一种用于通过通讯录数据进行预测的方法、设备、介质
文献发布时间:2023-06-19 19:35:22
技术领域
本申请涉及通信领域,尤其涉及一种用于通过通讯录数据进行预测的技术。
背景技术
在传统移动信息领域,对性别判断主要基于图像、声音、App安装列表、App内的购物或娱乐行为数据等,存在数据采集量大、覆盖度不足、准确率不高等问题。
发明内容
本申请的一个目的是提供一种用于通过通讯录数据进行预测的方法、设备、介质及程序产品。
根据本申请的一个方面,提供了一种用于通过通讯录数据进行预测的方法,该方法包括:
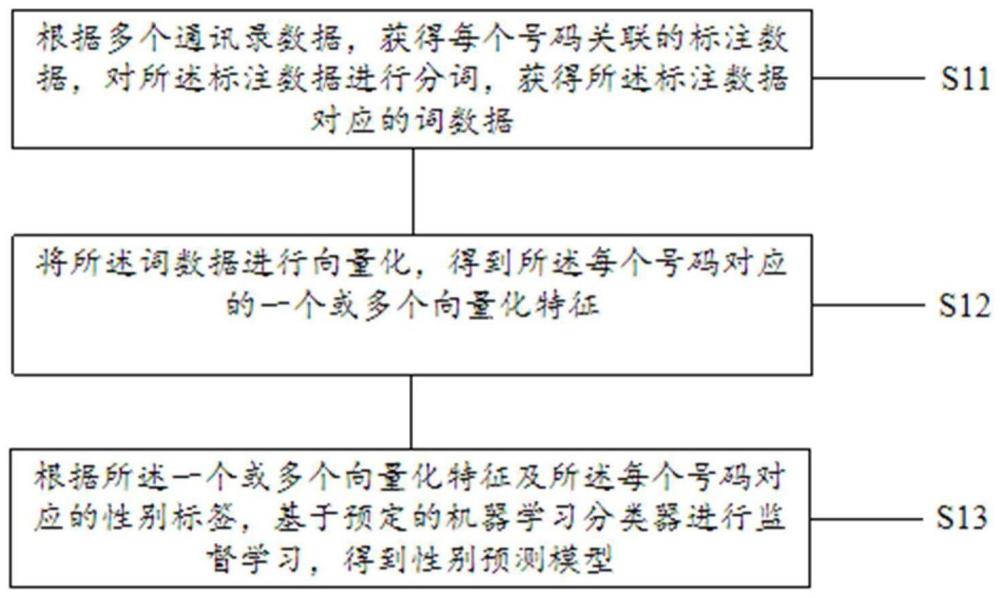
根据多个通讯录数据,获得每个号码关联的标注数据,对所述标注数据进行分词,获得所述标注数据对应的词数据;
将所述词数据进行向量化,得到所述每个号码对应的一个或多个向量化特征;
根据所述一个或多个向量化特征及所述每个号码对应的性别标签,基于预定的机器学习分类器进行监督学习,得到性别预测模型。
根据本申请的另一个方面,提供了一种用于通过通讯录数据进行预测的方法,该方法包括:
对目标号码关联的目标标注数据进行分词,获得所述目标标注数据对应的目标词数据;
将所述目标词数据进行向量化,得到所述目标号码对应的目标向量化特征;
将所述目标向量化特征输入性别预测模型,得到所述性别预测模型输出的所述目标号码对应的预测性别信息。
根据本申请的一个方面,提供了一种用于通过通讯录数据进行预测的计算机设备,该设备包括:
一一模块,用于根据多个通讯录数据,获得每个号码关联的标注数据,对所述标注数据进行分词,获得所述标注数据对应的词数据;
一二模块,用于将所述词数据进行向量化,得到所述每个号码对应的一个或多个向量化特征;
一三模块,用于根据所述一个或多个向量化特征及所述每个号码对应的性别标签,基于预定的机器学习分类器进行监督学习,得到性别预测模型。
根据本申请的另一个方面,提供了一种用于通过通讯录数据进行预测的计算机设备,该设备包括:
二一模块,用于对目标号码关联的目标标注数据进行分词,获得所述目标标注数据对应的目标词数据;
二二模块,用于将所述目标词数据进行向量化,得到所述目标号码对应的目标向量化特征;
二三模块,用于将所述目标向量化特征输入性别预测模型,得到所述性别预测模型输出的所述目标号码对应的预测性别信息。
根据本申请的一个方面,提供了一种用于通过通讯录数据进行预测的计算机设备,包括存储器、处理器及存储在存储器上的计算机程序,其中,所述处理器执行所述计算机程序以实现如上所述任一方法的操作。
根据本申请的一个方面,提供了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现如上所述任一方法的操作。
根据本申请的一个方面,提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现如上所述任一方法的步骤。
与现有技术相比,本申请根据多个通讯录数据,获得每个号码关联的标注数据,对所述标注数据进行分词,获得所述标注数据对应的词数据;将所述词数据进行向量化,得到所述每个号码对应的一个或多个向量化特征;根据所述一个或多个向量化特征及所述每个号码对应的性别标签,基于预定的机器学习分类器进行监督学习,得到性别预测模型,从而可以根据通讯录主相对客观的用户号码标注信息,通过嵌入向量化方式,得到每个被标注号码的向量化特征,将向量化特征输入到性别预测模型,即可对被标注号码进行性别预测,可以明显提高性别预测的覆盖度与准确率,且由于不用管具体的标注内容,不需要对标注内容进行理解,该方法可以扩展应用到任何外文。
附图说明
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本申请的其它特征、目的和优点将会变得更明显:
图1示出根据本申请一个实施例的一种用于通过通讯录数据进行预测的方法流程图;
图2示出根据本申请一个实施例的一种用于通过通讯录数据进行预测的方法流程图;
图3示出根据本申请一个实施例的一种用于通过通讯录数据进行预测的计算机设备结构图;
图4示出根据本申请一个实施例的一种用于通过通讯录数据进行预测的计算机设备结构图;
图5示出可被用于实施本申请中所述的各个实施例的示例性系统。
附图中相同或相似的附图标记代表相同或相似的部件。
具体实施方式
下面结合附图对本申请作进一步详细描述。
在本申请一个典型的配置中,终端、服务网络的设备和可信方均包括一个或多个处理器(例如,中央处理器(Central Processing Unit,CPU))、输入/输出接口、网络接口和内存。
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RandomAccess Memory,RAM)和/或非易失性内存等形式,如只读存储器(Read Only Memory,ROM)或闪存(Flash Memory)。内存是计算机可读介质的示例。
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(Phase-Change Memory,PCM)、可编程随机存取存储器(Programmable Random Access Memory,PRAM)、静态随机存取存储器(Static Random-Access Memory,SRAM)、动态随机存取存储器(Dynamic Random AccessMemory,DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(Electrically-Erasable Programmable Read-Only Memory,EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(Compact Disc Read-Only Memory,CD-ROM)、数字多功能光盘(Digital Versatile Disc,DVD)或其他光学存储、磁盒式磁带,磁带磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。
本申请所指设备包括但不限于终端、网络设备、或终端与网络设备通过网络相集成所构成的设备。所述终端包括但不限于任何一种可与用户进行人机交互(例如通过触摸板进行人机交互)的移动电子产品,例如智能手机、平板电脑等,所述移动电子产品可以采用任意操作系统,如Android操作系统、iOS操作系统等。其中,所述网络设备包括一种能够按照事先设定或存储的指令,自动进行数值计算和信息处理的电子设备,其硬件包括但不限于微处理器、专用集成电路(Application Specific Integrated Circuit,ASIC)、可编程逻辑器件(Programmable Logic Device,PLD)、现场可编程门阵列(Field ProgrammableGate Array,FPGA)、数字信号处理器(Digital Signal Processor,DSP)、嵌入式设备等。所述网络设备包括但不限于计算机、网络主机、单个网络服务器、多个网络服务器集或多个服务器构成的云;在此,云由基于云计算(Cloud Computing)的大量计算机或网络服务器构成,其中,云计算是分布式计算的一种,由一群松散耦合的计算机集组成的一个虚拟超级计算机。所述网络包括但不限于互联网、广域网、城域网、局域网、VPN网络、无线自组织网络(Ad Hoc网络)等。优选地,所述设备还可以是运行于所述终端、网络设备、或终端与网络设备、网络设备、触摸终端或网络设备与触摸终端通过网络相集成所构成的设备上的程序。
当然,本领域技术人员应能理解上述设备仅为举例,其他现有的或今后可能出现的设备如可适用于本申请,也应包含在本申请保护范围以内,并在此以引用方式包含于此。
在本申请的描述中,“多个”的含义是两个或者更多,除非另有明确具体的限定。
图1示出根据本申请一个实施例的一种用于通过通讯录数据进行预测的方法流程图,该方法包括步骤S11、步骤S12和步骤S13。在步骤S11中,计算机设备根据多个通讯录数据,获得每个号码关联的标注数据,对所述标注数据进行分词,获得所述标注数据对应的词数据;在步骤S12中,计算机设备将所述词数据进行向量化,得到所述每个号码对应的一个或多个向量化特征;在步骤S13中,计算机设备根据所述一个或多个向量化特征及所述每个号码对应的性别标签,基于预定的机器学习分类器进行监督学习,得到性别预测模型。
在步骤S11中,计算机设备根据多个通讯录数据,获得每个号码关联的标注数据,对所述标注数据进行分词,获得所述标注数据对应的词数据。在一些实施例中,用户可以在通讯录中对某个联系人号码添加备注(例如,称谓、昵称、职业、名字等),预先收集多个用户的通讯录,将各个通讯录的数据进行整合汇总,对于某个联系人号码,若一个或多个通讯录中存在该联系人号码对应的备注信息,则该联系人号码与该一个或多个通讯录相关联,该联系人号码关联的标注数据包括与该联系人号码相关联的一个或多个通讯录中的该联系人号码对应的备注信息。在一些实施例中,若每个号码关联的标注数据中包括多个备注信息,则该多个备注信息可以使用预定的分隔符(例如,空格、逗号等)拼接在一起。在一些实施例中,对于每个号码关联的标注数据,使用预定的分词算法将该标注数据切分成多个词数据,例如,可以使用jieba分词算法(例如,python版本的jieba分词算法“https://github.com/fxsjy/jieba”)。
在步骤S12中,计算机设备将所述词数据进行向量化,得到所述每个号码对应的一个或多个向量化特征。在一些实施例中,可以通过预定的嵌入式(embedding)算法将每个人联系人号码对应的词数据进行向量化,用低维稠密的数值向量来表示词数据,得到该联系人号码对应的一个或多个向量化特征,每个向量化特征对应一个词数据,每个向量化特征用于通过一个向量来表示一个词数据,例如,可以使用word2vec嵌入式算法(word2vec是Google公司于2013年发布的一个开源的词向量算法)。
在步骤S13中,计算机设备根据所述一个或多个向量化特征及所述每个号码对应的性别标签,基于预定的机器学习分类器进行监督学习,得到性别预测模型。在一些实施例中,将每个联系人号码对应的性别标准数据作为该联系人号码的监督学习标签即性别标签,基于每个联系人号码对应的一个或多个向量化特征以及该联系人号码的性别标签,基于预定的机器学习分类器进行监督学习,训练得到一个性别预测模型。在一些实施例中,该机器学习分类器包括但不限于随机森林分类器、梯度提升树分类器等。在一些实施例中,监督学习是指通过让机器学习大量带有标签的样本数据,调整分类器的参数,训练出一个模型,使得该模型可以对新的无标签的数据进行预测或分类的过程。在一些实施例中,性别预测模型用于根据某个号码在一个通讯录中的备注信息或者根据某个号码在一个或多个通讯录中所关联的标注数据,预测得到该号码所对应的用户的性别数据。本申请可以根据通讯录主相对客观的用户号码标注信息,通过嵌入向量化方式,得到每个被标注号码的向量化特征,将向量化特征输入到性别预测模型,即可对被标注号码进行性别预测,可以明显提高性别预测的覆盖度与准确率,且由于不用管具体的标注内容,不需要对标注内容进行理解,该方法可以扩展应用到任何外文。
在一些实施例中,所述对所述标注数据进行分词,获得所述标注数据对应的词数据,包括:对所述标注数据进行分词,去除分词结果中的无意义词,获得所述标注数据对应的词数据。在一些实施例中,对于每个号码关联的标注数据,先使用预定的分词算法将该标注数据切分成多个分词,再去除该多个分词中的一个或多个无意义词,将去除后的至少一个分词作为该标注数据对应的词数据,其中,该无意义词包括但不限于没有实际意义的符号、数字等。
在一些实施例中,所述对所述标注数据进行分词,去除分词结果中的无意义词,获得所述标注数据对应的词数据,包括:对所述标注数据进行分词,去除分词结果中的无意义词,并将分词结果中出现次数大于或等于预定次数阈值的一个或多个分词作为所述标注数据对应的词数据。在一些实施例中,对于每个号码关联的标注数据,先使用预定的分词算法将该标注数据切分成多个分词,再去除该多个分词中的一个或多个无意义词,然后再选取在去除后的至少一个分词中的出现次数大于或等于预定次数阈值的一个或多个分词,并将该一个或多个分词作为该标注数据对应的词数据。
在一些实施例中,所述步骤S12包括:计算机设备将所述词数据输入已训练的词向量模型,得到所述词向量模型输出的所述每个号码对应的一个或多个向量化特征。在一些实施例中,对于每个号码关联的标注数据,可以将该标注数据所对应的词数据输入一个已训练的词向量模型,该词向量模型会输出该号码对应的一个或多个向量化特征。
在一些实施例中,所述方法还包括:计算机设备设置词向量模型对应的训练参数;根据多个号码分别关联的标注数据对所述量模型进行训练,得到已训练的词向量模型。在一些实施例中,首先预先设置词向量模型对应的训练参数,该训练参数包括但不限于向量化维度数(例如,32)、最少词频(例如,100)等,然后随机抽取多个号码分别关联的标注数据作为训练数据,再使用该训练数据对该词向量模型进行无标签训练,可以得到已训练的词向量模型。
在一些实施例中,所述训练参数包括以下至少一项:向量化维度数;最少词频。在一些实施例中,向量化维度数是指用一个多少维度的向量来表示一个词数据。在一些实施例中,最少词频(min_count)用于去掉一些生僻的低频词,即不使用向量化特征来表示这些低频词,这些低频词不存在对应的向量化特征。
在一些实施例中,所述机器学习分类器包括以下任一项:随机森林分类器;梯度提升树分类器。在一些实施例中,随机森林(Random Forest)分类器是利用多棵树对样本进行训练并预测的一种包含多个决策树的分类器。在一些实施例中,梯度提升树(GradientBoosting Tree,或者,Gradient Boosting Decison Tree)分类器是一种基于决策树的通过用损失函数的负梯度在当前模型的值来模拟回归问题中残差的近似值的分类器。
在一些实施例中,所述方法还包括:计算机设备对目标号码关联的目标标注数据进行分词,获得所述目标标注数据对应的目标词数据;将所述目标词数据进行向量化,得到所述目标号码对应的目标向量化特征;将所述目标向量化特征输入所述性别预测模型,得到所述性别预测模型输出的所述目标号码对应的预测性别信息。在一些实施例中,性别预测模型在预测阶段,对于某个待预测性别的联系人号码即目标号码,先获得该目标改号码在一个或多个通讯录中所关联的目标标注数据,再获得该目标标注数据对应的目标向量化特征,具体根据标注数据获得向量化特征的方式如前所述(先分词再向量化),在此不再赘述,然后将该目标向量化特征输入该性别预测模型,该性别预测模型会输出该号码对应的预测性别。
在一些实施例中,对于所述一个或多个向量化特征中的每个向量化特征,根据该向量化特征对应的通讯录用户与该号码之间的通话数据信息,确定该向量化特征对应的学习权重信息;其中,所述步骤S13包括:计算机设备根据所述一个或多个向量化特征、所述学习权重信息及所述每个号码对应的性别标签,基于预定的机器学习分类器进行监督学习,得到性别预测模型。在一些实施例中,对于每个号码,若在目标用户的通讯录中存在该号码对应的目标备注信息,该号码关联的标注数据包括目标备注信息以及其他用户的通讯录中该号码对应的备注信息,对于该号码对应的一个或多个向量化特征中的每个向量化特征,若该向量化特征是通过对该目标备注信息对应的词数据进行向量化得到的,则该向量化特征对应的通讯录用户为该目标用户,可以根据该通讯录用户(即该目标用户)与该号码之间的通话数据信息,来确定该向量化特征对应的学习权重,其中,通话数据信息包括但不限于通话次数信息、通话总时长信息、最近一次通话时间距离当前的时间间隔信息。在一些实施例中,将每个号码对应的性别标准数据作为该号码的监督学习标签即性别标签,基于每个号码对应的一个或多个向量化特征、每个向量化特征对应的学习权重以及该号码的性别标签,基于预定的机器学习分类器进行监督学习,训练得到一个性别预测模型,其中,在监督学习的时候会对不同学习权重的向量化特征进行不同程度的学习,即不同学习权重的向量化特征对应不同的学习率,从而可以使得监督学习更具有针对性。
在一些实施例中,所述通话数据信息包括以下至少一项:通话次数信息;通话总时长信息;最近一次通话时间距离当前的时间间隔信息。在一些实施例中,学习权重与通话次数成正相关,通话次数越多,对应的学习权重越大。在一些实施例中,学习权重与通话总时长成正相关,通话总时长越多,对应的学习权重越大。在一些实施例中,学习权重与最近一次通话时间距离当前的时间间隔成负相关,时间间隔越短,对应的学习权重越大。
图2示出根据本申请一个实施例的一种用于通过通讯录数据进行预测的方法流程图,该方法包括步骤S21、步骤S22和步骤S23。在步骤S21中,计算机设备对目标号码关联的目标标注数据进行分词,获得所述目标标注数据对应的目标词数据;在步骤S22中,计算机设备将所述目标词数据进行向量化,得到所述目标号码对应的目标向量化特征;在步骤S23中,计算机设备将所述目标向量化特征输入性别预测模型,得到所述性别预测模型输出的所述目标号码对应的预测性别信息。
在步骤S21中,计算机设备对目标号码关联的目标标注数据进行分词,获得所述目标标注数据对应的目标词数据。在此,相关操作已在前文予以详述,在此不再赘述。
在步骤S22中,计算机设备将所述目标词数据进行向量化,得到所述目标号码对应的目标向量化特征。在此,相关操作已在前文予以详述,在此不再赘述。
在步骤S23中,计算机设备将所述目标向量化特征输入性别预测模型,得到所述性别预测模型输出的所述目标号码对应的预测性别信息。在此,相关操作已在前文予以详述,在此不再赘述。
在一些实施例中,所述方法还包括:计算机设备根据多个通讯录数据,获得每个号码关联的标注数据,对所述标注数据进行分词,获得所述标注数据对应的词数据;将所述词数据进行向量化,得到所述每个号码对应的一个或多个向量化特征;根据所述一个或多个向量化特征及所述每个号码对应的性别标签,基于预定的机器学习分类器进行监督学习,得到所述性别预测模型。在此,相关操作已在前文予以详述,在此不再赘述。
图3示出根据本申请一个实施例的一种用于通过通讯录数据进行预测的计算机设备结构图,该设备包括一一模块11、一二模块12和一三模块13。一一模块11,用于根据多个通讯录数据,获得每个号码关联的标注数据,对所述标注数据进行分词,获得所述标注数据对应的词数据;一二模块12,用于将所述词数据进行向量化,得到所述每个号码对应的一个或多个向量化特征;一三模块13,用于根据所述一个或多个向量化特征及所述每个号码对应的性别标签,基于预定的机器学习分类器进行监督学习,得到性别预测模型。
一一模块11,用于根据多个通讯录数据,获得每个号码关联的标注数据,对所述标注数据进行分词,获得所述标注数据对应的词数据。在一些实施例中,用户可以在通讯录中对某个联系人号码添加备注(例如,称谓、昵称、职业、名字等),预先收集多个用户的通讯录,将各个通讯录的数据进行整合汇总,对于某个联系人号码,若一个或多个通讯录中存在该联系人号码对应的备注信息,则该联系人号码与该一个或多个通讯录相关联,该联系人号码关联的标注数据包括与该联系人号码相关联的一个或多个通讯录中的该联系人号码对应的备注信息。在一些实施例中,若每个号码关联的标注数据中包括多个备注信息,则该多个备注信息可以使用预定的分隔符(例如,空格、逗号等)拼接在一起。在一些实施例中,对于每个号码关联的标注数据,使用预定的分词算法将该标注数据切分成多个词数据,例如,可以使用jieba分词算法(例如,python版本的jieba分词算法“https://github.com/fxsjy/jieba”)。
一二模块12,用于将所述词数据进行向量化,得到所述每个号码对应的一个或多个向量化特征。在一些实施例中,可以通过预定的嵌入式(embedding)算法将每个人联系人号码对应的词数据进行向量化,用低维稠密的数值向量来表示词数据,得到该联系人号码对应的一个或多个向量化特征,每个向量化特征对应一个词数据,每个向量化特征用于通过一个向量来表示一个词数据,例如,可以使用word2vec嵌入式算法(word2vec是Google公司于2013年发布的一个开源的词向量算法)。
一三模块13,用于根据所述一个或多个向量化特征及所述每个号码对应的性别标签,基于预定的机器学习分类器进行监督学习,得到性别预测模型。在一些实施例中,将每个联系人号码对应的性别标准数据作为该联系人号码的监督学习标签即性别标签,基于每个联系人号码对应的一个或多个向量化特征以及该联系人号码的性别标签,基于预定的机器学习分类器进行监督学习,训练得到一个性别预测模型。在一些实施例中,该机器学习分类器包括但不限于随机森林分类器、梯度提升树分类器等。在一些实施例中,监督学习是指通过让机器学习大量带有标签的样本数据,调整分类器的参数,训练出一个模型,使得该模型可以对新的无标签的数据进行预测或分类的过程。在一些实施例中,性别预测模型用于根据某个号码在一个通讯录中的备注信息或者根据某个号码在一个或多个通讯录中所关联的标注数据,预测得到该号码所对应的用户的性别数据。本申请可以根据通讯录主相对客观的用户号码标注信息,通过嵌入向量化方式,得到每个被标注号码的向量化特征,将向量化特征输入到性别预测模型,即可对被标注号码进行性别预测,可以明显提高性别预测的覆盖度与准确率,且由于不用管具体的标注内容,不需要对标注内容进行理解,该方法可以扩展应用到任何外文。
在一些实施例中,所述对所述标注数据进行分词,获得所述标注数据对应的词数据,包括:对所述标注数据进行分词,去除分词结果中的无意义词,获得所述标注数据对应的词数据。在此,相关操作与图1所示实施例相同或相近,故不再赘述,在此以引用方式包含于此。
在一些实施例中,所述对所述标注数据进行分词,去除分词结果中的无意义词,获得所述标注数据对应的词数据,包括:对所述标注数据进行分词,去除分词结果中的无意义词,并将分词结果中出现次数大于或等于预定次数阈值的一个或多个分词作为所述标注数据对应的词数据。在此,相关操作与图1所示实施例相同或相近,故不再赘述,在此以引用方式包含于此。
在一些实施例中,所述一二模块12用于:将所述词数据输入已训练的词向量模型,得到所述词向量模型输出的所述每个号码对应的一个或多个向量化特征。在此,相关操作与图1所示实施例相同或相近,故不再赘述,在此以引用方式包含于此。
在一些实施例中,所述设备还用于:设置词向量模型对应的训练参数;根据多个号码分别关联的标注数据对所述量模型进行训练,得到已训练的词向量模型。在此,相关操作与图1所示实施例相同或相近,故不再赘述,在此以引用方式包含于此。
在一些实施例中,所述训练参数包括以下至少一项:向量化维度数;最少词频。在此,相关操作与图1所示实施例相同或相近,故不再赘述,在此以引用方式包含于此。
在一些实施例中,所述机器学习分类器包括以下任一项:随机森林分类器;梯度提升树分类器。在此,相关操作与图1所示实施例相同或相近,故不再赘述,在此以引用方式包含于此。
在一些实施例中,所述设备还用于:对目标号码关联的目标标注数据进行分词,获得所述目标标注数据对应的目标词数据;将所述目标词数据进行向量化,得到所述目标号码对应的目标向量化特征;将所述目标向量化特征输入所述性别预测模型,得到所述性别预测模型输出的所述目标号码对应的预测性别信息。在此,相关操作与图1所示实施例相同或相近,故不再赘述,在此以引用方式包含于此。
在一些实施例中,对于所述一个或多个向量化特征中的每个向量化特征,根据该向量化特征对应的通讯录用户与该号码之间的通话数据信息,确定该向量化特征对应的学习权重信息;其中,所述一三模块13用于:根据所述一个或多个向量化特征、所述学习权重信息及所述每个号码对应的性别标签,基于预定的机器学习分类器进行监督学习,得到性别预测模型。在此,相关操作与图1所示实施例相同或相近,故不再赘述,在此以引用方式包含于此。
在一些实施例中,所述通话数据信息包括以下至少一项:通话次数信息;通话总时长信息;最近一次通话时间距离当前的时间间隔信息。在此,相关操作与图1所示实施例相同或相近,故不再赘述,在此以引用方式包含于此。
图4示出根据本申请一个实施例的一种用于通过通讯录数据进行预测的计算机设备结构图,该设备包括二一模块21、二二模块22和二三模块23。二一模块21,用于对目标号码关联的目标标注数据进行分词,获得所述目标标注数据对应的目标词数据;二二模块22,用于将所述目标词数据进行向量化,得到所述目标号码对应的目标向量化特征;二三模块23,用于将所述目标向量化特征输入性别预测模型,得到所述性别预测模型输出的所述目标号码对应的预测性别信息。
二一模块21,用于对目标号码关联的目标标注数据进行分词,获得所述目标标注数据对应的目标词数据。在此,相关操作已在前文予以详述,在此不再赘述。
二二模块22,用于将所述目标词数据进行向量化,得到所述目标号码对应的目标向量化特征。在此,相关操作已在前文予以详述,在此不再赘述。
二三模块23,用于将所述目标向量化特征输入性别预测模型,得到所述性别预测模型输出的所述目标号码对应的预测性别信息。在此,相关操作已在前文予以详述,在此不再赘述。
在一些实施例中,所述设备还用于:根据多个通讯录数据,获得每个号码关联的标注数据,对所述标注数据进行分词,获得所述标注数据对应的词数据;将所述词数据进行向量化,得到所述每个号码对应的一个或多个向量化特征;根据所述一个或多个向量化特征及所述每个号码对应的性别标签,基于预定的机器学习分类器进行监督学习,得到所述性别预测模型。在此,相关操作已在前文予以详述,在此不再赘述。
除上述各实施例介绍的方法和设备外,本申请还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机代码,当所述计算机代码被执行时,如前任一项所述的方法被执行。
本申请还提供了一种计算机程序产品,当所述计算机程序产品被计算机设备执行时,如前任一项所述的方法被执行。
本申请还提供了一种计算机设备,所述计算机设备包括:
一个或多个处理器;
存储器,用于存储一个或多个计算机程序;
当所述一个或多个计算机程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现如前任一项所述的方法。
图5示出了可被用于实施本申请中所述的各个实施例的示例性系统;
如图5所示在一些实施例中,系统300能够作为各所述实施例中的任意一个设备。在一些实施例中,系统300可包括具有指令的一个或多个计算机可读介质(例如,系统存储器或NVM/存储设备320)以及与该一个或多个计算机可读介质耦合并被配置为执行指令以实现模块从而执行本申请中所述的动作的一个或多个处理器(例如,(一个或多个)处理器305)。
对于一个实施例,系统控制模块310可包括任意适当的接口控制器,以向(一个或多个)处理器305中的至少一个和/或与系统控制模块310通信的任意适当的设备或组件提供任意适当的接口。
系统控制模块310可包括存储器控制器模块330,以向系统存储器315提供接口。存储器控制器模块330可以是硬件模块、软件模块和/或固件模块。
系统存储器315可被用于例如为系统300加载和存储数据和/或指令。对于一个实施例,系统存储器315可包括任意适当的易失性存储器,例如,适当的DRAM。在一些实施例中,系统存储器315可包括双倍数据速率类型四同步动态随机存取存储器(DDR4SDRAM)。
对于一个实施例,系统控制模块310可包括一个或多个输入/输出(I/O)控制器,以向NVM/存储设备320及(一个或多个)通信接口325提供接口。
例如,NVM/存储设备320可被用于存储数据和/或指令。NVM/存储设备320可包括任意适当的非易失性存储器(例如,闪存)和/或可包括任意适当的(一个或多个)非易失性存储设备(例如,一个或多个硬盘驱动器(HDD)、一个或多个光盘(CD)驱动器和/或一个或多个数字通用光盘(DVD)驱动器)。
NVM/存储设备320可包括在物理上作为系统300被安装在其上的设备的一部分的存储资源,或者其可被该设备访问而不必作为该设备的一部分。例如,NVM/存储设备320可通过网络经由(一个或多个)通信接口325进行访问。
(一个或多个)通信接口325可为系统300提供接口以通过一个或多个网络和/或与任意其他适当的设备通信。系统300可根据一个或多个无线网络标准和/或协议中的任意标准和/或协议来与无线网络的一个或多个组件进行无线通信。
对于一个实施例,(一个或多个)处理器305中的至少一个可与系统控制模块310的一个或多个控制器(例如,存储器控制器模块330)的逻辑封装在一起。对于一个实施例,(一个或多个)处理器305中的至少一个可与系统控制模块310的一个或多个控制器的逻辑封装在一起以形成系统级封装(SiP)。对于一个实施例,(一个或多个)处理器305中的至少一个可与系统控制模块310的一个或多个控制器的逻辑集成在同一模具上。对于一个实施例,(一个或多个)处理器305中的至少一个可与系统控制模块310的一个或多个控制器的逻辑集成在同一模具上以形成片上系统(SoC)。
在各个实施例中,系统300可以但不限于是:服务器、工作站、台式计算设备或移动计算设备(例如,膝上型计算设备、手持计算设备、平板电脑、上网本等)。在各个实施例中,系统300可具有更多或更少的组件和/或不同的架构。例如,在一些实施例中,系统300包括一个或多个摄像机、键盘、液晶显示器(LCD)屏幕(包括触屏显示器)、非易失性存储器端口、多个天线、图形芯片、专用集成电路(ASIC)和扬声器。
需要注意的是,本申请可在软件和/或软件与硬件的组合体中被实施,例如,可采用专用集成电路(ASIC)、通用目的计算机或任何其他类似硬件设备来实现。在一个实施例中,本申请的软件程序可以通过处理器执行以实现上文所述步骤或功能。同样地,本申请的软件程序(包括相关的数据结构)可以被存储到计算机可读记录介质中,例如,RAM存储器,磁或光驱动器或软磁盘及类似设备。另外,本申请的一些步骤或功能可采用硬件来实现,例如,作为与处理器配合从而执行各个步骤或功能的电路。
另外,本申请的一部分可被应用为计算机程序产品,例如计算机程序指令,当其被计算机执行时,通过该计算机的操作,可以调用或提供根据本申请的方法和/或技术方案。本领域技术人员应能理解,计算机程序指令在计算机可读介质中的存在形式包括但不限于源文件、可执行文件、安装包文件等,相应地,计算机程序指令被计算机执行的方式包括但不限于:该计算机直接执行该指令,或者该计算机编译该指令后再执行对应的编译后程序,或者该计算机读取并执行该指令,或者该计算机读取并安装该指令后再执行对应的安装后程序。在此,计算机可读介质可以是可供计算机访问的任意可用的计算机可读存储介质或通信介质。
通信介质包括藉此包含例如计算机可读指令、数据结构、程序模块或其他数据的通信信号被从一个系统传送到另一系统的介质。通信介质可包括有导的传输介质(诸如电缆和线(例如,光纤、同轴等))和能传播能量波的无线(未有导的传输)介质,诸如声音、电磁、RF、微波和红外。计算机可读指令、数据结构、程序模块或其他数据可被体现为例如无线介质(诸如载波或诸如被体现为扩展频谱技术的一部分的类似机制)中的已调制数据信号。术语“已调制数据信号”指的是其一个或多个特征以在信号中编码信息的方式被更改或设定的信号。调制可以是模拟的、数字的或混合调制技术。
作为示例而非限制,计算机可读存储介质可包括以用于存储诸如计算机可读指令、数据结构、程序模块或其它数据的信息的任何方法或技术实现的易失性和非易失性、可移动和不可移动的介质。例如,计算机可读存储介质包括,但不限于,易失性存储器,诸如随机存储器(RAM,DRAM,SRAM);以及非易失性存储器,诸如闪存、各种只读存储器(ROM,PROM,EPROM,EEPROM)、磁性和铁磁/铁电存储器(MRAM,FeRAM);以及磁性和光学存储设备(硬盘、磁带、CD、DVD);或其它现在已知的介质或今后开发的能够存储供计算机系统使用的计算机可读信息/数据。
在此,根据本申请的一个实施例包括一个装置,该装置包括用于存储计算机程序指令的存储器和用于执行程序指令的处理器,其中,当该计算机程序指令被该处理器执行时,触发该装置运行基于前述根据本申请的多个实施例的方法和/或技术方案。
对于本领域技术人员而言,显然本申请不限于上述示范性实施例的细节,而且在不背离本申请的精神或基本特征的情况下,能够以其他的具体形式实现本申请。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本申请的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化涵括在本申请内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。此外,显然“包括”一词不排除其他单元或步骤,单数不排除复数。装置权利要求中陈述的多个单元或装置也可以由一个单元或装置通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。