一种基于自监督对比学习的文本分类方法
文献发布时间:2023-06-19 11:54:11
技术领域
本发明涉及自然语言处理的技术领域,更具体地,涉及一种基于自监督对比学习的文本分类方法。
背景技术
目前,文本分类技术大多基于深度神经网络,利用深度神经网络对文本分类时需要大量的有标注的数据。获得大量的标注数据需要高昂的经济开销和密集的人力重复劳作,并且也难以确保标注的准确性。随着机器学习应用领域的逐渐拓展,带标签的领域数据严重匮乏。自监督学习方法在图像处理多项任务上取得了巨大进展,自监督学仅需要较少的数据和标签,就可以提高模型的泛化性能。如何将自监督学习方式运用在自然语言处理领域急需解决的问题。
2021年2月23日公开的中国专利CN112395419A中提供了一种文本分类模型的训练方法及装置、文本分类方法及装置,其中方法包括:根据样本文本集的第一样本文本和标签集确定第一向量组和第二向量组集合;将第一向量组和第二向量组集合输入词级注意力层,得到第三向量集合和第四向量集合;将第三向量集合和第四向量集合输入句级注意力层,得到与标签集相关的第一样本文本向量集;将第一样本文本向量集输入全连接层,得到第一样本文本的预测标签;基于预测标签和标签集中第一样本文本对应的第一标签组对文本分类模型进行训练,直到达到训练停止条件。该方法通过上述步骤一定程度上提高了文本分类模型的准确率,但对文本分类模型进行训练时大量、准确的样本文本和标签集,数据成本高昂;并且标签的准确性会对分类精度造成影响。
发明内容
本发明为克服上述现有技术对文本进行分类时需要大量具有标注的数据的缺陷,提供一种基于自监督对比学习的文本分类方法,可以在少量具有标注的数据下实现快速学习,对待分类文本进行分类,数据成本低,分类结果准确。
为解决上述技术问题,本发明的技术方案如下:
本发明提供一种基于自监督对比学习的文本分类方法,所述方法包括以下步骤:
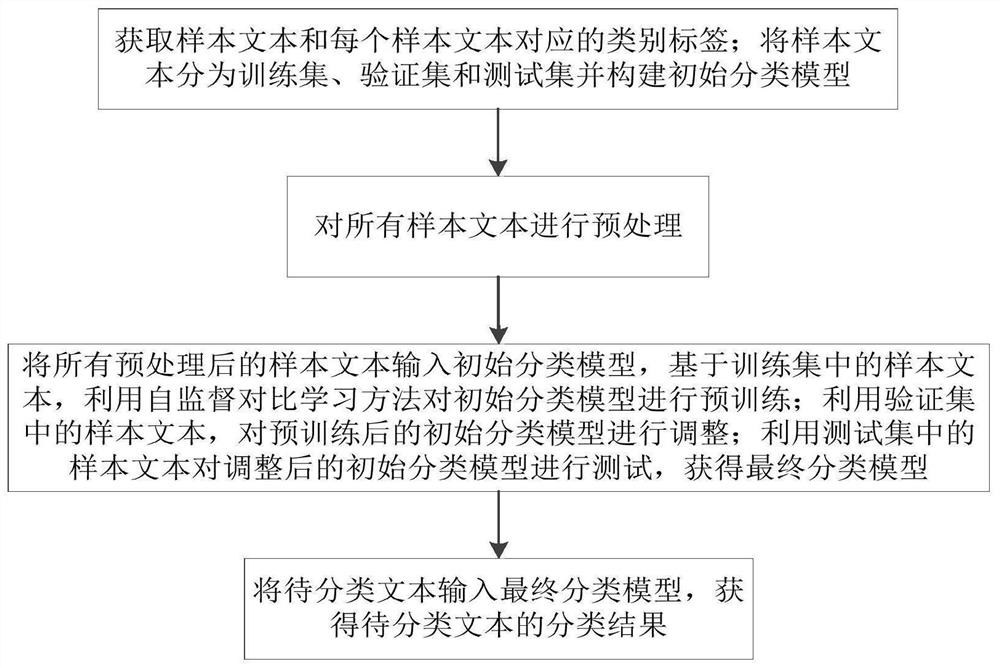
S1:获取样本文本和每个样本文本对应的类别标签;将样本文本分为训练集、验证集和测试集并构建初始分类模型;
S2:对所有样本文本进行预处理;
S3:将所有预处理后的样本文本输入初始分类模型,基于训练集中的样本文本,利用自监督对比学习方法对初始分类模型进行预训练;利用验证集中的样本文本,对预训练后的初始分类模型进行调整;利用测试集中的样本文本对调整后的初始分类模型进行测试,获得最终分类模型;
S4:将待分类文本输入最终分类模型,获得待分类文本的分类结果。
优选地,所述样本文本从现有的Cnews数据集中获取。
优选地,所述获取样本文本对应的类别标签的方法包括:人工标注的方法、采用辅助工具进行半自动标注的方法、采用基于规则和词典进行全自动标注的方法。
优选地,所述预处理的具体方法为:
文本分句:根据标点符号对文本分句;
句子分词:对中文词语根据语义分词,英文根据空格切割单词;
去除停用词:去除对分类无明显帮助的停用词汇、标点符号及数字。
优选地,所述S3中,获得最终分类模型的具体方法为:
S3.1:基于预处理后的样本文本,获得所有样本文本的词向量表征形式;
S3.2:对词向量表征形式的所有样本文本进行特征提取;
S3.3:对特征提取后的样本文本进行池化操作,获得池化后的训练集、验证集和测试集;
S3.4:基于池化后的训练集中的样本文本,利用自监督学习方法对初始分类模型进行预训练;利用池化后的验证集中的样本文本,通过设置第一损失函数,持续对初始分类模型进行调整,当第一损失函数的取值最小时,调整完成;
S3.5:利用池化后的测试数据集中的样本文本,对调整后的初始分类模型进行测试;设置第二损失函数,当第二损失函数的取值最小时,测试完成,获得最终分类模型。
优选地,所述S3.1中,获得样本文本的词向量表征形式的具体方法为:
利用词嵌入技术对预处理后的所有样本文本进行词向量训练,将样本文本向量化编码为x
优选地,所述S3.2中,利用多层CNN对所有样本文本进行特征提取,并根据特征将样本文本分为正类样本文本和负类样本文本。
优选地,所述S3.3中,对特征提取后的样本文本进行池化操作具体为最大池化操作。
优选地,所述S3.4中,第一损失函数为:
其中,x表示样本文本向量,x
优选地,所述S3.5中,第二损失函数为:
其中,C表示样本文本的类别数量,c为某个类别,y
与现有技术相比,本发明技术方案的有益效果是:
本发明通过将少量具有类别标签的样本文本分为训练集、验证集和测试集,首先基于训练集的样本文本,利用自监督对比学习方法对初始分类模型进行预训练,利用验证集中的样本文本,对与训练的初始分类模型进行调整,最后利用测试集中的样本文本对调整后的初始分类模型进行测试,获得最终分类模型;将待分类的文本输入最终分类模型,获得待分类文本的分类结果。在完整的训练过程中,本发明利用少量具有类别标签的样本文本作为输入对初始分类模型进行训练,大大减轻了对大量的、具有准确标注的数据的依赖,减轻了人力标注的重复劳作,可以在少量具有标注的数据下实现快速学习,数据成本低,分类结果准确。
附图说明
图1为实施例所述一种基于自监督对比学习的文本分类方法的流程图;
图2为实施例所述获得最终分类模型的方法的流程图;
图3为传统TextRNN在样本文本每类500个时的学习速度和分类精度示意图;
图4为传统TextCNN在样本文本每类500个时的学习速度和分类精度示意图;
图5为传统SCL-RNN在样本文本每类500个时的学习速度和分类精度示意图;
图6为实施例所述方法在样本文本每类500个时的学习速度和分类精度示意图;
图7为传统TextRNN在样本文本每类1000个时的学习速度和分类精度示意图;
图8为传统TextCNN在样本文本每类1000个时的学习速度和分类精度示意图;
图9为传统SCL-RNN在样本文本每类1000个时的学习速度和分类精度示意图;
图10为实施例所述方法在样本文本每类1000个时的学习速度和分类精度示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例
本发明为克服上述现有技术对文本进行分类时需要大量具有标注的数据的缺陷,提供一种基于自监督对比学习的文本分类方法,可以在少量具有标注的数据下实现快速学习,对待分类文本进行分类,数据成分低,分类结果准确。
为解决上述技术问题,本发明的技术方案如下:
本实施例提供一种基于自监督对比学习的文本分类方法,如图1所示,所述方法包括以下步骤:
S1:获取样本文本和每个样本文本对应的类别标签;将样本文本分为训练集、验证集和测试集并构建初始分类模型;本实施例中,利用有无监督聚类方法构建初始分类模型;
S2:对所有样本文本进行预处理;
S3:将所有预处理后的样本文本输入初始分类模型,基于训练集中的样本文本,利用自监督对比学习方法对初始分类模型进行预训练;利用验证集中的样本文本,对预训练后的初始分类模型进行调整;利用测试集中的样本文本对调整后的初始分类模型进行测试,获得最终分类模型;
S4:将待分类文本输入最终分类模型,获得待分类文本的分类结果。
所述样本文本从现有的Cnews数据集中获取。
所述获取样本文本对应的类别标签的方法包括:人工标注的方法、采用辅助工具进行半自动标注的方法、采用基于规则和词典进行全自动标注的方法。
所述预处理的具体方法为:
文本分句:根据标点符号对文本分句;
句子分词:对中文词语根据语义分词,英文跟换有空格切割单词;
去除停用词:去除对分类无明显帮助的停用词汇、标点符号及数字。
如图2所示,所述S3中,获得最终分类模型的具体方法为:
S3.1:基于预处理后的样本文本,获得所有样本文本的词向量表征形式;
利用词嵌入技术对预处理后的所有样本文本进行词向量训练,将样本文本向量化编码为x
S3.2:对词向量表征形式的所有样本文本进行特征提取;
利用多层CNN对所有样本文本进行特征提取,并根据特征将样本文本分为正类样本文本和负类样本文本。本实施例中,CNN网络的基础参数设定为:输入维度为500,dropout=0.2,filter=256,kernel_size=3/4/5,激活函数使用relu函数。
S3.3:对特征提取后的样本文本进行最大池化操作,获得池化后的训练集、验证集和测试集;
S3.4:基于池化后的训练集中的样本文本,利用自监督学习方法对初始分类模型进行预训练;利用池化后的验证集中的样本文本,通过设置第一损失函数,持续对初始分类模型进行调整,当第一损失函数的取值最小时,调整完成;
第一损失函数为:
其中,x表示样本文本向量,x
S3.5:利用池化后的测试数据集中的样本文本,对调整后的初始分类模型进行测试;设置第二损失函数,当第二损失函数的取值最小时,测试完成,获得最终分类模型。
第二损失函数为:
其中,C表示样本文本的类别数量,c为某个类别,y
在具体实施过程中,从Cnews数据集获取样本文本,分别取每一类500和1000条样本文本,参数设定一致将本实施例的基于自监督对比学习的文本分类方法(SCL-CNN)与传统TextRNN、TextCNN和SCL-RNN进行比较,样本文本每一类为500个时,结果如下表所示,
样本文本每一类为1000个时,结果如下表所示,
表中Batch-size和Epochs为参数,设置保持一致,Acc表示精度,从表中可以看出,本实施例提供的基于自监督对比学习的文本分类方法(SCL-CNN)分类精度高于传统的TextRNN、TextCNN和SCL-RNN的分类精度,并且将样本文本从每类500个提高到每类1000个,没有为本方法带来分类精度的提升,说明本方法在少量具有标注的数据下就可实现对待分类文本的准确分类;
图3-图6中左侧为样本文本每类500个时学习速度的示意图,横坐标为Epochs,纵坐标为第二损失函数的LOSS值;可以看出,利用本实施例提供的方法进行训练时,拐点出现的Epochs值远早于传统TextRNN、TextCNN和SCL-RNN的拐点出现的Epochs值;图3-图6中右侧为样本文本每类500个时分类精度示意图,横坐标为Epochs,纵坐标为分类精度值,可以看出,利用本实施例提供的方法进行训练时,更快达到最大分类精度;
将样本文本从每类500个提高到每类1000个,图7-图10中左侧为样本文本每类1000个时学习速度的示意图,同样可以看出,利用本实施例提供的方法进行训练时,拐点出现的Epochs值远早于传统TextRNN、TextCNN和SCL-RNN的拐点出现的Epochs值;图3-图6中右侧为样本文本每类1000个时分类精度示意图,也可以看出,利用本实施例提供的方法进行训练时更快达到最大分类精度;
综上说明本实施例提供的方法的学习速度远快于传统TextRNN、TextCNN和SCL-RNN的学习速度;
对比图6和图10,将样本文本从每类500个提高到每类1000个,拐点出现的Epochs值和最大分类精度出现的Epochs值没有明显提升,说明本方法在少量具有标注的数据下就可实现快速学习。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 一种基于自监督对比学习的文本分类方法
- 基于对比学习的自监督图像分类方法