基于特征图双轴Transformer模块的车辆检测方法
文献发布时间:2023-06-19 19:27:02
技术领域
本发明涉及计算机视觉的目标检测领域,具体是一种基于特征图双轴Transformer模块的车辆检测方法。
背景技术
目标检测技术从阶段上分为二阶段检测技术和一阶段检测技术。
二阶段检测技术的基本流程是先提出目标候选框,在第一阶段计算目标框的粗略位置、大小和前景概率,在第二阶段计算精确的目标框位置、大小及类别,代表性的方法有:RCNN(RegionswithCNNfeatures)、SPP-NET(SpatialPyramidPooling)、FastRCNN、FasterRCNN等。一阶段检测技术的做法是直接通过深度神经网络计算目标的大小、位置和类别,代表性的方法有YOLO(YouOnlyLookOnce)、SSD(SingleShotMultiBoxDetector)。二阶段检测技术的架构具有较高的检测精度,但也限制了检测速度,一阶段检测技术的优势是速度快,劣势是精度下降。
近年来,Transformer在自然语言处理、搜索推荐领域取了显著的应用成果。Transformer由自然语言处理领域知名论文《attentionisallyouneed》提出,通过attention机制对不同的信息赋予不同的权重,同时考虑到信息间的交互关系,进行融合编码。Transformer结构对信息提取和处理能力优于卷积结构。Transformer在机器视觉中的应用如VIT(visiontransformer)等,但是Transformer结构计算复杂度高(Transformer属于一阶段检测技术),Transformer提升模型效果的同时会大幅增加计算量。为了保证模型的效率,SwinTransformer、C-SwinTransformer相继被提出,其主要方式是通过滑动窗口方法计算窗口内Attention。上述方法在采用Transformer模块时多使用在输入图像或Backbone阶段,此时,图像尺寸较大,Transformer计算复杂度较高。
发明内容
本发明的目的是克服上述背景技术中的不足,提供一种基于特征图双轴Transformer模块的车辆检测方法,该方法应具有检测精度高的特点。
本发明的技术方案是:
基于特征图双轴Transformer模块的车辆检测方法,包括以下步骤:
1)采集道路监控图片并对图片中的车辆轮廓进行标注形成数据集;
2)将数据集输入双轴Transformer模块进行训练;
3)利用双轴Transformer模块对道路监控图片进行检测;
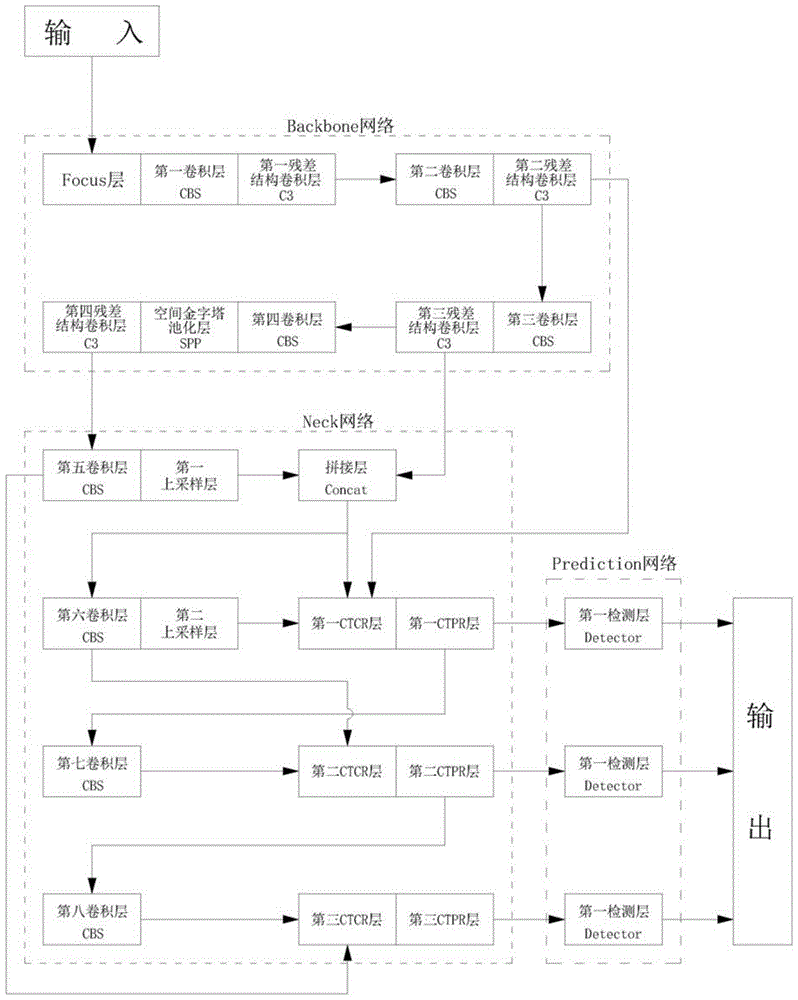
所述双轴Transformer模块包括Backbone网络、Neck网络、Prediction网络;
所述Backbone网络包括依次连接的Focus层、第一卷积层、第一残差结构卷积层、第二卷积层、第二残差结构卷积层、第三卷积层、第三残差结构卷积层、第四卷积层、空间金字塔池化层、第四残差结构卷积层;
所述Neck网络包括依次连接的第五卷积层、第一上采样层、拼接层、第六卷积层、第二上采样层、第一CTCR层、第一CTPR层、第七卷积层、第二CTCR层、第二CTPR层、第八卷积层、第三CTCR层、第三CTPR层;
所述Prediction网络基于预设定尺寸的候选框对特征图的目标进行分类和边界预测,Prediction网络包括第一检测层、第二检测层、第三检测层;
所述第二残差结构卷积层的输出还连接第一CTCR层的输入,第三残差结构卷积层的输出还连接拼接层的输入,第五卷积层的输出还连接第三CTPR层的输入,拼接层的输出还连接第一CTPR层的输入,第六卷积层的输出还连接第二CTPR层的输入;所述第一CTPR层的输出还连接第一检测层的输入,第二CTPR层的输出还连接第二检测层的输入,第三CTPR层的输出连接第三检测层的输入。
所述第一CTCR层、第二CTCR层、第三CTCR层均包括:
S1-1、对输入特征图进行两次卷积操作;
S1-2、对输入特征图经过Transformer_C模块处理;
S1-3、将S1-1的输出、S1-2的输出、输入特征图进行拼接,再进行卷积操作;
所述第一CTPR层、第二CTPR层、第三CTPR层均包括:
S2-1、对输入特征图进行两次卷积操作;
S2-2、对输入特征图经过Transformer_P模块处理;
S2-3、将S2-1的输出、S2-2的输出、输入特征图进行拼接,再进行卷积操作。
所述Transformer_C模块依次包括:先对输入的特征图按通道级进行展开,再给每个向量增加位置参数,然后所有向量均经过Attention模块处理后进行拼接,接着经过全连接层得到输出向量,最后通过Reshape操作还原向量。
所述Transformer_P模块依次包括:先对特征图进行区域划分得到区域块,再按区域块进行展开,然后给每个区域块向量增加位置参数,接着所有向量均经过Attention模块处理后进行拼接,经过全连接层得到输出向量,最后通过Reshape操作还原向量。
所述Attention模块依次包括先将输入向量映射成Query向量、Key向量、Value向量,再用Query向量和Key向量计算关联性作为加权Value的权重,然后经过全连接层进行计算得到输出结果。
所述Focus层包括:对图片进行切片操作,将每张图片分成四张互补的图片,再将四张图片拼接后进行卷积操作,得到二倍下采样特征图。
所述第一卷积层、第二卷积层、第三卷积层、第四卷积层、第五卷积层、第六卷积层、第七卷积层、第八卷积层、卷积操作的步骤相同。
所述第一残差结构卷积层、第二残差结构卷积层、第三残差结构卷积层、第四残差结构卷积层均包括:
S3-1、对输入特征图进行两次卷积操作;
S3-2、将S3-1的输出与输入特征图进行相加;
S3-3、将输入特征图进行一次卷积操作;
S3-4、将S3-2和S3-3的输出进行拼接,然后再进行一次卷积操作。
所述空间金字塔池化层包括:
S4-1、对输入特征图进行一次卷积操作;
S4-2、使用不同大小的池化窗口对输入特征图进行池化;
S4-3、将输入特征图与S4-2的输出进行拼接,再进行卷积操作。
所述拼接层包括将浅层次的特征图和深层次的特征图进行拼接以融合多层次特征图的信息。
所述第一上采样层与第二上采样层均采用内插值法;所述第一卷积层包括向量卷积、BatchNorm层和激活。
本发明的有益效果是:
本发明通过融合YOLOV5和Transformer结构来提高模型检测精度,将Transformer结构引入目标检测模型neck特征图计算阶段,并设计双轴Transformer模型结构(CTCR、CTPR)来融合不同特征图间与特征图通道间信息,提高检测精度,并应用于车辆检测场景进行验证;现有算法在neck部分采用concat结构进行拼接,本发明采用双轴(Twin-axial)-Transformer模块融合;在特征图融合阶段使用基于特征图patch级的Transformer结构(CTPR),避免在backbone阶段使用Transformer结构导致计算量暴增与模型计算效率降低;在特征图融合阶段使用特征图通道级Transformer结构(CTCR),提高特征图融合效果,从而提高检测精度。
附图说明
图1是本发明的双轴Transformer模块的总体架构图。
图2是本发明的Focus层的示意图。
图3是本发明的第一卷积层的示意图。
图4是本发明的第一残差结构卷积层的示意图。
图5是本发明的空间金字塔池化层的示意图。
图6是本发明的第一CTCR层的示意图。
图7是本发明的Transformer_C模块的示意图。
图8是本发明的Attion模块的示意图。
图9是本发明的第一CTPR层的示意图。
图10是本发明的Transformer_P模块的示意图。
图11是数据集的标签分布图。
图12是数据集的标签的标注框尺寸比例图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
车辆检测是基于道路监控视频进行道路监控、管控重要基础,本发明提供了一种基于特征图双轴Transformer模块的车辆检测方法,包括以下步骤:
1)采集道路监控图片并对图片中的车辆轮廓进行标注形成数据集;将数据集划分为训练集与测试集;
2)将数据集输入双轴Transformer模块进行训练,得到训练后的双轴Transformer模块;
3)利用训练后的双轴Transformer模块对道路监控图片进行检测。
双轴Transformer模块(特征图双轴Transformer车辆检测,Twins-axisTransformerbasedDetector,简称TDD)包括三个部分(图1所示),分别为Backbone网络(主干网络)、Neck网络(头网络)、Prediction网络(检测网络)。
所述Backbone网络包括四种类型的神经网络层,分别为Focus层、卷积层(CBS)、残差结构卷积层(C3)、空间金字塔池化层(SPP)。其中,Backbone网络包括依次连接的Focus层、第一卷积层、第一残差结构卷积层、第二卷积层、第二残差结构卷积层、第三卷积层、第三残差结构卷积层、第四卷积层、空间金字塔池化层、第四残差结构卷积层。
所述Neck网络包括五种类型的神经网络层,分别为卷积层(CBS)、上采样层、拼接层(Concat)、CTCR层(通道级残差结构卷积-Transformer层,图中简称CTCR)、CTPR层(patch级残差结构卷积-Transformer层,图中简称CTCR)。其中,Neck网络包括依次连接的第五卷积层、第一上采样层、拼接层、第六卷积层、第二上采样层、第一CTCR层、第一CTPR层、第七卷积层、第二CTCR层、第二CTPR层、第八卷积层、第三CTCR层、第三CTPR层。
所述第二残差结构卷积层的输出还连接第一CTCR层的输入,第三残差结构卷积层的输出还连接拼接层的输入,第五卷积层的输出还连接第三CTPR层的输入,拼接层的输出还连接第一CTPR层的输入,第六卷积层的输出还连接第二CTPR层的输入。
所述Prediction网络基于预设定尺寸的候选框对特征图上的目标进行分类和边界预测。所述Prediction网络包括第一检测层、第二检测层、第三检测层。所述第一CTPR层的输出还连接第一检测层的输入,第二CTPR层的输出还连接第二检测层的输入,第三CTPR层的输出连接第三检测层的输入。
三个检测层连接了不同尺寸的特征图,第一检测层对应的特征图尺寸最大,用于小目标检测,第二检测曾对应的特征图尺寸中等,用于中等目标检测,第三检测层对应特征图尺寸最小,用于大目标检测。
所述Focus层先对图片进行切片,再将图片进行通道级拼接(通道数扩张数倍),最后进行卷积。具体步骤是:如图2所示,是在原始输入图片上隔像素点取一个值(类似于邻近下采样),将一张图片分成四份(Slice)后进行拼接(Concat),四份图片互补但是无信息丢失,从而将W、H信息集中到了通道空间,输入通道扩充了4倍,拼接起来的图片相对于原先的RGB三通道模式扩张成12个通道,将获得的新图片再进行卷积操作(CBS),最后得到无信息丢失的二倍下采样特征图。
如图4所示,所述第一残差结构卷积层、第二残差结构卷积层、第三残差结构卷积层、第四残差结构卷积层的步骤相同,均包括(C3表示各个残差结构卷积层):
S3-1、对输入特征图进行两次卷积操作(CBS);
S1-2、将S3-1的输出与输入特征图进行相加(add);相加是把对应特征图上的相同通道进行一一对应相加,通道数不变;
S3-3、将输入特征图进行一次卷积操作(CBS);
S3-4、将S3-2和S3-3的输出进行拼接(Concat),然后再进行一次卷积操作(CBS);拼接是指在通道深度上扩展,通道数增加。
如图5所示,所述空间金字塔池化层(SPP)用于提取不同尺度的特征,包括:
S4-1、将输入特征图进行一次卷积操作(CBS);
S4-2、使用不同大小的池化窗口(MaxPool)对输入特征图进行池化;图中显示有3个池化窗口,池化窗口大小分别为5*5、9*9、13*13;
S4-3、将输入特征图与S4-2的输出进行拼接(Concat),再进行卷积操作(CBS)。
所述第一上采样层与第二上采样层均采用内插值法(最近邻下采样),内插值法是最简单的一种插值方法,不需要计算,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素(最近邻下采样,在待求像素的四邻像素中,将距离待求像素最近的邻像素灰度赋给待求像素)。
所述拼接层对多个特征图进行通道级拼接,拼接前先通过第一上采样层把特征图统一尺寸。所述拼接层的目的是为了融合多层次特征图的信息,本发明中,拼接层将浅层次的特征图和深层次的特征图进行拼接,浅层次的特征图有利于目标检测的边界计算,而深层次的特征图有利于图像语义计算。所述拼接层将第三残差结构卷积层(浅层次)与第一上采样层(深层次)进行拼接。
所述第一卷积层、第二卷积层、第三卷积层、第四卷积层、第五卷积层、第六卷积层、第七卷积层、第八卷积层的步骤与卷积操作(CBS)的步骤相同,均包括(如图3所示):对特征图进行向量卷积(Conv)、BatchNorm层(BN)和激活(Silu)。激活选用SiLU函数(SigmoidWeighted Liner Unit)。
向量卷积是指卷积核与特征图上的数值对应相乘相加,卷积核可以在特征图上上下左右滑动,完成所有位置的计算。BatchNorm层为batch内所有数据做归一化,具体步骤是,先求出此次批量数据的均值和标准差,其次将所有卷积核输出值减去均值除以标准差,最后引入缩放和平移变量,即乘上一个可学习的系数,加上一个偏置。Batchnorm层有效解决梯度消失问题,并加速收敛。SiLU函数,SiLU全称Sigmoid Weighted Liner Unit,计算公式为:
SiLU(x)=x*Sigmoid(x)
SiLU函数是非饱和型激活函数,且在全值域可导。
卷积操作是图像操作中的重要部分,本质是用卷积核的参数来提取数据的特征,具体做法是用卷积核对图像上对应区域的元素值相加求和,并使用滑动方法完成对整个图像的卷积操作,相关参数包括卷积核大小、步长、数量(输出通道数)等。
如图6所示,所述第一CTCR层、第二CTCR层、第三CTCR层的步骤相同,均包括:
S1-1、对输入特征图进行两次卷积操作;
S1-2、对输入特征图经过Transformer_C模块处理;
S1-3、将S1-1的输出、S1-2的输出、输入特征图进行拼接,再进行卷积操作。
该层是本发明中提出的用于特征图通道级融合处理的关键模块,前一层为不同层次特征图拼接后的结果,结果输出到下一层进行处理。
如图7所示,所述Transformer_C模块依次包括:先对输入的特征图按通道级进行展开(Flatten(chanel level)),输入向量维度为batchsize*Chanel*H*W,经过通道级Flatten处理之后,输出向量维度为batchsize*M,M大小为Chanel*H*W;再给每个向量增加位置参数(Add Pos),然后所有向量均经过Attention模块处理后进行拼接(Concat),接着经过全连接层(FC)得到输出向量,最后通过Reshape操作还原向量。
如图8所示,所述Attention模块依次包括先将输入向量映射成Query向量、Key向量、Value向量,再用Query向量和Key向量计算关联性作为加权Value的权重,然后经过全连接层(FC)进行计算得到输出结果。向量经过多个Attention模块后也成为Multi-headattention。
如图9所示,所述第一CTPR层、第二CTPR层、第三CTPR层的步骤相同,均包括:
S2-1、对输入特征图进行两次卷积操作;
S2-2、对输入特征图经过Transformer_P模块处理
S2-3、将S2-1的输出、S2-2的输出、输入特征图进行拼接,再进行卷积操作。
该层是本发明中提出的用于特征图区域级融合处理的关键模块。该模块通过对特征图不同区域的attention处理,更新特征图的表达向量,不同区域的表达向量中考虑区域块间的相互关联。
如图10所示,所述Transformer_P模块依次包括:先对特征图进行区域划分(Partition)得到区域块,再按区域块进行展开(Flatten(part level)),然后给每个区域块向量增加位置参数(Add Pos),接着所有向量均经过Attention模块处理后(基于区域块间的关联性更新区域块的表达向量)进行拼接(Concat),经过全连接层(FC)得到输出向量,最后通过Reshape操作还原向量。Transformer_P模块的Attention模块与Transformer_P模块的Attention模块结构相同。
CTCP和CTPR是从空间轴和通道轴进行融合编码,在通道级和空间级的信息交互。CTCP和CTPR均使用残差结构。其中:CTCP的Transformer_C模块在通道级信息使用Transformer结构进行融合处理,对不同特征图在通道轴使用注意力机制进行加权,从而使得检测网络在不同尺度目标检测时对特征图层次有所侧重。而现有网络一般通过Concat直接拼接,检测效果有局限性。第三路将输入保持不变,最后通过卷积模块将三路数据融合。
CTPR的Transformer_P模块在空间维度使用Transformer结构对特征图进行编码,对特征图某一位置的编码考虑了周围位置的图像信息,是一种全局编码的机制,此时特征图尺寸一般比原始输入图像小,因此,在Neck网络使用CTPR既能有效融合空间位置信息,同时又不会产生大量计算需求。本发明采用了4个残差结构卷积层能提取更深层次的特征,同时有利于效果提升和参数优化效率。激活函数采用silu函数,silu函数相较于leaky relu具备有下界无上界、全域可导的优点,能增强模型的非线性表达能力。此外,再配合Focus层、空间金字塔池化层进行优化。
双轴Transformer模块的总体流程(表1所示)为:
第1层为Focus层,通过采样将原始图片分为4份并进行通道级拼接,然后经过CBS层,其中卷积核数32,输出特征图尺寸为240*240*32。第2到11层由CBS、C3、SPP层组成,每一层的输入均来自上一层。第12、15层是上采样层,采用最近邻方法,采样倍率为2。第13层是Concat层。其他层由CBS、CTPR、CTCR层构成。TDD中所有卷积核大小均为3*3。数据从第一层开始顺序流转,最后一层为Detect层,所需要的特征图来自17、20、23层。
表1 TTD各层类别、输入与超参
实验验证
对比Baseline选择YOLOV5算法。选用YOLOV5的原因有:
1、YOLOV5算法是目标检测领域的前沿和具有代表性的算法;
2、模型结构大小和参数量与本发明提出的方法相当,具有效果可比性。
实验一:车辆检测
数据集采用实景道路拍摄的视频。视频以每秒25帧(Fps)的速度录制,分辨率为960×540像素。该数据集包括训练集与测试集,训练集包含约8万张图片,测试集包含约1万4千张图片。如图11所示,标签包含四个类别,分别为Car、Van、Bus、Others。标签的标注框尺寸比例如图12所示。
表2实验一检测精度
实验结论:
TTD在第5个epoch训练时达到最佳效果,Precison为0.729,Recall为0.761,mAP为0.798。Yolov5在第10个epoch训练时达到最佳效果,Precison为0.683,Recall为0.746,mAP为0.783。综合上述指标,本发明提出的方法相对于YOLOv5算法,在收敛速度和精准度均有明显提升。
附图中给出了本发明的较佳实施例。但是,本发明可以以许多不同的形式来实现,并不限于本说明书所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。