红外视频多目标跟踪方法
文献发布时间:2023-06-19 13:45:04
技术领域
本发明属于计算机视觉领域,特别涉及一种红外视频多目标跟踪方法,可用于复杂红外场景中对行人及车辆的多目标实时跟踪。
技术背景
近年来,在目标识别与跟踪任务上主要采用深度学习方法,该方法具有强大的特征建模能力,其主要有如下两类:
第一类是将卷积特征与相关滤波器结合。例如,Danelljan等提出了C-COT算法,通过在连续的分辨率序列中学习,创建时域连续的的相关滤波器,可以将不同分辨率的特征图作为滤波器的输入,使得传统特征和深度特征能够深度结合。这一类方法的缺点是跟踪速度较慢,在跟踪数据集上训练易造成过拟合。
第二类是使用孪生网络的方法。该类方法能极大地增强跟踪速度,使待搜索图像大小不受限制,并且可避免在跟踪数据集上训练造成的过拟合。但此类方法的跟踪模版始终为上一帧的被跟踪目标,对被跟踪帧的目标特征没有预判。
目前,红外视频的跟踪算法大多基于传统非深度学习,例如使用模板匹配法、光流法、粒子滤波的生成式算法,或者使用基于互相关滤波的判别式算法。这类算法在复杂红外场景中目标跟踪精度仍有较大提升空间。而受深度学习在计算机视觉广泛应用的启发,人们尝试将深度神经网络应用到红外目标跟踪以提高算法性能。由于红外视频不同与一般深度学习使用的彩色视频,其目标更易受到周围环境影响,且目标的外观常有较大的变化幅度,主要表现为轮廓变化和灰度分布变化,导致跟踪困难。同时由于红外视频分辨率低、可利用的通道信息少,因而使用参数量较大深度过深的神经网络容易导致模型过拟合,降低跟踪效果。
发明内容
本发明的目的在于针对上述现有技术的不足,提出一种红外视频多目标跟踪方法,以提升跟踪精度,降低过拟合程度。
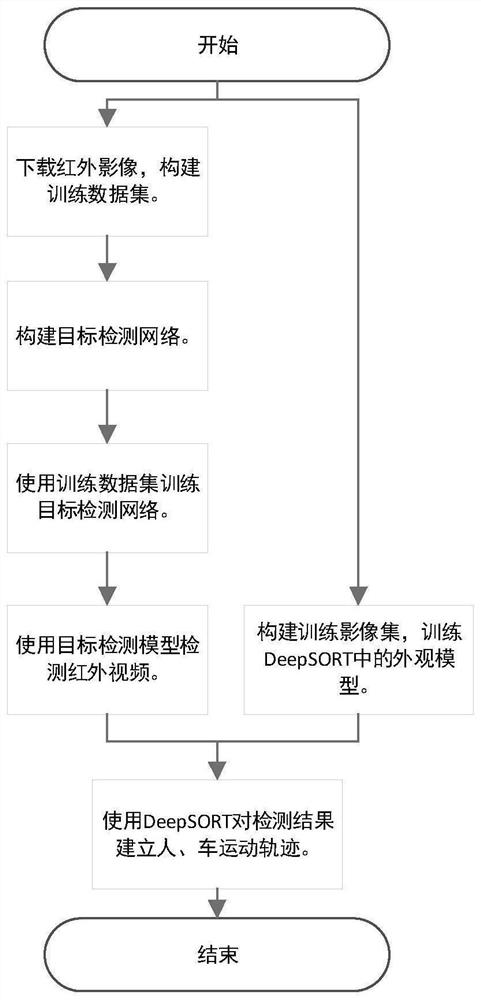
本发明的技术思路是:通过目标检测网络获取视频中出现的所有目标,通过匹配算法建立轨迹跟踪目标。
根据上述思路,本发明的红外视频多目标跟踪方法,包括:
(1)对包含人、车的红外影像进行直方图均衡化,框选出矫正后影像中人、车对象的边界框,随机选取90%的矫正后影像及其对应的标签作为训练数据集;
(2)构建目标检测网络:
使用RFBNet网络作为基础,修改其骨干网络,即将该骨干网络所有卷积模块的第二个卷积层替换为SK注意力层;
在SK注意力层内设置2个卷积分支,分别用于进行卷积核大小为3*3和5*5且分组数为2的分组卷积运算;
设置SK注意力层的特征压缩比例为原通道数的1/2;
(3)使用训练数据集,采用梯度下降法训练目标检测网络,得到训练好的目标检测网络;
(4)将红外视频中每一帧输入训练好的目标检测网络中,输出红外视频中每一帧的人、车检测结果;
(5)选用DeepSORT多目标跟踪算法对检测结果进行数据关联、建立人、车的运动轨迹,得到红外视频多目标跟踪结果。
与现有技术相比,本发明具有如下优点:
1)本发明由于采用了改进后的RFBNet作为目标检测网络,拥有更高目标检测精度。仿真结果表明,在COCO数据集的标准下,红外目标检测的mAP 0.50:0.95相较于原RFBNet网络提升了1.7。
2)本发明由于在SK注意力层中采用了分组卷积运算,相较于同等精度的其他目标检测网络,具有更低的网络的参数量和更快的推理速度,且降低了网络对数据过拟合的可能性。
附图说明
图1为本发明的实现流程图;
图2为本发明中使用的SK注意力层结构图;
图3为本发明中构建的目标检测网络骨干部分结构图;
图4用本发明进行目标检测的仿真结果图;
图5用本发明对红外视频中人、车目标跟踪的效果图。
具体实施方式
以下结合附图,对本发明的实施和效果进行详细描述。
参照图1,本发明的实施步骤如下:
步骤1,获取红外影像,确定训练数据集:
1.1)从网址为
1.2)对FLIR数据集中每一张红外影像都进行如下直方图均衡化过程:
1.2.1)统计红外影像中0至255每个灰度值出现的次数,得到灰度分布直方图H;
1.2.2)根据灰度分布直方图H,计算红外影像中每个像素的新灰度值p:
式中,A为该红外影像像素点的个数,p'为该像素原本的灰度值,H(u)表示灰度分布直方图H中灰度u对应的值;
1.2.3)利用上述公式计算红外影像中所有像素点的新灰度值,得到直方图均衡化后的红外影像;
1.3)随机选取90%直方图均衡化后的影像及其对应的标签作为训练集,剩余10%的影像及其对应标签作为测试集。
步骤2,构建目标检测网络。
本实例在现有RFBNet网络的基础上构建目标检测网络,该网络包含有使用VGG16网络的骨干网络、使用感受野块的颈部网络、头部网络,其中骨干网络包含有6个卷积块,前2个卷积块有两个卷积层,后四个卷积块有3个卷积层,本实例是在其骨干网络上进行如下修改:
2.1)将骨干网络中每个卷积块的第二个卷积层替换为SK注意力层:
参照图2,SK注意力层中包含若干个卷积分支,若干个卷积分支之后为一个全局平均池化层以及两个连接层;其中第一个全连接层进行特征压缩,第二个全连接层生成权值向量,权值向量用于将卷积分支输出的结果进行融合;
对于骨干中每个卷积块的第二个卷积层,使用如下方式将其替换:
2.1.1)设置一个SK注意力层,该SK注意力层的输入输出尺寸与卷积层的输入输出尺寸相同;
2.1.2)在SK注意力层内设置2个卷积分支,分别用于进行卷积核大小为3*3和5*5且分组数为2的分组卷积运算,SK注意力层的特征压缩比例为原通道数的1/2;
2.1.3)将待替换卷积层的输入作为SK注意力层的输入,SK注意力层输出的结果输入到后续的网路结构中,删除待替换的卷积层,得到改进的骨干子网络;
2.2)将改进的骨干子网络与现有RFBNet中原有的使用感受野块的颈部子网络和头部子网络进行级联,得到构建的目标检测网络,如图3所示,其中,图3中经过改进的骨干子网络包含有6个卷积模块,每个卷积模块后为一个最大池化层;前两个卷积块依次包含有一个卷积层和一个SK注意力层,后4个卷积块结构为一个卷积层、一个SK注意力层和另一个卷积层,其结构关系为:
第一卷积层->第一SK注意力层->第一最大池化层->第二卷积层->第二SK注意力层->第二最大池化层->第三卷积层->第三SK注意力层->第四卷积层->第三最大池化层->第五卷积层->第四SK注意力层->第六卷积层->第四最大池化层->第七卷积层->第五SK注意力层->第八卷积层->第五最大池化层->第九卷积层->第六SK注意力层->第十卷积层->第六最大池化层。
步骤3,训练目标检测网络。
使用步骤1中构建的训练集采用梯度下降法对目标检测网络进行训练,其具体实现如下:
3.1)使用带动量的SGD随机梯度下降法作为训练目标检测网络的优化器,设动量值为0.9,网络初始学习率为0.01,网络的损失函数采用RFBNet原有的损失函数;
3.2)在一次迭代内向网络中输入4张训练集内的图片及其对应的标签,经过前向传播后,网络输出本次迭代的损失值,使用该损失值对网络进行反向传播,当训练集内所有图片均输入过一次网络后即完成一个时期的训练;
3.3)在网络训练的前5个时期的每次迭代中,通过如下公式动态调整学习率lr:
其中,i为当前迭代轮数,S为一个时期内的总迭代轮数;
3.4)在之后的训练中保持经过前5个时期调整后的学习率不变,直到时期数分别为150、200、250时,将学习率变为上一时期学习率的1/10;
3.5)使用(3.1)、(3.3)、(3.4)中对动量以及学习率的参数设置,以一个时期为单位重复(3.2)的训练过程,计算每个时期内网络输出损失值的平均值,直到平均损失值停止下降,结束训练,保存网络参数,得到训练好的目标检测网络。
步骤4,选用DeepSORT作为跟踪器,训练其中的外观模型。
所述的DeepSORT是一个多目标跟踪算法,它可以利用一个视频不同帧中待跟踪目标的边界框位置串连得到目标的运动轨迹,其包含两部分:一部分是用于提取目标外观特征的外观模型,另一部分是用于生成运动轨迹的数据关联算法。其中外观模型在使用之前需要训练,其训练方式如下:
4.1)拍摄数段包含人、车的红外视频,对红外视频每一帧中出现的人、车对象进行裁剪并缩放为64*128大小的图片,再将同一对象的图片归为一类,得到训练影像集;
4.2)将训练影像集输入到现有的DeepSORT多目标跟踪算法中,调用该算法中已有的外观模型训练方法,对外观模型进行训练,得到训练好的DeepSORT外观模型。
步骤5,利用训练好的目标检测网络,获得红外影像中人、车的位置标签。
将待跟踪的红外视频的每一帧依次输入到训练好的目标检测网络,网络输出所有的人、车的位置坐标以及它们的置信度和类别;
利用位置坐标采用非极大抑制算法排除其中重复的检测结果,并将检测结果按置信度从高到低排序,删除其中的置信度较低的检测结果,得到每一帧红外影像中人、车的位置标签。
每一个人、车对象的位置标签均含五个参数:x、y、w、h、c,其中:x、y、w、h分别为该对象外接矩形的左上角X轴坐标、左上角Y轴坐标、外界矩形的宽、外接矩形的高,c为该目标的类别。
步骤6,使用DeepSORT多目标跟踪算法进行数据关联,得到人、车运动轨迹。
对于目标检测网络得到的每一帧的所有人、车位置标签,依次进行以下步骤:
6.1)使用当前帧中人、车的位置标签的x、y、w、h参数,在对应的视频帧中裁剪出人、车的图像,并将裁剪图像输入到训练好的外观模型中,得到当前帧的人、车对应的外观特征;计算当前帧所有人、车外观特征与前一帧所有人、车外观特征的余弦距离矩阵M
6.2)利用当前帧之前每一帧中人、车的位置标签,使用卡尔曼滤波预测之前帧中出现过的人、车目标在当前帧的位置标签;计算当前帧人、车预测的位置标签与当前帧人、车位置标签之间的马氏距离矩阵M
6.3)设定阈值t,将马氏距离矩阵M
若b
6.4)利用相似度矩阵M
本发明的算法效果可以通过以下仿真实验进一步说明:
一、仿真环境:
操作系统:Ubuntu20.4.0
CPU:intel Core i7-10700
GPU:RTX3080
深度学习框架:Pytorch
仿真实验1的测试数据集为步骤1中FLIR数据集划分的10%测试集。
二、仿真内容
仿真实验1,用本发明的目标检测网络检测测试数据集,得到红外图像的人、车位置标签,其中三张红外影像的检测结果如图4所示。图4(a)为第一张红外影像中检测到的四个车标签,外接矩形框标出了标签的位置,并在矩形框右上方标注标签类别为车辆;图4(b)为第二张红外影像中检测到两个人标签,外接矩形标出了标签的位置,并在矩形框右上方标注标签类别为人;图4(c)为第三张红外影像中检测到两个人标签,外接矩形标出了标签的位置,并在矩形框右上方标注标签类别为人。
由图4可以得出:本发明的目标检测网络可以检测出红外影像中包含的人、车对象的位置,并能给出该对象的类别。
使用评价指标为COCO数据集评价标准中的AP 0.5:0.95指标,对上述测试数据集检测得到的所有人、车位置标签与测试数据集中提供的人、车位置标签进行精度评价,并将其与原有的RFBNet网络的检测精度进行对比,结果如表1所示:
表1 RFBNet网络与本发明目标检测网络的目标检测精度对比
从表1的结果可以得出:本发明改进后的目标检测网络相较于原RFBNet网络目标检测精度有较大提升:mAP 0.5:0.95指标提升了1.7。
仿真实验2,从网址为http://csr.bu.edu/BU-TIV/BUTIV.html的网络下载BU-TIV数据集,选取其中包含人、车的三条红外红外视频及其人、车轨迹真值作为跟踪测试集。使用本发明的红外多目标跟踪方法对跟踪测试集中的红外视频进行跟踪,其中前两个视频的跟踪结果如图5所示,其中:
图5(a)列举了第一个红外视频的跟踪效果,其中包含了从该视频中抽取出的三帧跟踪结果,使用外接矩形标出了每一帧中跟踪到的人目标的位置,矩形框上方标注了该目标的类别与其代号,不同帧具有相同代号的矩形框中的目标为跟踪到的同一目标;
图5(b)列举了第二个红外视频的跟踪效果,其中包含了从该视频中抽取出的三帧跟踪结果,外接矩形标出了每一帧中跟踪到的人、车目标的位置,在矩形框上方标注了该目标的类别与其代号,不同帧具有相同代号的矩形框中的目标为跟踪到的同一目标。
由图5可以得出:本发明的红外多目标跟踪算法可以对红外视频中出现的人、车目标进行跟踪,得到目标运动轨迹。
使用MOT数据集的多目标跟踪评价方法,对本发明利用跟踪测试集的跟踪结果轨迹与跟踪测试集中提供的人、车轨迹进行红外多目标跟踪的效果精度评价,结果如表2所示:
表2本发明红外多目标跟踪算法的跟踪精度指标
表2中,IDF1为代号的F1得分;IDP为代号的精确度;IDR为代号的召回率;Rcll目标检测的召回率;GT为轨迹真值中轨迹的总数量;FP为误报检测的总数;IDs为跟踪过程中代号错误切换的总次数;MOTA为多目标跟踪的准确度;MOTP为多目标跟踪的精确度。
由表2中结果可以看出:本发明的红外目标跟踪方法对红外视频中的人、车目标有较好的跟踪精度。