基于多模态Transformer的虚假新闻检测方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及虚假新闻检测技术领域,具体为基于多模态Transformer的虚假新闻检测方法。
背景技术
近年来社交媒体已成为重要的新闻信息来源,人们逐渐习惯在社交媒体上获取最新的新闻并自由地发表自己的观点。然而,社交媒体的便利性和开放性也为虚假新闻的传播提供了极大的便利,造成了很多消极的社会影响。因此,能否利用技术手段对虚假新闻进行自动检测已经成为自媒体时代亟待解决的问题。文本作为新闻事件的主要描述载体,是传统虚假新闻检测方法的关注重点。最近,假新闻从传统的基于文本的新闻形式逐步向基于多模态内容的新闻形式演变。因此,基于多模态内容的检测方法,即多模态虚假新闻检测,成为当前的研究热点。
现有的多模态虚假新闻检测方法大多使用预训练的深度卷积神经网络来提取图像特征,如VGG16、VGG19、ResNet。在实际训练过程中,充当图像特征提取器的预训练模型的参数会保持冻结,使得预训练模型并不完美,这会限制整个多模态模型的性能,为了减少特征提取时间,图像特征通常会被预先存储起来,往往会使得这些模型的缺点被忽略,由于不同模态数据之间可以相互补充,因此处理好跨模态特征融合是多模态模型成功的关键。现有多模态虚假新闻检测方法使用的特征融合方式大多十分简单,例如有些仅将图像特征和文本特征拼接在一起送入分类器中,没有充分考虑模态间的互补关系。
为此,提出基于多模态Transformer的虚假新闻检测方法。
发明内容
本发明的目的在于提供基于多模态Transformer的虚假新闻检测方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:基于多模态Transformer的虚假新闻检测方法,具体包括以下步骤:
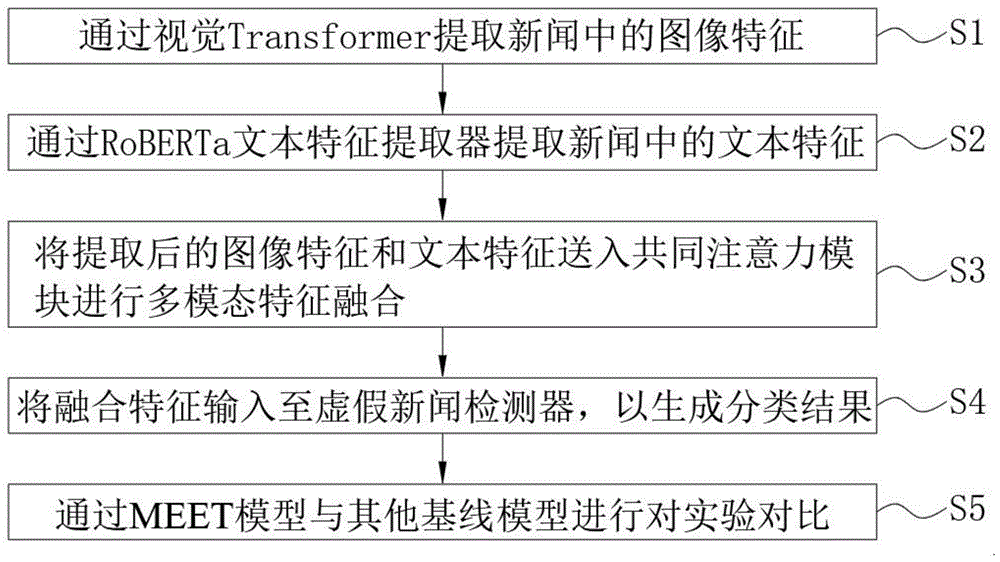
步骤一:通过视觉Transformer图像特征提取器提取新闻中的图像特征;
步骤二:通过RoBERTa文本特征提取器提取新闻中的文本特征;
步骤三:将提取后的图像特征和文本特征送入共同注意力模块进行多模态特征融合;
步骤四:将融合特征输入至虚假新闻检测器,以生成预测新闻是真假新闻的概率;
步骤五:通过MEET与其他基线模型进行对实验对比。
优选的,所述步骤一中视觉Transformer图像特征提取器采用的是基于对比语言图像预训练(contrastive language-image pre-training,CLIP)的视觉Transformer模型,简称CLIPViT,所述视觉Transformer图像特征提取器在提取新闻中的图像特征时,要对新闻的图像进行序列化预处理。
优选的,所述序列化预处理包括使用卷积层将图像切分为n*n个patch,之后将所有patch展平成长度为n*n总和的序列,在序列前拼接分类标记嵌入再加上位置嵌入就得到了完整的图像嵌入矩阵,对于给定图像嵌入R,通过CLIPViT提取到的图像特征的导出公式如下:
V={v
其中
优选的,所述步骤二中RoBERTa文本特征提取器用Transformer编码器作为网络主体,RoBERTa文本特征提取器包括使用更大的文本嵌入词汇表、预训练任务中去除预测下一个句子和使用动态掩码策略。
优选的,所述步骤三中共同注意力模块是由两个交叉注意力网络构成,每个所述交叉注意力网络都是一个N层的Transformer结构,与一般的Transformer相比每层多了一个交叉注意力块,所述步骤三中多模态特征融合通过共同注意力模块的交叉注意力机制,得到更新后的图像特征和文本特征,并将图像分类特征与文本分类特征进行拼接。
优选的,所述步骤四中融合特征输入至虚假新闻检测器是指虚假新闻检测器以多模态融合特征作为输入,利用两层全连接层来预测新闻是真假新闻的概率,其计算公式如下:
H=σ
P=σ
式中σ
优选的,所述MEET是基于端到端训练的多模态Transformer模型的英文缩写,所述其他基线模型包括单模态模型和多模态模型,所述单模态模型包括Textual模型和Visual模型,所述多模态模型包括EANN模型、MVAE模型、SpotFake模型和HMCAN模型。
为了解决上述问题,本发明还提供了一种基于多模态Transformer的虚假新闻检测系统,包括:
提取模块,其被配置为提取待检测新闻的文本特征和图像特征,其中文本特征的提取采用RoBERTa文本特征提取器,图像特征的提取采用视觉Transformer图像特征提取器;
融合模块,其被配置为将提取后的图像特征和文本特征送入共同注意力模块进行多模态特征融合,得到多模态融合特征;
检测模块,其被配置为将多模态融合特征输入至虚假新闻检测器,利用两层全连接层来预测新闻是真假新闻的概率。
为了解决上述问题,本发明还提供了一种计算机可读存储介质,其上存储有程序,所述计算机程序被处理器执行时实现上述所述的基于多模态Transformer的虚假新闻检测方法。
为了解决上述问题,本发明还提供了一种电子设备,包括处理器、与处理器通信连接的存储器及存储在存储器上并可在处理器上运行的程序,所述处理器执行所述程序时实现上述所述的基于多模态Transformer的虚假新闻检测方法。
与现有技术相比,本发明的有益效果是:
1、本发明中提出了MEET模型,使用视觉Transfomer作为图像特征提取器,以相同的方式处理不同模态的输入,同时采用端到端的方式对模型进行了训练,通过使用视觉Transformer图像特征提取器提取图像特征,将对图像输入的处理简化为与处理文本输入一致的无卷积方式,统一了不同模态的特征提取过程。
2、本发明中,首次在虚假新闻检测任务中使用共同注意力模块,共同注意力模块由两个交叉注意力网络构成,每个交叉注意力网络都是一个N层的Transformer结构,与一般Transformer相比每层多了一个交叉注意力块,通过在两个网络对应层的交叉注意力块之间交换键矩阵K和值矩阵V,使得图像对应的文本特征能够被纳入网络输出的图像表示中,同样文本对应的图像特征也会被纳入网络输出的文本表示中,并通过消融实验证明了共同注意力模块在虚假新闻检测中的有效性。
3、本发明中,本实施例第一次在虚假新闻检测任务中引入端到端预训练,并在TWITTER数据集上与没有经过预训练的MEET模型进行了对比分析,实验结果验证了端到端预训练方法的优越性,MEET模型可以通过图像输入补充信息,有助于提升模型检测性能。
附图说明
图1为本发明的步骤流程示意图;
图2为本发明中基于多模态Transformer的虚假新闻检测模型示意图;
图3为本发明中图像预处理过程示意图;
图4为本发明中共同注意力模块示意图;
图5为本发明中不同预训练设置下的训练损失曲线图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1至图5,本发明提供基于多模态Transformer的虚假新闻检测方法的技术方案:
基于多模态Transformer的虚假新闻检测方法,具体包括以下步骤:
步骤一:通过视觉Transformer图像特征提取器提取新闻中的图像特征;
步骤二:通过RoBERTa文本特征提取器提取新闻中的文本特征;
步骤三:将提取后的图像特征和文本特征送入共同注意力模块进行多模态特征融合;
步骤四:将融合特征输入至虚假新闻检测器,以生成预测新闻是真假新闻的概率;
步骤五:通过MEET(MEET模型进行了端到端预训练,预训练任务包括掩码语言建模(masked language modeling,MLM)和图像文本匹配(image-text matching,ITM),在MLM任务中,将15%的输入文本替换为掩码标记([MASK]),并让模型学习输出被替换的原始文本,在ITM任务中,按相同概率采样匹配和不匹配的图像标题对送入模型,模型需要输出输入的图像标题对是否匹配)与其他基线模型进行对实验对比。
作为本发明的一种实施例,如图1-3所示,所述步骤一中视觉Transformer图像特征提取器采用的是基于对比语言图像预训练(contrastive language-image pre-training,CLIP)的视觉Transformer模型,简称CLIPViT,CLIPViT与其他预训练视觉Transfomer的区别在于其预训练数据是多模态的,它是在从互联网上抓取的4亿个图像文本对上训练的,此外,CLIPViT还在ImageNet分类等基准数据集上展现出强大的零样本学习能力,所述视觉Transformer图像特征提取器在提取新闻中的图像特征时,要对新闻的图像进行序列化预处理;
所述序列化预处理包括使用卷积层将图像切分为n*n个patch,之后将所有patch展平成长度为n*n总和的序列,在序列前拼接分类标记嵌入再加上位置嵌入就得到了完整的图像嵌入矩阵,对于给定图像嵌入R,通过CLIPViT提取到的图像特征的导出公式如下:
V={v
其中
工作时,为了使图像输入的三维矩阵结构变为符合Transformer输入要求的序列结构,首先要对图像进行序列化预处理,假设图像输入矩阵尺寸为224×224×3,首先使用卷积层将图像切分为14×14个patch,之后将所有patch展平成长度为196的序列,在序列前拼接分类标记嵌入再加上位置嵌入就得到了完整的图像嵌入矩阵,整个处理过程如图2所示。
作为本发明的一种实施例,如图1-2所示,所述步骤二中RoBERTa文本特征提取器用Transformer编码器作为网络主体,RoBERTa文本特征提取器包括使用更大的文本嵌入词汇表、预训练任务中去除预测下一个句子和使用动态掩码策略,目前常用的预训练语言模型有BERT和RoBERTa,但是RoBERTa已经在多个自然语言处理任务上表现出超越BERT的性能。
工作时,令T={t
L={l
其中
作为本发明的一种实施例,如图1-4所示,所述步骤三中共同注意力模块是由两个交叉注意力网络构成,每个所述交叉注意力网络都是一个N层的Transformer结构,与一般的Transformer相比每层多了一个交叉注意力块,通过在两个网络对应层的交叉注意力块之间交换键矩阵K和值矩阵V,使得图像对应的文本特征能够被纳入网络输出的图像表示中,同样文本对应的图像特征也会被纳入网络输出的文本表示中。共同注意力模块已经被用于视觉语言模型中,并且在图像问答、图像标注等任务上证明了其有效性,所述步骤三中多模态特征融合通过共同注意力模块的交叉注意力机制,得到更新后的图像特征和文本特征,并将图像分类特征与文本分类特征进行拼接。
作为本发明的一种实施例,如图1-4所示,所述步骤四中融合特征输入至虚假新闻检测器是指虚假新闻检测器以多模态融合特征作为输入,利用两层全连接层来预测新闻是真假新闻的概率,其计算公式如下:
H=σ
P=σ
式中σ
作为本发明的一种实施例,如图1-5所示,所述MEET是基于端到端训练的多模态Transformer模型的英文缩写,所述其他基线模型包括单模态模型和多模态模型,所述单模态模型包括Textual模型和Visual模型;
Textual模型仅使用新闻文本作为模型输入,首先使用预训练的词嵌入模型生成文本嵌入,然后将文本嵌入输入双向LSTM模型以提取新闻文本特征,最后使用全连接层输出分类结果;
Visual模型仅使用新闻图片作为模型输入,首先将图片输入预训练VGG-19模型提取图像特征,接着将图像特征输入全连接层进行虚假新闻检测;
所述多模态模型包括EANN模型、MVAE模型、SpotFake模型和HMCAN模型;
EANN模型主要由三个部分组成:多模态特征提取器、虚假新闻检测器和事件鉴别器。在多模态特征提取器中,分别使用TextCNN模型和预训练VGG19模型提取文本特征和图像特征,之后将提取到的文本特征和图像特征拼接后输入虚假新闻检测器中。为了保证实验公平,本实施例使用的是不包含事件鉴别器的简化版EANN模型;
MVAE模型使用双模态变分自编码器和二值分类器进行虚假新闻检测,其中双模态变分自编码器使用双向LSTM模型和预训练VGG19模型作为文本编码器和图像编码器,利用全连接层进行特征融合;
SpotFake模型使用预训练语言模型(如BERT)提取文本特征,并使用预训练VGG-19模型提取图像特征,没有使用特征融合方法。
HMCAN模型使用预训练BERT模型和ResNet模型提取新闻文本特征和图像特征,并将提取到的特征输入多模态上下文注意网络进行特征融合,此外模型还使用层次编码网络捕捉输入文本的层次语义特征。
工作时,将在两个公开的虚假新闻数据集上,分别是英文TWITTER数据集(TWITTER数据集是在MediaEval研讨会上发布的虚假新闻检测数据集MediaEval2015。该数据集由17000条来自Twitter平台的推文文本及其相关图像组成,是多模态虚假新闻检测任务中最常用的数据集之一)和中文WEIBO数据集(WEIBO数据集是由经过微博官方辟谣平台验证的虚假新闻和经新华社核实的真实新闻组成,这些新闻同样包含文本和图像。使用不同语言的数据集能够更好地评估模型的泛用性和鲁棒性),对本实施例提出的MEET模型与其他基线模型进行了实验对比;
在对新闻文本进行简单预处理后,筛选出了所有既包含文本又包含图像的新闻,其中图像不包括动图和视频,经过筛选后的数据集统计信息如表1所示。
表1:两个数据集的统计信息
MEET模型与其他基线模型在两个公开数据集上的实验结果,如表2所示,其中MEET(PTM)为经过端到端预训练的MEET模型。
从表2中可以看到在TWITTER数据集上Visual模型性能优于Textual模型,而在WEIBO数据集上的实验结果则相反。这主要与两个数据集中的新闻图片数量有关,TWITTER数据集包含的图片数量远远小于WEIBO数据集,Visual模型在TWITTER数据集上需要学习的虚假新闻图像特征也更少。
表2:不同方法在两个数据集上的实验结果
此外,多模态模型与单模态模型相比具有明显优势,其中SpotFake和HMCAN的性能表现较好,表明预训练BERT模型能够从新闻文本中提取到更好的特征。HMCAN在TWITTER数据集上的检测准确率与SpotFake相比有较大提升,证明其特征融合方法和层次编码网络的有效性。本实施例提出的模型MEET在两个数据集上性能都优于其他所有基线模型,其中在TWITTER数据集上MEET(PTM)模型表现最好,表明端到端预训练能够提升模型性能,MEET(PTM)模型和MEET模型在训练过程中的损失曲线,如图5所示,可以看到MEET(PTM)在前400步中训练损失下降更快,说明端到端预训练还可以加快模型的收敛速度;
为了进一步探索模型每个模块对模型性能的影响,本实施例设计了两种MEET模型变体与完整的MEET模型进行消融实验,分别是去除图像输入的MEET-V模型和去除共同注意力模块的MEET-C模型,实验结果如表3所示。
表3:消融实验结果
首先对比MEET模型和MEET-V模型在两个数据集上的实验结果,从中可以看到MEET模型表现更好,说明图像输入可以提供补充信息,有助于提升模型检测性能。接着观察MEET模型和MEET-C模型的实验结果,发现不使用特征融合方法的MEET-C模型表现更差,证实了共同注意力模块在MEET模型中的有效性;
本实施例遵循已有的工作,在四个公开数据集上对模型进行端到端预训练,包括COCO数据集、Conceptual Captions数据集、SBU Captions数据集和Visual Genome数据集,为了使预训练数据集与微调数据集中的文本语言保持一致,本实施例只在英文TWITTER数据集上对端到端预训练效果进行了验证。
根据对两个公开数据集中文本长度的统计,将TWITTER数据集文本序列最大长度设置为50,WEIBO数据集文本序列最大长度设置为200,超出部分截断,不足部分补零。对于图片,所有图片输入大小都会被调整为224×224×3,训练过程中对图片应用随机的数据增强以加强模型泛化性能,验证和测试过程中不使用数据增强。每个数据集都按照7:1:2划分为训练集、测试集和验证集,且不同数据划分不会包含相同图片。
MEET模型的图像特征提取器和文本特征提取器都是12层Transformer结构,图像嵌入和文本嵌入维数均为768,图像切分的patch大小为16×16,图像切分后的patch数量为196。共同注意模块中两个交叉注意力网络均为6层Transformer结构。虚假新闻检测器中两层全连接层的神经元个数分别为1536和2,激活函数分别为gelu和softmax,损失函数为交叉熵损失函数。
使用AdamW优化器,多模态特征提取器的学习率设置为5e-6,共同注意力模块和虚假新闻检测器学习率设置为2.5e-5,训练批次大小为256,训练轮数为50,为了减缓模型过拟合同时加速模型收敛,学习率在训练总步数的前10%中会从0线性递增到设置的学习率,之后再线性衰减到0。
作为本发明的一种实施例,一种基于多模态Transformer的虚假新闻检测系统,包括:
提取模块,其被配置为提取待检测新闻的文本特征和图像特征,其中文本特征的提取采用RoBERTa文本特征提取器,图像特征的提取采用视觉Transformer(CLIPViT)图像特征提取器;
融合模块,其被配置为将提取后的图像特征和文本特征送入共同注意力模块进行多模态特征融合,得到多模态融合特征;
检测模块,其被配置为将多模态融合特征输入至虚假新闻检测器,利用两层全连接层来预测新闻是真假新闻的概率。
作为本发明的一种实施例,一种计算机可读存储介质,其上存储有程序,所述计算机程序被处理器执行时实现上述所述的基于多模态Transformer的虚假新闻检测方法。
作为本发明的一种实施例,一种电子设备,包括处理器、与处理器通信连接的存储器及存储在存储器上并可在处理器上运行的程序,所述处理器执行所述程序时实现上述所述的基于多模态Transformer的虚假新闻检测方法;
存储器存储内存为32G,处理器的型号为NvidiaRTX 3090,使用的编程语言为python3.8,使用的深度学习框架为pytorch-lightning 1.3.2、pytorch 1.7.1和transformers 4.6.0。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种基于用户认知一致性推理的多模态虚假新闻检测方法
- 基于渐进式多模态融合网络的虚假新闻检测方法及系统