D-669356)、埃博霉素(Epothilone)(例如,埃博霉素A、埃博霉素B、埃博霉素C(即,脱氧埃博霉素A或dEpoA)、埃博霉素D(即,KOS-862、dEpoB和脱氧埃博霉素B)、埃博霉素E、埃博霉素F、埃博霉素B N-氧化物、埃博霉素A N-氧化物、16-氮杂-埃博霉素B、21-氨基埃博霉素B(即,BMS-310705)、21-羟基埃博霉素D(即,脱氧埃博霉素F和dEpoF)、26-氟埃博霉素、澳瑞他汀(Auristati)PE(即,NSC-654663)、索利多亭(Soblidotin)(即,TZT-1027)、LS-4559-P(法玛西亚(Pharmacia),即,LS-4577)、LS-4578(法玛西亚,即,LS-477-P)、LS-4477(法玛西亚)、LS-4559(法玛西亚)、RPR-112378(安内特(Aventis))、硫酸长春新碱、DZ-3358(第一制药(Daiichi))、FR-182877(藤泽(Fujisawa),即,WS-9885B)、GS-164(武田(Takeda))、GS-198(武田)、KAR-2(匈牙利科学院(HungarianAcademy of Sciences))、BSF-223651((巴斯夫)BASF,即,ILX-651和LU-223651)、SAH-49960(礼来/诺华(Lilly/Novartis))、SDZ-268970(礼来/诺华)、AM-97(阿马德/协和发酵(Armad/Kyowa Hakko))、AM-132(阿马德)、AM-138(阿马德/协和发酵)、IDN-5005(意迪那(Indena))、念珠藻素52(即,LY-355703)、AC-7739(味之素(Ajinomoto),即,AVE-8063A和CS-39.HCl)、AC-7700(味之素,即,AVE-8062、AVE-8062A、CS-39-L-Ser.HCl和RPR-258062A)、维替乐维酰胺(Vitilevuamide)、妥布赖森(Tubulysin)A、卡纳登索(Canadensol)、矢车菊黄素(Centaureidin)(即,NSC-106969)、T-138067(杜拉瑞克(Tularik),即,T-67、TL-138067和TI-138067)、COBRA-1(派克休斯研究所(Parker HughesInstitute),即,DDE-261和WHI-261)、H10(堪萨斯州立大学)、H16(堪萨斯州立大学)、奥克西丁(Oncocidin)A1(即,BTO-956和DIME)、DDE-313(派克休斯研究所)、斐吉诺莱(Fijianolide)B、莱利霉素(Laulimalide)、SPA-2(派克休斯研究所)、SPA-1(派克休斯研究所,即,SPIKET-P)、3-IAABU(细胞骨架/西奈山伊坎医学院(Cytoskeleton/Mt.SinaiSchool of Medicine),即,MF-569)、纳可辛(Narcosine)(也被称为NSC-5366)、纳司卡滨(Nascapine)D-24851(爱斯达制药(Asta Medica))、A-105972(雅培)、哈米特林(Hemiasterlin)、3-BAABU(细胞骨架/西奈山伊坎医学院,即,MF-191)、TMPN(亚利桑那州立大学)、双钒乙酰丙酮(Vanadocene acetylacetonate)、T-138026(杜拉瑞克)、莫那撒尔(Monsatrol)、依那斯纳(lnanocine)(即,NSC-698666)、3-IAABE(细胞骨架/西奈山伊坎医学院)、A-204197(雅培)、T-607(图拉里克(Tuiarik),即,T-900607)、RPR-115781(安内特)、伊斯罗宾(Eleutherobin)(如脱甲基伊斯罗宾(Desmethyleleutherobin)、脱乙酸基伊斯罗宾(Desaetyleleutherobin)、异伊斯罗宾(lsoeleutherobin)A和Z-伊斯罗宾)、卡巴斯德(Caribaeoside)、卡利贝林(Caribaeolin)、软海绵素(Halichondrin)B、D-64131(爱斯达制药)、D-68144(爱斯达制药)、含氯环肽(Diazonamide)A、A-293620(雅培)、NPI-2350(涅柔斯(Nereus))、根薯酮内酯(Taccalonolide)A、TUB-245(安内特)、A-259754(雅培)、第在斯汀(Diozostatin)、(-)-苯基阿斯丁(Phenylahistin)(即,NSCL-96F037)、D-68838(爱斯达制药)、D-68836(爱斯达制药)、肌基质蛋白(Myoseverin)B、D-43411(Zentaris公司,即,D-81862)、A-289099(雅培)、A-318315(雅培)、HTI-286(即,SPA-110,三氟乙酸盐(trifluoroacetate salt))(惠氏公司(Wyeth))、D-82317(Zentaris公司)、D-82318(Zentaris公司)、SC-12983(NCI)、瑞瓦斯汀磷酸钠(Resverastatin phosphate sodium)、BPR-OY-007(卫生研究院)和SSR-250411(赛诺菲(Sanofi)))、类固醇(例如,地塞米松)、非那雄胺(finasteride)、芳香酶抑制剂、如戈舍瑞林(goserelin)或亮丙瑞林(leuprolide)等促性腺激素释放素激动剂(GnRH)、肾上腺皮质类固醇(例如,强的松)、孕酮(例如,己酸羟孕酮(hydroxyprogesterone caproate)、醋酸甲地孕酮、醋酸甲羟孕酮(medroxyprogesterone acetate))、雌激素(例如,二乙基己烯雌酚(diethlystilbestrol)、乙炔雌二醇(ethinyl estradiol))、抗雌激素(例如,三苯氧胺(tamoxifen))、雄激素(例如,丙酸睾酮(testosterone propionate)、氟甲睾酮(fluoxymesterone))、抗雄激素(例如,氟他胺(flutamide))、免疫刺激剂(例如,卡介苗(Bacillus Calmette-Guérin,BCG)、左旋咪唑、白介素-2、α-干扰素等)、单克隆抗体(例如,抗CD20、抗HER2、抗CD52、抗HLA-DR和抗VEGF单克隆抗体)、免疫毒素(例如,抗CD33单克隆抗体-加利车霉素缀合物、抗CD22单克隆抗体-假单胞菌外毒素缀合物等)、放射免疫疗法(例如,与
如本文所使用的,“治疗(treating)”或“治疗(treatment of)”病状、疾病或病症或与病状、疾病或病症相关的症状是指用于获得有益或期望结果(包含临床结果)的方法。有益或期望的临床结果可以包含但不限于减轻或改善一种或多种症状或病状;减轻病状、病症或疾病的程度;稳定病状、病症或疾病的状态;预防病状、病症或疾病的发展;预防病状、病症或疾病的传播;延缓或减缓病状、病症或疾病进展;延缓或减缓病状、病症或疾病发作;改善或缓和病状、病症或疾病状态;以及缓解,无论是部分的还是全部的。“治疗”还可以意指延长受试者的存活超过不存在治疗的情况下的预期存活。“治疗”还可以意指抑制病状、病症或疾病的进展,暂时减缓病状、病症或疾病的进展,尽管在一些实例中,其涉及永久地停止病状、病症或疾病的进展。本文所使用的术语治疗(treatment、treat或treating)是指降低以蛋白酶表达为特征的疾病或病状的一种或多种症状的影响或以蛋白酶表达为特征的疾病或病状的症状的影响的方法。因此,在所公开的方法中,治疗可以是指已确定的疾病、病状或疾病或病状的症状的严重程度降低10%、20%、30%、40%、50%、60%、70%、80%、90%或100%。例如,如果与对照相比,受试者的疾病的一种或多种症状减少10%,则用于治疗疾病的方法被认为是治疗。因此,与天然或对照水平相比,减少可以是10%、20%、30%、40%、50%、60%、70%、80%、90%、100%或介于10%与100%之间的任何百分比减少。应理解,治疗并不一定是指治愈或完全消除疾病、病状、或疾病或病状的症状。另外,如本文所使用的,与对照水平相比,提及降低、减少或抑制包含10%、20%、30%、40%、50%、60%、70%、80%、90%或更大的变化,并且这些术语可以包含但不一定包含完全消除。
术语“剂量(dose)”和“剂量(dosage)”在本文中可互换地使用。剂量是指每次施用时给予个体的活性成分的量。剂量将取决于多种因素而变化,所述因素包含给定疗法的正常剂量范围、施用频率;个体的大小和耐受性;病状的严重程度;副作用的风险;以及施用途径。技术人员将认识到,剂量可以取决于上述因素或基于治疗进展而修改。术语“剂型”是指药物或药物组合物的特定形式,并且取决于施用途径。例如,剂型可以呈用于雾化的液体形式,例如用于吸入剂,呈片剂或液体形式,例如用于口服递送,或盐溶液,例如用于注射。
如本文所使用的“治疗有效剂量或量”是指产生施用其的效果的剂量(例如,治疗或预防疾病)。精确剂量和调配物将取决于治疗的目的,并且将可由本领域的技术人员使用已知的技术确定(参见例如,Lieberman,《医药剂型(Pharmaceutical Dosage Forms)》(第1-3卷,1992);Lloyd,《医药学配混的艺术、科学和技术(The Art,Science and Technologyof Pharmaceutical Compounding)》(1999);《雷明顿:药学的科学与实践(Remington:TheScience and Practice of Pharmacy)》,第20版,编辑Gennaro,(2003);以及Pickar,《剂量计算(Dosage Calculations)》(1999))。例如,对于给定参数,治疗有效量将显示增加或降低至少5%、10%、15%、20%、25%、40%、50%、60%、75%、80%、90%或至少100%。治疗功效也可以表示为“倍数”增加或减少。例如,治疗有效量的效果可以是标准对照的效果的至少1.2倍、1.5倍、2倍、5倍或更多倍。治疗有效剂量或量可以改善疾病的一种或多种症状。当施用治疗有效剂量或量的效果是治疗处于发展疾病的风险的人时,治疗有效量或量可以预防或延缓疾病或疾病的一种或多种症状的发作。
如本文所使用的,术语“施用”意指向受试者口服施用、以栓剂形式施用、局部接触、静脉内、腹膜内、肌肉内、病灶内、鞘内、鼻内或皮下施用,或植入缓慢释放装置,例如,微型渗透泵。通过任何途径进行施用,包含肠胃外和经粘膜(例如,颊、舌下、腭、牙龈、鼻、阴道、直肠或经皮)。肠胃外施用包含例如静脉内、肌肉内、动脉内、皮内、皮下、腹膜内、心室内和颅内施用。其它递送模式包含但不限于使用脂质体调配物、静脉内输注、经皮贴片等。“共施用”意指本文所描述的组合物在施用一种或多种另外疗法,例如,如化学疗法、激素疗法、放射疗法或免疫疗法等癌症疗法的同时、恰好在其之前或恰好在其之后施用。本发明的化合物可以单独施用或可以共施用于患者。共施用旨在包含化合物单独地或以组合形式(多于一种化合物)同时或依序施用。因此,制剂还可以在需要时与其它活性物质组合(例如,以减少代谢性降解)。本发明的组合物可以通过局部途径,调配成涂抹棒、溶液、悬浮液、乳液、凝胶、乳膏、软膏、糊剂、果冻、油漆、粉末和气雾剂,经皮递送。
本发明的组合物可以另外地包含提供持续释放和/或舒适性的组分。此类组分包含高分子量、阴离子类粘液状聚合物、胶凝多糖和精细分散的药物载体底物。在美国专利第4,911,920号;第5,403,841号;第5,212,162号;和第4,861,760号中更详细地讨论了这些组分。这些专利的全部内容出于所有目通过引用全文并入本文。本发明的组合物也可以以微球的形式递送以在体内缓慢释放。例如,可以通过皮内注射含药物的微球来施用微球,所述微球在皮下缓慢释放(参见Rao,《生物材料科学杂志聚合物版(J.BiomaterSci.Polym.Ed.)》7:623-645,1995;以可生物降解和可注射凝胶调配物的形式(参见例如,Gao《药学研究(Pharm.Res.)》12:857-863,1995);或以微球的形式以供口服施用(参见例如,Eyles,《药学和药理学杂志(J.Pharm.Pharmacol.)》49:669-674,1997)。在各实施例中,本发明的组合物的调配物可以通过使用与细胞膜融合或被内吞的脂质体来递送,即,通过使用附着到脂质体的受体配体,所述受体配体与细胞的表面膜蛋白受体结合从而导致内吞。通过使用脂质体,特别是在脂质体表面携带对靶细胞具有特异性或以其它方式优先针对特定器官的受体配体的情况下,可以集中本发明的组合物在体内递送到靶细胞中。(参见例如,Al-Muhammed,《微包封杂志(J.Microencapsul.)》13:293-306,1996;Chonn,《生物技术当前述评(Curr.Opin.Biotechnol.)》6:698-708,1995;Ostro,《美国医院药学杂志(Am.J.Hosp.Pharm.)》46:1576-1587,1989)。本发明的组合物也可以作为纳米颗粒递送。
如本文所使用的,术语“药学上可接受的”与“生理上可接受的”和“药理学上可接受的”同义地使用。药物组合物通常将包括用于缓冲和在储存中保存的药剂,并且可以包含用于适当递送的缓冲液和载体,这取决于施用途径。
“药学上可接受的赋形剂”和“药学上可接受的载体”是指有助于向受试者施用活性剂并且有助于受试者吸收的物质,并且所述物质可以包含在本发明的组合物中而不会对患者引起显著不良的毒性作用。药学上可接受的赋形剂的非-限制性实例包含水、NaCl、生理盐水溶液、乳酸化林格氏(Ringer's)液、普通蔗糖、普通葡萄糖、粘合剂、填充剂、崩解剂、润滑剂、包衣、甜味剂、调味剂、盐溶液(如林格氏溶液)、醇、油、明胶、碳水化合物(如乳糖、直链淀粉或淀粉)、脂肪酸酯、羧甲基纤维素、聚乙烯吡咯烷酮和颜料等。此类制剂可以进行灭菌,并且如果需要,可以与不与本发明的化合物有害地反应的助剂混合,所述助剂如润滑剂、防腐剂、稳定剂、润湿剂、乳化剂、用于影响渗透压的盐、缓冲液、着色物质和/或芳香物质等。本领域的技术人员将认识到,其它药物赋形剂在本发明中是有用的。
术语“药学上可接受的盐”是指衍生自本领域众所周知的多种有机和无机抗衡离子的盐,并且仅举例来说包含钠、钾、钙、镁、铵、四烷基铵等;以及当分子含有碱性官能团时,有机或无机酸的盐,如盐酸盐、氢溴酸盐、酒石酸盐、甲磺酸盐、乙酸盐、马来酸盐、草酸盐等。
术语“制剂”旨在包含活性化合物与作为提供胶囊的载体的封装材料的调配物,其中具有或不具有其它载体的活性组分由载体包围,所述载体由此与活性组分相关。类似地,包含扁囊剂和锭剂。片剂、粉末、胶囊、丸剂、扁囊剂以及锭剂可以用作适用于口服施用的固体剂型。
药物制剂任选地呈单位剂型的形式。在这种形式中,制剂被细分成含有适当量的活性组分的单位剂量。单位剂型可以是包装的制剂,所述包装含有离散量的制剂,如在小瓶或安瓿中的包装的片剂、胶囊以及粉末。而且,单位剂型可以是胶囊、片剂、扁囊剂或锭剂本身,或其可以是适当数量的这些包装形式中的任何一种。单位剂型可以是冷冻的分散体。
应当理解,本文所描述的实例和实施例仅是出于说明性目的,并且根据其进行的各种修改或改变将启发本领域的技术人员并且将被包含在本申请的精神与权限范围内和所附权利要求书的范围内。本文所引用的所有出版物、专利和专利申请均出于所有目的特此通过引用整体并入。
抗ROR2抗体
本文尤其提供了以高效率和特异性与人酪氨酸激酶样孤儿受体2(ROR2)结合的抗体(例如,人源化抗体、单克隆抗体)、抗体片段(例如,scFv)和抗体组合物(例如,嵌合抗原受体、双特异性抗体)。本文提供的抗体和抗体组合物包含新型轻链和重链结构域CDR和框架区,并且已经被鉴定为与人ROR2的胞外结构域结合。例如,本文提供的抗体(包含其实施例)可以以高亲和力和特异性与ROR2的Kringle或Ig样结构域结合。另外,申请人表征了ROR2胞外结构域中的氨基酸残基,其对于结合如本文所描述的抗体(包含其实施例)很重要。与本文所描述的表位特异性结合的抗体(包含其实施例)可用于以高有效性和亲和力与人ROR2结合,并且抑制表达ROR2的细胞中的ROR2信号传导。本文提供的抗体(包含其实施例)可以用于癌症和其它ROR2相关疾病的诊断和治疗目的。本文提供的可变轻链和可变重链结构域尤其可以形成抗ROR2嵌合抗原受体或抗ROR2双特异性抗体的一部分。此外,由于其内化性质,本文提供的一些抗ROR2抗体可以附着到治疗部分并用作抗体药物缀合物(ADC),或者所述抗体可以附着到可检测部分并用于诊断目的。本文提供的抗体(包含其实施例)具有抑制表达ROR2的转移性细胞的迁移的能力,并且因此能够减轻具有表达ROR2的癌细胞的患者的转移的风险。
本文提供的示例性抗ROR2抗体通过克隆名称(例如,6E6、4G9、5C11和5G3)提及。在各实施例中,抗ROR2抗体是抗体6E6。在各实施例中,抗体6E6具有SEQ ID NO:2的重链可变结构域和SEQ ID NO:4的轻链可变结构域。在各实施例中,抗体6E6具有重链可变结构域和轻链可变结构域,其中所述重链可变结构域包含:如SEQ ID NO:25中所示的CDR H1、如SEQID NO:26中所示的CDR H2和如SEQ ID NO:27中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ ID NO:28中所示的CDR L1、如SEQ ID NO:29中所示的CDR L2和如SEQ IDNO:30中所示的CDR L3。在各实施例中,抗ROR2抗体是抗体4G9。在各实施例中,抗体4G9具有SEQ ID NO:6的重链可变结构域和SEQ ID NO:8的轻链可变结构域。在各实施例中,抗体4G9具有重链可变结构域和轻链可变结构域,其中重链可变结构域包含:如SEQ ID NO:31中所示的CDR H1、如SEQ ID NO:32中所示的CDR H2和如SEQ ID NO:33中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ ID NO:34中所示的CDR L1、如SEQ ID NO:35中所示的CDR L2和如SEQ ID NO:36中所示的CDR L3。在各实施例中,抗ROR2抗体是抗体5C11。在各实施例中,抗体5C11具有SEQ ID NO:10的重链可变结构域和SEQ ID NO:12的轻链可变结构域。在各实施例中,抗体5C11具有重链可变结构域和轻链可变结构域,其中重链可变结构域包含:如SEQ ID NO:37中所示的CDR H1、如SEQ ID NO:38中所示的CDR H2和如SEQ ID NO:39中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ ID NO:40中所示的CDR L1、如SEQ ID NO:41中所示的CDR L2和如SEQ ID NO:42中所示的CDR L3。在各实施例中,抗ROR2抗体是抗体5G3。在各实施例中,抗体5G3具有SEQ ID NO:14的重链可变结构域和SEQID NO:16的轻链可变结构域。在各实施例中,抗体5G3具有重链可变结构域和轻链可变结构域,其中重链可变结构域包含:如SEQ ID NO:43中所示的CDR H1、如SEQ ID NO:44中所示的CDR H2和如SEQ ID NO:45中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ IDNO:46中所示的CDR L1、如SEQ ID NO:47中所示的CDR L2和如SEQ ID NO:48中所示的CDRL3。
在一方面提供了一种抗酪氨酸激酶样孤儿受体2(ROR2)抗体,其包含重链可变结构域和轻链可变结构域,其中所述重链可变结构域包含:如SEQ ID NO:25中所示的CDR H1、如SEQ ID NO:26中所示的CDR H2和如SEQ ID NO:27中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ ID NO:28中所示的CDR L1、如SEQ ID NO:29中所示的CDR L2和如SEQID NO:30中所示的CDR L3。
如上所述,如本文提供的“轻链可变(VL)结构域”是指抗体、抗体变体或其片段的轻链的可变区。同样地,如本文提供的“重链可变(VH)结构域”是指抗体、抗体变体或其片段的重链的可变区。轻链可变结构域和重链可变结构域一起形成互补位,所述互补位与抗原(表位)结合。互补位或抗原结合位点形成于抗体、抗体变体或其片段的N末端处。在各实施例中,轻链可变(VL)结构域包含抗体轻链的CDR L1、CDR L2、CDR L3和FR L1、FR L2、FR L3和FR L4(框架区)。在各实施例中,重链可变(VH)结构域包含抗体重链的CDR H1、CDR H2、CDR H3和FR H1、FR H2、FR H3和FR H4(框架区)。在各实施例中,轻链可变(VL)结构域和轻链恒定(CL)结构域形成抗体轻链的一部分。在各实施例中,重链可变(VH)结构域和重链恒定(CH1)结构域形成抗体重链的一部分。在各实施例中,重链可变(VH)结构域和一个或多个重链恒定(CH1、CH2或CH3)结构域形成抗体重链的一部分。因此,在各实施例中,轻链可变(VL)结构域形成抗体的一部分。在各实施例中,重链可变(VH)结构域形成抗体的一部分。在各实施例中,轻链可变(VL)结构域形成治疗性抗体的一部分。在各实施例中,重链可变(VH)结构域形成治疗性抗体的一部分。在各实施例中,轻链可变(VL)结构域形成人抗体的一部分。在各实施例中,重链可变(VH)结构域形成人抗体的一部分。在各实施例中,轻链可变(VL)结构域形成人源化抗体的一部分。在各实施例中,重链可变(VH)结构域形成人源化抗体的一部分。在各实施例中,轻链可变(VL)结构域形成嵌合抗体的一部分。在各实施例中,重链可变(VH)结构域形成嵌合抗体的一部分。在各实施例中,轻链可变(VL)结构域形成抗体片段的一部分。在各实施例中,重链可变(VH)结构域形成抗体片段的一部分。在各实施例中,轻链可变(VL)结构域形成抗体变体的一部分。在各实施例中,重链可变(VH)结构域形成抗体变体的一部分。在各实施例中,轻链可变(VL)结构域形成Fab的一部分。在各实施例中,重链可变(VH)结构域形成Fab的一部分。在各实施例中,轻链可变(VL)结构域形成scFv的一部分。在各实施例中,重链可变(VH)结构域形成scFv的一部分。
在各实施例中,重链可变结构域包含SEQ ID NO:2的序列。在各实施例中,重链可变结构域是SEQ ID NO:2的序列。在各实施例中,轻链可变结构域包含SEQ ID NO:4的序列。在各实施例中,轻链可变结构域是SEQ ID NO:4的序列。
在各实施例中,重链可变结构域包含如SEQ ID NO:49中所示的FR H1、如SEQ IDNO:50中所示的FR H2、如SEQ ID NO:51中所示的FR H3和如SEQ ID NO:52中所示的FR H4。在各实施例中,轻链可变结构域包含如SEQ ID NO:53中所示的FR L1、如SEQ ID NO:54中所示的FR L2、如SEQ ID NO:55中所示的FR L3和如SEQ ID NO:56中所示的FR L4。
在各实施例中,抗体能够与ROR2蛋白结合。在各实施例中,ROR2蛋白是人ROR2蛋白。在各实施例中,抗体与ROR2蛋白结合。在各实施例中,ROR2蛋白包含SEQ ID NO:18的氨基酸序列。在各实施例中,抗体能够与ROR2蛋白的胞外结构域结合。在各实施例中,抗体与ROR2蛋白的胞外结构域结合。在各实施例中,胞外结构域包含SEQ ID NO:22的氨基酸序列。在各实施例中,胞外结构域是Kringle结构域。在各实施例中,Kringle结构域包含SEQ IDNO:113的氨基酸序列。
在各实施例中,ROR2蛋白包含位于与SEQ ID NO:22的位置349相对应的位置处的组氨酸或位于与位置354相对应的位置处的天冬氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:22的位置349相对应的位置处的组氨酸和位于与位置354相对应的位置处的天冬氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:18的位置349相对应的位置处的组氨酸或位于与位置354相对应的位置处的天冬氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:18的位置349相对应的位置处的组氨酸和位于与位置354相对应的位置处的天冬氨酸。
在各实施例中,抗体不与和SEQ ID NO:20的位置349相对应的位置处的精氨酸结合。在各实施例中,抗体不与和SEQ ID NO:20的位置354相对应的位置处的谷氨酸结合。在各实施例中,抗体不与和SEQ ID NO:24的位置349相对应的位置处的精氨酸结合。在各实施例中,抗体不与和SEQ ID NO:24的位置354相对应的位置处的谷氨酸结合。
抗体结合特定表位(例如,ROR2蛋白、ROR2的Kringle结构域或Ig样结构域)的能力可以用平衡解离常数(K
在各实施例中,抗体以0.01nM到10nM的平衡解离常数(K
在各实施例中,抗体以0.01nM到9.9nM的K
在各实施例中,抗体以0.01、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1、1.1、1.2、1.3、1.4、1.5、1.6、1.7、1.8、1.9、2、2.1、2.2、2.3、2.4、2.5、2.6、2.7、2.8、2.9、3、3.1、3.2、3.3、3.4、3.5、3.6、3.7、3.8、3.9、4、4.1、4.2、4.3、4.4、4.5、4.6、4.7、4.8、4.9、5、5.1、5.2、5.3、5.4、5.5、5.6、5.7、5.8、5.9、6、6.1、6.2、6.3、6.4、6.5、6.6、6.7、6.8、6.9、7、7.1、7.2、7.3、7.4、7.5、7.6、7.7、7.8、7.9、8、8.1、8.2、8.3、8.4、8.5、8.6、8.7、8.8、8.9、9、9.1、9.2、9.3、9.4、9.5、9.6、9.7、9.8、9.9或10nM的K
在各实施例中,抗体以约0.06nM的K
在各实施例中,抗体附着到治疗剂。在各实施例中,抗体附着到诊断剂。在各实施例中,诊断剂是可检测部分。
在一个实施例中,抗体具有SEQ ID NO:2的重链可变结构域和SEQ ID NO:4的轻链可变结构域。在一个实施例中,抗体包含(i)重链可变结构域,所述重链可变结构域包含如SEQ ID NO:25中所示的CDR H1、如SEQ ID NO:26中所示的CDR H2;如SEQ ID NO:27中所示的CDR H3;如SEQ ID NO:49中所示的FR H1、如SEQ ID NO:50中所示的FR H2、如SEQ ID NO:51中所示的FR H3和如SEQ ID NO:52中所示的FR H4;以及(ii)轻链可变结构域,所述轻链可变结构域包含如SEQ ID NO:28中所示的CDR L1、如SEQ ID NO:29中所示的CDR L2、如SEQID NO:30中所示的CDR L3;如SEQ ID NO:53中所示的FR L1、如SEQ ID NO:54中所示的FRL2、如SEQ ID NO:55中所示的FR L3和如SEQ ID NO:56中所示的FR L4。在一个另外的实施例中,抗体是抗体6E6。
在一方面提供了一种抗酪氨酸激酶样孤儿受体2(ROR2)抗体,其包含重链可变结构域和轻链可变结构域,其中所述重链可变结构域包含:如SEQ ID NO:31中所示的CDR H1、如SEQ ID NO:32中所示的CDR H2和如SEQ ID NO:33中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ ID NO:34中所示的CDR L1、如SEQ ID NO:35中所示的CDR L2和如SEQID NO:36中所示的CDR L3。
在各实施例中,重链可变结构域包含SEQ ID NO:6的序列。在各实施例中,重链可变结构域是SEQ ID NO:6的序列。在各实施例中,轻链可变结构域包含SEQ ID NO:8的序列。在各实施例中,轻链可变结构域是SEQ ID NO:8的序列。
在各实施例中,重链可变结构域包含如SEQ ID NO:57中所示的FR H1、如SEQ IDNO:58中所示的FR H2、如SEQ ID NO:59中所示的FR H3和如SEQ ID NO:60中所示的FR H4。在各实施例中,轻链可变结构域包含如SEQ ID NO:61中所示的FR L1、如SEQ ID NO:62中所示的FR L2、如SEQ ID NO:63中所示的FR L3和如SEQ ID NO:64中所示的FR L4。
在各实施例中,抗体能够与ROR2蛋白结合。在各实施例中,ROR2蛋白是人ROR2蛋白。在各实施例中,抗体与ROR2蛋白结合。在各实施例中,ROR2蛋白包含SEQ ID NO:18的氨基酸序列。在各实施例中,抗体能够与ROR2蛋白的胞外结构域结合。在各实施例中,抗体与ROR2蛋白的胞外结构域结合。在各实施例中,胞外结构域包含SEQ ID NO:22的氨基酸序列。在各实施例中,胞外结构域是Ig样结构域。在各实施例中,Ig样结构域包含SEQ ID NO:114的氨基酸序列。
在各实施例中,ROR2蛋白包含位于与SEQ ID NO:22的位置386相对应的位置处的甲硫氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:18的位置386相对应的位置处的甲硫氨酸。
在各实施例中,抗体不与和SEQ ID NO:20的位置349相对应的位置处的缬氨酸结合。在各实施例中,抗体不与和SEQ ID NO:24的位置349相对应的位置处的缬氨酸结合。
在各实施例中,抗体以0.2nM到5nM的K
在各实施例中,抗体以0.2nM到4.6nM的K
在各实施例中,抗体以0.1nM到10nM的K
在各实施例中,抗体以0.1nM到9.5nM的K
在各实施例中,抗体以0.1、0.4、0.8、1.2、1.6、2、2.4、2.8、3.2、3.6、4、4.4、4.8、5.2、5.6、6、6.4、6.8、7.2、7.6、8、8.4、8.8、9.2、9.6或10nM的K
在各实施例中,抗体以约1.9nM的K
在各实施例中,抗体附着到治疗剂。在各实施例中,抗体附着到诊断剂。在各实施例中,诊断剂是可检测部分。
在一个实施例中,抗体具有SEQ ID NO:6的重链可变结构域和SEQ ID NO:8的轻链可变结构域。在一个实施例中,抗体包含(i)重链可变结构域,所述重链可变结构域包含如SEQ ID NO:31中所示的CDR H1、如SEQ ID NO:32中所示的CDR H2;如SEQ ID NO:33中所示的CDR H3;如SEQ ID NO:57中所示的FR H1、如SEQ ID NO:58中所示的FR H2、如SEQ ID NO:59中所示的FR H3和如SEQ ID NO:60中所示的FR H4;以及(ii)轻链可变结构域,所述轻链可变结构域包含如SEQ ID NO:34中所示的CDR L1、如SEQ ID NO:35中所示的CDR L2、如SEQID NO:36中所示的CDR L3;如SEQ ID NO:61中所示的FR L1、如SEQ ID NO:62中所示的FRL2、如SEQ ID NO:63中所示的FR L3和如SEQ ID NO:64中所示的FR L4。在一个另外的实施例中,抗体是抗体4G9。
在一方面提供了一种抗酪氨酸激酶样孤儿受体2(ROR2)抗体,其包含重链可变结构域和轻链可变结构域,其中所述重链可变结构域包含:如SEQ ID NO:37中所示的CDR H1、如SEQ ID NO:38中所示的CDR H2和如SEQ ID NO:39中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ ID NO:40中所示的CDR L1、如SEQ ID NO:41中所示的CDR L2和如SEQID NO:42中所示的CDR L3。
在各实施例中,重链可变结构域包含SEQ ID NO:10的序列。在各实施例中,重链可变结构域是SEQ ID NO:10的序列。在各实施例中,轻链可变结构域包含SEQ ID NO:12的序列。在各实施例中,轻链可变结构域是SEQ ID NO:12的序列。
在各实施例中,重链可变结构域包含如SEQ ID NO:65中所示的FR H1、如SEQ IDNO:66中所示的FR H2、如SEQ ID NO:67中所示的FR H3和如SEQ ID NO:68中所示的FR H4。在各实施例中,轻链可变结构域包含如SEQ ID NO:69中所示的FR L1、如SEQ ID NO:70中所示的FR L2、如SEQ ID NO:71中所示的FR L3和如SEQ ID NO:72中所示的FR L4。
在各实施例中,抗体能够与ROR2蛋白结合。在各实施例中,ROR2蛋白是人ROR2蛋白。在各实施例中,抗体与ROR2蛋白结合。在各实施例中,ROR2蛋白包含SEQ ID NO:18的氨基酸序列。在各实施例中,抗体能够与ROR2蛋白的胞外结构域结合。在各实施例中,抗体与ROR2蛋白的胞外结构域结合。在各实施例中,胞外结构域包含SEQ ID NO:22的氨基酸序列。在各实施例中,胞外结构域是Kringle结构域。在各实施例中,Kringle结构域包含SEQ IDNO:113的氨基酸序列。
在各实施例中,ROR2蛋白包含位于与SEQ ID NO:22的位置349相对应的位置处的组氨酸、位于与位置354相对应的位置处的天冬氨酸或位于与位置386相对应的位置处的甲硫氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:22的位置349相对应的位置处的组氨酸、位于与位置354相对应的位置处的天冬氨酸和位于与位置386相对应的位置处的甲硫氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:18的位置349相对应的位置处的组氨酸、位于与位置354相对应的位置处的天冬氨酸或位于与位置386相对应的位置处的甲硫氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:18的位置349相对应的位置处的组氨酸、位于与位置354相对应的位置处的天冬氨酸和位于与位置386相对应的位置处的甲硫氨酸。
在各实施例中,抗体不与和SEQ ID NO:20的位置349相对应的位置处的精氨酸结合。在各实施例中,抗体不与和SEQ ID NO:20的位置354相对应的位置处的谷氨酸结合。在各实施例中,抗体不与和SEQ ID NO:20的位置386相对应的位置处的缬氨酸结合。在各实施例中,抗体不与和SEQ ID NO:24的位置349相对应的位置处的精氨酸结合。在各实施例中,抗体不与和SEQ ID NO:24的位置354相对应的位置处的谷氨酸结合。在各实施例中,抗体不与和SEQ ID NO:24的位置386相对应的位置处的缬氨酸结合。
在各实施例中,抗体以10nM到150nM的K
在各实施例中,抗体以10nM到140nM的K
在各实施例中,抗体是5C11,并且以10、20、30、40、50、60、70、80、90、100、110、120、130、140或150nM的K
在各实施例中,抗体附着到治疗剂。在各实施例中,抗体附着到诊断剂。在各实施例中,诊断剂是可检测部分。
在一个实施例中,抗体具有SEQ ID NO:10的重链可变结构域和SEQ ID NO:12的轻链可变结构域。在一个实施例中,抗体包含(i)重链可变结构域,所述重链可变结构域包含如SEQ ID NO:37中所示的CDR H1、如SEQ ID NO:38中所示的CDR H2;如SEQ ID NO:39中所示的CDR H3;如SEQ ID NO:65中所示的FR H1、如SEQ ID NO:66中所示的FR H2、如SEQ IDNO:67中所示的FR H3和如SEQ ID NO:68中所示的FR H4;以及(ii)轻链可变结构域,所述轻链可变结构域包含如SEQ ID NO:40中所示的CDR L1、如SEQ ID NO:41中所示的CDR L2、如SEQ ID NO:42中所示的CDR L3;如SEQ ID NO:69中所示的FR L1、如SEQ ID NO:70中所示的FR L2、如SEQ ID NO:71中所示的FR L3和如SEQ ID NO:72中所示的FR L4。在一个另外的实施例中,抗体是抗体5C11。
在一方面提供了一种抗酪氨酸激酶样孤儿受体2(ROR2)抗体,其包含重链可变结构域和轻链可变结构域,其中所述重链可变结构域包含:如SEQ ID NO:43中所示的CDR H1、如SEQ ID NO:44中所示的CDR H2和如SEQ ID NO:45中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ ID NO:46中所示的CDR L1、如SEQ ID NO:47中所示的CDR L2和如SEQID NO:48中所示的CDR L3。
在各实施例中,重链可变结构域包含SEQ ID NO:14的序列。在各实施例中,重链可变结构域是SEQ ID NO:14的序列。在各实施例中,轻链可变结构域包含SEQ ID NO:16的序列。在各实施例中,轻链可变结构域是SEQ ID NO:16的序列。
在各实施例中,重链可变结构域包含如SEQ ID NO:73中所示的FR H1、如SEQ IDNO:74中所示的FR H2、如SEQ ID NO:75中所示的FR H3和如SEQ ID NO:76中所示的FR H4。在各实施例中,轻链可变结构域包含如SEQ ID NO:77中所示的FR L1、如SEQ ID NO:78中所示的FR L2、如SEQ ID NO:79中所示的FR L3和如SEQ ID NO:80中所示的FR L4。
在各实施例中,抗体能够与ROR2蛋白结合。在各实施例中,ROR2蛋白是人ROR2蛋白。在各实施例中,抗体与ROR2蛋白结合。在各实施例中,ROR2蛋白包含SEQ ID NO:18的氨基酸序列。在各实施例中,抗体能够与ROR2蛋白的胞外结构域结合。在各实施例中,抗体与ROR2蛋白的胞外结构域结合。在各实施例中,胞外结构域包含SEQ ID NO:22的氨基酸序列。在各实施例中,胞外结构域是Ig样结构域。在各实施例中,Ig样结构域包含包含SEQ ID NO:114的氨基酸序列。
在各实施例中,抗体以10nM到150nM的K
在各实施例中,抗体以10nM到140nM的K
在各实施例中,抗体是5G3,并且以10、20、30、40、50、60、70、80、90、100、110、120、130、140或150nM的K
在各实施例中,抗体附着到治疗剂。在各实施例中,抗体附着到诊断剂。在各实施例中,诊断剂是可检测部分。
在一个实施例中,抗体具有SEQ ID NO:14的重链可变结构域和SEQ ID NO:16的轻链可变结构域。在一个实施例中,抗体包含(i)重链可变结构域,所述重链可变结构域包含如SEQ ID NO:43中所示的CDR H1、如SEQ ID NO:44中所示的CDR H2;如SEQ ID NO:45中所示的CDR H3;如SEQ ID NO:73中所示的FR H1、如SEQ ID NO:74中所示的FR H2、如SEQ IDNO:75中所示的FR H3和如SEQ ID NO:76中所示的FR H4;以及(ii)轻链可变结构域,所述轻链可变结构域包含如SEQ ID NO:46中所示的CDR L1、如SEQ ID NO:47中所示的CDR L2、如SEQ ID NO:48中所示的CDR L3;如SEQ ID NO:77中所示的FR L1、如SEQ ID NO:78中所示的FR L2、如SEQ ID NO:79中所示的FR L3和如SEQ ID NO:80中所示的FR L4。在一个另外的实施例中,抗体是抗体5G3。
本文提供的抗体(包含其实施例)(例如,抗体6e6、4G9、5C11或5G3)可以是人源化抗体。因此,在各实施例中,抗体是人源化抗体。在各实施例中,抗体是嵌合抗体。在各实施例中,抗体是Fab'片段。在各实施例中,抗体是IgG。在各实施例中,抗体是IgG。本文提供的抗ROR2抗体可以是IgG1、IgG2、IgG3或IgG4。在各实施例中,抗体是IgG1。在各实施例中,抗体是IgG2。在各实施例中,抗体是IgG2a。在各实施例中,抗体是IgG3。在各实施例中,抗体是IgG4。
在各实施例中,抗体不与小鼠ROR2蛋白结合。在各实施例中,抗体不与由UniProt参考编号Q9Z138鉴定的小鼠ROR2蛋白结合。在各实施例中,本文提供的抗体不与包括SEQID NO:20的氨基酸序列的蛋白质结合。在各实施例中,本文提供的抗体不与包括SEQ IDNO:24的氨基酸序列的蛋白质结合。在各实施例中,本文提供的抗体不与SEQ ID NO:20或SEQ ID NO:24的蛋白质结合。在各实施例中,本文提供的抗体不与SEQ ID NO:20的蛋白质结合。在各实施例中,本文提供的抗体不与SEQ ID NO:24的蛋白质结合。
在一方面提供了由本文提供的抗体(包含其实施例)(例如,抗体6e6、4G9、5C11或5G3)结合的ROR2蛋白可以由细胞(例如,癌细胞)表达。因此,在各实施例中,ROR2蛋白在细胞上表达。在各实施例中,细胞是癌细胞。在各实施例中,癌细胞是癌症是乳腺癌细胞、卵巢癌细胞、胰腺癌细胞、宫颈癌细胞、胃癌细胞、肾癌细胞、头颈癌细胞、骨癌细胞、皮肤癌细胞或前列腺癌细胞。在各实施例中,癌细胞是乳腺癌细胞。在各实施例中,癌细胞是卵巢癌细胞。在各实施例中,癌细胞是胰腺癌细胞。在各实施例中,癌细胞是癌症是宫颈癌细胞。在各实施例中,癌细胞是癌症是胃癌细胞。在各实施例中,癌细胞是癌症是肾癌细胞。在各实施例中,癌细胞是癌症是头颈癌细胞。在各实施例中,癌细胞是癌症是骨癌细胞。在各实施例中,癌细胞是癌症是皮肤癌细胞。在各实施例中,癌细胞是癌症是前列腺癌细胞。
在各实施例中,本文提供的抗体(例如,抗体6E6、4G9、5C11或5G3)不与ROR2阴性细胞结合。如本文提供的“ROR2阴性细胞”是相对于标准对照不表达可检测量的ROR2蛋白的细胞。在各实施例中,使用本领域常规已知的用于检测细胞中的蛋白质表达的方法(例如,免疫荧光检测、蛋白质生物化学、RNA表达水平),ROR2阴性细胞的表达水平是不可检测的。在各实施例中,ROR2阴性细胞的表达水平为标准对照的表达水平(例如,使用常规方法的细胞表达可检测的ROR2水平)的1/1000、1/500、1/100、1/50、1/25、1/20、1/10、1/5或1/1.5。ROR2阴性细胞的非限制性实例包含来自健康受试者的外周血单核细胞(PBMC)。
本文提供的抗体的可变轻链结构域或可变重链中的任何一个可以形成scFv的一部分。因此,在各实施例中,抗体是单链抗体(scFv)。在各实施例中,轻链可变结构域和重链可变结构域形成scFv的一部分。在各实施例中,连接子形成scFv的一部分。在各实施例中,连接子包含SEQ ID NO:82的序列。在各实施例中,前导肽形成scFv的一部分。在各实施例中,前导肽包含SEQ ID NO:81的序列。在各实施例中,scFv进一步包含重链恒定区(CH2-CH3)。在各实施例中,重链恒定区包含SEQ ID NO:84的序列。
在各实施例中,scFv包含SEQ ID NO:85的序列。在各实施例中,scFv是SEQ ID NO:85的序列。
在各实施例中,scFv以0.01nM到10nM的平衡解离常数(K
在各实施例中,scFv以0.01nM到9.9nM的K
在各实施例中,scFv以0.01、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1、1.1、1.2、1.3、1.4、1.5、1.6、1.7、1.8、1.9、2、2.1、2.2、2.3、2.4、2.5、2.6、2.7、2.8、2.9、3、3.1、3.2、3.3、3.4、3.5、3.6、3.7、3.8、3.9、4、4.1、4.2、4.3、4.4、4.5、4.6、4.7、4.8、4.9、5、5.1、5.2、5.3、5.4、5.5、5.6、5.7、5.8、5.9、6、6.1、6.2、6.3、6.4、6.5、6.6、6.7、6.8、6.9、7、7.1、7.2、7.3、7.4、7.5、7.6、7.7、7.8、7.9、8、8.1、8.2、8.3、8.4、8.5、8.6、8.7、8.8、8.9、9、9.1、9.2、9.3、9.4、9.5、9.6、9.7、9.8、9.9或10nM的K
在各实施例中,scFv以约0.07nM的K
在一个实施例中,scFv从N端到C端包含:SEQ ID NO:81的前导肽、SEQ ID NO:4的轻链可变结构域、SEQ ID NO:82的连接子结构域、SEQ ID NO:2的重链可变结构域、SEQ IDNO:83的间隔子以及SEQ ID NO:84的恒定重链结构域(CH2-CH3)。在一个另外的实施例中,scFv是6E6 scFv。
在各实施例中,scFv包含SEQ ID NO:86的序列。在各实施例中,scFv是SEQ ID NO:86的序列。
在各实施例中,scFv以0.01nM到150nM的K
在各实施例中,scFv以0.01nM到140nM的K
在各实施例中,scFv是4G9 scFv,并且以0.01、1、10、20、30、40、50、60、70、80、90、100、110、120、130、140或150nM的K
在一个实施例中,scFv从N端到C端包含:SEQ ID NO:81的前导肽、SEQ ID NO:8的轻链可变结构域、SEQ ID NO:82的连接子结构域、SEQ ID NO:6的重链可变结构域、SEQ IDNO:83的间隔子和SEQ ID NO:84的恒定重链结构域(CH2-CH3)。在一个另外的实施例中,scFv是4G9 scFv。
在各实施例中,scFv能够与ROR2蛋白结合。在各实施例中,ROR2蛋白是人ROR2蛋白。在各实施例中,scFv与ROR2蛋白结合。在各实施例中,ROR2蛋白包含SEQ ID NO:18的氨基酸序列。在各实施例中,scFv能够与ROR2蛋白的胞外结构域结合。在各实施例中,scFv与ROR2蛋白的胞外结构域结合。在各实施例中,胞外结构域包含SEQ ID NO:22的氨基酸序列。在各实施例中,胞外结构域是Kringle结构域。在各实施例中,Kringle结构域包含SEQ IDNO:113的氨基酸序列。在各实施例中,胞外结构域是Ig样结构域。在各实施例中,Ig样结构域包含SEQ ID NO:114的氨基酸序列。
在各实施例中,scFv不与小鼠ROR2蛋白结合。在各实施例中,scFv不与由UniProt参考编号Q9Z138鉴定的小鼠ROR2蛋白结合。在各实施例中,本文提供的scFv不与包括SEQID NO:20的氨基酸序列的蛋白质结合。在各实施例中,本文提供的scFv不与包括SEQ IDNO:24的氨基酸序列的蛋白质结合。在各实施例中,本文提供的scFv不与SEQ ID NO:20或SEQ ID NO:24的蛋白质结合。在各实施例中,本文提供的scFv不与SEQ ID NO:20的蛋白质结合。在各实施例中,本文提供的scFv不与SEQ ID NO:24的蛋白质结合。
在另一方面,提供了一种抗ROR2抗体。所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:重链可变结构域,所述重链可变结构域包含:如SEQ ID NO:25中所示的CDRH1、如SEQ ID NO:26中所示的CDR H2和如SEQ ID NO:27中所示的CDR H3;以及轻链可变结构域,所述轻链可变结构域包含:如SEQ ID NO:28中所示的CDR L1、如SEQ ID NO:29中所示的CDR L2和如SEQ ID NO:30中所示的CDR L3。在各实施例中,重链可变结构域包含SEQ IDNO:2的序列。在各实施例中,轻链可变结构域包含SEQ ID NO:4的序列。
在一方面提供了一种抗ROR2抗体。所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:SEQ ID:2的重链可变结构域;以及SEQ ID NO:4的轻链可变结构域。
在一方面提供了一种抗ROR2抗体。所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:由SEQ ID:1的核酸序列编码的重链可变结构域;以及由SEQ ID:3的核酸序列编码的轻链可变结构域。
在一方面提供了一种抗ROR2抗体。所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:重链可变结构域,所述重链可变结构域包含:如SEQ ID NO:31中所示的CDR H1、如SEQ ID NO:32中所示的CDR H2和如SEQ ID NO:33中所示的CDR H3;以及轻链可变结构域,所述轻链可变结构域包含:如SEQ ID NO:34中所示的CDR L1、如SEQ ID NO:35中所示的CDR L2和如SEQ ID NO:36中所示的CDR L3。在各实施例中,重链可变结构域包含SEQ ID:6的序列。在各实施例中,轻链可变结构域包含SEQ ID NO:8的序列。
在一方面,提供了一种抗ROR2抗体。所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:SEQ ID:6的重链可变结构域;以及SEQ ID NO:8的轻链可变结构域。
在一方面,提供了一种抗ROR2抗体。所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:由SEQ ID:5的核酸序列编码的重链可变结构域;以及由SEQ ID:7的核酸序列编码的轻链可变结构域。
在一方面提供了一种抗ROR2抗体。所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:SEQ ID:10的重链可变结构域;以及SEQ ID NO:12的轻链可变结构域。
在一方面提供了一种抗ROR2抗体。所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:由SEQ ID:9的核酸序列编码的重链可变结构域;以及由SEQ ID:11的核酸序列编码的轻链可变结构域。
在一方面提供了一种抗ROR2抗体。所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:重链可变结构域,所述重链可变结构域包含:如SEQ ID NO:43中所示的CDR H1、如SEQ ID NO:44中所示的CDR H2和如SEQ ID NO:45中所示的CDR H3;以及轻链可变结构域,所述轻链可变结构域包含:如SEQ ID NO:46中所示的CDR L1、如SEQ ID NO:47中所示的CDR L2和如SEQ ID NO:48中所示的CDR L3。在各实施例中,重链可变结构域包含SEQ ID:14的序列。在各实施例中,轻链可变结构域包含SEQ ID NO:16的序列。
在一方面提供了一种抗ROR2抗体。所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:SEQ ID:14的重链可变结构域;以及SEQ ID NO:16的轻链可变结构域。
在一方面提供了一种抗ROR2抗体。所述抗ROR2抗体与包含以下的抗ROR2抗体结合同一表位:由SEQ ID:13的核酸序列编码的重链可变结构域;以及由SEQ ID:15的核酸序列编码的轻链可变结构域。
在各实施例中,抗体能够与ROR2蛋白结合。在各实施例中,ROR2蛋白是人ROR2蛋白。在各实施例中,抗体与ROR2蛋白结合。在各实施例中,ROR2蛋白包含SEQ ID NO:18的氨基酸序列。在各实施例中,抗体能够与ROR2蛋白的胞外结构域结合。在各实施例中,抗体与ROR2蛋白的胞外结构域结合。在各实施例中,胞外结构域包含SEQ ID NO:22的氨基酸序列。在各实施例中,胞外结构域是Kringle结构域。在各实施例中,Kringle结构域包含SEQ IDNO:113的氨基酸序列。在各实施例中,胞外结构域是Ig样结构域。在各实施例中,Ig样结构域包含包含SEQ ID NO:114的氨基酸序列。
在各实施例中,ROR2蛋白包含位于与SEQ ID NO:22的位置349相对应的位置处的组氨酸、位于与位置354相对应的位置处的天冬氨酸或位于与位置386相对应的位置处的甲硫氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:22的位置349相对应的位置处的组氨酸、位于与位置354相对应的位置处的天冬氨酸和位于与位置386相对应的位置处的甲硫氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:18的位置349相对应的位置处的组氨酸、位于与位置354相对应的位置处的天冬氨酸或位于与位置386相对应的位置处的甲硫氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:18的位置349相对应的位置处的组氨酸、位于与位置354相对应的位置处的天冬氨酸和位于与位置386相对应的位置处的甲硫氨酸。
在各实施例中,ROR2蛋白包含位于与SEQ ID NO:22的位置386相对应的位置处的甲硫氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:22的位置349相对应的位置处的组氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:22的位置354相对应的位置处的天冬氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:18的位置386相对应的位置处的甲硫氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:18的位置349相对应的位置处的组氨酸。在各实施例中,ROR2蛋白包含位于与SEQ ID NO:18的位置354相对应的位置处的天冬氨酸。
在各实施例中,抗体能够与ROR2蛋白结合。在各实施例中,ROR2蛋白是人ROR2蛋白。在各实施例中,抗体与ROR2蛋白结合。在各实施例中,ROR2蛋白包含SEQ ID NO:18的氨基酸序列。在各实施例中,抗体能够与ROR2蛋白的胞外结构域结合。在各实施例中,抗体与ROR2蛋白的胞外结构域结合。在各实施例中,胞外结构域包含SEQ ID NO:22的氨基酸序列。在各实施例中,胞外结构域是Ig样结构域。在各实施例中,Ig样结构域包含与SEQ ID NO:22的位置79到147相对应的残基。
在各实施例中,抗体附着到治疗剂。在各实施例中,抗体附着到诊断剂。在各实施例中,诊断剂是可检测部分。
在各实施例中,抗体以0.01nM到150nM的K
在各实施例中,抗体以0.01nM到140nM的K
与本文提供的表位结合的抗体可以是人源化抗体。因此,在各实施例中,抗体是人源化抗体。在各实施例中,抗体是嵌合抗体。在各实施例中,抗体是Fab'片段。在各实施例中,抗体是IgG。在各实施例中,抗体是IgG。本文提供的抗ROR2抗体可以是IgG1、IgG2、IgG3或IgG4。在各实施例中,抗体是IgG1。在各实施例中,抗体是IgG2。在各实施例中,抗体是IgG2a。在各实施例中,抗体是IgG3。在各实施例中,抗体是IgG4。
在各实施例中,抗体不与小鼠ROR2蛋白结合。在各实施例中,抗体不与由UniProt参考编号Q9Z138鉴定的小鼠ROR2蛋白结合。在各实施例中,本文提供的抗体不与包括SEQID NO:20的氨基酸序列的蛋白质结合。在各实施例中,本文提供的抗体不与包括SEQ IDNO:24的氨基酸序列的蛋白质结合。在各实施例中,本文提供的抗体不与SEQ ID NO:20或SEQ ID NO:24的蛋白质结合。在各实施例中,本文提供的抗体不与SEQ ID NO:20的蛋白质结合。在各实施例中,本文提供的抗体不与SEQ ID NO:24的蛋白质结合。
在各实施例中,抗体不与和SEQ ID NO:20的位置349相对应的位置处的精氨酸结合。在各实施例中,抗体不与和SEQ ID NO:20的位置354相对应的位置处的谷氨酸结合。在各实施例中,抗体不与和SEQ ID NO:20的位置386相对应的位置处的缬氨酸结合。在各实施例中,抗体不与和SEQ ID NO:24的位置349相对应的位置处的精氨酸结合。在各实施例中,抗体不与和SEQ ID NO:24的位置354相对应的位置处的谷氨酸结合。在各实施例中,抗体不与和SEQ ID NO:24的位置386相对应的位置处的缬氨酸结合。
在各实施例中,本文提供的抗体不与ROR2阴性细胞结合。如本文提供的“ROR2阴性细胞”是相对于标准对照不表达可检测量的ROR2蛋白的细胞。在各实施例中,使用本领域常规已知的用于检测细胞中的蛋白质表达的方法(例如,免疫荧光检测、蛋白质生物化学、RNA表达水平),ROR2阴性细胞的表达水平是不可检测的。在各实施例中,ROR2阴性细胞的表达水平为标准对照的表达水平(例如,使用常规方法的细胞表达可检测的ROR2水平)的1/1000、1/500、1/100、1/50、1/25、1/20、1/10、1/5或1/1.5。ROR2阴性细胞的非限制性实例包含来自健康受试者的外周血单核细胞(PBMC)。
嵌合抗原受体蛋白
如上所述,本文提供的重链可变(VH)结构域和轻链可变(VL)结构域(包含其实施例)可以各自独立地形成抗体、抗体片段或嵌合抗原受体或双特异性抗体的一部分。本文尤其提供了嵌合抗原受体和双特异性抗体,其包含如本文提供的轻链可变(VL)结构域和/或重链可变(VH)结构域,并且因此能够有效且高效地与人ROR2结合。嵌合抗原受体的抗体区可以包含本文提供的轻链和重链可变结构域(包含其实施例)中的任何一个。如本文提供的轻链可变(VL)结构域和/或重链可变(VH)结构域可以形成嵌合抗原受体的一部分。因此,在一方面提供了一种嵌合抗原受体,其包含:(i)抗体区,所述抗体区包含:(a)轻链可变结构域,所述轻链可变结构域包含如SEQ ID NO:28中所示的CDR L1、如SEQ ID NO:29中所示的CDR L2和如SEQ ID NO:30中所示的CDR L3;以及{4}(b)重链可变区结构域,所述重链可变区结构域包含如SEQ ID NO:25中所示的CDR H1、如SEQ ID NO:26中所示的CDR H2和如SEQID NO:27中所示的CDR H3;以及(ii)跨膜结构域。在一个实施例中,嵌合抗原受体包含抗体6E6的轻链可变结构域和抗体6E6的重链可变结构域。
在另一方面提供了一种嵌合抗原受体,其包含:(i)抗体区,所述抗体区包含:(a)轻链可变结构域,所述轻链可变结构域包含如SEQ ID NO:34中所示的CDR L1、如SEQ IDNO:35中所示的CDR L2和如SEQ ID NO:36中所示的CDR L3;以及{7}(b)重链可变区结构域,所述重链可变区结构域包含如SEQ ID NO:31中所示的CDR H1、如SEQ ID NO:32中所示的CDR H2和如SEQ ID NO:33中所示的CDR H3;以及(ii)跨膜结构域。在一个实施例中,嵌合抗原受体包含抗体4G9的轻链可变结构域和抗体4G9的重链可变结构域。
在另一方面提供了一种嵌合抗原受体,其包含:(i)抗体区,所述抗体区包含:(a)轻链可变结构域,所述轻链可变结构域包含如SEQ ID NO:40中所示的CDR L1、如SEQ IDNO:41中所示的CDR L2和如SEQ ID NO:42中所示的CDR L3;以及{7}(b)重链可变区结构域,所述重链可变区结构域包含如SEQ ID NO:37中所示的CDR H1、如SEQ ID NO:38中所示的CDR H2和如SEQ ID NO:39中所示的CDR H3;以及(ii)跨膜结构域。在一个实施例中,嵌合抗原受体包含抗体5C11的轻链可变结构域和抗体5C11的重链可变结构域。
在一方面提供了一种嵌合抗原受体,其包含:(i)抗体区,所述抗体区包含:(a)轻链可变结构域,所述轻链可变结构域包含如SEQ ID NO:46中所示的CDR L1、如SEQ ID NO:47中所示的CDR L2和如SEQ ID NO:48中所示的CDR L3;以及{7}(b)重链可变区结构域,所述重链可变区结构域包含如SEQ ID NO:43中所示的CDR H1、如SEQ ID NO:44中所示的CDRH2和如SEQ ID NO:45中所示的CDR H3;以及(ii)跨膜结构域。在一个实施例中,嵌合抗原受体包含抗体5G3的轻链可变结构域和抗体5G3的重链可变结构域。
如本文提供的“抗体区”是指形成本文提供的重组蛋白(例如,CAR、双特异性抗体)的一部分的单价或多价蛋白质部分(包含其实施例)。因此,本领域的普通技术人员将立即认识到抗体区是能够与抗原(表位)结合的蛋白质部分。因此,本文提供的抗体区可以包含抗体的结构域(例如,轻链可变(VL)结构域、重链可变(VH)结构域)或抗体片段(例如,Fab)。在各实施例中,抗体区是蛋白缀合物。如本文提供的“蛋白缀合物”是指由多于一种多肽组成的构建体,其中所述多肽共价或非共价结合在一起。在各实施例中,蛋白缀合物的多肽由一个核酸分子编码。在各实施例中,蛋白缀合物的多肽由不同的核酸分子编码。在各实施例中,多肽通过连接子连接。在各实施例中,多肽通过化学连接子连接。在各实施例中,抗体区是scFv。抗体区可以包含轻链可变(VL)结构域和/或重链可变(VH)结构域。在各实施例中,抗体区包含轻链可变(VL)结构域。在各实施例中,抗体区包含重链可变(VH)结构域。
如本文提供的“跨膜结构域”是指形成生物膜的一部分的多肽。本文提供的跨膜结构域能够从膜的一侧跨越生物膜(例如,细胞膜)到膜的另一侧。在各实施例中,跨膜结构域从细胞膜的胞内侧跨越到细胞膜的胞外侧。跨膜结构域可以包含非极性疏水性残基,所述残基将本文提供的蛋白质(包含其实施例)锚定在生物膜(例如,T细胞的细胞膜)中。设想了能够锚定本文提供的蛋白质(包含其实施例)的任何跨膜结构域。跨膜结构域的非限制性实例包含CD28、CD8、CD4或CD3ζ的跨膜结构域。在各实施例中,跨膜结构域是CD4跨膜结构域。
在各实施例中,跨膜结构域是CD28跨膜结构域。如本文提供的术语“CD28跨膜结构域”包含CD28的跨膜结构域的任何重组或天然存在的形式,或者其维持CD28跨膜结构域活性(例如,与CD28跨膜结构域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的变体或同源物。在一些方面,与天然存在的CD28跨膜结构域多肽相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在各实施例中,CD28是如通过NCBI序列参考GI:340545506、其同源物或功能片段鉴定的蛋白质。
在各实施例中,跨膜结构域是CD8跨膜结构域。如本文提供的术语“CD8跨膜结构域”包含CD8的跨膜结构域的任何重组或天然存在的形式,或者其维持CD8跨膜结构域活性(例如,与CD8跨膜结构域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的变体或同源物。在一些方面,与天然存在的CD8跨膜结构域多肽相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在各实施例中,CD8是如通过NCBI序列参考GI:225007534、其同源物或功能片段鉴定的蛋白质。
在各实施例中,跨膜结构域是CD4跨膜结构域。如本文提供的术语“CD4跨膜结构域”包含CD4的跨膜结构域的任何重组或天然存在的形式,或者其维持CD4跨膜结构域活性(例如,与CD4跨膜结构域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的变体或同源物。在一些方面,与天然存在的CD4跨膜结构域多肽相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在各实施例中,CD4是如通过NCBI序列参考GI:303522473、其同源物或功能片段鉴定的蛋白质。
在各实施例中,跨膜结构域是CD3ζ(也被称为CD247)跨膜结构域。如本文提供的术语“CD3ζ跨膜结构域”包含CD3ζ的跨膜结构域的任何重组或天然存在的形式,或者其维持CD3ζ跨膜结构域活性(例如,与CD3ζ跨膜结构域相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的变体或同源物。在一些方面,与天然存在的CD3ζ跨膜结构域多肽相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在各实施例中,CD3ζ是如通过NCBI序列参考GI:166362721、其同源物或功能片段鉴定的蛋白质。
在各实施例中,嵌合抗原受体进一步包含胞内T细胞信号传导结构域。如本文提供的“胞内T细胞信号传导结构域”包含能够响应于抗原与本文提供的抗体区(包含其实施例)的结合而提供一级信号传导的氨基酸序列。在各实施例中,胞内T细胞信号传导结构域的信号传导导致表达其的T细胞的激活。在各实施例中,胞内T细胞信号传导结构域的信号传导导致表达其的T细胞的增殖(细胞分裂)。在各实施例中,胞内T细胞信号传导结构域的信号传导导致所述T细胞表达本领域已知的具有激活的T细胞特性的蛋白质(例如,CTLA-4、PD-1、CD28、CD69)。在各实施例中,胞内T细胞信号传导结构域是CD3ζ胞内T细胞信号传导结构域。
在各实施例中,嵌合抗原受体进一步包含胞内共刺激T细胞信号传导结构域。如本文提供的“胞内共刺激信号传导结构域”包含能够响应于抗原与本文提供的抗体区(包含其实施例)的结合而提供共刺激信号传导的氨基酸序列。在各实施例中,共刺激信号传导结构域的信号传导导致细胞因子的产生和表达细胞因子的T细胞的增殖。在各实施例中,胞内共刺激信号传导结构域是CD28胞内共刺激信号传导结构域、4-1BB胞内共刺激信号传导结构域、ICOS胞内共刺激信号传导结构域或OX-40胞内共刺激信号传导结构域。在各实施例中,胞内共刺激信号传导结构域是CD28胞内共刺激信号传导结构域。在各实施例中,胞内共刺激信号传导结构域是4-1BB胞内共刺激信号传导结构域。在各实施例中,胞内共刺激信号传导结构域是ICOS胞内共刺激信号传导结构域。在各实施例中,胞内共刺激信号传导结构域是OX-40胞内共刺激信号传导结构域。
在各实施例中,抗体区包含Fc结构域。在各实施例中,抗体区包含间隔子区。在各实施例中,间隔子区位于跨膜结构域与抗体区之间。如本文提供的“间隔子区”是连接抗体区与跨膜结构域的多肽。在各实施例中,间隔子区将重链恒定区与跨膜结构域连接。在各实施例中,间隔子区包含Fc区。在各实施例中,间隔子区是Fc区。设想本文提供的组合物的间隔子区的实例包含但不限于免疫球蛋白分子或其片段(例如,IgG1、IgG2、IgG3、IgG4)和包含影响Fc受体结合的突变的免疫球蛋白分子或其片段(例如,IgG1、IgG2、IgG3、IgG4)。在各实施例中,间隔子区是铰链区。
如本文所提及的术语“CTLA-4”包含细胞毒性T淋巴细胞相关蛋白4蛋白,也被称为CD152(分化簇152)的任何重组或天然存在的形式,或者其维持CTLA-4活性(例如,与CTLA-4相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的变体或同源物。在一些方面,与天然存在的CTLA-4蛋白相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在各实施例中,CTLA-4蛋白与由UniProt参考编号P16410鉴定的蛋白质或与其基本上相同的变体或同源物基本上相同。
如本文所提及的术语“CD28”包含分化簇28蛋白的任何重组或天然存在的形式,或者其维持CD28活性(例如,与CD28相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的变体或同源物。在一些方面,与天然存在的CD28蛋白相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在各实施例中,CD28蛋白与由UniProt参考编号P10747鉴定的蛋白质或与其基本上相同的变体或同源物基本上相同。
如本文所提及的术语“CD69”包含分化簇69蛋白的任何重组或天然存在的形式,或者其维持CD69活性(例如,与CD69相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的变体或同源物。在一些方面,与天然存在的CD69蛋白相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在各实施例中,CD69蛋白与由UniProt参考编号Q07108鉴定的蛋白质或与其基本上相同的变体或同源物基本上相同。
如本文所提及的术语“4-1BB”包含4-1BB蛋白,也被称为肿瘤坏死因子受体超家族成员9(TNFRSF9)、分化簇137(CD137)并且通过淋巴细胞激活(ILA)诱导的任何重组或天然存在的形式,或者其维持4-1BB活性(例如,与4-1BB相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的变体或同源物。在一些方面,与天然存在的EGFR蛋白相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在各实施例中,4-1BB蛋白与由UniProt参考编号Q07011鉴定的蛋白质或与其基本上相同的变体或同源物基本上相同。
本文提供的嵌合抗原受体可以包含本文所述的抗ROR2抗体或其片段中的任何一个。因此,嵌合抗原受体可以包含本文提供的CDR、FR、重链可变结构域或轻链可变结构域中的任何一个。例如,重链可变结构域可以包含SEQ ID NO:2、SEQ ID NO:6、SEQ ID NO:10或SEQ ID NO:14的序列。在各实施例中,重链可变结构域是SEQ ID NO:2、SEQ ID NO:6、SEQID NO:10或SEQ ID NO:14的序列。例如,轻链可变结构域可以包含SEQ ID NO:4、SEQ IDNO:8、SEQ ID NO:12或SEQ ID NO:16的序列。在各实施例中,轻链可变结构域是SEQ ID NO:4、SEQ ID NO:8、SEQ ID NO:12或SEQ ID NO:16的序列。
在各实施例中,嵌合抗原受体进一步包含重链恒定结构域。在各实施例中,嵌合抗原受体进一步包含间隔子区。在各实施例中,间隔子区位于跨膜结构域与抗体区之间。在各实施例中,间隔子区进一步包含铰链区。在各实施例中,间隔子区包含SEQ ID NO:94的序列。在各实施例中,间隔子区包含SEQ ID NO:95的序列。在各实施例中,间隔子区包含SEQID NO:96的序列。
在各实施例中,嵌合抗原受体进一步包含连接子结构域。在各实施例中,连接子结构域位于重链可变结构域与轻链可变结构域之间。在各实施例中,连接子结构域包含SEQID NO:82的序列。在各实施例中,嵌合抗原受体进一步包含前导肽。在各实施例中,前导肽包含SEQ ID NO:93的序列。
在各实施例中,嵌合抗原受体包含SEQ ID NO:100的序列。在各实施例中,嵌合抗原受体是SEQ ID NO:100的序列。在各实施例中,嵌合抗原受体包含SEQ ID NO:101的序列。在各实施例中,嵌合抗原受体是SEQ ID NO:101的序列。
在一个实施例中,嵌合抗原受体从N端到C端包含:SEQ ID NO:93的前导肽、SEQ IDNO:4的轻链可变结构域、SEQ ID NO:82的连接子结构域、SEQ ID NO:2的重链可变结构域、SEQ ID NO:96的间隔子结构域、SEQ ID NO:97的跨膜结构域、SEQ ID NO:98的胞内共刺激信号传导结构域以及SEQ ID NO:99的胞内T细胞信号传导结构域。
在一个实施例中,蛋白质从N端到C端包含:SEQ ID NO:93的前导肽、SEQ ID NO:8的轻链可变结构域、SEQ ID NO:82的连接子结构域、SEQ ID NO:6的重链可变结构域、SEQID NO:96的间隔子结构域、SEQ ID NO:97的跨膜结构域、SEQ ID NO:98的胞内共刺激信号传导结构域以及SEQ ID NO:99的胞内T细胞信号传导结构域。
双特异性抗体
如本文提供的轻链可变(VL)结构域和重链可变(VH)结构域可以形成双特异性抗体的一部分。因此,第二抗体区可以包含本文提供的轻链和/或重链可变结构域(包含其实施例)中的任何一个。
因此,在另一方面提供了一种双特异性抗体,其包含:(i)第一抗体区,所述第一抗体区能够与效应细胞配体结合;以及(ii)第二抗体区,所述第二抗体区包含:(a)重链可变结构域,所述重链可变结构域包含如SEQ ID NO:25中所示的CDR H1、如SEQ ID NO:26中所示的CDR H2和如SEQ ID NO:27中所示的CDR H3;以及(b)如SEQ ID NO:28中所示的CDR L1、如SEQ ID NO:29中所示的CDR L2和如SEQ ID NO:30中所示的CDR L3。
在另一方面提供了一种双特异性抗体,其包含:(i)第一抗体区,所述第一抗体区能够与效应细胞配体结合;以及(ii)第二抗体区,所述第二抗体区包含:(a)重链可变结构域,所述重链可变结构域包含如SEQ ID NO:31中所示的CDR H1、如SEQ ID NO:32中所示的CDR H2和如SEQ ID NO:33中所示的CDR H3;以及(b)如SEQ ID NO:34中所示的CDR L1、如SEQ ID NO:35中所示的CDR L2和如SEQ ID NO:36中所示的CDR L3。
在另一方面提供了一种双特异性抗体,其包含:(i)第一抗体区,所述第一抗体区能够与效应细胞配体结合;以及(ii)第二抗体区,所述第二抗体区包含:(a)重链可变结构域,所述重链可变结构域包含如SEQ ID NO:37中所示的CDR H1、如SEQ ID NO:38中所示的CDR H2和如SEQ ID NO:39中所示的CDR H3;以及(b)如SEQ ID NO:40中所示的CDR L1、如SEQ ID NO:41中所示的CDR L2和如SEQ ID NO:42中所示的CDR L3。
在另一方面提供了一种双特异性抗体,其包含:(i)第一抗体区,所述第一抗体区能够与效应细胞配体结合;以及(ii)第二抗体区,所述第二抗体区包含:(a)重链可变结构域,所述重链可变结构域包含如SEQ ID NO:43中所示的CDR H1、如SEQ ID NO:44中所示的CDR H2和如SEQ ID NO:45中所示的CDR H3;以及(b)如SEQ ID NO:46中所示的CDR L1、如SEQ ID NO:47中所示的CDR L2和如SEQ ID NO:48中所示的CDR L3。
如本文提供的术语“效应细胞配体”是指在免疫系统的效应细胞(例如,细胞毒性T细胞、辅助T细胞、B细胞、自然杀伤细胞)上表达的细胞表面分子。当第一抗体区与在效应细胞上表达的效应细胞配体结合时,效应细胞被激活并能够发挥其功能(例如,选择性杀伤或根除恶性、感染的或其它不健康的细胞)。在各实施例中,效应细胞配体是CD3蛋白。在各实施例中,效应细胞配体是CD16蛋白。在各实施例中,效应细胞配体是CD32蛋白。在各实施例中,效应细胞配体是NKp46蛋白。如本文提供的第一抗体区可以是抗体、抗体变体、抗体片段或抗体变体的片段。
如本文所提及的“CD3蛋白”包含分化簇3(CD3)蛋白的任何重组或天然存在的形式,或者其包括介导信号转导并维持CD3复合物活性(例如,与CD3复合物相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的CD3复合物的变体或同源物。在一些方面,与CD3复合物中的天然存在的CD3蛋白相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。
如本文所提及的术语“CD16蛋白”包含分化簇16(CD16)蛋白,也被称为低亲和力免疫球蛋白γFc区受体III-A的任何重组或天然存在的形式,或者其维持CD16活性(例如,与CD16相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的变体或同源物。在一些方面,与天然存在的CD16蛋白相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在各实施例中,CD16蛋白与由UniProt参考编号P08637鉴定的蛋白质或与其基本上相同的变体或同源物基本上相同。
如本文所提及的术语“CD32蛋白”包含分化簇32(CD32)蛋白,也被称为低亲和力免疫球蛋白γFc区受体II-A的任何重组或天然存在的形式,或者其维持CD32活性(例如,与CD32相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的变体或同源物。在一些方面,与天然存在的CD32蛋白相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在各实施例中,CD32蛋白与由UniProt参考编号P12318鉴定的蛋白质或与其基本上相同的变体或同源物基本上相同。
如本文所提及的术语“NKp46蛋白”包含NKp46蛋白,也被称为天然细胞毒性触发受体1的任何重组或天然存在的形式,或者其维持NKp46活性(例如,与NKp46相比,在至少50%、80%、90%、95%、96%、97%、98%、99%或100%活性内)的变体或同源物。在一些方面,与天然存在的NKp46蛋白相比,变体或同源物跨整个序列或序列的一部分(例如,50个、100个、150个或200个连续氨基酸部分)具有至少90%、95%、96%、97%、98%、99%或100%氨基酸序列同一性。在各实施例中,NKp46蛋白与由UniProt参考编号O76036鉴定的蛋白质或与其基本上相同的变体或同源物基本上相同。
本文提供的双特异性抗体可以包含本文所述的ROR2抗体或其片段中的任何一个。因此,第二抗体区可以包含本文提供的CDR、FR、重链可变结构域或轻链可变结构域中的任何一个。在各实施例中,第二抗体区包含包括SEQ ID NO:2的序列的重链可变结构域。在各实施例中,第二抗体区包含包括SEQ ID NO:4的序列的轻链可变结构域。在各实施例中,第二抗体区包含具有SEQ ID NO:2的序列的重链可变结构域。在各实施例中,第二抗体区包含具有SEQ ID NO:4的序列的轻链可变结构域。
因此,第二抗体区的重链可变结构域可以包含例如如SEQ ID NO:49中所示的FRH1、如SEQ ID NO:50中所示的FR H2、如SEQ ID NO:51中所示的FR H3和如SEQ ID NO:52中所示的FR H4。第二抗体区a的轻链可变结构域可以包含本文提供的CDR或FR中的任何一个。例如,轻链可变结构域可以包含例如如SEQ ID NO:53中所示的FR L1、如SEQ ID NO:54中所示的FR L2、如SEQ ID NO:55中所示的FR L3和如SEQ ID NO:56中所示的FR L4。
在各实施例中,第二抗体区包含包括SEQ ID NO:6的序列的重链可变结构域。在各实施例中,第二抗体区包含包括SEQ ID NO:8的序列的轻链可变结构域。在各实施例中,第二抗体区包含具有SEQ ID NO:6的序列的重链可变结构域。在各实施例中,第二抗体区包含具有SEQ ID NO:8的序列的轻链可变结构域。
第二抗体区的重链可变结构域可以包含例如如SEQ ID NO:57中所示的FR H1、如SEQ ID NO:58中所示的FR H2、如SEQ ID NO:59中所示的FR H3和如SEQ ID NO:60中所示的FR H4。本文提供的双特异性抗体的轻链可变结构域可以包含例如如SEQ ID NO:61中所示的FR L1、如SEQ ID NO:62中所示的FR L2、如SEQ ID NO:63中所示的FR L3和如SEQ ID NO:64中所示的FR L4。
在各实施例中,第二抗体区包含包括SEQ ID NO:10的序列的重链可变结构域。在各实施例中,第二抗体区包含包括SEQ ID NO:12的序列的轻链可变结构域。在各实施例中,第二抗体区包含具有SEQ ID NO:10的序列的重链可变结构域。在各实施例中,第二抗体区包含具有SEQ ID NO:12的序列的轻链可变结构域。
第二抗体区的重链可变结构域可以包含例如如SEQ ID NO:65中所示的FR H1、如SEQ ID NO:66中所示的FR H2、如SEQ ID NO:67中所示的FR H3和如SEQ ID NO:68中所示的FR H4。本文提供的双特异性抗体的轻链可变结构域可以包含例如如SEQ ID NO:69中所示的FR L1、如SEQ ID NO:70中所示的FR L2、如SEQ ID NO:71中所示的FR L3和如SEQ ID NO:72中所示的FR L4。
在各实施例中,第二抗体区包含包括SEQ ID NO:14的序列的重链可变结构域。在各实施例中,第二抗体区包含包括SEQ ID NO:16的序列的轻链可变结构域。在各实施例中,第二抗体区包含具有SEQ ID NO:14的序列的重链可变结构域。在各实施例中,第二抗体区包含具有SEQ ID NO:16的序列的轻链可变结构域。
第二抗体区的重链可变结构域可以包含例如如SEQ ID NO:73中所示的FR H1、如SEQ ID NO:74中所示的FR H2、如SEQ ID NO:75中所示的FR H3和如SEQ ID NO:76中所示的FR H4。本文提供的双特异性抗体的轻链可变结构域可以包含例如如SEQ ID NO:77中所示的FR L1、如SEQ ID NO:78中所示的FR L2、如SEQ ID NO:79中所示的FR L3和如SEQ ID NO:80中所示的FR L4。
在各实施例中,第一抗体区是第一Fab'片段或第二抗体区是第二Fab'片段。在各实施例中,第一抗体区是单链可变片段(scFv)或第二抗体区是第二单链可变片段(scFv)。
在各实施例中,第二抗体区的scFv以0.01nM到150nM的K
在各实施例中,第二抗体区的scFv以0.01nM到140nM的K
在各实施例中,第二抗体区的scFv以约0.07nM的K
第二抗体区可以包含轻链可变(VL)结构域或重链可变(VH)结构域。在各实施例中,第二抗体区包含轻链可变(VL)结构域。在各实施例中,第二抗体区包含重链可变(VH)结构域。
在各实施例中,第二抗体区与ROR2蛋白结合。在各实施例中,ROR2蛋白在细胞上表达。在各实施例中,细胞是癌细胞。在各实施例中,癌细胞是癌症是乳腺癌细胞、卵巢癌细胞、胰腺癌细胞、宫颈癌细胞、胃癌细胞、肾癌细胞、头颈癌细胞、骨癌细胞、皮肤癌细胞或前列腺癌细胞。在各实施例中,癌细胞是乳腺癌细胞。在各实施例中,癌细胞是卵巢癌细胞。在各实施例中,癌细胞是胰腺癌细胞。在各实施例中,癌细胞是癌症是宫颈癌细胞。在各实施例中,癌细胞是癌症是胃癌细胞。在各实施例中,癌细胞是癌症是肾癌细胞。在各实施例中,癌细胞是癌症是头颈癌细胞。在各实施例中,癌细胞是癌症是骨癌细胞。在各实施例中,癌细胞是癌症是皮肤癌细胞。在各实施例中,癌细胞是癌症是前列腺癌细胞。
核酸组合物
本文提供的组合物包含编码本文提供的抗ROR2抗体、CAR和双特异性抗体或其部分(包含其实施例)的核酸分子。贯穿本申请详细描述了由分离的核酸编码的抗体、CAR和双特异性抗体(包含上文和实例部分中的描述)。因此,在一方面,提供了一种编码如本文提供的抗体(包含其实施例)的分离的核酸。
在各实施例中,分离的核酸编码本文提供的可变重链结构域或可变轻链结构域。在各实施例中,分离的核酸编码可变重链结构域。在各实施例中,分离的核酸编码可变轻链结构域。在各实施例中,分离的核酸包含SEQ ID NO:1的序列。在各实施例中,分离的核酸包含SEQ ID NO:3的序列。在各实施例中,分离的核酸包含SEQ ID NO:5的序列。在各实施例中,分离的核酸包含SEQ ID NO:7的序列。在各实施例中,分离的核酸包含SEQ ID NO:9的序列。在各实施例中,分离的核酸包含SEQ ID NO:11的序列。在各实施例中,分离的核酸包含SEQ ID NO:13的序列。在各实施例中,分离的核酸包含SEQ ID NO:15的序列。
在另一方面,提供了一种编码如本文提供的抗体(包含其实施例)的分离的核酸。在各实施例中,分离的核酸包含SEQ ID NO:91的序列。在各实施例中,分离的核酸包含SEQID NO:92的序列。
在另一方面,提供了一种编码如本文提供的嵌合抗原受体(包含其实施例)的分离的核酸。在各实施例中,分离的核酸包含SEQ ID NO:111的序列。在各实施例中,分离的核酸包含SEQ ID NO:112的序列。
药物组合物
本文提供的组合物包含药物组合物,所述药物组合物包含本文提供的抗抗ROR2抗体、CAR和双特异性抗体(包含其实施例)。因此,在一方面提供了一种药物组合物,所述药物组合物包含治疗有效量的如本文提供的抗体(包含其实施例)和药学上可接受的赋形剂。
在另一方面提供了一种药物组合物,所述药物组合物包含治疗有效量的如本文提供的CAR(包含其实施例)和药学上可接受的赋形剂。
在另一方面提供了一种药物组合物,所述药物组合物包含治疗有效量的如本文提供的双特异性抗体(包含其实施例)和药学上可接受的赋形剂。
治疗方法
本文提供的组合物(例如,抗ROR2抗体、CAR和双特异性抗体)(包含其实施例)被设想为提供对如癌症(例如,乳腺癌)等疾病的有效治疗。
因此,在一方面提供了一种治疗有需要的受试者的癌症的方法,所述方法包含向受试者施用治疗有效量的如本文提供的抗体(包含其实施例)。在另一方面提供了一种抑制有需要的受试者的表达ROR2的癌症的转移的方法,所述方法包含向受试者施用治疗有效量的本文提供的抗体(包含其实施例)。
在另一方面提供了一种治疗有需要的受试者的癌症的方法,所述方法包含向受试者施用治疗有效量的本文提供的嵌合抗原受体(包含其实施例)。
在各实施例中,癌症是实体瘤恶性肿瘤。在各实施例中,癌症是乳腺癌、卵巢癌、胰腺癌、宫颈癌、胃癌、肾癌、头颈癌、骨癌、皮肤癌或前列腺癌。在各实施例中,癌症是乳腺癌。在各实施例中,癌症是卵巢癌。在各实施例中,癌症是胰腺癌。在各实施例中,癌症是宫颈癌。在各实施例中,癌症是胃癌。在各实施例中,癌症是肾癌。在各实施例中,癌症是头颈癌。在各实施例中,癌症是骨癌。在各实施例中,癌症是皮肤癌。在各实施例中,癌症是前列腺癌。
在一方面提供了一种检测表达ROR2的细胞的方法,所述方法包含(i)使表达ROR2的细胞与本文提供的抗体(包含其实施例)接触;(ii)以及检测所述抗体与由所述细胞表达的ROR2蛋白的结合。在各实施例中,抗体附着到可检测部分。
在一方面是一种向表达ROR2的细胞递送治疗剂的方法,所述方法包含使表达ROR2的细胞与本文提供的抗体(包含其实施例)接触,其中所述抗体附着到治疗剂。在各实施例中,治疗剂是抗癌剂。示例性抗癌剂包含但不限于本领域常规使用和本领域已知的任何抗癌剂,例如,卡奇霉素(calicheamicin)、倍癌霉素(duocarmycin)、吡咯并苯二氮卓(PBD)、SN-38、DXd和抗微管蛋白。用于产生抗体药物缀合物的方法在本领域中是众所周知的,并且例如提供以下进行描述:Hafeez,U.等人,《用于癌症疗法的抗体药物缀合物(Antibody-Drug Conjugates for Cancer Therapy)》;《分子(Molecules)》2020,25,4764;doi:10.3390/molecules25204764.;Ponziani,S.等人,《抗体药物缀合物(Antibody-DrugConjugates)》;《化疗新前沿(The New Frontier of Chemotherpy.)》《国际分子科学杂志(Int.J.Mol.Sci.)》2020,21,5510;doi:10.3390/ijms21155510.;以及Joubert,N.等人,抗体药物缀合物:过去十年(Antibody-Drug Conjugates:The Last Decade.)《制药(Pharmaceuticals)》2020,13,245;doi:10.3390/ph13090245.;所述文献通过引用整体并出于所有目的并入本文。
对于本文提供的方法,在各实施例中,接触在体外发生。在各实施例中,表达ROR2的细胞位于受试者体内。在各实施例中,受试者是健康的受试者。在各实施例中,受试者是患有癌症的受试者。在各实施例中,癌症是实体瘤恶性肿瘤。在各实施例中,癌症是乳腺癌、卵巢癌、胰腺癌、宫颈癌、胃癌、肾癌、头颈癌、骨癌、皮肤癌或前列腺癌。在各实施例中,癌症是乳腺癌。在各实施例中,癌症是卵巢癌。在各实施例中,癌症是胰腺癌。在各实施例中,癌症是宫颈癌。在各实施例中,癌症是胃癌。在各实施例中,癌症是肾癌。在各实施例中,癌症是头颈癌。在各实施例中,癌症是骨癌。在各实施例中,癌症是皮肤癌。在各实施例中,癌症是前列腺癌。
对于本文提供的方法,在各实施例中,表达ROR2的细胞是癌细胞。在各实施例中,癌细胞是癌症是乳腺癌细胞、卵巢癌细胞、胰腺癌细胞、宫颈癌细胞、胃癌细胞、肾癌细胞、头颈癌细胞、骨癌细胞、皮肤癌细胞或前列腺癌细胞。在各实施例中,癌细胞是乳腺癌细胞。在各实施例中,癌细胞是卵巢癌细胞。在各实施例中,癌细胞是胰腺癌细胞。在各实施例中,癌细胞是癌症是宫颈癌细胞。在各实施例中,癌细胞是癌症是胃癌细胞。在各实施例中,癌细胞是癌症是肾癌细胞。在各实施例中,癌细胞是癌症是头颈癌细胞。在各实施例中,癌细胞是癌症是骨癌细胞。在各实施例中,癌细胞是癌症是皮肤癌细胞。在各实施例中,癌细胞是癌症是前列腺癌细胞。
对于本文提供的方法,在各实施例中,抗体以约0.01nM到约10nM的量施用。在各实施例中,抗体以约0.05nM到约10nM的量施用。在各实施例中,抗体以约0.1nM到约10nM的量施用。在各实施例中,抗体以约0.5nM到约10nM的量施用。在各实施例中,抗体以约1nM到约10nM的量施用。在各实施例中,抗体以约2nM到约10nM的量施用。在各实施例中,抗体以约4nM到约10nM的量施用。在各实施例中,抗体以约6nM到约10nM的量施用。在各实施例中,抗体以约4nM到约10nM的量施用。在各实施例中,抗体以约8nM到约10nM的量施用。在各实施例中,抗体以约0.01nM、0.05nM、0.1nM、0.5nM、1nM、2nM、2nM、4nM、5nM、6nM、7nM、8nM、9nM或10nM的量施用。
在各实施例中,抗体以0.01nM到10nM的量施用。在各实施例中,抗体以0.05nM到10nM的量施用。在各实施例中,抗体以0.1nM到10nM的量施用。在各实施例中,抗体以0.5nM到10nM的量施用。在各实施例中,抗体以1nM到10nM的量施用。在各实施例中,抗体以2nM到10nM的量施用。在各实施例中,抗体以4nM到10nM的量施用。在各实施例中,抗体以6nM到10nM的量施用。在各实施例中,抗体以4nM到10nM的量施用。在各实施例中,抗体以8nM到10nM的量施用。在各实施例中,抗体以0.01nM、0.05nM、0.1nM、0.5nM、1nM、2nM、2nM、4nM、5nM、6nM、7nM、8nM、9nM或10nM的量施用。
在各实施例中,抗体以约0.01nM到约8nM的量施用。在各实施例中,抗体以约0.05nM到约8nM的量施用。在各实施例中,抗体以约0.1nM到约8nM的量施用。在各实施例中,抗体以约0.5nM到约8nM的量施用。在各实施例中,抗体以约1nM到约8nM的量施用。在各实施例中,抗体以约2nM到约8nM的量施用。在各实施例中,抗体以约4nM到约8nM的量施用。在各实施例中,抗体以约6nM到约8nM的量施用。在各实施例中,抗体以约4nM到约8nM的量施用。
在各实施例中,抗体以0.01nM到8nM的量施用。在各实施例中,抗体以0.05nM到8nM的量施用。在各实施例中,抗体以0.1nM到8nM的量施用。在各实施例中,抗体以0.5nM到8nM的量施用。在各实施例中,抗体以1nM到8nM的量施用。在各实施例中,抗体以2nM到8nM的量施用。在各实施例中,抗体以4nM到8nM的量施用。在各实施例中,抗体以6nM到8nM的量施用。在各实施例中,抗体以4nM到8nM的量施用。
在各实施例中,抗体以约0.01nM到约6nM的量施用。在各实施例中,抗体以约0.05nM到约6nM的量施用。在各实施例中,抗体以约0.1nM到约6nM的量施用。在各实施例中,抗体以约0.5nM到约8nM的量施用。在各实施例中,抗体以约1nM到约6nM的量施用。在各实施例中,抗体以约2nM到约6nM的量施用。在各实施例中,抗体以约4nM到约6nM的量施用。
在各实施例中,抗体以0.01nM到6nM的量施用。在各实施例中,抗体以0.05nM到6nM的量施用。在各实施例中,抗体以0.1nM到6nM的量施用。在各实施例中,抗体以0.5nM到6nM的量施用。在各实施例中,抗体以1nM到6nM的量施用。在各实施例中,抗体以2nM到6nM的量施用。在各实施例中,抗体以4nM到6nM的量施用。
在各实施例中,抗体以约0.01nM到约4nM的量施用。在各实施例中,抗体以约0.05nM到约4nM的量施用。在各实施例中,抗体以约0.1nM到约4nM的量施用。在各实施例中,抗体以约0.5nM到约4nM的量施用。在各实施例中,抗体以约1nM到约4nM的量施用。在各实施例中,抗体以约2nM到约4nM的量施用。
在各实施例中,抗体以0.01nM到4nM的量施用。在各实施例中,抗体以0.05nM到4nM的量施用。在各实施例中,抗体以0.1nM到4nM的量施用。在各实施例中,抗体以0.5nM到4nM的量施用。在各实施例中,抗体以1nM到4nM的量施用。在各实施例中,抗体以2nM到4nM的量施用。
在各实施例中,抗体以约0.01nM到约2nM的量施用。在各实施例中,抗体以约0.05nM到约2nM的量施用。在各实施例中,抗体以约0.1nM到约2nM的量施用。在各实施例中,抗体以约0.5nM到约2nM的量施用。在各实施例中,抗体以约1nM到约2nM的量施用。
在各实施例中,抗体以0.01nM到2nM的量施用。在各实施例中,抗体以0.05nM到2nM的量施用。在各实施例中,抗体以0.1nM到2nM的量施用。在各实施例中,抗体以0.5nM到2nM的量施用。在各实施例中,抗体以1nM到2nM的量施用。
在各实施例中,抗体以约0.01nM到约1nM的量施用。在各实施例中,抗体以约0.05nM到约1nM的量施用。在各实施例中,抗体以约0.1nM到约1nM的量施用。在各实施例中,抗体以约0.5nM到约1nM的量施用。
在各实施例中,抗体以0.01nM到1nM的量施用。在各实施例中,抗体以0.05nM到1nM的量施用。在各实施例中,抗体以0.1nM到1nM的量施用。在各实施例中,抗体以0.5nM到1nM的量施用。
在各实施例中,抗体以约3.15nM的量施用。在各实施例中,抗体以3.15nM的量施用。在各实施例中,抗体以约1.05nM的量施用。在各实施例中,抗体以1.05nM的量施用。
应当理解,本文提供的双特异性抗体或嵌合抗原受体(包含其实施例)可以以本文针对施用抗体所描述的浓度中的任何浓度(例如,0.01nM-10nM)施用。
在各实施例中,抗体以约10μg到约500μg的量施用。在各实施例中,抗体以约20μg到约500μg的量施用。在各实施例中,抗体以约30μg到约500μg的量施用。在各实施例中,抗体以约40μg到约500μg的量施用。在各实施例中,抗体以约50μg到约500μg的量施用。在各实施例中,抗体以约60μg到约500μg的量施用。在各实施例中,抗体以约70μg到约500μg的量施用。在各实施例中,抗体以约80μg到约500μg的量施用。在各实施例中,抗体以约90μg到约500μg的量施用。在各实施例中,抗体以约100μg到约500μg的量施用。
在各实施例中,抗体以约110μg到约500μg的量施用。在各实施例中,抗体以约120μg到约500μg的量施用。在各实施例中,抗体以约130μg到约500μg的量施用。在各实施例中,抗体以约140μg到约500μg的量施用。在各实施例中,抗体以约150μg到约500μg的量施用。在各实施例中,抗体以约160μg到约500μg的量施用。在各实施例中,抗体以约170μg到约500μg的量施用。在各实施例中,抗体以约180μg到约500μg的量施用。在各实施例中,抗体以约190μg到约500μg的量施用。在各实施例中,抗体以约200μg到约500μg的量施用。
在各实施例中,抗体以约210μg到约500μg的量施用。在各实施例中,抗体以约220μg到约500μg的量施用。在各实施例中,抗体以约230μg到约500μg的量施用。在各实施例中,抗体以约240μg到约500μg的量施用。在各实施例中,抗体以约250μg到约500μg的量施用。在各实施例中,抗体以约260μg到约500μg的量施用。在各实施例中,抗体以约270μg到约500μg的量施用。在各实施例中,抗体以约280μg到约500μg的量施用。在各实施例中,抗体以约290μg到约500μg的量施用。在各实施例中,抗体以约300μg到约500μg的量施用。
在各实施例中,抗体以约310μg到约500μg的量施用。在各实施例中,抗体以约320μg到约500μg的量施用。在各实施例中,抗体以约330μg到约500μg的量施用。在各实施例中,抗体以约340μg到约500μg的量施用。在各实施例中,抗体以约350μg到约500μg的量施用。在各实施例中,抗体以约360μg到约500μg的量施用。在各实施例中,抗体以约370μg到约500μg的量施用。在各实施例中,抗体以约380μg到约500μg的量施用。在各实施例中,抗体以约390μg到约500μg的量施用。在各实施例中,抗体以约400μg到约500μg的量施用。
在各实施例中,抗体以约410μg到约500μg的量施用。在各实施例中,抗体以约420μg到约500μg的量施用。在各实施例中,抗体以约430μg到约500μg的量施用。在各实施例中,抗体以约440μg到约500μg的量施用。在各实施例中,抗体以约450μg到约500μg的量施用。在各实施例中,抗体以约460μg到约500μg的量施用。在各实施例中,抗体以约470μg到约500μg的量施用。在各实施例中,抗体以约480μg到约500μg的量施用。在各实施例中,抗体以约490μg到约500μg的量施用。
在各实施例中,抗体以约10μg到约400μg的量施用。在各实施例中,抗体以约20μg到约400μg的量施用。在各实施例中,抗体以约30μg到约400μg的量施用。在各实施例中,抗体以约40μg到约400μg的量施用。在各实施例中,抗体以约50μg到约400μg的量施用。在各实施例中,抗体以约60μg到约400μg的量施用。在各实施例中,抗体以约70μg到约400μg的量施用。在各实施例中,抗体以约80μg到约400μg的量施用。在各实施例中,抗体以约90μg到约400μg的量施用。在各实施例中,抗体以约100μg到约400μg的量施用。
在各实施例中,抗体以约10μg到约300μg的量施用。在各实施例中,抗体以约20μg到约300μg的量施用。在各实施例中,抗体以约30μg到约300μg的量施用。在各实施例中,抗体以约40μg到约300μg的量施用。在各实施例中,抗体以约50μg到约300μg的量施用。在各实施例中,抗体以约60μg到约300μg的量施用。在各实施例中,抗体以约70μg到约300μg的量施用。在各实施例中,抗体以约80μg到约300μg的量施用。在各实施例中,抗体以约90μg到约300μg的量施用。在各实施例中,抗体以约100μg到约300μg的量施用。
在各实施例中,抗体以约10μg到约200μg的量施用。在各实施例中,抗体以约20μg到约200μg的量施用。在各实施例中,抗体以约30μg到约200μg的量施用。在各实施例中,抗体以约40μg到约200μg的量施用。在各实施例中,抗体以约50μg到约200μg的量施用。在各实施例中,抗体以约60μg到约200μg的量施用。在各实施例中,抗体以约70μg到约200μg的量施用。在各实施例中,抗体以约80μg到约200μg的量施用。在各实施例中,抗体以约90μg到约200μg的量施用。在各实施例中,抗体以约100μg到约200μg的量施用。
在各实施例中,抗体以约10μg到约100μg的量施用。在各实施例中,抗体以约20μg到约100μg的量施用。在各实施例中,抗体以约30μg到约100μg的量施用。在各实施例中,抗体以约40μg到约100μg的量施用。在各实施例中,抗体以约50μg到约100μg的量施用。在各实施例中,抗体以约60μg到约100μg的量施用。在各实施例中,抗体以约70μg到约100μg的量施用。在各实施例中,抗体以约80μg到约100μg的量施用。在各实施例中,抗体以约90μg到约100μg的量施用。
在各实施例中,抗体以约10μg、20μg、30μg、40μg、50μg、60μg、70μg、80μg、90μg、100μg、110μg、120μg、130μg、140μg、150μg、160μg、170μg、180μg、190μg、200μg、210μg、220μg、230μg、240μg、250μg、260μg、270μg、280μg、290μg、300μg、310μg、320μg、330μg、340μg、350μg、360μg、370μg、380μg、390μg、400μg、410μg、420μg、430μg、440μg、450μg、460μg、470μg、480μg、490μg或500μg的量施用。
在各实施例中,抗体以10μg、20μg、30μg、40μg、50μg、60μg、70μg、80μg、90μg、100μg、110μg、120μg、130μg、140μg、150μg、160μg、170μg、180μg、190μg、200μg、210μg、220μg、230μg、240μg、250μg、260μg、270μg、280μg、290μg、300μg、310μg、320μg、330μg、340μg、350μg、360μg、370μg、380μg、390μg、400μg、410μg、420μg、430μg、440μg、450μg、460μg、470μg、480μg、490μg或500μg的量施用。
应当理解,本文提供的双特异性抗体或嵌合抗原受体(包含其实施例)可以以本文针对施用抗体所描述的浓度中的任何浓度(例如,10μg-500μg)施用。
抑制细胞迁移的方法
本文提供的组合物(包含其实施例)被进一步设想用于抑制细胞迁移。因此,在一方面提供了一种抑制表达ROR2的细胞的迁移的方法,所述方法包含使表达ROR2的细胞与本文提供的抗体(包含其实施例)接触。在各实施例中,抗体包含重链可变结构域和轻链可变结构域,其中所述重链可变结构域包含:如SEQ ID NO:25中所示的CDR H1、如SEQ ID NO:26中所示的CDR H2和如SEQ ID NO:27中所示的CDR H3;并且其中所述轻链可变结构域包含:如SEQ ID NO:28中所示的CDR L1、如SEQ ID NO:29中所示的CDR L2和如SEQ ID NO:30中所示的CDR L3。
对于本文提供的方法,在各实施例中,表达ROR2的细胞是癌细胞。在各实施例中,癌细胞是癌症是乳腺癌细胞、卵巢癌细胞、胰腺癌细胞、宫颈癌细胞、胃癌细胞、肾癌细胞、头颈癌细胞、骨癌细胞、皮肤癌细胞或前列腺癌细胞。在各实施例中,癌症是癌症是乳腺癌。在各实施例中,癌细胞是卵巢癌细胞。在各实施例中,癌细胞是胰腺癌细胞。在各实施例中,癌细胞是癌症是宫颈癌细胞。在各实施例中,癌细胞是癌症是胃癌细胞。在各实施例中,癌细胞是癌症是肾癌细胞。在各实施例中,癌细胞是癌症是头颈癌细胞。在各实施例中,癌细胞是癌症是骨癌细胞。在各实施例中,癌细胞是癌症是皮肤癌细胞。在各实施例中,癌细胞是癌症是前列腺癌细胞。
应当理解,本文所描述的实例和实施例仅是出于说明性目的,并且根据其进行的各种修改或改变将启发本领域的技术人员并且将被包含在本申请的精神与权限范围内和所附权利要求书的范围内。本文所引用的所有出版物、专利和专利申请均出于所有目的特此通过引用整体并入。
实例
实例1:
由于其在癌细胞中的表达,ROR2具有充当诊断和治疗靶标的潜力。据报道,已经产生与ROR2结合并且可从商业来源获得的单克隆抗体。然而,申请人发现,若干单克隆抗体通过免疫印迹和/或流式细胞术与表达ROR2的细胞发生反应。另外,申请人发现,这些抗体中的若干抗体还出乎意料地与使用CRISPR-Cas9技术缺失ROR2的细胞发生反应。这种出乎意料的结合揭示,许多可商购获得的抗体对ROR2不具有特异性。
因此,申请人产生特异性靶向人ROR2的胞外部分的单克隆抗体。为此,用包含Ig样、富含半胱氨酸的结构域(CRD)和Kringle结构域(图1)的ROR2蛋白的胞外部分(AA1-403)的重组蛋白对小鼠进行免疫。由于鼠与人分子之间的高度同源性,所以申请人共注射免疫刺激剂,如弗氏完全佐剂(Freund's Complete Adjuvant),以使抗人ROR2抗体的产生最大化。使用ELISA和流式细胞术筛选脾细胞与骨髓瘤融合伴侣融合后产生的杂交瘤中的抗ROR2 mAb的表达,以鉴定产生与人ROR2特异性结合的抗体的克隆。这些抗体在本公开中被指定为mAb N-LN或更熟悉的形式6-E6,列于表1中,并且重链和轻链可变区的序列描绘于图2中。
表1:抗人ROR2单克隆抗体的表征
申请人在ELISA测定中使用重组ROR2胞外蛋白评估每种mAb的结合特异性和相对亲和力,其中使用减少/限制量的ROR2蛋白来测量结合,并且与四种mAb中的每种mAb的降低浓度组合地评估结合(图3)。在较低的ROR2蛋白量和较低的mAb浓度两者下,6E6和4G9的较高吸光度值指示这些mAb与5C11和5G3相比具有较高亲和力。在测量溶液中的未经修饰分子之间的平衡结合亲和力和动力学的动力学排除测定(KinExA)中测量平衡解离常数(Kd)。6E6 mAb以约0.1nM的Kd与靶ROR2胞外序列结合。4G9以约2nM的Kd与人ROR2的胞外结构域结合(图4A和4B)。5C11和5G3 mAb的分析确定,各自的Kd大于约40nM,这与上述ELISA分析的结果一致。
申请人开发了分离人ROR2蛋白的特定结构域的一系列重组人/小鼠杂交蛋白。这些重组蛋白用于鉴定四个mAb靶标中的每个mAb靶标的特异性结合结构域(图5)。6E6和5C11mAb与人而非小鼠ROR2的Kringle结构域结合。4G9和5G3 mAb结合在人ROR2的前111aa内,其包含Ig样结构域。四种mAb均不与小鼠ROR2结合。
申请人还改进了这一程序,以鉴定对于结合在Kringle结构域内的两种抗ROR2mAb的结合至关重要的特异性氨基酸(图6)。申请人产生若干重组人ROR2蛋白,其中在Kringle结构域内的人与小鼠ROR2之间不同的氨基酸之一被小鼠ROR2的对应氨基酸替代。6E6和5C11 mAb的结合的评估表明,其需要位置349处的组氨酸残基和位置354处的天冬氨酸以与人ROR2的Kringle结构域结合,因为这些氨基酸分别被鼠分子的精氨酸和谷氨酸残基替代,6E6和5C11 mAb不再与ROR2蛋白结合。另外,5C11需要位置386处的甲硫氨酸残基,因为在甲硫氨酸被小鼠ROR2的缬氨酸替代后失去结合。
所述mAb中的每种mAb与人ROR2的结合通过流式细胞术染色和使用与Alexa647缀合的每种mAb分析已知表达ROR2的若干细胞系来验证(图7A)。通过与HCT116结肠直肠癌细胞和HEK293细胞的结合的缺乏来验证特异性,其中使用CRISPR-cas9来消除ROR2表达(图7B)。这些mAb的特异性的验证使其与许多可商购获得的抗人ROR2多克隆和单克隆抗体分开,因为在最近几年中,已经广泛用于公开研究中的一些抗体随后已经被召回并且不再可用,因为其被确定为对ROR2不具有特异性。
另外,6E6和4G9 mAb已经在原代人细胞上进行测试。与用等量的同种型匹配的Alex647缀合的对照抗体染色相比,6E6和4G9各自染色BR1936上的ROR2,而非BR1367(ROR2阴性),人乳腺癌PDX细胞(图8)。6E6和4G9均未表现出与从若干健康供体分离的外周血单核细胞的结合(图9)。
6E6和4G9的初始功能研究表明,如通过与pH敏感染料pHrodo缀合的6E6和4G9 mAb的相对荧光增加所评估的,每种mAb被内化。在用饱和量的pHrodo缀合的mAb染色后,将细胞洗涤,在37℃或4℃下温育2小时,并且通过流式细胞术分析与pHrodo和较低的胞内pH相关的相对细胞荧光的变化(图10),这表明抗体被内化到表达ROR2的经处理细胞的初级核内体和溶酶体中。相对于未染色细胞或在4℃下温育的细胞,6E6和4G9 mAb两者在K562细胞中在37℃下具有增加的相对荧光,并且对于缺乏ROR2表达的JEKO细胞在任一温度下均未显示出差异。申请人发现,6E6内化的效率高于4G9。因为已经证明内化到初级核内体/溶酶体中的抗体是用于将药物或与其缀合的其它分子递送到表达靶抗原的细胞的有效媒剂,在这种情况下是ROR2,所以申请人从这些数据中得出结论:6E6作为然后可以靶向表达ROR2的细胞的抗体药物缀合物(或ADC)中的抗体是非常有效的。
因此,靶向由6E6识别的表位的抗体可以用于以允许药物/化合物内化到细胞中并且在ROR2细胞内具有活性的方式将药物或其它化合物有效地递送到表达ROR2的细胞。这允许ROR2阳性细胞在体内的选择性靶向。另外,这些抗体可以用于用可以鉴定表达ROR2的细胞的药剂靶向表达ROR2的细胞,以在ROR2阳性癌细胞的外科手术提取期间进行诊断成像或荧光鉴定。
ROR2的肿瘤细胞表达可以具有功能显著性。用编码ROR2的表达载体转染乳腺癌细胞系MCF7产生表达表面ROR2的MCF7-ROR2细胞。MCF7-ROR2细胞对Wnt5a的应答比不表达ROR2的亲本MCF7细胞具有增强的运动性和组织侵袭性。运动性和侵袭性的增加与免疫缺陷小鼠中形成转移性肿瘤的能力增强相关,这已经使用转染以表达ROR1的MCF7细胞观察到。
申请人通过将6E6或4G9的轻链和重链的可变区组合到人IgG1的恒定区(CH2-CH3)上来产生单链Fv(scFv)。这些单链构建体的可变区包含连接两种抗体的轻和重可变区的连接子序列。申请人发现,针对6E6或4G9的scFv通过ELISA与ROR2抗原结合,并且可以与表达ROR2表面抗原的细胞特异性结合(图12)。因此,6E6或4G9 scFv保留其对靶抗原的特异性和结合活性。此类scFv还可以用于产生双特异性抗体,所述双特异性抗体将6E6或4G9的scFv与另一种scFv,如识别由T细胞表达的表面抗原(例如,CD3)的scFv连接。出于杀伤用此类双特异性抗体治疗的患者的表达ROR2的细胞的目的,这些嵌合双特异性分子可以用于细胞免疫激活。
scFv以高特异性和亲和力与ROR2蛋白结合的能力允许产生嵌合抗原受体(CAR),所述受体可以转导到T细胞或NK细胞中以产生能够特异性杀伤表达ROR2表面抗原的细胞的细胞毒性效应细胞。申请人已经使用6E6或4G9 scFv的可变区序列产生CAR构建体。申请人发现,用这些构建体转染细胞可以产生表达与ROR2的胞外结构域结合的表面CAR的细胞。为了证明这一点,申请人产生了称为ROR2-Ig的重组蛋白,其包含人IgG1的ROR2胞外结构域和CH2-CH3恒定区结构域。申请人还产生了称为ROR1-Ig的重组蛋白,其包含人IgG1的ROR1的胞外结构域和CH2-CH3恒定区结构域。这允许分离具有ROR2或ROR1的胞外结构域的可溶性蛋白。申请人发现,用从6E6或4G9的scFv产生的ROR2-CAR构建体转染的细胞可以与ROR2-Ig特异性结合,但不与高度相关的ROR1-Ig结合,这证明了这种相互作用的特异性(图13)。因此,具有从6E6或4G9产生的序列的scFv或其人源化对应物可以用于产生对表达ROR2的细胞具有特异性细胞毒性的ROR2特异性CAR T细胞或CAR NK细胞。
基于这些临床前发现,申请人相信这些抗人ROR2 mAb对人ROR2具有高亲和力和特异性,并且可以用于靶向各种人癌症的ROR2。
实施例
实施例1.一种抗酪氨酸激酶样孤儿受体2(ROR2)抗体,其包括重链可变结构域和轻链可变结构域,其中所述重链可变结构域包括:如SEQ ID NO:25中所示的CDR H1、如SEQID NO:26中所示的CDR H2和如SEQ ID NO:27中所示的CDR H3;并且其中所述轻链可变结构域包括:如SEQ ID NO:28中所示的CDR L1、如SEQ ID NO:29中所示的CDR L2和如SEQ IDNO:30中所示的CDR L3。
实施例2.根据实施例1所述的抗体,其中所述重链可变结构域包括SEQ ID NO:2的序列。
实施例3.根据实施例1或2所述的抗体,其中所述轻链可变结构域包括SEQ ID NO:4的序列。
实施例4.根据实施例1到3中任一项所述的抗体,其中所述抗体是人源化抗体。
实施例5.根据实施例1到4中任一项所述的抗体,其中所述抗体是Fab'片段。
实施例6.根据实施例1到4中任一项所述的抗体,其中所述抗体是单链抗体(scFv)。
实施例7.根据实施例1到3中任一项所述的抗体,其中所述抗体是嵌合抗体。
实施例8.根据实施例1到4中任一项所述的抗体,其中所述抗体是IgG。
实施例9.根据实施例1到4或8中任一项所述的抗体,其中所述抗体是IgG1或IgG2。
实施例10.根据实施例1到9中任一项所述的抗体,其中所述抗体能够与ROR2蛋白结合。
实施例11.根据实施例10所述的抗体,其中所述ROR2蛋白包括SEQ ID NO:18的氨基酸序列。
实施例12.根据实施例10或11所述的抗体,其中所述抗体能够与所述ROR2蛋白的胞外结构域结合。
实施例13.根据实施例12所述的抗体,其中所述胞外结构域包括SEQ ID NO:22的氨基酸序列。
实施例14.根据实施例12所述的抗体,其中所述胞外结构域是Kringle结构域。
实施例15.根据实施例10到14中任一项所述的抗体,其中所述ROR2蛋白包括位于与SEQ ID NO:22的位置349相对应的位置处的组氨酸或位于与位置354相对应的位置处的天冬氨酸。
实施例16.根据实施例10到15中任一项所述的抗体,其中所述ROR2蛋白在细胞上表达。
实施例17.根据实施例16所述的抗体,其中所述细胞是癌细胞。
实施例18.根据实施例17所述的抗体,其中所述癌细胞是乳腺癌细胞、卵巢癌细胞、胰腺癌细胞、宫颈癌细胞、胃癌细胞、肾癌细胞、头颈癌细胞、骨癌细胞、皮肤癌细胞或前列腺癌细胞。
实施例19.根据实施例10到18中任一项所述的抗体,其中所述抗体能够以约0.01nM到约1nM的平衡解离常数(K
实施例20.根据实施例10到19中任一项所述的抗体,其中所述抗体能够以约0.06nM的平衡解离常数(K
实施例21.根据实施例1到20中任一项所述的抗体,其中所述抗体附着到治疗剂。
实施例22.根据实施例1到20中任一项所述的抗体,其中所述抗体附着到诊断剂。
实施例23.一种抗酪氨酸激酶样孤儿受体2(ROR2)抗体,其包括重链可变结构域和轻链可变结构域,其中所述重链可变结构域包括:如SEQ ID NO:31中所示的CDR H1、如SEQID NO:32中所示的CDR H2和如SEQ ID NO:33中所示的CDR H3;并且其中所述轻链可变结构域包括:如SEQ ID NO:34中所示的CDR L1、如SEQ ID NO:35中所示的CDR L2和如SEQ IDNO:36中所示的CDR L3。
实施例24.根据实施例23所述的抗体,其中所述重链可变结构域包括SEQ ID NO:6的序列。
实施例25.根据实施例23或24所述的抗体,其中所述轻链可变结构域包括SEQ IDNO:8的序列。
实施例26.根据实施例23到25中任一项所述的抗体,其中所述抗体是人源化抗体。
实施例27.根据实施例23到26中任一项所述的抗体,其中所述抗体是Fab'片段。
实施例28.根据实施例23到26中任一项所述的抗体,其中所述抗体是单链抗体(scFv)。
实施例29.根据实施例23到25中任一项所述的抗体,其中所述抗体是嵌合抗体。
实施例30.根据实施例23到26中任一项所述的抗体,其中所述抗体是IgG。
实施例31.根据实施例23到26或30中任一项所述的抗体,其中所述抗体是IgG1或IgG2。
实施例32.根据实施例23到31中任一项所述的抗体,其中所述抗体能够与包括SEQID NO:18的氨基酸序列的ROR2蛋白结合。
实施例33.根据实施例32所述的抗体,其中所述抗体能够与所述ROR2蛋白的胞外结构域结合。
实施例34.根据实施例33所述的抗体,其中所述胞外结构域包括SEQ ID NO:22的氨基酸序列。
实施例35.根据实施例33所述的抗体,其中所述胞外结构域是Ig样结构域。
实施例36.根据实施例32到35中任一项所述的抗体,其中所述ROR2蛋白包括位于与SEQ ID NO:22的位置386相对应的位置处的甲硫氨酸。
实施例37.根据实施例32到36中任一项所述的抗体,其中所述ROR2蛋白在细胞上表达。
实施例38.根据实施例37所述的抗体,其中所述细胞是癌细胞。
实施例39.根据实施例38所述的抗体,其中所述癌细胞是乳腺癌细胞、卵巢癌细胞、胰腺癌细胞、宫颈癌细胞、胃癌细胞、肾癌细胞、头颈癌细胞、骨癌细胞、皮肤癌细胞或前列腺癌细胞。
实施例40.根据实施例32到39中任一项所述的抗体,其中所述抗体能够以约0.2nM到约5nM的平衡解离常数(K
实施例41.根据实施例32到40中任一项所述的抗体,其中所述抗体能够以约1.9nM的平衡解离常数(K
实施例42.根据实施例23到41中任一项所述的抗体,其中所述抗体与治疗剂缀合。
实施例43.根据实施例23到41中任一项所述的抗体,其中所述抗体与诊断剂缀合。
实施例44.一种抗酪氨酸激酶样孤儿受体2(ROR2)抗体,其包括重链可变结构域和轻链可变结构域,其中所述重链可变结构域包括:如SEQ ID NO:37中所示的CDR H1、如SEQID NO:38中所示的CDR H2和如SEQ ID NO:39中所示的CDR H3;并且其中所述轻链可变结构域包括:如SEQ ID NO:40中所示的CDR L1、如SEQ ID NO:41中所示的CDR L2和如SEQ IDNO:42中所示的CDR L3。
实施例45.根据实施例44所述的抗体,其中所述重链可变结构域包括SEQ ID NO:10的序列。
实施例46.根据实施例44或45所述的抗体,其中所述轻链可变结构域包括SEQ IDNO:12的序列。
实施例47.根据实施例44到46中任一项所述的抗体,其中所述抗体是人源化抗体。
实施例48.根据实施例44到47中任一项所述的抗体,其中所述抗体是Fab'片段。
实施例49.根据实施例44到47中任一项所述的抗体,其中所述抗体是单链抗体(scFv)。
实施例50.根据实施例44到46中任一项所述的抗体,其中所述抗体是嵌合抗体。
实施例51.根据实施例44到47中任一项所述的抗体,其中所述抗体是IgG。
实施例52.根据实施例44到47或51中任一项所述的抗体,其中所述抗体是IgG1。
实施例53.根据实施例44到52中任一项所述的抗体,其中所述抗体能够与包括SEQID NO:18的氨基酸序列的ROR2蛋白结合。
实施例54.根据实施例53所述的抗体,其中所述抗体能够与ROR2蛋白的胞外结构域结合。
实施例55.根据实施例54所述的抗体,其中所述胞外结构域包括SEQ ID NO:22的氨基酸序列。
实施例56.根据实施例54所述的抗体,其中所述胞外结构域是Kringle结构域。
实施例57.根据实施例53到56中任一项所述的抗体,其中所述ROR2蛋白包括位于与SEQ ID NO:22的位置349相对应的位置处的组氨酸、位于与位置354相对应的位置处的天冬氨酸或位于与位置386相对应的位置处的甲硫氨酸。
实施例58.根据实施例43到57中任一项所述的抗体,其中所述ROR2蛋白在细胞上表达。
实施例59.根据实施例58所述的抗体,其中所述细胞是癌细胞。
实施例60.根据实施例59所述的抗体,其中所述癌细胞是乳腺癌细胞、卵巢癌细胞、胰腺癌细胞、宫颈癌细胞、胃癌细胞、肾癌细胞、头颈癌细胞、骨癌细胞、皮肤癌细胞或前列腺癌细胞。
实施例61.根据实施例44到50中任一项所述的抗体,其中所述抗体能够以约10nM到约150nM的平衡解离常数(K
实施例62.根据实施例44到61中任一项所述的抗体,其中所述抗体与治疗剂缀合。
实施例63.根据实施例44到61中任一项所述的抗体,其中所述抗体与诊断剂缀合。
实施例64.一种抗酪氨酸激酶样孤儿受体2(ROR2)抗体,其包括重链可变结构域和轻链可变结构域,其中所述重链可变结构域包括:如SEQ ID NO:43中所示的CDR H1、如SEQID NO:44中所示的CDR H2和如SEQ ID NO:45中所示的CDR H3;并且其中所述轻链可变结构域包括:如SEQ ID NO:46中所示的CDR L1、如SEQ ID NO:47中所示的CDR L2和如SEQ IDNO:48中所示的CDR L3。
实施例65.根据实施例64所述的抗体,其中所述重链可变结构域包括SEQ ID NO:14的序列。
实施例66.根据实施例64或65所述的抗体,其中所述轻链可变结构域包括SEQ IDNO:16的序列。
实施例67.根据实施例64到66中任一项所述的抗体,其中所述抗体是人源化抗体。
实施例68.根据实施例64到67中任一项所述的抗体,其中所述抗体是Fab'片段。
实施例69.根据实施例64到67中任一项所述的抗体,其中所述抗体是单链抗体(scFv)。
实施例70.根据实施例64到66中任一项所述的抗体,其中所述抗体是嵌合抗体。
实施例71.根据实施例64到67中任一项所述的抗体,其中所述抗体是IgG。
实施例72.根据实施例64到66或71中任一项所述的抗体,其中所述抗体是IgG1。
实施例73.根据实施例64到67中任一项所述的抗体,其中所述抗体能够与包括SEQID NO:18的氨基酸序列的ROR2蛋白结合。
实施例74.根据实施例73所述的抗体,其中所述抗体能够与所述ROR2蛋白的胞外结构域结合。
实施例75.根据实施例74所述的抗体,其中所述胞外结构域包括SEQ ID NO:22的氨基酸序列。
实施例76.根据实施例72所述的抗体,其中所述胞外结构域是Ig样结构域。
实施例77.根据实施例74到76中任一项所述的抗体,其中所述ROR2蛋白在细胞上表达。
实施例78.根据实施例77所述的抗体,其中所述细胞是癌细胞。
实施例79.根据实施例78所述的抗体,其中所述癌细胞是乳腺癌细胞、卵巢癌细胞、胰腺癌细胞、宫颈癌细胞、胃癌细胞、肾癌细胞、头颈癌细胞、骨癌细胞、皮肤癌细胞或前列腺癌细胞。
实施例80.根据实施例64到79中任一项所述的抗体,其中所述抗体能够以约10nM到约150nM的平衡解离常数(K
实施例81.根据实施例64到80中任一项所述的抗体,其中所述抗体与治疗剂缀合。
实施例82.根据实施例64到80中任一项所述的抗体,其中所述抗体与诊断剂缀合。
实施例83.一种治疗有需要的受试者的癌症的方法,所述方法包括向受试者施用治疗有效量的根据实施例1到82中任一项所述的抗体。
实施例84.一种抑制有需要的受试者的表达ROR2的癌症的转移的方法,所述方法包括向受试者施用治疗有效量的根据实施例1到82中任一项所述的抗体。
实施例85.根据实施例83或84所述的方法,其中所述癌症是乳腺癌、卵巢癌、胰腺癌、宫颈癌、胃癌、肾癌、头颈癌、骨癌、皮肤癌或前列腺癌。
实施例86.一种检测表达ROR2的细胞的方法,所述方法包括(i)使表达ROR2的细胞与根据实施例1到82中任一项所述的抗体接触;以及(ii)检测所述抗体与由所述细胞表达的ROR2蛋白的结合。
实施例87.根据实施例86所述的方法,其中所述抗体附着到可检测部分。
实施例88.根据实施例86或87所述的方法,其中所述表达ROR2的细胞位于受试者体内。
实施例89.根据实施例88所述的方法,其中所述受试者是患有癌症的受试者。
实施例90.根据实施例89所述的方法,其中所述癌症是癌症是乳腺癌、卵巢癌、胰腺癌、宫颈癌、胃癌、肾癌、头颈癌、骨癌、皮肤癌或前列腺癌。
实施例91.根据实施例86或87所述的方法,其中所述接触在体外发生。
实施例92.一种向表达ROR2的细胞递送治疗剂的方法,所述方法包括使表达ROR2的细胞与根据实施例1到82中任一项所述的抗体接触,其中所述抗体附着到治疗剂。
实施例93.根据实施例92所述的方法,其中所述治疗剂是抗癌剂。
实施例94.根据实施例92或93所述的方法,其中所述表达ROR2的细胞位于受试者体内。
实施例95.根据实施例94所述的方法,其中所述受试者是患有癌症的受试者。
实施例96.根据实施例95所述的方法,其中所述癌症是癌症是乳腺癌、卵巢癌、胰腺癌、宫颈癌、胃癌、肾癌、头颈癌、骨癌、皮肤癌或前列腺癌。
实施例97.根据实施例93或94所述的方法,其中所述接触在体外发生。
实施例98.一种抑制表达ROR2的细胞的迁移的方法,所述方法包括使表达ROR2的细胞与根据实施例1到80中任一项所述的抗体接触。
实施例99.根据实施例98所述的方法,其中所述表达ROR2的细胞位于患有癌症的受试者体内。
实施例100.根据实施例99所述的方法,其中所述癌症是癌症是乳腺癌、卵巢癌、胰腺癌、宫颈癌、胃癌、肾癌、头颈癌、骨癌、皮肤癌或前列腺癌。
实施例101.根据实施例98所述的方法,其中所述接触在体外发生。
实施例102.根据实施例86到101中任一项所述的方法,其中所述表达ROR2的细胞是癌细胞。
实施例103.根据实施例102所述的方法,其中所述癌细胞是乳腺癌细胞、卵巢癌细胞、胰腺癌细胞、宫颈癌细胞、胃癌细胞、肾癌细胞、头颈癌细胞、骨癌细胞、皮肤癌细胞或前列腺癌细胞。
实施例104.一种抗ROR2抗体,其中所述抗ROR2抗体与包括以下的抗ROR2抗体结合同一表位:重链可变结构域,所述重链可变结构域包括:如SEQ ID NO:25中所示的CDR H1、如SEQ ID NO:26中所示的CDR H2和如SEQ ID NO:27中所示的CDR H3;以及轻链可变结构域,所述轻链可变结构域包括:如SEQ ID NO:28中所示的CDR L1、如SEQ ID NO:29中所示的CDR L2和如SEQ ID NO:30中所示的CDR L3。
实施例105.一种抗ROR2抗体,其中所述抗ROR2抗体与包括以下的抗ROR2抗体结合同一表位:SEQ ID:2的重链可变结构域;以及SEQ ID NO:4的轻链可变结构域。
实施例106.一种抗ROR2抗体,其中所述抗ROR2抗体与包括以下的抗ROR2抗体结合同一表位:由SEQ ID:1的核酸序列编码的重链可变结构域;以及由SEQ ID:3的核酸序列编码的轻链可变结构域。
实施例107.一种抗ROR2抗体,其中所述抗ROR2抗体与包括以下的抗ROR2抗体结合同一表位:重链可变结构域,所述重链可变结构域包括:如SEQ ID NO:31中所示的CDR H1、如SEQ ID NO:32中所示的CDR H2和如SEQ ID NO:33中所示的CDR H3;以及轻链可变结构域,所述轻链可变结构域包括:如SEQ ID NO:34中所示的CDR L1、如SEQ ID NO:35中所示的CDR L2和如SEQ ID NO:36中所示的CDR L3。
实施例108.一种抗ROR2抗体,其中所述抗ROR2抗体与包括以下的抗ROR2抗体结合同一表位:SEQ ID:6的重链可变结构域;以及SEQ ID NO:8的轻链可变结构域。
实施例109.一种抗ROR2抗体,其中所述抗ROR2抗体与包括以下的抗ROR2抗体结合同一表位:由SEQ ID:5的核酸序列编码的重链可变结构域;以及由SEQ ID:7的核酸序列编码的轻链可变结构域。
实施例110.一种抗ROR2抗体,其中所述抗ROR2抗体与包括以下的抗ROR2抗体结合同一表位:重链可变结构域,所述重链可变结构域包括:如SEQ ID NO:37中所示的CDR H1、如SEQ ID NO:38中所示的CDR H2和如SEQ ID NO:39中所示的CDR H3;以及轻链可变结构域,所述轻链可变结构域包括:如SEQ ID NO:40中所示的CDR L1、如SEQ ID NO:41中所示的CDR L2和如SEQ ID NO:42中所示的CDR L3。
实施例111.一种抗ROR2抗体,其中所述抗ROR2抗体与包括以下的抗ROR2抗体结合同一表位:SEQ ID:10的重链可变结构域;以及SEQ ID NO:12的轻链可变结构域。
实施例112.一种抗ROR2抗体,其中所述抗ROR2抗体与包括以下的抗ROR2抗体结合同一表位:由SEQ ID:9的核酸序列编码的重链可变结构域;以及由SEQ ID:11的核酸序列编码的轻链可变结构域。
实施例113.一种抗ROR2抗体,其中所述抗ROR2抗体与包括以下的抗ROR2抗体结合同一表位:重链可变结构域,所述重链可变结构域包括:如SEQ ID NO:43中所示的CDR H1、如SEQ ID NO:44中所示的CDR H2和如SEQ ID NO:45中所示的CDR H3;以及轻链可变结构域,所述轻链可变结构域包括:如SEQ ID NO:46中所示的CDR L1、如SEQ ID NO:47中所示的CDR L2和如SEQ ID NO:48中所示的CDR L3。
实施例114.一种抗ROR2抗体,其中所述抗ROR2抗体与包括以下的抗ROR2抗体结合同一表位:SEQ ID:14的重链可变结构域;以及SEQ ID NO:16的轻链可变结构域。
实施例115.一种抗ROR2抗体,其中所述抗ROR2抗体与包括以下的抗ROR2抗体结合同一表位:由SEQ ID:13的核酸序列编码的重链可变结构域;以及由SEQ ID:15的核酸序列编码的轻链可变结构域。
实施例116.一种嵌合抗原受体,其包括:(i)抗体区,所述抗体区包括:(a)轻链可变结构域,所述轻链可变结构域包括如SEQ ID NO:28中所示的CDR L1、如SEQ ID NO:29中所示的CDR L2和如SEQ ID NO:30中所示的CDR L3;以及{4}(b)重链可变区结构域,所述重链可变区结构域包括如SEQ ID NO:25中所示的CDR H1、如SEQ ID NO:26中所示的CDR H2和如SEQ ID NO:27中所示的CDR H3;以及(ii)跨膜结构域。
实施例117.一种嵌合抗原受体,其包括:(i)抗体区,所述抗体区包括:(a)轻链可变结构域,所述轻链可变结构域包括如SEQ ID NO:34中所示的CDR L1、如SEQ ID NO:35中所示的CDR L2和如SEQ ID NO:36中所示的CDR L3;以及{4}(b)重链可变区结构域,所述重链可变区结构域包括如SEQ ID NO:31中所示的CDR H1、如SEQ ID NO:32中所示的CDR H2和如SEQ ID NO:33中所示的CDR H3;以及(ii)跨膜结构域。
实施例118.一种嵌合抗原受体,其包括:(i)抗体区,所述抗体区包括:(a)轻链可变结构域,所述轻链可变结构域包括如SEQ ID NO:40中所示的CDR L1、如SEQ ID NO:41中所示的CDR L2和如SEQ ID NO:42中所示的CDR L3;以及{4}(b)重链可变区结构域,所述重链可变区结构域包括如SEQ ID NO:37中所示的CDR H1、如SEQ ID NO:38中所示的CDR H2和如SEQ ID NO:39中所示的CDR H3;以及(ii)跨膜结构域。
实施例119.一种嵌合抗原受体,其包括:(i)抗体区,所述抗体区包括:(a)轻链可变结构域,所述轻链可变结构域包括如SEQ ID NO:46中所示的CDR L1、如SEQ ID NO:47中所示的CDR L2和如SEQ ID NO:48中所示的CDR L3;以及{4}(b)重链可变区结构域,所述重链可变区结构域包括如SEQ ID NO:43中所示的CDR H1、如SEQ ID NO:44中所示的CDR H2和如SEQ ID NO:45中所示的CDR H3;以及(ii)跨膜结构域。
实施例120.根据实施例116到119中任一项所述的嵌合抗原受体,其进一步包括胞内T细胞信号传导结构域。
实施例121.根据实施例116到120所述的嵌合抗原受体,其中所述胞内T细胞信号传导结构域是CD3ζ胞内T细胞信号传导结构域。
实施例122.根据实施例116到121中任一项所述的嵌合抗原受体,其进一步包括胞内共刺激T细胞信号传导结构域。
实施例123.根据实施例122所述的嵌合抗原受体,其中所述胞内共刺激信号传导结构域是CD28胞内共刺激信号传导结构域、4-1BB胞内共刺激信号传导结构域、ICOS胞内共刺激信号传导结构域或OX-40胞内共刺激信号传导结构域。
实施例124.根据实施例116到123中任一项所述的嵌合抗原受体,其进一步包括间隔子区。
实施例125.根据实施例124所述的嵌合抗原受体,其中所述间隔子区进一步包括铰链区。
实施例126.根据实施例116到125中任一项所述的嵌合抗原受体,其进一步包括连接子结构域。
实施例127.根据实施例116到126中任一项所述的嵌合抗原受体,其进一步包括重链恒定结构域。
实施例128.一种治疗有需要的受试者的癌症的方法,所述方法包括向受试者施用治疗有效量的根据实施例116到127中任一项所述的嵌合抗原受体。
实施例129.根据实施例126所述的方法,其中所述癌症是癌症是乳腺癌、卵巢癌、胰腺癌、宫颈癌、胃癌、肾癌、头颈癌、骨癌、皮肤癌或前列腺癌。
非正式序列表
SEQ ID NO:1;6E6 VH SEQ
GAGGTGCAGCTGGTGGAGTCTGGGGGAGACTTAGTGAAGCCTGGAGGGTCCCTGAAACTCTCCTGTGCAGCCTCTGGATTCACTTTCAGTAATTATGGCATGTCTTGGGTTCGCCAGACTCCAGACAAGAGGCTGGAGTGGGTCGCAACCATTAGTAGTGGTGGTGGTTACACTCACTATGTAGACAGTGTGAAGGGGCGATTCACCATTTCCAGAGACAATGCCAACCATATCCTGTACCTGCAAATGAGCAGTCTGAACTCTGAGGACACAGCCATGTATTATTGTGCAAGACACCCGAGGGATTTTTCCTATGCTATGGACTACTGGGGTCAGGGAACCTCAGTCACCGTCTCCTCA
SEQ ID NO:2;6E6 VH SEQ
EVQLVESGGDLVKPGGSLKLSCAASGFTFSNYGMSWVRQTPDKRLEWVATISSGGGYTHYVDSVKGRFTISRDNANHILYLQMSSLNSEDTAMYYCARHPRDFSYAMDYWGQGTSVTVSS
SEQ ID NO:3;6E6 VK SEQ
GACATTGTGATGACCCAGTCTCACAAATTCATGTCCACATCAATAGGAGACAGGGTCAGCATCACCTGCAAGGCCAGTCAGGATGTGGGTCATTATGTGGCCTGGTATCAACAGAAACCAGGTCAATCTCCTAAACTACTGATTTACTGGGCATCCACCCGGCACACTGGAGTCCCTGATCGCTTCACAGGTAGTGGATCTGGGACAGATTTCACTCTCACCATTAGCAATGTGCAGTCTGAAGACTTGGCAGATTATTTCTGTCAGCAATATAACATCTATCCGTGGACGTTCGGTGGAGGCTCCAAGCTGGCAATCAAA
SEQ ID NO:4;6E6 VL SEQ
DIVMTQSHKFMSTSIGDRVSITCKASQDVGHYVAWYQQKPGQSPKLLIYWASTRHTGVPDRFTGSGSGTDFTLTISNVQSEDLADYFCQQYNIYPWTFGGGSKLAIK
SEQ ID NO:5;4G9 VH SEQ
CAGGTTCAACTGCAACAGTCTGGGGCTGAGCTGGTGAGGCCTGGGGCTTCAGTGAAGCTGTCCTGCAAGGCTTTGGGCTACACATTTACTGACTATGAAATGCACTGGGTGAAGCAGACACCTGTGCATGGCCTGGAATGGATTGGAGCTATTCATCCAGGAAGTGGTGGTACTGCCTATAATCAGAAGTTCAAGGGCAAGGCCACACTGACTGCAGACAAATCCTCCAGCACAGCCTACATGGAGCTCAGCAGGCTGACATCTGAGGACTCTGCTGTCTATTACTGTACAAGAAGGAGGCCTAGGTTCTATGGTATGGACTACTGGGGTCAAGGAACCTCAGTCACCGTCTCCTCA
SEQ ID NO:6;4G9 VH SEQ
QVQLQQSGAELVRPGASVKLSCKALGYTFTDYEMHWVKQTPVHGLEWIGAIHPGSGGTAYNQKFKGKATLTADKSSSTAYMELSRLTSEDSAVYYCTRRRPRFYGMDYWGQGTSVTVSS
SEQ ID NO:7;4G9 VL SEQ
GATATTGTGATGACTCAGGCTGCACCCTCTGTACCTGTCACTCCTGGAGAGTCAGTATCCATCTCCTGCAGGTCTAGTAAGAGTCTCCTGCATAGTAATGGCAACACTTACTTGTATTGGTTCCTGCAGAGGCCAGGCCAGTCTCCTCAGCTCCTGATATATCGGATGTCCAACCTTGCCTCAGGAGTCCCAGACAGGTTCAGTGGCAGTGGGTCAGGAACTGCTTTCACACTGAGAATCAGTAGAGTGGAGGCTGAGGATGTGGGTGTTTATTACTGTATGCAACATCTAGAATATCCTCTCACGGTCGGTGCTGGGACCAAGCTGGAGCTGAAA
SEQ ID NO:8;4G9 VL SEQ
DIVMTQAAPSVPVTPGESVSISCRSSKSLLHSNGNTYLYWFLQRPGQSPQLLIYRMSNLASGVPDRFSGSGSGTAFTLRISRVEAEDVGVYYCMQHLEYPLTVGAGTKLELK
SEQ ID NO:9;5C11 VH SEQ
GAGGTGCAGCTGGTGGAGTCTGGGGGAGACTTGGTGAAGCCTGGAGGGTCCCTGAAACTCTCCTGTGCAGCCTCTGGATTCACTTTCAGTAACTATGGCATGTCTTGGGTTCGCCAGACTCCAGACAAGAGGCTGGAGTGGGTCGCAACCATTAGTAGTGGTGGTGGTTCCACCTACTATCCAGACAGTGTGAAGGGGCGATTCACCATCTCCAGAGACAATGCCAAGAACTCCCTGTACCTGCAAATGAGCAGTCTGAAGTCTGAGGACACAGCCATGTATTACTGTGCAAGACATCCCTATGATTACGGGTACTACTTTGACTACTGGGGCCAAGGCACCACTCTCACAGTCTCCTCA
SEQ ID NO:10;5C11 VH SEQ
EVQLVESGGDLVKPGGSLKLSCAASGFTFSNYGMSWVRQTPDKRLEWVATISSGGGSTYYPDSVKGRFTISRDNAKNSLYLQMSSLKSEDTAMYYCARHPYDYGYYFDYWGQGTTLTVSS
SEQ ID NO:11;5C11 VL SEQ
GACATCTTGCTGACTCAGTCTCCAGACATCCTGTCTGTGAGTCCAGGAGAAAGAGTCAGTTTCTCCTGCAGGGCCAGTCAGAGCATTGGCACAAGCATACACTGGTATCAGCAGAGAACAAATGGTTCTCCAAGGCTTCTCATAAAATATGCTTCTGAGTCTATCTCTGGGATCCCTTCCAGGTTTAGTGGCAGTGGATCAGGGACAGATTTTACTCTTAGCATCAACAGTGTGGAGTCTGAAGATATTGCAGATTATTACTGTCAACAAAGTGATAGCTGGCCATTCCCGTTCGGCTCGGGGACAAAATTGGAAAAAAAA
SEQ ID NO:12;5C11 VL SEQ
DILLTQSPDILSVSPGERVSFSCRASQSIGTSIHWYQQRTNGSPRLLIKYASESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYCQQSDSWPFPFGSGTKLEKK
SEQ ID NO:13;5G3 VH SEQ
GAGGTGCAGCTTGTTGAGTCTGGTGGAGGATTGGTGCAGCCTAAAGGGTCATTGAAGCTCTCATGTGCAGCCTCTGGATTCACCTTCAATACCTACGCCATGAACTGGGTCCGCCAGGCTCCAGGAAAGGGTTTGGAATGGGTTGCTCGCATAAGAAGTAAAAGTAATAATTATGCAACATATTATGCCGATTCAGTGAAAGACAGGTTCACCATCTCCAGAGATGATTCACAAAGCATGCTCCATCTGCAAATGAACAACTTGAAAACTGAGGACACAGCCATGTATTACTGTGTGAGACACGGTAGTAGCCTCTACTATGCTATGGACTACTGGGGTCAAGGAACCTCAGTCACCGTCTCCTCA
SEQ ID NO:14;5G3 VH SEQ
EVQLVESGGGLVQPKGSLKLSCAASGFTFNTYAMNWVRQAPGKGLEWVARIRSKSNNYATYYADSVKDRFTISRDDSQSMLHLQMNNLKTEDTAMYYCVRHGSSLYYAMDYWGQGTSVTVSS
SEQ ID NO:15;5G3 VL SEQ
GACATCCAGATGACCCAGTCTCCATCCTCCTTATCTGCCTCTCTGGGAGAAAGAGTCAGTCTCACTTGTCGGGCAAGTCAGGAAATTAGTGGTTACTTAGGCTGGCTTCAGCAGAAACCAGATGGAACTATTAAACGCCTGATCTACGCCGCATCCACTTTAGATTCTGGTGTCCCAAAAAGGTTCAGTGGCAGTAGGTCTGGGTCAGCTTATTCTCTCACCATCAGCAGCCTTGAGTCTGAAGATTTTGCAGACTATTACTGTCTACAATATGCTAGTTATCCGTACACGTTCGGAGGGGGGACCAAGCTGGAAATAAAA
SEQ ID NO:16;5G3 VL SEQ
DIQMTQSPSSLSASLGERVSLTCRASQEISGYLGWLQQKPDGTIKRLIYAASTLDSGVPKRFSGSRSGSAYSLTISSLESEDFADYYCLQYASYPYTFGGGTKLEIK
SEQ ID NO:17;人ROR2全长
ATGGCCCGGGGCTCGGCGCTCCCGCGGCGGCCGCTGCTGTGCATCCCGGCCGTCTGGGCGGCCGCCGCGCTTCTGCTCTCAGTGTCCCGGACTTCAGGTGAAGTGGAGGTTCTGGATCCGAACGACCCTTTAGGACCCCTTGATGGGCAGGACGGCCCGATTCCAACTCTGAAAGGTTACTTTCTGAATTTTCTGGAGCCAGTAAACAATATCACCATTGTCCAAGGCCAGACGGCAATTCTGCACTGCAAGGTGGCAGGAAACCCACCCCCTAACGTGCGGTGGCTAAAGAATGATGCCCCGGTGGTGCAGGAGCCGCGGCGGATCATCATCCGGAAGACAGAATATGGTTCACGACTGCGAATCCAGGACCTGGACACGACAGACACTGGCTACTACCAGTGCGTGGCCACCAACGGGATGAAGACCATTACCGCCACTGGCGTCCTGTTTGTGCGGCTGGGTCCAACGCACAGCCCAAATCATAACTTTCAGGATGATTACCACGAGGATGGGTTCTGCCAGCCTTACCGGGGAATTGCCTGTGCACGCTTCATTGGCAACCGGACCATTTATGTGGACTCGCTTCAGATGCAGGGGGAGATTGAAAACCGAATCACAGCGGCCTTCACCATGATCGGCACGTCTACGCACCTGTCGGACCAGTGCTCACAGTTCGCCATCCCATCCTTCTGCCACTTCGTGTTTCCTCTGTGCGACGCGCGCTCCCGGGCACCCAAGCCGCGTGAGCTGTGCCGCGACGAGTGCGAGGTGCTGGAGAGCGACCTGTGCCGCCAGGAGTACACCATCGCCCGCTCCAACCCGCTCATCCTCATGCGGCTTCAGCTGCCCAAGTGTGAGGCGCTGCCCATGCCTGAGAGCCCCGACGCTGCCAACTGCATGCGCATTGGCATCCCAGCCGAGAGGCTGGGCCGCTACCATCAGTGCTATAACGGCTCAGGCATGGATTACAGAGGAACGGCAAGCACCACCAAGTCAGGCCACCAGTGCCAGCCGTGGGCCCTGCAGCACCCCCACAGCCACCACCTGTCCAGCACAGACTTCCCTGAGCTTGGAGGGGGGCACGCCTACTGCCGGAACCCCGGAGGCCAGATGGAGGGCCCCTGGTGCTTTACGCAGAATAAAAACGTACGCATGGAACTGTGTGACGTACCCTCGTGTAGTCCCCGAGACAGCAGCAAGATGGGGATTCTGTACATCTTGGTCCCCAGCATCGCAATTCCACTGGTCATCGCTTGCCTTTTCTTCTTGGTTTGCATGTGCCGGAATAAGCAGAAGGCATCTGCGTCCACACCGCAGCGGCGACAGCTGATGGCCTCGCCCAGCCAAGACATGGAAATGCCCCTCATTAACCAGCACAAACAGGCCAAACTCAAAGAGATCAGCCTGTCTGCGGTGAGGTTCATGGAGGAGCTGGGAGAGGACCGGTTTGGGAAAGTCTACAAAGGTCACCTGTTCGGCCCTGCCCCGGGGGAGCAGACCCAGGCTGTGGCCATCAAAACGCTGAAGGACAAAGCGGAGGGGCCCCTGCGGGAGGAGTTCCGGCATGAGGCTATGCTGCGAGCACGGCTGCAACACCCCAACGTCGTCTGCCTGCTGGGCGTGGTGACCAAGGACCAGCCCCTGAGCATGATCTTCAGCTACTGTTCGCACGGCGACCTCCACGAATTCCTGGTCATGCGCTCGCCGCACTCGGACGTGGGCAGCACCGATGATGACCGCACGGTGAAGTCCGCCCTGGAGCCCCCCGACTTCGTGCACCTTGTGGCACAGATCGCGGCGGGGATGGAGTACCTATCCAGCCACCACGTGGTTCACAAGGACCTGGCCACCCGCAATGTGCTAGTGTACGACAAGCTGAACGTGAAGATCTCAGACTTGGGCCTCTTCCGAGAGGTGTATGCCGCCGATTACTACAAGCTGCTGGGGAACTCGCTGCTGCCTATCCGCTGGATGGCCCCAGAGGCCATCATGTACGGCAAGTTCTCCATCGACTCAGACATCTGGTCCTACGGTGTGGTCCTGTGGGAGGTCTTCAGCTACGGCCTGCAGCCCTACTGCGGGTACTCCAACCAGGATGTGGTGGAGATGATCCGGAACCGGCAGGTGCTGCCTTGCCCCGATGACTGTCCCGCCTGGGTGTATGCCCTCATGATCGAGTGCTGGAACGAGTTCCCCAGCCGGCGGCCCCGCTTCAAGGACATCCACAGCCGGCTCCGAGCCTGGGGCAACCTTTCCAACTACAACAGCTCGGCGCAGACCTCGGGGGCCAGCAACACCACGCAGACCAGCTCCCTGAGCACCAGCCCAGTGAGCAATGTGAGCAACGCCCGCTACGTGGGGCCCAAGCAGAAGGCCCCGCCCTTCCCACAGCCCCAGTTCATCCCCATGAAGGGCCAGATCAGACCCATGGTGCCCCCGCCGCAGCTCTACGTCCCCGTCAACGGCTACCAGCCGGTGCCGGCCTATGGGGCCTACCTGCCCAACTTCTACCCGGTGCAGATCCCAATGCAGATGGCCCCGCAGCAGGTGCCTCCTCAGATGGTCCCCAAGCCCAGCTCACACCACAGTGGCAGTGGCTCCACCAGCACAGGCTACGTCACCACGGCCCCCTCCAACACATCCATGGCAGACAGGGCAGCCCTGCTCTCAGAGGGCGCTGATGACACACAGAACGCCCCAGAAGATGGGGCCCAGAGCACCGTGCAGGAAGCAGAGGAGGAGGAGGAAGGCTCTGTCCCAGAGACTGAGCTGCTGGGGGACTGTGACACTCTGCAGGTGGACGAGGCCCAAGTCCAGCTGGAAGCTTGA
SEQ ID NO:18;人ROR2全长
MARGSALPRRPLLCIPAVWAAAALLLSVSRTSGEVEVLDPNDPLGPLDGQDGPIPTLKGYFLNFLEPVNNITIVQGQTAILHCKVAGNPPPNVRWLKNDAPVVQEPRRIIIRKTEYGSRLRIQDLDTTDTGYYQCVATNGMKTITATGVLFVRLGPTHSPNHNFQDDYHEDGFCQPYRGIACARFIGNRTIYVDSLQMQGEIENRITAAFTMIGTSTHLSDQCSQFAIPSFCHFVFPLCDARSRTPKPRELCRDECEVLESDLCRQEYTIARSNPLILMRLQLPKCEALPMPESPDAANCMRIGIPAERLGRYHQCYNGSGMDYRGTASTTKSGHQCQPWALQHPHSHHLSSTDFPELGGGHAYCRNPGGQMEGPWCFTQNKNVRMELCDVPSCSPRDSSKMGILYILVPSIAIPLVIACLFFLVCMCRNKQKASASTPQRRQLMASPSQDMEMPLINQHKQAKLKEISLSAVRFMEELGEDRFGKVYKGHLFGPAPGEQTQAVAIKTLKDKAEGPLREEFRHEAMLRARLQHPNVVCLLGVVTKDQPLSMIFSYCSHGDLHEFLVMRSPHSDVGSTDDDRTVKSALEPPDFVHLVAQIAAGMEYLSSHHVVHKDLATRNVLVYDKLNVKISDLGLFREVYAADYYKLLGNSLLPIRWMAPEAIMYGKFSIDSDIWSYGVVLWEVFSYGLQPYCGYSNQDVVEMIRNRQVLPCPDDCPAWVYALMIECWNEFPSRRPRFKDIHSRLRAWGNLSNYNSSAQTSGASNTTQTSSLSTSPVSNVSNARYVGPKQKAPPFPQPQFIPMKGQIRPMVPPPQLYVPVNGYQPVPAYGAYLPNFYPVQIPMQMAPQQVPPQMVPKPSSHHSGSGSTSTGYVTTAPSNTSMADRAALLSEGADDTQNAPEDGAQSTVQEAEEEEEGSVPETELLGDCDTLQVDEAQVQLEA
SEQ ID NO:19;小鼠ROR2全长
ATGGCTCGGGGCTGGGTGCGGCCGAGCCGTGTGCCTCTGTGCGCCCGGGCCGTCTGGACGGCTGCGGCGCTCCTGCTCTGGACACCCTGGACGGCAGGTGAAGTGGAAGATTCGGAGGCAATCGACACCTTGGGACAACCTGATGGACCGGACAGCCCACTTCCCACTCTGAAAGGCTACTTTCTGAATTTTCTGGAGCCAGTCAACAATATCACCATTGTTCAGGGCCAGACGGCAATCCTGCACTGCAAGGTGGCGGGAAACCCACCTCCCAATGTGCGGTGGCTGAAGAATGATGCCCCGGTTGTGCAAGAGCCACGAAGGGTCGTCATCCGGAAGACAGAATACGGCTCCCGGCTGCGGATCCAAGACCTGGACACAACAGACACAGGCTACTACCAGTGTGTGGCTACCAACGGGCTGAAGACCATCACTGCCACTGGGGTTCTATATGTGCGGCTCGGTCCGACGCACAGCCCGAACCACAATTTTCAGGATGACGATCAGGAAGATGGCTTCTGCCAGCCGTACCGAGGGATCGCTTGTGCGCGCTTCATTGGGAACCGGACTATTTATGTGGACTCCCTCCAGATGCAGGGGGAGATTGAAAACCGAATCACAGCTGCCTTCACCATGATCGGCACCTCCACGCAACTGTCAGACCAGTGTTCACAGTTTGCCATCCCATCCTTCTGCCACTTCGTCTTCCCTCTGTGCGACGCATGCTCCCGGGCGCCCAAGCCTCGCGAACTGTGCCGGGATGAATGTGAGGTGCTGGAGAACGACCTGTGCCGCCAGGAGTACACCATCGCCCGCTCCAACCCGCTCATCCTCATGCGGCTCCAGCTGCCCAAGTGCGAAGCGCTGCCCATGCCCGAGAGCCCGGATGCTGCGAACTGCATGCGCATCGGGATCCCCGCGGAGAGGCTGGGTCGCTACCACCAGTGCTACAACGGCTCCGGCGCCGATTACAGGGGGATGGCCAGTACCACCAAGTCAGGCCACCAGTGTCAGCCTTGGGCTCTGCAGCACCCCCACAGCCATCGCCTATCCAGCACGGAATTCCCTGAGCTGGGAGGAGGCCATGCCTACTGCCGGAACCCCGGGGGCCAGATGGAAGGCCCGTGGTGCTTTACGCAGAATAAAAACGTACGCGTGGAACTGTGTGACGTACCCCCGTGTAGTCCCCGATATGGCAGCAAGATGGGGATTCTGTACATCCTGGTCCCCAGCATTGCTATCCCCCTGGTCATCGCTTGCCTGTTCTTCCTCGTCTGCATGTGCCGCAACAAACAGAAGGCTTCGGCCTCCACCCCACAGCGCCGGCAGCTGATGGCCTCTCCCAGCCAGGACATGGAGATGCCACTCATCAGCCAGCACAAACAGGCCAAACTCAAAGAGATCAGCTTGTCCACAGTGAGGTTCATGGAGGAGCTCGGGGAGGACCGGTTTGGCAAGGTCTACAAAGGCCACCTGTTCGGGCCTGCCCCAGGAGAACCAACCCAGGCCGTGGCCATCAAGACGCTGAAAGACAAGGCTGAGGGGCCCCTGCGGGAGGAGTTCCGGCAAGAGGCGATGCTCCGGGCCCGACTGCAGCACCCCAACATCGTCTGTCTCCTAGGCGTCGTGACCAAGGACCAACCCTTGAGCATGATCTTCAGCTACTGTTCCCATGGCGACCTTCATGAATTCCTGGTCATGCGCTCGCCGCACTCCGATGTGGGCAGCACCGATGACGACCGCACAGTGAAGTCAGCCCTGGAGCCCCCGGACTTCGTGCACGTGGTGGCGCAGATCGCTGCGGGGATGGAGTTCCTGTCCAGCCACCACGTGTGCCATAAGGACCTGGCCACACGCAATGTGCTGGTGTACGACAAGCTGAACGTGAGGATCTCAGACTTGGGCCTCTTCCGTGAGGTATACTCCGCAGATTACTACAAACTCATGGGCAATTCACTGCTGCCCATCCGCTGGATGTCCCCCGAGGCCGTCATGTATGGAAAGTTCTCCATCGACTCTGACATCTGGTCCTACGGTGTGGTCCTCTGGGAGGTCTTTAGCTACGGCCTGCAGCCCTACTGTGGGTACTCCAACCAGGACGTGGTGGAGATGATCCGGAGCCGGCAGGTGCTGCCCTGCCCGGATGACTGCCCCGCCTGGGTCTATGCCCTCATGATTGAATGCTGGAATGAGTTCCCAAGCCGGAGGCCCCGCTTTAAGGACATCCACAGCCGGCTCCGGTCCTGGGGCAACCTATCCAACTATAATAGTTCCGCGCAGACCTCAGGAGCCAGCAACACCACACAGACCAGCTCCCTGAGCACCAGCCCCGTAAGCAATGTGAGCAATGCCCGCTATATGGCCCCCAAGCAGAAGGCCCAGCCCTTCCCACAGCCTCAGTTCATCCCCATGAAGGGTCAGATCAGACCCTTGGTGCCCCCCGCACAGCTGTACATCCCGGTGAACGGCTATCAGCCGGTACCGGCATACGGGGCCTACCTGCCCAACTTCTACCCAGTCCAGATCCCCATGCAGATGGCCCCACAGCAGGTGCCCCCTCAGATGGTCCCCAAGCCGAGCTCACACCACAGTGGCAGCGGCTCCACCAGCACTGGCTACGTCACCACGGCGCCCTCCAATACATCTGTGGCGGACAGGGCGGCCCTACTCTCTGAGGGCACCGAGGATGTACAGAACATCGCGGAAGACGTGGCCCAGAGCCCTGTGCAGGAAGCAGAGGAGGAGGAGGAGGGGTCTGTCCCTGAGACTGAACTCCTGGGAGACAATGACACGCTCCAGGTGACCGAGGCGGCTCATGTCCAGCTTGAAGCCTGA
SEQ ID NO:20;小鼠ROR2全长
MARGWVRPSRVPLCARAVWTAAALLLWTPWTAGEVEDSEAIDTLGQPDGPDSPLPTLKGYFLNFLEPVNNITIVQGQTAILHCKVAGNPPPNVRWLKNDAPVVQEPRRVVIRKTEYGSRLRIQDLDTTDTGYYQCVATNGLKTITATGVLYVRLGPTHSPNHNFQDDDQEDGFCQPYRGIACARFIGNRTIYVDSLQMQGEIENRITAAFTMIGTSTQLSDQCSQFAIPSFCHFVFPLCDACSRAPKPRELCRDECEVLENDLCRQEYTIARSNPLILMRLQLPKCEALPMPESPDAANCMRIGIPAERLGRYHQCYNGSGADYRGMASTTKSGHQCQPWALQHPHSHRLSSTEFPELGGGHAYCRNPGGQMEGPWCFTQNKNVRVELCDVPPCSPRYGSKMGILYILVPSIAIPLVIACLFFLVCMCRNKQKASASTPQRRQLMASPSQDMEMPLISQHKQAKLKEISLSTVRFMEELGEDRFGKVYKGHLFGPAPGEPTQAVAIKTLKDKAEGPLREEFRQEAMLRARLQHPNIVCLLGVVTKDQPLSMIFSYCSHGDLHEFLVMRSPHSDVGSTDDDRTVKSALEPPDFVHVVAQIAAGMEFLSSHHVCHKDLATRNVLVYDKLNVRISDLGLFREVYSADYYKLMGNSLLPIRWMSPEAVMYGKFSIDSDIWSYGVVLWEVFSYGLQPYCGYSNQDVVEMIRSRQVLPCPDDCPAWVYALMIECWNEFPSRRPRFKDIHSRLRSWGNLSNYNSSAQTSGASNTTQTSSLSTSPVSNVSNARYMAPKQKAQPFPQPQFIPMKGQIRPLVPPAQLYIPVNGYQPVPAYGAYLPNFYPVQIPMQMAPQQVPPQMVPKPSSHHSGSGSTSTGYVTTAPSNTSVADRAALLSEGTEDVQNIAEDVAQSPVQEAEEEEEGSVPETELLGDNDTLQVTEAAHVQLEA
SEQ ID NO:21;人ROR2胞外区
ATGGCCCGGGGCTCGGCGCTCCCGCGGCGGCCGCTGCTGTGCATCCCGGCCGTCTGGGCGGCCGCCGCGCTTCTGCTCTCAGTGTCCCGGACTTCAGGTGAAGTGGAGGTTCTGGATCCGAACGACCCTTTAGGACCCCTTGATGGGCAGGACGGCCCGATTCCAACTCTGAAAGGTTACTTTCTGAATTTTCTGGAGCCAGTAAACAATATCACCATTGTCCAAGGCCAGACGGCAATTCTGCACTGCAAGGTGGCAGGAAACCCACCCCCTAACGTGCGGTGGCTAAAGAATGATGCCCCGGTGGTGCAGGAGCCGCGGCGGATCATCATCCGGAAGACAGAATATGGTTCACGACTGCGAATCCAGGACCTGGACACGACAGACACTGGCTACTACCAGTGCGTGGCCACCAACGGGATGAAGACCATTACCGCCACTGGCGTCCTGTTTGTGCGGCTGGGTCCAACGCACAGCCCAAATCATAACTTTCAGGATGATTACCACGAGGATGGGTTCTGCCAGCCTTACCGGGGAATTGCCTGTGCACGCTTCATTGGCAACCGGACCATTTATGTGGACTCGCTTCAGATGCAGGGGGAGATTGAAAACCGAATCACAGCGGCCTTCACCATGATCGGCACGTCTACGCACCTGTCGGACCAGTGCTCACAGTTCGCCATCCCATCCTTCTGCCACTTCGTGTTTCCTCTGTGCGACGCGCGCTCCCGGGCACCCAAGCCGCGTGAGCTGTGCCGCGACGAGTGCGAGGTGCTGGAGAGCGACCTGTGCCGCCAGGAGTACACCATCGCCCGCTCCAACCCGCTCATCCTCATGCGGCTTCAGCTGCCCAAGTGTGAGGCGCTGCCCATGCCTGAGAGCCCCGACGCTGCCAACTGCATGCGCATTGGCATCCCAGCCGAGAGGCTGGGCCGCTACCATCAGTGCTATAACGGCTCAGGCATGGATTACAGAGGAACGGCAAGCACCACCAAGTCAGGCCACCAGTGCCAGCCGTGGGCCCTGCAGCACCCCCACAGCCACCACCTGTCCAGCACAGACTTCCCTGAGCTTGGAGGGGGGCACGCCTACTGCCGGAACCCCGGAGGCCAGATGGAGGGCCCCTGGTGCTTTACGCAGAATAAAAACGTACGCATGGAACTGTGTGACGTACCCTCGTGTAGTCCCCGAGACAGCAGCAAGATGGGG
SEQ ID NO:22;人ROR2胞外区
MARGSALPRRPLLCIPAVWAAAALLLSVSRTSGEVEVLDPNDPLGPLDGQDGPIPTLKGYFLNFLEPVNNITIVQGQTAILHCKVAGNPPPNVRWLKNDAPVVQEPRRIIIRKTEYGSRLRIQDLDTTDTGYYQCVATNGMKTITATGVLFVRLGPTHSPNHNFQDDYHEDGFCQPYRGIACARFIGNRTIYVDSLQMQGEIENRITAAFTMIGTSTHLSDQCSQFAIPSFCHFVFPLCDARSRTPKPRELCRDECEVLESDLCRQEYTIARSNPLILMRLQLPKCEALPMPESPDAANCMRIGIPAERLGRYHQCYNGSGMDYRGTASTTKSGHQCQPWALQHPHSHHLSSTDFPELGGGHAYCRNPGGQMEGPWCFTQNKNVRMELCDVPSCSPRDSSKMG
SEQ ID NO:23;小鼠ROR2胞外区
ATGGCTCGGGGCTGGGTGCGGCCGAGCCGTGTGCCTCTGTGCGCCCGGGCCGTCTGGACGGCTGCGGCGCTCCTGCTCTGGACACCCTGGACGGCAGGTGAAGTGGAAGATTCGGAGGCAATCGACACCTTGGGACAACCTGATGGACCGGACAGCCCACTTCCCACTCTGAAAGGCTACTTTCTGAATTTTCTGGAGCCAGTCAACAATATCACCATTGTTCAGGGCCAGACGGCAATCCTGCACTGCAAGGTGGCGGGAAACCCACCTCCCAATGTGCGGTGGCTGAAGAATGATGCCCCGGTTGTGCAAGAGCCACGAAGGGTCGTCATCCGGAAGACAGAATACGGCTCCCGGCTGCGGATCCAAGACCTGGACACAACAGACACAGGCTACTACCAGTGTGTGGCTACCAACGGGCTGAAGACCATCACTGCCACTGGGGTTCTATATGTGCGGCTCGGTCCGACGCACAGCCCGAACCACAATTTTCAGGATGACGATCAGGAAGATGGCTTCTGCCAGCCGTACCGAGGGATCGCTTGTGCGCGCTTCATTGGGAACCGGACTATTTATGTGGACTCCCTCCAGATGCAGGGGGAGATTGAAAACCGAATCACAGCTGCCTTCACCATGATCGGCACCTCCACGCAACTGTCAGACCAGTGTTCACAGTTTGCCATCCCATCCTTCTGCCACTTCGTCTTCCCTCTGTGCGACGCATGCTCCCGGGCGCCCAAGCCTCGCGAACTGTGCCGGGATGAATGTGAGGTGCTGGAGAACGACCTGTGCCGCCAGGAGTACACCATCGCCCGCTCCAACCCGCTCATCCTCATGCGGCTCCAGCTGCCCAAGTGCGAAGCGCTGCCCATGCCCGAGAGCCCGGATGCTGCGAACTGCATGCGCATCGGGATCCCCGCGGAGAGGCTGGGTCGCTACCACCAGTGCTACAACGGCTCCGGCGCCGATTACAGGGGGATGGCCAGTACCACCAAGTCAGGCCACCAGTGTCAGCCTTGGGCTCTGCAGCACCCCCACAGCCATCGCCTATCCAGCACGGAATTCCCTGAGCTGGGAGGAGGCCATGCCTACTGCCGGAACCCCGGGGGCCAGATGGAAGGCCCGTGGTGCTTTACGCAGAATAAAAACGTACGCGTGGAACTGTGTGACGTACCCCCGTGTAGTCCCCGATATGGCAGCAAGATGGGG
SEQ ID NO:24;小鼠ROR2胞外区
MARGWVRPSRVPLCARAVWTAAALLLWTPWTAGEVEDSEAIDTLGQPDGPDSPLPTLKGYFLNFLEPVNNITIVQGQTAILHCKVAGNPPPNVRWLKNDAPVVQEPRRVVIRKTEYGSRLRIQDLDTTDTGYYQCVATNGLKTITATGVLYVRLGPTHSPNHNFQDDDQEDGFCQPYRGIACARFIGNRTIYVDSLQMQGEIENRITAAFTMIGTSTQLSDQCSQFAIPSFCHFVFPLCDACSRAPKPRELCRDECEVLENDLCRQEYTIARSNPLILMRLQLPKCEALPMPESPDAANCMRIGIPAERLGRYHQCYNGSGADYRGMASTTKSGHQCQPWALQHPHSHRLSSTEFPELGGGHAYCRNPGGQMEGPWCFTQNKNVRVELCDVPPCSPRYGSKMG
SEQ ID NO:25;6E6 CDR H1
GFTFSNYG
SEQ ID NO:26;6E6 CDR H2
ISSGGGYT
SEQ ID NO:27;6E6 CDR H3
HPRDFSYAMDY
SEQ ID NO:28;6E6 CDR L1
QDVGHY
SEQ ID NO:29;6E6 CDR L2
WAS
SEQ ID NO:30;6E6 CDR L3
QQYNIYPWT
SEQ ID NO:31;4G9 CDR H1
GYTFTDYE
SEQ ID NO:32;4G9 CDR H2
IHPGSGGT
SEQ ID NO:33;4G9 CDR H3
RRPRFYGMDY
SEQ ID NO:34;4G9 CDR L1
KSLLHSNGNTY
SEQ ID NO:35;4G9 CDR L2
RMS
SEQ ID NO:36;4G9 CDR L3
MQHLEYPLT
SEQ ID NO:37;5C11 CDR H1
GFTFSNYG
SEQ ID NO:38;5C11 CDR H2
I S SGGGST
SEQ ID NO:39;5C11 CDR H3
HPYDYGYYFDY
SEQ ID NO:40;5C11 CDR L1
QS IGTS
SEQ ID NO:41;5C11 CDR L2
YAS
SEQ ID NO:42;5C11 CDR L3
QQSDSWPFP
SEQ ID NO:43;5G3 CDR H1
GFTFNTYA
SEQ ID NO:44;5G3 CDR H2
IRSKSNNYAT
SEQ ID NO:45;5G3 CDR H3
HGSSLYYAMDY
SEQ ID NO:46;5G3 CDR L1
QE I SGY
SEQ ID NO:47;5G3 CDR L2
AAS
SEQ ID NO:48;5G3 CDR L3
LQYASYPYT
SEQ ID NO:49;6E6 VH FR1
EVQLVESGGDLVKPGGSLKLSCAAS
SEQ ID NO:50;6E6 VH FR2
MSWVRQTPDKRLEWVAT
SEQ ID NO:51;6E6 VH FR3
HYVDSVKGRFTI SRDNANHILYLQMS SLNSEDTAMYYCARSEQ ID NO:52;6E6 VH FR4
WGQGTSVTVS S
SEQ ID NO:53;6E6 VL FR1
DIVMTQSHKFMSTS IGDRVS ITCKAS
SEQ ID NO:54;6E6 VL FR2
VAWYQQKPGQSPKLLIY
SEQ ID NO:55;6E6 VL FR3
TRHTGVPDRFTGSGSGTDFTLT I SNVQSEDLADYFC
SEQ ID NO:56;6E6 VL FR4
FGGGSKLAIK
SEQ ID NO:57;4G9 VH FR1
QVQLQQSGAELVRPGASVKLSCKAL
SEQ ID NO:58;4G9 VH FR2
MHWVKQTPVHGLEWIGA
SEQ ID NO:59;4G9 VH FR3
AYNQKFKGKATLTADKSSSTAYMELSRLTSEDSAVYYCTR
SEQ ID NO:60;4G9 VH FR4
WGQGTSVTVSS
SEQ ID NO:61;4G9 VL FR1
DIVMTQAAPSVPVTPGESVSISCRSS
SEQ ID NO:62;4G9 VL FR2
LYWFLQRPGQSPQLLIY
SEQ ID NO:63;4G9 VL FR3
NLASGVPDRFSGSGSGTAFTLRISRVEAEDVGVYYC
SEQ ID NO:64;4G9 VL FR4
VGAGTKLELK
SEQ ID NO:65;5C11 VH FR1
EVQLVESGGDLVKPGGSLKLSCAAS
SEQ ID NO:66;5C11 VH FR2
MSWVRQTPDKRLEWVAT
SEQ ID NO:67;5C11 VH FR3
YYPDSVKGRFTISRDNAKNSLYLQMSSLKSEDTAMYYCAR
SEQ ID NO:68;5C11 VH FR4
WGQGTTLTVSS
SEQ ID NO:69;5C11 VL FR1
DILLTQSPDILSVSPGERVSFSCRAS
SEQ ID NO:70;5C11 VL FR2
IHWYQQRTNGSPRLLIK
SEQ ID NO:71;5C11 VL FR3
ESISGIPSRFSGSGSGTDFTLSINSVESEDIADYYC
SEQ ID NO:72;5C11 VL FR4
FGSGTKLEKK
SEQ ID NO:73;5G3 VH FR1
EVQLVESGGGLVQPKGSLKLSCAAS
SEQ ID NO:74;5G3 VH FR2
MNWVRQAPGKGLEWVAR
SEQ ID NO:75;5G3 VH FR3
YYADSVKDRFTISRDDSQSMLHLQMNNLKTEDTAMYYCVR
SEQ ID NO:76;5G3 VH FR4
WGQGTSVTVSS
SEQ ID NO:77;5G3 VH FR1
DIQMTQSPSSLSASLGERVSLTCRAS
SEQ ID NO:78;5G3 VL FR2
LGWLQQKPDGTIKRLIY
SEQ ID NO:79;5G3 VL FR3
TLDSGVPKRFSGSRSGSAYSLTISSLESEDFADYYC
SEQ ID NO:80;5G3 VL FR4
FGGGTKLEIK
SEQ ID NO:81;ScFv前导肽
ATMGWSCIILFLVATATGVHS
SEQ ID NO:82;ScFv和CAR连接子
GSTSGSGKPGSGEGSTKG
SEQ ID NO:83;scFv间隔子
EF
SEQ ID NO:84;ScFv CH2/CH3
LFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDESRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:85;6E6 scFv氨基酸序列
ATMGWSCIILFLVATATGVHSDIVMTQSHKFMSTSIGDRVSITCKASQDVGHYVAWYQQKPGQSPKLLIYWASTRHTGVPDRFTGSGSGTDFTLTISNVQSEDLADYFCQQYNIYPWTFGGGSKLAIKGSTSGSGKPGSGEGSTKGEVQLVESGGDLVKPGGSLKLSCAASGFTFSNYGMSWVRQTPDKRLEWVATISSGGGYTHYVDSVKGRFTISRDNANHILYLQMSSLNSEDTAMYYCARHPRDFSYAMDYWGQGTSVTVSSEFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDESRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:86;4G9 scFv氨基酸序列
ATMGWSCIILFLVATATGVHSDIVMTQAAPSVPVTPGESVSISCRSSKSLLHSNGNTYLYWFLQRPGQSPQLLIYRMSNLASGVPDRFSGSGSGTAFTLRISRVEAEDVGVYYCMQHLEYPLTVGAGTKLELKGSTSGSGKPGSGEGSTKGQVQLQQSGAELVRPGASVKLSCKALGYTFTDYEMHWVKQTPVHGLEWIGAIHPGSGGTAYNQKFKGKATLTADKSSSTAYMELSRLTSEDSAVYYCTRRRPRFYGMDYWGQGTSVTVSSEFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDESRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:87;scFv前导肽核酸
GCCACCATGGGATGGTCATGTATCATCCTTTTTCTAGTAGCAACTGCAACCGGTGTACATTCC
SEQ ID NO:88;scFv和CAR连接子核酸
GGCTCCACCTCTGGATCCGGCAAGCCCGGATCTGGCGAGGGATCCACCAAGGGC
SEQ ID NO:89;scFv间隔子核酸
GAATTC
SEQ ID NO:90;scFv CH2/CH3核酸
CTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCACCGTGGACGAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA
SEQ ID NO:91;6E6 scFv全长核苷酸序列
GCCACCATGGGATGGTCATGTATCATCCTTTTTCTAGTAGCAACTGCAACCGGTGTACATTCCGACATTGTGATGACCCAGTCTCACAAATTCATGTCCACATCAATAGGAGACAGGGTCAGCATCACCTGCAAGGCCAGTCAGGATGTGGGTCATTATGTGGCCTGGTATCAACAGAAACCAGGTCAATCTCCTAAACTACTGATTTACTGGGCATCCACCCGGCACACTGGAGTCCCTGATCGCTTCACAGGTAGTGGATCTGGGACAGATTTCACTCTCACCATTAGCAATGTGCAGTCTGAAGACTTGGCAGATTATTTCTGTCAGCAATATAACATCTATCCGTGGACGTTCGGTGGAGGCTCCAAGCTGGCAATCAAAGGCTCCACCTCTGGATCCGGCAAGCCCGGATCTGGCGAGGGATCtACCAAGGGCGAGGTGCAGCTGGTGGAGTCTGGGGGAGACTTAGTGAAGCCTGGAGGGTCCCTGAAACTCTCCTGTGCAGCCTCTGGATTCACTTTCAGTAATTATGGCATGTCTTGGGTTCGCCAGACTCCAGACAAGAGGCTGGAGTGGGTCGCAACCATTAGTAGTGGTGGTGGTTACACTCACTATGTAGACAGTGTGAAGGGGCGATTCACCATTTCCAGAGACAATGCCAACCATATCCTGTACCTGCAAATGAGCAGTCTGAACTCTGAGGACACAGCCATGTATTATTGTGCAAGACACCCGAGGGATTTTTCCTATGCTATGGACTACTGGGGTCAGGGAACCTCAGTCACCGTCTCCTCAGAATTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCACCGTGGACGAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA
SEQ ID NO:92;4G9 scfv全长核苷酸序列
GCCACCATGGGATGGTCATGTATCATCCTTTTTCTAGTAGCAACTGCAACCGGTGTACATTCCGATATTGTGATGACTCAGGCTGCACCCTCTGTACCTGTCACTCCTGGAGAGTCAGTATCCATCTCCTGCAGGTCTAGTAAGAGTCTCCTGCATAGTAATGGCAACACTTACTTGTATTGGTTCCTGCAGAGGCCAGGCCAGTCTCCTCAGCTCCTGATATATCGGATGTCCAACCTTGCCTCAGGAGTCCCAGACAGGTTCAGTGGCAGTGGGTCAGGAACTGCTTTCACACTGAGAATCAGTAGAGTGGAGGCTGAGGATGTGGGTGTTTATTACTGTATGCAACATCTAGAATATCCTCTCACGGTCGGTGCTGGGACCAAGCTGGAGCTGAAAGGCTCCACCTCTGGATCCGGCAAGCCCGGATCTGGCGAGGGATCtACCAAGGGCCAGGTTCAACTGCAACAGTCTGGGGCTGAGCTGGTGAGGCCTGGGGCTTCAGTGAAGCTGTCCTGCAAGGCTTTGGGCTACACATTTACTGACTATGAAATGCACTGGGTGAAGCAGACACCTGTGCATGGCCTGGAATGGATTGGAGCTATTCATCCAGGAAGTGGTGGTACTGCCTATAATCAGAAGTTCAAGGGCAAGGCCACACTGACTGCAGACAAATCCTCCAGCACAGCCTACATGGAGCTCAGCAGGCTGACATCTGAGGACTCTGCTGTCTATTACTGTACAAGAAGGAGGCCTAGGTTCTATGGTATGGACTACTGGGGTCAAGGAACCTCAGTCACCGTCTCCTCAGAATTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCACCGTGGACGAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAATGA
SEQ ID NO:93;CAR前导肽
MGWSCI ILFLVATATGVHS
SEQ ID NO:94;仅CAR间隔子hIgG4铰链
VDESKYGPPCPPCP
SEQ ID NO:95;CAR hIgG4+CH3
VDESKYGPPCPPCPGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGKM
SEQ ID NO:96;CAR hIgG4+CH2/CH3
VDESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGKM
SEQ ID NO:97;CAR hCD28
FWVLVVVGGVLACYSLLVTVAFI IFWVRSKRSRLLHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRS
SEQ ID NO:98;CAR hCD137
KRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCEL
SEQ ID NO:99;CAR hCD3z
RVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
SEQ ID NO:100;6E6 CAR
MGWSCI ILFLVATATGVHSDIVMTQSHKFMSTSIGDRVSITCKASQDVGHYVAWYQQKPGQSPKLLIYWASTRHTGVPDRFTGSGSGTDFTLTI SNVQSEDLADYFCQQYNIYPWTFGGGSKLAIKGSTSGSGKPGSGEGSTKGEVQLVESGGDLVKPGGSLKLSCAASGFTFSNYGMSWVRQTPDKRLEWVATISSGGGYTHYVDSVKGRFTI SRDNANHILYLQMSSLNSEDTAMYYCARHPRDFSYAMDYWGQGTSVTVSSVDESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGKMFWVLVVVGGVLACYSLLVTVAFI IFWVRSKRSRGGHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
SEQ ID NO:101;4G9 CAR
MGWSCI ILFLVATATGVHSDIVMTQAAPSVPVTPGESVSISCRSSKSLLHSNGNTYLYWFLQRPGQSPQLLIYRMSNLASGVPDRFSGSGSGTAFTLRISRVEAEDVGVYYCMQHLEYPLTVGAGTKLELKGSTSGSGKPGSGEGSTKGQVQLQQSGAELVRPGASVKLSCKALGYTFTDYEMHWVKQTPVHGLEWIGAIHPGSGGTAYNQKFKGKATLTADKSSSTAYMELSRLTSEDSAVYYCTRRRPRFYGMDYWGQGTSVTVSSVDESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGKMFWVLVVVGGVLACYSLLVTVAFIIFWVRSKRSRGGHSDYMNMTPRRPGPTRKHYQPYAPPRDFAAYRSKRGRKKLLYIFKQPFMRPVQTTQEEDGCSCRFPEEEEGGCELRVKFSRSADAPAYQQGQNQLYNELNLGRREEYDVLDKRRGRDPEMGGKPRRKNPQEGLYNELQKDKMAEAYSEIGMKGERRRGKGHDGLYQGLSTATKDTYDALHMQALPPR
SEQ ID NO:102;ROR2-IG
MARGSALPRRPLLCIPAVWAAAALLLSVSRTSGEVEVLDPNDPLGPLDGQDGPI PTLKGYFLNFLEPVNNITIVQGQTAILHCKVAGNPPPNVRWLKNDAPVVQEPRRI I IRKTEYGSRLRIQDLDTTDTGYYQCVATNGMKTITATGVLFVRLGPTHSPNHNFQDDYHEDGFCQPYRGIACARFIGNRTIYVDSLQMQGEIENRITAAFTMIGTSTHLSDQCSQFAIPSFCHFVFPLCDARSRTPKPRELCRDECEVLESDLCRQEYTIARSNPLILMRLQLPKCEALPMPESPDAANCMRIGIPAERLGRYHQCYNGSGMDYRGTASTTKSGHQCQPWALQHPHSHHLSSTDFPELGGGHAYCRNPGGQMEGPWCFTQNKNVRMELCDVPSCSPRDSSKMGPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:103;ROR1-Ig
MHRPRRRGTRPPLLALLAALLLAARGAAAQETELSVSAELVPTSSWNISSELNKDSYLTLDEPMNNITTSLGQTAELHCKVSGNPPPTIRWFKNDAPVVQEPRRLSFRSTIYGSRLRIRNLDTTDTGYFQCVATNGKEVVSSTGVLFVKFGPPPTASPGYSDEYEEDGFCQPYRGIACARFIGNRTVYMESLHMQGEIENQITAAFTMIGTSSHLSDKCSQFAIPSLCHYAFPYCDETSSVPKPRDLCRDECEILENVLCQTEYIFARSNPMILMRLKLPNCEDLPQPESPEAANCIRIGIPMADPINKNHKCYNSTGVDYRGTVSVTKSGRQCQPWNSQYPHTHTFTALRFPELNGGHSYCRNPGNQKEAPWCFTLDENFKSDLCDIPACDSKDSKEKNKMEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:104;CAR前导肽核酸
ATGGGATGGTCATGTATCATCCTTTTTCTAGTAGCAACTGCAACCGGTGTACATTCC
SEQ ID NO:105;仅CAR间隔子hIgG4铰链核酸
GTCGACGAGTCCAAATATGGTCCCCCATGCCCACCATGCCCA
SEQ ID NO:106;CAR hIgG4+CH3核酸
GTCGACGAGTCCAAATATGGTCCCCCATGCCCACCATGCCCAGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGGCCTCCCGTCCTCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAGCCACAGGTGTACACCCTGCCCCCATCCCAGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAGGCTAACCGTGGACAAGAGCAGGTGGCAGGAGGGGAATGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACACAGAAGAGCCTCTCCCTGTCCCTAGGTAAAATG
SEQ ID NO:107;CAR hIgG4+CH2/CH3核酸
GTCGACGAGTCCAAATATGGTCCCCCATGCCCACCATGCCCAGCACCTGAGTTCCTGGGGGGACCATCAGTCTTCCTGTTCCCCCCAAAACCCAAGGACACTCTCATGATCTCCCGGACCCCTGAGGTCACGTGCGTGGTGGTGGACGTGAGCCAGGAAGACCCCGAGGTCCAGTTCAACTGGTACGTGGATGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTTCAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAACGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGGCCTCCCGTCCTCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAGCCACAGGTGTACACCCTGCCCCCATCCCAGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAGGCTAACCGTGGACAAGAGCAGGTGGCAGGAGGGGAATGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACACAGAAGAGCCTCTCCCTGTCCCTAGGTAAAATG
SEQ ID NO:108;CAR hCD28核酸
TTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGCTCCTGCACAGTGACTACATGAACATGACTCCCCGCCGCCCCGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCC
SEQ ID NO:109;CAR hCD137核酸
aaacggggcagaaagaaactcctgtatatattcaaacaaccatttatgagaccagtacaaactactcaagaggaagatggctgtagctgccgatttccagaagaagaagaaggaggatgtgaactg
SEQ ID NO:110;CAR hCD3z核酸
AGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTACAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTACAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTACCAGGGTCTCAGTACAGCCACCAAGGACACCTACGACGCCCTTCACATGCAGGCCCTGCCCCCTCGCTGA
SEQ ID NO:111;6E6 CAR核酸
ATGGGATGGTCATGTATCATCCTTTTTCTAGTAGCAACTGCAACCGGTGTACATTCCGACATTGTGATGACCCAGTCTCACAAATTCATGTCCACATCAATAGGAGACAGGGTCAGCATCACCTGCAAGGCCAGTCAGGATGTGGGTCATTATGTGGCCTGGTATCAACAGAAACCAGGTCAATCTCCTAAACTACTGATTTACTGGGCATCCACCCGGCACACTGGAGTCCCTGATCGCTTCACAGGTAGTGGATCTGGGACAGATTTCACTCTCACCATTAGCAATGTGCAGTCTGAAGACTTGGCAGATTATTTCTGTCAGCAATATAACATCTATCCGTGGACGTTCGGTGGAGGCTCCAAGCTGGCAATCAAAGGCTCCACCTCTGGATCCGGCAAGCCCGGATCTGGCGAGGGATCCACCAAGGGCGAGGTGCAGCTGGTGGAGTCTGGGGGAGACTTAGTGAAGCCTGGAGGGTCCCTGAAACTCTCCTGTGCAGCCTCTGGATTCACTTTCAGTAATTATGGCATGTCTTGGGTTCGCCAGACTCCAGACAAGAGGCTGGAGTGGGTCGCAACCATTAGTAGTGGTGGTGGTTACACTCACTATGTAGACAGTGTGAAGGGGCGATTCACCATTTCCAGAGACAATGCCAACCATATCCTGTACCTGCAAATGAGCAGTCTGAACTCTGAGGACACAGCCATGTATTATTGTGCAAGACACCCGAGGGATTTTTCCTATGCTATGGACTACTGGGGTCAGGGAACCTCAGTCACCGTCTCCTCAGTCGACGAGTCCAAATATGGTCCCCCATGCCCACCATGCCCAGCACCTGAGTTCCTGGGGGGACCATCAGTCTTCCTGTTCCCCCCAAAACCCAAGGACACTCTCATGATCTCCCGGACCCCTGAGGTCACGTGCGTGGTGGTGGACGTGAGCCAGGAAGACCCCGAGGTCCAGTTCAACTGGTACGTGGATGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTTCAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAACGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGGCCTCCCGTCCTCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAGCCACAGGTGTACACCCTGCCCCCATCCCAGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAGGCTAACCGTGGACAAGAGCAGGTGGCAGGAGGGGAATGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACACAGAAGAGCCTCTCCCTGTCCCTAGGTAAAATGTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGGGCGGACACAGTGACTACATGAACATGACTCCCCGCCGCCCTGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAAACGGGGCAGAAAGAAACTCCTGTATATATTCAAACAACCATTTATGAGACCAGTACAAACTACTCAAGAGGAAGATGGCTGTAGCTGCCGATTTCCAGAAGAAGAAGAAGGAGGATGTGAACTGAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTACAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTACAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTACCAGGGTCTCAGTACAGCCACCAAGGACACCTACGACGCCCTTCACATGCAGGCCCTGCCCCCTCGCTGA
SEQ ID NO:112;4G9 CAR核酸
ATGGGATGGTCATGTATCATCCTTTTTCTAGTAGCAACTGCAACCGGTGTACATTCCGATATTGTGATGACTCAGGCTGCACCCTCTGTACCTGTCACTCCTGGAGAGTCAGTATCCATCTCCTGCAGGTCTAGTAAGAGTCTCCTGCATAGTAATGGCAACACTTACTTGTATTGGTTCCTGCAGAGGCCAGGCCAGTCTCCTCAGCTCCTGATATATCGGATGTCCAACCTTGCCTCAGGAGTCCCAGACAGGTTCAGTGGCAGTGGGTCAGGAACTGCTTTCACACTGAGAATCAGTAGAGTGGAGGCTGAGGATGTGGGTGTTTATTACTGTATGCAACATCTAGAATATCCTCTCACGGTCGGTGCTGGGACCAAGCTGGAGCTGAAAGGCTCCACCTCTGGATCCGGCAAGCCCGGATCTGGCGAGGGATCCACCAAGGGCCAGGTTCAACTGCAACAGTCTGGGGCTGAGCTGGTGAGGCCTGGGGCTTCAGTGAAGCTGTCCTGCAAGGCTTTGGGCTACACATTTACTGACTATGAAATGCACTGGGTGAAGCAGACACCTGTGCATGGCCTGGAATGGATTGGAGCTATTCATCCAGGAAGTGGTGGTACTGCCTATAATCAGAAGTTCAAGGGCAAGGCCACACTGACTGCAGACAAATCCTCCAGCACAGCCTACATGGAGCTCAGCAGGCTGACATCTGAGGACTCTGCTGTCTATTACTGTACAAGAAGGAGGCCTAGGTTCTATGGTATGGACTACTGGGGTCAAGGAACCTCAGTCACCGTCTCCTCAGTCGACGAGTCCAAATATGGTCCCCCATGCCCACCATGCCCAGCACCTGAGTTCCTGGGGGGACCATCAGTCTTCCTGTTCCCCCCAAAACCCAAGGACACTCTCATGATCTCCCGGACCCCTGAGGTCACGTGCGTGGTGGTGGACGTGAGCCAGGAAGACCCCGAGGTCCAGTTCAACTGGTACGTGGATGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTTCAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAACGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGGCCTCCCGTCCTCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAGCCACAGGTGTACACCCTGCCCCCATCCCAGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTACCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAGGCTAACCGTGGACAAGAGCAGGTGGCAGGAGGGGAATGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACACAGAAGAGCCTCTCCCTGTCCCTAGGTAAAATGTTTTGGGTGCTGGTGGTGGTTGGTGGAGTCCTGGCTTGCTATAGCTTGCTAGTAACAGTGGCCTTTATTATTTTCTGGGTGAGGAGTAAGAGGAGCAGGGGCGGACACAGTGACTACATGAACATGACTCCCCGCCGCCCTGGGCCCACCCGCAAGCATTACCAGCCCTATGCCCCACCACGCGACTTCGCAGCCTATCGCTCCAAACGGGGCAGAAAGAAACTCCTGTATATATTCAAACAACCATTTATGAGACCAGTACAAACTACTCAAGAGGAAGATGGCTGTAGCTGCCGATTTCCAGAAGAAGAAGAAGGAGGATGTGAACTGAGAGTGAAGTTCAGCAGGAGCGCAGACGCCCCCGCGTACCAGCAGGGCCAGAACCAGCTCTATAACGAGCTCAATCTAGGACGAAGAGAGGAGTACGATGTTTTGGACAAGAGACGTGGCCGGGACCCTGAGATGGGGGGAAAGCCGAGAAGGAAGAACCCTCAGGAAGGCCTGTACAATGAACTGCAGAAAGATAAGATGGCGGAGGCCTACAGTGAGATTGGGATGAAAGGCGAGCGCCGGAGGGGCAAGGGGCACGATGGCCTTTACCAGGGTCTCAGTACAGCCACCAAGGACACCTACGACGCCCTTCACATGCAGGCCCTGCCCCCTCGCTGA
SEQ ID NO:113;人ROR2 Kringle结构域
HQCYNGSGMDYRGTASTTKSGHQCQPWALQHPHSHHLSSTDFPELGGGHAYCRNPGGQMEGPWCFTQNKNVRMELCDVPSCS
SEQ ID NO:114;人ROR2 Ig样结构域
AILHCKVAGNPPPNVRWLKNDAPVVQEPRRIIIRKTEYGSRLRIQDLDTTDTGYYQCVATNGMKTITAT
序列表
<110>加利福尼亚大学董事会
<120>抗ROR-2抗体和使用方法
<130>048537-632001WO
<150>US 62/936,900
<151>2019-11-18
<160>114
<170>PatentIn 3.5版
<210>1
<211>360
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>1
gaggtgcagc tggtggagtc tgggggagac ttagtgaagc ctggagggtc cctgaaactc60
tcctgtgcag cctctggatt cactttcagt aattatggca tgtcttgggt tcgccagact 120
ccagacaaga ggctggagtg ggtcgcaacc attagtagtg gtggtggtta cactcactat 180
gtagacagtg tgaaggggcg attcaccatt tccagagaca atgccaacca tatcctgtac 240
ctgcaaatga gcagtctgaa ctctgaggac acagccatgt attattgtgc aagacacccg 300
agggattttt cctatgctat ggactactgg ggtcagggaa cctcagtcac cgtctcctca 360
<210>2
<211>120
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>2
Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Lys Pro Gly Gly
1 5 1015
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
202530
Gly Met Ser Trp Val Arg Gln Thr Pro Asp Lys Arg Leu Glu Trp Val
354045
Ala Thr Ile Ser Ser Gly Gly Gly Tyr Thr His Tyr Val Asp Ser Val
505560
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Asn His Ile Leu Tyr
65707580
Leu Gln Met Ser Ser Leu Asn Ser Glu Asp Thr Ala Met Tyr Tyr Cys
859095
Ala Arg His Pro Arg Asp Phe Ser Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Ser Val Thr Val Ser Ser
115 120
<210>3
<211>321
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>3
gacattgtga tgacccagtc tcacaaattc atgtccacat caataggaga cagggtcagc60
atcacctgca aggccagtca ggatgtgggt cattatgtgg cctggtatca acagaaacca 120
ggtcaatctc ctaaactact gatttactgg gcatccaccc ggcacactgg agtccctgat 180
cgcttcacag gtagtggatc tgggacagat ttcactctca ccattagcaa tgtgcagtct 240
gaagacttgg cagattattt ctgtcagcaa tataacatct atccgtggac gttcggtgga 300
ggctccaagc tggcaatcaa a 321
<210>4
<211>107
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>4
Asp Ile Val Met Thr Gln Ser His Lys Phe Met Ser Thr Ser Ile Gly
1 5 1015
Asp Arg Val Ser Ile Thr Cys Lys Ala Ser Gln Asp Val Gly His Tyr
202530
Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile
354045
Tyr Trp Ala Ser Thr Arg His Thr Gly Val Pro Asp Arg Phe Thr Gly
505560
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Asn Val Gln Ser
65707580
Glu Asp Leu Ala Asp Tyr Phe Cys Gln Gln Tyr Asn Ile Tyr Pro Trp
859095
Thr Phe Gly Gly Gly Ser Lys Leu Ala Ile Lys
100 105
<210>5
<211>357
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>5
caggttcaac tgcaacagtc tggggctgag ctggtgaggc ctggggcttc agtgaagctg60
tcctgcaagg ctttgggcta cacatttact gactatgaaa tgcactgggt gaagcagaca 120
cctgtgcatg gcctggaatg gattggagct attcatccag gaagtggtgg tactgcctat 180
aatcagaagt tcaagggcaa ggccacactg actgcagaca aatcctccag cacagcctac 240
atggagctca gcaggctgac atctgaggac tctgctgtct attactgtac aagaaggagg 300
cctaggttct atggtatgga ctactggggt caaggaacct cagtcaccgt ctcctca357
<210>6
<211>119
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>6
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 1015
Ser Val Lys Leu Ser Cys Lys Ala Leu Gly Tyr Thr Phe Thr Asp Tyr
202530
Glu Met His Trp Val Lys Gln Thr Pro Val His Gly Leu Glu Trp Ile
354045
Gly Ala Ile His Pro Gly Ser Gly Gly Thr Ala Tyr Asn Gln Lys Phe
505560
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65707580
Met Glu Leu Ser Arg Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
859095
Thr Arg Arg Arg Pro Arg Phe Tyr Gly Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210>7
<211>336
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>7
gatattgtga tgactcaggc tgcaccctct gtacctgtca ctcctggaga gtcagtatcc60
atctcctgca ggtctagtaa gagtctcctg catagtaatg gcaacactta cttgtattgg 120
ttcctgcaga ggccaggcca gtctcctcag ctcctgatat atcggatgtc caaccttgcc 180
tcaggagtcc cagacaggtt cagtggcagt gggtcaggaa ctgctttcac actgagaatc 240
agtagagtgg aggctgagga tgtgggtgtt tattactgta tgcaacatct agaatatcct 300
ctcacggtcg gtgctgggac caagctggag ctgaaa 336
<210>8
<211>112
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>8
Asp Ile Val Met Thr Gln Ala Ala Pro Ser Val Pro Val Thr Pro Gly
1 5 1015
Glu Ser Val Ser Ile Ser Cys Arg Ser Ser Lys Ser Leu Leu His Ser
202530
Asn Gly Asn Thr Tyr Leu Tyr Trp Phe Leu Gln Arg Pro Gly Gln Ser
354045
Pro Gln Leu Leu Ile Tyr Arg Met Ser Asn Leu Ala Ser Gly Val Pro
505560
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Ala Phe Thr Leu Arg Ile
65707580
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln His
859095
Leu Glu Tyr Pro Leu Thr Val Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105 110
<210>9
<211>360
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>9
gaggtgcagc tggtggagtc tgggggagac ttggtgaagc ctggagggtc cctgaaactc60
tcctgtgcag cctctggatt cactttcagt aactatggca tgtcttgggt tcgccagact 120
ccagacaaga ggctggagtg ggtcgcaacc attagtagtg gtggtggttc cacctactat 180
ccagacagtg tgaaggggcg attcaccatc tccagagaca atgccaagaa ctccctgtac 240
ctgcaaatga gcagtctgaa gtctgaggac acagccatgt attactgtgc aagacatccc 300
tatgattacg ggtactactt tgactactgg ggccaaggca ccactctcac agtctcctca 360
<210>10
<211>120
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>10
Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Lys Pro Gly Gly
1 5 1015
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
202530
Gly Met Ser Trp Val Arg Gln Thr Pro Asp Lys Arg Leu Glu Trp Val
354045
Ala Thr Ile Ser Ser Gly Gly Gly Ser Thr Tyr Tyr Pro Asp Ser Val
505560
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65707580
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
859095
Ala Arg His Pro Tyr Asp Tyr Gly Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210>11
<211>321
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>11
gacatcttgc tgactcagtc tccagacatc ctgtctgtga gtccaggaga aagagtcagt60
ttctcctgca gggccagtca gagcattggc acaagcatac actggtatca gcagagaaca 120
aatggttctc caaggcttct cataaaatat gcttctgagt ctatctctgg gatcccttcc 180
aggtttagtg gcagtggatc agggacagat tttactctta gcatcaacag tgtggagtct 240
gaagatattg cagattatta ctgtcaacaa agtgatagct ggccattccc gttcggctcg 300
gggacaaaat tggaaaaaaa a 321
<210>12
<211>107
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>12
Asp Ile Leu Leu Thr Gln Ser Pro Asp Ile Leu Ser Val Ser Pro Gly
1 5 1015
Glu Arg Val Ser Phe Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Ser
202530
Ile His Trp Tyr Gln Gln Arg Thr Asn Gly Ser Pro Arg Leu Leu Ile
354045
Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro Ser Arg Phe Ser Gly
505560
Ser Gly Ser Gly Thr Asp Phe Thr Leu Ser Ile Asn Ser Val Glu Ser
65707580
Glu Asp Ile Ala Asp Tyr Tyr Cys Gln Gln Ser Asp Ser Trp Pro Phe
859095
Pro Phe Gly Ser Gly Thr Lys Leu Glu Lys Lys
100 105
<210>13
<211>366
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>13
gaggtgcagc ttgttgagtc tggtggagga ttggtgcagc ctaaagggtc attgaagctc60
tcatgtgcag cctctggatt caccttcaat acctacgcca tgaactgggt ccgccaggct 120
ccaggaaagg gtttggaatg ggttgctcgc ataagaagta aaagtaataa ttatgcaaca 180
tattatgccg attcagtgaa agacaggttc accatctcca gagatgattc acaaagcatg 240
ctccatctgc aaatgaacaa cttgaaaact gaggacacag ccatgtatta ctgtgtgaga 300
cacggtagta gcctctacta tgctatggac tactggggtc aaggaacctc agtcaccgtc 360
tcctca366
<210>14
<211>122
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>14
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Lys Gly
1 5 1015
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Thr Tyr
202530
Ala Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
354045
Ala Arg Ile Arg Ser Lys Ser Asn Asn Tyr Ala Thr Tyr Tyr Ala Asp
505560
Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp Ser Gln Ser Met
65707580
Leu His Leu Gln Met Asn Asn Leu Lys Thr Glu Asp Thr Ala Met Tyr
859095
Tyr Cys Val Arg His Gly Ser Ser Leu Tyr Tyr Ala Met Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210>15
<211>321
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>15
gacatccaga tgacccagtc tccatcctcc ttatctgcct ctctgggaga aagagtcagt60
ctcacttgtc gggcaagtca ggaaattagt ggttacttag gctggcttca gcagaaacca 120
gatggaacta ttaaacgcct gatctacgcc gcatccactt tagattctgg tgtcccaaaa 180
aggttcagtg gcagtaggtc tgggtcagct tattctctca ccatcagcag ccttgagtct 240
gaagattttg cagactatta ctgtctacaa tatgctagtt atccgtacac gttcggaggg 300
gggaccaagc tggaaataaa a 321
<210>16
<211>107
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>16
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Leu Gly
1 5 1015
Glu Arg Val Ser Leu Thr Cys Arg Ala Ser Gln Glu Ile Ser Gly Tyr
202530
Leu Gly Trp Leu Gln Gln Lys Pro Asp Gly Thr Ile Lys Arg Leu Ile
354045
Tyr Ala Ala Ser Thr Leu Asp Ser Gly Val Pro Lys Arg Phe Ser Gly
505560
Ser Arg Ser Gly Ser Ala Tyr Ser Leu Thr Ile Ser Ser Leu Glu Ser
65707580
Glu Asp Phe Ala Asp Tyr Tyr Cys Leu Gln Tyr Ala Ser Tyr Pro Tyr
859095
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210>17
<211>2832
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>17
atggcccggg gctcggcgct cccgcggcgg ccgctgctgt gcatcccggc cgtctgggcg60
gccgccgcgc ttctgctctc agtgtcccgg acttcaggtg aagtggaggt tctggatccg 120
aacgaccctt taggacccct tgatgggcag gacggcccga ttccaactct gaaaggttac 180
tttctgaatt ttctggagcc agtaaacaat atcaccattg tccaaggcca gacggcaatt 240
ctgcactgca aggtggcagg aaacccaccc cctaacgtgc ggtggctaaa gaatgatgcc 300
ccggtggtgc aggagccgcg gcggatcatc atccggaaga cagaatatgg ttcacgactg 360
cgaatccagg acctggacac gacagacact ggctactacc agtgcgtggc caccaacggg 420
atgaagacca ttaccgccac tggcgtcctg tttgtgcggc tgggtccaac gcacagccca 480
aatcataact ttcaggatga ttaccacgag gatgggttct gccagcctta ccggggaatt 540
gcctgtgcac gcttcattgg caaccggacc atttatgtgg actcgcttca gatgcagggg 600
gagattgaaa accgaatcac agcggccttc accatgatcg gcacgtctac gcacctgtcg 660
gaccagtgct cacagttcgc catcccatcc ttctgccact tcgtgtttcc tctgtgcgac 720
gcgcgctccc gggcacccaa gccgcgtgag ctgtgccgcg acgagtgcga ggtgctggag 780
agcgacctgt gccgccagga gtacaccatc gcccgctcca acccgctcat cctcatgcgg 840
cttcagctgc ccaagtgtga ggcgctgccc atgcctgaga gccccgacgc tgccaactgc 900
atgcgcattg gcatcccagc cgagaggctg ggccgctacc atcagtgcta taacggctca 960
ggcatggatt acagaggaac ggcaagcacc accaagtcag gccaccagtg ccagccgtgg1020
gccctgcagc acccccacag ccaccacctg tccagcacag acttccctga gcttggaggg1080
gggcacgcct actgccggaa ccccggaggc cagatggagg gcccctggtg ctttacgcag1140
aataaaaacg tacgcatgga actgtgtgac gtaccctcgt gtagtccccg agacagcagc1200
aagatgggga ttctgtacat cttggtcccc agcatcgcaa ttccactggt catcgcttgc1260
cttttcttct tggtttgcat gtgccggaat aagcagaagg catctgcgtc cacaccgcag1320
cggcgacagc tgatggcctc gcccagccaa gacatggaaa tgcccctcat taaccagcac1380
aaacaggcca aactcaaaga gatcagcctg tctgcggtga ggttcatgga ggagctggga1440
gaggaccggt ttgggaaagt ctacaaaggt cacctgttcg gccctgcccc gggggagcag1500
acccaggctg tggccatcaa aacgctgaag gacaaagcgg aggggcccct gcgggaggag1560
ttccggcatg aggctatgct gcgagcacgg ctgcaacacc ccaacgtcgt ctgcctgctg1620
ggcgtggtga ccaaggacca gcccctgagc atgatcttca gctactgttc gcacggcgac1680
ctccacgaat tcctggtcat gcgctcgccg cactcggacg tgggcagcac cgatgatgac1740
cgcacggtga agtccgccct ggagcccccc gacttcgtgc accttgtggc acagatcgcg1800
gcggggatgg agtacctatc cagccaccac gtggttcaca aggacctggc cacccgcaat1860
gtgctagtgt acgacaagct gaacgtgaag atctcagact tgggcctctt ccgagaggtg1920
tatgccgccg attactacaa gctgctgggg aactcgctgc tgcctatccg ctggatggcc1980
ccagaggcca tcatgtacgg caagttctcc atcgactcag acatctggtc ctacggtgtg2040
gtcctgtggg aggtcttcag ctacggcctg cagccctact gcgggtactc caaccaggat2100
gtggtggaga tgatccggaa ccggcaggtg ctgccttgcc ccgatgactg tcccgcctgg2160
gtgtatgccc tcatgatcga gtgctggaac gagttcccca gccggcggcc ccgcttcaag2220
gacatccaca gccggctccg agcctggggc aacctttcca actacaacag ctcggcgcag2280
acctcggggg ccagcaacac cacgcagacc agctccctga gcaccagccc agtgagcaat2340
gtgagcaacg cccgctacgt ggggcccaag cagaaggccc cgcccttccc acagccccag2400
ttcatcccca tgaagggcca gatcagaccc atggtgcccc cgccgcagct ctacgtcccc2460
gtcaacggct accagccggt gccggcctat ggggcctacc tgcccaactt ctacccggtg2520
cagatcccaa tgcagatggc cccgcagcag gtgcctcctc agatggtccc caagcccagc2580
tcacaccaca gtggcagtgg ctccaccagc acaggctacg tcaccacggc cccctccaac2640
acatccatgg cagacagggc agccctgctc tcagagggcg ctgatgacac acagaacgcc2700
ccagaagatg gggcccagag caccgtgcag gaagcagagg aggaggagga aggctctgtc2760
ccagagactg agctgctggg ggactgtgac actctgcagg tggacgaggc ccaagtccag2820
ctggaagctt ga2832
<210>18
<211>943
<212>PRT
<213>智人(Homo sapiens)
<400>18
Met Ala Arg Gly Ser Ala Leu Pro Arg Arg Pro Leu Leu Cys Ile Pro
1 5 1015
Ala Val Trp Ala Ala Ala Ala Leu Leu Leu Ser Val Ser Arg Thr Ser
202530
Gly Glu Val Glu Val Leu Asp Pro Asn Asp Pro Leu Gly Pro Leu Asp
354045
Gly Gln Asp Gly Pro Ile Pro Thr Leu Lys Gly Tyr Phe Leu Asn Phe
505560
Leu Glu Pro Val Asn Asn Ile Thr Ile Val Gln Gly Gln Thr Ala Ile
65707580
Leu His Cys Lys Val Ala Gly Asn Pro Pro Pro Asn Val Arg Trp Leu
859095
Lys Asn Asp Ala Pro Val Val Gln Glu Pro Arg Arg Ile Ile Ile Arg
100 105 110
Lys Thr Glu Tyr Gly Ser Arg Leu Arg Ile Gln Asp Leu Asp Thr Thr
115 120 125
Asp Thr Gly Tyr Tyr Gln Cys Val Ala Thr Asn Gly Met Lys Thr Ile
130 135 140
Thr Ala Thr Gly Val Leu Phe Val Arg Leu Gly Pro Thr His Ser Pro
145 150 155 160
Asn His Asn Phe Gln Asp Asp Tyr His Glu Asp Gly Phe Cys Gln Pro
165 170 175
Tyr Arg Gly Ile Ala Cys Ala Arg Phe Ile Gly Asn Arg Thr Ile Tyr
180 185 190
Val Asp Ser Leu Gln Met Gln Gly Glu Ile Glu Asn Arg Ile Thr Ala
195 200 205
Ala Phe Thr Met Ile Gly Thr Ser Thr His Leu Ser Asp Gln Cys Ser
210 215 220
Gln Phe Ala Ile Pro Ser Phe Cys His Phe Val Phe Pro Leu Cys Asp
225 230 235 240
Ala Arg Ser Arg Thr Pro Lys Pro Arg Glu Leu Cys Arg Asp Glu Cys
245 250 255
Glu Val Leu Glu Ser Asp Leu Cys Arg Gln Glu Tyr Thr Ile Ala Arg
260 265 270
Ser Asn Pro Leu Ile Leu Met Arg Leu Gln Leu Pro Lys Cys Glu Ala
275 280 285
Leu Pro Met Pro Glu Ser Pro Asp Ala Ala Asn Cys Met Arg Ile Gly
290 295 300
Ile Pro Ala Glu Arg Leu Gly Arg Tyr His Gln Cys Tyr Asn Gly Ser
305 310 315 320
Gly Met Asp Tyr Arg Gly Thr Ala Ser Thr Thr Lys Ser Gly His Gln
325 330 335
Cys Gln Pro Trp Ala Leu Gln His Pro His Ser His His Leu Ser Ser
340 345 350
Thr Asp Phe Pro Glu Leu Gly Gly Gly His Ala Tyr Cys Arg Asn Pro
355 360 365
Gly Gly Gln Met Glu Gly Pro Trp Cys Phe Thr Gln Asn Lys Asn Val
370 375 380
Arg Met Glu Leu Cys Asp Val Pro Ser Cys Ser Pro Arg Asp Ser Ser
385 390 395 400
Lys Met Gly Ile Leu Tyr Ile Leu Val Pro Ser Ile Ala Ile Pro Leu
405 410 415
Val Ile Ala Cys Leu Phe Phe Leu Val Cys Met Cys Arg Asn Lys Gln
420 425 430
Lys Ala Ser Ala Ser Thr Pro Gln Arg Arg Gln Leu Met Ala Ser Pro
435 440 445
Ser Gln Asp Met Glu Met Pro Leu Ile Asn Gln His Lys Gln Ala Lys
450 455 460
Leu Lys Glu Ile Ser Leu Ser Ala Val Arg Phe Met Glu Glu Leu Gly
465 470 475 480
Glu Asp Arg Phe Gly Lys Val Tyr Lys Gly His Leu Phe Gly Pro Ala
485 490 495
Pro Gly Glu Gln Thr Gln Ala Val Ala Ile Lys Thr Leu Lys Asp Lys
500 505 510
Ala Glu Gly Pro Leu Arg Glu Glu Phe Arg His Glu Ala Met Leu Arg
515 520 525
Ala Arg Leu Gln His Pro Asn Val Val Cys Leu Leu Gly Val Val Thr
530 535 540
Lys Asp Gln Pro Leu Ser Met Ile Phe Ser Tyr Cys Ser His Gly Asp
545 550 555 560
Leu His Glu Phe Leu Val Met Arg Ser Pro His Ser Asp Val Gly Ser
565 570 575
Thr Asp Asp Asp Arg Thr Val Lys Ser Ala Leu Glu Pro Pro Asp Phe
580 585 590
Val His Leu Val Ala Gln Ile Ala Ala Gly Met Glu Tyr Leu Ser Ser
595 600 605
His His Val Val His Lys Asp Leu Ala Thr Arg Asn Val Leu Val Tyr
610 615 620
Asp Lys Leu Asn Val Lys Ile Ser Asp Leu Gly Leu Phe Arg Glu Val
625 630 635 640
Tyr Ala Ala Asp Tyr Tyr Lys Leu Leu Gly Asn Ser Leu Leu Pro Ile
645 650 655
Arg Trp Met Ala Pro Glu Ala Ile Met Tyr Gly Lys Phe Ser Ile Asp
660 665 670
Ser Asp Ile Trp Ser Tyr Gly Val Val Leu Trp Glu Val Phe Ser Tyr
675 680 685
Gly Leu Gln Pro Tyr Cys Gly Tyr Ser Asn Gln Asp Val Val Glu Met
690 695 700
Ile Arg Asn Arg Gln Val Leu Pro Cys Pro Asp Asp Cys Pro Ala Trp
705 710 715 720
Val Tyr Ala Leu Met Ile Glu Cys Trp Asn Glu Phe Pro Ser Arg Arg
725 730 735
Pro Arg Phe Lys Asp Ile His Ser Arg Leu Arg Ala Trp Gly Asn Leu
740 745 750
Ser Asn Tyr Asn Ser Ser Ala Gln Thr Ser Gly Ala Ser Asn Thr Thr
755 760 765
Gln Thr Ser Ser Leu Ser Thr Ser Pro Val Ser Asn Val Ser Asn Ala
770 775 780
Arg Tyr Val Gly Pro Lys Gln Lys Ala Pro Pro Phe Pro Gln Pro Gln
785 790 795 800
Phe Ile Pro Met Lys Gly Gln Ile Arg Pro Met Val Pro Pro Pro Gln
805 810 815
Leu Tyr Val Pro Val Asn Gly Tyr Gln Pro Val Pro Ala Tyr Gly Ala
820 825 830
Tyr Leu Pro Asn Phe Tyr Pro Val Gln Ile Pro Met Gln Met Ala Pro
835 840 845
Gln Gln Val Pro Pro Gln Met Val Pro Lys Pro Ser Ser His His Ser
850 855 860
Gly Ser Gly Ser Thr Ser Thr Gly Tyr Val Thr Thr Ala Pro Ser Asn
865 870 875 880
Thr Ser Met Ala Asp Arg Ala Ala Leu Leu Ser Glu Gly Ala Asp Asp
885 890 895
Thr Gln Asn Ala Pro Glu Asp Gly Ala Gln Ser Thr Val Gln Glu Ala
900 905 910
Glu Glu Glu Glu Glu Gly Ser Val Pro Glu Thr Glu Leu Leu Gly Asp
915 920 925
Cys Asp Thr Leu Gln Val Asp Glu Ala Gln Val Gln Leu Glu Ala
930 935 940
<210>19
<211>2835
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>19
atggctcggg gctgggtgcg gccgagccgt gtgcctctgt gcgcccgggc cgtctggacg60
gctgcggcgc tcctgctctg gacaccctgg acggcaggtg aagtggaaga ttcggaggca 120
atcgacacct tgggacaacc tgatggaccg gacagcccac ttcccactct gaaaggctac 180
tttctgaatt ttctggagcc agtcaacaat atcaccattg ttcagggcca gacggcaatc 240
ctgcactgca aggtggcggg aaacccacct cccaatgtgc ggtggctgaa gaatgatgcc 300
ccggttgtgc aagagccacg aagggtcgtc atccggaaga cagaatacgg ctcccggctg 360
cggatccaag acctggacac aacagacaca ggctactacc agtgtgtggc taccaacggg 420
ctgaagacca tcactgccac tggggttcta tatgtgcggc tcggtccgac gcacagcccg 480
aaccacaatt ttcaggatga cgatcaggaa gatggcttct gccagccgta ccgagggatc 540
gcttgtgcgc gcttcattgg gaaccggact atttatgtgg actccctcca gatgcagggg 600
gagattgaaa accgaatcac agctgccttc accatgatcg gcacctccac gcaactgtca 660
gaccagtgtt cacagtttgc catcccatcc ttctgccact tcgtcttccc tctgtgcgac 720
gcatgctccc gggcgcccaa gcctcgcgaa ctgtgccggg atgaatgtga ggtgctggag 780
aacgacctgt gccgccagga gtacaccatc gcccgctcca acccgctcat cctcatgcgg 840
ctccagctgc ccaagtgcga agcgctgccc atgcccgaga gcccggatgc tgcgaactgc 900
atgcgcatcg ggatccccgc ggagaggctg ggtcgctacc accagtgcta caacggctcc 960
ggcgccgatt acagggggat ggccagtacc accaagtcag gccaccagtg tcagccttgg1020
gctctgcagc acccccacag ccatcgccta tccagcacgg aattccctga gctgggagga1080
ggccatgcct actgccggaa ccccgggggc cagatggaag gcccgtggtg ctttacgcag1140
aataaaaacg tacgcgtgga actgtgtgac gtacccccgt gtagtccccg atatggcagc1200
aagatgggga ttctgtacat cctggtcccc agcattgcta tccccctggt catcgcttgc1260
ctgttcttcc tcgtctgcat gtgccgcaac aaacagaagg cttcggcctc caccccacag1320
cgccggcagc tgatggcctc tcccagccag gacatggaga tgccactcat cagccagcac1380
aaacaggcca aactcaaaga gatcagcttg tccacagtga ggttcatgga ggagctcggg1440
gaggaccggt ttggcaaggt ctacaaaggc cacctgttcg ggcctgcccc aggagaacca1500
acccaggccg tggccatcaa gacgctgaaa gacaaggctg aggggcccct gcgggaggag1560
ttccggcaag aggcgatgct ccgggcccga ctgcagcacc ccaacatcgt ctgtctccta1620
ggcgtcgtga ccaaggacca acccttgagc atgatcttca gctactgttc ccatggcgac1680
cttcatgaat tcctggtcat gcgctcgccg cactccgatg tgggcagcac cgatgacgac1740
cgcacagtga agtcagccct ggagcccccg gacttcgtgc acgtggtggc gcagatcgct1800
gcggggatgg agttcctgtc cagccaccac gtgtgccata aggacctggc cacacgcaat1860
gtgctggtgt acgacaagct gaacgtgagg atctcagact tgggcctctt ccgtgaggta1920
tactccgcag attactacaa actcatgggc aattcactgc tgcccatccg ctggatgtcc1980
cccgaggccg tcatgtatgg aaagttctcc atcgactctg acatctggtc ctacggtgtg2040
gtcctctggg aggtctttag ctacggcctg cagccctact gtgggtactc caaccaggac2100
gtggtggaga tgatccggag ccggcaggtg ctgccctgcc cggatgactg ccccgcctgg2160
gtctatgccc tcatgattga atgctggaat gagttcccaa gccggaggcc ccgctttaag2220
gacatccaca gccggctccg gtcctggggc aacctatcca actataatag ttccgcgcag2280
acctcaggag ccagcaacac cacacagacc agctccctga gcaccagccc cgtaagcaat2340
gtgagcaatg cccgctatat ggcccccaag cagaaggccc agcccttccc acagcctcag2400
ttcatcccca tgaagggtca gatcagaccc ttggtgcccc ccgcacagct gtacatcccg2460
gtgaacggct atcagccggt accggcatac ggggcctacc tgcccaactt ctacccagtc2520
cagatcccca tgcagatggc cccacagcag gtgccccctc agatggtccc caagccgagc2580
tcacaccaca gtggcagcgg ctccaccagc actggctacg tcaccacggc gccctccaat2640
acatctgtgg cggacagggc ggccctactc tctgagggca ccgaggatgt acagaacatc2700
gcggaagacg tggcccagag ccctgtgcag gaagcagagg aggaggagga ggggtctgtc2760
cctgagactg aactcctggg agacaatgac acgctccagg tgaccgaggc ggctcatgtc2820
cagcttgaag cctga 2835
<210>20
<211>944
<212>PRT
<213>小家鼠(Mus musculus)
<400>20
Met Ala Arg Gly Trp Val Arg Pro Ser Arg Val Pro Leu Cys Ala Arg
1 5 1015
Ala Val Trp Thr Ala Ala Ala Leu Leu Leu Trp Thr Pro Trp Thr Ala
202530
Gly Glu Val Glu Asp Ser Glu Ala Ile Asp Thr Leu Gly Gln Pro Asp
354045
Gly Pro Asp Ser Pro Leu Pro Thr Leu Lys Gly Tyr Phe Leu Asn Phe
505560
Leu Glu Pro Val Asn Asn Ile Thr Ile Val Gln Gly Gln Thr Ala Ile
65707580
Leu His Cys Lys Val Ala Gly Asn Pro Pro Pro Asn Val Arg Trp Leu
859095
Lys Asn Asp Ala Pro Val Val Gln Glu Pro Arg Arg Val Val Ile Arg
100 105 110
Lys Thr Glu Tyr Gly Ser Arg Leu Arg Ile Gln Asp Leu Asp Thr Thr
115 120 125
Asp Thr Gly Tyr Tyr Gln Cys Val Ala Thr Asn Gly Leu Lys Thr Ile
130 135 140
Thr Ala Thr Gly Val Leu Tyr Val Arg Leu Gly Pro Thr His Ser Pro
145 150 155 160
Asn His Asn Phe Gln Asp Asp Asp Gln Glu Asp Gly Phe Cys Gln Pro
165 170 175
Tyr Arg Gly Ile Ala Cys Ala Arg Phe Ile Gly Asn Arg Thr Ile Tyr
180 185 190
Val Asp Ser Leu Gln Met Gln Gly Glu Ile Glu Asn Arg Ile Thr Ala
195 200 205
Ala Phe Thr Met Ile Gly Thr Ser Thr Gln Leu Ser Asp Gln Cys Ser
210 215 220
Gln Phe Ala Ile Pro Ser Phe Cys His Phe Val Phe Pro Leu Cys Asp
225 230 235 240
Ala Cys Ser Arg Ala Pro Lys Pro Arg Glu Leu Cys Arg Asp Glu Cys
245 250 255
Glu Val Leu Glu Asn Asp Leu Cys Arg Gln Glu Tyr Thr Ile Ala Arg
260 265 270
Ser Asn Pro Leu Ile Leu Met Arg Leu Gln Leu Pro Lys Cys Glu Ala
275 280 285
Leu Pro Met Pro Glu Ser Pro Asp Ala Ala Asn Cys Met Arg Ile Gly
290 295 300
Ile Pro Ala Glu Arg Leu Gly Arg Tyr His Gln Cys Tyr Asn Gly Ser
305 310 315 320
Gly Ala Asp Tyr Arg Gly Met Ala Ser Thr Thr Lys Ser Gly His Gln
325 330 335
Cys Gln Pro Trp Ala Leu Gln His Pro His Ser His Arg Leu Ser Ser
340 345 350
Thr Glu Phe Pro Glu Leu Gly Gly Gly His Ala Tyr Cys Arg Asn Pro
355 360 365
Gly Gly Gln Met Glu Gly Pro Trp Cys Phe Thr Gln Asn Lys Asn Val
370 375 380
Arg Val Glu Leu Cys Asp Val Pro Pro Cys Ser Pro Arg Tyr Gly Ser
385 390 395 400
Lys Met Gly Ile Leu Tyr Ile Leu Val Pro Ser Ile Ala Ile Pro Leu
405 410 415
Val Ile Ala Cys Leu Phe Phe Leu Val Cys Met Cys Arg Asn Lys Gln
420 425 430
Lys Ala Ser Ala Ser Thr Pro Gln Arg Arg Gln Leu Met Ala Ser Pro
435 440 445
Ser Gln Asp Met Glu Met Pro Leu Ile Ser Gln His Lys Gln Ala Lys
450 455 460
Leu Lys Glu Ile Ser Leu Ser Thr Val Arg Phe Met Glu Glu Leu Gly
465 470 475 480
Glu Asp Arg Phe Gly Lys Val Tyr Lys Gly His Leu Phe Gly Pro Ala
485 490 495
Pro Gly Glu Pro Thr Gln Ala Val Ala Ile Lys Thr Leu Lys Asp Lys
500 505 510
Ala Glu Gly Pro Leu Arg Glu Glu Phe Arg Gln Glu Ala Met Leu Arg
515 520 525
Ala Arg Leu Gln His Pro Asn Ile Val Cys Leu Leu Gly Val Val Thr
530 535 540
Lys Asp Gln Pro Leu Ser Met Ile Phe Ser Tyr Cys Ser His Gly Asp
545 550 555 560
Leu His Glu Phe Leu Val Met Arg Ser Pro His Ser Asp Val Gly Ser
565 570 575
Thr Asp Asp Asp Arg Thr Val Lys Ser Ala Leu Glu Pro Pro Asp Phe
580 585 590
Val His Val Val Ala Gln Ile Ala Ala Gly Met Glu Phe Leu Ser Ser
595 600 605
His His Val Cys His Lys Asp Leu Ala Thr Arg Asn Val Leu Val Tyr
610 615 620
Asp Lys Leu Asn Val Arg Ile Ser Asp Leu Gly Leu Phe Arg Glu Val
625 630 635 640
Tyr Ser Ala Asp Tyr Tyr Lys Leu Met Gly Asn Ser Leu Leu Pro Ile
645 650 655
Arg Trp Met Ser Pro Glu Ala Val Met Tyr Gly Lys Phe Ser Ile Asp
660 665 670
Ser Asp Ile Trp Ser Tyr Gly Val Val Leu Trp Glu Val Phe Ser Tyr
675 680 685
Gly Leu Gln Pro Tyr Cys Gly Tyr Ser Asn Gln Asp Val Val Glu Met
690 695 700
Ile Arg Ser Arg Gln Val Leu Pro Cys Pro Asp Asp Cys Pro Ala Trp
705 710 715 720
Val Tyr Ala Leu Met Ile Glu Cys Trp Asn Glu Phe Pro Ser Arg Arg
725 730 735
Pro Arg Phe Lys Asp Ile His Ser Arg Leu Arg Ser Trp Gly Asn Leu
740 745 750
Ser Asn Tyr Asn Ser Ser Ala Gln Thr Ser Gly Ala Ser Asn Thr Thr
755 760 765
Gln Thr Ser Ser Leu Ser Thr Ser Pro Val Ser Asn Val Ser Asn Ala
770 775 780
Arg Tyr Met Ala Pro Lys Gln Lys Ala Gln Pro Phe Pro Gln Pro Gln
785 790 795 800
Phe Ile Pro Met Lys Gly Gln Ile Arg Pro Leu Val Pro Pro Ala Gln
805 810 815
Leu Tyr Ile Pro Val Asn Gly Tyr Gln Pro Val Pro Ala Tyr Gly Ala
820 825 830
Tyr Leu Pro Asn Phe Tyr Pro Val Gln Ile Pro Met Gln Met Ala Pro
835 840 845
Gln Gln Val Pro Pro Gln Met Val Pro Lys Pro Ser Ser His His Ser
850 855 860
Gly Ser Gly Ser Thr Ser Thr Gly Tyr Val Thr Thr Ala Pro Ser Asn
865 870 875 880
Thr Ser Val Ala Asp Arg Ala Ala Leu Leu Ser Glu Gly Thr Glu Asp
885 890 895
Val Gln Asn Ile Ala Glu Asp Val Ala Gln Ser Pro Val Gln Glu Ala
900 905 910
Glu Glu Glu Glu Glu Gly Ser Val Pro Glu Thr Glu Leu Leu Gly Asp
915 920 925
Asn Asp Thr Leu Gln Val Thr Glu Ala Ala His Val Gln Leu Glu Ala
930 935 940
<210>21
<211>1209
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>21
atggcccggg gctcggcgct cccgcggcgg ccgctgctgt gcatcccggc cgtctgggcg60
gccgccgcgc ttctgctctc agtgtcccgg acttcaggtg aagtggaggt tctggatccg 120
aacgaccctt taggacccct tgatgggcag gacggcccga ttccaactct gaaaggttac 180
tttctgaatt ttctggagcc agtaaacaat atcaccattg tccaaggcca gacggcaatt 240
ctgcactgca aggtggcagg aaacccaccc cctaacgtgc ggtggctaaa gaatgatgcc 300
ccggtggtgc aggagccgcg gcggatcatc atccggaaga cagaatatgg ttcacgactg 360
cgaatccagg acctggacac gacagacact ggctactacc agtgcgtggc caccaacggg 420
atgaagacca ttaccgccac tggcgtcctg tttgtgcggc tgggtccaac gcacagccca 480
aatcataact ttcaggatga ttaccacgag gatgggttct gccagcctta ccggggaatt 540
gcctgtgcac gcttcattgg caaccggacc atttatgtgg actcgcttca gatgcagggg 600
gagattgaaa accgaatcac agcggccttc accatgatcg gcacgtctac gcacctgtcg 660
gaccagtgct cacagttcgc catcccatcc ttctgccact tcgtgtttcc tctgtgcgac 720
gcgcgctccc gggcacccaa gccgcgtgag ctgtgccgcg acgagtgcga ggtgctggag 780
agcgacctgt gccgccagga gtacaccatc gcccgctcca acccgctcat cctcatgcgg 840
cttcagctgc ccaagtgtga ggcgctgccc atgcctgaga gccccgacgc tgccaactgc 900
atgcgcattg gcatcccagc cgagaggctg ggccgctacc atcagtgcta taacggctca 960
ggcatggatt acagaggaac ggcaagcacc accaagtcag gccaccagtg ccagccgtgg1020
gccctgcagc acccccacag ccaccacctg tccagcacag acttccctga gcttggaggg1080
gggcacgcct actgccggaa ccccggaggc cagatggagg gcccctggtg ctttacgcag1140
aataaaaacg tacgcatgga actgtgtgac gtaccctcgt gtagtccccg agacagcagc1200
aagatgggg1209
<210>22
<211>403
<212>PRT
<213>智人(Homo sapiens)
<400>22
Met Ala Arg Gly Ser Ala Leu Pro Arg Arg Pro Leu Leu Cys Ile Pro
1 5 1015
Ala Val Trp Ala Ala Ala Ala Leu Leu Leu Ser Val Ser Arg Thr Ser
202530
Gly Glu Val Glu Val Leu Asp Pro Asn Asp Pro Leu Gly Pro Leu Asp
354045
Gly Gln Asp Gly Pro Ile Pro Thr Leu Lys Gly Tyr Phe Leu Asn Phe
505560
Leu Glu Pro Val Asn Asn Ile Thr Ile Val Gln Gly Gln Thr Ala Ile
65707580
Leu His Cys Lys Val Ala Gly Asn Pro Pro Pro Asn Val Arg Trp Leu
859095
Lys Asn Asp Ala Pro Val Val Gln Glu Pro Arg Arg Ile Ile Ile Arg
100 105 110
Lys Thr Glu Tyr Gly Ser Arg Leu Arg Ile Gln Asp Leu Asp Thr Thr
115 120 125
Asp Thr Gly Tyr Tyr Gln Cys Val Ala Thr Asn Gly Met Lys Thr Ile
130 135 140
Thr Ala Thr Gly Val Leu Phe Val Arg Leu Gly Pro Thr His Ser Pro
145 150 155 160
Asn His Asn Phe Gln Asp Asp Tyr His Glu Asp Gly Phe Cys Gln Pro
165 170 175
Tyr Arg Gly Ile Ala Cys Ala Arg Phe Ile Gly Asn Arg Thr Ile Tyr
180 185 190
Val Asp Ser Leu Gln Met Gln Gly Glu Ile Glu Asn Arg Ile Thr Ala
195 200 205
Ala Phe Thr Met Ile Gly Thr Ser Thr His Leu Ser Asp Gln Cys Ser
210 215 220
Gln Phe Ala Ile Pro Ser Phe Cys His Phe Val Phe Pro Leu Cys Asp
225 230 235 240
Ala Arg Ser Arg Thr Pro Lys Pro Arg Glu Leu Cys Arg Asp Glu Cys
245 250 255
Glu Val Leu Glu Ser Asp Leu Cys Arg Gln Glu Tyr Thr Ile Ala Arg
260 265 270
Ser Asn Pro Leu Ile Leu Met Arg Leu Gln Leu Pro Lys Cys Glu Ala
275 280 285
Leu Pro Met Pro Glu Ser Pro Asp Ala Ala Asn Cys Met Arg Ile Gly
290 295 300
Ile Pro Ala Glu Arg Leu Gly Arg Tyr His Gln Cys Tyr Asn Gly Ser
305 310 315 320
Gly Met Asp Tyr Arg Gly Thr Ala Ser Thr Thr Lys Ser Gly His Gln
325 330 335
Cys Gln Pro Trp Ala Leu Gln His Pro His Ser His His Leu Ser Ser
340 345 350
Thr Asp Phe Pro Glu Leu Gly Gly Gly His Ala Tyr Cys Arg Asn Pro
355 360 365
Gly Gly Gln Met Glu Gly Pro Trp Cys Phe Thr Gln Asn Lys Asn Val
370 375 380
Arg Met Glu Leu Cys Asp Val Pro Ser Cys Ser Pro Arg Asp Ser Ser
385 390 395 400
Lys Met Gly
<210>23
<211>1209
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>23
atggctcggg gctgggtgcg gccgagccgt gtgcctctgt gcgcccgggc cgtctggacg60
gctgcggcgc tcctgctctg gacaccctgg acggcaggtg aagtggaaga ttcggaggca 120
atcgacacct tgggacaacc tgatggaccg gacagcccac ttcccactct gaaaggctac 180
tttctgaatt ttctggagcc agtcaacaat atcaccattg ttcagggcca gacggcaatc 240
ctgcactgca aggtggcggg aaacccacct cccaatgtgc ggtggctgaa gaatgatgcc 300
ccggttgtgc aagagccacg aagggtcgtc atccggaaga cagaatacgg ctcccggctg 360
cggatccaag acctggacac aacagacaca ggctactacc agtgtgtggc taccaacggg 420
ctgaagacca tcactgccac tggggttcta tatgtgcggc tcggtccgac gcacagcccg 480
aaccacaatt ttcaggatga cgatcaggaa gatggcttct gccagccgta ccgagggatc 540
gcttgtgcgc gcttcattgg gaaccggact atttatgtgg actccctcca gatgcagggg 600
gagattgaaa accgaatcac agctgccttc accatgatcg gcacctccac gcaactgtca 660
gaccagtgtt cacagtttgc catcccatcc ttctgccact tcgtcttccc tctgtgcgac 720
gcatgctccc gggcgcccaa gcctcgcgaa ctgtgccggg atgaatgtga ggtgctggag 780
aacgacctgt gccgccagga gtacaccatc gcccgctcca acccgctcat cctcatgcgg 840
ctccagctgc ccaagtgcga agcgctgccc atgcccgaga gcccggatgc tgcgaactgc 900
atgcgcatcg ggatccccgc ggagaggctg ggtcgctacc accagtgcta caacggctcc 960
ggcgccgatt acagggggat ggccagtacc accaagtcag gccaccagtg tcagccttgg1020
gctctgcagc acccccacag ccatcgccta tccagcacgg aattccctga gctgggagga1080
ggccatgcct actgccggaa ccccgggggc cagatggaag gcccgtggtg ctttacgcag1140
aataaaaacg tacgcgtgga actgtgtgac gtacccccgt gtagtccccg atatggcagc1200
aagatgggg1209
<210>24
<211>403
<212>PRT
<213>小家鼠(Mus musculus)
<400>24
Met Ala Arg Gly Trp Val Arg Pro Ser Arg Val Pro Leu Cys Ala Arg
1 5 1015
Ala Val Trp Thr Ala Ala Ala Leu Leu Leu Trp Thr Pro Trp Thr Ala
202530
Gly Glu Val Glu Asp Ser Glu Ala Ile Asp Thr Leu Gly Gln Pro Asp
354045
Gly Pro Asp Ser Pro Leu Pro Thr Leu Lys Gly Tyr Phe Leu Asn Phe
505560
Leu Glu Pro Val Asn Asn Ile Thr Ile Val Gln Gly Gln Thr Ala Ile
65707580
Leu His Cys Lys Val Ala Gly Asn Pro Pro Pro Asn Val Arg Trp Leu
859095
Lys Asn Asp Ala Pro Val Val Gln Glu Pro Arg Arg Val Val Ile Arg
100 105 110
Lys Thr Glu Tyr Gly Ser Arg Leu Arg Ile Gln Asp Leu Asp Thr Thr
115 120 125
Asp Thr Gly Tyr Tyr Gln Cys Val Ala Thr Asn Gly Leu Lys Thr Ile
130 135 140
Thr Ala Thr Gly Val Leu Tyr Val Arg Leu Gly Pro Thr His Ser Pro
145 150 155 160
Asn His Asn Phe Gln Asp Asp Asp Gln Glu Asp Gly Phe Cys Gln Pro
165 170 175
Tyr Arg Gly Ile Ala Cys Ala Arg Phe Ile Gly Asn Arg Thr Ile Tyr
180 185 190
Val Asp Ser Leu Gln Met Gln Gly Glu Ile Glu Asn Arg Ile Thr Ala
195 200 205
Ala Phe Thr Met Ile Gly Thr Ser Thr Gln Leu Ser Asp Gln Cys Ser
210 215 220
Gln Phe Ala Ile Pro Ser Phe Cys His Phe Val Phe Pro Leu Cys Asp
225 230 235 240
Ala Cys Ser Arg Ala Pro Lys Pro Arg Glu Leu Cys Arg Asp Glu Cys
245 250 255
Glu Val Leu Glu Asn Asp Leu Cys Arg Gln Glu Tyr Thr Ile Ala Arg
260 265 270
Ser Asn Pro Leu Ile Leu Met Arg Leu Gln Leu Pro Lys Cys Glu Ala
275 280 285
Leu Pro Met Pro Glu Ser Pro Asp Ala Ala Asn Cys Met Arg Ile Gly
290 295 300
Ile Pro Ala Glu Arg Leu Gly Arg Tyr His Gln Cys Tyr Asn Gly Ser
305 310 315 320
Gly Ala Asp Tyr Arg Gly Met Ala Ser Thr Thr Lys Ser Gly His Gln
325 330 335
Cys Gln Pro Trp Ala Leu Gln His Pro His Ser His Arg Leu Ser Ser
340 345 350
Thr Glu Phe Pro Glu Leu Gly Gly Gly His Ala Tyr Cys Arg Asn Pro
355 360 365
Gly Gly Gln Met Glu Gly Pro Trp Cys Phe Thr Gln Asn Lys Asn Val
370 375 380
Arg Val Glu Leu Cys Asp Val Pro Pro Cys Ser Pro Arg Tyr Gly Ser
385 390 395 400
Lys Met Gly
<210>25
<211>8
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>25
Gly Phe Thr Phe Ser Asn Tyr Gly
1 5
<210>26
<211>8
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>26
Ile Ser Ser Gly Gly Gly Tyr Thr
1 5
<210>27
<211>11
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>27
His Pro Arg Asp Phe Ser Tyr Ala Met Asp Tyr
1 5 10
<210>28
<211>6
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>28
Gln Asp Val Gly His Tyr
1 5
<210>29
<211>3
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>29
Trp Ala Ser
1
<210>30
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>30
Gln Gln Tyr Asn Ile Tyr Pro Trp Thr
1 5
<210>31
<211>8
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>31
Gly Tyr Thr Phe Thr Asp Tyr Glu
1 5
<210>32
<211>8
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>32
Ile His Pro Gly Ser Gly Gly Thr
1 5
<210>33
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>33
Arg Arg Pro Arg Phe Tyr Gly Met Asp Tyr
1 5 10
<210>34
<211>11
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>34
Lys Ser Leu Leu His Ser Asn Gly Asn Thr Tyr
1 5 10
<210>35
<211>3
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>35
Arg Met Ser
1
<210>36
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>36
Met Gln His Leu Glu Tyr Pro Leu Thr
1 5
<210>37
<211>8
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>37
Gly Phe Thr Phe Ser Asn Tyr Gly
1 5
<210>38
<211>8
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>38
Ile Ser Ser Gly Gly Gly Ser Thr
1 5
<210>39
<211>11
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>39
His Pro Tyr Asp Tyr Gly Tyr Tyr Phe Asp Tyr
1 5 10
<210>40
<211>6
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>40
Gln Ser Ile Gly Thr Ser
1 5
<210>41
<211>3
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>41
Tyr Ala Ser
1
<210>42
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>42
Gln Gln Ser Asp Ser Trp Pro Phe Pro
1 5
<210>43
<211>8
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>43
Gly Phe Thr Phe Asn Thr Tyr Ala
1 5
<210>44
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>44
Ile Arg Ser Lys Ser Asn Asn Tyr Ala Thr
1 5 10
<210>45
<211>11
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>45
His Gly Ser Ser Leu Tyr Tyr Ala Met Asp Tyr
1 5 10
<210>46
<211>6
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>46
Gln Glu Ile Ser Gly Tyr
1 5
<210>47
<211>3
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>47
Ala Ala Ser
1
<210>48
<211>9
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>48
Leu Gln Tyr Ala Ser Tyr Pro Tyr Thr
1 5
<210>49
<211>25
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>49
Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Lys Pro Gly Gly
1 5 1015
Ser Leu Lys Leu Ser Cys Ala Ala Ser
2025
<210>50
<211>17
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>50
Met Ser Trp Val Arg Gln Thr Pro Asp Lys Arg Leu Glu Trp Val Ala
1 5 1015
Thr
<210>51
<211>40
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>51
His Tyr Val Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn
1 5 1015
Ala Asn His Ile Leu Tyr Leu Gln Met Ser Ser Leu Asn Ser Glu Asp
202530
Thr Ala Met Tyr Tyr Cys Ala Arg
3540
<210>52
<211>11
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>52
Trp Gly Gln Gly Thr Ser Val Thr Val Ser Ser
1 5 10
<210>53
<211>26
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>53
Asp Ile Val Met Thr Gln Ser His Lys Phe Met Ser Thr Ser Ile Gly
1 5 1015
Asp Arg Val Ser Ile Thr Cys Lys Ala Ser
2025
<210>54
<211>17
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>54
Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile
1 5 1015
Tyr
<210>55
<211>36
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>55
Thr Arg His Thr Gly Val Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly
1 5 1015
Thr Asp Phe Thr Leu Thr Ile Ser Asn Val Gln Ser Glu Asp Leu Ala
202530
Asp Tyr Phe Cys
35
<210>56
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>56
Phe Gly Gly Gly Ser Lys Leu Ala Ile Lys
1 5 10
<210>57
<211>25
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>57
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 1015
Ser Val Lys Leu Ser Cys Lys Ala Leu
2025
<210>58
<211>17
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>58
Met His Trp Val Lys Gln Thr Pro Val His Gly Leu Glu Trp Ile Gly
1 5 1015
Ala
<210>59
<211>40
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>59
Ala Tyr Asn Gln Lys Phe Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys
1 5 1015
Ser Ser Ser Thr Ala Tyr Met Glu Leu Ser Arg Leu Thr Ser Glu Asp
202530
Ser Ala Val Tyr Tyr Cys Thr Arg
3540
<210>60
<211>11
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>60
Trp Gly Gln Gly Thr Ser Val Thr Val Ser Ser
1 5 10
<210>61
<211>26
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>61
Asp Ile Val Met Thr Gln Ala Ala Pro Ser Val Pro Val Thr Pro Gly
1 5 1015
Glu Ser Val Ser Ile Ser Cys Arg Ser Ser
2025
<210>62
<211>17
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>62
Leu Tyr Trp Phe Leu Gln Arg Pro Gly Gln Ser Pro Gln Leu Leu Ile
1 5 1015
Tyr
<210>63
<211>36
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>63
Asn Leu Ala Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly
1 5 1015
Thr Ala Phe Thr Leu Arg Ile Ser Arg Val Glu Ala Glu Asp Val Gly
202530
Val Tyr Tyr Cys
35
<210>64
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>64
Val Gly Ala Gly Thr Lys Leu Glu Leu Lys
1 5 10
<210>65
<211>25
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>65
Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Lys Pro Gly Gly
1 5 1015
Ser Leu Lys Leu Ser Cys Ala Ala Ser
2025
<210>66
<211>17
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>66
Met Ser Trp Val Arg Gln Thr Pro Asp Lys Arg Leu Glu Trp Val Ala
1 5 1015
Thr
<210>67
<211>40
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>67
Tyr Tyr Pro Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn
1 5 1015
Ala Lys Asn Ser Leu Tyr Leu Gln Met Ser Ser Leu Lys Ser Glu Asp
202530
Thr Ala Met Tyr Tyr Cys Ala Arg
3540
<210>68
<211>11
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>68
Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
1 5 10
<210>69
<211>26
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>69
Asp Ile Leu Leu Thr Gln Ser Pro Asp Ile Leu Ser Val Ser Pro Gly
1 5 1015
Glu Arg Val Ser Phe Ser Cys Arg Ala Ser
2025
<210>70
<211>17
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>70
Ile His Trp Tyr Gln Gln Arg Thr Asn Gly Ser Pro Arg Leu Leu Ile
1 5 1015
Lys
<210>71
<211>36
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>71
Glu Ser Ile Ser Gly Ile Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly
1 5 1015
Thr Asp Phe Thr Leu Ser Ile Asn Ser Val Glu Ser Glu Asp Ile Ala
202530
Asp Tyr Tyr Cys
35
<210>72
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>72
Phe Gly Ser Gly Thr Lys Leu Glu Lys Lys
1 5 10
<210>73
<211>25
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>73
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Lys Gly
1 5 1015
Ser Leu Lys Leu Ser Cys Ala Ala Ser
2025
<210>74
<211>17
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>74
Met Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ala
1 5 1015
Arg
<210>75
<211>40
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>75
Tyr Tyr Ala Asp Ser Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Asp
1 5 1015
Ser Gln Ser Met Leu His Leu Gln Met Asn Asn Leu Lys Thr Glu Asp
202530
Thr Ala Met Tyr Tyr Cys Val Arg
3540
<210>76
<211>11
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>SEQ ID NO:77
<400>76
Trp Gly Gln Gly Thr Ser Val Thr Val Ser Ser
1 5 10
<210>77
<211>26
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>77
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Leu Gly
1 5 1015
Glu Arg Val Ser Leu Thr Cys Arg Ala Ser
2025
<210>78
<211>17
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>78
Leu Gly Trp Leu Gln Gln Lys Pro Asp Gly Thr Ile Lys Arg Leu Ile
1 5 1015
Tyr
<210>79
<211>36
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>79
Thr Leu Asp Ser Gly Val Pro Lys Arg Phe Ser Gly Ser Arg Ser Gly
1 5 1015
Ser Ala Tyr Ser Leu Thr Ile Ser Ser Leu Glu Ser Glu Asp Phe Ala
202530
Asp Tyr Tyr Cys
35
<210>80
<211>10
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>80
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
1 5 10
<210>81
<211>21
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>81
Ala Thr Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala
1 5 1015
Thr Gly Val His Ser
20
<210>82
<211>18
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>82
Gly Ser Thr Ser Gly Ser Gly Lys Pro Gly Ser Gly Glu Gly Ser Thr
1 5 1015
Lys Gly
<210>83
<211>2
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>83
Glu Phe
1
<210>84
<211>206
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>84
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
1 5 1015
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
202530
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
354045
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
505560
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
65707580
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
859095
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
100 105 110
Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
115 120 125
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
130 135 140
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
145 150 155 160
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Glu Ser Arg Trp
165 170 175
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
180 185 190
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
195 200 205
<210>85
<211>474
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>85
Ala Thr Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala
1 5 1015
Thr Gly Val His Ser Asp Ile Val Met Thr Gln Ser His Lys Phe Met
202530
Ser Thr Ser Ile Gly Asp Arg Val Ser Ile Thr Cys Lys Ala Ser Gln
354045
Asp Val Gly His Tyr Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ser
505560
Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg His Thr Gly Val Pro
65707580
Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
859095
Ser Asn Val Gln Ser Glu Asp Leu Ala Asp Tyr Phe Cys Gln Gln Tyr
100 105 110
Asn Ile Tyr Pro Trp Thr Phe Gly Gly Gly Ser Lys Leu Ala Ile Lys
115 120 125
Gly Ser Thr Ser Gly Ser Gly Lys Pro Gly Ser Gly Glu Gly Ser Thr
130 135 140
Lys Gly Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Lys Pro
145 150 155 160
Gly Gly Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser
165 170 175
Asn Tyr Gly Met Ser Trp Val Arg Gln Thr Pro Asp Lys Arg Leu Glu
180 185 190
Trp Val Ala Thr Ile Ser Ser Gly Gly Gly Tyr Thr His Tyr Val Asp
195 200 205
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Asn His Ile
210 215 220
Leu Tyr Leu Gln Met Ser Ser Leu Asn Ser Glu Asp Thr Ala Met Tyr
225 230 235 240
Tyr Cys Ala Arg His Pro Arg Asp Phe Ser Tyr Ala Met Asp Tyr Trp
245 250 255
Gly Gln Gly Thr Ser Val Thr Val Ser Ser Glu Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
370 375 380
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Lys Leu Thr Val Asp Glu Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
465 470
<210>86
<211>478
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>86
Ala Thr Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala
1 5 1015
Thr Gly Val His Ser Asp Ile Val Met Thr Gln Ala Ala Pro Ser Val
202530
Pro Val Thr Pro Gly Glu Ser Val Ser Ile Ser Cys Arg Ser Ser Lys
354045
Ser Leu Leu His Ser Asn Gly Asn Thr Tyr Leu Tyr Trp Phe Leu Gln
505560
Arg Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr Arg Met Ser Asn Leu
65707580
Ala Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Ala
859095
Phe Thr Leu Arg Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr
100 105 110
Tyr Cys Met Gln His Leu Glu Tyr Pro Leu Thr Val Gly Ala Gly Thr
115 120 125
Lys Leu Glu Leu Lys Gly Ser Thr Ser Gly Ser Gly Lys Pro Gly Ser
130 135 140
Gly Glu Gly Ser Thr Lys Gly Gln Val Gln Leu Gln Gln Ser Gly Ala
145 150 155 160
Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Leu
165 170 175
Gly Tyr Thr Phe Thr Asp Tyr Glu Met His Trp Val Lys Gln Thr Pro
180 185 190
Val His Gly Leu Glu Trp Ile Gly Ala Ile His Pro Gly Ser Gly Gly
195 200 205
Thr Ala Tyr Asn Gln Lys Phe Lys Gly Lys Ala Thr Leu Thr Ala Asp
210 215 220
Lys Ser Ser Ser Thr Ala Tyr Met Glu Leu Ser Arg Leu Thr Ser Glu
225 230 235 240
Asp Ser Ala Val Tyr Tyr Cys Thr Arg Arg Arg Pro Arg Phe Tyr Gly
245 250 255
Met Asp Tyr Trp Gly Gln Gly Thr Ser Val Thr Val Ser Ser Glu Phe
260 265 270
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
275 280 285
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
290 295 300
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
305 310 315 320
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
325 330 335
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
340 345 350
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
355 360 365
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
370 375 380
Ser Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
385 390 395 400
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
405 410 415
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
420 425 430
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Glu Ser Arg Trp
435 440 445
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
450 455 460
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
465 470 475
<210>87
<211>63
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>87
gccaccatgg gatggtcatg tatcatcctt tttctagtag caactgcaac cggtgtacat60
tcc63
<210>88
<211>54
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>88
ggctccacct ctggatccgg caagcccgga tctggcgagg gatccaccaa gggc54
<210>89
<211>6
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>89
gaattc6
<210>90
<211>621
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>90
ctcttccccc caaaacccaa ggacaccctc atgatctccc ggacccctga ggtcacatgc60
gtggtggtgg acgtgagcca cgaagaccct gaggtcaagt tcaactggta cgtggacggc 120
gtggaggtgc ataatgccaa gacaaagccg cgggaggagc agtacaacag cacgtaccgt 180
gtggtcagcg tcctcaccgt cctgcaccag gactggctga atggcaagga gtacaagtgc 240
aaggtctcca acaaagccct cccagccccc atcgagaaaa ccatctccaa agccaaaggg 300
cagccccgag aaccacaggt gtacaccctg cccccatccc gggaggagat gaccaagaac 360
caggtcagcc tgacctgcct ggtcaaaggc ttctatccca gcgacatcgc cgtggagtgg 420
gagagcaatg ggcagccgga gaacaactac aagaccacgc ctcccgtgct ggactccgac 480
ggctccttct tcctctatag caagctcacc gtggacgaga gcaggtggca gcaggggaac 540
gtcttctcat gctccgtgat gcatgaggct ctgcacaacc actacacgca gaagagcctc 600
tccctgtctc cgggtaaatg a 621
<210>91
<211>1425
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>91
gccaccatgg gatggtcatg tatcatcctt tttctagtag caactgcaac cggtgtacat60
tccgacattg tgatgaccca gtctcacaaa ttcatgtcca catcaatagg agacagggtc 120
agcatcacct gcaaggccag tcaggatgtg ggtcattatg tggcctggta tcaacagaaa 180
ccaggtcaat ctcctaaact actgatttac tgggcatcca cccggcacac tggagtccct 240
gatcgcttca caggtagtgg atctgggaca gatttcactc tcaccattag caatgtgcag 300
tctgaagact tggcagatta tttctgtcag caatataaca tctatccgtg gacgttcggt 360
ggaggctcca agctggcaat caaaggctcc acctctggat ccggcaagcc cggatctggc 420
gagggatcta ccaagggcga ggtgcagctg gtggagtctg ggggagactt agtgaagcct 480
ggagggtccc tgaaactctc ctgtgcagcc tctggattca ctttcagtaa ttatggcatg 540
tcttgggttc gccagactcc agacaagagg ctggagtggg tcgcaaccat tagtagtggt 600
ggtggttaca ctcactatgt agacagtgtg aaggggcgat tcaccatttc cagagacaat 660
gccaaccata tcctgtacct gcaaatgagc agtctgaact ctgaggacac agccatgtat 720
tattgtgcaa gacacccgag ggatttttcc tatgctatgg actactgggg tcagggaacc 780
tcagtcaccg tctcctcaga attcctcttc cccccaaaac ccaaggacac cctcatgatc 840
tcccggaccc ctgaggtcac atgcgtggtg gtggacgtga gccacgaaga ccctgaggtc 900
aagttcaact ggtacgtgga cggcgtggag gtgcataatg ccaagacaaa gccgcgggag 960
gagcagtaca acagcacgta ccgtgtggtc agcgtcctca ccgtcctgca ccaggactgg1020
ctgaatggca aggagtacaa gtgcaaggtc tccaacaaag ccctcccagc ccccatcgag1080
aaaaccatct ccaaagccaa agggcagccc cgagaaccac aggtgtacac cctgccccca1140
tcccgggagg agatgaccaa gaaccaggtc agcctgacct gcctggtcaa aggcttctat1200
cccagcgaca tcgccgtgga gtgggagagc aatgggcagc cggagaacaa ctacaagacc1260
acgcctcccg tgctggactc cgacggctcc ttcttcctct atagcaagct caccgtggac1320
gagagcaggt ggcagcaggg gaacgtcttc tcatgctccg tgatgcatga ggctctgcac1380
aaccactaca cgcagaagag cctctccctg tctccgggta aatga1425
<210>92
<211>1437
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>92
gccaccatgg gatggtcatg tatcatcctt tttctagtag caactgcaac cggtgtacat60
tccgatattg tgatgactca ggctgcaccc tctgtacctg tcactcctgg agagtcagta 120
tccatctcct gcaggtctag taagagtctc ctgcatagta atggcaacac ttacttgtat 180
tggttcctgc agaggccagg ccagtctcct cagctcctga tatatcggat gtccaacctt 240
gcctcaggag tcccagacag gttcagtggc agtgggtcag gaactgcttt cacactgaga 300
atcagtagag tggaggctga ggatgtgggt gtttattact gtatgcaaca tctagaatat 360
cctctcacgg tcggtgctgg gaccaagctg gagctgaaag gctccacctc tggatccggc 420
aagcccggat ctggcgaggg atctaccaag ggccaggttc aactgcaaca gtctggggct 480
gagctggtga ggcctggggc ttcagtgaag ctgtcctgca aggctttggg ctacacattt 540
actgactatg aaatgcactg ggtgaagcag acacctgtgc atggcctgga atggattgga 600
gctattcatc caggaagtgg tggtactgcc tataatcaga agttcaaggg caaggccaca 660
ctgactgcag acaaatcctc cagcacagcc tacatggagc tcagcaggct gacatctgag 720
gactctgctg tctattactg tacaagaagg aggcctaggt tctatggtat ggactactgg 780
ggtcaaggaa cctcagtcac cgtctcctca gaattcctct tccccccaaa acccaaggac 840
accctcatga tctcccggac ccctgaggtc acatgcgtgg tggtggacgt gagccacgaa 900
gaccctgagg tcaagttcaa ctggtacgtg gacggcgtgg aggtgcataa tgccaagaca 960
aagccgcggg aggagcagta caacagcacg taccgtgtgg tcagcgtcct caccgtcctg1020
caccaggact ggctgaatgg caaggagtac aagtgcaagg tctccaacaa agccctccca1080
gcccccatcg agaaaaccat ctccaaagcc aaagggcagc cccgagaacc acaggtgtac1140
accctgcccc catcccggga ggagatgacc aagaaccagg tcagcctgac ctgcctggtc1200
aaaggcttct atcccagcga catcgccgtg gagtgggaga gcaatgggca gccggagaac1260
aactacaaga ccacgcctcc cgtgctggac tccgacggct ccttcttcct ctatagcaag1320
ctcaccgtgg acgagagcag gtggcagcag gggaacgtct tctcatgctc cgtgatgcat1380
gaggctctgc acaaccacta cacgcagaag agcctctccc tgtctccggg taaatga 1437
<210>93
<211>19
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>93
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 1015
Val His Ser
<210>94
<211>14
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>94
Val Asp Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro
1 5 10
<210>95
<211>147
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>SEQ ID NO:96
<400>95
Val Asp Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Gly Lys
1 5 1015
Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu
202530
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
354045
Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu
505560
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
65707580
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
859095
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp
100 105 110
Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His
115 120 125
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu
130 135 140
Gly Lys Met
145
<210>96
<211>232
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>96
Val Asp Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
1 5 1015
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
202530
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
354045
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
505560
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
65707580
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
859095
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
100 105 110
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
115 120 125
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
130 135 140
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
145 150 155 160
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
165 170 175
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
180 185 190
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
195 200 205
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
210 215 220
Leu Ser Leu Ser Leu Gly Lys Met
225 230
<210>97
<211>68
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>97
Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu
1 5 1015
Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser
202530
Arg Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly
354045
Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala
505560
Ala Tyr Arg Ser
65
<210>98
<211>42
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>98
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
1 5 1015
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
202530
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu
3540
<210>99
<211>112
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>99
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly
1 5 1015
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
202530
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
354045
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys
505560
Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
65707580
Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala
859095
Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
100 105 110
<210>100
<211>718
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>100
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 1015
Val His Ser Asp Ile Val Met Thr Gln Ser His Lys Phe Met Ser Thr
202530
Ser Ile Gly Asp Arg Val Ser Ile Thr Cys Lys Ala Ser Gln Asp Val
354045
Gly His Tyr Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ser Pro Lys
505560
Leu Leu Ile Tyr Trp Ala Ser Thr Arg His Thr Gly Val Pro Asp Arg
65707580
Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Asn
859095
Val Gln Ser Glu Asp Leu Ala Asp Tyr Phe Cys Gln Gln Tyr Asn Ile
100 105 110
Tyr Pro Trp Thr Phe Gly Gly Gly Ser Lys Leu Ala Ile Lys Gly Ser
115 120 125
Thr Ser Gly Ser Gly Lys Pro Gly Ser Gly Glu Gly Ser Thr Lys Gly
130 135 140
Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Lys Pro Gly Gly
145 150 155 160
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
165 170 175
Gly Met Ser Trp Val Arg Gln Thr Pro Asp Lys Arg Leu Glu Trp Val
180 185 190
Ala Thr Ile Ser Ser Gly Gly Gly Tyr Thr His Tyr Val Asp Ser Val
195 200 205
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Asn His Ile Leu Tyr
210 215 220
Leu Gln Met Ser Ser Leu Asn Ser Glu Asp Thr Ala Met Tyr Tyr Cys
225 230 235 240
Ala Arg His Pro Arg Asp Phe Ser Tyr Ala Met Asp Tyr Trp Gly Gln
245 250 255
Gly Thr Ser Val Thr Val Ser Ser Val Asp Glu Ser Lys Tyr Gly Pro
260 265 270
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
275 280 285
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
290 295 300
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
305 310 315 320
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
325 330 335
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
340 345 350
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
355 360 365
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
370 375 380
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
385 390 395 400
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
405 410 415
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
420 425 430
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
435 440 445
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
450 455 460
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
465 470 475 480
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys Met
485 490 495
Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr Ser Leu
500 505 510
Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys Arg Ser
515 520 525
Arg Gly Gly His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly
530 535 540
Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala
545 550 555 560
Ala Tyr Arg Ser Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys
565 570 575
Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys
580 585 590
Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val
595 600 605
Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn
610 615 620
Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val
625 630 635 640
Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg
645 650 655
Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys
660 665 670
Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg
675 680 685
Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys
690 695 700
Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
705 710 715
<210>101
<211>722
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>101
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 1015
Val His Ser Asp Ile Val Met Thr Gln Ala Ala Pro Ser Val Pro Val
202530
Thr Pro Gly Glu Ser Val Ser Ile Ser Cys Arg Ser Ser Lys Ser Leu
354045
Leu His Ser Asn Gly Asn Thr Tyr Leu Tyr Trp Phe Leu Gln Arg Pro
505560
Gly Gln Ser Pro Gln Leu Leu Ile Tyr Arg Met Ser Asn Leu Ala Ser
65707580
Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Ala Phe Thr
859095
Leu Arg Ile Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys
100 105 110
Met Gln His Leu Glu Tyr Pro Leu Thr Val Gly Ala Gly Thr Lys Leu
115 120 125
Glu Leu Lys Gly Ser Thr Ser Gly Ser Gly Lys Pro Gly Ser Gly Glu
130 135 140
Gly Ser Thr Lys Gly Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu
145 150 155 160
Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Leu Gly Tyr
165 170 175
Thr Phe Thr Asp Tyr Glu Met His Trp Val Lys Gln Thr Pro Val His
180 185 190
Gly Leu Glu Trp Ile Gly Ala Ile His Pro Gly Ser Gly Gly Thr Ala
195 200 205
Tyr Asn Gln Lys Phe Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser
210 215 220
Ser Ser Thr Ala Tyr Met Glu Leu Ser Arg Leu Thr Ser Glu Asp Ser
225 230 235 240
Ala Val Tyr Tyr Cys Thr Arg Arg Arg Pro Arg Phe Tyr Gly Met Asp
245 250 255
Tyr Trp Gly Gln Gly Thr Ser Val Thr Val Ser Ser Val Asp Glu Ser
260 265 270
Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly
275 280 285
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
290 295 300
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln
305 310 315 320
Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val
325 330 335
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr
340 345 350
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
355 360 365
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile
370 375 380
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
385 390 395 400
Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser
405 410 415
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
420 425 430
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
435 440 445
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val
450 455 460
Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met
465 470 475 480
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
485 490 495
Leu Gly Lys Met Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala
500 505 510
Cys Tyr Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg
515 520 525
Ser Lys Arg Ser Arg Gly Gly His Ser Asp Tyr Met Asn Met Thr Pro
530 535 540
Arg Arg Pro Gly Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro
545 550 555 560
Arg Asp Phe Ala Ala Tyr Arg Ser Lys Arg Gly Arg Lys Lys Leu Leu
565 570 575
Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu
580 585 590
Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys
595 600 605
Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln
610 615 620
Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu
625 630 635 640
Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly
645 650 655
Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu
660 665 670
Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly
675 680 685
Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser
690 695 700
Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro
705 710 715 720
Pro Arg
<210>102
<211>634
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>102
Met Ala Arg Gly Ser Ala Leu Pro Arg Arg Pro Leu Leu Cys Ile Pro
1 5 1015
Ala Val Trp Ala Ala Ala Ala Leu Leu Leu Ser Val Ser Arg Thr Ser
202530
Gly Glu Val Glu Val Leu Asp Pro Asn Asp Pro Leu Gly Pro Leu Asp
354045
Gly Gln Asp Gly Pro Ile Pro Thr Leu Lys Gly Tyr Phe Leu Asn Phe
505560
Leu Glu Pro Val Asn Asn Ile Thr Ile Val Gln Gly Gln Thr Ala Ile
65707580
Leu His Cys Lys Val Ala Gly Asn Pro Pro Pro Asn Val Arg Trp Leu
859095
Lys Asn Asp Ala Pro Val Val Gln Glu Pro Arg Arg Ile Ile Ile Arg
100 105 110
Lys Thr Glu Tyr Gly Ser Arg Leu Arg Ile Gln Asp Leu Asp Thr Thr
115 120 125
Asp Thr Gly Tyr Tyr Gln Cys Val Ala Thr Asn Gly Met Lys Thr Ile
130 135 140
Thr Ala Thr Gly Val Leu Phe Val Arg Leu Gly Pro Thr His Ser Pro
145 150 155 160
Asn His Asn Phe Gln Asp Asp Tyr His Glu Asp Gly Phe Cys Gln Pro
165 170 175
Tyr Arg Gly Ile Ala Cys Ala Arg Phe Ile Gly Asn Arg Thr Ile Tyr
180 185 190
Val Asp Ser Leu Gln Met Gln Gly Glu Ile Glu Asn Arg Ile Thr Ala
195 200 205
Ala Phe Thr Met Ile Gly Thr Ser Thr His Leu Ser Asp Gln Cys Ser
210 215 220
Gln Phe Ala Ile Pro Ser Phe Cys His Phe Val Phe Pro Leu Cys Asp
225 230 235 240
Ala Arg Ser Arg Thr Pro Lys Pro Arg Glu Leu Cys Arg Asp Glu Cys
245 250 255
Glu Val Leu Glu Ser Asp Leu Cys Arg Gln Glu Tyr Thr Ile Ala Arg
260 265 270
Ser Asn Pro Leu Ile Leu Met Arg Leu Gln Leu Pro Lys Cys Glu Ala
275 280 285
Leu Pro Met Pro Glu Ser Pro Asp Ala Ala Asn Cys Met Arg Ile Gly
290 295 300
Ile Pro Ala Glu Arg Leu Gly Arg Tyr His Gln Cys Tyr Asn Gly Ser
305 310 315 320
Gly Met Asp Tyr Arg Gly Thr Ala Ser Thr Thr Lys Ser Gly His Gln
325 330 335
Cys Gln Pro Trp Ala Leu Gln His Pro His Ser His His Leu Ser Ser
340 345 350
Thr Asp Phe Pro Glu Leu Gly Gly Gly His Ala Tyr Cys Arg Asn Pro
355 360 365
Gly Gly Gln Met Glu Gly Pro Trp Cys Phe Thr Gln Asn Lys Asn Val
370 375 380
Arg Met Glu Leu Cys Asp Val Pro Ser Cys Ser Pro Arg Asp Ser Ser
385 390 395 400
Lys Met Gly Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
405 410 415
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
420 425 430
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
435 440 445
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
450 455 460
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
465 470 475 480
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
485 490 495
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
500 505 510
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
515 520 525
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
530 535 540
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
545 550 555 560
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
565 570 575
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
580 585 590
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
595 600 605
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
610 615 620
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
625 630
<210>103
<211>634
<212>PRT
<213>人工序列(Artificial Sequence)
<220>
<223>合成多肽
<400>103
Met His Arg Pro Arg Arg Arg Gly Thr Arg Pro Pro Leu Leu Ala Leu
1 5 1015
Leu Ala Ala Leu Leu Leu Ala Ala Arg Gly Ala Ala Ala Gln Glu Thr
202530
Glu Leu Ser Val Ser Ala Glu Leu Val Pro Thr Ser Ser Trp Asn Ile
354045
Ser Ser Glu Leu Asn Lys Asp Ser Tyr Leu Thr Leu Asp Glu Pro Met
505560
Asn Asn Ile Thr Thr Ser Leu Gly Gln Thr Ala Glu Leu His Cys Lys
65707580
Val Ser Gly Asn Pro Pro Pro Thr Ile Arg Trp Phe Lys Asn Asp Ala
859095
Pro Val Val Gln Glu Pro Arg Arg Leu Ser Phe Arg Ser Thr Ile Tyr
100 105 110
Gly Ser Arg Leu Arg Ile Arg Asn Leu Asp Thr Thr Asp Thr Gly Tyr
115 120 125
Phe Gln Cys Val Ala Thr Asn Gly Lys Glu Val Val Ser Ser Thr Gly
130 135 140
Val Leu Phe Val Lys Phe Gly Pro Pro Pro Thr Ala Ser Pro Gly Tyr
145 150 155 160
Ser Asp Glu Tyr Glu Glu Asp Gly Phe Cys Gln Pro Tyr Arg Gly Ile
165 170 175
Ala Cys Ala Arg Phe Ile Gly Asn Arg Thr Val Tyr Met Glu Ser Leu
180 185 190
His Met Gln Gly Glu Ile Glu Asn Gln Ile Thr Ala Ala Phe Thr Met
195 200 205
Ile Gly Thr Ser Ser His Leu Ser Asp Lys Cys Ser Gln Phe Ala Ile
210 215 220
Pro Ser Leu Cys His Tyr Ala Phe Pro Tyr Cys Asp Glu Thr Ser Ser
225 230 235 240
Val Pro Lys Pro Arg Asp Leu Cys Arg Asp Glu Cys Glu Ile Leu Glu
245 250 255
Asn Val Leu Cys Gln Thr Glu Tyr Ile Phe Ala Arg Ser Asn Pro Met
260 265 270
Ile Leu Met Arg Leu Lys Leu Pro Asn Cys Glu Asp Leu Pro Gln Pro
275 280 285
Glu Ser Pro Glu Ala Ala Asn Cys Ile Arg Ile Gly Ile Pro Met Ala
290 295 300
Asp Pro Ile Asn Lys Asn His Lys Cys Tyr Asn Ser Thr Gly Val Asp
305 310 315 320
Tyr Arg Gly Thr Val Ser Val Thr Lys Ser Gly Arg Gln Cys Gln Pro
325 330 335
Trp Asn Ser Gln Tyr Pro His Thr His Thr Phe Thr Ala Leu Arg Phe
340 345 350
Pro Glu Leu Asn Gly Gly His Ser Tyr Cys Arg Asn Pro Gly Asn Gln
355 360 365
Lys Glu Ala Pro Trp Cys Phe Thr Leu Asp Glu Asn Phe Lys Ser Asp
370 375 380
Leu Cys Asp Ile Pro Ala Cys Asp Ser Lys Asp Ser Lys Glu Lys Asn
385 390 395 400
Lys Met Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
405 410 415
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
420 425 430
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
435 440 445
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
450 455 460
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
465 470 475 480
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
485 490 495
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
500 505 510
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
515 520 525
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
530 535 540
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
545 550 555 560
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
565 570 575
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
580 585 590
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
595 600 605
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
610 615 620
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
625 630
<210>104
<211>57
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>104
atgggatggt catgtatcat cctttttcta gtagcaactg caaccggtgt acattcc 57
<210>105
<211>42
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>105
gtcgacgagt ccaaatatgg tcccccatgc ccaccatgcc ca 42
<210>106
<211>441
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>106
gtcgacgagt ccaaatatgg tcccccatgc ccaccatgcc caggcaagga gtacaagtgc60
aaggtctcca acaaaggcct cccgtcctcc atcgagaaaa ccatctccaa agccaaaggg 120
cagccccgag agccacaggt gtacaccctg cccccatccc aggaggagat gaccaagaac 180
caggtcagcc tgacctgcct ggtcaaaggc ttctacccca gcgacatcgc cgtggagtgg 240
gagagcaatg ggcagccgga gaacaactac aagaccacgc ctcccgtgct ggactccgac 300
ggctccttct tcctctacag caggctaacc gtggacaaga gcaggtggca ggaggggaat 360
gtcttctcat gctccgtgat gcatgaggct ctgcacaacc actacacaca gaagagcctc 420
tccctgtccc taggtaaaat g 441
<210>107
<211>696
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>107
gtcgacgagt ccaaatatgg tcccccatgc ccaccatgcc cagcacctga gttcctgggg60
ggaccatcag tcttcctgtt ccccccaaaa cccaaggaca ctctcatgat ctcccggacc 120
cctgaggtca cgtgcgtggt ggtggacgtg agccaggaag accccgaggt ccagttcaac 180
tggtacgtgg atggcgtgga ggtgcataat gccaagacaa agccgcggga ggagcagttc 240
aacagcacgt accgtgtggt cagcgtcctc accgtcctgc accaggactg gctgaacggc 300
aaggagtaca agtgcaaggt ctccaacaaa ggcctcccgt cctccatcga gaaaaccatc 360
tccaaagcca aagggcagcc ccgagagcca caggtgtaca ccctgccccc atcccaggag 420
gagatgacca agaaccaggt cagcctgacc tgcctggtca aaggcttcta ccccagcgac 480
atcgccgtgg agtgggagag caatgggcag ccggagaaca actacaagac cacgcctccc 540
gtgctggact ccgacggctc cttcttcctc tacagcaggc taaccgtgga caagagcagg 600
tggcaggagg ggaatgtctt ctcatgctcc gtgatgcatg aggctctgca caaccactac 660
acacagaaga gcctctccct gtccctaggt aaaatg 696
<210>108
<211>204
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>108
ttttgggtgc tggtggtggt tggtggagtc ctggcttgct atagcttgct agtaacagtg60
gcctttatta ttttctgggt gaggagtaag aggagcaggc tcctgcacag tgactacatg 120
aacatgactc cccgccgccc cgggcccacc cgcaagcatt accagcccta tgccccacca 180
cgcgacttcg cagcctatcg ctcc204
<210>109
<211>126
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>109
aaacggggca gaaagaaact cctgtatata ttcaaacaac catttatgag accagtacaa60
actactcaag aggaagatgg ctgtagctgc cgatttccag aagaagaaga aggaggatgt 120
gaactg126
<210>110
<211>339
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>110
agagtgaagt tcagcaggag cgcagacgcc cccgcgtacc agcagggcca gaaccagctc60
tataacgagc tcaatctagg acgaagagag gagtacgatg ttttggacaa gagacgtggc 120
cgggaccctg agatgggggg aaagccgaga aggaagaacc ctcaggaagg cctgtacaat 180
gaactgcaga aagataagat ggcggaggcc tacagtgaga ttgggatgaa aggcgagcgc 240
cggaggggca aggggcacga tggcctttac cagggtctca gtacagccac caaggacacc 300
tacgacgccc ttcacatgca ggccctgccc cctcgctga339
<210>111
<211>2157
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>111
atgggatggt catgtatcat cctttttcta gtagcaactg caaccggtgt acattccgac60
attgtgatga cccagtctca caaattcatg tccacatcaa taggagacag ggtcagcatc 120
acctgcaagg ccagtcagga tgtgggtcat tatgtggcct ggtatcaaca gaaaccaggt 180
caatctccta aactactgat ttactgggca tccacccggc acactggagt ccctgatcgc 240
ttcacaggta gtggatctgg gacagatttc actctcacca ttagcaatgt gcagtctgaa 300
gacttggcag attatttctg tcagcaatat aacatctatc cgtggacgtt cggtggaggc 360
tccaagctgg caatcaaagg ctccacctct ggatccggca agcccggatc tggcgaggga 420
tccaccaagg gcgaggtgca gctggtggag tctgggggag acttagtgaa gcctggaggg 480
tccctgaaac tctcctgtgc agcctctgga ttcactttca gtaattatgg catgtcttgg 540
gttcgccaga ctccagacaa gaggctggag tgggtcgcaa ccattagtag tggtggtggt 600
tacactcact atgtagacag tgtgaagggg cgattcacca tttccagaga caatgccaac 660
catatcctgt acctgcaaat gagcagtctg aactctgagg acacagccat gtattattgt 720
gcaagacacc cgagggattt ttcctatgct atggactact ggggtcaggg aacctcagtc 780
accgtctcct cagtcgacga gtccaaatat ggtcccccat gcccaccatg cccagcacct 840
gagttcctgg ggggaccatc agtcttcctg ttccccccaa aacccaagga cactctcatg 900
atctcccgga cccctgaggt cacgtgcgtg gtggtggacg tgagccagga agaccccgag 960
gtccagttca actggtacgt ggatggcgtg gaggtgcata atgccaagac aaagccgcgg1020
gaggagcagt tcaacagcac gtaccgtgtg gtcagcgtcc tcaccgtcct gcaccaggac1080
tggctgaacg gcaaggagta caagtgcaag gtctccaaca aaggcctccc gtcctccatc1140
gagaaaacca tctccaaagc caaagggcag ccccgagagc cacaggtgta caccctgccc1200
ccatcccagg aggagatgac caagaaccag gtcagcctga cctgcctggt caaaggcttc1260
taccccagcg acatcgccgt ggagtgggag agcaatgggc agccggagaa caactacaag1320
accacgcctc ccgtgctgga ctccgacggc tccttcttcc tctacagcag gctaaccgtg1380
gacaagagca ggtggcagga ggggaatgtc ttctcatgct ccgtgatgca tgaggctctg1440
cacaaccact acacacagaa gagcctctcc ctgtccctag gtaaaatgtt ttgggtgctg1500
gtggtggttg gtggagtcct ggcttgctat agcttgctag taacagtggc ctttattatt1560
ttctgggtga ggagtaagag gagcaggggc ggacacagtg actacatgaa catgactccc1620
cgccgccctg ggcccacccg caagcattac cagccctatg ccccaccacg cgacttcgca1680
gcctatcgct ccaaacgggg cagaaagaaa ctcctgtata tattcaaaca accatttatg1740
agaccagtac aaactactca agaggaagat ggctgtagct gccgatttcc agaagaagaa1800
gaaggaggat gtgaactgag agtgaagttc agcaggagcg cagacgcccc cgcgtaccag1860
cagggccaga accagctcta taacgagctc aatctaggac gaagagagga gtacgatgtt1920
ttggacaaga gacgtggccg ggaccctgag atggggggaa agccgagaag gaagaaccct1980
caggaaggcc tgtacaatga actgcagaaa gataagatgg cggaggccta cagtgagatt2040
gggatgaaag gcgagcgccg gaggggcaag gggcacgatg gcctttacca gggtctcagt2100
acagccacca aggacaccta cgacgccctt cacatgcagg ccctgccccc tcgctga 2157
<210>112
<211>2169
<212>DNA
<213>人工序列(Artificial Sequence)
<220>
<223>合成多核苷酸
<400>112
atgggatggt catgtatcat cctttttcta gtagcaactg caaccggtgt acattccgat60
attgtgatga ctcaggctgc accctctgta cctgtcactc ctggagagtc agtatccatc 120
tcctgcaggt ctagtaagag tctcctgcat agtaatggca acacttactt gtattggttc 180
ctgcagaggc caggccagtc tcctcagctc ctgatatatc ggatgtccaa ccttgcctca 240
ggagtcccag acaggttcag tggcagtggg tcaggaactg ctttcacact gagaatcagt 300
agagtggagg ctgaggatgt gggtgtttat tactgtatgc aacatctaga atatcctctc 360
acggtcggtg ctgggaccaa gctggagctg aaaggctcca cctctggatc cggcaagccc 420
ggatctggcg agggatccac caagggccag gttcaactgc aacagtctgg ggctgagctg 480
gtgaggcctg gggcttcagt gaagctgtcc tgcaaggctt tgggctacac atttactgac 540
tatgaaatgc actgggtgaa gcagacacct gtgcatggcc tggaatggat tggagctatt 600
catccaggaa gtggtggtac tgcctataat cagaagttca agggcaaggc cacactgact 660
gcagacaaat cctccagcac agcctacatg gagctcagca ggctgacatc tgaggactct 720
gctgtctatt actgtacaag aaggaggcct aggttctatg gtatggacta ctggggtcaa 780
ggaacctcag tcaccgtctc ctcagtcgac gagtccaaat atggtccccc atgcccacca 840
tgcccagcac ctgagttcct ggggggacca tcagtcttcc tgttcccccc aaaacccaag 900
gacactctca tgatctcccg gacccctgag gtcacgtgcg tggtggtgga cgtgagccag 960
gaagaccccg aggtccagtt caactggtac gtggatggcg tggaggtgca taatgccaag1020
acaaagccgc gggaggagca gttcaacagc acgtaccgtg tggtcagcgt cctcaccgtc1080
ctgcaccagg actggctgaa cggcaaggag tacaagtgca aggtctccaa caaaggcctc1140
ccgtcctcca tcgagaaaac catctccaaa gccaaagggc agccccgaga gccacaggtg1200
tacaccctgc ccccatccca ggaggagatg accaagaacc aggtcagcct gacctgcctg1260
gtcaaaggct tctaccccag cgacatcgcc gtggagtggg agagcaatgg gcagccggag1320
aacaactaca agaccacgcc tcccgtgctg gactccgacg gctccttctt cctctacagc1380
aggctaaccg tggacaagag caggtggcag gaggggaatg tcttctcatg ctccgtgatg1440
catgaggctc tgcacaacca ctacacacag aagagcctct ccctgtccct aggtaaaatg1500
ttttgggtgc tggtggtggt tggtggagtc ctggcttgct atagcttgct agtaacagtg1560
gcctttatta ttttctgggt gaggagtaag aggagcaggg gcggacacag tgactacatg1620
aacatgactc cccgccgccc tgggcccacc cgcaagcatt accagcccta tgccccacca1680
cgcgacttcg cagcctatcg ctccaaacgg ggcagaaaga aactcctgta tatattcaaa1740
caaccattta tgagaccagt acaaactact caagaggaag atggctgtag ctgccgattt1800
ccagaagaag aagaaggagg atgtgaactg agagtgaagt tcagcaggag cgcagacgcc1860
cccgcgtacc agcagggcca gaaccagctc tataacgagc tcaatctagg acgaagagag1920
gagtacgatg ttttggacaa gagacgtggc cgggaccctg agatgggggg aaagccgaga1980
aggaagaacc ctcaggaagg cctgtacaat gaactgcaga aagataagat ggcggaggcc2040
tacagtgaga ttgggatgaa aggcgagcgc cggaggggca aggggcacga tggcctttac2100
cagggtctca gtacagccac caaggacacc tacgacgccc ttcacatgca ggccctgccc2160
cctcgctga2169
<210>113
<211>82
<212>PRT
<213>智人(Homo sapiens)
<400>113
His Gln Cys Tyr Asn Gly Ser Gly Met Asp Tyr Arg Gly Thr Ala Ser
1 5 1015
Thr Thr Lys Ser Gly His Gln Cys Gln Pro Trp Ala Leu Gln His Pro
202530
His Ser His His Leu Ser Ser Thr Asp Phe Pro Glu Leu Gly Gly Gly
354045
His Ala Tyr Cys Arg Asn Pro Gly Gly Gln Met Glu Gly Pro Trp Cys
505560
Phe Thr Gln Asn Lys Asn Val Arg Met Glu Leu Cys Asp Val Pro Ser
65707580
Cys Ser
<210>114
<211>69
<212>PRT
<213>智人(Homo sapiens)
<400>114
Ala Ile Leu His Cys Lys Val Ala Gly Asn Pro Pro Pro Asn Val Arg
1 5 1015
Trp Leu Lys Asn Asp Ala Pro Val Val Gln Glu Pro Arg Arg Ile Ile
202530
Ile Arg Lys Thr Glu Tyr Gly Ser Arg Leu Arg Ile Gln Asp Leu Asp
354045
Thr Thr Asp Thr Gly Tyr Tyr Gln Cys Val Ala Thr Asn Gly Met Lys
505560
Thr Ile Thr Ala Thr
65