一种面向智能交通中边缘端图像识别的分布式学习方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明属于人工智能技术领域,尤其涉及一种面向智能交通中边缘端图像识别的分布式学习方法。
背景技术
交通运输系统是一个国家经济发展的基础。通信和网络技术的快速发展,如移动边缘计算、5G网络,极大地提高了运输系统收集必要信息和系统内各部件相互连接的能力。为充分实现交通系统潜力,诸如机器学习智能分析技术被应用到交通运输系统中。连接交通运输系统和机器学习的领域是智能交通系统(Intelligent Transport System,ITS)。通过将智能技术综合运用于交通运输的领域,形成高效节能的交通系统。
在智能交通系统中,图像识别技术得到广泛应用,用以识别交通繁忙程度,检测碰撞,行人和自行车。为维持服务质量,ITS会使用路侧单元,路侧单元放置在道路两侧,具有采集图像数据的传感器和处理能力。图像处理是交通系统的一个关键功能。
智能交通系统中的图像识别应用面临着一系列独特的挑战。与集中式控制集群不同,它包括大量边缘端参与设备,其在计算能力、健壮性、通信性能的方面差异巨大。此外,跨设备的数据也是异构的,不同边缘端之间的数据量和数据分布有很大的差异。除数据和设备的异构性之外,智能交通系统对分布式学习的应用提出了特殊的挑战,即动态环境,它的参与者能够是高移动性和不稳定连接的交通工具,或者是计算能力或能量容量低的边缘设备。由于设备错误或设备所有者的意愿,通信网络可能会出现故障,设备可能会失去连接,这一问题会在智能交通系统中加剧。另外,智能交通系统中的许多参与边缘端具有高移动性,并且设备的性能不稳定。为此,需要某些控制方法来保持系统性能稳定。
图像识别模型能够表示为大量计算节点和参数组合而成的计算图,通过多轮的前向传播(Forward Propagation)和反向传播(Backward Propagation)过程训练模型。很多图像识别模型包含大量参数,无法在资源受限的单一边缘端设备上利用本地数据进行直接训练。然而,现有的模型并行分布式方法在性能方面存在局限性,并且无法适应智能交通系统中的动态环境。
本发明涉及的技术缩略语和技术关键术语定义如下:
ITS:Intelligent Transport System,智能交通系统;
Forward Propagation:前向传播,智能模型训练的一个步骤;
Backward Propagation:反向传播,智能模型训练的一个步骤;
ResNet18:卷积神经网络模型,包含17个卷积层和1个全连接层;
ReLU:神经网络的一层,实现线性整流函数;
Dropout:神经网络的一层,随机丢弃一些神经网络训练单元,避免过拟合;
SoftMax:神经网络的一层,又名归一化指数函数,是一种激活函数;
Oort:一种目前先进的分布式学习参与者选择方案;
L2范数:用于衡量两个向量的欧式距离,对于矢量x=(x
epoch:所有数据被遍历一次称为1个epoch;
CIFAR10:数据集,常用于图像分类,包括猫、马的10类彩色图片,共50000张;
FEMNIST:手写数字数据集,包括大写字母、小写字母和数字共62类黑白图片,共805263张;
IID:Independent Identically Distribution,独立同分布,训练数据的一种分布特性;
Adam:一种对随机目标函数执行一阶梯度优化的算法。
发明内容
本发明的目的在于提供一种能够克服上述技术问题的面向智能交通中边缘端图像识别的分布式学习方法,本发明所述方法包括如下步骤:
步骤1:服务器选择智能交通应用场景下的分布式学习任务和深度学习模型:
步骤1.1:服务器初始化分布式学习模型,得到初始全局计算图G和初始模型参数w
步骤1.2:服务器设置训练配置,包括边缘端数量N、训练轮数E、计算图节点分组参数L的参数,及分布式学习过程中使用的学习速率的超参数;
步骤2:服务器进行模型预处理,划分给参与的边缘端:
步骤2.1:应用常量折叠(constant folding)、计算融合(operator fusing)的技术,服务器优化深度模型计算图结构;
步骤2.2:服务器根据计算图中各个节点所属的层数,将每L层节点划分为一个子图,层数的定义为在计算图中的根节点为第零层,所有根节点的子节点为第一层,依此类推,L的值根据不同的模型大小由服务器调整,参数设定为L=2;
步骤3:服务器开始第t(t=1,2…,E)轮分布式模型训练过程,t的初始值为1:
步骤3.1:每个智能设备包括效用值这一数值属性,服务器从所有候选的可用智能边缘设备中,选择效用值最高的K个作为训练子集C
步骤3.2:服务器将多组子图平均划分并发送到C
步骤4:参与学习的边缘设备进行log(K)轮本地分布式模型训练:
步骤4.1:每一个边缘设备进行前向传播计算;
步骤4.2:设定当前轮次为h,边缘设备编号为k,则判断是否k≥2
步骤4.3:针对A和B中的计算图节点,基于本地数据D
步骤4.4:边缘端k使用梯度下降算法更新分布式模型在第t轮的本地权重如以下公式(1)所示:
其中,η为梯度下降算法的学习速率参数;
步骤5:服务器基于边缘设备选择策略,决定是否在当前轮次重新选择参与分布式学习的边缘设备,采取根据使用基于数据集属性和动态环境而设置固定的选择频率p,即:每隔p轮次,重新选择一次边缘设备;
当不重新选择边缘端,则重复执行步骤3至步骤4;当重新选择边缘端则执行步骤6;
步骤6:根据已有训练中的信息反馈,边缘端计算自身效用值δ
步骤6.1:边缘端的效用包括其可用性U和实用性P,边缘端的可用性依据于工作提交的时间、设备所有者的贡献意愿、距离,实用性指边缘端本地更新的影响,包括是否会造成全局模型权重偏移增加、收敛缓慢,或由于信道问题传输过慢、本地训练数据过大导致训练过慢、本地训练数据过小导致数据与整体数据分布差距过大,如以下公式所示:
δ=ω
其中,ω
步骤6.2:边缘端将其效用值发送至服务器端;
步骤7:重复步骤3至步骤8,直到模型参数收敛。
本发明所述方法的优越效果是:
1、本发明所述方法提出的以计算图节点为基本调度单位的并行训练方法,利用智能交通系统中资源受限的边缘设备实现了细控制粒度、高性能的图像识别模型联合训练;
2、本发明所述方法根据模型训练效果调整边缘端选择频率能够减少参与者的数量,从而降低了能源成本,这是智能交通系统的一个关键目标,通过动态调整选择频率,在保持准确性的同时减少了边缘端的参与,有效地提高了系统的鲁棒性;
3、本发明所述方法边缘端效用的分布式训练和边缘设备选择为边缘端选择提供了大的调整空间以实现对选择频率的细粒度控制。
4、本发明所述方法在动态环境下优化选择参与学习的边缘设备,并将模型分布到不同的设备上,通过高性能分布式计算反向传播训练模型,通过参与者的选择频度机制,突出了分布式学习进程对选择过程的反馈控制,探索了每一轮的准确性性能和系统进程之间的权衡。
附图说明
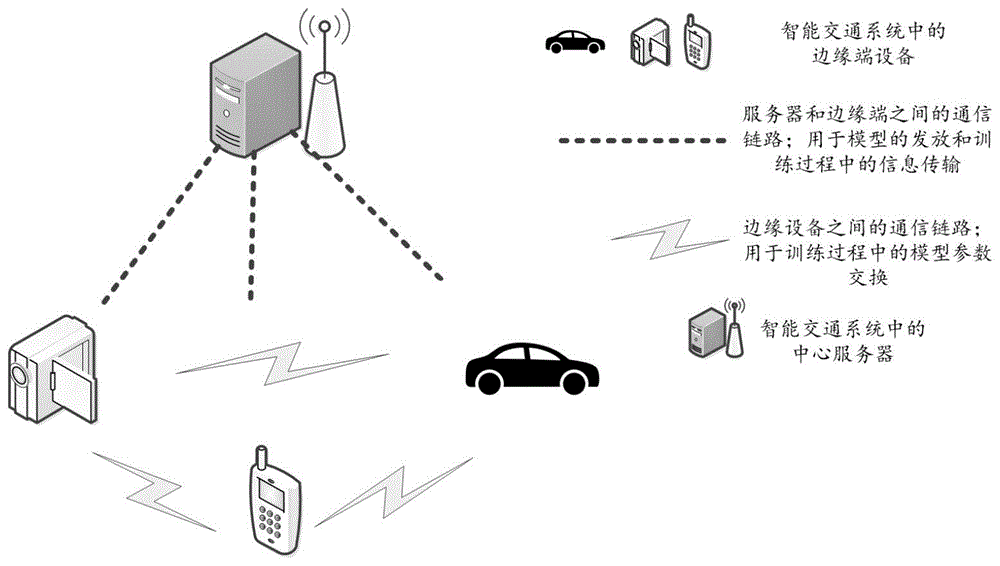
图1是本发明所述方法针对的基本系统架构示意图;
图2是本发明所述方法的不同数据集上边缘端选择方法的准确性比较示意图;
图3是本发明所述方法的不同的边缘端选择频率对模型性能的影响示意图。
具体实施方式
下面结合附图对本发明的实施方式进行详细描述。
本发明所述方法包括如下步骤:
步骤1:服务器选择智能交通应用场景下的分布式学习任务和深度学习模型:
步骤1.1:服务器初始化分布式学习模型,得到初始全局计算图G和初始模型参数w
步骤1.2:服务器设置训练配置,包括边缘端数量N、训练轮数E、计算图节点分组参数L的参数,及分布式学习过程中使用的学习速率的超参数;
步骤2:服务器进行模型预处理,划分给参与的边缘端:
步骤2.1:应用常量折叠(constant folding)、计算融合(operator fusing)的技术,服务器优化深度模型计算图结构;
步骤2.2:服务器根据计算图中各个节点所属的层数,将每L层节点划分为一个子图,层数的定义为在计算图中根节点为第零层,所有根节点的子节点为第一层,依此类推,L的值根据不同的模型大小由服务器调整,参数设定为L=2;
步骤3:服务器开始第t(t=1,2…,E)轮分布式模型训练过程,t的初始值为1:
步骤3.1:每个智能设备包括效用值这一数值属性,服务器从所有候选的可用智能边缘设备中,选择效用值最高的K个作为训练子集C
步骤3.2:服务器将多组子图平均划分并发送到C
步骤4:参与学习的边缘设备进行log(K)轮本地分布式模型训练:
步骤4.1:每一个边缘设备进行前向传播计算;
步骤4.2:设定当前轮次为h,边缘设备编号为k,则判断是否k≥2
步骤4.3:针对A和B中的计算图节点,基于本地数据D
步骤4.4:边缘端k使用梯度下降算法更新分布式模型在第t轮的本地权重如以下公式(1)所示:
其中,η为梯度下降算法的学习速率参数;
步骤5:服务器基于边缘设备选择策略,决定是否在当前轮次重新选择参与分布式学习的边缘设备,采取根据使用基于数据集属性和动态环境而设置固定的选择频率p,即:每隔p轮次,重新选择一次边缘设备;
当不重新选择边缘端,则重复执行步骤3至步骤4;当重新选择边缘端则执行步骤6;
步骤6:根据已有训练中的信息反馈,边缘端计算自身效用值δ
步骤6.1:边缘端的效用包括其可用性U和实用性P,边缘端的可用性依据于工作提交的时间、设备所有者的贡献意愿、距离,实用性指边缘端本地更新的影响,包括是否会造成全局模型权重偏移增加、收敛缓慢,或由于信道问题传输过慢、本地训练数据过大导致训练过慢、本地训练数据过小导致数据与整体数据分布差距过大,如以下公式(2)所示:
δ=ω
其中,ω
步骤6.2:边缘端将其效用值发送至服务器端;
步骤7:重复步骤3至步骤8,直到模型参数收敛。
本发明所述方法基于的智能交通系统架构如图1所示,智能交通系统包括一个中心服务器和多个参与的智能边缘终端,如智能摄像头或车辆。服务器和边缘端以及边缘端之间均通过蜂窝网络或WiFi进行通信,中心服务器设定初始模型,并设置训练参数,边缘端则基于本地数据进行前向传播和反向传播计算,通过边缘设备间的通信交换训练过程中的信息。针对智能交通系统的动态环境,本发明所述方法对边缘端选择这一步骤进行了细粒度控制,即服务器根据当前模型训练效果控制是否在当前轮重新选择边缘端,以减少服务器和边缘端的通信量并提高通信效率,在给定时间内实现模型精度和系统进度之间的权衡。
本发明所述方法的实施例实现的面向智能交通中边缘端图像识别的分布式学习按以下步骤部署运行:
步骤A:实施例平台选择和数据集选择:
实施例选择搭建在FedScale开源平台上,平台模拟真实世界的异构分布式学习系统,提供各种训练任务,还包含不同的神经网络模型和数据集,将参与设备配置为具有不同的设备运行时间,并使用来自移动平台上网络性能的信息模拟网络连接。
数据集使用CIFAR10数据集和FEMNIST数据集,在原FEMNIST数据集创建六个数据集,它们具有不同的分布和大小特性,如表1所示,其中s表示了数据集的Non-IID程度,s越小,数据集Non-IID程度越大,分割大小显示了不同边缘端的数据是否平均;
表1基于FEMNIST数据集构建的数据集
步骤B:深度神经网络的构建:
对于CIFAR10数据集,使用ResNet18模型,FEMNIST数据集使用的神经网络结构包括两个卷积层,卷积层有32和64个输出通道,内核大小为3×3,步幅大小为1,两个层后面都是ReLU激活层和DropOut层,之后是两个全连接层,第一个的输出大小为128,第二个的输出大小为64,最后包含一个SoftMax层。
本地训练批次大小设置为10,本地epoch数为5,使用Adam优化器,学习速率η为0.001,参数设置为(0.9,0.999);
步骤C:分布式学习训练设计:
使用本发明提出的分布式学习方法,作为所述步骤5的限定,用户使用基于数据集属性和动态的分布式训练环境的固定速率,手动调整新参与者的选择率,在本实施例中,使用每1、5、10和20轮重新选择一次分布式学习的参与者;
作为所述步骤6的限定,实施例使用边缘端本地更新前后的权重变化的L2范数作为边缘端的效用度量,本实施例使用的边缘端k的效用U
系数
本实施例内容和测试结果如下:
1)分布式图像识别模型训练:
在测试中,将本发明所述方法和现有Oort方法以及基准方法FedAvg对比,在实验中,将可用参与者的总数设置为24,并在每轮中从中选择6个,每个实验持续20轮,图2是本次测试的结果,从结果能够看出本发明实现了比基准方法更好的性能,在数据在所有边缘端上平均分割的情况下,实施例的性能优于基准方法,差异随着Non-IID程度的增加而增加,当数据分割大小从相等改为不等,结论仍然成立。在不同的数据异构场景中,本发明提出的方法在提高分布式训练中的全局分布式学习模型精度方面比基准方法高出20%。
2)采样频率:
本测试评估采样频率在本发明所述方法的影响,对于每个设置使用每1、5、10和20轮选择新参与者的选择率来比较全局分布式学习模型性能,结果如图3所示,在本地数据为边缘端IID的稳定环境中,智能交通系统能够选择应用少频率的选择,而不会影响全局分布式学习模型精度,随着Non-IID程度的增加,这些选择频率之间的差异变得更加明显,选择率的两个极端选择之间的性能差距小于5%,即使使用这种高度Non-IID的数据集,将选择频率从每一轮减少到每五轮也不会明显影响全局模型精度,这表明,选择率维度为调整边缘端选择频率提供了充足的空间,对全局模型精度性能没有影响或影响有限。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明公开的范围内,能够轻易想到的变化或替换,都应涵盖在本发明权利要求的保护范围内。