一种基于机器学习重建时变重力场模型间断数据的方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及卫星重力学应用领域,更具体涉及一种基于机器学习重建时变重力场模型间断数据的方法。
背景技术
目前,时变重力场模型的数据来源于重力卫星观测数据,但由于重力卫星仪器校准或卫星姿态调整,卫星受空间天气的影响导致部分数据缺失,即存在数据间断,当采用时变重力场模型进行应用分析时,需要人为的将间断数据补充完整。时变重力场数据的重建有多种方法,其中深度学习模型长短期记忆神经网络(LSTM)被广泛使用。
长短期记忆神经网络(LSTM)进行重建时变重力场模型间断数据需要先进行数据预处理,处理后的数据按一定比例划分训练集和测试集;然后进行模型搭建和模型训练,将训练集输入模型,并通过调节神经网络模型的超参数,根据最优模型最终获得重建后的时变重力场模型数据。由于时间序列特征复杂,现有技术也采用多层LSTM组合的深度学习神经网络进行时变重力场缺失信息递推预测,或通过多层感知机重建等效水高。
求和自回归滑动平均(ARIMA)模型是时间序列预测法,通过编制和分析时间序列,根据时间序列所反映出来的发展过程、方向和趋势,进行类推或延伸,目前广泛用于金融分析等领域,可用于预测非平稳时间序列,该模型表示为ARIMA(p,d,q):
其中,A(z)表示AR(p),B(z)表示MA(q),X
时变重力场的时间序列数据具有强烈的季节性变化,其自身的历史变化是具备规律的,理论上可以用时间序列预测方法来进行预测和重建,但由于时变重力场数据所受如气温、降水这类自然影响和人类各项活动影响较大,所产生的时间序列包含大量噪声和复杂规律,使用单一的时间序列预测模型时,由于各类数据内部可能存在的多种类型的函数关系,导致模型无法完全把握数据的历史变化规律,输出结构不够稳健,精度不够高,泛化能力不强等问题,而使用单一的神经网络模型虽能够捕捉序列根据时间变化的规律和关系,但模型使用反向传播和激活函数,仍然存在梯度爆炸或消失的问题,可能无法得到最优解,导致预测效果大打折扣;同样的超参数设置由于LSTM模型本身是随机初始化参数,会出现不同的解,模型的稳定性差,精度低。
发明内容
针对现有技术采用单一模型存在的缺陷,本发明的目的是提供一种基于机器学习重建时变重力场模型间断数据的方法,利用多种模型,提高重建的时变重力场数据精度,使结果更加符合真实情况,同时能够适应更多地区的数据重建工作,提高重建模型的稳定性和普适性。
一种基于机器学习重建时变重力场模型间断数据的方法,包括以下步骤:
S1:采用球谐系数法反演流域的等效水高,通过滤波得到流域的陆地水储量变化的原始时间序列数据;
S2:对原始时间序列数据TWSA
TWSA
S3:建立并训练自回归移动平均模型(ARIMA)和长短时记忆神经网络(LSTM)组成的ARIMA-LSTM组合模型,然后进行格网尺度和流域尺度的数据重建,所述的数据重建包括:对于周期项C
S4:计算差值ε
对所述的差值ε
作为本发明进一步的方案:采用球谐系数法反演流域的等效水高的公式如下:
式中,Δh(θ,λ)为等效水高;θ和λ为待计算点的余纬和经度;a为地球半径;ρ
反演出流域的等效水高后,选用半径300km的FAN滤波和P3M15的去相关滤波形成的组合滤波方法,通过滤波得到流域的陆地水储量变化的时间序列数据。
作为本发明进一步的方案:所述的组合模型训练需要的数据包括流域尺度和格网(1°×1°)尺度的陆地水储量变化数据,流域尺度为整个流域的格网点值的平均,格网尺度为数据是以1°为单位的点状空间分布。
作为本发明进一步的方案:所述皮尔逊相关系数(CC)评价预测的TWSA与GRACE-TWSA真实值之间的线性关系,所述纳什效率系数(NSE)用于衡量模型的拟合程度;所述平均绝对值百分比误差(MAPE)来估计预测的TWSA与GRACE-TWSA真实值的偏差,所述均方根误差(RMSE)衡量误差绝对大小,计算公式如下:
式中,σ
本发明与现有技术相比具有以下有益效果:
1、本发明使用多模型的组合,利用不同模型的优势,ARIMA是线性关系模型,适合预测线性且非平稳的序列,LSTM是神经网络模型,可以找到序列中的高度非线性函数关系,通常时间序列受到的影响因素太多,自身规律比较复杂,对由采用球谐系数法反演流域的等效水高,通过滤波得到流域的陆地水储量变化的原始时间序列数据进行季节性分解,可以分解成具有线性特征的周期项、高度非线性的趋势项以及残差项,分解后的多个序列较原始序列更简单,根据不同序列的数学特点分别使用不同的方法进行预测,对于周期项,采用ARIMA预测,对于趋势项以及残差项,采用LSTM预测,求和后得到预测的时间序列数据,预测效果好。
2、本发明的ARIMA-LSTM组合模型较单一模型能够提高TWSA重建的稳定性,适用性和精度,使神经网络结果的权重减小,避免单一神经网络带来的不稳定影响;同时分解序列能够降低数据复杂度使得模型更容易学习数据的特征,方便了重建工作,提高数据重建的精度。
附图说明
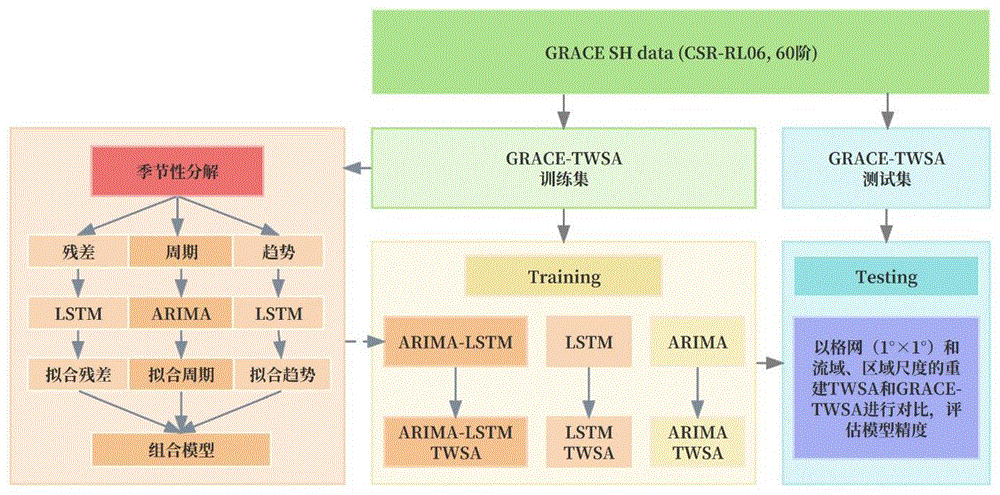
图1为本发明的技术路线图;
图2为ARIMA模型,LSTM模型以及ARIMA-LSTM组合模型所预测的2015年7月至2017年5月共23个月的全球11个流域和区域的TWSA时间序列;
图3为ARIMA模型,LSTM模型以及ARIMA-LSTM组合模型重建的TWSA对比GRACE卫星观测值的纳什效率系数;
图4为ARIMA模型,LSTM模型以及ARIMA-LSTM组合模型在亚马逊河流域重建的TWSA(1°×1°)格网图。
具体实施方式
以下将参照附图,对本发明的优选实施例进行详细的描述。应当理解,优选实施例仅为了说明本发明,而不是为了限制本发明的保护范围。
图1为本发明的技术路线图,本发明使用季节性分解时间序列的方法,结合ARIMA模型和LSTM神经网络模型的各自优点,进行新的ARIMA-LSTM组合模型构造。
数据为美国国家航空航天局(NASA)和德国航空航天中心(DLR)在地球系统科学探路者计划下联合开发的重力恢复和气候实验(GRACE)卫星通过测量重力场的不规则变化,以等效水高的形式提供了每月全球陆地水储量变化(TWSA)数据。官方GRACE数据集分别是喷气推进实验室(JPL),德克萨斯大学奥斯汀分校空间研究中心(CSR)和德国地球科学研究中心(GFZ)制作的,分辨率为400km。本发明创造获取了基于CSR在2002年4月至2017年5月(GRACE卫星的服务时间为2002年4月至2017年6月)期间162个月的Level-2球谐系数法(SH)计算的GRACE等效水高数据。SH数据都是Rlease-06版本,CSR SH产品以1°×1°的比例格网化。由于卫星电池和仪器故障,共有20个月的GRACE-TWSA数据丢失。因此在计算TWSA后对缺失部分还采用了三次样条插值来进行补足,增大训练数据量以减小模型的训练难度,共使用了从2002年4月至2017年5月共182个月的数据作为训练样本数据,保证数据的连续性。对于Level-2 CSR SH数据,在地心校正后应用了一些必要的后处理程序,包括球谐系数中C10项需要替换为由Swenson等的方法所计算值和由于GRACE卫星无法确定C20项的精确值,需要卫星激光测距(SLR)得到的解进行替换、半径为300km的高斯平滑滤波进行高阶噪声的去噪处理、应用去相关滤波去除球谐系数的相关性、冰川回弹改正(GIA)、大气负荷校正(GAD)以及背景场更正包括扣除相应的平均值模型。
实施例
首先,采用球谐系数法反演流域的等效水高,通过滤波得到流域的陆地水储量变化的时间序列数据,等效水高的计算公式为:
式中,Δh(θ,λ)为等效水高;θ和λ为待计算点的余纬和经度;a为地球半径;ρ
采用2002年4月至2015年6月共159个月的时间序列数据作为模型训练集,2015年7月至2017年5月共23个月的数据作为模型测试集。模型训练需要的数据包括流域尺度和格网(1°×1°)尺度的陆地水储量变化时间序列,流域尺度为整个流域的格网点值的平均,格网尺度为数据是以1°为单位的点状空间分布,上述数据作为输入变量,使用ARIMA-LSTM组合模型以学习数据的自相关因素并进行预测。测试集用于验证模型的预测效果。
然后,对原始时间序列进行季节性分解,得到具有线性特征的周期项C
TWSA
对于C
使用皮尔逊相关系数(CC)评价预测的TWSA与GRACE-TWSA真实值之间的线性关系,使用纳什效率系数(NSE)用于衡量模型的拟合程度;使用平均绝对值百分比误差(MAPE)来估计预测的TWSA与GRACE-TWSA真实值的偏差,使用均方根误差(RMSE)衡量误差绝对大小,公式如下:
其中,σ
对比例1
使用ARIMA组合模型以学习数据的自相关因素并进行预测,其他步骤与实施例相同。
对比例2
使用LSTM组合模型以学习数据的自相关因素并进行预测,其他步骤与实施例相同。
对实施例和对比例1、对比例2进行了比较,ARIMA模型,LSTM模型以及ARIMA-LSTM组合模型根据历史数据(2002年4月至2015年6月)所重建的2015年7月至2017年5月的区域尺度和格网尺度的从GRACE卫星获得的TWSA数据。采用NSE、CC、RMSE和MAPE四项指标进行模型效果的精度评估和对比分析。
图2为ARIMA模型,LSTM模型以及ARIMA-LSTM组合模型所预测的2015年7月至2017年5月共23个月的全球11个流域和区域的TWSA时间序列。全球11个流域和区域为亚马逊河流域,鄂毕河流域,华北平原,莱纳河流域,叶尼塞河流域,密西西比河流域,刚果河流域,马更些河流域,尼罗河流域,乍得河流域以及伏尔加河流域。
由图2可知,各个模型在各大流域的重建效果均较为良好,且随着预测时间的后移,三种模型的预测精度逐渐下降,而单一模型(ARIMA模型和LSTM模型)下降最为严重,ARIMA-LSTM组合模型下降幅度较小,这一点在亚马逊河流域,叶尼塞河流域,乍得河流域和华北平原最为明显,而在刚果河流域,其时间序列的变化规律更为复杂,统计模型ARIMA模型的效果随时间后移会显著差于包含神经网络的模型。
表1
表2
表3
表4
表1至表4分别为三种模型重建TWSA对比GRACE观测值的NSE值,MAPE值,RMSE值和CC值。根据表1可知,ARIMA-LSTM模型在所有的大型流域的重建效果最好,且72%以上的流域能够达到建模程度80%以上的NSE指标,在所有流域的NSE均值为0.827,远好于ARIMA模型的0.642、LSTM模型的0.668,说明该模型能够同时学习时间序列中的线性关系和非线性关系,根据MAPE指标可以看到在绝大多数流域ARIMA-LSTM模型的相对真值的误差百分比最小,均值为1.03%,小于LSTM模型的2.38%、ARIMA模型的1.70%。而根据RMSE指标,可以看出ARIMA-LSTM模型的绝对误差在所有流域最小,均值为1.673cm,小于LSTM模型的2.453cm、ARIMA模型的2.675cm,在亚马逊河流域3.833cm甚至能够接近ARIMA模型误差(9.211cm)的三分之一。ARIMA模型仅能在多数流域达到50%的NSE指标,在所有流域的NSE均值为0.642,符合ARIMA模型仅能对线性的自相关序列结构具备良好学习性能的情况,根据MAPE和RMSE指标,ARIMA模型(1.70%/2.675cm)与LSTM模型(2.38%/2.453cm)各有优劣,尤其是在亚马逊河流域、鄂毕河流域、密西西比河流域、尼罗河流域以及伏尔加河流域,ARIMA模型的精度更高,因为这些流域的具有线性特征的周期信号明显更强,适合使用该模型进行预测。LSTM模型在绝大多数区域的NSE值超过了ARIMA模型,NSE均值为0.668,说明神经网络对TWSA的预测能力较统计模型更为有效。最后结合各个模型的平均CC指标(ARIMA/0.865,LSTM/0.892,ARIMA-LSTM/0.932)发现无论哪种模型都具有良好的预测能力,其预测值都与GRACE观测值具有强线性相关,ARIMA-LSTM组合模型在72%以上的流域能够达到90%以上的CC指标,这与NSE指标表现一致,而单一神经网络LSTM则只能达到54%,单一ARIMA模型为45%,因此ARIMA-LSTM组合模型表现更为优异,能够进一步提高TWSA预测的效果。
由图3可知,对于各个流域,NSE值通常是单一ARIMA模型<单一神经网络LSTM模型 图4为三种模型在亚马逊河流域重建的格网图,由于亚马逊流域是世界上最大的河流流域,且亚马逊河流域由于水位年变化较大,时空分布季节变化显著,物理信号强,便于模型学习其变化规律,计算的格网图可以直观地表现模型的学习效果。受篇幅限制,选取重建时间段中分布均匀的四个时期(2015年10月,2016年4月,2016年10月,2017年4月),可以看出三种模型在空间上能够较好反应TWSA的趋势性和周期性,同时图像之间具备较高的相关性。ARIMA-LSTM组合模型的结果与真值最为相近,在空间上最为平滑,出现最少的断层,表现了最好的重建效果,同时随着时间推移,误差逐渐累积,与真值的差距变大。ARIMA模型过分强化了信号强度,使整体区域的重建值偏大,同时空间上信号不够平滑,与真值差距较大。LSTM模型尽管能够把握TWSA整体的变化趋势,而且较ARIMA模型的重建结果更平滑,但不够稳定,出现较多的错误信号。 根据上述对比结果,可知: 从重建GRACE TWSA的模型性能指标可以看出ARIMA-LSTM组合模型在TWSA时间序列重建中具有优秀的泛化能力,在多个流域的重建中,均表现了较好的精度,NSE和CC均值达到0.827/0.932,对不同流域的时间序列都有较好效果。ARIMA-LSTM组合模型重建精度稳定,相较于ARIMA模型和LSTM模型存在普遍优势,在不同流域的重建中均优于两种单一模型。 在空间上,ARIMA-LSTM组合模型与单一模型的输出具有相似的空间格局,但与真值的相关性最好,在空间平滑度,趋势和周期上均由于另外两种模型。 综合以上时间序列的折线图,四项指标和格网图,能够发现ARIMA-LSTM组合模型较单一模型能够提高TWSA重建的稳定性,适用性和精度。 以上所述,仅为本发明较佳的一部分具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以组合、等同替换或改变,都应涵盖在本发明的保护范围之内。