一种基于训练后量化的视频超分方法
文献发布时间:2024-04-18 19:58:53
技术领域
本专利属于计算机视觉中的视频超分领域,是一种利用训练后量化方案来对视频超分方法进行量化,可以减少模型的大小、降低显存占用以及缩短推理时间。
背景技术
视频超分是通过深度学习技术,结合视频去模糊、降噪等画质修复增强处理以及针对视频场景和画面进行有效分析,有效的降低高分辨率视频的制作以及传输成本。
视频超分落地目前的一个最大问题即是需要巨大的计算量、推理时间以及显存占用,移动端以及边缘设备上的计算能力难以满足视频超分网络的需求,以及大多应用场景下难以接受较高的推理时间。因此降低视频超分计算量的使用以及减少推理时间是一个迫在眉睫的问题。常用的解决办法有设计轻量化的网络以及对网络进行量化处理。设计轻量化网络能够有效的解决显存的视频和推理时间问题,但是性能可能会有大幅度的降低,需要长时间的训练调整参数来得到一个满足需求的轻量化网络结构。对于网络的量化是一个较好的解决方案,量化能够降低模型的大小,并缩短算子的计算时间,另外并不会大幅度的降低网络的性能。
量化在深度学习领域有两个层面的意义,第一个是存储量化,即是用更少的bit来存储原本需要用浮点数存储的tensor,一般是将FP32量化为Int8,第二个是计算量化,即是用更少的bit来完成原本浮点数完成的计算。量化一般能够带来两点的好处,一个更小的模型体积,Int8量化理论上为FP32模型的75%左右,以及更少的内存访问和更快的Int8计算,一般能够加速40%左右。量化又分为动态量化、静态量化、感知量化。其中动态量化为推理过程中的量化,也叫训练后动态量化这种量化方式较为容易使用但缺点是效效果降低较多。静态量化为训练后量化的静态量化,需要部分数据作为输入去得到scale,相比较于动态量化效果会有所提高。感知量化为训练中量化,即是边训练边量化同时是效果最好的一种量化方式,但缺点是需要训练以及量化时间较长。本发明提出一种新的量化方案,是基于训练后量化的分组量化方案,能够降低视频超分网络的显存占用,减少计算量。
发明内容
针对现有技术中存在的不足,本发明提供一种基于训练后量化的视频超分方法。
本发明的目的在于降低视频超分的计算量,缩短视频超分需要的时间,同时输入为长视频,输出为超分后的长视频。将训练好的视频超分网络模型部署到TensorRT上并使用训练后量化的静态量化进行推理。发明中使用的训练数据集以及量化中用到的数据集是REDS数据集,该数据集有240个训练序列30个验证序列,每个序列包含100帧图像。
一种基于训练后量化的视频超分方法,包括以下步骤:
步骤(1)使用数据集训练FP32的模型;
对模型进行训练,使用FRVSR方法作为视频超分方法,使用Pytorch这一深度学习训练框架,另外使用mmediting配置训练FRVSR需要的模型参数、训练数据集并能够进行多显卡并行训练,。
步骤(2)使用TensorRT对模型进行部署;
使用C++调用TensorRT原生API逐层搭建FRVSR网络结构。
步骤(3)使用数据集进行int8量化以及校准;
使用TensorRT对FRVSR进行训练后静态量化,使用部分数据集进行校准,以减少模型大小以及缩短推理时间。使用REDS4数据集的测试集,作为校准数据集送入到TensorRT中计算出scales,对于量化误差大的层,使用分组量化,即在实际运算的时候使用的FP16进行计算,对于量化误差小的层,使用int8量化,在实际运算的时候使用的是int8数据类型。
进一步的,步骤(1)具体实现如下:
步骤1-1.使用mmediting中的工具包代码下载REDS4数据集,并对训练集和测试集进行划分整理。
步骤1-2.设置mmediting中训练FRVSR的配置文件,设置参数包括data中的训练集和测试集lq和gt目录,以及根据设备的显存设置每个GPU上的workers以及每个GPU上的samples。另外修改学习策略,全部的迭代次数为300k,训练策略为CosineRestart。
步骤1-3.根据配置的参数对模型进行训练,在训练的过程中程序会不断输出loss的变化以及每到一个阶段会有测试集的结果,通过判断测试集的结果判断是否训练出现问题。程序持续训练直至完成模型的训练。
步骤1-4.对模型进行保存和导出。通过测试集的结果比较出训练最好的模型,选择该模型并保存,在导出时选择保存该模型的网络结构以及模型参数一同保存成为磁盘文件,便于后续步骤的读取与利用。
进一步的,步骤(2)具体实现如下:
使用C++调用TensorRT原生API去搭建FRVSR的网络结构。并实现前向的推理。首先分析FRVSR的网络结构,采用TensorRT的layers来实现对FRVSR网络的搭建。搭建完网络之后生成engine,随后序列化engine。此时的engine是FP32格式的。
进一步的,步骤(3)具体实现如下:
对模型进行量化以及使用少量的数据集对齐进行校准,使用KL散度校准法来进行校准,得到FP32与int8特征值的scales。
选择一部分具有代表的数据作为校准数据集,对于校准数据进行FP32推理,对于每一层收集activation的分布直方图,使用不同的阈值来生成一定数量的量化好的分布。计算量化好的分布与FP32分布的KL散度,并选取KL最小的阈值作为aturation的阈值。
随后不断调整阈值,得到最优解即是得到后续量化需要的scale。
在TensorRT中输入进行量化的config,随后会对输入进行Int8的量化,并插入量化反量化、再量化三种算子,首先量化算子能够将FP32转换到int8,反量化算子是能够将int8转换到FP32,再量化算子的目的是当int8与int8相乘的结果会是int32,此时需要再量化算子将int32转换到int8。TensorRT将自动的根据网络结构以及数据特性添加这三类算子以达到我们需要的量化结果。
根据得到的scale逐层计算量化误差,将量化误差大的层执行后续分组量化,量化误差小的层保持不变。视频超分领域量化误差阈值为10%。分组量化的具体执行过程是将模型权重分为64或者128每组,每组去计算一个量化尺度和量化偏差,其中模型权重是int8的数据类型,量化尺度和量化偏差是FP16的数据类型。通过分组的大小来调整量化误差,分组越小量化的误差就越小。
本发明有益效果如下:
(1)本发明提出了视频超分网络的优化方法能够有效的减少参数量,缩短推理时间。并实现部分场景下的落地使用。
(2)本发明基于TensorRT对FRVSR做训练后静态量化,并针对量化误差大的层做分组量化,能够保证最终的量化精度,并提出了具体的实现方案,能够有效的优化FRVSR在GPU上的推理部署。
附图说明
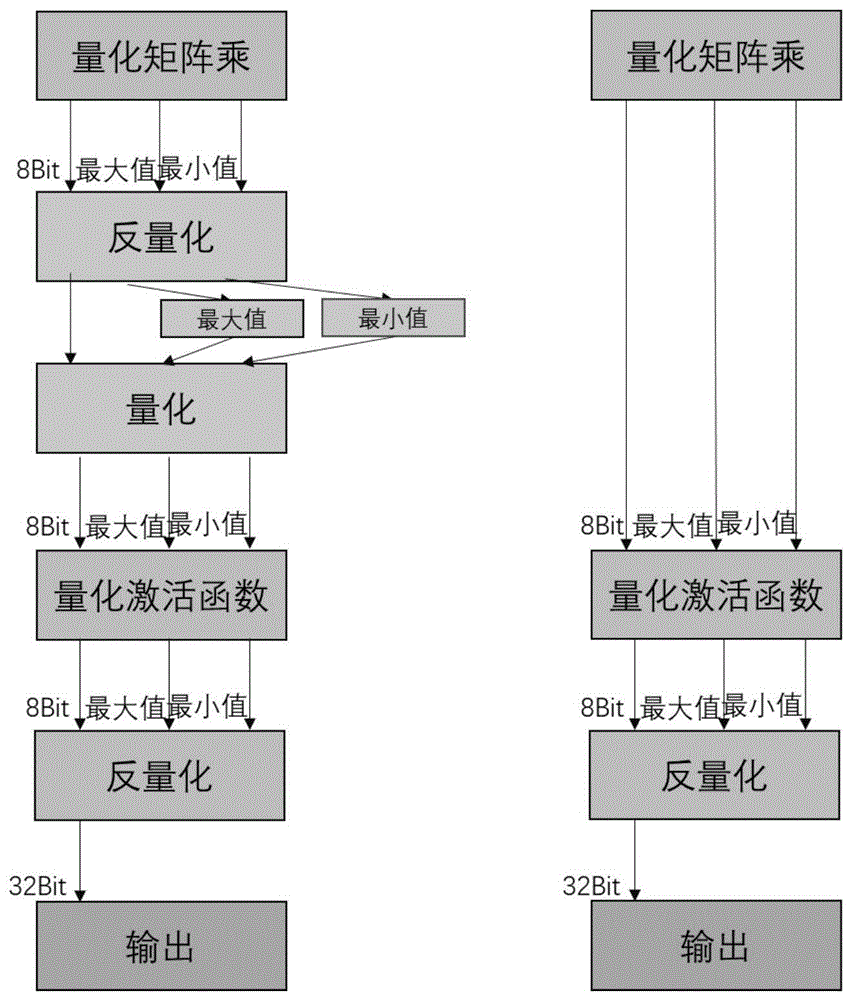
图1为训练后静态量化算法流程过程。
具体实施方式
下面结合本专利的附图来对发明专利的具体实施进行详细描述。
一种基于训练后量化的视频超分方法,包括以下步骤:
步骤(1)使用数据集训练FP32的模型;
在该阶段中,我们需要对模型进行训练,我们使用FRVSR方法作为我们的视频超分方法,该方法在参数量大小以及模型性能上都能达到我们的需求。使用Pytorch这一深度学习训练框架,能够高效的搭建网络并进行梯度的前向反向传播以及模型参数的更新学习。另外我们使用mmediting这个基于Pytorch的开源图像视频编辑工具代码库。使用mmediting能够高效的配置训练FRVSR需要的模型参数、训练数据集等并能够进行多显卡并行训练,高效的完成我们需要的模型训练任务。
步骤(2)使用TensorRT对模型进行部署;
TensorRT是NVIDIA推出的一个高性能的深度学习推理框架,可以让深度学习模型在NVIDIA GPU上实现低延迟,高吞吐量的部署。TensorRT是一个C++库,并且提供了C++API和Python API,主要在NVIDIA GPU进行高性能的推理(Inference)加速。使用TensorRT对模型进部署能够对模型的推理起到加速的效果,并能够降低显存的使用,是模型在推理上线使用的强大工具。在本步骤中我们使用C++调用TensorRT原生API逐层搭建FRVSR网络结构,以达到更为高效的目的。
步骤(3)使用数据集进行int8量化以及校准;
在该阶段,我们使用TensorRT对FRVSR进行训练后静态量化,使用部分数据集进行校准,以减少模型大小以及缩短推理时间。我们使用REDS4数据集的测试集也是较为有代表性的四个视频分别是序列000,011,015,020,作为校准数据集送入到TensorRT中计算出scales,对于量化误差大于设定阈值的层,我们使用分组量化,即在实际运算的时候使用的FP16进行计算,对于量化误差小于设定阈值的层,我们使用常规的int8量化,在实际运算的时候使用的是int8数据类型。
实施例
本发明主要包含以下实施阶段:
步骤1.训练模型并导出模型和计算图:
1-1.使用mmediting中的工具包代码下载REDS4数据集,并对训练集和测试集进行划分整理。
1-2.设置mmediting中训练FRVSR的配置文件,主要设置参数有data中的训练集和测试集lq和gt目录,以及根据设备的显存设置每个GPU上的workers以及每个GPU上的samples。另外需要修改学习策略,全部的迭代次数为300k,训练策略为CosineRestart。
1-3.使用两块或者四块显卡以及前面所配置的参数对模型进行训练,在训练的过程中程序会不断输出loss的变化以及每到一个阶段会有测试集的结果,通过判断测试集的结果来简单判断是否训练出现问题。程序持续训练两到三天能够完成模型的训练。
1-4.对模型进行保存和导出。通过测试集的结果可以比较出训练最好的模型,选择该模型并保存,在导出时选择保存该模型的网络结构以及模型参数一同保存成为磁盘文件,便于后续步骤的读取与利用。
步骤2.在TensorRT上部署FRVSR:
该步骤中,我们使用C++调用TensorRT原生API去搭建FRVSR的网络结构。并实现前向的推理。首先分析FRVSR的网络结构,以卷积层激活函数层为主,还有一些残差连接的结构。因此主要是采用TensorRT的addConvolutionNd()、addPooling()、addSoftMax()等layers来实现对FRVSR网络的搭建。搭建完网络之后生成engine,随后序列化engine。此时的engine是FP32格式的。
步骤3.进行模型量化以及使用数据集校准:
在此步骤里,我们要对模型进行量化以及使用少量的数据集对齐进行校准,我们这里使用KL散度校准法来进行校准,校准的目的就是得到FP32与int8特征值的scales。
其中KL散度校准法也叫相对熵,其中p表示真实分布,q表示非真实分布或p的近似分布。
其中相对熵是用来衡量真实分布和非真实分布的差异大小。目的就是改变量化域,实则就是改变真实的分布,并使得修改后的真实分布在量化后与量化前相对熵越小越好。具体的执行流程就是选择一部分具有代表的数据作为校准数据集,对于校准数据进行FP32推理,对于每一层收集activation的分布直方图,使用不同的阈值来生成一定数量的量化好的分布。计算量化好的分布与FP32分布的KL散度,并选取KL最小的阈值作为aturation的阈值。
随后不断调整阈值,得到最优解即是得到后续量化需要的scale。
在TensorRT中输入进行量化的config,随后会对输入进行Int8的量化,并插入量化反量化、再量化三种算子,首先量化算子能够将FP32转换到int8,反量化算子是能够将int8转换到FP32,再量化算子的目的是当int8与int8相乘的结果会是int32,此时需要再量化算子将int32转换到int8。TensorRT将自动的根据网络结构以及数据特性添加这三类算子以达到我们需要的量化结果。
根据得到的scale逐层计算量化误差,将量化误差大的层执行后续分组量化,量化误差小的层保持不变。评判量化误差大小根据不同领域会有不同的阈值,在视频超分领域量化误差阈值大概在10%左右。分组量化实际上执行的是FP16的运算,比int8能够表示更多的信息,比FP32计算更快,更少的占用显存。分组量化的具体执行过程是将模型权重分为64或者128每组,每组去计算一个量化尺度和量化偏差,其中模型权重是int8的数据类型,量化尺度和量化偏差是FP16的数据类型。通过分组的大小来调整量化误差,分组越小量化的误差就越小。通过这样就能够解决视频超分需要的高计算量高显存,以及再部分层做量化会带来较大误差的问题。图1为训练后静态量化算法流程过程。
步骤(4).通过经过量化和校准后的模型完成视频超分;
以上内容是结合具体/优选的实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员,在不脱离本发明构思的前提下,其还可以对这些已描述的实施方式做出若干替代或变型,而这些替代或变型方式都应当视为属于本发明的保护范围。
本发明未详细说明部分属于本领域技术人员公知技术。