基于要素检测的人脸识别方法、设备、系统及存储介质
文献发布时间:2023-06-19 19:40:14
技术领域
本发明涉及深度学习领域,更具体地,涉及基于要素检测的人脸识别方法、设备、系统及存储介质。
背景技术
在基于深度学习的人脸识别技术领域,在常用的人脸遮挡识别技术中,人脸遮挡识别通常基于MobileNetV2卷积神经网络等模型作为主干网络进行特征提取,该技术方案为分类模型,将模型做三个类别的二分类输出;但问题在于,模型智能对图片单人脸信息图片的分类,并且只识别眼睛、鼻子、嘴巴是否被遮挡,对于遮挡物的类型没有识别,其效率低且用户体验差。
在专利《人脸遮挡检测方法、模型训练方法、装置及电子设备》中,提供一种人脸遮挡检测方法、模型训练方法、装置及电子设备,人脸遮挡检测方法包括:获取待检测图像;将待检测图像输入目标分割模型进行处理,得到目标掩膜图像;通过两级遮挡检测,在第一级整体人脸遮挡检测的结果表示有遮挡的情况下,进一步进行局部遮挡检测,得到M个局部区域的遮挡检测结果,实现人脸遮挡的检测。该专利采用图像分割的方式获取遮挡物识别目标,且采用二阶段的模型结构,在运行速度上达不到实时,在分割效果上对于多目标分割效果不好;在专利《用于人脸遮挡检测的多标签深度卷积神经网络方法、装置和电子设备》中,对所述人脸图像进行检测得到人脸信息,包括人脸框和人脸关键点,将所述的人脸关键点与预设的人脸关键点进行仿射变换对齐,取裁剪后的人脸图像,将裁剪后的人脸图像输入预训练的人脸遮挡检测模型进行识别,得到待测人脸图像的遮挡信息;该专利预训练的人脸遮挡检测模型只接受裁剪人脸图片信息,无法对图片中多人脸进行同时识别,存在同一张多人脸照片需要多次调用关键点检测模型进行人脸图片裁剪和多次人脸遮挡识别的情况,运行效率低用户体验差。
发明内容
本发明旨在克服上述现有技术的至少一种缺陷,提供基于要素检测的人脸识别方法、设备、系统及存储介质,用于解决背景技术中因人脸占比过大导致人脸识别无法顺利进行,人脸识别效率低的问题。
本发明采用的技术方案包括:
一种基于要素检测的人脸识别方法,包括:
获取图像数据;
将所述图像数据输入人脸识别模型识别出若干人脸要素信息;
所述人脸识别模型包括编解码深度学习神经网络和预测特征神经网络;
通过iou模块过滤相同的人脸要素信息;
通过候选框分类模块将目标要素分类,将每一个人脸信息要素与其相关的目标要素聚合为一个要素集合并为要素集合赋予唯一的编码;
通过iou模块对每一个要素集合进行过滤;
将每一个要素集合多线程输入到逻辑判断模块进行遮挡判断,得到编码与遮挡判断结果的映射;
输出人脸识别结果;
所述iou模块用于判断同一标签的人脸要素信息的重叠度,若重叠度过高则作为冗余过滤;
所述遮挡判断为判断所述要素集合缺少的目标要素,若缺少,则将缺少的目标要素记为该要素集合的遮挡判断结果。
本发明的方案可以采用真实原色、未处理过的图像或视频作为系统的输入,可以提供图片输入接口和视频输入接口,此参数为必要参数。与此同时,还可以提供了对应输入图片或者视频帧的人脸框信息以字典类型传入系统的接口,此参数为可选变量,默认为空值。
iou模块类似于IOU交并比计算,用于计算不同类别候选框之间的重叠率,IoU即Intersection over Union,即把预测框与真实框的相交的面积除以相并的面积。
卷积模块即卷积神经网络,是目前计算机视觉中使用最普遍的模型结构,在卷积神经网络中,计算范围是在像素点的空间邻域内进行的,卷积核参数的数目也远小于全连接层。卷积核本身与输入图片大小无关,它代表了对空间邻域内某种特征模式的提取。比如,有些卷积核提取物体边缘特征,有些卷积核提取物体拐角处的特征,图像上不同区域共享同一个卷积核。当输入图片大小不一样时,仍然可以使用同一个卷积核进行操作。卷积是数学分析中的一种积分变化的方法,在图像处理中采用的是卷积的离散形式。这里需要说明的是,在卷积神经网络中,卷积层的实现方式实际上是数学中定义的互相关(cross-correlation)运算,与数学分析中的卷积定义有所不同,这里跟其他框架和卷积神经网络的教程保持一致,都使用互相关运算作为卷积的定义。单个卷积模块即卷积核(kernel)也被叫做滤波器(filter)。
进一步,所述解码深度学习神经网络包括依次正向传播的主干网络、上采样网络和收缩路径网络。
进一步,所述主干网络包括若干个依次减小的卷积模块。
进一步,所述上采样网络包括若干个依次增大的卷积模块,上采样网络的卷积模块对主干网络提取到的特征进行concat特征融合。
进一步,所述收缩路径网络包括若干依次减小的卷积模块,收缩路径网络的卷积模块对主干网络和上采样网络融合的若干特征进行concat特征融合。
进一步,所述预测特征神经网络包括若干大小不同的卷积模块,预测特征神经网络的卷积模块用于对所述编解码深度学习神经网络输出的特征进行对应的卷积输出,获得若干组预测特征。
在卷积神经网络当中,大的、浅层的特征图更多关注的是图像中物体的形状、颜色等细节特征信息,小的、深层的特征图关注更多的是图片区域的语义特征信息,大人脸的特征信息较多的保存在浅层的特征图中,将浅层特征和深层特征进行特征融合,可以将更多的大人脸信息得以保留,所以提升了对大人脸的识别敏感度。
本发明的人脸识别模型通过high-level特征与low-level特征的融合,完成了对大人脸识别准确率的提升,有效的解决了视频过程中客户离摄像头太近,人脸过大导致的人脸信息无法识别的问题。
进一步,所述iou模块设定人脸信息要素的分类中心和重叠度的阈值;
根据所述分类中心和其他人脸信息要素的距离判断重叠度。
将iou模块的计算作为距离计算各人脸信息要素标签与分类中心的iou值进行分类,最后得到图片中每个人脸信息要素以及与其相关的目标物体的信息的集合,方便后续开启多线程送入逻辑判断模块进行并行输出。
基于同样的发明构思,本发明还提供一种基于要素检测的人脸识别系统,包括:
图像获取模块,用于获取图像数据;
人脸识别模型,用于将所述图像数据输入人脸识别模型识别出若干人脸要素信息;
所述人脸识别模型包括编解码深度学习神经网络和预测特征神经网络;
iou模块,用于过滤相同的人脸要素信息以及对每一个要素集合进行过滤;
候选框分类模块,用于将目标要素分类,将每一个人脸信息要素与其相关的目标要素聚合为一个要素集合并为要素集合赋予唯一的编码;
逻辑判断模块,用于将每一个要素集合多线程输入到逻辑判断模块进行遮挡判断,得到编码与遮挡判断结果的映射;
输出模块,用于输出人脸识别结果;
所述iou模块用于判断同一标签的人脸要素信息的重叠度,若重叠度过高则作为冗余过滤;
所述遮挡判断为判断所述要素集合缺少的目标要素,若缺少,则将缺少的目标要素记为该要素集合的遮挡判断结果。
基于同样的发明构思,本发明还提供一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现所述的基于要素检测的人脸识别方法。
基于同样的发明构思,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现所述的基于要素检测的人脸识别方法。
与现有技术相比,本发明的有益效果为:
1.本发明支持单图片中包含多人脸情况的人脸遮挡同时识别,不但支持检测眼睛、鼻子、嘴巴是否被遮挡,并且支持遮挡物的类别输出,更直观的体现出图像的遮挡情况,解决了视频审核中实时的要求,且更好的用户体验。
2.本发明的模型运行速度快,同时模型支持多人脸同时识别模块,可以达到实时效果,模型识别准确率高,鲁棒性更强,用户体验更好;
3.本发明支持单图片中包含多人脸情况的人脸遮挡同时识别,同一张多人脸照片只需调用一次模型就可以输出全部人脸的识别结果,提升效率的同时有更好的用户体验。
附图说明
图1为本发明实施例1的方法流程示意图。
图2为本发明实施例3的方法步骤示意图。
图3为本发明实施例3的FaceOcclusionNet神经网络结构图。
图4为本发明的应用装置及系统数据交互示意图。
具体实施方式
本发明附图仅用于示例性说明,不能理解为对本发明的限制。为了更好说明以下实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
实施例1
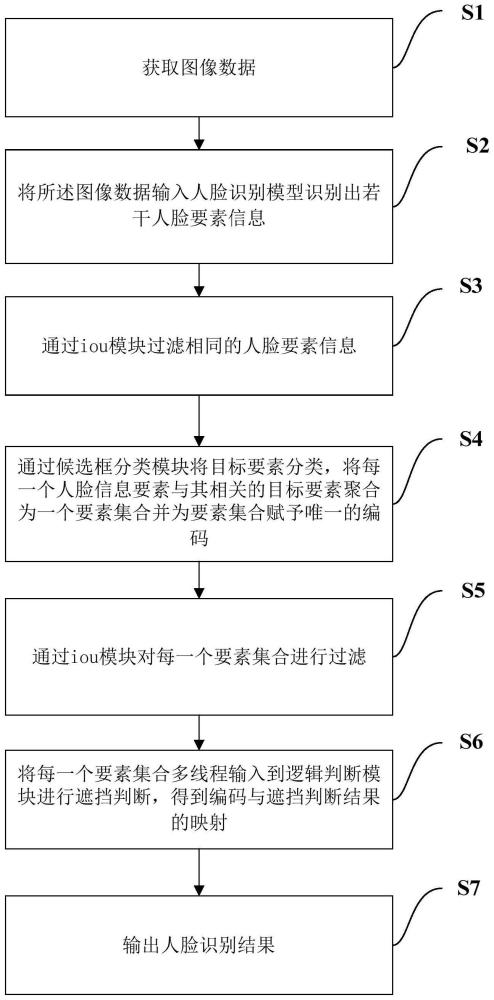
如图1所示,本实施例提供一种基于要素检测的人脸识别方法,包括:
S1、获取图像数据;
S2、将所述图像数据输入人脸识别模型识别出若干人脸要素信息;
所述人脸识别模型包括编解码深度学习神经网络和预测特征神经网络;
S3、通过iou模块过滤相同的人脸要素信息;
S4、通过候选框分类模块将目标要素分类,将每一个人脸信息要素与其相关的目标要素聚合为一个要素集合并为要素集合赋予唯一的编码;
S5、通过iou模块对每一个要素集合进行过滤;
S6、将每一个要素集合多线程输入到逻辑判断模块进行遮挡判断,得到编码与遮挡判断结果的映射;
S7、输出人脸识别结果;
所述iou模块用于判断同一标签的人脸要素信息的重叠度,若重叠度过高则作为冗余过滤;
所述遮挡判断为判断所述要素集合缺少的目标要素,若缺少,则将缺少的目标要素记为该要素集合的遮挡判断结果。
本实施例的方案可以采用真实原色、未处理过的图像或视频作为系统的输入,可以提供图片输入接口和视频输入接口,此参数为必要参数。与此同时,还可以提供了对应输入图片或者视频帧的人脸框信息以字典类型传入系统的接口,此参数为可选变量,默认为空值。
iou模块类似于IOU交并比计算,用于计算不同类别候选框之间的重叠率,IoU即Intersection over Union,即把预测框与真实框的相交的面积除以相并的面积。
卷积模块即卷积神经网络,是目前计算机视觉中使用最普遍的模型结构,在卷积神经网络中,计算范围是在像素点的空间邻域内进行的,卷积核参数的数目也远小于全连接层。卷积核本身与输入图片大小无关,它代表了对空间邻域内某种特征模式的提取。比如,有些卷积核提取物体边缘特征,有些卷积核提取物体拐角处的特征,图像上不同区域共享同一个卷积核。当输入图片大小不一样时,仍然可以使用同一个卷积核进行操作。卷积是数学分析中的一种积分变化的方法,在图像处理中采用的是卷积的离散形式。这里需要说明的是,在卷积神经网络中,卷积层的实现方式实际上是数学中定义的互相关(cross-correlation)运算,与数学分析中的卷积定义有所不同,这里跟其他框架和卷积神经网络的教程保持一致,都使用互相关运算作为卷积的定义。单个卷积模块即卷积核(kernel)也被叫做滤波器(filter)。
优选地,所述解码深度学习神经网络包括依次正向传播的主干网络、上采样网络和收缩路径网络。
优选地,所述主干网络包括若干个依次减小的卷积模块。
优选地,所述上采样网络包括若干个依次增大的卷积模块,上采样网络的卷积模块对主干网络提取到的特征进行concat特征融合。
优选地,所述收缩路径网络包括若干依次减小的卷积模块,收缩路径网络的卷积模块对主干网络和上采样网络融合的若干特征进行concat特征融合。
优选地,所述预测特征神经网络包括若干大小不同的卷积模块,预测特征神经网络的卷积模块用于对所述编解码深度学习神经网络输出的特征进行对应的卷积输出,获得若干组预测特征。
在卷积神经网络当中,大的、浅层的特征图更多关注的是图像中物体的形状、颜色等细节特征信息,小的、深层的特征图关注更多的是图片区域的语义特征信息,大人脸的特征信息较多的保存在浅层的特征图中,将浅层特征和深层特征进行特征融合,可以将更多的大人脸信息得以保留,所以提升了对大人脸的识别敏感度。
本发明的人脸识别模型通过high-level特征与low-level特征的融合,完成了对大人脸识别准确率的提升,有效的解决了视频过程中客户离摄像头太近,人脸过大导致的人脸信息无法识别的问题。
优选地,所述iou模块设定人脸信息要素的分类中心和重叠度的阈值;
根据所述分类中心和其他人脸信息要素的距离判断重叠度。
将iou模块的计算作为距离计算各人脸信息要素标签与分类中心的iou值进行分类,最后得到图片中每个人脸信息要素以及与其相关的目标物体的信息的集合,方便后续开启多线程送入逻辑判断模块进行并行输出。
实施例2
基于同样的发明构思,本实施例还提供一种基于要素检测的人脸识别系统,包括:
图像获取模块,用于获取图像数据;
人脸识别模型,用于将所述图像数据输入人脸识别模型识别出若干人脸要素信息;
所述人脸识别模型包括编解码深度学习神经网络和预测特征神经网络;
iou模块,用于过滤相同的人脸要素信息以及对每一个要素集合进行过滤;
候选框分类模块,用于将目标要素分类,将每一个人脸信息要素与其相关的目标要素聚合为一个要素集合并为要素集合赋予唯一的编码;
逻辑判断模块,用于将每一个要素集合多线程输入到逻辑判断模块进行遮挡判断,得到编码与遮挡判断结果的映射;
输出模块,用于输出人脸识别结果;
所述iou模块用于判断同一标签的人脸要素信息的重叠度,若重叠度过高则作为冗余过滤;
所述遮挡判断为判断所述要素集合缺少的目标要素,若缺少,则将缺少的目标要素记为该要素集合的遮挡判断结果。
实施例3
如图2所示,本实施例提供一种基于要素检测的人脸识别方法,步骤包括:
第一步:当系统接收到图片或视频帧信息,而未获得对应的人脸框信息,系统会将输入的图片信息传递给FaceOcclusionNet神经网络做对应要素检测识别,要素包括眼睛、鼻子、嘴巴、眼镜、墨镜、口罩、帽子等;
第二步:通过l-iou模块过滤掉相同人脸要素信息,使人脸要素信息集合唯一,如果人脸要素信息集合为空,则系统返回没有检测到人脸要素信息的提示,并结束程序;
第三步:将检测到的人脸要素信息作为不同类别,通过Face-KNN模块对目标检测模型检测到的所有目标要素进行分类,使每一个人脸要素与其相关的目标要素聚为一个要素集合,同时对每一个要素集合赋唯一ID编码,然后针对每一个类别集合通过l-iou模块对集合中的重复要素进行过滤,得到准确、唯一的要素;
所述Face-KNN模块是多人脸并行检测的基础与前提,此模块主要是将FaceOcclusionNet模型的识别标签通过设定head(人头/人脸)标签做为分类中心,将l-iou计算作为距离计算各标签与head标签的l-iou值进行分类,最后得到图片中每个人脸信息以及与其相关的目标物体的信息的集合,方便后续开启多线程送入Logical模块进行并行输出。
第四步:将每一个人脸要素信息下的目标要素集合多线程送入到Logical模块进行逻辑判断,包括是否遮挡判断、遮挡要素显示、被遮挡人脸要素显示等,系统会将不同人脸要素识别信息通过ID编码与输出结果映射,判断结果以字典的形式返回。
本实施例采用了真实原色、未处理过的图像或视频作为系统的输入,系统提供图片输入接口和视频输入接口,此参数为必要参数;与此同时,系统还提供了对应输入图片或者视频帧的人脸框信息以字典类型传入系统的接口,此参数为可选变量,默认为空值。
在具体应用过程中,方法和步骤包括:
收集训练数据,数据包括网络下载数据和生产环境中视频的截图帧;
用标注后的数据13000张,训练数据、验证数据、测试数据的比例为7:2:1进行模型训练;
FaceOcclusionNet模型用c++编写模型前向,FaceOcclusionNet模型用于图片识别和视频识别两个方向,采用tensorrt加速的算法库进行前向推理,以达到实时的视频检测;
系统对接入的图片和视频进行检测,对于图片,若检测到要素遮挡打标签1,无要素遮挡打标签2;对于视频,若检测不到要素遮挡不做任何提示,对于要素遮挡给予文字提示。
如图3所示,1-12组成基于FPN结构的编解码深度学习神经网络,1-4为模型的主干网络,5-8为模型的上采样阶段,并对主干网络提取到的特征进行concat融合,9-12为模型的收缩路径;13-15组成预测特征神经网络模型。
第一步,模型接收输入图片或视频帧大小为640*640*3;
第一步,经过1号卷积模块,特征输出大小为320*320*32;
第三步,经过2号卷积模块,特征输出大小为80*80*128;
第四步,经过3号卷积模块,特征输出大小为40*40*256;
第五步,经过4号卷积模块,特征输出大小为20*20*256;
第六步,经过5号卷积模块,特征输出大小为20*20*512;
第七步,将经过5号上采样模块与3号输出特征进行concat融合,特征输出大小为40*40*512,后续操作步骤与上述步骤类似;
第八步,最后经过12号卷积模块,特征输出大小为20*20*512,再将1号模块输出结果通过池化操作与之进行concat融合,特征输出大小为20*20*1024。
在卷积神经网络当中,大的、浅层的特征图更多关注的是图像中物体的形状、颜色等细节特征信息,小的、深层的特征图关注更多的是图片区域的语义特征信息,大人脸的特征信息较多的保存在浅层的特征图中,将浅层特征和深层特征进行特征融合,可以将更多的大人脸特征信息得以保留,所以提升了对大人脸的识别敏感度。
GPU图像处理器为一种专门在个人电脑、工作站和一些移动设备上做图像和图像相关工作的微处理器;
Face-KNN为候选框分类模块,将人脸框作为类别中心,将与中心框l-iou值大于定义阈值的候选框进行分类;
Logical模块为智能判断筛选逻辑模块,通过对去重后的目标框的逻辑判断,转化为符合图片遮挡状态的描述结果;
Openvino为一种模型加速框架,是英特尔基于自身现有的硬件平台开发的一种可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,支持各种英特尔平台的硬件加速器上进行深度学习,并允许直接异构执行;
TensorRT为一个高性能的深度学习推理优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。目前已支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
多人同框情况下,本实施例的神经网络模型单帧运行速度在8ms以内,可以达到实时人脸检测要求。另外,通过high-level特征与low-level特征的融合,完成了对大人脸识别准确率的提升,有效的解决了视频过程中客户离摄像头太近,人脸过大导致的人脸信息无法识别的问题;
显然,本发明的上述实施例仅仅是为清楚地说明本发明技术方案所作的举例,而并非是对本发明的具体实施方式的限定。凡在本发明权利要求书的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。