自主机器应用中障碍物检测的距离
文献发布时间:2023-06-19 12:07:15
背景技术
能够正确地检测车辆(例如自主或半自主车辆)与环境中的对象或障碍物之间的距离对于车辆的安全操作至关重要。例如,基于传感器数据的障碍估计的准确距离是纵向控制任务(例如自动巡航控制(ACC)和自动紧急制动(AEB))以及横向控制任务(例如安全检查车道变化以及安全通道更改执行)的核心。
在车辆的环境中计算到对象或障碍物的距离的常规方法依赖于接地平面或地球是平坦的假设。基于该假设,可以使用二维(2D)信息源(诸如2D图像)来建模三维(3D)信息。例如,因为假设接地平面是平坦的,所以传统的系统还假设与检测到的对象对应的二维包围盒的底部位于接地平面上。这样,一旦检测到对象,并且基于该平面假设,简单的几何形状用于计算给定对象或障碍物与车辆的距离。
然而,当限定实际接地平面的实际道路表面弯曲或以其他方式不平坦时,这些传统方法受到影响。例如,当施加接地平面是平坦的假设实际上并不是时,驾驶表面中的曲线导致不准确的预测-例如,高估或低估-相对于环境中的对象或障碍物的距离。在任何一种情况下,不准确的距离估计对车辆的各种操作具有直接的负面后果,从而可能损害横向和纵向控制的安全性,性能和可靠性或警告相关驾驶特征。作为示例,低估的距离可能导致未能接合ACC以及,甚至更加关键地,未能接合AEB功能以防止潜在的碰撞。相反,高估的距离可能会导致在不需要时无法激活ACC或AEB功能,从而对乘客造成潜在的不适或伤害,同时还降低了乘客对车辆安全执行的能力的置信度。
传统系统的另一个缺点是依赖于训练期间使用的相机和部署中使用的相机之间的统一。例如,因为深度神经网络(DNN)可以从对象和周围环境的缩放学习,所以当在部署期间使用的图像数据由具有不同于训练中使用的相机的参数生成时出现限制。例如,训练图像数据中的对象的缩放可以与部署的图像数据中的对象的缩放不同,从而导致DNN相对于对象或障碍物的距离不准确的预测。这些不准确的预测可能导致上面关于车辆各种驱动任务的准确性和有效性的类似问题。
发明内容
本公开的实施例涉及自动机器应用中的障碍物计算的距离。公开了系统和方法,其使用传感器数据(例如LIDAR数据,RADAR数据,SONAR数据,图像数据等等)训练的深度神经网络(DNN)准确且鲁棒地预测对环境中的对象或障碍物的距离。例如,通过使用传感器数据而不是仅用于训练DNN的图像数据,即使对于弯曲或以其他方式不平坦的驾驶表面,DNN的预测也是准确且可靠的。
与传统系统相比,例如上述那些,可以使用一个或更多个深度传感器(例如LIDAR传感器,RADAR传感器,SONAR传感器等等)训练DNN,以使用由车辆的一个或更多个相机生成的图像数据在环境中预测对象或障碍物的距离。这样,通过利用训练期间的地面实况生成的深度传感器,DNN可以在部署中仅使用图像数据准确地预测到环境中的对象或障碍物的距离。特别地,依赖于RADAR数据以援助地面实况生成可能有助于训练DNN以在更大的距离处估计对象,例如距离车辆超过50米。
另外,因为实施例不限于平地估计(传统系统的缺点),无论驾驶表面的拓扑如何,DNN都可能能够鲁棒地预测距离。
编码管线的地面实况数据可以使用来自一个或更多个深度传感器的传感器数据-自动地,没有手动注释,在实施例中-编码对应于训练图像数据的地面实况数据,以便训练DNN单独从图像数据进行准确预测。结果,可以去除手动标记导致的训练瓶颈,并且可以减少训练期。另外,在一些实施例中,可以使用相机自适应算法来克服相机模型的内部特征的方差,从而允许DNN准确地执行,而不管相机模型如何。
在一些实施例中,由于DNN的预测中的潜在噪声的结果,可以在后处理期间执行安全边界计算,以确保计算距离落入安全允许的值范围内。例如,可以利用与对象或障碍物的包围形状对应的驾驶表面和/或数据的形状来确定距离上限和/或距离下限。这样,当DNN的预测在安全允许的范围之外时,距离值可以被限定到距离上限或距离下限。
附图说明
下面参考附图详细描述了用于自主机器应用中的障碍物检测的距离的系统和方法,其中:
图1是根据本公开的一些实施例的用于训练一个或更多个机器学习模型以预测环境中的对象和/或障碍物的距离的过程的数据流程图;
图2是根据本公开的一些实施例的使用传感器数据进行地面实况数据编码的数据流程图;
图3A是根据本公开的一些实施例的一个或更多个激光雷达(LIDAR)传感器生成的地面实况数据的可视化;
图3B是根据本公开的一些实施例的一个或更多个雷达(RADAR)传感器生成的地面实况数据的可视化;
图4是根据本公开的一些实施例的相机适应算法中使用的各种计算的图示;
图5A包括根据本公开的一些实施例的基于变化的传感器参数的一个或更多个机器学习模型的地面实况掩模和深度图预测的可视化;
图5B包括根据本公开的一些实施例的具有变化参数的传感器的失真图和直方图的图示;
图6是示出根据本公开的一些实施例的用于训练一个或更多个机器学习模型以预测环境中的对象和/或障碍物的距离的方法的流程图;
图7是根据本公开的一些实施例的使用一个或更多个机器学习模型预测环境中的对象和/或障碍物的距离的过程的数据流程图;
图8A-8B是根据本公开的一些实施例的基于一个或更多个机器学习模型的输出的对象检测和深度预测的可视化;
图9是示出根据本公开的一些实施例的用于使用一个或更多个机器学习模型预测环境中的对象和/或障碍物的距离的方法的流程图;
图10A是示出根据本公开的一些实施例的用于限定一个或更多个机器学习模型的距离预测的安全边界的计算的图表;
图10B是示出根据本公开的一些实施例的用于安全边界计算的最大向上轮廓的图表;
图10C是根据本公开的一些实施例的计算上安全边界的图示;
图10D是示出根据本公开的一些实施例的安全边界计算的最大向下轮廓的图表;
图10E是根据本公开的一些实施例计算下安全边界的图示;
图10F是根据本公开的一些实施例的安全带图案的图示;
图11是示出根据本公开的一些实施例的使用道路形状的安全边界确定的方法的流程图;
图12是根据本公开的一些实施例的使用与对象对应的包围形状计算安全边界的图示;
图13是示出根据本公开的一些实施例的使用包围形状特性的安全边界确定的方法的流程图;
图14A是根据本公开的一些实施例的示例自主车辆的图示;
图14B是根据本公开的一些实施例的图14A的示例自主车辆的相机位置和视场的示例;
图14C是根据本公开的一些实施例的图14A的示例自主车辆的示例系统架构的框图;
图14D是根据本公开的一些实施例的一个或更多个基于云的服务器和图14A的示例自主车辆之间的通信系统图;以及
图15是适用于实现本公开的一些实施例的示例计算设备的框图。
具体实施方式
公开了与自主机器应用中的障碍物检测的距离相关的系统和方法。尽管可以关于示例自主车辆1400描述本公开(在本文中可选地称为“车辆1400”,“自我车辆1400”或“自主车辆1400”),其示例参照图14A-14D描述,但这不是限制性的。例如,本文描述的系统和方法可以由,但不限于,非自主车辆,半自主车辆(例如,在一个或更多个自适应驾驶员辅助系统(ADAS)中),机器人,仓库车辆,越野车,飞船,船,班车,应急车辆,摩托车,电动或机动自行车,飞机,建筑车辆,水下舰艇,无人机和/或其他车辆类型使用。另外,尽管可以关于自动驾驶或ADAS系统描述本公开,但是这不是限制性的。例如,本文描述的系统和方法可以用于模拟环境(例如,以在模拟期间测试机器学习模型的准确性),在机器人,空中系统,划船系统和/或其他技术领域,例如对感知,世界模型管理,路径规划,避障和/或其他过程。
训练一个或更多个机器学习模型用于距离预测
现在参考图1,图1是根据本公开的一些实施例的用于训练一个或更多个机器学习模型以预测环境中的对象和/或障碍物的距离的过程100的数据流程图。过程100可以包括从车辆1400的一个或更多个传感器生成和/或接收传感器数据102。在部署中,传感器数据102可以由车辆1400在过程100内使用,以预测环境中一个或更多个对象或障碍物(例如其他车辆,行人,静态对象等)的深度和/或距离。例如,预测的距离可以表示在“z”方向上的值,其可以被称为深度方向。传感器数据102可以包括但不限于来自车辆1400的任何传感器(和/或其他车辆或对象,例如机器人设备,VR系统,AR系统等,在一些示例中)的传感器数据102。例如,参考图14A-14C,传感器数据102可以包括由不限于一个或更多个全局导航卫星系统(GNSS)传感器1458(例如,一个或更多个全球定位系统传感器),一个或更多个RADAR传感器1460,一个或更多个超声波传感器1462,一个或更多个LIDAR传感器1464,一个或更多个惯性测量单元(IMU)传感器1466(例如,一个或更多个加速度计,一个或更多个陀螺仪,一个或更多个磁罗盘,一个或更多个磁力计等),一个或更多个麦克风1496,一个或更多个立体声相机1468,一个或更多个广角相机1470(例如,鱼眼相机),一个或更多个红外相机1472,一个或更多个环绕相机1474(例如,360度相机),一个或更多个远程和/或中程相机1498,一个或更多个速度传感器1444(例如,用于测量车辆1400的速度)和/或其他传感器类型生成的数据。虽然主要参考对应于LIDAR数据,RADAR数据和图像数据的传感器数据102,但这不是限制性的,并且传感器数据102可以替代地或另外地由车辆1400,另一车辆和/或另一系统(例如,在模拟环境中的虚拟车辆)的任何传感器生成。
在一些示例中,传感器数据102可以包括由一个或更多个前向传感器,侧视传感器和/或后视传感器生成的传感器数据。该传感器数据102可用于对环境中车辆1400周围的对象的移动的识别,检测,分类和/或跟踪。在实施例中,任何数量的传感器可用于结合多个视场(例如,图14B的远程相机1498,前向立体声相机1468和/或前向广角相机1470的视场)和/或感觉场(例如,LIDAR传感器1464,RADAR传感器1460等)。
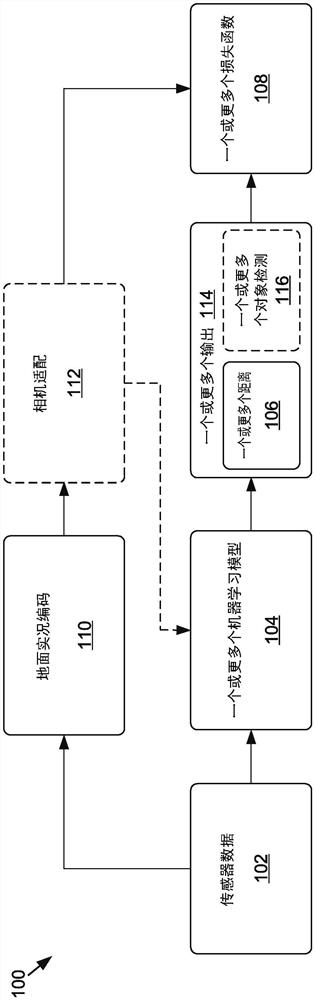
在一些实施例中,可以训练一个或更多个机器学习模型104以仅使用图像数据预测的一个或更多个一个或更多个距离106和/或一个或更多个一个或更多个对象检测116。例如,过程100可用于训练一个或更多个机器学习模型104使用图像作为输入数据以预测环境中一个或更多个对象的一个或更多个距离106(或可以转换为距离的深度图)和/或障碍物。另外,在一些实施例中,可以训练一个或更多个机器学习模型104以本质上计算一个或更多个一个或更多个对象检测116(但是,在一些实施例中,可以通过对象检测器(例如对象检测算法,计算机视觉算法,神经网络等)计算一个或更多个对象检测)。然而,为了更有效地训练一个或更多个机器学习模型104,来自传感器数据102的附加数据-例如LIDAR数据,RADAR数据,SONAR数据等等-可以用于生成对应于图像(例如,通过地面实况编码110)的地面实况数据。作为返回,可以使用地面实况数据来通过利用该补充传感器数据102(例如,LIDAR数据,RADAR数据,SONAR数据等)的附加准确度来提高预测一个或更多个距离106和/或一个或更多个对象检测116时的一个或更多个机器学习模型104的准确性。
关于一个或更多个机器学习模型104的输入,传感器数据102可以包括表示一个或更多个图像的图像数据和/或表示视频的图像数据(例如,视频的快照)。在传感器数据102包括图像数据的情况下,可以使用任何类型的图像数据格式,例如但不限于,诸如联合摄影专家组(JPEG)或亮度/色度(YUV)格式的压缩图像,压缩图像作为来自压缩视频格式(诸如H.264/高级视频编码(AVC)或H.265/高效视频编码(HEVC))的帧,原始图像,如源自红色清晰蓝色(RCCB),红色清晰(RCCC)或其他类型的成像传感器和/或其他格式。另外,在一些示例中,传感器数据102可以在过程100内使用而没有任何预处理(例如,以原始或捕获格式),而在其他示例中,传感器数据102可以经过预处理(例如,噪声平衡,去脱模,缩放,裁剪,增强,白平衡,音调曲线调整等,例如使用传感器数据预处理器(未示出)。如本文所使用的,传感器数据102可以引用未处理的传感器数据,预处理的传感器数据或其组合。
作为非限制性实施例,为了生成用于训练一个或更多个机器学习模型的地面实况数据104,可以根据图2的地面实况编码110的处理过程来执行地面实况编码110。例如,传感器数据102-诸如表示一个或更多个图像的图像数据-可以由对象检测器214使用以检测由图像数据表示的对象和/或障碍物。例如,人类,动物,车辆,标志,杆,交通灯,建筑物,飞船,船和/或其他类型的对象和/或障碍物可以由对象检测器214检测。对象检测器214的输出可以是与由图像数据表示的对象或障碍物对应的包围形状(例如,包围盒,矩形,正方形,圆形,多边形等)的位置。一旦包围形状位置和尺寸是关于特定图像已知的,附加传感器数据102-诸如LIDAR数据和/或RADAR数据,作为非限制性示例-可用于确定与相应包围形状对应的对象或障碍物的距离。这样,可能难以仅使用图像数据来准确地确定对象或障碍物的距离-或者另一二维表示-该附加传感器数据102可用于增加相对于图像内的对象或障碍物的距离的预测准确度。
在一些实施例中,地面实况编码110可以自动发生而没有手动和/或人的标记或注释。例如,因为来自一个或更多个LIDAR传感器,RADAR传感器,SONAR传感器等的世界空间输出到一个或更多个相机的图像空间输出的转换可能已知,并且因为图像空间内的包围形状的位置和尺寸已知,距离(例如,一个或更多个LIDAR距离216,一个或更多个RADAR距离218等)可以与图像内的对象和/或障碍自动相关。作为示例,世界空间中的到一个或更多个对象的一个或更多个距离被确定为对应于与对象的包围形状相关联的图像空间区域,一个或更多个距离可以与对象相关联用于地面实况编码110的目的。在一些示例中,单个距离值可以与每个对象相关联,而在其他示例中,对应对象的距离可以基于LIDAR传感器,RADAR传感器,SONAR传感器等的变化距离输出而变化。
在一些实施例中,根据由一个或更多个LIDAR传感器1464生成的LIDAR数据确定的一个或更多个LIDAR距离216可用于距离的地面实况编码110。例如,并且参照图3A,分别对应于对象306A-306E的包围形状304A-304E可以由对象检测器214生成并与图像302相关联。另外,LIDAR数据-由在图3A的可视化中的LIDAR点310表示-可以与图像302相关联。例如,如本文所述,可以使用LIDAR传感器1465和/或生成图像302的相机内在和/或外在参数(例如在校准之后)知道或确定LIDAR数据的世界空间位置和相应图像空间位置之间的转换。因此,因为世界空间和图像空间之间的这种关系是已知的,并且因为可以基本上同时捕获LIDAR数据和图像数据,LIDAR数据距离预测可以与图像302中各种对象306(或它们的相应包围形状304)相关联。
尽管LIDAR点仅在包围形状304内示出,但这并不旨在限制并且仅用于说明目的。在一些示例中,可以生成LIDAR点以对应于整个图像302,或者对应于图像302的附加或替代部分而不是图3A示出的可视化。
在一些实施例中,可以针对每个对象306生成尺寸等于或小于与对象对应的包围形状304的裁剪包围形状308。例如,因为由对象检测器输出的包围形状304(例如,对象检测神经网络,计算机视觉算法或另一种对象检测算法)可以包括不属于对象306或障碍物的环境的附加部分。这样,并且努力提高与对应于对象306或障碍物的图像302的像素的LIDAR数据的深度值的协调的准确性,可以在包围形状304内创建裁剪包围形状308。
在一些示例中,裁剪包围形状308的尺寸可以基于对象306与参考位置的距离(例如,来自自我车辆、来自相机、来自LIDAR传感器等)来确定,这样当对象远离参考位置时,裁剪量会发生变化。例如,随着对象306的距离增加,裁剪的数量,百分比(例如,包围形状304的百分比)或比率(裁剪包围形状308与裁剪形状304的尺寸比率,反之亦然)可能会减小,反之亦然。在这样的示例中,可以存在根据距离(例如,使用一个或更多个等式,曲线,关系,函数等)的裁剪的量、百分比或比率的计算变化,或者可能存在区域,其中特定距离区域对应于一定量、百分比或比率的裁剪。例如,在0-10米的第一距离范围内,裁剪可能为50%,在10-20米处,裁剪可能为40%,在20-40米,裁剪可能为35%,等等。
在一些实施例中,裁剪包围形状308的尺寸可以不同地确定裁剪包围形状308的不同侧面或边缘。例如,用以生成相应的裁剪包围形状308的包围形状304的底部裁剪可以是与顶部裁剪、左侧裁剪和/或右侧裁剪的不同量、百分比或比率,用以生成相应的裁剪包围形状308的包围形状304的顶部裁剪可以是与底部裁剪、左侧裁剪和/或右侧裁剪的不同的量、百分比或比率。例如,底部裁剪可以是每个裁剪包围形状308的设定量、百分比或比率,而顶部裁剪可以基于某些因子或变量(例如距离参考位置的距离,对象的类型等)来改变,或相反亦然。作为非限制性示例,底部裁剪可以始终为10%,而顶部裁剪可以在10%和20%之间的范围内,其中基于对象306与参考位置的距离的一些函数来确定范围内的值。
在至少一个实施例中,用于确定对象306的距离的LIDAR点310可以是与裁剪包围形状308对应的LIDAR点310。结果,在这样的实施例中,被确定为对应于对象306的深度或距离实际上对应于对象306的可能性增加了。在其他实施例中,用于确定对象的距离的LIDAR点310可以是对应于包围形状304的LIDAR点310(并且在这样的实施例中可以不使用或不生成裁剪包围形状304)。与每个对象306相关联的距离(对象306A为10.21米(m),对象306B为14.90m,对象306C为24.13m,对象306D为54.45m,以及对象306E为58.86m)可以使用与相应的包围形状304和/或裁剪包围形状308相关联的一个或更多个LIDAR点310来确定。例如,与包围形状304和/或裁剪包围形状308内的每个LIDAR点310相关联的距离可以被平均以生成最终距离值。作为另一示例,可以使用最接近包围形状304和/或裁剪包围形状308的质心的LIDAR点310来确定最终距离值。在另一个示例中,LIDAR点310的组或子集-例如包围形状304和/或裁剪包围形状308的质心附近的区域内的子集-可以用于确定对象306的最终距离值(例如,通过平均,加权和/或以其他方式使用与LIDAR点310的每个组或子集相关联的距离值来计算最终距离值)。
另外,在一些实施例中,为了帮助降低投影到图像空间的LIDAR点310中的噪声,可以应用滤波算法以去除或滤除噪声的LIDAR点310。例如,但不限于随机样本共识(RANSAC)算法可以应用于群集相关的相机到LIDAR数据点,以滤除噪声LIDAR点310。由于使用过滤算法(例如RANSAC),在给定包围形状304和/或裁剪包围形状308内的幸存LIDAR点310可以被解释为远离相机或其他参考位置的公共距离。
在一些实施例中,从由一个或更多个RADAR传感器1460生成的RADAR数据确定的一个或更多个RADAR距离218可以用于距离的地面实况编码110。例如,并且参照图3B,分别对应于对象306A-306E的包围形状304A-304E可以由对象检测器214生成并与图像302相关联。另外,在图3B的可视化中由RADAR点312表示的RADAR数据可以与图像302相关联。例如,如本文所述,可以使用RADAR传感器1460和/或产生图像302的相机的内在和/或外在参数(例如,在校准之后)已知或确定RADAR数据的世界空间位置和相应图像空间位置之间的转换。在一些实施例中,可以使用RADAR目标群集和跟踪来确定RADAR目标群集和跟踪来确定RADAR点312和对象306之间的关联或对应的包围形状304。因此,因为已知世界空间和图像空间之间的这种关系,并且因为RADAR数据和图像数据可以基本上同时捕获,所以RADAR数据距离预测可以与图像302中各种对象306(或它们的相应包围形状304)相关联。
尽管RADAR点312仅在包围形状304内示出,但这并不旨在限制并且仅用于说明目的。在一些示例中,可以生成RADAR点以对应于整个图像302,或者对应于图像302的附加或替代部分而不是图3B示出的可视化。
在一些实施例中,类似于本文参照图3A所描述的,可以针对尺寸等于或小于与对象对应的包围形状304的每个对象306生成裁剪包围形状308(图3B中未示出)。在这样的实施例中,并且努力提高与对应于对象306或障碍物的图像302的像素的RADAR数据对应的深度值的准确性,可以在包围形状304内创建裁剪包围形状308。因此,在至少一个实施例中,用于确定对象306的距离的RADAR点312可以是对应于裁剪包围形状308的RADAR点312。
与每个对象306相关联的距离(例如,对象306A为13.1m,对象306B为18.9m,对象306C为28.0m,对象306D为63.3m,对象306E为58.6m)可以是使用与相应的包围形状304和/或裁剪包围形状308相关联的一个或更多个RADAR点312确定。例如,与包围形状304(例如,图3B中的RADAR点312A和312B)和/或包围形状308内的每个RADAR点312相关联的距离可以平均为生成最终距离值。作为另一示例,可以选择单个RADAR点312以用于计算最终距离值。例如,如图3B所示,RADAR点312A可以用于对象306A(如通过交叉阴影线所示),而RADAR点312B可能不使用。例如,置信度可以与相机到RADAR点相关联,使得可以选择较高的置信度点(例如,可以在RADAR点312B上选择RADAR点312A)。可以使用任何计算来确定置信度,例如但不限于,与包围形状304和/或裁剪包围形状308的质心的距离。
一旦使用LIDAR数据和/或RADAR数据(和/或SONAR数据,超声数据等)对每个对象306确定了最终距离值,可以确定对每个物体306使用的最终距离值中的哪一个。例如,对于每个对象306,可以确定是否使用一个或更多个LIDAR距离216,一个或更多个RADAR距离218和/或其组合来生成用于生成地面实况深度图222。在仅从一个深度传感器模态(例如,RADAR或LIDAR)计算特定对象306的距离的情况下,与对象306相关联的距离可以是距离一个深度传感器模式的距离。在两个或更多个模式已经计算特定对象306的距离中,可以使用噪声阈值220来确定用于距离值的一个或更多个模态。在一些非限制性实施例中,噪声阈值220可以被优化为超参数。尽管可以使用任何数量的深度传感器模态,但是在使用RADAR和LIDAR的示例中,可以在另一个模型上选择单个模态,其中两个都具有对象的相应深度值。例如,可以在一个或更多个RADAR距离218上选择一个或更多个LIDAR距离216,反之亦然。在其他示例中,可以在阈值距离下方选择一个模态,并且可以超过阈值距离选择另一个。在这样的示例中,一个或更多个LIDAR距离216可以用于更靠近的距离(例如,在相机或其他参考位置的40米之内),并且一个或更多个RADAR距离218可以用于更远的距离(例如,距离相机或其他参考位置远于40米)。以这种方式使用阈值距离可以利用不同距离范围的各种深度传感器模态的准确度。在至少一个实施例中,一个或更多个LIDAR距离216和一个或更多个RADAR距离218,其中两者都被用于对象306,可以平均或加权以计算单个组合距离值。例如,两个距离可以用相等的权重平均,或者一个模态可以加权大于另一个。在使用加权的情况下,每种模态的权重的确定可以是恒定的(例如,LIDAR 60%,RADAR40%),或者可以根据一些因子(例如,距离(在相机其他参考位置的50米范围内,LIDAR权重70%,RADAR权重30%,当相机或其他参考位置超过50米,LIDAR权重40%,RADAR权重60%))而变化。这样,可以使用一个或更多个深度传感器模态来确定特定对象306的哪个距离值是最终距离值,并且可以取决于各种因素(例如,来自各种深度传感器模态的数据的可用性,对象与参考位置的距离,数据的噪声等)。
在一些示例中,通过在对象轨道上应用时间域状态估计器(基于运动模型)可以进一步增强一个或更多个LIDAR距离216和/或一个或更多个RADAR距离218。使用这种方法,可以滤除从LIDAR和/或RADAR读取的噪声。状态估计器可以进一步模拟状态的协方差,该状态可以表示地面实况深度值上的不确定性的量度。例如,可以在一个或更多个机器学习模型104的训练和评估中使用这种措施,例如,通过对高不确定性样本的权重衰减损失。
一旦为对象306选择了一个或更多个最终距离值,就可以用一个或更多个最终深度值编码图像302的一个或更多个像素以生成地面实况深度图222。在一些非限制性实施例中,为了确定用于对象306编码的一个或更多个像素,与包围形状304和/或裁剪包围形状308相关联的每个像素可以用一个或更多个最终距离值编码。然而,在这样的示例中,其中两个或更多个包围形状304和/或裁剪包围形状308至少部分地重叠(例如,一个包围形状304遮挡另一个),使用包围形状304和/或裁剪包围形状308的每个像素可以导致一个或更多个对象306未在地面实况深度图222中充分表示。因此,在一些实施例中,可以为每个对象生成形状-诸如圆形或椭圆形。在一些示例中,形状可以以包围形状304和/或裁剪包围形状308的质心为中心。通过生成圆形或椭圆形,闭塞的潜力导致地面实况深度图222中缺乏对象306的表示可能减少,从而提高了每个对象306在地面实况深度图222中被表示的可能性。结果,地面实况深度图222可以表示编码到图像(例如,深度图图像)的地面实况距离。然后,地面实况深度图222(或深度图图像)可以用作训练一个或更多个机器学习模型104的地面实况,以使用由一个或更多个相机生成的图像预测到对象的距离。这样,一个或更多个机器学习模型104可以训练以预测-在部署中-与由车辆1400(和/或其他车辆类型,机器人,模拟车辆,水船,飞机,无人机等)捕获的图像中描绘的对象和/或障碍物对应的深度图。
关于一个或更多个对象检测116的预测的地面实况编码110可以包括标记或注释,传感器数据102(例如,图像,深度图,点云等)具有包围形状和/或相应的类标签(例如,车辆,行人,建筑,飞机,船只,路牌等)。这样,可以使用一个或更多个损失函数108比较地面实况注释或标签与一个或更多个机器学习模型104的对象检测的预测,以更新和优化一个或更多个机器学习模型104用于预测对象和/或障碍物的位置。
关于自动(例如,用于编码地面实况深度图222)和/或手动生成地面实况注释,在一些示例中可以在绘图程序(例如,注释程序),计算机辅助设计(CAD)程序,标签程序,适用于生成注释的另一种类型的程序内和/或可以手动绘制生成用于训练图像的注释。在任何示例中,注释可以综合产生(例如,从计算机模型或渲染生成),实时产生(例如,由真实世界数据设计和产生),机器自动化(例如,使用特征分析和学习来从数据提取特征然后生成标签),人类注释(例如,标签或注释专家,定义标签的位置),和/或其组合(例如,人制定一个或更多个规则或标签约定,机器生成注释)。在一些示例中,LIDAR数据,RADAR数据,图像数据和/或其他传感器数据102可以用作一个或更多个机器学习模型104的输入和/或用于生成在虚拟或模拟环境中可以生成的地面实况数据。例如,关于虚拟车辆(例如,汽车,卡车,水船,建筑车辆,飞机,无人机等),虚拟车辆可以包括虚拟传感器(例如,虚拟相机,虚拟LIDAR,虚拟RADAR,虚拟SONAR等)捕获虚拟或模拟环境的模拟或虚拟数据。这样,在一些实施例中,除了或替代地真实世界数据被用作一个或更多个机器学习模型的输入和/或用于地面实况生成,可以使用模拟或虚拟传感器数据,因此包括在传感器数据102内。
再次参考图1,可以在一些实施例中执行相机自适应112,以便使一个或更多个机器学习模型104针对底层相机内在特征是不变的。例如,为了考虑与参考位置(例如,相机)的相同距离的类似对象的潜在挑战,根据相机参数(例如,视场)不同地出现,可以使用相机自适应算法来启用相机内在不变性。如果未考虑相机内在参数的方差,针对到对象或障碍物的距离估计解决方案,一个或更多个机器学习模型104的性能可以降低。
在一些实施例中,相机自适应112可以包括将缩放因子应用于基于相机的图像标签。作为非限制性示例,如果使用具有60度视场的相机作为参考相机,则可以将2x的乘数应用于具有120度场的相机生成的完全相同场景的图像的标签,因为与参考相机生成的那些相比,该相机生成的对象将看起来一半的尺寸。类似地,作为另一个非限制性示例,如果使用相同的参考相机,则可以将负2x的乘数应用于具有30度视场的相机生成的完全相同场景的图像的标签,因为与参考相机生成的那些相比,该相机生成的对象将看起来两倍的尺寸。
在至少在实施例中,相机自适应112包括生成缩放和失真图作为对一个或更多个机器学习模型104的额外输入。这可以允许相机模型信息作为输入可用与学习-如图1中所示虚线箭头从相机自适应112到一个或更多个机器学习模型104。例如,参考图4,图4是根据本公开的一些实施例的相机自适应算法中使用的各种计算的图示400。参照图示400,x(例如,x轴),y(例如,y轴)和z(例如,z轴)表示相机坐标系中的位置的3D坐标,而u(例如,u轴)和v(例如,v轴)表示相机图像平面中的2D坐标。位置p表示2矢量[u,v]作为图像平面中的位置。在u
这样,图4的图示400表示允许将相机建模为C的函数的坐标惯例(建模或表示相机的函数),其映射3D光线(θ,φ)(例如,沿对象和/或特征方向铸造)图像平面上的2D位置(u,v)。如果对象或特征位于3D方向(θ,φ),则其在相机传感器上的图像将位于像素(u,v)=C(θ,φ),其中C是表示或模拟相机的函数。结果,2向量(3D方向)被视为输入以生成2向量(在传感器上的2D位置)。类似地,因为C是可逆的,所以存在逆[θ,φ]=C
C的局部衍生物可用于计算局部放大因子m,如下面的等式(1)所示:
其中逆函数C
在一些实施例中,一个或更多个机器学习模型的初始层104任务有特征提取,对象检测(在实施例中该特征是一个或更多个机器学习模型104的任务内部)和/或其他任务,也可以是扩展不变的并且即使没有相机自适应112也可以很好地工作。结果,可以使用相机自适应112确定的相机信息更深入地注入网络(例如,在一个或更多个层进一步进入一个或更多个机器学习模型的架构,在特征提取,对象检测和/或其他层之后),其中特征图尺寸可以远小于早期的层。这些更深层(例如,卷积层)的输入特征映射可以用m(u,v)来增强,以使这些层有任务的深度回归来学习适应相机模型。
最终,可以生成单个特征图,m(u,v),并将其提供给一个或更多个机器学习模型104作为对象如何通过不同的相机解决依赖性的额外提示。这可以使单个机器学习模型104能够从具有不同相机参数的不同相机获得的图像可靠地预测距离,例如不同的视场。在训练期间,然后可以使用空间增强(缩放)应用于学习鲁棒深度回归来使用多个相机。空间增强不仅转换图像,还转换相机模型函数C或其逆函数。在推理期间,如本文更详细描述的,相机模型可用于计算固定的(例如,在部署中,所使用的相机可以是恒定的)放大特征图,m(u,v),然后可以与由一个或更多个机器学习模型104的一个或更多个层(例如,卷积层)生成的输入特征映射连接。
示出具有相机自适应112的地面实况编码110,如图5A和5B中的非限制性示例。例如,图5A包括根据本公开的一些实施例的基于变化的传感器参数的一个或更多个机器学习模型的地面实况掩模和深度地图预测的可视化。地面实况深度图502A,502B和502C是图2的地面实况深度图222的示例可视化,并分别对应于图像506A,506B和506C。作为示例,可以使用120度视场相机捕获图像506A,可以使用60度视场相机捕获图像506B,并且可以使用30度视场相机捕获图像506C。预测深度图504A,504B和504C分别对应于图像506A,506B和506C的一个或更多个机器学习模型104的预测。对象508A,508B和508C全部距离参考位置(例如,相机,一个或更多个其他传感器,车辆1400等的参考位置)大致相同的绝对距离,但由于不同的视场,在图像506A,506B和506C中显示不同的尺寸或维度。然而,如每个预测深度图504中的圆形所示,对象508全部正确预测与参考位置大致相同的绝对距离。随机缩放增强也可以应用于图像506,并且因为相机模型可以基于增强来调整,预测的深度图504仍将正确识别对象508。
虽然为了清楚起见没有突出显示或用图5A中的圆标识,图像506中的每个其他对象也在地面实况深度图502中以及预测的深度图504中表示。
作为缩放和失真图的示例。图5B包括根据本公开的一些实施例的具有变化参数的传感器的失真图和直方图的图示。例如,失真图520A可以表示具有30度视场的相机的失真图,失真图520B可以表示具有60度视场的相机的失真图,并且失真图520C可以表示具有120度视场的相机的失真图。与其相关联的是分别缩放图522A,522B和522C,其对应于通过相机的视场(例如,如图像空间中所示)的深度或距离值的缩放量。例如,关于失真图520A,来自缩放图522A的缩放因子全部小于1.0,以考虑相对于参考相机的对象的增加尺寸。作为另一示例,关于失真图520C,来自缩放图522C的缩放因子包括大于1.0的值,以考虑用具有120度视场的相机捕获的对象的看似较小的尺寸,尤其是在围绕视场的外部部分。直方图542A,524B和524C分别对应于失真图520A,520B和520C,示出了与失真图520对应的缩放变化。
再次参考图1,一个或更多个机器学习模型104可以用作由传感器数据102表示的一个或更多个图像(或其他数据表示)的输入以生成一个或更多个距离106(例如,表示为图像空间中的深度图)和/或对象检测(例如,与传感器数据102中描绘的对象和/或障碍物相对应的包围形状的位置)作为输出。在非限制性示例中,一个或更多个机器学习模型104可以作为由预处理的传感器数据和/或传感器数据102表示的图像的输入,并且可以使用传感器数据来回归对应于图像中描绘的对象或障碍物的一个或更多个距离106。
在一些非限制性实施例中,可以进一步训练一个或更多个机器学习模型104以本质上预测包围形状的位置作为一个或更多个对象检测116(在其他实施例中,可以使用外部对象检测算法或网络生成包围形状)。在一些这样的示例中,可以训练一个或更多个机器学习模型104以在与每个对象对应的包围形状的质心上回归,以及在四个包围形状边缘位置(例如,从质心到包围形状的边缘的四个像素距离)上回归。因此,当预测包围形状时,一个或更多个机器学习模型104可以因此输出与掩模信道对应的第一信道,该掩模信道包括用于像素的置信度,其中较高的置信度(例如,1)表示包围形状的质心。除了掩模信道之外,可以由一个或更多个机器学习模型104输出附加信道(例如,四个附加信道),其对应于到边界形状的边缘的距离(例如,从质心沿一列像素向上的距离,从质心沿一列像素向下的距离,从质心沿一行像素向右的距离,以及从质心沿一行像素向左的距离)。在其他实施例中,一个或更多个机器学习模型104可以输出包围形状位置的其他表示,例如边缘的图像和尺寸中的包围形状边缘的位置,图像中的包围形状的顶点的位置,以及/或其他输出表示。
在一个或更多个机器学习模型104被训练以预测包围形状的示例中,地面实况编码110还可以包括对由对象检测器(例如,对象检测器214)生成的包围形状的位置编码作为地面实况数据。在一些实施例中,一类对象或障碍物也可以被编码为地面实况并与每个包围形状相关联。例如,当对象是车辆的情况下,车辆分类,车辆类型,车辆颜色,车辆制造,车辆模型,车辆年和/或其他信息的分类可以与对应于车辆的包围形状相关联。
尽管本文关于使用神经网络和特定卷积神经网络作为一个或更多个机器学习模型(例如,如本文关于图7的更详细描述的)描述了示例,但这不是旨在的限制。例如,但不限于,本文描述的一个或更多个机器学习模型104可以包括任何类型的机器学习模型,例如使用线性回归,逻辑回归,决策树,支持向量机(SVM),天真贝叶斯,k最近邻(knn),k均值聚类,随机森林,维数减少算法,梯度提升算法,神经网络(例如,自动编码器,卷积,复发,感觉,长/短期记忆(LSTM),Hopfield,Boltzmann,深度信念,去卷积,生成对抗,液态机等)的一个或更多个机器学习模型和/或其他类型的机器学习模型。
在一些实施例中,一个或更多个机器学习模型104可包括卷积层结构,包括诸如本文所述的层。例如,一个或更多个机器学习模型104可以包括用于生成一个或更多个输出114的任务的完整架构。在其他示例中,可以使用设计用于对象检测的现有或生成的一个或更多个机器学习模型104,和附加层-例如,诸如本文所述的卷积层-可以插入现有模型(例如,作为报头)。例如,特征提取器层可用于生成与传感器数据102对应的特征映射,其作为输入被提供至一个或更多个机器学习模型104。然后可以将特征映射应用于任务为对象检测(例如,计算一个或更多个对象检测116)的一个或更多个机器学习模型104第一层流或第一报头,和/或可以应用于任务为距离估计(例如,计算一个或更多个距离106)的一个或更多个机器学习模型104的第二层流或第二报头。这样,在一个或更多个机器学习模型104被设计为生成一个或更多个距离106和一个或更多个对象检测116时,一个或更多个机器学习模型104可以在一个或更多个机器学习模型104的架构内的某些位置包括至少两个层流(或两个报头)。
一个或更多个机器学习模型104可以使用传感器数据102(和/或预处理的传感器数据)作为输入。传感器数据102可以包括表示由一个或更多个相机生成的图像数据的图像(例如,本文参照图14A-14C描述的一个或更多个相机)。例如,传感器数据102可以包括表示相机的视场的图像数据。更具体地,传感器数据102可以包括由相机生成的单独图像,其中表示一个或更多个单个图像的图像数据可以在每次迭代时输入到一个或更多个机器学习模型104中。
传感器数据102可以作为单个图像输入,或者可以使用批处理输入,例如迷你批次。例如,可以将两个或更多个图像一起用作输入(例如,同时)。两个或更多个图像可以来自同时捕获图像的两个或更多个传感器(例如,两个或更多个相机)。
传感器数据102和/或预处理的传感器数据可以输入到一个或更多个机器学习模型的特征提取器层,然后,在对象检测到一个或更多个机器学习模型104的内在的实施例中,特征提取器层的输出可以作为输入提供到一个或更多个机器学习模型104的对象检测层。例如,在特征提取器层和/或对象检测层之后,一个或更多个机器学习模型104的附加层可以在与传感器数据102中描绘的对象或障碍物对应的距离106上回归。
一个或更多个层可以包括输入层。输入层可以保持与传感器数据102和/或预处理传感器数据相关联的值。例如,当传感器数据102是图像时,输入层可以保持表示图像的原始像素值的值作为体积(例如,宽度W,高度H和颜色通道C(例如,RGB),例如32×32x 3)和/或批量大小B(例如,使用批处理)
一个或更多个机器学习模型的一个或更多个层104可以包括卷积层。卷积层可以计算连接到输入层(例如,输入层)中的局部区域的神经元的输出,每个神经元计算它们的权重和它们连接到输入体积的小区域之间的点积。卷积层的结果可以是另一个体积,其尺寸之一基于施加的滤波器的数量(例如,宽度,高度和滤波器的数量,例如32x 32x 12,如果12为滤波器数量的话)。
一个或更多个层可以包括整流的线性单元(Relu)层。Relu层可以应用元素激活函数,例如max(0,x),例如零阈值。Relu层得到的体积可以与Relu层的输入的体积相同。
一个或更多个层可包括池化层。池化层可以沿空间尺寸(例如,高度和宽度)执行下采样操作,这可能导致比池化层的输入较小的体积(例如,16x 16x 12来自32x32 x 12输入体积)。在一些示例中,一个或更多个机器学习模型104可以不包括任何池化层。在这样的示例中,可以使用跨步卷积层代替池化层。在一些示例中,特征提取器层126可包括交替的卷积层和池化层。
一个或更多个层可以包括全连接层。全连接层中的每个神经元可以连接到先前体积中的每个神经元。全连接层可以计算类别分数,并且得到的卷可以是1x 1x类的数量。在一些示例中,一个或更多个机器学习模型可以作为整体使用没有完全连接的层,以增加处理时间并降低计算资源要求。在这样的示例中,在没有使用全连接层的情况下,一个或更多个机器学习模型104可以被称为完全卷积网络。
在一些示例中,一个或更多个层可以包括解卷积层。然而,术语解卷积的使用可能是误导性的并且不旨在限制。例如,一个或更多个解卷积层可以替代地称为转置的卷积层或部分跨步的卷积层。一个或更多个解卷积层可用于在现有层的输出上执行上采样。例如,一个或更多个解卷积层可以用来向上样品到空间分辨率,该空间分辨率等于输入图像的空间分辨率(例如,传感器数据102)到一个或更多个机器学习模型104,或者用于上采样到下一层的输入空间分辨率。
尽管本文相对于一个或更多个机器学习模型104讨论了输入层,卷积层,池化层,Relu层,解卷积层和全连接层,但这不是限制性的。例如,可以使用附加或替代层,例如归一化层,SoftMax层和/或其他层类型。
可以根据实施例使用一个或更多个机器学习模型104的层的不同的顺序和数量。另外,一些层可以包括参数(例如,权重和/或偏置),而其他层可以不包括例如Relu层和池化层。在一些示例中,可以在训练期间通过一个或更多个机器学习模型104学习参数。此外,一些层可以包括额外的超参数(例如,学习率,步幅,时期,内核尺寸,滤波器的数量,用于池化层的类型等)-例如一个或更多个卷积层,一个或更多个解卷积层和一个或更多个池化层-而其他层可能不这样,例如Relu层。可以使用各种激活功能,包括但不限于Relu,泄漏的Relu,S形,双曲线切线(tanh),指数线性单元(ELU)等。参数,超参数和/或激活功能不是受限制,可能因实施例而有所不同。
在训练期间,传感器数据102-例如,表示由具有一个或更多个相机参数的一个或更多个相机捕获的图像的图像数据-可以应用于一个或更多个机器学习模型104。在一些非限制性实施例中,如上所述本文,缩放和/或失真图可以应用于一个或更多个机器学习模型104作为另一输入,如从相机自适应112到一个或更多个机器学习模型104的虚线向所指示的。一个或更多个机器学习模型104可以预测一个或更多个距离106和/或一个或更多个对象检测116(例如,在实施例中一个或更多个机器学习模型104被训练以预测对应于对象或障碍物的包围形状)。可以将预测与在地面实况编码110期间生成的地面实况进行比较,其示例至少参考图2在本文解释。在一些示例中,如本文所述,地面实况数据可以通过相机自适应112来增强,而在其他实施例中,相机自适应112可以不在地面实况数据上执行(如虚线所示)。损失函数108可用于将地面实况与一个或更多个机器学习模型104的输出114进行比较。
例如,可以使用多次迭代的训练图像训练一个或更多个机器学习模型104,直到一个或更多个机器学习模型104的损失函数108的值低于阈值损失值(例如,可接受的损失)。一个或更多个损失函数108可用于使用地面实况数据测量一个或更多个机器学习模型104的预测中的错误。在一些非限制性示例中,可以使用交叉熵损失函数(例如,二进制交叉熵),L1损失函数,均方误差损失函数,二次损失函数,L2损失函数,平均绝对误差损失函数,平均偏置损失函数,铰链损失函数和/或负日志损失函数。
现在参考图6,本文描述的方法600每个框包括可以使用硬件,固件和/或软件的任何组合来执行的计算过程。例如,可以通过执行存储在存储器中的处理器执行各种功能。方法600还可以体现为存储在计算机存储介质上的计算机可用指令。方法600可以由独立应用程序,服务或托管服务(独立或与另一个托管服务组合)提供,或者插件提供给另一产品,仅举几例。另外,通过示例相对于图1的过程100描述方法600。然而,该方法600可以附加地或替代地由任何一个系统或任何系统的任何组合执行,包括但不限于本文所述的那些。
图6是示出根据本公开的一些实施例的用于训练一个或更多个机器学习模型以预测环境中的对象和/或障碍物的距离的方法600的流程图。在框B602处,方法600包括接收表示LIDAR信息的第一数据,表示RADAR信息的第二数据,以及表示图像的第三数据。例如,传感器数据102可以被接收(和/或生成),其中传感器数据102可以包括RADAR数据,LIDAR数据,SONAR数据,表示一个或更多个图像的图像数据和/或其他传感器数据类型。
在框B604处,方法600包括接收表示与图像中所示的对象相对应的包围形状的第四数据。例如,参考图2,对象检测器214可以生成与对象的位置相对应的数据,如通过对应于图像的包围形状所表示的。
在框B606处,方法600包括将至少部分地基于LIDAR信息或RADAR信息之一或两者确定的深度信息与包围形状相关。例如,来自LIDAR数据,RADAR数据和/或其他传感器数据类型的深度信息可以与(例如,在实施例中,在实施例中自动地)与图像中描绘的对象或障碍物相对应的包围形状相关。
在框B608处,方法600包括生成表示地面实况信息的第五数据,至少部分地基于将深度信息转换为深度图生成所述第五数据。例如,对应于包围形状的深度信息可用于生成地面实况深度图222(图2)。
在框B610处,方法600包括训练神经网络以使用第五数据来计算预测的深度图。例如,可以使用地面实况深度图222作为地面实况训练一个或更多个机器学习模型104,以生成与图像中描绘的对象和/或障碍物对应的一个或更多个距离106。
用于预测距离的一个或更多个机器学习模型
现在参考图7,图7是根据本公开的一些实施例的用于使用一个或更多个机器学习模型预测环境中对象和/或障碍物的距离的过程700的数据流程图。传感器数据702可以包括与本文至少参照图1和图2描述的类似传感器数据。然而,在一些实施例中,应用于部署中的一个或更多个机器学习模型104的传感器数据702可以仅是图像数据。例如,使用图1的过程100可以训练一个或更多个机器学习模型104以仅使用图像数据来精确地预测一个或更多个距离106和/或一个或更多个对象检测116。在这样的实施例中,图像数据可以由一个或更多个相机(例如,单眼相机,在实施例中,例如图14B所示的广角相机1470,多个相机等)生成。
在实施例中,传感器数据102可以经历相机自适应704。例如,类似于图1的相机自适应112,在推断,相机模型可用于计算可由一个或更多个机器学习模型104使用的固定放大特征图,m(u,v)。例如,在一些实施例中,缩放和/或者失真图(诸如图5中的实施例中所示的那些)可以应用于一个或更多个机器学习模型104作为附加输入。然而,因为一个或更多个相同的相机可以在部署实例中使用(例如,对于车辆1400,相同的相机可以用于生成图像数据),所以可以将缩放和/或失真图等固定在整个部署过程中。这样,在一些非限制性实施例中,可以将固定放大特征图连结到卷积层输入特征图。
从相机自适应704生成的传感器数据702和/或缩放和/或失真图可以应用于一个或更多个机器学习模型104。一个或更多个机器学习模型104(在本文参照图1更详细描述的)可以使用传感器数据702和/或缩放和/或失真图来生成输出114。一个或更多个输出114可以包括一个或更多个距离106和/或一个或更多个对象检测116。
一个或更多个距离106可以被计算为对应于图像的像素的深度或距离值。例如,对于对应于对象或障碍物的至少像素,可以计算深度值以生成与图像中描绘的对象或障碍物的距离相对应的深度图。如本文所述,深度值可以对应于z方向,其可以被解释为从参考位置(例如,从相机)到至少部分地由给定像素表示的对象或障碍物的距离。
如本文所述,一个或更多个对象检测116可以是一个或更多个机器学习模型的内在和/或可以通过与一个或更多个机器学习模型104分开的对象检测器来计算。在一个或更多个机器学习模型104被训练以生成一个或更多个对象检测116的情况下,一个或更多个机器学习模型104可以输出与图像中描绘的对象或障碍物的包围形状的位置相对应的数据。在非限制性实施例中,一个或更多个机器学习模型104可以包括与一个或更多个对象检测116对应的多个输出信道。例如,输出可以对应于具有指示与包围形状的质心对应的像素的置信度的值的掩模信道。每个像素-或者至少具有对于质心的高置信度(例如,1,是等)的像素-也可以包括与质心相对应的包围形状的边缘的位置或像素距离的位置对应的数字(例如,4)输出信道。例如,第一信道可以包括沿着包括预测或回归质心的像素列的顶部边缘的像素距离,第二信道可以包括沿着包括预测或回归质心的像素列的右边缘的像素距离,第三信道可以包括沿着包括预测或回归质心的像素行的左边缘的像素距离,并且第四信道可以包括沿着包括预测或回归质心的像素列的底部边缘的像素距离。这样,该信息可用于生成用于检测每个图像中检测到的对象或障碍物的一个或更多个包围形状。在其他实施例中,一个或更多个机器学习模型104可以将包围形状预测输出为包围形状的顶点的位置,或包围形状的质心和尺寸的位置等。
在一个或更多个机器学习模型104未本质上预测对象检测的实施例中,可以由对象检测器708(例如,类似于图2的对象检测器214)生成或计算对象检测。在这样的示例中,可以类似地本文针对包围形状的描述计算对应于对象的包围形状的位置,例如顶点的位置,质心的位置,与边缘的距离,包围形状内的每个像素的像素位置,或沿包围形状的边缘的每个像素等。
解码器706可以使用一个或更多个输出114和/或对象检测器708的输出,以确定来自一个或更多个距离106的深度值(例如,来自预测深度图)和对应于对象的包围形状之间的关联。例如,在为对象计算单个包围形状的情况下,可以由解码器706使用对象的包围形状内的图像的像素对应的距离值来确定到对象的距离。在一些示例中,在距离值在包围形状的像素上变化的情况下,可以对距离值进行平均,加权和/或可以为对象选择单个距离值。在非限制性实施例中,每个包围形状提议可以与深度图中的单个像素(例如,表示一个或更多个距离106)相关联。单个像素可以是中心像素(例如,质心像素),或者可以是另一个像素,例如具有与对象相关联的具有最高置信度的像素。
在一些示例中,使用一个或更多个机器学习模型104或对象检测器708用于对象检测,可以存在为单个对象生成的多个对象检测(例如,包围形状)。对象的每个对象检测可以与来自深度图的不同像素相关联,从而导致对象的多个潜在位置和对象的潜在变化的距离值。为了将多个对象检测提案巩固到每个物理对象实例中的单个对象检测预测中,提议可以群集(例如,使用具有噪声的应用程序的基于密度的空间群集(DBSCAN)算法)到每个物理对象实例的单个预测群集。可以通过在每个群集内形成各个包围形状和距离预测的平均来获得每个物理对象实例的最终单个对象检测。结果,可以针对检测到的每个对象确定单个包围形状,并且单个深度值可以与对象的包围形状相关联。
在一些实施例中,最终包围形状内的每个像素可以与深度值相关联,并且可以确定世界空间中的像素的位置,使得车辆1400能够在世界空间中使用该距离信息执行一个或更多个操作。一个或更多个操作可以包括更新世界模型,执行路径规划,根据路径确定用于导航车辆1400的一个或更多个控制,更新安全过程信息以确保车辆1400可用的安全操作而不会碰撞,和/或用于其他操作。
图8A-8B是根据本公开的一些实施例的基于一个或更多个机器学习模型的输出的对象检测和深度预测的可视化。例如,图8A-8B包括图像802A和802B,其可以是应用于一个或更多个机器学习模型104的图像数据(例如,传感器数据702)的表示。可视化804A和804B,分别对应于图像802A和802B,表示由一个或更多个机器学习模型104和/或对象检测器708检测的图像802A和802B中的对象(例如,车辆)对应的包围形状。深度图806A和806B,分别对应于图像802A和802B,表示由一个或更多个机器学习模型104预测的一个或更多个距离106。这样,解码器706可以将可视化804A和804B内的包围形状的位置分别与深度图806A和806B中表示的距离值相关。车辆1400的结果可以是从车辆1400(或其参考位置,例如相机或车辆1400的另一个位置)到具有相关的包围形状的每个对象的距离。
在一些实施例中,由于一个或更多个机器学习模型104的训练中的噪声和/或熵,一个或更多个机器学习模型104可以偶尔在推理或部署时间处输出不正确的距离值。例如,在检测到的远离对象的小包围形状与检测到的近距离对象的较大包围形状重叠的情况下,可以错误地预测到两个对象的距离是相同的。这样,在一些实施例中,可以通过安全边界710施加后处理算法,以确保一个或更多个机器学习模型104计算的一个或更多个距离106落入值的安全允许范围内。其中一个或更多个距离106应该位于的安全允许带-例如,可接受作为安全允许的最小和最大距离估计值-可以从传感器数据702中的视觉线索获得。例如,有用的线索可以是对应于对象或障碍物的道路形状和/或包围形状(例如,如通过一个或更多个机器学习模型104和/或对象检测器708预测的)。在本文中至少参照图10A-13进一步描述安全边界计算。
现在参考图9,本文描述的方法900的每个框包括可以使用硬件,固件和/或软件的任何组合来执行的计算过程。例如,可以通过执行存储在存储器中的指令的处理器执行各种功能。方法900还可以体现为存储在计算机存储介质上的计算机可用指令。方法900可以由独立应用程序,服务或托管服务(独立或与另一个托管服务组合)提供,或者插入另一个产品,仅举几例。另外,作为示例,参照图7的过程700描述方法900。然而,该方法900可以附加地或替代地由任何一个系统或系统的任何组合执行,包括但不限于本文所述的系统。
图9是示出根据本公开的一些实施例的用于使用一个或更多个机器学习模型预测环境中的对象和/或障碍物的距离的方法900的流程图。在框B902处,方法900包括将表示图像传感器的视场的图像的第一数据应用于神经网络,该神经网络至少部分地基于表示使用LIDAR传感器或RADAR传感器中的至少一个生成的地面实况信息的第二数据训练。例如,传感器数据702(和/或表示来自相机自适应704的缩放和/或失真图的数据)可以应用于一个或更多个机器学习模型104。如本文所述,一个或更多个机器学习模型104可以使用LIDAR传感器和/或RADAR传感器生成的底面实况(在实施例中,自动地,没有人工标记或注释)训练。
在框B904处,方法900包括使用神经网络并且至少部分地基于第一数据计算表示对应于图像的深度值的第三数据。例如,一个或更多个机器学习模型104可以计算一个或更多个距离106(或其深度图表示)。
在框B906处,方法900包括确定对应于图像中描绘的对象的包围形状的图像的一个或更多个像素。例如,解码器706可以确定由一个或更多个机器学习模型104和/或对象检测器708预测的包围形状和由一个或更多个机器学习模型104预测的一个或更多个距离106的深度值之间的相关性。
在框B908处,方法900包括将与一个或更多个像素相对应的深度值中的深度值与对象相关联。例如,对于具有相关包围形状的每个对象,可以将一个或更多个距离106指派给对象。
限定距离值的安全边界计算
鉴于对象检测方法的准确性(例如,通过一个或更多个机器学习模型104,通过对象检测器708等),可以生成具有良好的准确度的图像中对象或障碍物周围的紧密包围形状。因此,基于相机校准参数,可以计算光线需要通过3D、世界空间的路径,以便在图像空间中创建目标位置中的像素。目标位置可以包括与包围形状相对应的位置,例如包围形状内的位置,沿包围形状的边缘的位置,或者在一些实施例中,包围形状的底部中点(例如,一个点在底部,包围形状的较低边缘)。假设包围形状的底部中点位于接地平面(或相对于车辆或驾驶环境的驾驶平面上),在此点光线可以与地面相交。如果已知道路曲率或等级,则可以直接计算径向距离。然而,准确地预测道路曲率,特别是使用图像数据,存在挑战。
这样,在一些实施例中,即使在缺乏实际道路曲率或等级的直接信息时,也可以假设用于驾驶表面的最大向上上升曲率和最大向下上升曲率-例如通过关于道路等级的使用规定作为指导。曲率可以被视为实际道路曲率的极端边界壁,使得这些曲率可以称为安全边界。这样,从相机通过这些最大曲率点追踪的光线的交点给出了距离106可能落入的最小和最大限制,以便被认为是安全允许的。为了计算最小道路曲率和最大道路曲率,光线轨迹可以与道路曲率轨迹相交(例如,如通过闭合形式等式估计的,在一个实施例中,可以近似为线性(如图10B和10D所示),并受到道路级限制的汽车规定的限制)。结果,可以通过确保一个或更多个距离106落入由最小值和最大值确定的值范围内的一个或更多个距离106落入所述值的距离来将一个或更多个机器学习模型104的一个或更多个距离106限定到安全允许的范围。例如,在距离106小于最小的情况下,距离106可以被更新或限定至最小值,其中距离106大于最大值,距离106可以被可以更新或钳限定至最大值。在3D世界空间中,在一些实施例中,由道路曲率控制的物理边界可以是碗状的。
作为示例,并且参照10A,图10A是根据本公开的一些实施例的用于限定一个或更多个机器学习模型的距离预测的安全边界计算的图表1000。图表1000包括表示所确定的最大向上曲率的向上曲线1002,表示所确定的最大向下曲率的向下曲线1004和接地平面1008。向上曲率和向下曲率有助于定义用于确定最大值1012(例如,最大距离值)和最小值1012(例如,最小距离值)的安全允许频带。光线1006可以通过与对象的包围形状对应的点(例如,底部中心点)从相机投射到对象的包围形状。随着光线1006投射到世界空间中,光线1006与向上曲线1002相交以定义最小值1012并与向下曲线1004相交以定义最大值1010。
现在参考图10B,图10B是根据本公开的一些实施例的示出用于安全边界计算的最大向上轮廓的图表1020。例如,图表1020包括生成或定义图10A的向上曲线1002的示例,其用于定义最小值1012。在一些实施例中,如本文所述,具有在阈值之后限制的平滑上升的壁或向上曲线1002可以更实用。这可能是距离越来越靠近地平线的距离的结果。然而,仔细地调谐向上曲线1002的参数是很重要的,因为如果向上曲线1002向上弯曲过多,则最小值1012可以为不确定性提供更多自由度。最小值1012也不应该如此紧张,以便在近距离拒绝准确的测量。在一些示例中,对于每个平滑上升的向上曲线1002,线性曲线1022可以通过连接光滑向上曲线1002的端部来构造。在一些非限制性实施例中,该简单的线性曲线1022可以用作定义最小值1012的安全边界的向上曲线1002。如图10B所示,示出了向上曲线1002的若干潜在选择。向上曲线1002A表示斜率小于向上曲线1002B的向上曲线1002。垂直壁1024可以表示参数设置的极端向上曲线。
现在参考图10C,图10C是根据本公开的一些实施例的计算上安全边界的图示。在至少一个实施例中,如本文所述,线性曲线1022可以通过向上曲线1002的端部(例如,1002A或1002B)的连接来确定,并且可以用作计算最小值1012的向上曲线1002。例如,在这样的实施例中,可以存在两个参数,用于控制线性曲线1022的结构-倾斜角θ和径向距离帽λ。倾斜角度θ可以被写为边界参数D的函数,以简化等式。让h成为相机(例如,从相机上的中心点或其他参考位置)到接地平面1008的高度。可以假设壁以角度θ线性上升,其中角度倾斜度θ由以下等式(4)给出:
这样,线性曲线1022的倾斜可以通过该改变D而变化。来自相机的光线1006可以在从径向轴上处于径向距离d的点O处与接地平面1008相交。相同的光线可以在点P处与壁相交,并且可以使用下面的等式(5)-(9)找到点P的径向距离。可以通过使用平面假设获得d的值来计算径向距离。在此,由PAO=θ形成的三角形,以及由POA=θ1形成的三角形。
可以通过将正弦规则应用于三角形PAO来观察以下等式(6)-
(7):
由于λ是最大径向距离盖,
r=λ,否则 (9)
现在参考图10D,图10D是根据本公开的一些实施例的示出用于安全边界计算的最大向下轮廓的图表1030。向下曲线1004用于定义最大值1012。与向上曲线1002类似,对于每个平滑向下上升壁或向下曲线1004,可以生成简单的线性曲线1032,其在最大值1012上表现出一些灵活性。在一些示例中,对于每个平滑上升的向下曲线1004,线性曲线1032可以通过连接光滑向下曲线1004的端部来构造。在一些非限制性实施例中,该简单的线性曲线1032可以用作定义最大值1010的安全边界的向下曲线1004。在图10D中,示出了向下曲线1004的几个潜在选择。向下曲线1004A表示向下曲线1004的一个示例,然而,可以在不脱离本公开的范围的情况下考虑具有更多或更少斜率的附加向下曲线1004。垂直壁1034可以表示参数设置的极端向下曲线。
现在参考图10E,图10E是根据本公开的一些实施例的计算较低安全边界的图示。在至少一个实施例中,如本文所述,线性曲线1032可以通过连接向下曲线1004(例如,1004A)的端部来确定,并且可以用作计算最大值1010的目的的向下曲线1004。例如,在这样的实施例中,可以存在两个参数,用于控制线性曲线1032的结构-倾斜角,θ和径向距离帽λ。倾斜角度θ可以被写为边界参数D的函数,以简化等式。让h成为相机(例如,从相机上的中心点或其他参考位置)到接地平面1008的高度。可以假设壁以θ的角度线性上升,其中角度倾斜度θ由本文描述的等式(4)给出。这样,线性曲线1032的倾斜可以通过改变D来变化。来自相机的光线1006可以在从径向轴上处于径向距离d的点O处与接地平面1008相交。相同的光线可以在点P处与壁相交,并且可以使用本文下面所述等式(10)-(13)找到点P的径向距离,等式(5)。可以通过使用平面假设获得d的值来计算径向距离。在此,由PAO=θ形成的三角形,以及由COA=θ1形成的三角形。可以通过将正弦规则应用于三角形PAO来观察以下等式(10)-(11):
由于λ是最大径向距离上限,
r=λ,否则 (13)
现在参考图10F,图10F是示出根据本公开的一些实施例的安全带轮廓的图示。例如,当光线沿着平面移动时,看看安全带1040也可能是重要的,这可能基本上是最大值1010和最小值1012之间的差。在接近距离时,安全带1040应紧张,并且应随着障碍物或对象进一步移动而增加。
现在参考图11,本文描述的方法1100块包括可以使用硬件,固件和/或软件的任何组合来执行的计算过程。例如,可以通过执行存储在存储器中的指令的处理器执行各种功能。方法1100也可以体现为存储在计算机存储介质上的计算机可用指令。方法1100可以由独立应用程序,服务或托管服务(独立或与另一个托管服务组合)提供,或者插入另一个产品,仅举几例。另外,通过示例的方式参照图10A-10F描述方法1100。方法1100可以由任何一个系统或系统的任何组合执行,包括但不限于本文所述的系统。
图11是示出根据本公开的一些实施例的使用道路形状的用于安全边界确定的方法1100的流程图。在框B1102处,方法1100包括在一个或更多个机器学习模型104处接收图像(或其他传感器数据702)。一个或更多个机器学习模型104(和/或对象检测器708)可以输出包围形状,其可以在框B1104处使用来估计来自向上曲线1102的最小值1012,并且在框B1106处使用以估计来自向下曲线1104的最大值1010。最大值1010和最小值1012可以定义安全边界(例如,最小值1012和最大值1010之间的距离值范围可以是安全允许距离值)对应于包围形状的特定对象实例处的特定对象。在框B1102处,一个或更多个机器学习模型104可以输出一个或更多个距离106,作为与由包围形状表示的对象实例对应的预测距离。在框B1108处,可以在一个或更多个距离106和由最小值1012和最大值1012限定的安全边界之间进行比较。如果一个或更多个距离106落在安全边界内(例如,大于最小值1012且小于最大值1010),可以确定一个或更多个距离106处于框B1108的安全距离,并且可以传递给框B1112,以向系统指示一个或更多个距离106是可以接受的。如果一个或更多个距离106落在安全边界之外(例如,小于最小值1012或大于最大值1010),则可以确定一个或更多个距离106不在框B1108的安全距离。当一个或更多个距离106在安全边界之外时,一个或更多个距离106在框B1110处可以被限定至安全边界。例如,在一个或更多个距离106小于最小值1012的情况下,可以将一个或更多个距离106更新至最小值1012。类似地,其中一个或更多个距离106大于最大值1010,可以将一个或更多个距离106更新至最大值1010。一旦更新,更新的距离可以传递给框B1112以向系统指示更新的距离是可接受的。
现在参考图12,图12是根据本公开的一些实施例的使用与对象对应的包围形状计算安全范围的图示。例如,如本文所述,可以与来自道路形状的安全边界分开或结合使用的另一种确定安全边界定的方法使用对象或障碍物的包围形状。图12可以表示针孔相机模型。使用对象1204的焦距f,真实高度H,包围形状高度h和投影函数F,则可以使用等式(14)来计算对象的距离d,以下:
d=F(f,H,h) (14)
在一些实施例中,与对象的距离d可以与包围形状高度h成反比,它们通常是针孔相机模型。这样,可以使用下面的等式(15)来计算距离d,其可以被称为距离模型:
对象检测和与对象估计的距离可以提供距离({d
其中e是预定义的安全边缘。这样,可以使用基于随着时间的d和h数据样本的建模(例如,等式(15))来估计对象的实际高度H。
包围形状高度h和焦距f可以由包围形状的中间顶部和中间底部的光线之间的角度α代替,如下面的等式(18)所示:
然后可以将逆相机模型直接应用于包围形状以获得角度α。因此,针对任何已知的相机模型,可以使用基于d和α的样本随时间的等式(18)估计真实对象高度H。
现在参考图13,本文描述的方法1300的每个框包括可以使用硬件,固件和/或软件的任何组合来执行的计算过程。例如,可以通过执行存储在存储器中的指令的处理器执行各种功能。方法1300也可以体现为存储在计算机存储介质上的计算机可用指令。方法1300可以由独立应用程序,服务或托管服务(独立或与另一个托管服务组合)提供,或者由另一产品的插件提供,仅举几例。另外,通过示例的方式参照图12描述方法1300。方法1300可以由任何一个系统或系统的任何组合来执行,包括但不限于本文所述的系统。
图13示出了根据本公开的一些实施例的示出使用包围形状特性的用于安全边界确定的方法1300的流程图。在框B1302处,方法1300包括在一个或更多个机器学习模型104处接收图像(或其他传感器数据702)。一个或更多个机器学习模型104(和/或对象检测器708)可以输出包围形状,其可以在框B1304处用于计算距离d,根据本文所述的等式(15)的距离模型。然后可以在框B1306处使用距离d计算安全边界(例如,最小值,d
示例自主车辆
图14A为根据本公开一些实施例的示例自主车辆1400的图示。自主车辆1400(可替代地,在本文称为“车辆1400”)可以包括但不限于乘用车,例如汽车、卡车、公共汽车、急救车、穿梭车、电动或机动自行车、摩托车、消防车、警车、救护车、船、工程车辆、水下航行器、无人机和/或另一种类型的车辆(例如,无人驾驶和/或可容纳一名或更多名乘客)。自主车辆通常按照美国运输部的一个部门——国家公路交通安全管理局(NHTSA)以及汽车工程师协会(SAE)“Taxonomy and Definitions for Terms Related to Driving AutomationSystems for On-Road Motor Vehicles”(2018年6月15日发布的标准No.J3016-201806,2016年9月30日发布的标准No.J3016-201609,以及该标准的先前和未来的版本)定义的自动化级别进行描述。车辆1400可能够实现符合自主驾驶级别的3级-5级中的一个或更多个的功能。例如,取决于实施例,车辆1400可能够实现条件自动化(3级)、高自动化(4级)和/或全自动化(5级)。
车辆1400可以包括诸如底盘、车身、车轮(例如2个、4个、6个、8个、18个等)、轮胎、车轴之类的部件以及车辆的其他部件。车辆1400可以包括推进系统1450,例如内燃机、混合动力发电厂、全电动发动机和/或另一种推进系统类型。推进系统1450可以连接到可以包括变速器的车辆1400的传动系以便实现车辆1400的推进。可以响应于接收到来自油门/加速器1452的信号而控制推进系统1450。
可以包括方向盘的转向(steering)系统1454可以用来在推进系统1450操作时(例如在车辆运动时)使车辆1400转向(例如沿着希望的路径或路线)。转向系统1454可以接收来自转向执行器1456的信号。对于全自动(5级)功能而言,方向盘可以是可选的。
制动传感器系统1446可以用来响应于接收到来自制动执行器1448和/或制动传感器的信号而操作车辆制动器。
可以包括一个或更多个片上系统(SoC)1404(图14C)和/或一个或更多个GPU的一个或更多个控制器1436可以向车辆1400的一个或更多个部件和/或系统提供(例如表示命令的)信号。例如,一个或更多个控制器可以发送经由一个或更多个制动执行器1448操作车辆制动器、经由一个或更多个转向执行器1456操作转向系统1454、经由一个或更多个油门/加速器1452操作推进系统1450的信号。一个或更多个控制器1436可以包括一个或更多个板载(例如集成)计算设备(例如超级计算机),所述计算设备处理传感器信号并且输出操作命令(例如表示命令的信号),以实现自主驾驶和/或辅助人类驾驶员驾驶车辆1400。一个或更多个控制器1436可以包括用于自主驾驶功能的第一控制器1436、用于功能性安全功能的第二控制器1436、用于人工智能功能(例如计算机视觉)的第三控制器1436、用于信息娱乐功能的第四控制器1436、用于紧急情况下的冗余的第五控制器1436和/或其他控制器。在一些示例中,单个控制器1436可以处理上述功能中的两个或更多,两个或更多控制器1436可以处理单个功能,和/或其任意组合。
一个或更多个控制器1436可以响应于接收自一个或更多个传感器的传感器数据(例如传感器输入),提供用于控制车辆1400的一个或更多个部件和/或系统的信号。传感器数据可以接收自例如且不限于全球导航卫星系统传感器1458(例如全球定位系统传感器)、RADAR传感器1460、超声传感器1462、LIDAR传感器1464、惯性测量单元(IMU)传感器1466(例如加速度计、陀螺仪、磁罗盘、磁力计等)、麦克风1496、立体相机1468、广角相机1470(例如鱼眼相机)、红外相机1472、环绕相机1474(例如360度相机)、远程和/或中程相机1498、速度传感器1444(例如用于测量车辆1400的速率)、振动传感器1442、转向传感器1440、制动传感器(例如作为制动传感器系统1446的部分)和/或其他传感器类型。
控制器1436中的一个或更多个可以接收来自车辆1400的仪表组1432的输入(例如由输入数据表示),并且经由人机接口(HMI)显示器1434、听觉信号器、扬声器和/或经由车辆1400的其他部件提供输出(例如输出数据、显示数据等表示的)。这些输出可以包括诸如车辆速度、速率、时间、地图数据(例如图14C的HD地图1422)、位置数据(例如,车辆1400例如在地图上的位置)、方向、其他车辆的位置(例如占用网格)之类的信息,如控制器1436所感知的关于对象和对象状态的信息等等。例如,HMI显示器1434可以显示关于一个或更多个对象(例如街道指示牌、警示牌、交通灯变化等)的存在性的信息和/或关于车辆已经做出、正在做出或者将会做出的驾驶机动的信息(例如现在变道、两英里后离开34B,等等)。
车辆1400进一步包括网络接口1424,其可以使用一个或更多个无线天线1426和/或调制解调器通过一个或更多个网络通信。例如,网络接口1424可能够通过LTE、WCDMA、UMTS、GSM、CDMA2000等通信。一个或更多个无线天线1426也可以使用诸如蓝牙、蓝牙LE、Z波、ZigBee等等之类的一个或更多个局域网和/或诸如LoRaWAN、SigFox等等之类的一个或更多个低功率广域网(LPWAN)实现环境中的对象(例如车辆、移动设备等等)之间的通信。
图14B为根据本公开一些实施例的用于图14A的示例自主车辆1400的相机位置和视场的示例。相机和各自的视场是一个示例实施例,并不意图是限制性的。例如,可以包括附加的和/或可替换的相机,和/或这些相机可以位于车辆1400上的不同位置。
用于相机的相机类型可以包括但不限于可以适于与车辆1400的部件和/或系统一起使用的数字相机。所述相机可以在汽车安全完整性级别(ASIL)B下和/或在另一个ASIL下操作。相机类型可以具有任何图像捕获率,例如60帧每秒(fps)、1420fps、240fps等等,这取决于实施例。相机可能够使用滚动快门、全局快门、另一种类型的快门或者其组合。在一些示例中,滤色器阵列可以包括红白白白(RCCC)滤色器阵列、红白白蓝(RCCB)滤色器阵列、红蓝绿白(RBGC)滤色器阵列、Foveon X3滤色器阵列、拜耳传感器(RGGB)滤色器阵列、单色传感器滤色器阵列和/或另一种类型的滤色器阵列。在一些实施例中,诸如具有RCCC、RCCB和/或RBGC滤色器阵列的相机之类的清晰像素相机可以用在提高光敏感度的努力中。
在一些示例中,所述相机中的一个或更多个可以用来执行高级驾驶员辅助系统(ADAS)功能(例如作为冗余或故障安全设计的部分)。例如,可以安装多功能单目相机以提供包括车道偏离警告、交通指示牌辅助和智能前照灯控制在内的功能。所述相机中的一个或更多个(例如全部相机)可以同时记录和提供图像数据(例如视频)。
所述相机中的一个或更多个可以安装在诸如定制设计的(3-D打印的)组件之类的安装组件中,以便切断可能干扰相机的图像数据捕获能力的杂散光和来自汽车内的反射(例如挡风玻璃镜中反射的来自仪表板的反射)。关于翼镜安装组件,翼镜组件可以是定制3-D打印的,使得相机安装板匹配翼镜的形状。在一些示例中,一个或更多个相机可以集成到翼镜中。对于侧视相机而言,一个或更多个相机也可以集成到驾驶室每个拐角的四根柱子内。
具有包括车辆1400前面的环境部分的视场的相机(例如前置相机)可以用于环视,以帮助识别前向路径和障碍,以及在一个或更多个控制器1436和/或控制SoC的帮助下辅助提供对于生成占用网格和/或确定优选车辆路径至关重要的信息。前置相机可以用来执行许多与LIDAR相同的ADAS功能,包括紧急制动、行人检测和碰撞避免。前置相机也可以用于ADAS功能和系统,包括车道偏离警告(“LDW”)、自主巡航控制(“ACC”),和/或诸如交通指示牌识别之类的其他功能。
各种各样的相机可以用于前置配置中,包括例如包括CMOS(互补金属氧化物半导体)彩色成像仪在内的单目相机平台。另一个示例可以是广角相机1470,其可以用来感知从周边进入视场的对象(例如行人、十字路口交通或者自行车)。尽管图14B中图示出仅仅一个广角相机,但是在车辆1400上可以存在任意数量的广角相机1470。此外,远程相机1498(例如长视立体相机对)可以用于基于深度的对象检测,尤其是用于尚未针对其训练神经网络的对象。远程相机1498也可以用于对象检测和分类以及基本的对象跟踪。
一个或更多个立体相机1468也可以包括在前置配置中。立体相机1468可以包括集成控制单元,该单元包括可扩展处理单元,其可以提供在单个芯片上具有集成的CAN或以太网接口的多核微处理器和可编程逻辑(FPGA)。这样的单元可以用来生成车辆环境的3-D地图,包括针对图像中的所有点的距离估计。可替代的立体相机1468可以包括紧凑型立体视觉传感器,其可以包括两个相机镜头(左右各一个)以及可以测量从车辆到目标对象的距离并且使用生成的信息(例如元数据)激活自主紧急制动和车道偏离警告功能的图像处理芯片。除了本文所描述的那些之外或者可替代地,可以使用其他类型的立体相机1468。
具有包括车辆1400的侧面的环境部分的视场的相机(例如侧视相机)可以用于环视,提供用来创建和更新占用网格以及生成侧撞击碰撞警告的信息。例如,环绕相机1474(例如如图14B中所示的四个环绕相机1474)可以置于车辆1400上。环绕相机1474可以包括广角相机1470、鱼眼相机、360度相机等等。四个示例,四个鱼眼相机可以置于车辆的前面、后面和侧面。在一种可替代的布置中,车辆可以使用三个环绕相机1474(例如左边、右边和后面),并且可以利用一个或更多个其他相机(例如前向相机)作为第四环视相机。
具有包括车辆1400的后面的环境部分的视场的相机(例如后视相机)可以用于辅助停车、环视、后面碰撞警告以及创建和更新占用网格。可以使用各种各样的相机,包括但不限于也适合作为如本文所描述的前置相机(例如远程和/或中程相机1498、立体相机1468、红外相机1472等等)的相机。
图14C为根据本公开一些实施例的用于图14A的示例自主车辆1400的示例系统架构的框图。应当理解,这种布置和本文描述的其他布置仅仅作为示例而被阐述。除了所示的那些之外或者代替它们的是,可以使用其他的布置和元素(例如机器、接口、功能、顺序、功能分组等等),并且一些元素可以完全省略。进一步,许多本文描述的元素是功能实体,其可以实现为分立的或分布式部件或者结合其他部件实现,以及以任何适当的组合和位置实现。本文描述为由实体执行的各个功能可以通过硬件、固件和/或软件实现。例如,各个功能可以通过处理器执行存储在内存中的指令而实现。
图14C中车辆1400的部件、特征和系统中的每一个被图示为经由总线1402连接。总线1402可以包括控制器区域网络(CAN)数据接口(可替代地,本文称为“CAN总线”)。CAN可以是车辆1400内部的网络,用来辅助控制车辆1400的各种特征和功能,例如制动器、加速、制动、转向、挡风玻璃雨刷等等的驱动。CAN总线可以被配置为具有数十或者甚至数百个节点,每个节点具有其自己的唯一标识符(例如CAN ID)。可以读取CAN总线以找到方向盘角度、地速、每分钟发动机转速(RPM)、按钮位置和/或其他车辆状态指示符。CAN总线可以是ASIL B兼容的。
尽管本文将总线1402描述为CAN总线,但是这并不意图是限制性的。例如,除了CAN总线之外或者可替代地,可以使用FlexRay和/或以太网。此外,尽管用单条线来表示总线1402,但是这并不意图是限制性的。例如,可以存在任意数量的总线1402,其可以包括一条或更多条CAN总线、一条或更多条FlexRay总线、一条或更多条以太网总线和/或一条或更多条使用不同协议的其他类型的总线。在一些示例中,两条或更多总线1402可以用来执行不同的功能,和/或可以用于冗余。例如,第一总线1402可以用于碰撞避免功能,并且第二总线1402可以用于驱动控制。在任何示例中,每条总线1402可以与车辆1400的任何部件通信,并且两条或更多总线1402可以与相同的部件通信。在一些示例中,车辆内的每个SoC 1404、每个控制器1436和/或每个计算机可以有权访问相同的输入数据(例如来自车辆1400的传感器的输入),并且可以连接到诸如CAN总线之类的公共总线。
车辆1400可以包括一个或更多个控制器1436,例如本文关于图14A所描述的那些控制器。控制器1436可以用于各种各样的功能。控制器1436可以耦合到车辆1400的任何其他不同的部件和系统,并且可以用于车辆1400的控制、车辆1400的人工智能、用于车辆1400的信息娱乐等等。
车辆1400可以包括一个或更多个片上系统(SoC)1404。SoC 1404可以包括CPU1406、GPU 1408、处理器1410、高速缓存1412、加速器1414、数据存储1416和/或未图示出的其他部件和特征。在各种各样的平台和系统中,SoC 1404可以用来控制车辆1400。例如,一个或更多个SoC 1404可以在系统(例如车辆1400的系统)中与HD地图1422结合,所述HD地图可以经由网络接口1424从一个或更多个服务器(例如图14D的一个或更多个服务器1478)获得地图刷新和/或更新。
CPU 1406可以包括CPU簇或者CPU复合体(可替代地,本文称为“CCPLEX”)。CPU1406可以包括多个核和/或L2高速缓存。例如,在一些实施例中,CPU 1406在一致性多处理器配置中可以包括八个核。在一些实施例中,CPU 1406可以包括四个双核簇,其中每个簇具有专用的L2高速缓存(例如2MB L2高速缓存)。CPU 1406(例如CCPLEX)可以被配置为支持同时簇操作,使得CPU 1406的簇的任意组合能够在任何给定时间是活动的。
CPU 1406可以实现包括以下特征中的一个或更多个的功率管理能力:各硬件块在空闲时可以自动进行时钟门控以节省动态功率;由于WFI/WFE指令的执行,每个核时钟可以在该核不主动地执行指令时进行门控;每个核可以独立地进行功率门控;当所有核都进行时钟门控或者功率门控时,可以独立地对每个核簇进行时钟门控;和/或当所有核都进行功率门控时,可以独立地对每个核簇进行功率门控。CPU 1406可以进一步实现用于管理功率状态的增强算法,其中指定允许的功率状态和期望的唤醒时间,并且硬件/微代码为所述核、簇和CCPLEX确定要进入的最佳的功率状态。处理核可以在软件中支持简化的功率状态进入序列,该工作被卸载到微代码。
GPU 1408可以包括集成的GPU(可替代地,本文称为“iGPU”)。GPU 1408可以是可编程的,并且对于并行工作负载而言是高效的。在一些示例中,GPU 1408可以使用增强张量指令集。GPU 1408可以包括一个或更多个流式微处理器,其中每个流式微处理器可以包括L1高速缓存(例如具有至少96KB存储能力的L1高速缓存),并且这些流式微处理器中的两个或更多可以共享L2高速缓存(例如具有512KB存储能力的L2高速缓存)。在一些实施例中,GPU1408可以包括至少八个流式微处理器。GPU 1408可以使用计算应用编程接口(API)。此外,GPU 1408可以使用一个或更多个并行计算平台和/或编程模型(例如NVIDIA的CUDA)。
在汽车和嵌入式使用的情况下,可以对GPU 1408进行功率优化以实现最佳性能。例如,可以在鳍式场效应晶体管(FinFET)上制造GPU 1408。然而,这并不意图是限制性的,并且GPU 1408可以使用其他半导体制造工艺来制造。每个流式微处理器可以合并划分成多个块的若干混合精度处理核。例如且非限制性地,可以将64个PF32核和32个PF64核划分成四个处理块。在这样的示例中,每个处理块可以分配16个FP32核、8个FP64核、16个INT32核、用于深层学习矩阵算术的两个混合精度NVIDIA张量核、L0指令高速缓存、线程束(warp)调度器、分派单元和/或64KB寄存器文件。此外,流式微处理器可以包括独立的并行整数和浮点数据路径,以利用计算和寻址计算的混合提供工作负载的高效执行。流式微处理器可以包括独立线程调度能力,以允许实现并行线程之间的更细粒度的同步和协作。流式微处理器可以包括组合的L1数据高速缓存和共享内存单元,以便在简化编程的同时提高性能。
GPU 1408可以包括在一些示例中提供大约900GB/s的峰值内存带宽的高带宽内存(HBM)和/或16GB HBM2内存子系统。在一些示例中,除了HBM内存之外或者可替代地,可以使用同步图形随机存取存储器(SGRAM),例如第五代图形双倍数据速率同步随机存取存储器(GDDR5)。
GPU 1408可以包括统一内存技术,其包括访问计数器以允许内存页面更精确地迁移到最频繁地访问它们的处理器,从而提高处理器之间共享的内存范围的效率。在一些示例中,地址转换服务(ATS)支持可以用来允许GPU 1408直接访问CPU 1406页表。在这样的示例中,当GPU 1408内存管理单元(MMU)经历遗漏时,可以将地址转换请求传输至CPU 1406。作为响应,CPU 1406可以在其页表中寻找用于地址的虚拟-物理映射,并且将转换传输回GPU 1408。这样,统一内存技术可以允许单个统一虚拟地址空间用于CPU 1406和GPU 1408二者的内存,从而简化了GPU 1408编程和将应用程序移(port)到GPU 1408。
此外,GPU 1408可以包括访问计数器,其可以跟踪GPU 1408访问其他处理器的内存的频率。访问计数器可以帮助确保内存页面移至最频繁地访问这些页面的处理器的物理内存。
SoC 1404可以包括任意数量的高速缓存1412,包括本文描述的那些高速缓存。例如,高速缓存1412可以包括CPU 1406和GPU 1408二者可用的L3高速缓存(例如,其连接到CPU 1406和GPU 1408二者)。高速缓存1412可以包括回写高速缓存,其可以例如通过使用高速缓存一致性协议(例如MEI、MESI、MSI等)跟踪行的状态。取决于实施例,L3高速缓存可以包括4MB或者更多,但是也可以使用更小的高速缓存大小。
SoC 1404可以包括一个或更多个加速器1414(例如硬件加速器、软件加速器或者其组合)。例如,SoC 1404可以包括硬件加速簇,其可以包括优化的硬件加速器和/或大型片上内存。该大型片上内存(例如4MB SRAM)可以使得硬件加速簇能够加速神经网络和其他计算。硬件加速簇可以用来补充GPU 1408,并且卸载GPU 1408的一些任务(例如释放GPU 1408的更多周期以用于执行其他任务)。作为一个示例,加速器1414可以用于足够稳定以易于控制加速的有针对性的工作负载(例如感知、卷积神经网络(CNN)等等)。当在本文中使用时,术语“CNN”可以包括所有类型的CNN,包括基于区域的或者区域卷积神经网络(RCNN)和快速RCNN(例如用于对象检测)。
加速器1414(例如硬件加速簇)可以包括深度学习加速器(DLA)。DLA可以包括可以被配置成为深度学习应用和推理提供额外的每秒10万亿次操作的一个或更多个张量处理单元(TPU)。TPU可以是被配置为执行图像处理功能(例如用于CNN、RCNN等)且针对执行图像处理功能而优化的加速器。DLA可以进一步针对特定的一组神经网络类型和浮点运算以及推理进行优化。DLA的设计可以比通用GPU提供每毫米更高的性能,并且远远超过CPU的性能。TPU可以执行若干功能,包括单实例卷积函数,支持例如用于特征和权重二者的INT8、INT16和FP16数据类型,以及后处理器功能。
DLA可以在处理的或者未处理的数据上针对各种各样的功能中的任何功能快速且高效地执行神经网络,尤其是CNN,例如且不限于:用于使用来自相机传感器的数据进行对象识别和检测的CNN;用于使用来自相机传感器的数据进行距离估计的CNN;用于使用来自麦克风的数据进行应急车辆检测和识别与检测的CNN;用于使用来自相机传感器的数据进行面部识别和车主识别的CNN;和/或用于安全和/或安全相关事件的CNN。
DLA可以执行GPU 1408的任何功能,并且通过使用推理加速器,例如,设计者可以使DLA或GPU 1408针对任何功能。例如,设计者可以将CNN的处理和浮点运算聚焦在DLA上,并且将其他功能留给GPU 1408和/或其他加速器1414。
加速器1414(例如硬件加速簇)可以包括可编程视觉加速器(PVA),其在本文中可以可替代地称为计算机视觉加速器。PVA可以被设计和配置为加速用于高级驾驶员辅助系统(ADAS)、自主驾驶和/或增强现实(AR)和/或虚拟现实(VR)应用的计算机视觉算法。PVA可以提供性能与灵活性之间的平衡。例如,每个PVA可以包括例如且不限于任意数量的精简指令集计算机(RISC)核、直接内存访问(DMA)和/或任意数量的向量处理器。
RISC核可以与图像传感器(例如本文描述的任何相机的图像传感器)、图像信号处理器等等交互。这些RISC核中的每一个可以包括任意数量的内存。取决于实施例,RISC核可以使用若干协议中的任何协议。在一些示例中,RISC核可以执行实时操作系统(RTOS)。RISC核可以使用一个或更多个集成电路设备、专用集成电路(ASIC)和/或存储设备实现。例如,RISC核可以包括指令高速缓存和/或紧密耦合的RAM。
DMA可以使得PVA的部件能够独立于CPU 1406访问系统内存。DMA可以支持用来向PVA提供优化的任意数量的特征,包括但不限于支持多维寻址和/或循环寻址。在一些示例中,DMA可以支持高达六个或更多维度的寻址,其可以包括块宽度、块高度、块深度、水平块步进、竖直块步进和/或深度步进。
向量处理器可以是可编程处理器,其可以被设计为高效且灵活地执行用于计算机视觉算法的编程并且提供信号处理能力。在一些示例中,PVA可以包括PVA核和两个向量处理子系统分区。PVA核可以包括处理器子系统、一个或更多个DMA引擎(例如两个DMA引擎)和/或其他外围设备。向量处理子系统可以作为PVA的主处理引擎而操作,并且可以包括向量处理单元(VPU)、指令高速缓存和/或向量内存(例如VMEM)。VPU核可以包括数字信号处理器,诸如例如单指令多数据(SIMD)、超长指令字(VLIW)数字信号处理器。SIMD和VLIW的组合可以增强吞吐量和速率。
向量处理器中的每一个可以包括指令高速缓存并且可以耦合到专用内存。结果,在一些示例中,向量处理器中的每一个可以被配置为独立于其他向量处理器执行。在其他示例中,包括在特定PVA中的向量处理器可以被配置为采用数据并行化。例如,在一些实施例中,包括在单个PVA中的多个向量处理器可以执行相同的计算机视觉算法,但是在图像的不同区域上执行。在其他示例中,包括在特定PVA中的向量处理器可以在相同的图像上同时执行不同的计算机视觉算法,或者甚至在序列图像或者图像的部分上执行不同的算法。除其他的以外,任意数量的PVA可以包括在硬件加速簇中,并且任意数量的向量处理器可以包括在这些PVA中的每一个中。此外,PVA可以包括附加的纠错码(ECC)内存,以增强总体系统安全性。
加速器1414(例如硬件加速簇)可以包括片上计算机视觉网络和SRAM,以提供用于加速器1414的高带宽、低延迟SRAM。在一些示例中,片上内存可以包括由例如且不限于八个现场可配置的内存块组成的至少4MB SRAM,其可以由PVA和DLA二者访问。每对内存块可以包括高级外围总线(APB)接口、配置电路系统、控制器和复用器。可以使用任何类型的内存。PVA和DLA可以经由向PVA和DLA提供高速内存访问的主干(backbone)访问内存。主干可以包括(例如使用APB)将PVA和DLA互连到内存的片上计算机视觉网络。
片上计算机视觉网络可以包括在传输任何控制信号/地址/数据之前确定PVA和DLA二者都提供就绪且有效的信号的接口。这样的接口可以提供用于传输控制信号/地址/数据的单独相位和单独信道,以及用于连续数据传输的突发式通信。这种类型的接口可以符合ISO 26262或者IEC 61508标准,但是也可以使用其他标准和协议。
在一些示例中,SoC 1404可以包括例如在2018年8月10日提交的美国专利申请No.16/101,232中描述的实时光线追踪硬件加速器。该实时光线追踪硬件加速器可以用来快速且高效地确定(例如世界模型内的)对象的位置和范围,以便生成实时可视化仿真,以用于RADAR信号解释、用于声音传播合成和/或分析、用于SONAR系统仿真、用于一般波传播仿真、用于为了定位和/或其他功能的目的与LIDAR数据相比较和/或用于其他用途。
加速器1414(例如硬件加速器簇)具有广泛的自主驾驶用途。PVA可以是可编程视觉加速器,其可以用于ADAS和自主车辆中的关键处理阶段。PVA的能力是需要可预测处理、低功率和低延迟的算法域的良好匹配。换言之,PVA在半密集或者密集规则计算上,甚至在需要具有低延迟和低功率的可预测运行时间的小数据集上都表现良好。因此,在用于自主车辆的平台的背景下,PVA被设计为运行经典计算机视觉算法,因为它们在对象检测和整数数学运算方面很有效。
例如,根据该技术的一个实施例,PVA用来执行计算机立体视觉。在一些示例中,可以使用基于半全局匹配的算法,但是这并不意图是限制性的。许多用于3-5级自主驾驶的应用都需要即时运动估计/立体匹配(例如来自运动的结构、行人识别、车道检测等等)。PVA可以在来自两个单目相机的输入上执行计算机立体视觉功能。
在一些示例中,PVA可以用来执行密集的光流。根据过程原始RADAR数据(例如使用4D快速傅立叶变换)以提供经处理的RADAR。在其他示例中,PVA用于飞行时间深度处理,其例如通过处理原始飞行时间数据以提供经处理的飞行时间数据。
DLA可以用来运行任何类型的网络以增强控制和驾驶安全性,包括例如输出用于每个对象检测的置信度度量的神经网络。这样的置信度值可以解释为概率,或者解释为提供每个检测与其他检测相比的相对“权重”。该置信度值使得系统能够做出关于哪些检测应当被认为是真阳性检测而不是假阳性检测的进一步决策。例如,系统可以为置信度设置阈值,并且仅仅将超过阈值的检测看作真阳性检测。在自动紧急制动(AEB)系统中,假阳性检测会使得车辆自动地执行紧急制动,这显然是不希望的。因此,只有最确信的检测才应当被认为是AEB的触发因素。DLA可以运行用于回归置信度值的神经网络。该神经网络可以将至少一些参数子集作为其输入,例如包围盒维度,(例如从另一个子系统)获得的地平面估计,与车辆1400取向、距离相关的惯性测量单元(IMU)传感器1466输出,从神经网络和/或其他传感器(例如LIDAR传感器1464或RADAR传感器1460)获得的对象的3D位置估计等。
SoC 1404可以包括一个或更多个数据存储1416(例如内存)。数据存储1416可以是SoC 1404的片上内存,其可以存储要在GPU和/或DLA上执行的神经网络。在一些示例中,为了冗余和安全,数据存储1416可以容量足够大以存储神经网络的多个实例。数据存储1412可以包括L2或L3高速缓存1412。对数据存储1416的引用可以包括对与如本文所描述的PVA、DLA和/或其他加速器1414关联的内存的引用。
SoC 1404可以包括一个或更多个处理器1410(例如嵌入式处理器)。处理器1410可以包括启动和功率管理处理器,其可以是用于处理启动功率和管理功能以及有关安全实施的专用处理器和子系统。启动和功率管理处理器可以是SoC 1404启动序列的一部分,并且可以提供运行时间功率管理服务。启动功率和管理处理器可以提供时钟和电压编程、辅助系统低功率状态转换、SoC 1404热和温度传感器管理和/或SoC 1404功率状态管理。每个温度传感器可以实现为环形振荡器,其输出频率与温度成比例,并且SoC 1404可以使用环形振荡器检测CPU 1406、GPU 1408和/或加速器1414的温度。如果确定温度超过阈值,那么启动和功率管理处理器可以进入温度故障例程并且将SoC 1404置于较低功率状态和/或将车辆1400置于司机安全停车模式(例如使车辆1400安全停车)。
处理器1410可以进一步包括可以用作音频处理引擎的一组嵌入式处理器。音频处理引擎可以是一种音频子系统,其允许实现对于通过多个接口的多声道音频的完全硬件支持以及一系列广泛而灵活的音频I/O接口。在一些示例中,音频处理引擎是具有带有专用RAM的数字信号处理器的专用处理器核。
处理器1410可以进一步包括始终在处理器上的引擎,其可以提供必要的硬件特征以支持低功率传感器管理和唤醒用例。该始终在处理器上的引擎可以包括处理器核、紧密耦合的RAM、支持外围设备(例如定时器和中断控制器)、各种I/O控制器外围设备和路由逻辑。
处理器1410可以进一步包括安全簇引擎,其包括处理汽车应用的安全管理的专用处理器子系统。安全簇引擎可以包括两个或更多处理器核、紧密耦合的RAM、支持外围设备(例如定时器、中断控制器等等)和/或路由逻辑。在安全模式下,所述两个或更多核可以操作于锁步模式下,并且用作具有检测它们的操作之间的任何差异的比较逻辑的单核。
处理器1410可以进一步包括实时相机引擎,其可以包括用于处理实时相机管理的专用处理器子系统。
处理器1410可以进一步包括高动态范围信号处理器,其可以包括图像信号处理器,该图像信号处理器是一种硬件引擎,该硬件引擎是相机处理管线的部分。
处理器1410可以包括可以是(例如微处理器上实现的)处理块的视频图像复合器,其实现视频回放应用程序生成用于播放器窗口的最终图像所需的视频后处理功能。视频图像复合器可以对广角相机1470、环绕相机1474和/或对驾驶室内监控相机传感器执行镜头畸变校正。驾驶室内监控相机传感器优选地由运行在高级SoC的另一个实例上的神经网络监控,被配置为识别驾驶室内事件并且相对应地做出响应。驾驶室内系统可以执行唇读,以激活移动电话服务并拨打电话、口述电子邮件、改变车辆目的地、激活或改变车辆的信息娱乐系统和设置或者提供语音激活的网上冲浪。某些功能仅在车辆操作于自主模式下时对于驾驶员可用,并且在其他情况下被禁用。
视频图像复合器可以包括用于空间和时间降噪的增强时间降噪。例如,在视频中出现运动的情况下,降噪适当地对空间信息加权,降低邻近帧提供的信息的权重。在图像或者图像的部分不包括运动的情况下,视频图像复合器执行的时间降噪可以使用来自先前的图像的信息以降低当前图像中的噪声。
视频图像复合器也可以被配置为对输入立体镜头帧执行立体校正。当操作系统桌面正在使用并且GPU 1408无需连续地渲染(render)新的表面时,视频图像复合器可以进一步用于用户接口组成。甚至在GPU 1408上电并且激活,进行3D渲染时,视频图像复合器可以用来减轻GPU 1408的负担以提高性能和响应能力。
SoC 1404可以进一步包括用于从相机接收视频和输入的移动行业处理器接口(MIPI)相机串行接口、高速接口和/或可以用于相机和有关像素输入功能的视频输入块。SoC 1404可以进一步包括可以由软件控制并且可以用于接收未提交到特定角色的I/O信号的输入/输出控制器。
SoC 1404可以进一步包括大范围的外围设备接口,以使能与外围设备、音频编解码器、功率管理和/或其他设备通信。SoC 1404可以用来处理来自(通过千兆多媒体串行链路和以太网连接的)相机、传感器(例如可以通过以太网连接的LIDAR传感器1464、RADAR传感器1460等等)的数据,来自总线1402的数据(例如车辆1400的速率、方向盘位置等等),来自(通过以太网或CAN总线连接的)GNSS传感器1458的数据。SoC 1404可以进一步包括专用高性能大容量存储控制器,其可以包括它们自己的DMA引擎,并且其可以用来从日常数据管理任务中释放CPU 1406。
SoC 1404可以是具有灵活架构的端到端平台,该架构跨越自动化3-5级,从而提供利用和高效使用计算机视觉和ADAS技术以实现多样性和冗余、连同深度学习工具一起提供用于灵活可靠驾驶软件堆栈的平台的综合功能安全架构。SoC 1404可以比常规的系统更快、更可靠,甚至更加能量高效和空间高效。例如,当与CPU 1406、GPU 1408和数据存储1416结合时,加速器1414可以提供用于3-5级自主车辆的快速高效平台。
因此该技术提供了不能通过常规系统实现的能力和功能。例如,计算机视觉算法可以在CPU上执行,这些CPU可以使用诸如C编程语言之类的高级编程语言配置为跨各种各样的视觉数据执行各种各样的处理算法。然而,CPU常常不能满足许多计算机视觉应用的性能要求,诸如与例如执行时间和功耗有关的那些要求。特别地,许多CPU不能实时地执行复杂的对象检测算法,这是车载ADAS应用的要求和实用3-5级自主车辆的要求。
与常规系统形成对比的是,通过提供CPU复合体、GPU复合体和硬件加速簇,本文描述的技术允许同时和/或顺序地执行多个神经网络,并且将结果组合在一起以实现3-5级自主驾驶功能。例如,在DLA或dGPU(例如GPU 1420)上执行的CNN可以包括文本和单词识别,允许超级计算机读取和理解交通指示牌,包括尚未针对其特别地训练神经网络的指示牌。DLA可以进一步包括能够识别、解释和提供对指示牌的语义理解,并且将该语义理解传递给运行在CPU复合体上的路径规划模块的神经网络。
作为另一个示例,如3、4或5级驾驶所需的,多个神经网络可以同时运行。例如,由“注意:闪烁的灯指示结冰条件”组成的警告指示牌连同电灯可以由若干神经网络独立地或者共同地进行解释。指示牌本身可以由部署的第一神经网络(例如经过训练的神经网络)识别为交通指示牌,文本“闪烁的灯指示结冰条件”可以由部署的第二神经网络解释,该部署的第二神经网络告知车辆的路径规划软件(优选地在CPU复合体上执行)当检测到闪烁的灯时,存在结冰条件。闪烁的灯可以通过在多个帧上操作部署的第三神经网络而识别,该神经网络告知车辆的路径规划软件闪烁的灯的存在(或不存在)。所有三个神经网络可以例如在DLA内和/或在GPU 1408上同时运行。
在一些示例中,用于面部识别和车主识别的CNN可以使用来自相机传感器的数据识别车辆1400的授权的驾驶员和/或车主的存在。始终在传感器上的处理引擎可以用来在车主接近驾驶员车门时解锁车辆并且打开灯,并且在安全模式下,在车主离开车辆时禁用车辆。按照这种方式,SoC 1404提供了防范盗窃和/或劫车的安全性。
在另一个示例中,用于应急车辆检测和识别的CNN可以使用来自麦克风1496的数据来检测并且识别应急车辆警报(siren)。与使用通用分类器检测警报并且手动地提取特征的常规系统形成对比的是,SoC 1404使用CNN以对环境和城市声音分类以及对视觉数据分类。在优选的实施例中,运行在DLA上的CNN被训练为识别应急车辆的相对关闭速率(例如通过使用多普勒效应)。CNN也可以被训练为识别如GNSS传感器1458所识别的特定于车辆在其中操作的局部区域的应急车辆。因此,例如,当在欧洲操作时,CNN将寻求检测欧洲警报,并且当在美国时,CNN将寻求识别仅仅北美的警报。一旦检测到应急车辆,在超声传感器1462的辅助下,控制程序可以用来执行应急车辆安全例程,使车辆放慢速度,开到路边,停下车辆,和/或使车辆空转,直到应急车辆通过。
车辆可以包括可以经由高速互连(例如PCIe)耦合到SoC 1404的CPU 1418(例如分立的CPU或dCPU)。CPU 1418可以包括例如X86处理器。CPU 1418可以用来执行各种各样的功能中的任何功能,包括例如仲裁ADAS传感器与SoC 1404之间潜在地不一致的结果,和/或监控控制器1436和/或信息娱乐SoC 1430的状态和健康状况。
车辆1400可以包括可以经由高速互连(例如NVIDIA的NVLINK)耦合到SoC 1404的GPU 1420(例如分立的GPU或dGPU)。GPU 1420可以例如通过执行冗余的和/或不同的神经网络而提供附加的人工智能功能,并且可以用来至少部分地基于来自车辆1400的传感器的输入(例如传感器数据)来训练和/或更新神经网络。
车辆1400可以进一步包括网络接口1424,该网络接口可以包括一个或更多个无线天线1426(例如用于不同通信协议的一个或更多个无线天线,例如蜂窝天线、蓝牙天线等等)。网络接口1424可以用来使能通过因特网与云(例如与服务器1478和/或其他网络设备)、与其他车辆和/或与计算设备(例如乘客的客户端设备)的无线连接。为了与其他车辆通信,可以在这两辆车之间建立直接链接,和/或可以建立间接链接(例如跨网络以及通过因特网)。直接链接可以使用车对车通信链路提供。车对车通信链路可以向车辆1400提供关于接近车辆1400的车辆(例如车辆1400前面、侧面和/或后面的车辆)的信息。该功能可以是车辆1400的协作自适应巡航控制功能的部分。
网络接口1424可以包括提供调制和解调功能并且使得控制器1436能够通过无线网络通信的SoC。网络接口1424可以包括用于从基带到射频的上转换以及从射频到基带的下转换的射频前端。频率转换可以通过公知的过程执行,和/或可以使用超外差(super-heterodyne)过程执行。在一些示例中,射频前端功能可以由单独的芯片提供。网络接口可以包括用于通过LTE、WCDMA、UMTS、GSM、CDMA2000、蓝牙、蓝牙LE、Wi-Fi、Z波、ZigBee、LoRaWAN和/或其他无线协议通信的无线功能。
车辆1400可以进一步包括可包括片外(例如SoC 1404外)存储装置的数据存储1428。数据存储1428可以包括一个或更多个存储元件,包括RAM、SRAM、DRAM、VRAM、闪存、硬盘和/或可以存储至少一个比特的数据的其他部件和/或设备。
车辆1400可以进一步包括GNSS传感器1458。GNSS传感器1458(例如GPS和/或辅助GPS传感器)用于辅助映射、感知、占用网格生成和/或路径规划功能。可以使用任意数量的GNSS传感器1458,包括例如且不限于使用带有以太网到串行(RS-232)网桥的USB连接器的GPS。
车辆1400可以进一步包括RADAR传感器1460。RADAR传感器1460可以甚至在黑暗和/或恶劣天气条件下也由车辆1400用于远程车辆检测。RADAR功能安全级别可以是ASILB。RADAR传感器1460可以使用CAN和/或总线1402(例如以传输RADAR传感器1460生成的数据)以用于控制以及访问对象跟踪数据,在一些示例中接入以太网以访问原始数据。可以使用各种各样的RADAR传感器类型。例如且非限制性地,RADAR传感器1460可以适合前面、后面和侧面RADAR使用。在一些示例中,使用脉冲多普勒RADAR传感器。
RADAR传感器1460可以包括不同的配置,例如具有窄视场的远程、具有宽视场的短程、短程侧覆盖等等。在一些示例中,远程RADAR可以用于自适应巡航控制功能。远程RADAR系统可以提供通过两个或更多独立扫描实现的广阔视场(例如250m范围内)。RADAR传感器1460可以帮助区分静态对象和运动对象,并且可以由ADAS系统用于紧急制动辅助和前方碰撞警告。远程RADAR传感器可以包括具有多根(例如六根或更多)固定RADAR天线以及高速CAN和FlexRay接口的单站多模RADAR。在具有六根天线的示例中,中央四根天线可以创建聚焦的波束图案,其被设计为在更高速率下以来自邻近车道的最小交通干扰记录车辆1400的周围环境。其他两根天线可以扩展视场,使得快速地检测进入或离开车辆1400的车道的车辆成为可能。
作为一个示例,中程RADAR系统可以包括高达1460m(前面)或80m(后面)的范围以及高达42度(前面)或1450度(后面)的视场。短程RADAR系统可以包括但不限于被设计为安装在后保险杠两端的RADAR传感器。当安装在后保险杠两端时,这样的RADAR传感器系统可以创建持续地监控后方和车辆旁边的盲点的两个波束。
短程RADAR系统可以在ADAS系统中用于盲点检测和/或变道辅助。
车辆1400可以进一步包括超声传感器1462。可以置于车辆1400的前面、后面和/或侧面的超声传感器1462可以用于停车辅助和/或创建和更新占用网格。可以使用各种各样的超声传感器1462,并且不同的超声传感器1462可以用于不同的检测范围(例如2.5m、4m)。超声传感器1462可以操作于功能安全级别的ASIL B。
车辆1400可以包括LIDAR传感器1464。LIDAR传感器1464可以用于对象和行人检测、紧急制动、碰撞避免和/或其他功能。LIDAR传感器1464可以为功能安全级别的ASIL B。在一些示例中,车辆1400可以包括可以使用以太网(例如以将数据提供给千兆以太网交换机)的多个LIDAR传感器1464(例如两个、四个、六个等等)。
在一些示例中,LIDAR传感器1464可能够对360度视场提供对象列表及其距离。商业上可用的LIDAR传感器1464可以具有例如近似1400m的广告范围,精度为2cm-3cm,支持1400Mbps以太网连接。在一些示例中,可以使用一个或更多个非突出的LIDAR传感器1464。在这样的示例中,LIDAR传感器1464可以实现为可以嵌入到车辆1400的前面、后面、侧面和/或拐角的小设备。在这样的示例中,LIDAR传感器1464可以甚至对于低反射率对象提供高达1420度水平的和35度竖直的视场,具有200m的范围。前面安装的LIDAR传感器1464可以被配置用于45度与135度之间的水平视场。
在一些示例中,也可以使用诸如3D闪光LIDAR之类的LIDAR技术。3D闪光LIDAR使用激光的闪光作为发射源,以照亮高达约200m的车辆周围环境。闪光LIDAR单元包括接受器,该接受器将激光脉冲传输时间和反射光记录在每个像素上,其进而与从车辆到对象的范围相对应。闪光LIDAR可以允许利用每个激光闪光生成周围环境的高度精确且无失真的图像。在一些示例中,可以部署四个闪光LIDAR传感器,车辆1400的每一侧一个。可用的3D闪光LIDAR系统包括没有风扇以外的运动部件(moving part)的固态3D凝视阵列LIDAR相机(例如非扫描LIDAR设备)。闪光LIDAR设备可以使用每帧5纳秒I类(眼睛安全)激光脉冲,并且可以以3D范围点云和共同寄存的强度数据的形式捕获反射的激光。通过使用闪光LIDAR,并且因为闪光LIDAR是没有运动部件的固态设备,LIDAR传感器1464可以不太容易受到运动模糊、振动和/或震动的影响。
该车辆可以进一步包括IMU传感器1466。在一些示例中,IMU传感器1466可以位于车辆1400的后轴的中心。IMU传感器1466可以包括例如且不限于加速度计、磁力计、陀螺仪、磁罗盘和/或其他传感器类型。在一些示例中,例如在六轴应用中,IMU传感器1466可以包括加速度计和陀螺仪,而在九轴应用中,IMU传感器1466可以包括加速度计、陀螺仪和磁力计。
在一些实施例中,IMU传感器1466可以实现为微型高性能GPS辅助惯性导航系统(GPS/INS),其结合微机电系统(MEMS)惯性传感器、高灵敏度GPS接收器和高级卡尔曼滤波算法以提供位置、速度和姿态的估计。这样,在一些示例中,IMU传感器1466可以使得车辆1400能够在无需来自磁传感器的输入的情况下通过直接观察从GPS到IMU传感器1466的速度变化并且将其相关来估计方向(heading)。在一些示例中,IMU传感器1466和GNSS传感器1458可以结合到单个集成单元中。
该车辆可以包括置于车辆1400中和/或车辆1400周围的麦克风1496。除别的以外,麦克风1496可以用于应急车辆检测和识别。
该车辆可以进一步包括任意数量的相机类型,包括立体相机1468、广角相机1470、红外相机1472、环绕相机1474、远程和/或中程相机1498和/或其他相机类型。这些相机可以用来捕获车辆1400整个外围周围的图像数据。使用的相机类型取决于实施例和车辆1400的要求,并且相机类型的任意组合可以用来提供车辆1400周围的必要覆盖。此外,相机的数量可以根据实施例而不同。例如,该车辆可以包括六个相机、七个相机、十个相机、十二个相机和/或另一数量的相机。作为一个示例且非限制性地,这些相机可以支持千兆多媒体串行链路(GMSL)和/或千兆以太网。所述相机中的每一个在本文关于图14A和图14B更详细地进行了描述。
车辆1400可以进一步包括振动传感器1442。振动传感器1442可以测量车辆的诸如车轴之类的部件的振动。例如,振动的变化可以指示道路表面的变化。在另一个示例中,当使用两个或更多振动传感器1442时,振动之间的差异可以用来确定道路表面的摩擦或滑移(例如当动力驱动轴与自由旋转轴之间存在振动差异时)。
车辆1400可以包括ADAS系统1438。在一些示例中,ADAS系统1438可以包括SoC。ADAS系统1438可以包括自主/自适应/自动巡航控制(ACC)、协作自适应巡航控制(CACC)、前方撞车警告(FCW)、自动紧急制动(AEB)、车道偏离警告(LDW)、车道保持辅助(LKA)、盲点警告(BSW)、后方穿越交通警告(RCTW)、碰撞警告系统(CWS)、车道居中(LC)和/或其他特征和功能。
ACC系统可以使用RADAR传感器1460、LIDAR传感器1464和/或相机。ACC系统可以包括纵向ACC和/或横向ACC。纵向ACC监控并控制到紧接在车辆1400前方的车辆的距离,并且自动地调节车速以维持离前方车辆的安全距离。横向ACC执行距离保持,并且在必要时建议车辆1400改变车道。横向ACC与诸如LCA和CWS之类的其他ADAS应用程序有关。
CACC使用来自其他车辆的信息,该信息可以经由网络接口1424和/或无线天线1426经由无线链路或者通过网络连接(例如通过因特网)间接地从其他车辆接收。直接链接可以由车对车(V2V)通信链路提供,而间接链接可以是基础设施到车辆(I2V)的通信链路。通常,V2V通信概念提供关于紧接在前的车辆(例如紧接在车辆1400前方且与其处于相同车道的车辆)的信息,而I2V通信概念提供关于前方更远处的交通的信息。CACC系统可以包括I2V和V2V信息源中的任一个或者二者。给定车辆1400前方车辆的信息,CACC可以更加可靠,并且它有可能提高交通流的畅通性且降低道路拥堵。
FCW系统被设计为提醒驾驶员注意危险,使得驾驶员可以采取纠正措施。FCW系统使用耦合到专用处理器、DSP、FPGA和/或ASIC的前置相机和/或RADAR传感器1460,该专用处理器、DSP、FPGA和/或ASIC电耦合至诸如显示器、扬声器和/或振动部件之类的驾驶员反馈。FCW系统可以提供例如声音、视觉警告、振动和/或快速制动脉冲形式的警告。
AEB系统检测即将发生的与另一车辆或其他对象的前方碰撞,并且可以在驾驶员在指定的时间或距离参数内没有采取纠正措施的情况下自动地应用制动器。AEB系统可以使用耦合到专用处理器、DSP、FPGA和/或ASIC的前置相机和/或RADAR传感器1460。当AEB系统检测到危险时,它典型地首先提醒(alert)驾驶员采取纠正措施以避免碰撞,并且如果驾驶员没有采取纠正措施,那么AEB系统可以自动地应用制动器以努力防止或者至少减轻预测的碰撞的影响。AEB系统可以包括诸如动态制动支持和/或碰撞迫近制动之类的技术。
LDW系统提供了诸如方向盘或座位振动之类的视觉、听觉和/或触觉警告,以在车辆1400穿过车道标记时提醒驾驶员。当驾驶员指示有意偏离车道时,通过激活转弯信号,不激活LDW系统。LDW系统可以使用耦合到专用处理器、DSP、FPGA和/或ASIC的前侧朝向相机,该专用处理器、DSP、FPGA和/或ASIC电耦合至诸如显示器、扬声器和/或振动部件之类的驾驶员反馈。
LKA系统是LDW系统的变型。如果车辆1400开始离开车道,那么LKA系统提供纠正车辆1400的转向输入或制动。
BSW系统检测并向驾驶员警告汽车盲点中的车辆。BSW系统可以提供视觉、听觉和/或触觉警报以指示合并或改变车道是不安全的。系统可以在驾驶员使用转弯信号时提供附加的警告。BSW系统可以使用耦合到专用处理器、DSP、FPGA和/或ASIC的后侧朝向相机和/或RADAR传感器1460,该专用处理器、DSP、FPGA和/或ASIC电耦合至诸如显示器、扬声器和/或振动部件之类的驾驶员反馈。
RCTW系统可以在车辆1400倒车时在后置相机范围之外检测到对象时提供视觉、听觉和/或触觉通知。一些RCTW系统包括AEB以确保应用车辆制动器以避免撞车。RCTW系统可以使用耦合到专用处理器、DSP、FPGA和/或ASIC的一个或更多个后置RADAR传感器1460,该专用处理器、DSP、FPGA和/或ASIC电耦合至诸如显示器、扬声器和/或振动部件之类的驾驶员反馈。
常规的ADAS系统可能易于出现假阳性结果,这可能会让驾驶员烦恼并分散注意力,但是典型地不是灾难性的,因为ADAS系统提醒驾驶员并且允许驾驶员决定安全条件是否真正存在并且相对应地采取行动。然而,在自主车辆1400中,在冲突结果的情况下,车辆1400本身必须决定是否注意(heed)来自主计算机或者辅助计算机(例如第一控制器1436或第二控制器1436)的结果。例如,在一些实施例中,ADAS系统1438可以是用于向备用计算机合理性模块提供感知信息的备用和/或辅助计算机。备用计算机合理性监视器可以在硬件部件上运行冗余多样的软件,以检测感知和动态驾驶任务中的故障。来自ADAS系统1438的输出可以提供给监督MCU。如果来自主计算机和辅助计算机的输出冲突,那么监督MCU必须确定如何协调该冲突以确保安全操作。
在一些示例中,主计算机可以被配置为向监督MCU提供置信度评分,指示主计算机对所选结果的置信度。如果置信度评分超过阈值,那么监督MCU可以遵循主计算机的方向,而不管辅助计算机是否提供冲突或不一致的结果。在置信度评分不满足阈值的情况下并且在主计算机和辅助计算机指示不同的结果(例如冲突)的情况下,监督MCU可以在这些计算机之间进行仲裁以确定适当的结果。
监督MCU可以被配置为运行神经网络,所述神经网络被训练并且被配置为基于来自主计算机和辅助计算机的输出,确定辅助计算机提供假警报的条件。因此,监督MCU中的神经网络可以了解何时可以信任辅助计算机的输出以及何时不能。例如,当辅助计算机为基于RADAR的FCW系统时,监督MCU中的神经网络可以了解FCW系统何时正在识别事实上不是危险的金属对象,例如触发警报的排水栅格或井盖。类似地,当辅助计算机是基于相机的LDW系统时,监督MCU中的神经网络可以学习在骑车者或行人在场并且车道偏离实际上是最安全的策略时无视该LDW。在包括运行在监督MCU上的神经网络的实施例中,监督MCU可以包括适合于利用关联的内存运行神经网络的DLA或GPU中的至少一个。在优选的实施例中,监督MCU可以包括SoC 1404的部件和/或作为SoC 1404的部件而被包括。
在其他示例中,ADAS系统1438可以包括使用传统计算机视觉规则执行ADAS功能的辅助计算机。这样,辅助计算机可以使用经典的计算机视觉规则(如果-那么),并且在监督MCU中存在神经网络可以提高可靠性、安全性和性能。例如,多样化的实现方式和有意的非完全相同(non-identity)使得整个系统更加容错,对于软件(或者软件-硬件接口)功能造成的故障而言尤其如此。例如,如果在主计算机上运行的软件中存在软件漏洞或错误并且运行在辅助计算机上的非完全相同的软件代码提供相同的总体结果,那么监督MCU可以更加确信总体结果是正确的,并且主计算机上的软件或硬件中的漏洞不造成实质性的错误。
在一些示例中,ADAS系统1438的输出可以馈送至主计算机的感知块和/或主计算机的动态驾驶任务块。例如,如果ADAS系统1438由于对象紧接在前的原因而指示前方碰撞警告,那么感知块可以在识别对象时使用该信息。在其他示例中,辅助计算机可以具有它自己的神经网络,其被训练并且因此如本文所描述的降低假阳性的风险。
车辆1400可以进一步包括信息娱乐SoC 1430(例如车载信息娱乐系统(IVI))。尽管被图示和描述为SoC,但是信息娱乐系统可以不是SoC,并且可以包括两个或更多分立的部件。信息娱乐SoC 1430可以包括可以用来向车辆1400提供音频(例如音乐、个人数字助理、导航指令、新闻、广播等等)、视频(例如TV、电影、流媒体等等)、电话(例如免提呼叫)、网络连接(例如LTE、WiFi等等)和/或信息服务(例如导航系统,后停车援助,无线电数据系统,诸如燃油水平、覆盖的总距离、制动燃油水平、油位、车门开/关、空气滤波器信息之类的车辆有关信息,等等)的硬件和软件的组合。例如,信息娱乐SoC 1430可以包括收音机、盘播放器、导航系统、视频播放器、USB和蓝牙连接、车载电脑、车载娱乐、WiFi、方向盘音频控件、免提语音控件、平视显示器(HUD)、HMI显示器1434、远程信息处理设备、控制面板(例如用于控制各种部件、特征和/或系统,和/或与其交互)和/或其他部件。信息娱乐SoC 1430可以进一步用来向车辆的用户提供信息(例如视觉的和/或听觉的),例如来自ADAS系统1438的信息,诸如规划的车辆机动、轨迹、周围环境信息(例如交叉路口信息、车辆信息、道路信息等等)之类的自主驾驶信息,和/或其他信息。
信息娱乐SoC 1430可以包括GPU功能。信息娱乐SoC 1430可以通过总线1402(例如CAN总线、以太网等)与车辆1400的其他设备、系统和/或部件通信。在一些示例中,信息娱乐SoC 1430可以耦合至监督MCU,使得在主控制器1436(例如车辆1400的主和/或备用计算机)出现故障的情况下,信息娱乐系统的GPU可以执行一些自驾驶功能。在这样的示例中,信息娱乐SoC 1430可以如本文所描述的将车辆1400置于司机安全停车模式。
车辆1400可以进一步包括仪表组1432(例如数字仪表板、电子仪表组、数字仪表面板等等)。仪表组1432可以包括控制器和/或超级计算机(例如分立的控制器或超级计算机)。仪表组1432可以包括一套仪器,例如车速表、燃油水平、油压、转速表、里程表、转弯指示器、换档位置指示器、安全带警告灯、停车制动警告灯、发动机故障灯、安全气囊(SRS)系统信息、照明控件、安全系统控件、导航信息等等。在一些示例中,信息可以被显示和/或在信息娱乐SoC 1430和仪表组1432之间共享。换言之,仪表组1432可以作为信息娱乐SoC1430的部分而被包括,或者反之亦然。
图14D为根据本公开一些实施例的基于云的服务器与图14A的示例自主车辆1400之间的通信的系统示意图。系统1476可以包括服务器1478、网络1490以及包括车辆1400在内的车辆。服务器1478可以包括多个GPU 1484(A)-1484(H)(本文统称为GPU 1484)、PCIe交换机1482(A)-1482(H)(本文统称为PCIe交换机1482)和/或CPU 1480(A)-1480(B)(本文统称为CPU 1480)。GPU 1484、CPU 1480和PCIe交换机可以与诸如例如且不限于NVIDIA开发的NVLink接口1488之类的高速互连和/或PCIe连接1486互连。在一些示例中,GPU 1484经由NVLink和/或NVSwitch SoC连接,并且GPU 1484和PCIe交换机1482经由PCIe互连连接。尽管图示出八个GPU 1484、两个CPU 1480和两个PCIe交换机,但是这并不意图是限制性的。取决于实施例,服务器1478中的每一个可以包括任意数量的GPU 1484、CPU 1480和/或PCIe交换机。例如,服务器1478中的每一个可以包括八个、十六个、三十二个和/或更多GPU 1484。
服务器1478可以通过网络1490并且从车辆接收图像数据,该图像数据表示示出诸如最近开始的道路工程之类的意外或改变的道路状况的图像。服务器1478可以通过网络1490并且向车辆传输神经网络1492、更新的神经网络1492和/或地图信息1494,包括关于交通和道路状况的信息。对地图信息1494的更新可以包括对于HD地图1422的更新,例如关于建筑工地、坑洼、弯道、洪水或其他障碍物的信息。在一些示例中,神经网络1492、更新的神经网络1492和/或地图信息1494可以已从新的训练和/或从环境中的任意数量的车辆接收的数据中表示和/或至少部分地基于数据中心处执行的训练(例如使用服务器1478和/或其他服务器)的经验生成。
服务器1478可以用来至少部分地基于训练数据训练一个或更多个机器学习模型(例如神经网络)。训练数据可以由车辆生成,和/或可以在仿真中生成(例如使用游戏引擎)。在一些示例中,训练数据被标记(例如在神经网络受益于有监督学习的情况下)和/或经历其他预处理,而在其他示例中,训练数据不被标记和/或预处理(例如在神经网络无需有监督学习的情况下)。一旦一个或更多个机器学习模型被训练,一个或更多个机器学习模型可以由车辆使用(例如通过网络1490传输至车辆),和/或一个或更多个机器学习模型可以由服务器1478用来远程地监控车辆。
在一些示例中,服务器1478可以接收来自车辆的数据,并且将该数据应用到最新的实时神经网络以用于实时智能推理。服务器1478可以包括由GPU 1484供电的深度学习超级计算机和/或专用AI计算机,例如NVIDIA开发的DGX和DGX站机器。然而,在一些示例中,服务器1478可以包括仅使用CPU供电的数据中心的深度学习基础设施。
服务器1478的深度学习基础设施可能够快速实时推理,并且可以使用该能力来评估并验证车辆1400中的处理器、软件和/或关联硬件的健康状况。例如,深度学习基础设施可以接收来自车辆1400的定期更新,例如图像序列和/或车辆1400已经定位的位于该图像序列中的对象(例如经由计算机视觉和/或其他机器学习对象分类技术)。深度学习基础设施可以运行它自己的神经网络以识别对象并且将它们与车辆1400识别的对象相比较,如果结果不匹配并且该基础设施得出车辆1400中的AI发生故障的结论,那么服务器1478可以向车辆1400传输信号,指示车辆1400的故障保护计算机进行控制,通知乘客,并且完成安全停车操作。
为了推理,服务器1478可以包括GPU 1484和一个或更多个可编程推理加速器(例如NVIDIA的TensorRT 3)。GPU供电的服务器和推理加速的组合可以使得实时响应成为可能。在其他示例中,例如在性能不那么重要的情况下,CPU、FPGA和其他处理器供电的服务器可以用于推理。
示例计算设备
图15为适合用于实现本公开一些实施例的示例计算设备1500的框图。计算设备1500可以包括直接或间接耦合下列设备的总线1502:内存1504,一个或更多个中央处理单元(CPU)1506,一个或更多个图形处理单元(GPU)1508,通信接口1510,输入/输出(I/O)端口1512,输入/输出组件1514,电源1516,以及一个或更多个呈现组件1518(例如显示器)。
尽管图15的各个框被示为经由具有线路的总线1502连接,但是这并不意图是限制性的,并且仅仅为了清楚起见。例如,在一些实施例中,诸如显示设备之类的呈现组件1518可以被认为是I/O组件1514(例如如果显示器为触摸屏)。作为另一个示例,CPU 1506和/或GPU 1508可以包括内存(例如,内存1504可以表示除了GPU 1508、CPU 1506和/或其他组件的内存以外的存储设备)。换言之,图15的计算设备仅仅是说明性的。在诸如“工作站”、“服务器”、“膝上型电脑”、“台式机”、“平板电脑”、“客户端设备”、“移动设备”、“手持式设备”、“游戏控制台”、“电子控制单元(ECU)”、“虚拟现实系统”、“汽车计算设备”和/或其他设备或系统类型之类的类别之间不进行区分,因为所有这些都被考虑在图15的计算设备的范围内。在一些实施例中,本文关于图15描述的一个或更多个组件可由车辆1400使用,如本文所述。例如,CPU 1506、GPU 1508和/或其他组件可类似于本文所述的车辆1400的一个或更多个组件或可执行其功能。
总线1502可以表示一条或更多条总线,例如地址总线、数据总线、控制总线或者其组合。总线1502可以包括一种或更多种总线类型,例如行业标准架构(ISA)总线、扩展行业标准架构(EISA)总线、视频电子标准协会(VESA)总线、外围组件互连(PCI)总线、外围组件互连快速(PCIe)总线,和/或另一种类型的总线。
内存1504可以包括各种各样的计算机可读介质中的任何介质。计算机可读介质可以是可以由计算设备1500访问的任何可用介质。计算机可读介质可以包括易失性和非易失性介质以及可移除和不可移除介质。举例而言且非限制性地,计算机可读介质可以包括计算机存储介质和通信介质。
计算机存储介质可以包括易失性和非易失性介质和/或可移除和不可移除介质,其以用于存储诸如计算机可读指令、数据结构、程序模块和/或其他数据类型之类的信息的任何方法或技术实现。例如,内存1504可以存储计算机可读指令(例如其表示程序和/或程序元素,例如操作系统)。计算机存储介质可以包括但不限于RAM、ROM、EEPROM、闪存或者其他存储技术、CD-ROM、数字多功能盘(DVD)或其他光盘存储装置、磁带盒、磁带、磁盘存储装置或其他磁存储设备,或者可以用来存储期望的信息且可以由计算设备1500访问的任何其他介质。当在本文使用时,计算机存储介质并不包括信号本身。
通信介质可以在诸如载波之类的调制数据信号或其他传输机制中包含计算机可读指令、数据结构、程序模块和/或其他数据类型,并且包括任何信息输送介质。术语“调制数据信号”可以指这样的信号,该信号使它的特性中的一个或更多个以这样的将信息编码到该信号中的方式设置或改变。举例而言且非限制性地,通信介质可以包括诸如有线网络或直接有线连接之类的有线介质,以及诸如声音、RF、红外和其他无线介质之类的无线介质。任何以上所述的组合也应当包含在计算机可读介质的范围内。
CPU 1506可以被配置为执行计算机可读指令以便控制计算设备1500的一个或更多个组件执行本文描述的方法和/或过程中的一个或更多个。CPU 1506中的每一个可以包括能够同时处理大量软件线程的一个或更多个核(例如一个、两个、四个、八个、二十八个、七十二个等等)。CPU 1506可以包括任何类型的处理器,并且可以包括不同类型的处理器,这取决于实现的计算设备1500的类型(例如具有用于移动设备的较少核的处理器以及具有用于服务器的更多核的处理器)。例如,取决于计算设备1500的类型,处理器可以是使用精简指令集计算(RISC)实现的ARM处理器或者使用复杂指令集计算(CISC)实现的x86处理器。除了一个或更多个微处理器或者诸如数学协处理器之类的补充协处理器之外,计算设备1500还可以包括一个或更多个CPU 1506。
GPU 1508可以由计算设备1500用来渲染图形(例如3D图形)。GPU1508可以包括能够同时处理数百或数千个软件线程的数百或数千个核。GPU 1508可以响应于渲染命令(例如经由主机接口接收的来自CPU 1506的渲染命令)而生成用于输出图像的像素数据。GPU1508可以包括诸如显示内存之类的用于存储像素数据的图形内存。显示内存可以作为内存1504的部分而被包括。GPU 1508可以包括(例如经由链路)并行操作的两个或更多GPU。当组合在一起时,每个GPU 1508可以生成用于输出图像的不同部分或者用于不同输出图像的像素数据(例如,第一GPU用于第一图像,第二GPU用于第二图像)。每个GPU可以包括它自己的内存,或者可以与其他GPU共享内存。
在其中计算设备1500不包括GPU 1508的示例中,CPU 1506可以用来渲染图形。
通信接口1510可以包括一个或更多个接收器、发送器和/或收发器,其使得计算设备1500能够经由电子通信网络与其他计算设备通信,包括有线和/或无线通信。通信接口1510可以包括使能通过若干不同网络中的任何网络进行通信的组件和功能,所述网络例如无线网络(例如Wi-Fi、Z波、蓝牙、蓝牙LE、ZigBee等等)、有线网络(例如通过以太网通信)、低功率广域网(例如LoRaWAN、SigFox等等)和/或因特网。
I/O端口1512可以使得计算设备1500能够逻辑地耦合到包括I/O组件1514、呈现组件1518和/或其他组件在内的其他设备,其中一些可以内置到(例如集成到)计算设备1500中。说明性I/O组件1514包括麦克风、鼠标、键盘、操纵杆、游戏垫、游戏控制器、碟形卫星天线、扫描仪、打印机、无线设备等等。I/O组件1514可以提供处理用户生成的空中手势、语音或其他生理输入的自然用户接口(NUI)。在一些实例中,输入可以传输至适当的网络元件以便进一步处理。NUI可以实现语音识别、手写笔识别、面部识别、生物特征识别、屏幕上和邻近屏幕的手势识别、空中手势、头部和眼睛跟踪以及与计算设备1500的显示器关联的触摸识别(如下文更详细地描述的)的任意组合。计算设备1500可以包括诸如立体相机系统之类的深度相机、红外相机系统、RGB相机系统、触摸屏技术以及这些的组合,以用于手势检测和识别。此外,计算设备1500可以包括使能运动检测的加速度计或陀螺仪(例如作为惯性测量单元(IMU)的部分)。在一些示例中,加速度计或陀螺仪的输出可以由计算设备1500用来渲染沉浸式增强现实或者虚拟现实。
电源1516可以包括硬接线电源、电池电源或者其组合。电源1516可以向计算设备1500供电以使得计算设备1500的组件能够操作。
呈现组件1518可以包括显示器(例如监视器、触摸屏、电视屏幕、平视显示器(HUD)、其他显示器类型或者其组合)、扬声器和/或其他呈现组件。呈现组件1518可以接收来自其他组件(例如GPU 1508、CPU1506等等)的数据,并且输出该数据(例如作为图像、视频、声音等等)。
本公开可以在由计算机或者诸如个人数字助理或其他手持式设备之类的其他机器执行的、包括诸如程序模块之类的计算机可执行指令的机器可使用指令或者计算机代码的一般背景下进行描述。通常,包括例程、程序、对象、组件、数据结构等等的程序模块指的是执行特定任务或者实现特定抽象数据类型的代码。本公开可以在各种各样的系统配置中实践,这些配置包括手持式设备、消费电子器件、通用计算机、更专业的计算设备等等。本公开也可以在其中任务由通过通信网络链接的远程处理设备执行的分布式计算环境中实践。
如在本文中使用的,“和/或”关于两个或更多元素的叙述应当解释为仅指一个元素或者元素组合。例如,“元素A、元素B和/或元素C”可以包括仅仅元素A,仅仅元素B,仅仅元素C,元素A和元素B,元素A和元素C,元素B和元素C,或者元素A、B和C。此外,“元素A或元素B中的至少一个”可以包括元素A中的至少一个,元素B中的至少一个,或者元素A中的至少一个和元素B中的至少一个。进一步,“元素A和元素B中的至少一个”可以包括元素A中的至少一个,元素B中的至少一个,或者元素A中的至少一个和元素B中的至少一个。
本文详细地描述了本公开的主题以满足法定要求。然而,描述本身并非意在限制本公开的范围。相反地,本发明人已经设想到,要求保护的主题也可以以其他的方式具体化,以包括与本文中结合其他当前或未来技术描述的步骤不同的步骤或者相似的步骤的组合。而且,尽管术语“步骤”和/或“块”在本文中可以用来隐含采用的方法的不同元素,但是这些术语不应当被解释为暗示本文公开的各个步骤之中或之间的任何特定顺序,除非明确描述了各步骤的顺序。
权利要求书(按照条约第19条的修改)
1.一种方法,包括:将表示图像传感器的视场的图像的第一数据应用于神经网络,至少部分地基于使用激光雷达传感器或雷达传感器中的至少一个所生成的地面实况信息来训练所述神经网络;使用所述神经网络并至少部分地基于所述第一数据计算指示与所述图像的像素对应的深度值的第二数据;至少部分地基于所述第一数据,计算对应于所述图像中所描绘的对象的一个或更多个包围形状;确定与所述一个或更多个包围形状相关联的所述像素的子集;以及将至少部分地基于与所述像素的所述子集对应的所述深度值确定的深度值与所述对象相关联。
2.根据权利要求1所述的方法,其中,计算所述一个或更多个包围形状包括:接收表示与所述一个或更多个包围形状相对应的像素位置的第三数据;以及至少部分地基于所述像素位置确定所述图像中的所述一个或更多个包围形状的位置。
3.根据权利要求1所述的方法,至少部分地基于与所述对象相关联的所述深度值来由自主车辆执行一个或更多个操作。
4.根据权利要求1所述的方法,其中,计算所述一个或更多个包围形状包括计算像素位置,所述像素位置对应于所述一个或更多个包围形状中的每一个的中心像素和从所述中心像素到所述一个或更多个包围形状中的每一个的至少一个边缘的像素距离。
5.根据权利要求4所述的方法,其中,计算所述像素位置包括计算对应于所述图像的多个像素的置信度,所述置信度对应于所述多个像素中的每一个像素对应于所述一个或更多个包围形状的中心像素的可能性,其中所述一个或更多个包围形状中的每个包围形状的所述中心像素至少部分地基于所述置信度来确定。
6.根据权利要求1所述的方法,其中:计算与所述对象相关联的两个或更多个包围形状;带有噪声的应用程序的基于密度的空间群集(DBSCAN)算法被用于确定与所述对象对应的最终包围形状的最终像素位置。
7.根据权利要求1所述的方法,其中:所述图像传感器对应于部署的相机;根据参考相机的参考相机参数进一步训练所述神经网络;缩放因子被应用于所述深度值以基于所述部署的相机的与所述参考相机参数不同的部署相机参数来生成最终深度值;以及所述深度值中的所述深度值包括所述最终深度值中的最终深度值。
8.根据权利要求7所述的方法,其中,所述参考相机参数包括所述参考相机的第一视场(FOV)的第一角度,并且所述部署的相机参数包括所述部署的相机的第二FOV的第二角度。
9.根据权利要求1所述的方法,还包括:生成表示与对应于所述图像传感器的部署的相机的视场对应的失真图的第三数据;以及将所述第三数据应用于所述神经网络,其中至少部分地基于所述第三数据计算所述第二数据。
10.根据权利要求1所述的方法,还包括:至少部分地基于对象的包围形状或驾驶表面的形状中的至少一个,确定所述对象的最大深度值或最小深度值中的至少一个;以及以下中的一个:当所述深度值超过所述最大深度值时,将所述深度值限制到所述最大深度值;或者当所述深度值小于所述最大深度值时,将所述深度值限制到所述最小深度值。
11.一种方法,包括:接收表示激光雷达信息的第一数据、表示雷达信息的第二数据、以及表示图像的第三数据;接收表示与所述图像中描绘的对象相对应的包围形状的第四数据;将至少部分地基于激光雷达信息或雷达信息中的至少一个所确定的深度信息与包围形状相关;生成表示地面实况信息的第五数据;至少部分地基于将所述深度信息转换为深度图而生成所述第五数据,所述深度图表示与所述包围形状内的所述图像的像素相关联的深度值;以及训练神经网络以使用所述第五数据计算预测的深度图。
12.根据权利要求11所述的方法,其中,将所述深度信息与所述包围形状相关包括:将所述边界信息和所述激光雷达信息或所述雷达信息中的至少一个投影到所述图像中;以及确定所述包围形状与所述激光雷达信息或所述雷达信息中的至少一个之间的重叠。
13.根据权利要求11所述的方法,其中,将所述深度信息与所述包围形状相关包括:通过裁剪初始包围形状来生成最终包围形状,所述裁剪包括从所述初始包围形状的顶部去除第一百分比以及从所述初始包围形状的底部去除与所述第一百分比不同的第二百分比。
14.根据权利要求13所述的方法,其中,所述第一百分比大于所述第二百分比。
15.根据权利要求13所述的方法,其中,所述第一百分比至少部分地基于与所述初始包围形状对应的所述深度信息来确定,使得所述第一百分比随深度增加而增加。
16.根据权利要求11所述的方法,其中,将所述深度信息转换为所述深度图包括:确定所述包围形状内的代表性像素;从以所述代表性像素为中心的所述包围形状内的形状中选择所述包围形状的像素的子集;将对应于所述代表性像素的所述深度值中的深度值编码到所述像素的子集中的每一个子集。
17.根据权利要求16所述的方法,其中,所述形状是椭圆形或圆形之一,并且所述代表性像素是所述包围形状的中心像素。
18.根据权利要求11所述的方法,还包括:至少部分地基于捕获所述图像的相机的视场的角度,确定表示失真图的第六数据,其中所述神经网络进一步使用所述第六数据来训练。
19.根据权利要求11所述的方法,其中,所述第五数据还表示至少部分地基于捕获所述图像的相机的视场来确定的缩放因子。
20.一种系统,包括:一个或更多个图像传感器,用于生成表示车辆周围环境的图像的第一数据;包括一个或更多个处理设备的计算设备和通信地耦合到其上存储有程序指令的所述一个或更多个处理设备的一个或更多个存储器设备,其中当由所述处理器执行所述程序指令时导致以下实例化:深度确定器,用以使用神经网络并且至少部分地基于所述第一数据计算深度值,使用激光雷达数据或雷达数据中的至少一个作为地面实况来训练所述神经网络;对象指派器,用以计算表示与所述一个或更多个对象对应的一个或更多个包围形状的第二数据;确定与所述一个或更多个包围形状相关联的多个像素;确定与所述多个像素相对应的一个或更多个所述深度值;以及将使用所述一个或更多个所述深度值确定的深度值指派给所述图像中描绘的一个或更多个对象;以及控制组件,用以至少部分地基于所述深度值和所述第二数据,执行与所述车辆的控制相关联的一个或更多个操作。
21.根据权利要求20所述的系统,其中,所述第二数据由与所述神经网络分开的对象检测器生成,或者由所述神经网络以至少部分地基于所述第一数据来计算。
22.根据权利要求20所述的系统,其中,所述车辆是自主车辆或半自主车辆中之一,并且所述一个或更多个操作包括至少部分地基于所述深度值更新世界模型以包括从所述车辆到所述一个或更多个对象的距离。