一种优化混淆矩阵的双目标有界拒绝分类方法
文献发布时间:2023-06-19 09:58:59
技术领域
本发明涉及机器学习分类方法领域,具体涉及一种优化混淆矩阵的双目标有界拒绝分类方法。
背景技术
拒绝分类是对不确定样本延迟分类的一种方法,对置信度低的不确定样本拒绝分类,能够减少可能的分类错误,降低错分代价。拒绝分类在实际应用中是存在的,如医生根据当前已知的患者信息无法提供有把握的决策时,为防止误诊或漏诊不会立即做出判断,而是推迟决策,通过收集患者更多信息或者专家会诊等,减少不确定性,既而提供准确决策。拒绝分类在这种安全关键领域中具有广泛应用。
两类拒绝分类中,分类规则如下所示:
若样本x属于正类的置信得分s(x)不大于t
这些拒绝分类方法只优化一个固定的综合指标,面对不同应用场景时鲁棒性差。当优化的指标恰是具体应用中需求的,这个分类方法能够提供较优的分类性能;若实际应用中使用的评估指标不是拒绝分类方法的优化指标,那么使用这个拒绝分类方法可能不能得到满意的分类结果。另外,实际应用中代价信息难以获得或估计,优化与代价相关的指标是有局限性的,且当代价信息改变时,需要重新训练拒绝分类器,计算效率降低。
发明内容
任何一个性能评估指标都可以由带拒绝机制的混淆矩阵(简称“拒绝混淆矩阵”,如表1所示)求得,由于拒绝混淆矩阵有四个自由度,至少需要优化四个基本指标,因此,本发明提供了一种优化混淆矩阵的双目标有界拒绝分类方法。
一种优化混淆矩阵的双目标有界拒绝分类方法,包括:
(1)通过优化带拒绝机制的混淆矩阵确定拒绝分类器;
(2)分别约束正类和负类的拒绝率,最小化假阳性率和假阴性率;
(3)利用NSGA-II算法求解优化模型,得到帕累托最优解集;
(4)根据不同的应用场景或条件,从帕累托最优解集中选择最佳拒绝分类器;
(5)利用最佳拒绝分类器对待测样本进行分类,得到该样本的类别:正类、负类或拒绝分类。
本发明的优化混淆矩阵的双目标有界拒绝分类方法,优化模型如下:
min
其中:t表示二维实数空间R
表1两分类问题的带拒绝机制的混淆矩阵
本发明提供的优化模型是多目标优化问题,采用经典的多目标进化算法NSGA-II进行求解。
利用NSGA-II算法求解优化模型的基本步骤包括:
1)采用实数编码的方式对种群中染色体进行初始化;
2)在验证集上计算每个染色体对应的拒绝混淆矩阵;
3)由拒绝混淆矩阵计算fpr和fnr,根据帕累托支配对种群中的染色体进行排序,称为“非支配排序”,输出前沿集;
4)计算同一前沿集中每个染色体的拥挤距离,并按照拥挤距离从大到小排序;
5)采用二进制锦标赛策略从种群中选择较小前沿和较大拥挤距离的染色体,得到新种群,称为“父代种群”;
6)采用模拟二进制交叉和多项式变异从父代种群中产生新种群,称为“子代种群”;
7)从父代种群与子代种群中选择较小前沿和较大拥挤距离的染色体,构成新种群,至此完成一轮迭代,回到步骤2)进行下一轮迭代。
利用NSGA-II算法求解该拒绝分类模型会得到帕累托最优解集。帕累托最优解集中每个解,即每个拒绝阈值向量(t
可以根据不同的应用场景或不同的使用条件,从帕累托最优解集中选择最合适的拒绝分类器:
1)若代价信息已知,选择总代价最小的拒绝分类器:帕累托解集中每个拒绝阈值向量(t
cost(t
+p(+)·CTP·tpr+p(-)·CFP·fpr
+p(+)·CRP·rpr+p(-)·CRN·rnr
其中:p(+)和p(-)分别为验证集中正类和负类的先验概率,CTP、CTN、CFP、CFN、CRP和CRN分别为真阳性、真阴性、假阳性、假阴性、阳性拒绝和阴性拒绝的代价,tpr和tnr分别为真阳性率和真阴性率。每个拒绝阈值向量(t
2)若代价信息未知,选择满足拒绝约束的性能最优的拒绝分类器:提前设定拒绝率上界,得到每个拒绝阈值向量对应的混淆矩阵后,计算阳性拒绝率和阴性拒绝率,排除掉大于设定的拒绝率上界的拒绝阈值向量,在剩余拒绝阈值向量中选择性能(如正确率、AUC等)最优的。
在一优选例中,使用AUC评估性能,则在验证集上计算剩余拒绝阈值向量对应的AUC值,选择其中AUC最大的拒绝阈值向量作为最优拒绝分类器。
在一优选例中,使用错误率评估性能,则在剩余拒绝阈值向量中选择错误率最小的作为最优拒绝分类器。
本发明与现有技术相比,主要优点包括:
(1)本发明提供的拒绝分类方法摆脱了对代价信息的依赖。实际应用中难以获得或估计各种代价的取值,通常设置经验代价,而代价取值范围是实数,因此造成实验验证和应用的不便。另一方面,当代价改变时,以前的优化代价相关指标的拒绝分类方法需要重新训练模型,带来额外的计算代价。本发明提供的优化拒绝混淆矩阵的方法不依赖代价信息,当代价改变时,只需从帕累托解集中重新选择合适的拒绝分类器即可,达到了“一劳永逸”的效果,因此提高了使用的灵活性和计算效率。
(2)本发明提供的拒绝分类方法可以有效处理不平衡数据集。最小化错误率的拒绝分类方法没有考虑类分布差异,处理不平衡集时会出现多数类识别率高,而少数类识别率低的问题。本发明中优化目标是假阳性率和假阴性率,两者都独立于类分布。另外,本发明中拒绝约束是针对每个类别的,所以每个类别的拒绝率都能被超参数有效限定。基于上述两点,本发明提供的的拒绝分类方法更适合处理不平衡集。
(3)本发明提供的拒绝分类方法对多种应用场景具有鲁棒性。第一,若代价信息能够获得,则从帕累托解集中选择总代价最小的拒绝分类器;第二,若代价不可获得,该方法可以提供期望的评估指标最优的拒绝分类器。如,若期望得到较高的分类正确率,则在满足拒绝约束的情况下,可以从帕累托集中选择正确率最高的拒绝分类器;若期望得到高的AUC值,可以从帕累托集中选择满足拒绝约束的AUC最高的拒绝分类器。
附图说明
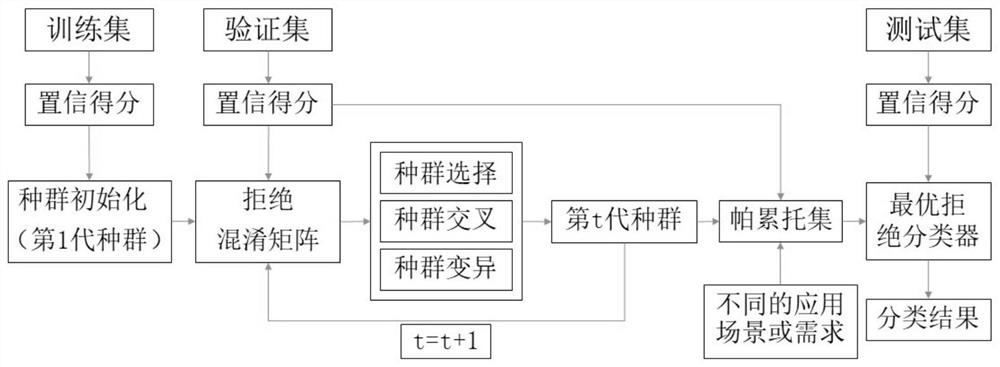
图1为本发明提供的一种优化混淆矩阵的双目标有界拒绝分类方法的训练和测试整体流程图;
图2为本发明提供的一种求解优化混淆矩阵的双目标有界拒绝分类模型的NSGA-II算法的基本步骤;
图3为本发明提供的NSGA-II算法中拥挤距离的示意图;
图4和图5为实施例两个应用场景下使用拒绝分类方法得到的性能-拒绝曲线图。
具体实施方式
下面结合附图及具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。下列实施例中未注明具体条件的操作方法,通常按照常规条件,或按照制造厂商所建议的条件。
图1是本发明提供的一种优化混淆矩阵的双目标有界拒绝分类方法的训练和测试整体流程图。首先,把样本集划分为三个互不相交的子集,其中训练集样本占60%,验证集和测试集样本分别占20%,训练阶段使用训练集和验证集,测试阶段使用测试集。
训练阶段:
(1)计算训练样本的置信得分。本发明中得分分类器采用twin support vectormachine(TWSVM),用所有训练样本学习一个TWSVM,然后将每个训练样本输入到该TWSVM,即可得到每个训练样本属于正类的置信得分。
下述步骤(2)到步骤(8)是图2所示的利用NSGA-II算法求解本发明提供的优化混淆矩阵的双目标有界拒绝分类模型的基本步骤。
(2)种群初始化。本发明设定种群大小为40,即种群包含40个染色体(个体),每个染色体表示一个拒绝阈值向量t=(t
其中rand()表示(0,1)间的随机数。若t
(3)计算拒绝混淆矩阵。首先由步骤(1)中得到的得分分类器求得验证集样本属于正类的置信得分,然后基于验证样本的置信得分,根据分类规则,得到每个验证样本的类别(正类、负类或拒绝分类),从而得到验证集的拒绝混淆矩阵。每个染色体会得到对应的拒绝混淆矩阵。
(4)非支配排序。该部分的目的是为种群中的染色体排序,为选择较优染色体做准备。帕累托支配(Pareto dominance)用来比较向量的优劣,定义如下:向量t帕累托支配向量t′,当且仅当
向量t是非支配的,当且仅当没有向量t′帕累托支配t,所有非支配解向量构成帕累托最优解集。根据步骤(3)得到的40个拒绝混淆矩阵,计算各自的假阳性率fpr和假阴性率fnr,判断每个染色体是否是帕累托支配的,并输出前沿集(front set)
(5)计算拥挤距离。计算所有前沿中每个染色体的拥挤距离:对同一前沿中染色体按照某一目标函数值排序,然后计算与选定的染色体相邻的两个染色体的欧式距离,目标函数空间中每个维度的距离之和即为该染色体的拥挤距离。如图3所示,对于目标函数F
其中,
(6)种群选择。采用二进制锦标赛策略选择染色体:首先从种群中随机选择两个染色体,然后根据前沿排序和拥挤距离大小选择其中一个染色体,即若两个染色体在不同的前沿中,则选择较小前沿的染色体,若两个染色体在同一前沿中,则选择较大拥挤距离的染色体。该过程执行40次,从而得到40个染色体,构成新种群,称为父代种群。
(7)种群交叉和变异。采用模拟二进制交叉和多项式变异。对于模拟二进制交叉,首先按照如下方式产生两个子染色体:
其中:y
其中η
其中,y
其中η
(8)精英选择。从父代种群与子代种群中按照帕累托前沿和拥挤距离比较染色体优劣,从中选择前沿较小,拥挤距离较大的40个染色体构成新的种群,回到步骤(3)进行下一轮迭代。
(9)选择最优拒绝分类器。当达到最大迭代次数,NSGA-II算法停止,这时得到一个帕累托最优解集,其中包含多个染色体,这些染色体必定属于第一前沿。下面说明根据不同的应用场景或需求选择最优拒绝分类器的方法。若代价信息已知,可以选择总代价最小的拒绝分类器:帕累托解集中每个拒绝阈值向量(t
cost(t
+p(+)·CTP·tpr+p(-)·CFP·fpr
+p(+)·CRP·rpr+p(-)·CRN·rnr
其中:p(+)和p(-)分别为验证集中正类和负类的先验概率,CTP、CTN、CFP、CFN、CRP和CRN分别为真阳性、真阴性、假阳性、假阴性、阳性拒绝和阴性拒绝的代价,tpr和tnr分别为真阳性率和真阴性率。每个拒绝阈值向量对应一个总代价,选择其中代价最小的作为最优拒绝分类器。当代价信息未知时,选择满足拒绝约束的性能最优的拒绝分类器:提前设定拒绝率上界,得到每个拒绝阈值向量对应的混淆矩阵后,计算阳性拒绝率和阴性拒绝率,排除掉大于设定的拒绝率上界的拒绝阈值向量,在剩余的向量中选择性能最优的。假如使用AUC评估性能,则在验证集上计算剩余拒绝阈值向量对应的AUC值,选择其中AUC最大的拒绝阈值向量作为最优拒绝分类器;假如使用错误率评估性能,则在剩余向量中选择错误率最小的作为最优拒绝分类器。
测试阶段:
由步骤(1)中得到的得分分类器计算测试集样本属于正类的置信得分,使用步骤(9)选择的最优拒绝分类器按照分类规则对测试样本进行分类,得到一个拒绝混淆矩阵,从而可以计算任何性能评估指标。本发明中使用UCI数据集进行实验,结果表明,在相同拒绝率下,本发明提供的拒绝分类方法能够得到更优的分类性能。
以下通过一个实例说明本发明提供的拒绝分类方法的具体应用。German creditdata是机器学习领域公开数据库UCI中的一个数据集,该数据集包含20维特征,用于判断每个样本信用风险的优劣,即判断信用优良(正类)或信用恶劣(负类)。信用风险的评估关系到企业甚至国家的利益,把信用恶劣的客户评估为信用优良的错分代价远远大于相反情况的错分代价,当没有很大信心评估某个客户的信用风险是优良还是恶劣的时候,可以推迟决策(拒绝分类),避免可能造成的错分代价,因此需要一个性能较优的拒绝分类方法。在German credit data上分别执行本发明提供的拒绝分类方法,以及前述文献(文献[2]:Pietraszek T.On the use of ROC analysis for the optimization of abstainingclassifiers[J].Machine Learning,2007,68(2):137-169;文献[3]:Guan H,Zhang Y,Cheng H D,et al.BA2Cs:Bounded abstaining with two constraints of reject ratesin binary classification[J].Neurocomputing,2019,357(SEP.10):125-134)中的拒绝分类方法,比较性能-拒绝曲线,本发明中性能评估指标采用正确率(accuracy)和AUC。
图4和图5为两个应用场景下使用拒绝分类方法得到的性能-拒绝曲线,横坐标为拒绝参数,即设定的拒绝率上界,纵坐标为不同应用场景下的性能评估指标,图4为使用正确率评估性能得到的正确率-拒绝曲线,图5为使用AUC评估性能得到的AUC-拒绝曲线。图注中BA和BA2Cs分别表示文献[2]和[3]中的拒绝分类方法,DOBA表示本发明提供的拒绝分类方法。在相同拒绝率下,正确率或AUC的值越高,说明分类方法性能越优。从图4和图5中看到,总体来说,当使用正确率时,本发明的拒绝分类方法明显优于BA2Cs;当使用AUC时,本发明的拒绝分类方法明显优于BA。由此可以说明,本发明提供的拒绝分类方法面对不同的应用场景具有鲁棒性。
此外应理解,在阅读了本发明的上述描述内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
- 一种优化混淆矩阵的双目标有界拒绝分类方法
- 一种移动应急电源的双目标优化调度方法