数据查询方法、装置及设备
文献发布时间:2023-06-19 09:30:39
技术领域
本申请涉及通信技术领域,尤其是涉及一种数据查询方法、装置及设备。
背景技术
日志数据是记录IT系统产生的过程性事件的记录数据,IT系统在保障业务运行的过程中,会持续产生大量的日志数据,通过查看日志数据,可以获知哪个用户、在什么时间、在哪台设备或什么应用系统、做了什么具体操作。
日志数据的来源有服务器、存储设备、网络设备、操作系统、中间件、数据库、业务系统等。日志数据可以分为状态日志和应用系统日志两大类,状态日志包括CPU(CentralProcessing Unit,中央处理器)使用状态、内存使用状态、温度信息、磁盘容量、流量信息、行为分析信息等。应用系统日志包括操作系统的日志数据,数据库的日志数据,中间件的日志数据等。若按照日志格式分类,日志数据可以分为文本类日志数据,系统类日志数据,SNMP(Simple Network Management Protocol,简单网络管理协议)类日志数据,数据库类日志数据。
越来越多的安全分析场景中,需要对日志数据进行查询和数据分析,但是,日志数据的数据量呈现几何级数的增长,每天都可能产生TB甚至PB级别的日志数据,如何对海量日志数据进行查询,目前并没有有效的实现方案。
发明内容
本申请提供一种数据查询方法,所述方法包括:
在接收到查询请求后,从所述查询请求中解析出关键字;
基于所述查询请求确定与所述关键字匹配的查询条件类型;其中,所述查询条件类型为倒排查询类型或者正排查询类型;
若所述查询条件类型为倒排查询类型,则通过所述关键字查询融合索引表中的倒排索引表,得到与所述关键字匹配的第一数据结构;
若所述查询条件类型为正排查询类型,则通过所述关键字查询所述融合索引表中的正排索引表,得到与所述关键字匹配的第二数据结构。
在一种可能的实施方式中,若所述关键字包括第一关键字和第二关键字,与所述第一关键字匹配的查询条件类型为倒排查询类型,与所述第二关键字匹配的查询条件类型为正排查询类型,所述方法还包括:
通过所述第一关键字查询所述融合索引表中的倒排索引表,得到与所述第一关键字匹配的第一数据结构,并通过所述第二关键字查询所述融合索引表中的正排索引表,得到与所述第二关键字匹配的第二数据结构。
示例性的,所述基于所述查询请求确定与所述关键字匹配的查询条件类型,包括:若所述查询请求用于实现全文查询,或实时数据查询,或分组聚合查询,或分词汇总查询,则确定所述查询条件类型为倒排查询类型;或,
若所述查询请求用于实现多字段查询,或长时间查询,或大流量查询,或复杂表连接查询,或分页查询,则确定所述查询条件类型为正排查询类型。
示例性的,所述融合索引表还包括全局标识,所述通过所述关键字查询融合索引表中的倒排索引表,得到与所述关键字匹配的第一数据结构之后,还包括:通过所述全局标识查询全量索引表,得到与所述关键字匹配的全量索引;
所述融合索引表还包括全局标识,所述通过所述关键字查询所述融合索引表中的正排索引表,得到与所述关键字匹配的第二数据结构之后,还包括:通过所述全局标识查询全量索引表,得到与所述关键字匹配的全量索引。
示例性的,所述方法还包括:获取日志数据;
基于所述日志数据确定倒排查询分词和所述倒排查询分词对应的第一数据结构,在倒排索引表中记录所述倒排查询分词和所述第一数据结构的映射关系;
基于所述日志数据确定正排查询分词和所述正排查询分词对应的第二数据结构,在正排索引表中记录所述正排查询分词和所述第二数据结构的映射关系;
对所述倒排索引表和所述正排索引表进行融合,得到融合索引表。
示例性的,所述获取日志数据之后,所述方法还包括:为所述日志数据分配全局标识,所述全局标识具有唯一性,所述融合索引表包括所述全局标识;
基于所述日志数据确定全量索引,所述全量索引包括倒排查询分词和正排查询分词,并在全量索引表中记录所述全局标识与所述全量索引的映射关系。
示例性的,所述基于所述日志数据确定倒排查询分词和所述倒排查询分词对应的第一数据结构,包括:
确定倒排查询分词的分词类型以及第一数据结构的数据类型;
基于所述日志数据确定与所述分词类型对应的倒排查询分词;
基于所述日志数据确定与所述数据类型对应的第一数据结构。
本申请提供一种数据查询装置,所述装置包括:
解析模块,用于在接收到查询请求后,从所述查询请求中解析出关键字;
确定模块,用于基于所述查询请求确定与所述关键字匹配的查询条件类型;其中,所述查询条件类型为倒排查询类型或者正排查询类型;
查询模块,用于若所述查询条件类型为倒排查询类型,则通过所述关键字查询融合索引表中的倒排索引表,得到与所述关键字匹配的第一数据结构;若所述查询条件类型为正排查询类型,则通过所述关键字查询所述融合索引表中的正排索引表,得到与所述关键字匹配的第二数据结构。
本申请提供一种数据查询设备,包括:处理器和机器可读存储介质,所述机器可读存储介质存储有能够被所述处理器执行的机器可执行指令;
所述处理器用于执行机器可执行指令,以实现如下步骤:
在接收到查询请求后,从所述查询请求中解析出关键字;
基于所述查询请求确定与所述关键字匹配的查询条件类型;其中,所述查询条件类型为倒排查询类型或者正排查询类型;
若所述查询条件类型为倒排查询类型,则通过所述关键字查询融合索引表中的倒排索引表,得到与所述关键字匹配的第一数据结构;
若所述查询条件类型为正排查询类型,则通过所述关键字查询所述融合索引表中的正排索引表,得到与所述关键字匹配的第二数据结构。
本申请提供一种机器可读存储介质,所述机器可读存储介质上存储有若干计算机指令,所述计算机指令被处理器执行时,实现上述数据查询方法。
基于上述技术方案,本申请实施例中,在安全分析场景中,可以建立融合索引表,且该融合索引表包括倒排索引表和正排索引表,在接收到查询请求后,若查询条件类型为倒排查询类型,则可以查询融合索引表中的倒排索引表,得到第一数据结构,若查询条件类型为正排查询类型,则可以查询融合索引表中的正排索引表,得到第二数据结构,上述方式可以根据业务场景灵活定制融合索引表,实现海量日志数据的查询,并快速返回查询响应,通过将倒排索引表和正排索引表进行融合,实现不同查询条件类型的数据查询,提高查询速度。
附图说明
为了更加清楚地说明本申请实施例或者现有技术中的技术方案,下面将对本申请实施例或者现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据本申请实施例的这些附图获得其它的附图。
图1是本申请一种实施方式中的建立融合索引表的示意图;
图2A是本申请一种实施方式中的分词类型和数据类型的示意图;
图2B是本申请一种实施方式中的融合索引表的示意图;
图2C是本申请一种实施方式中的clickhouse数据库的示意图;
图2D是本申请一种实施方式中的日志数据的处理示意图;
图3是本申请一种实施方式中的数据查询方法的流程图;
图4是本申请一种实施方式中的查询过程示意图;
图5是本申请一种实施方式中的数据查询装置的结构图;
图6是本申请一种实施方式中的数据查询设备的结构图。
具体实施方式
在本申请实施例使用的术语仅仅是出于描述特定实施例的目的,而非限制本申请。本申请和权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其它含义。还应当理解,本文中使用的术语“和/或”是指包含一个或多个相关联的列出项目的任何或所有可能组合。
应当理解,尽管在本申请实施例可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本申请范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,此外,所使用的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”。
越来越多的安全分析场景中,需要对日志数据进行查询和数据分析,但是,日志数据的数据量呈现几何级数的增长,每天都可能产生TB甚至PB级别的日志数据,如何对海量日志数据进行查询,目前并没有有效的实现方案。
针对上述问题,本实施例中,可以建立融合索引表,且融合索引表包括倒排索引表和正排索引表,通过将倒排索引表和正排索引表进行融合,得到融合索引表,实现不同查询条件类型的数据查询,提高查询速度。可以根据业务场景灵活定制融合索引表,实现海量日志数据的查询,并快速返回查询响应。
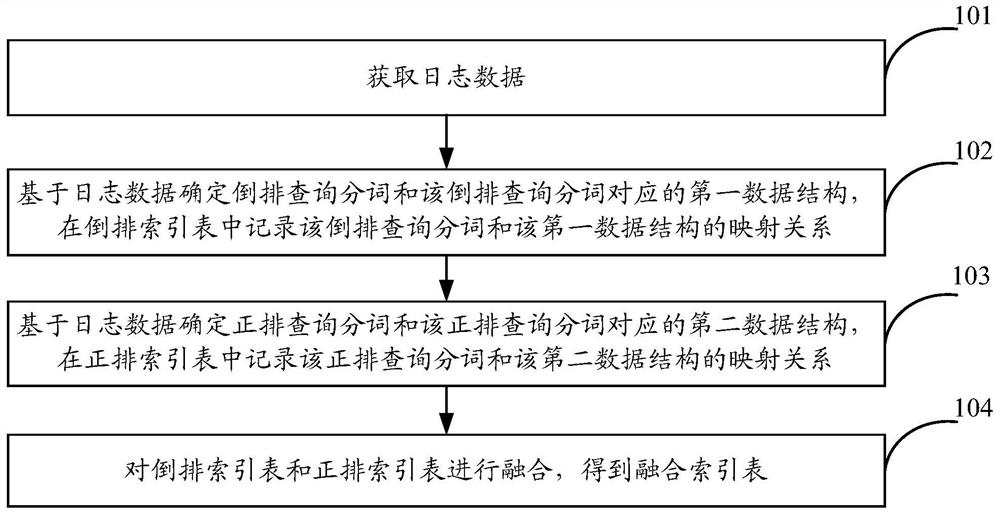
本申请实施例中,可以先建立融合索引表,基于已建立的融合索引表实现数据查询,参见图1所示,为建立融合索引表的示意图,该方法可以包括:
步骤101,获取日志数据。
示例性的,日志数据是记录IT系统产生的过程性事件的记录数据,通过查看日志数据,可以获知哪个用户、在什么时间、在哪台设备或什么应用系统、做了什么具体操作。日志数据的来源有服务器、存储设备、网络设备、操作系统、中间件、数据库、业务系统等。日志数据可以分为状态日志和应用系统日志两大类,状态日志包括CPU使用状态、内存使用状态、温度信息、磁盘容量、流量信息、行为分析信息等。应用系统日志包括操作系统的日志数据,数据库的日志数据,中间件的日志数据等。若按照日志格式分类,日志数据可以分为文本类日志数据,系统类日志数据,SNMP类日志数据,数据库类日志数据。
关于日志数据的获取方式,本实施例中不做限制,只要能够得到日志数据即可。参见如下示例,为日志数据的示例,对此日志数据的内容不做限制。
{
"_index":"log_20190104",
"_type":"log_flow",
"doc_id":"AWgUqnLERXj2HjI5G01I",
"app_name":"网页浏览(HTTP)",
"country_name":"中国",
"src_ip":"10.10.10.1",
"dest_ip":"20.20.20.1",
"app_type":"网络协议",
"attack_name":"主动攻击",
"attack_type":"僵木蠕",
"…":"…",
}
步骤102,基于日志数据确定倒排查询分词和该倒排查询分词对应的第一数据结构,在倒排索引表中记录该倒排查询分词和该第一数据结构的映射关系。
在一种可能的实施方式中,针对步骤102,为了基于日志数据确定倒排查询分词和该倒排查询分词对应的第一数据结构,可以采用如下方式:
步骤1021,确定倒排查询分词的分词类型和第一数据结构的数据类型。
示例性的,步骤101之前,可以先配置倒排查询分词的分词类型以及与该分词类型对应的第一数据结构的数据类型,对此配置方式不做限制。
比如说,由用户根据业务场景灵活配置倒排查询分词的分词类型(如需要进行实时检索和/或分析汇总的高频字段)以及与该分词类型对应的数据类型(对此数据类型不做限制,可以根据业务场景灵活配置),也可以由设备统计出需要进行实时检索和/或分析汇总的高频字段,将该高频字段确定为倒排查询分词的分词类型,并确定与该分词类型对应的数据类型,对此数据类型的确定方式不做限制,例如,可以将除了分词类型之外的重要字段确定为数据类型。
例如,分词类型可以为“攻击”,与该分词类型对应的数据类型可以为“攻击次数”和/或“攻击位置”等,“攻击次数”表示分词“攻击”在日志数据中出现的次数,“攻击位置”表示分词“攻击”在日志数据中出现的位置。当然,上述只是倒排查询分词的分词类型和数据类型的示例,对此不做限制。
参见图2A所示,为倒排查询分词的分词类型和数据类型的示例,可以先配置分词类型a以及与分词类型a对应的数据类型a1和数据类型a2,并配置分词类型b以及与分词类型b对应的数据类型b1和数据类型b2,对此不做限制。
基于上述配置内容,在步骤1021中,可以确定倒排查询分词的分词类型和第一数据结构的数据类型。例如,将分词类型a(如攻击)确定为倒排查询分词的分词类型,并将数据类型a1(如攻击次数)和数据类型a2(如攻击位置)确定为第一数据结构的数据类型。或者,将分词类型b确定为倒排查询分词的分词类型,并将数据类型b1和数据类型b2确定为第一数据结构的数据类型。
步骤1022,基于日志数据确定与该分词类型对应的倒排查询分词。
示例性的,针对每个日志数据来说,在获取到该日志数据后,可以从该日志数据中解析出与该分词类型对应的倒排查询分词,比如说,若该分词类型为“攻击”,则从该日志数据中解析出与分词类型“攻击”匹配的所有分词,并将这些分词确定为与该分词类型“攻击”对应的倒排查询分词。
步骤1023,基于日志数据确定与该数据类型对应的第一数据结构。
示例性的,在获取到日志数据后,可以从该日志数据中解析出与该数据类型对应的第一数据结构,该第一数据结构是与该倒排查询分词对应的数据结构,为了区分方便,将与该倒排查询分词对应的数据结构记为第一数据结构。
比如说,若数据类型为“攻击次数”和“攻击位置”,则从日志数据中解析出倒排查询分词在日志数据中出现的次数,并从日志数据中解析出倒排查询分词在日志数据中出现的位置,因此,第一数据结构包括倒排查询分词在日志数据中出现的次数,以及,倒排查询分词在日志数据中出现的位置。
综上所述,基于步骤1021-步骤1023,可以基于日志数据确定出倒排查询分词和第一数据结构,然后,可以在预先维护的倒排索引表中记录该倒排查询分词和该第一数据结构的映射关系。参见表1所示,为倒排索引表的示例,该倒排索引表用于记录该倒排查询分词和第一数据结构的映射关系,对此不做限制。
表1
在表1中,分词11可以表示倒排查询分词,如与分词类型“攻击”匹配的分词,数据11可以表示第一数据结构,如与“攻击次数”匹配的数据(倒排查询分词在日志数据中出现的次数)和与“攻击位置”匹配的数据(倒排查询分词在日志数据中出现的位置,从这个位置可以找到倒排查询分词),以此类推。
在一种可能的实施方式中,可以根据业务场景灵活设计倒排索引表,也就是说,通过配置倒排查询分词的分词类型和与该分词类型对应的数据类型,就可以根据业务场景灵活设计倒排索引表,该倒排索引表可以包括与该分词类型对应的倒排查询分词,以及,与该数据类型对应的第一数据结构。
步骤103,基于日志数据确定正排查询分词和该正排查询分词对应的第二数据结构,在正排索引表中记录该正排查询分词和该第二数据结构的映射关系。
在一种可能的实施方式中,针对步骤103,为了基于日志数据确定正排查询分词和该正排查询分词对应的第二数据结构,可以采用如下方式:
步骤1031,确定正排查询分词的分词类型和第二数据结构的数据类型。
示例性的,步骤101之前,可以配置正排查询分词的分词类型以及与该分词类型对应的第二数据结构的数据类型,对此配置方式不做限制。比如说,由用户根据业务场景灵活配置正排查询分词的分词类型(如需要离线分析和/或海量数据分析的高频字段)以及与该分词类型对应的数据类型(对此数据类型不做限制,可以根据业务场景灵活配置),也可以由设备统计出需要离线分析和/或海量数据分析的高频字段,将该高频字段确定为正排查询分词的分词类型,并确定与该分词类型对应的数据类型,对此数据类型的确定方式不做限制。
基于上述配置内容,在步骤1031中,可以确定正排查询分词的分词类型和第二数据结构的数据类型,对此分词类型和数据类型均不做限制。
步骤1032,基于日志数据确定与该分词类型对应的正排查询分词。
示例性的,在获取到日志数据后,从日志数据中解析出与该分词类型对应的正排查询分词,比如说,若分词类型为m,则从日志数据中解析出与分词类型m匹配的所有分词,并将这些分词确定为与分词类型m对应的正排查询分词。
步骤1033,基于日志数据确定与该数据类型对应的第二数据结构。
示例性的,在获取到日志数据后,可以从该日志数据中解析出与该数据类型对应的第二数据结构,该第二数据结构是与该正排查询分词对应的数据结构,为了区分方便,将与该正排查询分词对应的数据结构记为第二数据结构。
综上所述,基于步骤1031-步骤1033,可以基于日志数据确定出正排查询分词和第二数据结构,然后,可以在预先维护的正排索引表中记录该正排查询分词和该第二数据结构的映射关系。参见表2所示,为正排索引表的示例,该正排索引表用于记录该正排查询分词和第二数据结构的映射关系,对此不做限制。
表2
在一种可能的实施方式中,可以根据业务场景灵活设计正排索引表,也就是说,通过配置正排查询分词的分词类型和与该分词类型对应的数据类型,就可以根据业务场景灵活设计正排索引表,该正排索引表可以包括与该分词类型对应的正排查询分词,以及,与该数据类型对应的第二数据结构。
步骤104,对倒排索引表和正排索引表进行融合,得到融合索引表。
示例性的,针对每个日志数据,在获取到该日志数据后,可以基于该日志数据建立倒排索引表和正排索引表,并对倒排索引表和正排索引表进行融合,将融合后的数据更新到融合索引表中,得到更新后的融合索引表。
示例性的,融合索引表可以包括倒排索引表和正排索引表,正排索引表是采用正排索引方式建立的表格,正排索引是以文档标识为key(关键字),正排索引表中记录每个关键词出现的次数,查找时扫描正排索引表中的每个文档中字的信息,直到找到所有包含查询关键字的文档。倒排索引表是采用倒排索引方式建立的表格,倒排索引是根据属性值来查找记录,倒排索引表中的每一项包括一个属性值和具有该属性值的各记录的地址,由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(invertedindex)。
示例性的,可以设计融合索引表的结构,通过融合索引表实现倒排索引和正排索引的一一对应关系,比如说,参见表3所示,为融合索引表的示例,融合索引表中同一行的内容,就是同一条日志数据对应的倒排索引表和正排索引表,显然,通过对倒排索引表和正排索引表进行融合,就可以得到融合索引表。
表3
当然,上述表1、表2和表3是以表格的方式表示倒排索引表、正排索引表和融合索引表,在实际应用中,还可以采用其它结构表示倒排索引表、正排索引表和融合索引表,对此不做限制,本文以采用表格的方式为例进行说明。
参见图2B所示,可以将倒排索引表的索引字段和正排索引表的索引字段融合在复合表中,将这个复合表记为融合索引表,即融合索引表可以包括倒排索引表和正排索引表,对此倒排索引表和正排索引表的融合方式不做限制。
在一种可能的实施方式中,针对每个日志数据,在获取到日志数据后,还可以为该日志数据分配全局标识,且全局标识具有唯一性,例如,全局标识可以为UUID(UniversallyUnique Identifier,通用唯一识别码),对此全局标识不做限制,只要全局标识具有唯一性即可,即不同日志数据对应的全局标识不同。
示例性的,在倒排索引表中记录倒排查询分词和第一数据结构的映射关系时,该映射关系还可以包括日志数据的全局标识,即表1还包括日志数据的全局标识。在正排索引表中记录正排查询分词和第二数据结构的映射关系时,该映射关系还可以包括日志数据的全局标识,即表2还包括日志数据的全局标识。在对倒排索引表和正排索引表进行融合时,该融合索引表还可以包括日志数据的全局标识,参见表4所示,为融合索引表的示例,对此不做限制。
表4
在一种可能的实施方式中,针对每个日志数据,在获取到日志数据后,还可以基于该日志数据确定全量索引(如全量日志字段),即基于该日志数据能够得到的所有日志字段,该全量索引可以包括上述倒排查询分词和上述正排查询分词,该全量索引还可以包括除该倒排查询分词和该正排查询分词之外的其它分词,对此全量索引的类型不做限制。然后,可以在全量索引表(也可以称为数据存储表)中记录该日志数据的全局标识与该全量索引的映射关系,即全量索引表以日志数据的全局标识为关键字,以全量索引为查询结果。
在一种可能的实施方式中,针对每个日志数据,在获取到日志数据后,还可以在数据库中记录该日志数据,对此过程不做限制,与数据库的类型有关。
比如说,以clickhouse数据库(其它类型数据库的实现方式类似)为例,全量索引是clickhouse数据库定义的索引,即在clickhouse数据库中建立全量索引,并通过clickhouse数据库记录日志数据(全量日志数据)。clickhouse数据库支持按照日期建立全量索引,日志数据按照每天进行分区和索引,更新全量索引和日志数据,在写入日志数据时支持日志数据的查询,参见图2C所示。
clickhouse数据库是一款用于搜索的开源数据库组件,同时也是针对数据仓库场景的多维数据存储与检索工具,通过针对性的设计力图解决海量多维度数据的查询性能问题。clickhouse数据库采用Merge tree(合并树)实现全量索引和日志数据的管理,Mergetree是一种面向列式存储的数据索引编排技术。
示例性的,在clickhouse数据库中,以日期为索引,由很多分区组成,每一天的日志数据存储在单独分区中,每一个partition(分区)都包含上限和下限,当插入日志数据时,会创建一个新的临时排序分区,同时在后台不断地重新合并小文件,将若干个小的partition合并成一个大的全局分区。在插入日志数据的过程中,分属于不同天的数据会被分隔成不同的分片,而这些不同分片不会重组到一起。对于每一个分区,都会生成一个索引文件,索引的叶子节点中存储了具体每一行数据的索引主键的value数值,因此,可以快速定位到日志数据。
综上所述,本实施例中,参见图2D所示,可以获取日志数据,对该日志数据进行适配,即确定该日志数据是否为指定类型(可以根据业务需求配置,表示需要采用融合索引表进行查询的日志数据,如流量类型、漏洞攻击类型等)。
若否,则表示不采用本实施例的技术方案进行处理,对此过程不做限制,比如说,只对日志数据建立正排索引表,而不建立倒排索引表和融合索引表。
若是,则表示需要采用本实施例的技术方案进行处理,比如说,需要对日志数据建立倒排索引表、正排索引表和融合索引表。参见图2D所示,先基于该日志数据建立倒排索引表,基于该日志数据建立正排索引表。然后,基于倒排索引表和正排索引表建立融合索引表,并将日志数据存储到数据库中。
基于上述倒排索引表、正排索引表和融合索引表,本申请实施例提出一种数据查询方法,参见图3所示,为该数据查询方法的示意图,该方法可以包括:
步骤301,在接收到查询请求后,从该查询请求中解析出关键字。
示例性的,在接收到客户端发送的查询请求后,该查询请求中可以携带关键字,即需要查询的关键字,表示客户端需要查询与该关键字对应的内容,因此,可以从该查询请求中解析出该关键字,对此过程不做限制。
步骤302,基于该查询请求确定与该关键字匹配的查询条件类型;其中,该查询条件类型可以为倒排查询类型或者正排查询类型。
示例性的,倒排查询类型表示需要查询倒排索引表的类型,查询倒排索引表时能够提高查询性能,即,与查询正排索引表相比,查询倒排索引表的性能更高。正排查询类型表示需要查询正排索引表的类型,查询正排索引表时能够提高查询性能,即,与查询倒排索引表相比,查询正排索引表的性能更高。
在一种可能的实施方式中,可以根据业务需求配置倒排查询类型,对此倒排查询类型不做限制,比如说,该倒排查询类型可以包括但不限于:全文查询,实时数据查询,分组聚合查询,分词汇总查询等。在此基础上,若该查询请求用于实现全文查询,或实时数据查询,或分组聚合查询,或分词汇总查询,则可以确定与该关键字匹配的查询条件类型为倒排查询类型。
比如说,可以预先配置全文查询为倒排查询类型,当用户需要进行全文查询时,查询请求中携带与全文查询有关的内容,对此查询请求的内容不做限制。在接收到查询请求后,可以基于该查询请求分析出该查询请求用于实现全文查询(全文查询是指查询日志数据全文中的属性值,如日志数据全文中出现属性值A的次数),因此,能够确定查询条件类型为倒排查询类型。
又例如,可以预先配置实时数据查询为倒排查询类型,当用户需要进行实时数据查询时,查询请求中携带与实时数据查询有关的内容,对此查询请求的内容不做限制。在接收到查询请求后,可以基于该查询请求分析出该查询请求用于实现实时数据查询(实时数据查询是指查询日志数据中的实时数据,而不是查询日志数据中的海量数据,如只查询某一分钟的日志数据,而不是查询某天的完整日志数据),因此,能够确定查询条件类型为倒排查询类型。
又例如,可以预先配置分组聚合查询为倒排查询类型,当用户需要进行分组聚合查询时,查询请求中携带与分组聚合查询有关的内容,对此查询请求的内容不做限制。在接收到查询请求后,可以基于该查询请求分析出该查询请求用于实现分组聚合查询(分组聚合查询是指对日志数据进行分组与聚合,分组是使用特定条件将日志数据划分为多个组,聚合是对每个组中的日志数据执行某些操作,将结果整合),因此,能够确定查询条件类型为倒排查询类型。
又例如,可以预先配置分词汇总查询为倒排查询类型,当用户需要进行分词汇总查询时,查询请求中携带与分词汇总查询有关的内容,对此查询请求的内容不做限制。在接收到查询请求后,可以基于该查询请求分析出该查询请求用于实现分词汇总查询(分词汇总查询是指对日志数据进行分词与汇总,分词是将日志数据划分为多个分词,汇总是统计每个分词的数据,如分词在日志数据中出现的次数和位置等),因此,能够确定查询条件类型为倒排查询类型。
当然,上述只是倒排查询类型的几个示例,对此倒排查询类型不做限制。
在一种可能的实施方式中,可以根据业务需求配置正排查询类型,对此正排查询类型不做限制,例如,该正排查询类型可以包括但不限于:多字段查询,长时间查询,大流量查询,复杂表连接查询,分页查询等。基于此,若该查询请求用于实现多字段查询(如待查询的字段数量大于数量阈值),或长时间查询(如待查询数据所处的时间段大于时长阈值,如查询一年的数据等),或大流量查询(如待查询数据的流量大于流量阈值),或复杂表连接查询,或分页查询,则可以确定与该关键字匹配的查询条件类型为正排查询类型。
比如说,可以预先配置多字段查询为正排查询类型,当用户需要进行多字段查询时,查询请求中携带与多字段查询有关的内容,对此查询请求的内容不做限制。在接收到查询请求后,可以基于该查询请求分析出该查询请求用于实现多字段查询(多字段查询是指查询日志数据的多个字段,且待查询的字段数量大于数量阈值),因此,能够确定查询条件类型为正排查询类型。
又例如,可以预先配置长时间查询为正排查询类型,当用户需要进行长时间查询时,查询请求中携带与长时间查询有关的内容,对此查询请求的内容不做限制。在接收到查询请求后,可以基于该查询请求分析出该查询请求用于实现长时间查询,因此,能够确定查询条件类型为正排查询类型。
又例如,可以预先配置大流量查询为正排查询类型,当用户需要进行大流量查询时,查询请求中携带与大流量查询有关的内容,对此查询请求的内容不做限制。在接收到查询请求后,可以基于该查询请求分析出该查询请求用于实现大流量查询,因此,能够确定查询条件类型为正排查询类型。
又例如,可以预先配置复杂表连接查询为正排查询类型,当用户需要进行复杂表连接查询时,查询请求中携带与复杂表连接查询有关的内容,对此查询请求的内容不做限制。在接收到查询请求后,可以基于该查询请求分析出该查询请求用于实现复杂表连接查询(复杂表连接查询是指多个表的关联查询,即多表连接查询),因此,能够确定查询条件类型为正排查询类型。
又例如,可以预先配置分页查询为正排查询类型,当用户需要进行分页查询时,查询请求中携带与分页查询有关的内容,对此查询请求的内容不做限制。在接收到查询请求后,可以基于该查询请求分析出该查询请求用于实现分页查询(分页查询是指查询出的数据量很大,无法通过一页显示所有数据,需要通过多个页来显示所有数据),因此,能够确定查询条件类型为正排查询类型。
当然,上述只是正排查询类型的几个示例,对此正排查询类型不做限制。
综上所述,可以对查询请求的内容进行分析,得到与关键字匹配的查询条件类型,该查询条件类型可以为倒排查询类型或者正排查询类型。
步骤303,若该查询条件类型为倒排查询类型,则通过该关键字查询融合索引表中的倒排索引表,得到与该关键字匹配的第一数据结构。
示例性的,当用户需要进行全文查询,或实时数据查询,或分组聚合查询,或分词汇总查询时,查询请求中携带的关键字可以为倒排查询类型的关键字,如倒排查询分词,因此,在从查询请求中解析出该关键字后,可以通过该关键字查询融合索引表中的倒排索引表,得到与该关键字匹配的第一数据结构。
例如,参见表4所示,可以通过该关键字(如分词11)查询融合索引表中的倒排索引表,得到与该关键字匹配的第一数据结构为数据11。
步骤304,若该查询条件类型为正排查询类型,则通过该关键字查询融合索引表中的正排索引表,得到与该关键字匹配的第二数据结构。
示例性的,当用户需要进行多字段查询,或长时间查询,或大流量查询,或复杂表连接查询,或分页查询时,查询请求中携带的关键字可以为正排查询类型的关键字,如正排查询分词,因此,在从查询请求中解析出该关键字后,可以通过该关键字查询融合索引表中的正排索引表,得到与该关键字匹配的第二数据结构。例如,参见表4所示,可以通过该关键字(如分词21)查询融合索引表中的正排索引表,得到与该关键字匹配的第二数据结构为数据21。
在一种可能的实施方式中,若用户需要进行全文查询(或实时数据查询,或分组聚合查询,或分词汇总查询),且用户需要进行多字段查询(或长时间查询,或大流量查询,或复杂表连接查询,或分页查询),则查询请求携带的关键字包括第一关键字和第二关键字。比如说,查询请求包括两部分内容,第一部分内容用于实现全文查询,且第一部分内容包括第一关键字,第二部分内容用于实现多字段查询,且第二部分内容包括第二关键字。基于查询请求的第一部分内容确定与第一关键字匹配的查询条件类型,即与第一关键字匹配的查询条件类型为倒排查询类型(全文查询对应的查询条件类型),并基于查询请求的第二部分内容确定与第二关键字匹配的查询条件类型,即与第二关键字匹配的查询条件类型为正排查询类型(多字段查询对应的查询条件类型)。
基于此,由于第一关键字匹配的查询条件类型为倒排查询类型,则通过第一关键字查询融合索引表中的倒排索引表,得到与第一关键字匹配的第一数据结构。由于第二关键字匹配的查询条件类型为正排查询类型,则通过第二关键字查询融合索引表中的正排索引表,得到与第二关键字匹配的第二数据结构。
在一种可能的实施方式中,若用户需要进行分组聚合查询,且用户需要进行分词汇总查询,则查询请求携带的关键字包括第一关键字和第二关键字。比如说,查询请求包括两部分内容,第一部分内容用于实现分组聚合查询,且第一部分内容包括第一关键字,第二部分内容用于实现分词汇总查询,且第二部分内容包括第二关键字。基于查询请求的第一部分内容确定与第一关键字匹配的查询条件类型为倒排查询类型,基于查询请求的第二部分内容确定与第二关键字匹配的查询条件类型为倒排查询类型。基于此,通过第一关键字查询融合索引表中的倒排索引表,得到与第一关键字匹配的第一数据结构。通过第二关键字查询融合索引表中的倒排索引表,得到与第二关键字匹配的第一数据结构。
在一种可能的实施方式中,若用户需要进行复杂表连接查询,且用户需要进行分页查询,则查询请求携带的关键字包括第一关键字和第二关键字。比如说,查询请求包括两部分内容,第一部分内容用于实现复杂表连接查询,且第一部分内容包括第一关键字,第二部分内容用于实现分页查询,且第二部分内容包括第二关键字。基于查询请求的第一部分内容确定与第一关键字匹配的查询条件类型为正排查询类型,基于查询请求的第二部分内容确定与第二关键字匹配的查询条件类型为正排查询类型。基于此,通过第一关键字查询融合索引表中的正排索引表,得到与第一关键字匹配的第二数据结构。通过第二关键字查询融合索引表中的正排索引表,得到与第二关键字匹配的第二数据结构。
在一种可能的实施方式中,融合索引表还包括全局标识,针对步骤303,在通过关键字查询融合索引表中的倒排索引表,得到与该关键字匹配的第一数据结构时,还可以从融合索引表中查询到与该关键字匹配的全局标识,参见表4所示。进一步的,在得到与该关键字匹配的全局标识之后,还可以通过该全局标识查询全量索引表,得到与该关键字匹配的全量索引。比如说,由于全量索引表可以包括全局标识与全量索引之间的映射关系,因此,可以通过该全局标识查询该全量索引表,从而得到与该关键字匹配的全量索引。
示例性的,由于数据库(如clickhouse数据库)中包括日志数据,因此,还可以通过查询数据库,得到与该关键字匹配的日志数据,对此过程不做限制。
在一种可能的实施方式中,融合索引表还包括全局标识,针对步骤304,在通过关键字查询融合索引表中的正排索引表,得到与该关键字匹配的第二数据结构时,还可以从融合索引表中查询到与该关键字匹配的全局标识,参见表4所示。进一步的,在得到与该关键字匹配的全局标识之后,还可以通过该全局标识查询全量索引表,得到与该关键字匹配的全量索引。比如说,由于全量索引表可以包括全局标识与全量索引之间的映射关系,因此,可以通过该全局标识查询该全量索引表,从而得到与该关键字匹配的全量索引。
示例性的,由于数据库(如clickhouse数据库)中包括日志数据,因此,还可以通过查询数据库,得到与该关键字匹配的日志数据,对此过程不做限制。
参见图4所示,在接收到查询请求后,可以分析该查询请求以确定查询条件类型。例如,若查询请求用于实现实时数据的查询或者分词汇总排名,则查询条件类型为倒排查询类型,通过查询融合索引表中的倒排索引表,得到与关键字匹配的第一数据结构,从而实现快速查询。又例如,若查询请求用于实现复杂表连接或者分页查询,则查询条件类型为正排查询类型,通过查询融合索引表中的正排索引表,得到与关键字匹配的第二数据结构,从而实现快速查询。
在查询融合索引表中的倒排索引表或者正排索引表之后,还可以通过全局标识查询全量索引表,得到与关键字匹配的全量索引。以及,还可以查询数据库(如clickhouse数据库),从该数据库中查询与与关键字匹配的日志数据。
示例性的,上述执行顺序只是为了方便描述给出的示例,在实际应用中,还可以改变步骤之间的执行顺序,对此执行顺序不做限制。而且,在其它实施例中,并不一定按照本说明书示出和描述的顺序来执行相应方法的步骤,其方法所包括的步骤可以比本说明书所描述的更多或更少。此外,本说明书中所描述的单个步骤,在其它实施例中可能被分解为多个步骤进行描述;本说明书中所描述的多个步骤,在其它实施例也可能被合并为单个步骤进行描述。
基于上述技术方案,本申请实施例中,在安全分析场景中,可以建立融合索引表,且该融合索引表包括倒排索引表和正排索引表,在接收到查询请求后,若查询条件类型为倒排查询类型,则可以查询融合索引表中的倒排索引表,得到第一数据结构,若查询条件类型为正排查询类型,则可以查询融合索引表中的正排索引表,得到第二数据结构,上述方式可以根据业务场景灵活定制融合索引表,实现海量日志数据的快速查询,并快速返回查询响应,通过将倒排索引表和正排索引表进行融合,实现不同查询条件类型的数据查询,提高查询速度,可以满足大数据的存储和查询要求,支持灵活定制索引,支持指定字段和联合索引查询,适合多表连接查询,支持复杂SQL条件的查询。
基于与上述方法同样的申请构思,本申请实施例中提出一种数据查询装置,参见图5所示,为所述数据查询装置的结构示意图,所述装置可以包括:
解析模块51,用于在接收到查询请求后,从所述查询请求中解析出关键字;
确定模块52,用于基于所述查询请求确定与所述关键字匹配的查询条件类型;其中,所述查询条件类型为倒排查询类型或者正排查询类型;
查询模块53,用于若所述查询条件类型为倒排查询类型,则通过所述关键字查询融合索引表中的倒排索引表,得到与所述关键字匹配的第一数据结构;若所述查询条件类型为正排查询类型,则通过所述关键字查询所述融合索引表中的正排索引表,得到与所述关键字匹配的第二数据结构。
在一种可能的实施方式中,若所述关键字包括第一关键字和第二关键字,与所述第一关键字匹配的查询条件类型为倒排查询类型,与所述第二关键字匹配的查询条件类型为正排查询类型,基于此,所述查询模块53,还用于通过所述第一关键字查询所述融合索引表中的倒排索引表,得到与所述第一关键字匹配的第一数据结构,以及,通过所述第二关键字查询所述融合索引表中的正排索引表,得到与所述第二关键字匹配的第二数据结构。
示例性的,所述确定模块52基于所述查询请求确定与所述关键字匹配的查询条件类型时具体用于:若所述查询请求用于实现全文查询,或实时数据查询,或分组聚合查询,或分词汇总查询,则确定所述查询条件类型为倒排查询类型;或,若所述查询请求用于实现多字段查询,或长时间查询,或大流量查询,或复杂表连接查询,或分页查询,则确定所述查询条件类型为正排查询类型。
示例性的,所述融合索引表还包括全局标识,所述查询模块53,还用于通过所述全局标识查询全量索引表,得到与所述关键字匹配的全量索引。
在一种可能的实施方式中,所述装置还可以包括(在图中未示出):
获取模块,用于获取日志数据;记录模块,用于基于所述日志数据确定倒排查询分词和所述倒排查询分词对应的第一数据结构,并在倒排索引表中记录所述倒排查询分词和所述第一数据结构的映射关系;以及,基于所述日志数据确定正排查询分词和所述正排查询分词对应的第二数据结构,并在正排索引表中记录所述正排查询分词和所述第二数据结构的映射关系;融合模块,用于对所述倒排索引表和所述正排索引表进行融合,得到融合索引表。
示例性的,所述获取模块,还用于为所述日志数据分配全局标识,所述全局标识具有唯一性,且所述融合索引表包括所述全局标识;所述记录模块,还用于基于所述日志数据确定全量索引,所述全量索引包括倒排查询分词和正排查询分词,并在全量索引表中记录所述全局标识与所述全量索引的映射关系。
示例性的,所述记录模块基于所述日志数据确定倒排查询分词和所述倒排查询分词对应的第一数据结构时具体用于:确定倒排查询分词的分词类型以及第一数据结构的数据类型;基于所述日志数据确定与所述分词类型对应的倒排查询分词;基于所述日志数据确定与所述数据类型对应的第一数据结构。
基于与上述方法同样的申请构思,本申请实施例中提出一种数据查询设备,参见图6所示,所述数据查询设备包括:处理器61和机器可读存储介质62,所述机器可读存储介质62存储有能够被所述处理器61执行的机器可执行指令;所述处理器61用于执行机器可执行指令,以实现如下步骤:
在接收到查询请求后,从所述查询请求中解析出关键字;
基于所述查询请求确定与所述关键字匹配的查询条件类型;其中,所述查询条件类型为倒排查询类型或者正排查询类型;
若所述查询条件类型为倒排查询类型,则通过所述关键字查询融合索引表中的倒排索引表,得到与所述关键字匹配的第一数据结构;
若所述查询条件类型为正排查询类型,则通过所述关键字查询所述融合索引表中的正排索引表,得到与所述关键字匹配的第二数据结构。
基于与上述方法同样的申请构思,本申请实施例还提供一种机器可读存储介质,所述机器可读存储介质上存储有若干计算机指令,所述计算机指令被处理器执行时,能够实现本申请上述示例公开的数据查询方法。
其中,上述机器可读存储介质可以是任何电子、磁性、光学或其它物理存储装置,可以包含或存储信息,如可执行指令、数据,等等。例如,机器可读存储介质可以是:RAM(Radom Access Memory,随机存取存储器)、易失存储器、非易失性存储器、闪存、存储驱动器(如硬盘驱动器)、固态硬盘、任何类型的存储盘(如光盘、dvd等),或者类似的存储介质,或者它们的组合。
上述实施例阐明的系统、装置、模块或单元,具体可以由计算机芯片或实体实现,或者由具有某种功能的产品来实现。一种典型的实现设备为计算机,计算机的具体形式可以是个人计算机、膝上型计算机、蜂窝电话、相机电话、智能电话、个人数字助理、媒体播放器、导航设备、电子邮件收发设备、游戏控制台、平板计算机、可穿戴设备或者这些设备中的任意几种设备的组合。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可以由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其它可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其它可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
而且,这些计算机程序指令也可以存储在能引导计算机或其它可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或者多个流程和/或方框图一个方框或者多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其它可编程数据处理设备上,使得在计算机或者其它可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其它可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 数据处理方法、装置、设备及系统、数据查询方法、装置及设备
- 数据存储方法及装置、数据查询方法及装置、电子设备