基于长短时记忆网络的PM2.5预测方法
文献发布时间:2023-06-19 12:00:51
技术领域
本发明涉及数据处理领域,特别涉及一种基于长短时记忆网络的PM2.5预测方法。
背景技术
PM2.5浓度预测作为回归预测,现有方法主要包括线性回归和神经网络等,在预测效果上有一定的准确性,但未考虑到PM2.5浓度前后时刻具有的连续性,即下一个时段浓度值变化与上个时间段的含量具有很强的记忆关系,因此,使用该方式所得到的PM2.5浓度并不精确。
发明内容
本发明的目的是克服上述现有技术中存在的问题,提供一种基于长短时记忆网络的PM2.5预测方法,利用长短时记忆网络,更好的刻画PM2.5浓度本身具有的时间序列关系,最终训练得到的预测模型相较于线性回归和神经网络模型具有更高的准确度。
为此,本发明提供一种基于长短时记忆网络的PM2.5预测方法,包括如下步骤:
S1:获取目标空气质量监测站点中M个时间节点的每一个时间节点的PM2.5的值以及其他N-1个空气参数的值,其中M为正整数;
S2:截取第m个时间节点之前的F个时间节点的每一个时间节点的PM2.5的值以及其他N-1个空气参数的值,其中m、F以及N均为正整数,m∈M,F<m;
构建第f个时间节点的特征向量基数H
H
其中,x
S3:构建数据矩阵Z,使得
Z=[H
其中,f∈F;
S4:设置目标值Y,使得
Y=T
其中,T
S5:建立长短时记忆网络模型,所述长短时记忆网络模型包括依次设立的LSTM层和Dense层,初始化所述长短时记忆网络模型的参数并将所述数据矩阵Z作为输入,得到输出预测值W,将所述预测值W与所述目标值Y进行对比,根据对比结果修改所述长短时记忆网络模型的参数,直至对比结果的误差在设定的范围内。
进一步,本发明使用滚动时间窗口的方式进行所述步骤S1至步骤S4,使得所述数据矩阵Z遍历所述M个时间节点的每一个时间节点的PM2.5的值以及其他N-1个空气参数的值。
进一步,在步骤S2中,在得到构建的第f个时间节点的特征向量基数H
进一步,在步骤S1中,在得到M个时间节点的每一个时间节点的PM2.5的值以及其他N-1个空气参数的值之后,对数据进行清洗。
进一步,在步骤S5中,所述所述数据矩阵Z作为输入进入所述LSTM层,输出得到多维向量,在将所述LSTM层输出的所述多维向量送入所述Dense层进行向量转换得到一维数值,并将该输出的所述一维数值作为所述预测值W。
本发明提供的基于长短时记忆网络的PM2.5预测方法,具有如下有益效果:
1、本发明利用长短时记忆网络,更好的刻画PM2.5浓度本身具有的时间序列关系,最终训练得到的预测模型相较于线性回归和神经网络模型具有更高的准确度;
2、本发明充分考虑了包括其他污染物及天气因素对PM2.5浓度的影响,预测效果更加精确;
附图说明
图1为本发明的整体数据流程示意图;
图2为本发明的实测数据统计示意图。
具体实施方式
下面结合附图,对本发明的多个具体实施方式进行详细描述,但应当理解本发明的保护范围并不受具体实施方式的限制。
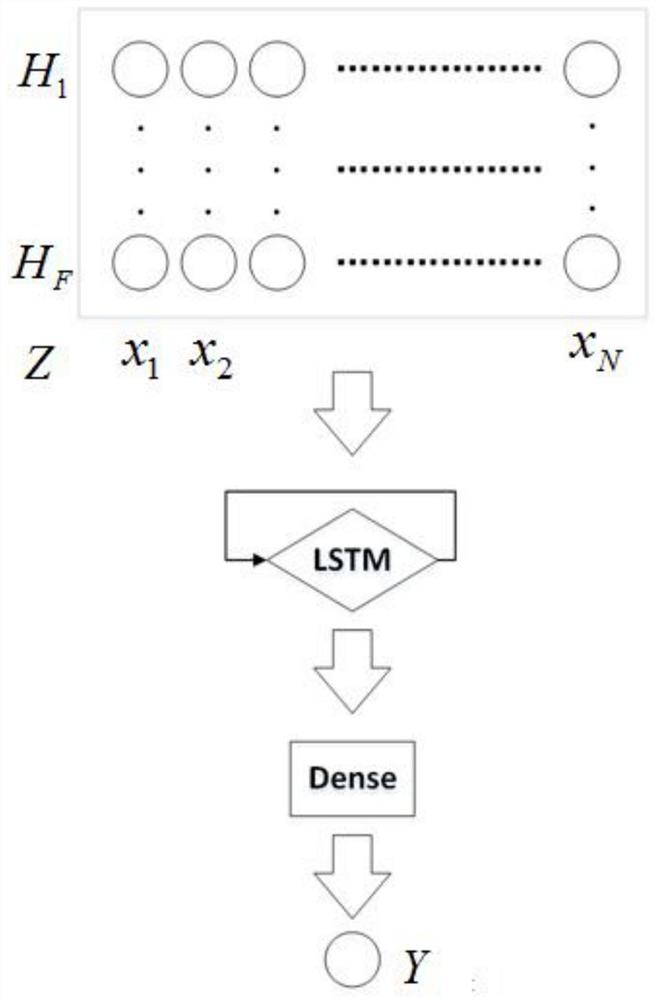
具体的,如图1所示,本发明实施例提供了一种基于长短时记忆网络的PM2.5预测方法,包括如下步骤:
S1:获取目标空气质量监测站点中M个时间节点的每一个时间节点的PM2.5的值以及其他N-1个空气参数的值,其中M为正整数;
S2:截取第m个时间节点之前的F个时间节点的每一个时间节点的PM2.5的值以及其他N-1个空气参数的值,其中m、F以及N均为正整数,m∈M,F<m;
构建第f个时间节点的特征向量基数H
H
其中,x
S3:构建数据矩阵Z,使得
Z=[H
其中,f∈F;
S4:设置目标值Y,使得
Y=T
其中,T
S5:建立长短时记忆网络模型,所述长短时记忆网络模型包括依次设立的LSTM层和Dense层,初始化所述长短时记忆网络模型的参数并将所述数据矩阵Z作为输入,得到输出预测值W,将所述预测值W与所述目标值Y进行对比,根据对比结果修改所述长短时记忆网络模型的参数,直至对比结果的误差在设定的范围内。
上述技术方案中,本发明利用长短时记忆网络模型,更好的刻画PM2.5浓度本身具有的时间序列关系,最终训练得到的预测模型相较于线性回归和神经网络模型具有更高的准确度。同时,本发明的长短时记忆网络模型,其预测间隔的时间点可以认为的进行限定,可以使得操作性更强,所得到的数据更加的准确。同时,本发明充分考虑了包括其他污染物及天气因素对PM2.5浓度的影响,预测效果更加精确。
在本实施例中,本发明使用滚动时间窗口的方式进行所述步骤S1至步骤S4,使得所述数据矩阵Z遍历所述M个时间节点的每一个时间节点的PM2.5的值以及其他N-1个空气参数的值。
这样就可以使得每一个时间节点的数值都可以参与到本发明的模型运算中,这样也就使得模型运算的时候,具有连续性,使得数据得到的更加的接近与真实值,从而使得预测结果更加精确。与此同时,本发明将数据充分的进行利用,这样就会使得数据的利用率更高。
在本实施例中,在步骤S2中,在得到构建的第f个时间节点的特征向量基数H
在本实施例中,在步骤S1中,在得到M个时间节点的每一个时间节点的PM2.5的值以及其他N-1个空气参数的值之后,对数据进行清洗。对数据清洗可以将数据进行删选,去除一些问题数据,提升预测的准确度。
在本实施例中,在步骤S5中,所述所述数据矩阵Z作为输入进入所述LSTM层,输出得到多维向量,在将所述LSTM层输出的所述多维向量送入所述Dense层进行向量转换得到一维数值,并将该输出的所述一维数值作为所述预测值W。
图2为本发明所提供的方法,在进行具体是时间适合所得到的数据,统计之后绘制的图表,仅供参考。
以上公开的仅为本发明的几个具体实施例,但是,本发明实施例并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
- 基于长短时记忆网络的PM2.5预测方法
- 基于长短时记忆网络的工单数量预测方法