一种基于云存储的生物医学数据分类管理控制方法和系统
文献发布时间:2023-06-19 11:54:11
技术领域
本发明涉及数据管理技术领域,尤其是涉及一种基于云存储的生物医学数据分类管理控制方法和系统。
背景技术
21世纪,随着高通量测序、单细胞测序和质谱分析等技术的快速发展和应用,使各个生物组学及医学数据也在不断地积累。据统计一般的医疗机构每年会产生1~20TB的数据,个别大型医院的年产数据量甚至达到300TB~1PB。而对于精准医学时代产生的PB~EB量级的生物医学数据,如何进行有效的存储和管理,进而有效的服务于临床的数据分析和研究是目前主要的研究课题。当前,一些用于生物医学大数据存储的系统(数据库系统)能够通过web端的系统对用户提交的数据进行存储,同时也能够实现数据的快速更新,以及支持用户进行数据的访问、发布、下载等基本的数据管理操作。例如,
1)GEO数据库是目前世界上最大、最全面的公共基因数据平台,提供了免费的芯片数据与二代测序数据的存储和发布;
2)LinkedOmics既是数据库,也是一个基于Web的分析平台。其数据库中包含了来自癌症基因组图谱(TCGA)项目的32种癌症和11158名患者的多组学数据和临床数据。该平台也是第一个集成了基于质谱(MS)的蛋白质组学数据的多组学数据库;
3)UCSC Xena同样既是一个大型的癌症数据库,也是一个基于Web的分析平台。UCSC Xena包括前端的Xena Browser和后台的Xena Hubs。该平台已收录了50多种癌症类型和1500多种数据集的数据,包括癌症基因组图谱(TCGA),国际癌症基因组协会(ICGC),基因组数据共享区(GDC)和UCSC RNA-seq中的数据。
除上述的3个例子之外,还有很多用于生物医学大数据存储的平台系统。但这些平台依然会有很多不足,一是高校、研究机构和医院的敏感数据不能上传到这些公共的数据存储平台;二是存储的生物医学数据类型单一、且不能被标准的分析工作流在线调用和分析。这就为科研人员和临床研究造成了诸多不便。因此,现有技术中急需一个公共、安全、高效、存储数据类型多元且能够与在线分析操作系统联动的生物医学数据云存储平台。
发明内容
本发明的目的就是为了克服上述现有技术存在的隐私性较差、能够存储的生物医学数据类型单一、且不能被标准的分析工作流在线调用和分析缺陷而提供一种基于云存储的生物医学数据分类管理控制方法和系统。
本发明的目的可以通过以下技术方案来实现:
一种基于云存储的生物医学数据分类管理控制方法,具体包括以下步骤:
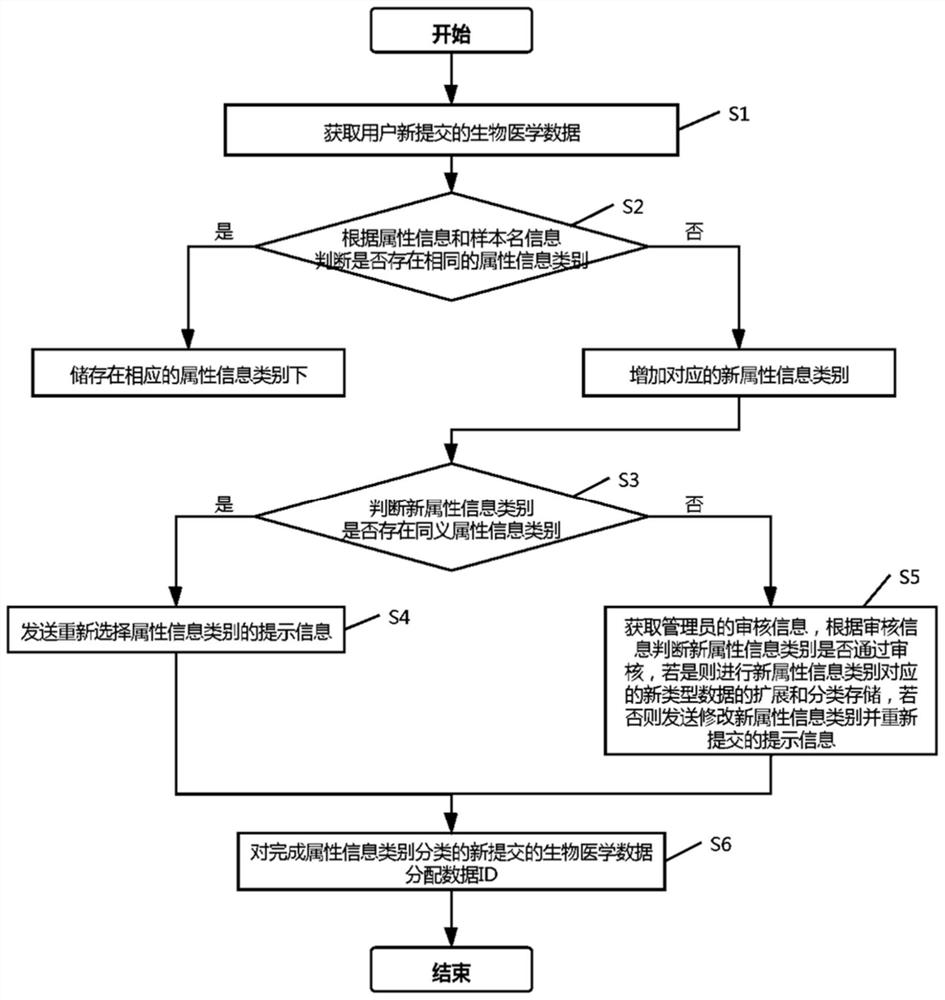
S1、获取用户新提交的生物医学数据;
S2、根据所述生物医学数据的属性信息和样本名信息,判断是否存在相同的属性信息类别,若是则储存在相应的属性信息类别下,如否则增加对应的新属性信息类别;
S3、判断所述新属性信息类别是否存在同义属性信息类别,若是转至步骤S4,否则转至步骤S5;
S4、发送重新选择属性信息类别的提示信息;
S5、获取管理员的审核信息,根据所述审核信息判断所述新属性信息类别是否通过审核,若是则进行新属性信息类别对应的新类型数据的扩展和分类存储,若否则发送修改新属性信息类别并重新提交的提示信息;
S6、对完成属性信息类别分类的新提交的生物医学数据分配数据ID,完成分类储存。
所述数据ID具有唯一性。
所述生物医学数据的属性信息包括分类、实验平台、数据格式、样本组织来源和样本类型。
所述步骤S2中增加对应的新属性信息类别的过程还包括上传生物医学数据的压缩文件,并设置所述生物医学数据的隐私权限。
进一步地,所述隐私权限的类型包括公开、半公开和个人。
进一步地,公开类型的隐私权限具体对应所有用户都可检索、查看和下载的生物医学数据;半公开类型的隐私权限具体对应所有用户都可检索、但仅上传该数据的用户可下载的生物医学数据;个人类型的隐私权限具体对应仅上传此数据的用户可以检索、查看和下载的生物医学数据。
一种使用所述的基于云存储的生物医学数据分类管理控制方法的管理系统,包括数据仓储子系统、数据分类子系统和云存储子系统,所述管理系统连接有数据分析系统,所述数据分析系统的分析工作流通过所述数据ID从数据仓储子系统中调用相应的生物医学数据。
所述云存储子系统通过分配的数据ID来存储用户提交的数据文件。
所述管理系统还包括个人中心控制模块,所述个人中心控制模块分别与数据仓储子系统和数据分析系统连接。
所述个人中心控制模块通过数据仓储子系统对其中储存的生物医学数据执行管理操作。
进一步地,所述个人中心控制模块在数据仓储子系统中执行的管理操作包括删除、下载和隐私权限设置。
所述数据分析系统通过分析工作流调用生物医学数据进行数据分析或数据可视化,并生成分析结果,所述分析结果的类型包括图像和表单。
进一步地,所述数据分析系统进行数据分析或数据可视化的原理具体为数据分析系统和数据仓储通子系统之间建立的数据接口为数据分析需求提供相关的计算和运行环境。
进一步地,所述个人中心控制模块中设有结果展示子模块,所述结果展示子模块获取所述数据分析系统的分析结果并展示。
与现有技术相比,本发明具有以下有益效果:
1.本发明中用户可通过添加属性信息进行自定义属性信息类别的扩展,在原有的存储系统中增加新的属性信息类别,相较于现有技术中不支持用户对新提交数据类型的分类、数据格式等属性信息的类别进行自定义扩展、数据存储类型较为单一或局限的缺陷,本发明支持的存储数据类型更多元、更友好、更高效,实现多元生物医学大数据的分类存储,提高了用户在管理生物医学大数据方面的体验。
2.本发明通过判断新属性信息类别是否存在同义属性信息类别,存在重复或类似语义的新属性信息类别需要修改新属性信息类别并重新上传数据,对存储的数据进行消歧,有效避免了存储系统中类型语义的属性信息类别重复设置,占用存储空间,同时类似的属性信息类别在具体调用数据时容易产生误差,本发明的设置有效提高了数据管理的准确性和稳定性。
附图说明
图1为本发明控制方法的流程示意图;
图2为本发明的整体流程示意图;
图3为本发明管理系统的结构示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
实施例
如图1所示,一种基于云存储的生物医学数据分类管理控制方法,具体包括以下步骤:
S1、获取用户新提交的生物医学数据;
S2、根据生物医学数据的属性信息和样本名信息,判断是否存在相同的属性信息类别,若是则储存在相应的属性信息类别下,如否则增加对应的新属性信息类别;
S3、判断新属性信息类别是否存在同义属性信息类别,若是转至步骤S4,否则转至步骤S5;
S4、发送重新选择属性信息类别的提示信息;
S5、获取管理员的审核信息,根据审核信息判断新属性信息类别是否通过审核,若是则进行新属性信息类别对应的新类型数据的扩展和分类存储,若否则发送修改新属性信息类别并重新提交的提示信息;
S6、对完成属性信息类别分类的新提交的生物医学数据分配数据ID,完成分类储存,本实施例中,生物医学数据的存储方式为MySQL数据库。
数据ID具有唯一性。
本实施例中,多元生物医学数据的类型包括二代和三代的组学测序数据、甲基化数据、质谱数据、医学影像数据和临床医学信息数据。
生物医学数据的属性信息包括分类、实验平台、数据格式、样本组织来源和样本类型。
步骤S2中增加对应的新属性信息类别的过程还包括上传生物医学数据的压缩文件,并设置生物医学数据的隐私权限。
隐私权限的类型包括公开、半公开和个人。
公开类型的隐私权限具体对应所有用户都可检索、查看和下载的生物医学数据,适用于已公开发表的数据类型;
半公开类型的隐私权限具体对应所有用户都可检索、但仅上传该数据的用户可下载的生物医学数据,适用于即将发表但未能公开的数据类型;
个人类型的隐私权限具体对应仅上传此数据的用户可以检索、查看和下载的生物医学数据,适用于隐私的数据类型。
如图3所示,一种使用基于云存储的生物医学数据分类管理控制方法的管理系统,包括数据仓储子系统、数据分类子系统和云存储子系统,管理系统连接有数据分析系统,数据分析系统的分析工作流通过数据ID从数据仓储子系统中调用相应的生物医学数据。
本实施例中,数据仓储子系统建于Web端,对云存储子系统和分类管理子系统中的数据进行检索、访问、上传、自扩展存储数据类型的分类、数据格式等属性信息、下载、删除、隐私权限管理等操作。
云存储子系统通过分配的数据ID来存储用户提交的数据文件。
管理系统还包括个人中心控制模块,个人中心控制模块分别与数据仓储子系统和数据分析系统连接。
个人中心控制模块通过数据仓储子系统对其中储存的生物医学数据执行管理操作。
个人中心控制模块在数据仓储子系统中执行的管理操作包括删除、下载和隐私权限设置。
数据分析系统通过分析工作流调用生物医学数据进行数据分析或数据可视化,并生成分析结果,分析结果的类型包括图像和表单。
数据分析系统进行数据分析或数据可视化的原理具体为数据分析系统和数据仓储通子系统之间建立的数据接口为数据分析需求提供相关的计算和运行环境。
个人中心控制模块中设有结果展示子模块,结果展示子模块获取数据分析系统的分析结果并展示。
如图2所示,本实施例中,管理系统的工作流程具体如下所示:
401、用户登录个人中心模块,点击数据仓储;
402、是否要新提交和存储数据,若是进入步骤403,否则进入步骤405;
403、选择提交和存储数据的分类、实验平台、数据格式、样本组织来源、样本类型等属性信息,并填写样本名等信息。若在上述数据的分类、实验平台、数据格式、样本组织来源、样本类型等属性信息的选项中没有用户数据对应的属性信息类别,用户可通过添加属性信息进行自定义属性信息类别的扩展,之后上传数据的压缩文件,最后选择数据的隐私权限后即可点击提交;
404、分类管理子系统判断用户提交数据的属性信息是否为新类别。若新添加的属性类别在系统内存在同义属性信息类别,系统会通过web界面提示用户重新选择数据的属性信息,从而实现分类等属性信息的消歧;
405、若新添加的属性类别在系统内不存在同义属性信息类别,系统会通知管理员进行审核,审核通过后即可进行新类型数据的扩展和分类存储;审核不通过则通知用户修改新添加的属性信息类别,并重新提交数据;
406、数据仓储子系统对用户新提交的数据分配唯一的数据ID;
407、若不是新提交和存储数据,则可通过数据仓储的分类管理系统进行查看或检索已上传的数据;
408、在个人中心模块,通过数据仓储子系统,用户可对已存储的数据进行删除、下载、隐私权限设置等管理操作;
409、用户可通过数据分析系统中的分析工作流调用数据仓储中已存储的生物医学数据进行分析或数据的可视化,并将分析结果反馈至Web端的结果展示子模块的展示页;
410、用户可在个人中心模块的结果展示子模块中查看和下载数据分析系统的分析结果。
此外,需要说明的是,本说明书中所描述的具体实施例,所取名称可以不同,本说明书中所描述的以上内容仅仅是对本发明结构所做的举例说明。凡依据本发明构思的构造、特征及原理所做的等效变化或者简单变化,均包括于本发明的保护范围内。本发明所属技术领域的技术人员可以对所描述的具体实例做各种各样的修改或补充或采用类似的方法,只要不偏离本发明的结构或者超越本权利要求书所定义的范围,均应属于本发明的保护范围。
- 一种基于云存储的生物医学数据分类管理控制方法和系统
- 一种基于聚类的多标签不平衡生物医学数据分类方法