基于机器学习的客户产品评论情绪分析方法
文献发布时间:2023-06-19 10:00:31
技术领域
本发明涉及一种基于机器学习的客户产品评论情绪分析方法。
背景技术
随着技术的发展,Facebook、Twitter、Wikis和在线论坛等社交媒体已经成为客户和企业之间交流的普遍手段。随后,它成为用户和企业在移动环境中通过使用不同的移动设备进行独立合作探索的主要通信模式;产生大量用户生成的内容。作为一个应用程序,许多电子商务网站,如Amazon.com和携程网,允许客户访问一个平台,在那里他们可以发布关于特定产品的评论。根据德勤消费品集团的调查,67%的顾客在购物前浏览了网上评论,82%的顾客根据这些评论做出购买决定,作为其他用户对某些产品的意见。要对反馈做出即时反应,公司必须随时随地执行移动办公,在各部门之间进行移动协同工作,并通过智能移动终端获取客户反馈问题的网络信息获取。组织应检查在线评论的非结构化文本,并提供客户意见的自动分类。因此,关于移动通信;情绪分类已经发展成为学术界和工业界都感兴趣的话题。
由于移动应用的不同目的,现有的研究在不同的粒度级别上处理情绪分类问题,从文档到句子级别。情绪分类的一些早期尝试是基于整个文档中带有情绪的单词的出现,比如“好”和“坏’。然而,这些文档级的分析技术很少通过考虑它们的上下文来改变单个情绪词的极性;使得派生的总体极性评估不那么准确。为了解决这一问题,进一步的研究试图将评论的情绪分类在一个更精细的层次上,即句子层面,并将句子聚合起来,以预测文档的情绪极性。大多数关于智能环境中的感性到文档情绪分类的研究都集中在用英语写的评论上,但汉语有着独特的情绪表达方式,因此这些英语评论的研究结果无法直接应用于汉语反馈。
发明内容
本发明的目的是提供一种基于机器学习的客户产品评论情绪分析方法,以解决现有文档级情绪分析总体极性评估准确不高的问题。
为解决上述技术问题,本发明提供一种基于机器学习的客户产品评论情绪分析方法,包括以下步骤:
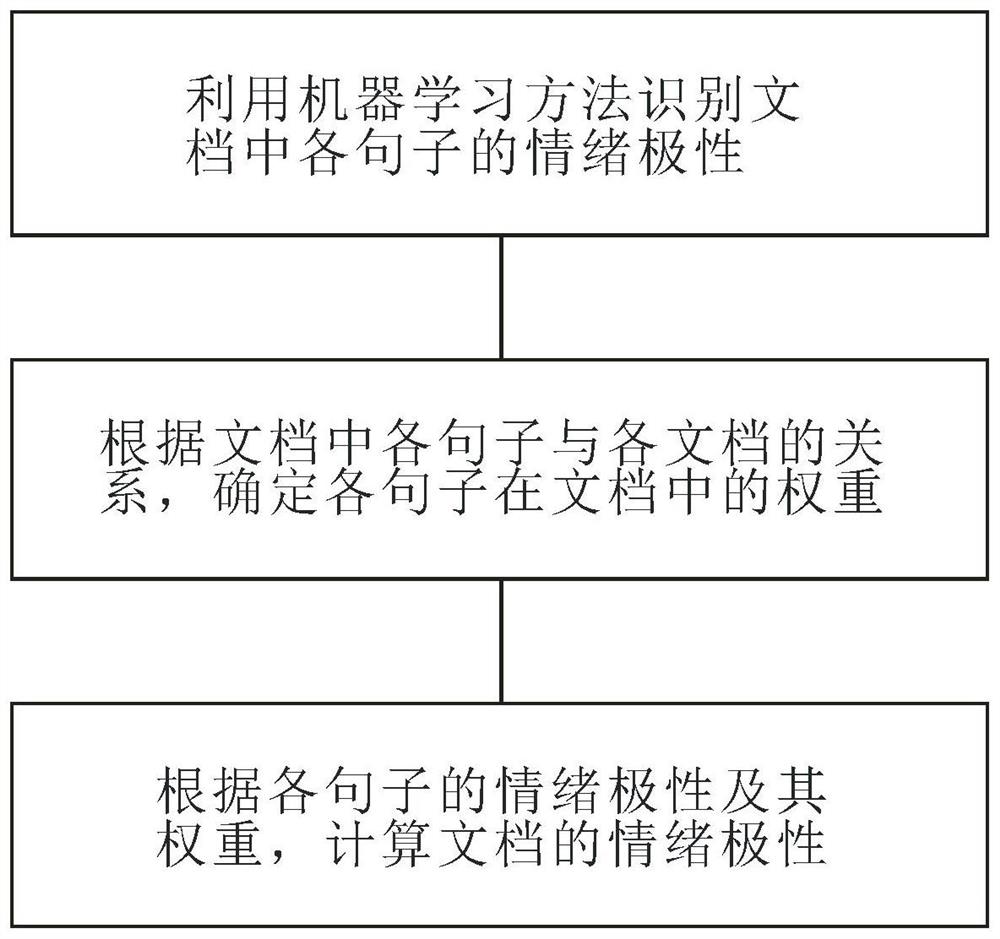
S1:利用机器学习方法识别文档中各句子的情绪极性;
S2:根据文档中各句子与各文档的关系,确定各句子在文档中的权重;
S3:根据各句子的情绪极性及其权重,计算文档的情绪极性。
进一步地,所述步骤S1具体包括:
S11:从句子中选择出具有情绪信息的文本特征;
S12:利用对步骤S11选择出的每个文本特征进行评价,提取所需要的文本特征;
S13:步骤S12提取出的文本特征进行特征加权;
S14:利用分类器对文本特征进行情绪分类,获得句子的情绪极性。
进一步地,每个文档由若干句子组成,故文档c表示为:
c= 其中,c表示文档;s 因此,文献的情绪极性T(c)表示为:
其中,T(c)表示文档c的情绪极性;T(s 进一步地,根据句子在文档中的不同位置赋予不同的权重表示,此时式(1)可扩展为:
其中,s 进一步地,所述文档中各句子与各文档的关系包括:各句子的权重相等、各句子的权重由句子与文档为相同情绪的概率决定或各句子的权重为各句子对具有相同情绪的文档产生相同情绪的影响的概率决定。 进一步地,当文档中各句子的权重相等时,则不同位置的句子的权重表示为: w 进一步地,当各句子的权重由句子与文档为相同情绪的概率决定时,则句子的权重表示为: w 此时,不同位置的句子的权重为:
其中,L 进一步地,当各句子的权重由各句子对具有相同情绪的文档产生相同情绪的影响的概率决定时,则句子的权重表示为:
此时,不同位置的句子的权重为:
本发明的有益效果为:该方法首先利用机器学习方法计算文档中各句子的情绪极性,然后根据句子与文档之间的关系对每个句子进行权重设置,最后汇总句子的加权情绪极性,以预测文档的情绪极性,通过考虑句子与文档之间的关系来对文档的情绪极性进行分析,提高了分析结果的准确性。 附图说明 此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,在这些附图中使用相同的参考标号来表示相同或相似的部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中: 图1为本发明一个实施例的流程图。 具体实施方式 如图1所示的基于机器学习的客户产品评论情绪分析方法,包括以下步骤: S1:利用机器学习方法识别文档中各句子的情绪极性; S2:根据文档中各句子与各文档的关系,确定各句子在文档中的权重; S3:根据各句子的情绪极性及其权重,计算文档的情绪极性。 根据本申请的一个实施例,所述步骤S1具体包括: S11:从句子中选择出具有情绪信息的文本特征;在选择文本特征之前,需要将句子超分成若干单词,并对超分出的单词的磁性进行标记;然后就可以选择形容词、副词和动词作为初始文本特征,需要注意的是,像“not”这样的否定词被认为是情感逆转者,因此本文用手动准备的否定词列表来识别否定,并将它们与后面的形容词或副词作为特征结合起来;例如,如果在“漂亮”之前有一个“不”,则该功能将是“不漂亮”; S12:利用对步骤S11选择出的每个文本特征进行评价,提取所需要的文本特征;具体可利用信息增益(IG)计算每个选出的文本特征的统计值,提取阈值以上的文本特征,取出小于阈值的文本特征。 S13:步骤S12提取出的文本特征进行特征加权;具体可选择通过布尔值(1或0)对特征进行加权,并将其输入到支持向量机(SVM)分类器中; S14:利用分类器对文本特征进行情绪分类,获得句子的情绪极性;其中,基于支持向量机(SVM)的分类器在情感分类方面具有优势,特别是在训练样本有限的情况下。 句子的情感分类示例如表1所示,形容词、副词和动词为选出的文本特征。 表1句情分类举例
根据本申请的一个实施例,每个文档由若干句子组成,故文档c表示为: c= 其中,c表示文档;s 因此,文献的情绪极性T(c)表示为:
其中,T(c)表示文档c的情绪极性;T(s 根据本申请的一个实施例,根据句子在文档中的不同位置赋予不同的权重表示,此时式(1)可扩展为:
其中,s 根据本申请的一个实施例,所述文档中各句子与各文档的关系包括:各句子的权重相等、各句子的权重由句子与文档为相同情绪的概率决定或各句子的权重为各句子对具有相同情绪的文档产生相同情绪的影响的概率决定。 根据本申请的一个实施例,当文档中各句子的权重相等时,则不同位置的句子的权重表示为: w 根据本申请的一个实施例,当各句子的权重由句子与文档为相同情绪的概率决定时,则句子的权重表示为: w 此时,不同位置的句子的权重为:
其中,L 根据本申请的一个实施例,当各句子的权重由各句子对具有相同情绪的文档产生相同情绪的影响的概率决定时,则句子的权重表示为:
此时,不同位置的句子的权重为:
该方法首先利用机器学习方法计算文档中各句子的情绪极性,然后根据句子与文档之间的关系对每个句子进行权重设置,最后汇总句子的加权情绪极性,以预测文档的情绪极性,通过考虑句子与文档之间的关系来对文档的情绪极性进行分析,提高了分析结果的准确性。 最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 基于机器学习的客户产品评论情绪分析方法
- 一种基于机器学习的电商产品客户满意度分析方法