一种基于lambdaMart的神经协同过滤模型推荐方法
文献发布时间:2023-06-19 09:38:30
技术领域
本发明涉及个性化推荐技术领域,尤其涉及一种基于lambdaMart的神经协同过滤模型推荐方法。
背景技术
随着科学技术的发展,网上数据也越来越多,使得用户在面对庞大的信息超载时无法获得真正有用的信息,对信息的使用效率大大降低,个性化推荐是解决信息超载的有效方法,通过该方法进行推荐可以更好的把握用户的观影习惯,为用户提供优质的电影推荐。
目前实现电影推荐采用的方法有:基于inception结构的神经网络协同过滤推荐算法、基于深度学习的混合推荐模型、基于噪声检测修正和神经网络的稀疏数据推荐算法和融合注意力和记忆网络的序列推荐算法。
其中基于inception结构的神经网络协同过滤推荐算法,充分利用商品评论信息,提高商品推荐系统精度,对NCF神经网络协同过滤模型进行改进,模型与Inception结构的卷积神经网络相结合,将商品评论信息融入模型进行预测和推荐。该项技术得不足之处是,推荐系统使用NCF-i模型进行离线训练会得到更优秀的推荐结果,但是由于使用神经网络的计算比较复杂,当用户和商品规模巨大时,会消耗大量的资源以及时间,因此无法将模型应用于实时在线推荐。
基于深度学习的混合推荐模型,针对传统的矩阵分解算法,仅利用评分信息作为推荐依据,当评分数据稀疏时,不能准确获取隐式反馈,影响推荐的准确性,充分利用辅助信息进行隐式特征的提取成为研究热点之一,提出一种基于深度学习的推荐模型HRS-DC,利用深度神经网络和卷积神经网络从辅助信息中分别提取出用户和项目的隐性特征向量,再将特征向量经过改进的神经协同过滤得出新的评分矩阵。该项技术的不足之处是NCF的网络层数,隐因子的维度等参数还没有找到最佳值,只是找到相对比较优化的值,对预测的准确性还有待提高,在稀疏性和冷启动问题上还有待提高。
基于噪声检测修正和神经网络的稀疏数据推荐算法,将用户和项目按评分分别分类为高分类、中等类和低分类,根据分类结果检测评分矩阵的奇异点,对奇异点做简单地修正处理。建立基于兴趣关系的受限玻尔兹曼机模型,将用户对项目的兴趣关系以及项目的次级信息作为条件受限玻尔兹曼机的输入,预测目标用户的top-k推荐列表。该项技术的不足之处是受限RBM的训练过程较为复杂,并且需要微调超参数,因此无法适用于动态的大数据推荐应用,例如:新闻推荐、股票推荐等实时数据流场景。需要引入参数较少的神经网络模型,并且研究神经网络的增量,技术提高推荐算法的实时性。
融合注意力和记忆网络的序列推荐算法,根据Word2vec算法,引申item2vec和user2vec,初始化用户和项目的固定表示嵌入矩阵,通过结合注意力机制和长短期记忆网络(LongShort-TermMemory,LSTM)解决序列之间的长距离依赖性差和区分度差问题。利用记忆网络获取用户的动态邻居,加强用户的动态表示,实现更准确的推荐。该技术的不足之处是在使用i-tem2vec学习项目向量表示时,少数项目不在训练集中,即冷启动项目,对于没有标签的项目,还需进一步处理才能适用,现实生活中存在大量冷项目,以及RNN的输入序列是在时间轴上位置相邻,没有考虑两项目之间时间间隔的影响。
发明内容
鉴以此,本发明的目的在于提供一种基于lambdaMart的神经协同过滤模型推荐方法,以解决现有的电影推荐方法所存在的上述问题。
一种基于lambdaMart的神经协同过滤模型推荐方法,所述方法包括以下步骤:
S1:输入用户信息,所述用户信息包括用户基本信息和电影评论信息,所述电影评论信息包括已评分电影信息和未评分电影信息;
S2:嵌入层将用户信息映射为用户特征向量,将电影评论信息映射为电影特征向量;
S3:将用户特征向量、电影特征向量输入到神经协同过滤模型中,提取高阶特征信息,同时提取排序信息;
S4:对高阶特征信息和排序信息进行处理获得推荐结果并输出。
进一步的,所述用户基本信息包括年龄、性别、职业、邮编,所述已评分电影信息和未评分电影信息均包括电影名、电影ID、上映日期、电影类型信息。
进一步的,所述步骤S2具体包括:
S21:对用户基本信息和电影评论信息中的用户ID进行提取并且映射为用户特征向量;
S22:对已评分的电影信息和未评分的中的电影ID进行提取并且映射为电影特征向量。
在本发明的其中一个实施例中,所述步骤S2、嵌入层将用户信息(Uid)映射为用户特征向量,将电影评论信息映射为电影特征向量,具体还包括:
输入层上面是嵌入层,它是一个全连接层用于将数据映射为特征向量。其中用户ID(Uid)映射为用户特征向量,用户已经评分的电影ID(Pid)和用户没有评分的电影ID(Nid)映射为电影特征向量。Uid,Pid与Nid都分别经过LMart嵌入层和MLP嵌入层映射为向量,然后后缀为Emb的向量去BPR层,后缀为MLP的向量去MLP层,分别命名为Uid_MLP,Uid_Emb,Pid_MLP,Pid_Emb,Nid_MLP,Nid_Emb。
在神经协同过滤模型的多层感知机层基础上,增加了批标准化(batchnormalization,BN)层与丢弃(Dropout)层,其中,BN层统一各层的方差加快模型的收敛速度,Dropout层提高泛化性防止过拟合。
进一步的,所述步骤S3中提取隐含高阶特征信息,具体包括:
S31:将用户特征向量、已评分电影信息和未评分电影信息特征向量拼接成新的向量;
S32:将上一步骤拼接获得的向量输入神经协同过滤模型的MLP层计算高阶特征信息
其中,P∈R
进一步的,所述步骤S3中提取排序信息,具体包括:
S33:假设任意用户u在电影p与n同时存在的情况下选择了电影p,认为p排序在n前面,如此记录此三元组(u,p,n),所有(u,p,n)组合的集合表示为D,>u代表用户u对应的所有商品的全序关系,优化目标是最大化后验概率p(θ|>u),最终的最大对数后验估计函数公式为:
其中,
S34:通过将
进一步的,所述步骤S4中对高阶特征信息和排序信息进行处理获得推荐结果并输出,具体包括:
S41:来自LMart层的排序信息和MLP层的特征信息拼接形成新的向量,加权输出,通过sigmoid激活函数对输出结果进行处理得到预测值0或者1,预测值表达式为:
其中h
通过减小预测值与真实属性值的交叉熵来迭代更新模型参数,更新模型参数表达式为:
其中,y
与现有技术相比,本发明的有益效果是:
本发明提供一种基于lambdaMart的神经协同过滤模型推荐方法。提出LMart-NCF模型,通过改进神经协同过滤模型,利用多层感知机的非线性特征处理提取高阶特征信息以及lambdaMart个性化排序算法提取排序信息,使推荐更加精准,从电影推荐实际应用来看,基于神经协同过滤模型的LMart-NCF模型,提高了挖掘信息的深度,提升了信息来源的广度。在推荐过程中,提高了推荐的命中率和准确率,而且只增加了极少的计算资源,没有过多的提高时间复杂度。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的优选实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
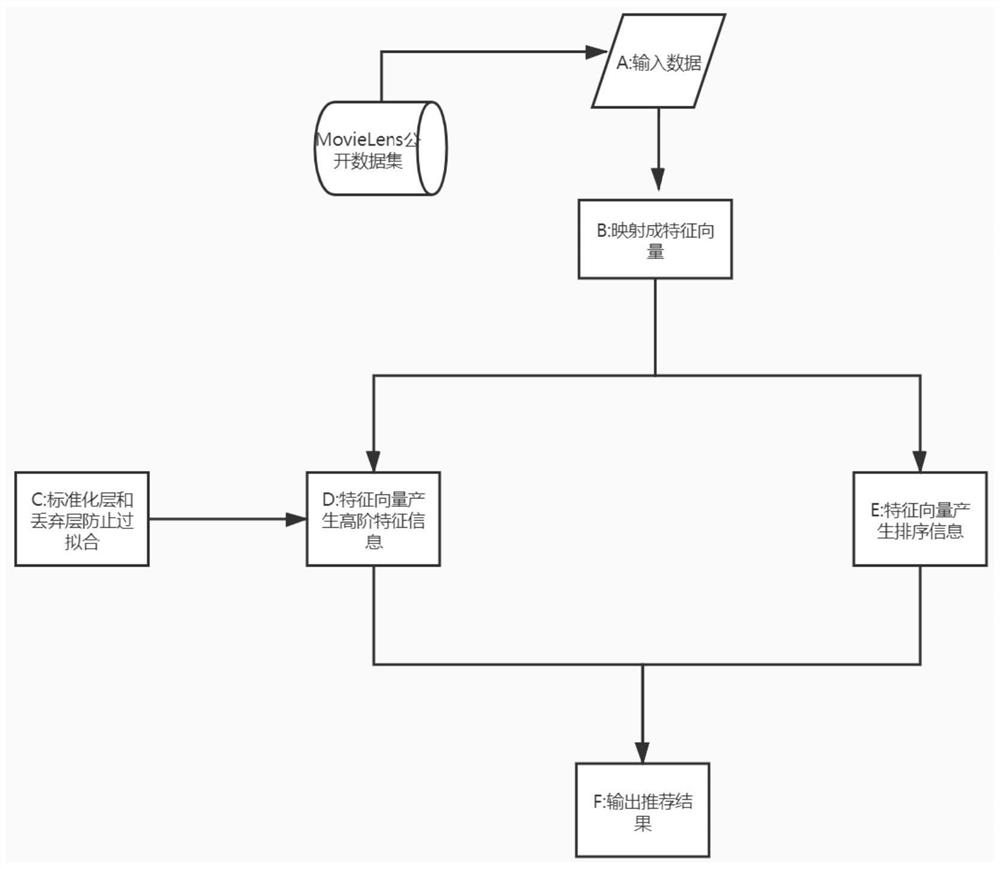
图1是本发明实施例提供的一种基于lambdaMart的神经协同过滤模型推荐方法整体结构流程图。
图2是本发明实施例提供的一种基于lambdaMart的神经协同过滤模型推荐方法LMart-NCF模型流程图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所列举实施例只用于解释本发明,并非用于限定本发明的范围。
参照图1和图2,本发明提供一种基于lambdaMart的神经协同过滤模型推荐方法,所述方法包括以下步骤:
S1:输入用户信息,所述用户信息包括用户基本信息和电影评论信息,所述电影评论信息包括已评分电影信息和未评分电影信息;
S2:嵌入层将用户信息映射为用户特征向量,将电影评论信息映射为电影特征向量;
S3:将用户特征向量、电影特征向量输入到神经协同过滤模型中,提取高阶特征信息,同时提取排序信息;
S4:对高阶特征信息和排序信息进行处理获得推荐结果并输出。
所述用户基本信息包括年龄、性别、职业、邮编,所述已评分电影信息和未评分电影信息均包括电影名、电影ID、上映日期、电影类型信息。
所述步骤S2具体包括:
S21:对用户基本信息和电影评论信息中的用户ID进行提取并且映射为用户特征向量;
S22:对已评分的电影信息和未评分的中的电影ID进行提取并且映射为电影特征向量。
所述步骤S3中提取隐含高阶特征信息,具体包括:
S31:将用户特征向量、已评分电影信息和未评分电影信息特征向量拼接成新的向量;
S32:将上一步骤拼接获得的向量输入神经协同过滤模型的MLP层计算高阶特征信息
其中,P∈R
所述步骤S3中提取排序信息,具体包括:
S33:假设任意用户u在电影p与u同时存在的情况下选择了电影p,认为p排序在n前面,如此记录此三元组(u,p,n),所有(u,p,n)组合的集合表示为D,>u代表用户u对应的所有商品的全序关系,优化目标是最大化后验概率p(θ|>u),最终的最大对数后验估计函数公式为:
其中,
S34:通过将
所述步骤S4中对高阶特征信息和排序信息进行处理获得推荐结果并输出,具体包括:
S41:来自LMart层的排序信息和MLP层的特征信息拼接形成新的向量,加权输出,通过sigmoid激活函数对输出结果进行处理得到预测值0或者1,预测值表达式为:
其中h
通过减小预测值与真实属性值的交叉熵来迭代更新模型参数,更新模型参数表达式为:
其中,y
进一步的技术方案,S1输入用户信息(Uid):MovieLens-100k,数据集里面包括u.data、u.info、u.item、u.genre、u.user、u.occupation等文件,其中u.data文件包含943个用户对于1682部电影的100000个评分(分值为[1,5]之间的整数),部分数据如表1所示;每个用户至少评级20部电影;u.user文件包含用户的人口统计信息(年龄,性别,职业,邮编),部分数据如表2所示;u.item文件包括电影名,电影ID,上映日期,IMDB电影网对应电影主页网址,所属的电影类型(恐怖,犯罪,喜剧等),部分数据如表3所示。
表1u.data
表2 u.user
表3 u.item
作为一个示例,在将上述实施例所提供的方法应用到电影推荐系统中时,其具体实现步骤包括:
输入:3组数据Uid、Pid和Nid,学习率α,正则项系数λ,隐空间的维度K。
输出:用户LMart嵌入层权重矩阵W,电影LMart嵌入层权重矩阵H。
(1)初始化所有嵌入层权重。
(2)在LMart层,Uid_Emb*Pid_Emb与Uid_Emb*Nid_Emb作差,由sigmoid激活函数变换得到[0.1]值再与1做差,差值作为排序信息LMartloss。LMart层输出排序信息与MLP层信息拼接成新的向量。
(3)新向量通过sigmoid激活函数转为取值在[0,1]的预测值,同时把评分表中任意用户的大于或等于4分的电影属性值设为1其余电影属性值设为0,通过减小预测值(modelprediction)与真实属性值(target)的交叉熵来迭代更新模型参数。如果损失函数收敛,则模型训练结束,输出W和H,否则回到步骤(2)。
(4)迭代更新完成后,就可以根据LMart嵌入层权重计算出任意用户u对任意一部电影的排序得分。
- 一种基于lambdaMart的神经协同过滤模型推荐方法
- 一种基于协同过滤模型的混合神经网络推荐系统