一种基于国网营销采集系统的数据同步链路方法及系统
文献发布时间:2024-01-17 01:13:28
技术领域
本发明属于电力系统用户侧技术领域,更具体地,涉及一种网上国网营销采集系统的数据同步链路方法及系统。
背景技术
国网营销采集系统为基础系统主要目的是存储用户的用电信息和账单信息,如图1所示,普通低压居民用户每天的用电量、企业用户每天的用电量、企业级高压用户的用电负荷、企业级高压用户的用电负荷趋势、居民及企业用户每个月的用电账单信息、居民及企业用户阶梯电量账单信息、居民及企业用户计量点账单信息、企业级高压用户趋势信息等,通过每个用户或企业的电表信息以及省侧线下营业厅办理的业务数据,对采集的数据通过用电类别进行归类和区分录入省级电网侧营销采集系统,省级电网侧营销采集系统需要将源数据同步至总部进行汇总和计算展示,目前网上国网总部运行方式为北京、上海双轨运行,待所有省环境都切换至北京环境以后,总部上海环境将成为备用环境。
总部的新型大数据平台中,使用Hive数据库工具和Gbase数据库就显得尤为重要。Hive服务可以提供海量数据仓库的解决方案以及针对大数据的分析建模,Hive处理的数据都存储在HDFS上可以实现存储大批量的数据,采用分布式计算的模式可以大大提高数据的计算能力,Gbase数据库也可以作为数据仓库,Gbase数据库具有联邦架构,大规模并行计算,海量数据压缩、高效存储结构、智能索引、虚拟集群及镜像、灵活的数据分布、完善的资源管理、在线快速扩展、在线节点替换、高并发、高可用性、高安全性、易维护、高效加载等优点。
从当前一般企业情况来看每天涉及的数据量都是上亿级别的,而这种大体量的数据每日都是需要进行数据同步,传输到目标端数据库进行备份存储和相关指标计算。比较常见的传输方式分两种,一种是全量抽取同步,还有一种是将数据按照一定的逻辑进行拆分然后多次进行同步直至同步完成,面对全量抽取同步时如果数据量较小那么效率会比较高,但是面对大体量的数据时候,同步效率就会大打折扣甚至出现无法同步的情况,如果是拆分同步的话,涉及的时间较长会影响整体的业务数据流转。
在国网体系中最为重要的就是用户的电量和账单的数据查询,全国用户的用电信息和账单信息每日增量均在十几亿左右,面对这种体量的数据如果采取传统的数据传输方式会影响整体数据的同步效率,同步缺失或者不及时会影响用户查询的状态。
在当前环境下数据同步过程中可能会出现数据文件丢失,没有监控看同步状态无法及时定位异常情况,数据链路不连续以及数据同步效率低等问题,解决这些问题已经成了信息化数据传输最为重要的一环。
发明内容
为解决现有技术中存在的不足,本发明提供了一种基于网上国网营销采集系统的数据同步链路方法及系统,该数据同步链路方法能够有效解决大批量增量数据的同步,并且能够做到实时监控和备份,对运维人员处理异常的情况起到了至关重要的作用。
本发明采用如下的技术方案。
一种基于网上国网营销采集系统的数据同步链路方法,所述方法包括步骤:
步骤1,在省级电网侧确认需要同步的数据信息;
步骤2,采用OGG+datahub的方式将省级电网侧营销采集系统中的上一天源数据同步至省级电网侧数据中台中的贴源层增量表当日分区内;
步骤3,将数据每天的全量表和增量表合并得到新的全量表,将数据加工并得到当日新的数据放置在ADS层并通过DI同步的方式上传到北京的数据中台;
步骤4,完成同步北京侧数据中台之后,再通过dataworks中的DI同步方式将省级电网侧数据中台ADS层中加工过后的增量数据同步至省级电网侧ADB数据库;
步骤5,省级电网侧每日定时将省侧对应ADB库中业务表create_time字段做为当日日期的增量数据通过省级电网侧的SG-UEP工具同步至省级电网侧kafka平台;
步骤6,省级电网侧将当日加工过后的ADB增量数据传输至kafka后由数据接收转发模块获取并打包数据传输至总部上海侧服务器;
步骤7,总部上海侧接收到省级电网侧上传的每日增量数据文件之后,总部上海侧将每日增量文件通过总部上海侧的数据接收转发模块传输至总部Hive库、Oracle库、Gbase库对应的服务器上;
步骤8,将总部上海侧的Gbase服务器中的增量文件移动至Gbase数据库数据目录并采取load的方式将数据导入到Gbase库;
步骤9,将总部上海侧Hive服务器中的增量文件移动至Hive数据库目录并采取load的方式将数据导入到Hive库中的ods层;
步骤10,将总部上海侧Oracle服务器中的增量文件移动至总部上海侧SG-UEP服务器数据目录并采取数据输入和表输出的方式将数据导入到Oracle查询库;
步骤11,数据完成3个库同步之后,对Hive库的ods层业务数据进行清洗按照相关的数据质量标准剔除异常数据并汇入到DWD层表中,数据清洗完成之后对DWD层的业务数据以及相关的中间表进行关联匹配;
步骤12,总部上海侧Hive数据完成计算之后可通过SG-UEP的方式将新的数据模型同步至总部上海侧Oracle查询库以及通过sftp的方式将数据传输至北京侧服务器;
步骤13,北京侧接受同步过来的数据之后通过ETL工具完成入库操作,完成上海侧北京侧两端同步;
步骤14,后端开发通过调用JDBC连接的方式访问总部Oracle查询库并在App上进行查询展示,通过JDBC的调用满足海量并发查询,其中查询效率取决于表的优化程度,数据同步至Oracle查询库之后需要对表进行分区和索引的优化
优选地,步骤2中,增量表按天、小时、分钟三级分区,不设置生命周期,采取定期人工删除增量数据(默认半年)。
优选地,步骤3中,数据中台在将数据加工去除不符合数据质量规范的业务数据并得到上一天新的数据放置在省级电网侧数据中台ADS层,ADS层为增量数据层存放每日的增量数据并通过DI同步的方式上传到北京总部的数据中台供北京侧环境使用。
优选地,步骤6中,对kafuka中对应topic的消费数据进行采集并以500M一个文件的标准打包数据。
优选地,步骤7中,总部服务器接收到上传的文件之后,通过sftp的模式将文件传输到不同的服务器上。
优选地,步骤13中,北京侧接收同步过来的数据后,通过ETL中的文件输入-表输出的方式将数据导入到北京侧的Oracle数据库。
优选地,步骤14中,数据同步至Oracle查询库后将进一步对表进行分区和索引的优化。
还包括SG-UEP的调度监控模块,该模块可以前台显示数据同步的进度和状态,可以用来实时监控,自研数据接收转发模块能够实现数据的文件备份和补传,以及上传状态进度的监控。
一种基于国网营销采集系统的数据同步链路系统,其中包括省级电网侧营销采集单元、总部北京侧数据处理单元、总部上海侧数据处理单元,其特征在于:
所述数据同步链路系统包括省级电网侧同步数据确认模块、省级电网侧数据同步上传模块、省级电网侧增量链路模块、省级电网侧全量生成模块、省级电网侧增量和全量结合模块、省级电网侧增量上传模块、省级电网侧数据上传监控备份模块、总部上海侧数据接收模块、总部上海侧数据备份监控模块、总部上海侧数据增量数据同步模块、总部上海侧数模计算同步模块、总部上海侧数据文件传输模块、总部北京侧数据接收模块、总部北京侧数据备份监控模块等。
其中所有数据同步模块均为连续且可控的,通过省级电网侧同步数据确认模块将需要同步的数据表文件提炼出来并通过省级电网侧数据同步上传模块将采集到的数据传输至省级电网侧数据中台中的增量表,并将增量表按照一定的数据质量规则与全量表进行汇总实现省级电网侧增量和全量结合模块,数据汇总完成以后通过省级电网侧增量上传模块、省级电网侧数据上传监控备份模块、总部上海侧数据接收模块来完成两级交互的数据同步,总部上海侧数据文件接收完成以后通过总部上海侧数据增量数据同步模块、总部上海侧数模计算同步模块完成总部上海侧增量数据的插入和汇总计算,完成同步和计算之后在通过总部上海侧数据文件传输模块、总部北京侧数据接收模块、总部北京侧数据备份监控模块完成北京和上海侧两级的数据同步链路。
本发明的有益效果在于,与现有技术相比:
1、能够有效解决大批量增量数据的同步,将数据采用增量与全量的结合方式实现增量数据的传输和历史数据的备份,通过设计不同的数据链路模块来优化整个同步链路做到每一个模块都是可控可维护的,并且能够做到实时监控和备份功能,在数据同步过程中某一模块出现问题可以及时定位和处理异常情况,对运维人员及开发人员使用起到了至关重要的作用。
2、本发明方法对大数据量的数据同步和数据处理起到了非常重要的帮助,能够提高数据同步的效率,也能够节省流转的时间,资源占用方面合理分配,能够实现多个数据库的无缝衔接,对数据的的可靠传输提供了一种方法。
附图说明
图1是现有技术中“网上国网营销采集系统”的功能结构示意图;
图2是本发明网上国网营销采集系统的数据同步链路方法流程图;
图3是本发明网上国网营销采集系统的数据同步链路方法省侧架构图;
图4是本发明网上国网营销采集系统的数据同步链路方法总部和省侧整体架构图;
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明的技术方案进行清楚、完整地描述。本申请所描述的实施例仅仅是本发明一部分的实施例,而不是全部实施例。基于本发明精神,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明的保护范围。
如图1所示,本发明所述的网上国网营销采集系统的数据同步链路方法中省级电网侧的营销采集系统包括以下部分:
1.由省级电网侧供电所单位收集低压用户、高压用户、企业用户等电表信息以及相关用户的交费和办理业务信息。
2.省级电网侧供电所单位将收集的数据汇总到省级营销采集系统中
3.营销采集系统根据不同的数据信息按照类别将数据汇入到不同的业务表中,例如:账单基础信息表、电源信息表、计量点电费表、抄表信息表、电量电费表等
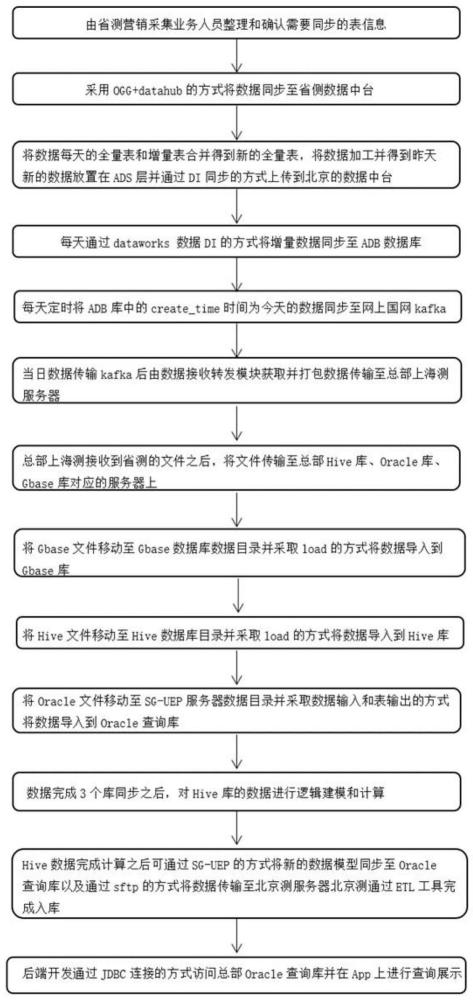
如图2所示,本发明所述的网上国网营销采集系统的数据同步链路方法,包括以下步骤:
步骤1,在省级电网侧确认需要同步的数据信息。
所述数据包括:低压日用能信息数据、高压日用能信息数据、高压日负荷数据、高压负荷趋势数据、账单基础信息数据、电源信息数据、计量点电量电费信息数据、抄表信息数据、电量电费数据等相关业务数据;将需要同步的数据表信息和表结构整理归纳形成相关数据模型文档。
步骤2,采用OGG+Datahub的方式将省级电网侧营销采集系统中的上一天源数据同步至省级电网侧数据中台中的贴源层增量表当日分区内。
先在源端配置OGG的抽取进程以及复制进程,同时安装Datahub插件,修改和配置Datahub相关配置以后在OGG进程里启动Datahub服务并创建MaxComputer的数据归档,Datahub捕获到数据之后会自动同步至MaxComputer中也就是数据中台。增量表按天、小时、分钟三级分区,不设置生命周期,采取定期人工删除增量数据(默认半年)。
步骤3,将数据每天的全量表和增量表合并得到新的全量表,将数据加工并得到当日新的数据放置在ADS层并通过DI同步的方式上传到北京的数据中台。
当上一天省级电网侧营销采集数据都同步至省级电网侧数据中台之后,在数据中台中将营销采集数据的全量表和上一天的增量表合并得到新的全量表,其中增量表为从营销系统每天同步的增量数据,全量表为历史数据和增量数据的结合数据,该全量表记录着对应业务表的全量业务数据,数据中台在将数据加工去除不符合数据质量规范的业务数据并得到上一天新的数据放置在省级电网侧数据中台ADS层并通过DI同步的方式上传到北京总部的数据中台供北京侧环境使用。
步骤4,每天通过DataWorks数据DI的方式将增量数据同步至ADB数据库。
在DataWorks中使用DI工具配置源端表以及目标端的地址可以将整理好的增量数据表同步至ADB数据库。
步骤5,每天定时将ADB库中的create_time时间作为今天的数据同步至网上国网kafka。
数据通过DI工具同步到ADB库中以后,使用SG-UEP工具定时执行相关业务流程,将每日的增量数据同步至Kafka中,这里采用SG-UEP的调度前台页面定时,并且可以通过前台页面实时查看数据抽取同步的状态,如果发现同步异常可以及时定位和处理。
步骤6,当日数据传输至kafka后由数据接收转发模块获取并打包数据传输至总部服务器。
SG-UEP工具完成同步之后,通过数据接收转发模块捕获和打包数据文件,该程序所实现的功能就是数据的采集和打包传输,先访问kafka中的对应Topic,并将消费数据压缩以500M一个文件标准打包数据,打包完成以后可自动传输至总部的服务器地址。
所述数据接收转发模块为自研程序jar包实现,其实现的功能为:从kafka平台消费不同的Topic数据并将数据按照规定的格式形成dbl数据文件,并将数据文件打包进行SFTP数据传输,该微服务程序能够实现数据文件的传输、数据文件的备份、数据传输链路的监控,数据文件的收集等功能,该微服务有数据文件备份目录,将kafka消费过后的数据文件进行本地压缩保留,文件通过压缩的方式来减少对服务器空间的占用,每个表都对应不同的上传日志,通过上传日志能够及时定位和发现异常情况,对于传输异常的数据文件可以将备份目录的文件一键传输,不需要再重新进行消费和源端数据上传。
步骤7,总部上海侧接收到省级电网侧上传的每日增量数据文件之后,总部上海侧将每日增量文件通过总部上海侧的数据接收转发模块传输至总部Hive库、Oracle库、Gbase库对应的服务器上。
总部服务器接收到上传的文件之后,通过sftp的模式将文件传输到不同的服务器上,Gbase数据库作为数据仓库主要实现的功能是源数据的备份和报表的计算,Oracle数据库实现的主要功能是作为查询库使用,将结果数据同步并提供给后端开发调用接口访问前台展示,Hive数据库主要实现的功能是计算大批量的数据模型,将大批量的数据进行合并和清洗,通过计算逻辑完成数据模型的构建,并将结果数据同步至Oracle查询库供前台展示。
步骤8,将总部上海侧的Gbase服务器中的增量文件移动至Gbase数据库数据目录并采取load的方式将数据导入到Gbase库。
数据文件同步之后,采用Gbase加载数据模式,用load命令将数据加载到数据库中。
步骤9,将总部上海侧Hive服务器中的增量文件移动至Hive数据库目录并采取load的方式将数据导入到Hive库中的ods层。
步骤10,将总部上海侧Oracle服务器中的增量文件移动至总部上海侧SG-UEP服务器数据目录并采取数据输入和表输出的方式将数据导入到Oracle查询库。
数据文件同步之后,配置相关的流程,并在调度监控页面上配置定时任务,定时将数据抽取到库中,在监控页面上可以实时查看到数据同步的状态和时间。
步骤11,数据完成3个库同步之后,对Hive库的ods层业务数据进行清洗按照相关的数据质量标准剔除异常数据并汇入到DWD层表中,数据清洗完成之后对DWD层的业务数据以及相关的中间表进行关联匹配。
所述Hive库ods层业务数据的清洗是将采集数据中的计量单位字段为空的更新为0、将当日的计量点电量为负数的数据进行剔除并汇入到DWD层表中。
数据清洗完成之后对DWD层的业务数据以及相关的中间表进行关联匹配,例如:用户注册表、用户交电费表、用户绑定表等中间表,通过不同的产品需求设计对应的业务逻辑,例如:能效账单产品需求,根据能效账单对应的业务模块,对数据进行开发和汇总,编写需求产品的数据计算脚本。
数据完成入库之后,根据业务逻辑对数据进行汇总和清洗建模,例如但不限于创建能效账单的数据模型,首先将采集表根据业务需要去除不需要的表字段和不符合数据标准的数据,其次再将营销账单数据同样进行清洗,将筛选过后的数据汇总到新表里,最后创建计算逻辑脚本,对汇总表的数据进行计算并形成新的结果表模型。
步骤12,总部上海侧Hive数据完成计算之后可通过SG-UEP的方式将新的数据模型同步至总部上海侧Oracle查询库以及通过sftp的方式将数据传输至北京侧服务器。
Hive完成结果表的创建之后,通过SG-UEP工具将结果表数据同步到Oracle查询库并通过sftp方式将表数据传输至北京服务器,这个过程可在调度监控页面上实时查看状态。
步骤13,北京侧接收同步过来的数据之后通过ETL工具完成入库操作,完成上海侧北京侧两端同步。
计算过后的数据模型传到北京之后,通过ETL中的文件输入-表输出的方式将数据导入到北京侧的Oracle数据库。
步骤14,后端开发通过调用JDBC连接的方式访问总部Oracle查询库并在App上进行查询展示。
通过JDBC的调用满足海量并发查询,其中查询效率取决于表的优化程度,数据同步至Oracle查询库之后需要对表进行分区和索引的优化。在整个数据同步过程中使用SG-UEP调度监控模块用来实时监控数据同步的进度和状态。
本发明在步骤5、6中可以实现数据的备份的作用,将数据传输至kafka可以将数据保留,并且通过数据接受转发模块将数据打包和压缩保存在本地,如果某个表某一天的数据出现问题了,可以直接通过数据文件进行补数,大大节省了数据重新加工的时间;步骤7中总部接收到文件之后在总部本地也按照表名分类将文件进行存储,为后续补数提供重要保障;步骤8,步骤9中采用Load的方式入库,可以通过查看后台的运行日志来实时监控数据的同步状态和数据量,并且Gbase数据库作为备份库存储源数据可以为总部的数据提供保障;步骤11在Hive库里计算数据能够大幅度提升数据计算的效率,并且能够通过日志实时查看进度和效率;步骤12,步骤13将新的建模数据同步上海和北京两端,目前网上国网运行上海和北京两侧但是北京侧缺少必要的环境,所以通过此方法能够将北京上海的一些业务数据模型实现同步和使用。
如图3所示,本发明所述的网上国网营销采集系统的数据同步链路方法中省级电网侧的架构图包括以下部分:
1.将省级电网侧营销业务系统增量数据通过OGG+datahub的方式,全量数据通过dataworks数据DI方式同步到省侧数据中台;
2.省级数据中台接入每日的增量数据放到ODS层。
3.将上传的每日增量数据放到ADS层以及ADB库中。
4.将ADB库的数据通过SG-UEP工具进行传输和打包上传。
如图4所示,本发明所述的网上国网营销采集系统的数据同步链路方法中省级电网侧和总部电网侧的整体架构图包括以下部分:
1.由省级电网侧将每日的增量数据汇总到数据中台里的ADS层以及ADB库中。
2.省级电网侧数据中台将ADS层的数据通过DI同步的方式将数据同步到总部北京电网侧的数据中台中。
3.省级电网侧数据中台将ADB库中的每日增量数据上传至kafka中在通过自研数据接收转发模块(dr0005微服务程序)对kafka中的数据进行消费并按照规定的格式将数据汇总成数据文件并进行打包。
4.省级电网侧通过自研数据接收转发模块将打包好的数据文件上传至总部上海侧对应的服务器上。
5.总部上海侧接收到文件以后进行Gbase库、Oracle、Hive库的入库。
6.总部上海侧数据同步完成以后在Hive库中进行数据的计算和建模,将计算好的数据同步至总部上海侧Oracle库以及北京Oracle查询库供APP查询使用。
7.目前网上国网总部环境为上海和北京双轨运行,针对环境已经切换到北京的省,采集营销数据直接从北京数据中台进行同步。
本发明的有益效果在于,与现有技术相比,能够有效解决大批量增量数据的同步,并且能够做到实时监控和备份,对运维人员处理异常及开发人员使用起到了至关重要的作用。
本发明方法对大数据量的数据同步和数据处理起到了非常重要的帮助,能够提高数据同步的效率,也能够节省流转的时间,资源占用方面合理分配,能够实现多个数据库的无缝衔接,对大数据的可靠传输提供了一种方法。
本公开可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本公开的各个方面的计算机可读程序指令。
计算机可读存储介质可以是可以保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以是――但不限于――电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、静态随机存取存储器(SRAM)、便携式压缩盘只读存储器(CD-ROM)、数字多功能盘(DVD)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。这里所使用的计算机可读存储介质不被解释为瞬时信号本身,诸如无线电波或者其它自由传播的电磁波、通过波导或其它传输媒介传播的电磁波(例如,通过光纤电缆的光脉冲)、或者通过电线传输的电信号。
这里所描述的计算机可读程序指令可以从计算机可读存储介质下载到各个计算/处理设备,或者通过网络、例如因特网、局域网、广域网和/或无线网下载到外部计算机或外部存储设备。网络可以包括铜传输电缆、光纤传输、无线传输、路由器、防火墙、交换机、网关计算机和/或边缘服务器。每个计算/处理设备中的网络适配卡或者网络接口从网络接收计算机可读程序指令,并转发该计算机可读程序指令,以供存储在各个计算/处理设备中的计算机可读存储介质中。
用于执行本公开操作的计算机程序指令可以是汇编指令、指令集架构(ISA)指令、机器指令、机器相关指令、微代码、固件指令、状态设置数据、或者以一种或多种编程语言的任意组合编写的源代码或目标代码,所述编程语言包括面向对象的编程语言—诸如Smalltalk、C++等,以及常规的过程式编程语言—诸如“C”语言或类似的编程语言。计算机可读程序指令可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络—包括局域网(LAN)或广域网(WAN)—连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。在一些实施例中,通过利用计算机可读程序指令的状态信息来个性化定制电子电路,例如可编程逻辑电路、现场可编程门阵列(FPGA)或可编程逻辑阵列(PLA),该电子电路可以执行计算机可读程序指令,从而实现本公开的各个方面。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
- 一种基于分布式文件系统的数据同步方法和装置
- 一种基于营销系统不停机发布的增量数据同步方法
- 一种数据同步采集系统及数据同步采集方法