一种车型视觉识别方法、系统、设备及存储介质
文献发布时间:2023-06-19 18:35:48
技术领域
本发明涉及车辆的检测与识别相关技术领域,尤其是涉及一种车型视觉识别方法、系统、设备及存储介质。
背景技术
随着我国经济持续发展的背景下,机动车不断的增长,全球汽车保有量急剧增加,交通拥堵现象也日渐严重。
智能交通系统应用计算机信息技术、数据通讯传输技术、控制技术等多种先进技术,将交通设备、驾驶员和车辆等因素有效联系在一起,能进行实时、准确、高效的交通运输系统管理,减少交通瘫痪。在智能交通系统中,车辆的检测与识别技术是重要组成部分。利用监控系统对道路中的车流量数据进行车辆的检测定位与车型的识别,能够了解当前车辆的通过和存在的交通情况,对于交通异常的信息流如拥堵、占用车道等进行实时监测,以便对交通进行最优的掌握和控制。
传统的目标检测与识别算法采用手工提取特征和分类器组合的方式,首先从图片场景中利用滑动窗口选取候选区,再对候选区进行识别特征提取,最后通过分类器获取准确的目标区域,其短板在于操作复杂、检测速度慢、识别效率低。2006年Hinton等人在机器学习(Machine Learning)基础上提出新的领域深度学习(Deep Learming),具有图像处理、语音识别以及自然语言学习等能力。此外,GPU芯片作为硬件加速器的飞速进步,加速了深度学习技术在新领域的发展步伐。但在实际应用过程中,由于目标运动车辆的尺度变化、多角度、光照强度不一、复杂背景等环境复杂多变,给车辆检测与车型识别带来了很大的影响。
发明内容
本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种车型视觉识别方法,能够提高车型识别的准确率。
本发明还提供用于执行上述车型视觉识别方法的系统、设备以及存储介质。
根据本发明的第一方面实施例的一种车型视觉识别方法,所述车型视觉识别方法包括:
获取多种车型图片;
对所述多种车型图片进行标注,生成图片数据集,并从所述图片数据集随机提取图片训练集;
采用Tiny-YOLOv3网络构建车型识别模型,通过所述图片训练集训练所述车型识别模型,得到训练完成的所述车型识别模型;
通过所述训练完成的所述车型识别模型对待识别图片中的车型进行识别。
根据本发明实施例的车型视觉识别方法,至少具有如下有益效果:
本方法针对车型识别精度不高、实时性差、识别有误问题,利用基于Yolov3简化后的Tiny-Yolov3构建车型识别模型,Tiny-Yolov3引入了FPN架构融合多尺度特征图信息来加强对小目标物体的检测,将深层特征与浅层特征相融合,从多个不同尺度的特征图提取图像特征作为网络输入来进行多尺度预测,从而提高识别的准确率;也利用残差网络增加网络的深度和降低网络参数计算量,保护在卷积过程中信息的完整性来提高准确率。而且,相较于Yolov3,本方法使用Tiny-Yolov3减少网络中参数量和计算量,提升了车辆识别精度及检测速度。
根据本申请的一些实施例,所述通过所述图片训练集训练所述车型识别模型时,根据图片标注的标签数据对先验框进行尺寸的修改。
根据本申请的一些实施例,所述Tiny-YOLOv3网络的输出层采用金字塔网络进行多尺度融合。
根据本申请的一些实施例,所述Tiny-YOLOv3网络的主干网络的池化层通过卷积层进行替换,其中用于替换所述池化层的所述卷积层的卷积核为3*3/2,步长为2*2。
根据本申请的一些实施例,通过K-means聚类线性尺度的缩放方式产生先验框,且为尺寸越小的特征图分配越大的先验框。
根据本申请的一些实施例,在所述得到训练完成的所述车型识别模型之后,所述车型视觉识别方法还包括:从所述图片数据集随机提取图片测试集,通过所述图片测试集对所述训练完成的所述车型识别模型进行测试,并在测试时,为所述图片测试集的测试图片添加置信度。
根据本申请的一些实施例,所述对所述多种车型图片进行标注包括:
对所述多种车型图片进行有序重命名;
通过LabelImg对有序重命名后的所述多种车型图片进行标注。
根据本发明的第二方面实施例的一种车型视觉识别系统,所述车型视觉识别系统包括:
图片获取单元,用于获取多种车型图片;
训练集生成单元,用于对所述多种车型图片进行标注,生成图片数据集,并从所述图片数据集随机提取图片训练集;
模型训练单元,用于采用Tiny-YOLOv3网络构建车型识别模型,通过所述图片训练集训练所述车型识别模型,得到训练完成的所述车型识别模型;
车型识别单元,用于通过所述训练完成的所述车型识别模型对待识别图片中的车型进行识别。由于车型视觉识别系统采用了上述实施例的车型视觉识别方法的全部技术方案,因此至少具有上述实施例的技术方案所带来的所有有益效果。
根据本发明的第三方面实施例的电子设备,包括至少一个控制处理器和用于与所述至少一个控制处理器通信连接的存储器;所述存储器存储有可被所述至少一个控制处理器执行的指令,所述指令被所述至少一个控制处理器执行,以使所述至少一个控制处理器能够执行如上述的车型视觉识别方法。由于电子设备采用了上述实施例的车型视觉识别方法的全部技术方案,因此至少具有上述实施例的技术方案所带来的所有有益效果。
根据本发明的第四方面实施例的计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行指令,所述计算机可执行指令用于使计算机执行如上述的车型视觉识别方法。由于计算机可读存储介质采用了上述实施例的车型视觉识别方法的全部技术方案,因此至少具有上述实施例的技术方案所带来的所有有益效果。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1是本发明一实施例提供的YOLOv3残差连接块的示意图;
图2是本发明一实施例提供的YOLOv3的网络结构示意图;
图3是本发明一实施例提供的一种车型视觉识别方法的流程示意图;
图4是本发明一实施例提供的Tiny-YOLOv3主干网络的示意图;
图5是本发明一实施例提供的Yolov3-tiny.cfg的部分文件的示意图;
图6是本发明一实施例提供的Tiny-Yolov3的结构示意图;
图7是本发明一实施例提供的检测效果图;
图8是本发明一实施例提供的修改函数的image.c文件示意图;
图9是本发明一实施例提供的cfg文件示意图;
图10是本发明一实施例提供的单张图片车型识别准确率示意图;
图11是本发明一实施例提供的各类车型的AP值与平均的mAP值;
图12是本发明另一实施例提供的单张图片车型识别准确率示意图;
图13是本发明另一实施例提供的各类车型的AP值与平均的mAP值;
图14是本发明另外一实施例提供的IOU与loss值的示意图;
图15是本发明另外一实施例提供的单张图片车型识别准确率示意图;
图16是本发明另外一实施例提供的各类车型的AP值与平均的mAP值;
图17是本发明一实施例提供的一种车型视觉识别系统的结构示意图;
图18是本发明一实施例提供的一种电子设备的结构示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
在本发明的描述中,如果有描述到第一、第二等只是用于区分技术特征为目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量或者隐含指明所指示的技术特征的先后关系。
在本发明的描述中,需要理解的是,涉及到方位描述,例如上、下等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
本发明的描述中,需要说明的是,除非另有明确的限定,设置、安装、连接等词语应做广义理解,所属技术领域技术人员可以结合技术方案的具体内容合理确定上述词语在本发明中的具体含义。
基于深度学习的目标检测算法主要分为基于Two-Stage和基于One-Stage的目标检测算法。
基于Two-Stage的算法基本流程包括:首先提取候选检测框区域,然后使用卷积神经网络(是一类包含深度结构且卷积运算的前馈神经网络,主要组成结构有卷积层、池化层、激活层和全连接层,通过多次迭代卷积、池化操作形成更深层次的网络结构)提取候选检测框的深度特征,最后对候选区域分类。基于Two-Stage的目标检测算法主要有RCNN,SPPNet,Fast RCNN,Faster RCN和Mask RCNN算法。
One-Stage目标检测算法直接提取输入图像的特征,不用提取候选区域,直接回归物体的类别概率和位置坐标值。基于One-Stage的目标检测算法主要有YOLOv1,YOLOv2,YOLOv3,SSD和DSSD算法。One-Stage目标检测算法速度更快,对物体的泛化特征能力强。
YOLOv3网络主要由一系列的1X1和3X3的卷积层组成,因为网络中总共有53层convolutional layers,被称为Darknet-53。同时引入了残差连接算法,加深了网络层次。残差连接块如图1所示。YOLOv3的网络结构图如图2所示,与其他网络结构相比,Darknet-53实现了每秒最高的浮点数计算量。YOLOv3网络算法采用回归的思想来预测图像的类别,但是其存在着实时性能差、对硬件要求高的缺陷。
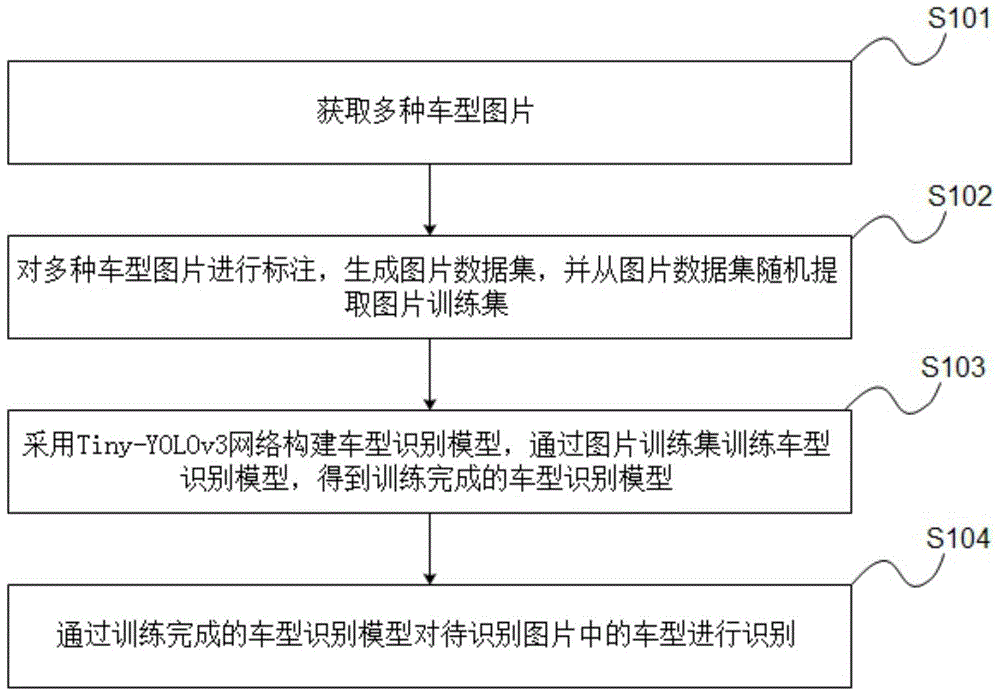
为了解决上述技术缺陷,参照图3,本申请的一个实施例,提供了一种车型视觉识别方法,本车型视觉识别方法包括如下步骤S101至S104,其中:
步骤S101、获取多种车型图片。
在本步骤S101中,可以通过相机拍摄图片,也可以在网络上收集图片。例如,收集16108张彩色图片,共4类车型:轿车、卡车、大巴车以及摩托车(car、truck、bus、motorcycle),各类别车型有4027张彩色图片。
步骤S102、对多种车型图片进行标注,生成图片数据集,并从图片数据集随机提取图片训练集。
目前,用于对深度网络训练的图片数据做标注的工具有很多,像LabelImg、Sloth、Vatic等,本实施例选用LabelImg软件对数据集进行打标签,速度快、操作方便。标注前先通过代码对图片进行有序重命名,如:0001、0002;然后进行标注,生成图片数据集。图片数据集可划分为用于训练模型的训练集和用于验证模型的验证集。
步骤S103、采用Tiny-YOLOv3网络构建车型识别模型,通过图片训练集训练车型识别模型,得到训练完成的车型识别模型。
在本实施例中,选用Darknet框架,采用基于YOLOv3网络简化后的Tiny-YOLOv3网络构建本车型识别模型。YOLOv3网络吸收了以往YOLOv1和YOLOv2网络的优点,比YOLOv1和YOLOv2检测精度更高,但是它在硬件性能比较差的终端检测时间还是比较长。
Tiny-YOLOv3是YOLOv3的简化网络,Tiny-YOLOv3的主干网络是7层的网络,只使用两个Yolo层进行多尺度检测。在终端设备(如计算机)上使用下面的命令可以把Tiny-Yolov3网络结构打印:
sudo./darknetdetectortraincfg/voc.datacfg/yolov3-tiny.cfgyolov3-tiny.conv.15。
Tiny-YOLOv3主干网络如图4所示,其中,filters是输出特征图的数量,size是卷积核的大小,input输入图片的尺寸,output输出图片尺寸。
YOLOv3有9个先验框,而Tiny-YOLOv3只有6个先验框,分别为(10,14),(23,27),(37,58),(81,82),(13,169),(344,319)。和YOLOv3网络一样,尺寸最小的特征图分配最大的先验框。13X13的特征图应用最大的先验框(81,82),(13,169),(344,319),26X26的特征图应用最小的先验框(10,14),(23,27),(37,58)。
如图5所示的Yolov3-tiny.cfg的部分文件,根据数据的类别数在出现yolo关键字修改filters和classes,整个文件共有两处;同时根据自己打标签数据对anchors(anchors是指在训练之前人为设定的先验框,网络输出结果的框是在anchors的基础上进行调整得到)进行修改属于自己的anchors尺寸。通过修改cfg文件里面的参数,包括设定网络的宽、高或者改变random的值为1进行多尺度训练,能够更均匀的获取大小车型的细节特征;改变迭代次数和学习率,能够找到用更短的时间就能训练出好的模型;改变卷积网络或者加入其他网络层加深网络层优化网络提高训练效果。
在本申请的一些实施例中,Tiny-YOLOv3网络的输出层采用金字塔网络进行多尺度融合。采用金字塔网络进行多尺度融合来提高对小目标的识别精度(包括将输入图片进行尺寸的修改)。利用高层具有强的语义信息和底层包含细粒度特征信息进行相融合,从而使得网络能对不同尺寸类型的车型获取全局信息,减少对小型车检测与识别信息损失,提升识别的准确度。
在本申请的一些实施例中,Tiny-YOLOv3网络的主干网络的池化层通过卷积层进行替换,其中用于替换池化层的卷积层的卷积核为3*3/2,步长为2*2。加深Tiny-Yolov3的主干网络层来提高更高层的语义信息。
Tiny-Yolov3的结构图如图6所示,第一个route层之前是一个完整的检测结构,route层就是获取相应层的输出,然后对这些输出的特征进行想要的处理;第二个route层就是进行多尺度融合:concat了两个尺度大小相同的特征。
在本申请的一些实施例中,由于本次车型识别中车型大小不一,数据集中既有大的车型也有小的车型,用原本的anchors锚框大小差不多,尺度集中,效果并不好,预测框得分很低,且容易对小的车型产生漏检情况。为了提高训练过程中预测框对大小车型特征的抓取能力,使用K-means聚类线性尺度的缩放方式产生anchors,产生的anchors中的锚框尺度大小都有,体现了多尺度输出的优势。如在darknet根目录下新建anchors.py文件产生新的数据集anchors锚框。
新建完anchors.py文件,在PyCharm编译软件进行编译,结果在neuron_anchors1.txt文件中,再进行模型训练时,发现效果有明显的提升。如图7所示:
在本申请的一些实施例中,当车型识别模型训练完成之后,对训练完成的车型识别模型进行测试,在测试过程中为了能直观看出训练效果,对Tiny-Yolov3的环境进行修改。在image.c文件片段中进行函数的修改,使得在测试图片时添加置信度,表示框出的box内确实有物体与box内将整个物体的所有特征的占比概率。如图8所示:
步骤S104、通过训练完成的车型识别模型对待识别图片中的车型进行识别。
本方法针对车型识别精度不高、实时性差、识别有误问题,利用基于Yolov3简化后的Tiny-Yolov3构建车型识别模型,Tiny-Yolov3引入了FPN架构融合多尺度特征图信息来加强对小目标物体的检测,将深层特征与浅层特征相融合,从多个不同尺度的特征图提取图像特征作为网络输入来进行多尺度预测,从而提高识别的准确率;也利用残差网络增加网络的深度和降低网络参数计算量,保护在卷积过程中信息的完整性来提高准确率。本方法还对潜在车辆的边界框采用多个不同尺寸提取方式来提升车辆实时信息检测的精度。而且,相较于Yolov3,本方法使用Tiny-Yolov3减少网络中参数量和计算量,提升了车辆识别精度及检测速度。
进一步,本方法针对小目标车型检测精度不高问题,在已有的Tiny-Yolov3算法基础上进行了改进,一方面,在网络的而输出层,采用金字塔网络进行多尺度融合来提高对小目标的识别精度(包括将输入图片进行尺寸的修改);另外一方面,将池化层用卷积层(卷积核为3*3/2,步长为2*2)进行替换,加深Tiny-Yolov3的主干网络层来提高更高层的语义信息。
参照图9至图16,以下提供一个实施例对本申请的技术方案进行说明:
1、数据集介绍;
车型图片包括相机拍摄的图片和在网络收集的图片,数据集包含16108张彩色图片,共4类车型:轿车、卡车、大巴车以及摩托车(car、truck、bus、motorcycle),各类别车型有4027张图片,其中有15302张训练图片和806张检测图片,数据集分为3个训练批次和一个测试批次,每个批次有5100张图片。
数据集按照VOC2007的格式修改自己的数据格式,VOC数据集主要是对已经收集好的图片通过labelImg进行标注生成的数据集,这里,只用到Annotations、ImageSets、JPEGImages、labels。
JPEGImages:存放了VOC数据集训练和测试的所有图片。
Annotations:存放的是图片标注后产生的xml文件,xml文件中存放各个目标的位置和类别。
ImageSets:存放的是trainval、train、test、val对应的图像数据。
Labels:存放的是运用代码将xml格式标签文件转换成的txt文件。
目标框的信息会储存在对应的txt文件中,包括图像的序号、车型及目标框的左上角和右下角的坐标。
2、评价方法;
针对不同的角度和维度,车型识别模型的评价指标有很多。单一的评价指标无法全面评价一个模型的性能,而过于复杂的评价指标堆叠会无法清晰评价一个模型的优缺点,所以结合具体的评价对象,以下是常见的几种评价标准。
(1)准确率(Preoision)表示正确预测为正类与所有预测为正类的比例,准确率主要看预测结果是否准确;
(2)召回率(Recall)表示正确预测为正类与所有实际为正类的比例,召回率主要看预测结果是否全面;
(3)IOU(Intersection over Union)表示预测的边界框与物体实际的边界框重叠相交的部分与两个框的并集之比。IOU的计算公式如下式所示:
IOU的计算公式中A表示检测物体的真实框,B表示检测物体的预测框。当IOU
(4)Ap(Average Precision)指的是:以recall为横坐标,precision为纵坐标绘制的precision-recall曲线下方的区域面积每个类别上性能的优劣。
mAP(mean Average Precision)的取值等于所有类别上AP的平均值,能够衡量网络模型在所有类别上性能的优劣。
(5)FPS(Frame Per Second)是用来评估目标检测算法速度的常用指标,它表示每秒可以处理图片的帧数件下对比不同算法的FPS。
3、实验环境;
本次实验是在Ubuntu环境下运行了Yolov3-tiny版代码进行了测试,具体配置如下表1所示。
表1
DarkNet是一个基于C和CUDA编写的开源深度学习框架,移植性好,支持CPU与GPU两种计算方式。用户可以根据自己的需求在此框架下增加代码设计新的网络结构。
4、数据预处理;
4.1、图片打标签;
这里选用LabelImg软件对数据集进行打标签,速度快、操作方便。标注前先通过代码对图片进行有序重命名,如:0001、0002;最后标注生成的xml文件包含:图片序号、车型类别以及目标框的左上角和右下角的坐标。
通过PyCharm运行voc_label.py文件生成训练和测试的文件路径,主要是存放图片的存放路径。
4.2、训练过程;
通过修改cfg文件夹下的yolov3-tiny.cfg文件参数,将Training参数打开,修改filters、classes、subdivision、batch、random以及anchor等等。部分参数如图9所示。
利用预训练模型权重对自己的数据集进行模型训练,在Ubuntu18.04系统的终端下执行以下指令进行模型训练。
/darknet partial./cfg/yolov3-tiny.cfg./yolov3-tiny.weights./yolov3-tiny.conv.1515
sudo./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.conv.152>1|tee log/train_yolov3.log
通过以上的指令可以得到自己的权重文件,训练得到的权重模型文件位于/backup文件中,以及得到log文件,实现对训练过程中的数据进行可视化,绘制loss、IOU、mAP等曲线图。后面将通过mAp和recall值的计算、iou和loss的可视化值、图片测试以及视频检测对模型权重文件的结果测试。通过对yolov3-tiny.cfg参数多次的修改进行对训练模型的优化。
(1)max_batches、steps与scales、learning_rate、random参数修改;
尝试对迭代次数、学习步长、学习效率以及多尺度训练参数的多修改,得到的不同的训练结果,迭代次数主要为:40000、30000、20000、10000。其中当迭代次数为20000此时,训练效果已经接近最佳,训练结果如下表2所示:
表2
当anchors使用原有的参数,5100张训练图片训练时,用图片检测时效果不是很佳,单张图片车型识别准确率如图10所示。经过批量检测,各类车型的AP值与平均的mAP值如图11所示。
(2)anchors参数修改;
用原来自带的anchors参数发现效果不是很佳,经过观察发现anchors参数是和自己的训练的数据集数量有关,通过K-means聚类线性尺度的缩放的方式的方法计算出新的anchors参数,新的参数:(5,7);(44,52);(88,137);(223,226);(389,487);(1032,957)共6组参数。经过修改anchors参数的修改后,训练得到效果大有突破,单张图片车型识别准确率如图12所示。经过批量检测,各类车型的AP值与平均的mAP值如图13所示。
(3)图片增加经过三次增加训练图片,训练图片达到了16108张,检测效果也明显得到很大的提升,视频检测效果、IOU与loss值、图片检测、AP与mAP值都达到了理想的数值和效果。IOU与loss值如图14(a)、图14(b)所示。单张图片车型识别准确率如图15所示。
经过批量检测,各类车型的AP值与平均的mAP值如图16所示:
1.5、车型识别结果分析;
通过以上多次训练结果可看出,训练的次数、车型大小、数量的多少以及anchors等参数对模型的训练都有很大的影响,其中,anchors值要通过自己的数据集获取新的参数,这样能够提升模型的训练效果。
参照图17,本申请的一个实施例,提供一种车型视觉识别系统,本系统包括图片获取单元1100、训练集生成单元1200、模型训练单元1300以及车型识别单元1400,具体的:
图片获取单元1100用于获取多种车型图片。
训练集生成单元1200用于对多种车型图片进行标注,生成图片数据集,并从图片数据集随机提取图片训练集。
模型训练单元1300用于采用Tiny-YOLOv3网络构建车型识别模型,通过图片训练集训练车型识别模型,得到训练完成的车型识别模型。
车型识别单元1400用于通过训练完成的车型识别模型对待识别图片中的车型进行识别。
需要注意的是,本系统实施例与上述的方法实施例是基于相同的发明构思,因此上述方法实施例的内容同样适用于本系统实施例,此处不再赘述。
参照图18,本申请实施例还提供了一种电子设备,本电子设备包括:
至少一个存储器;
至少一个处理器;
至少一个程序;
程序被存储在存储器中,处理器执行至少一个程序以实现本公开实施上述的基于决策树的幽门螺旋杆菌感染预测方法。
该电子设备可以为包括手机、平板电脑、个人数字助理(Personal DigitalAssistant,PDA)、车载电脑等任意智能终端。
电子设备包括:
处理器1600,可以采用通用的中央处理器(Central Processing Unit,CPU)、微处理器、应用专用集成电路(Application Specific Integrated Circuit,ASIC)、或者一个或多个集成电路等方式实现,用于执行相关程序,以实现本公开实施例所提供的技术方案;
存储器1700,可以采用只读存储器(Read Only Memory,ROM)、静态存储设备、动态存储设备或者随机存取存储器(Random Access Memory,RAM)等形式实现。存储器1700可以存储操作系统和其他应用程序,在通过软件或者固件来实现本说明书实施例所提供的技术方案时,相关的程序代码保存在存储器1700中,并由处理器1600来调用执行本公开实施例的基于决策树的幽门螺旋杆菌感染预测方法。
输入/输出接口1800,用于实现信息输入及输出;
通信接口1900,用于实现本设备与其他设备的通信交互,可以通过有线方式(例如USB、网线等)实现通信,也可以通过无线方式(例如移动网络、WIFI、蓝牙等)实现通信;
总线2000,在设备的各个组件(例如处理器1600、存储器1700、输入/输出接口1800和通信接口1900)之间传输信息;
其中处理器1600、存储器1700、输入/输出接口1800和通信接口1900通过总线2000实现彼此之间在设备内部的通信连接。
本公开实施例还提供了一种存储介质,该存储介质是计算机可读存储介质,该计算机可读存储介质存储有计算机可执行指令,该计算机可执行指令用于使计算机执行上述基于决策树的幽门螺旋杆菌感染预测方法。
存储器作为一种非暂态计算机可读存储介质,可用于存储非暂态软件程序以及非暂态性计算机可执行程序。此外,存储器可以包括高速随机存取存储器,还可以包括非暂态存储器,例如至少一个磁盘存储器件、闪存器件、或其他非暂态固态存储器件。在一些实施方式中,存储器可选包括相对于处理器远程设置的存储器,这些远程存储器可以通过网络连接至该处理器。上述网络的实例包括但不限于互联网、企业内部网、局域网、移动通信网及其组合。
本公开实施例描述的实施例是为了更加清楚的说明本公开实施例的技术方案,并不构成对于本公开实施例提供的技术方案的限定,本领域技术人员可知,随着技术的演变和新应用场景的出现,本公开实施例提供的技术方案对于类似的技术问题,同样适用。
本领域技术人员可以理解的是,图中示出的技术方案并不构成对本公开实施例的限定,可以包括比图示更多或更少的步骤,或者组合某些步骤,或者不同的步骤。
以上所描述的装置实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。
在本申请所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括多指令用以使得一台电子设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(Read-Only Memory,ROM)、随机存取存储器(Random Access Memory,RAM)、磁碟或者光盘等各种可以存储程序的介质。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示意性实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
上面结合附图对本发明实施例作了详细说明,但本发明不限于上述实施例,在所属技术领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。