结构化记录检索
文献发布时间:2023-06-19 10:14:56
相关申请的交叉引用
本申请要求2018年7月25日提交的美国临时申请62/702,992的优先权,该美国临时申请以引用的方式并入本文中。
背景技术
本说明书涉及结构化记录的检索,并且更具体而言,涉及具有可选部分的层次结构的记录的索引编制(indexing)以及基于索引编制对这些记录的检索。
在一些应用中,记录以这样的方式被格式化:其可以通过提供用于传输或存储的简明形式而被激励。在一些示例中,用于这些消息的标准可能在多年之前已建立并且可能在行业实践中根深蒂固。用于行政、商业和运输的电子数据交换(EDIFACT)定义了这种简明形式的一个示例,其句法是国际标准ISO 9735(1988)中定义的。根深蒂固地使用该标准的行业示例是在航空业内,其使用EDIFACT句法以用于传输及存储或预订相关数据。
各个EDIFACT记录被称为“消息”。消息通常由在消息的限定部分内的序列片段(sequenced segment)的集构成。一些片段可能会用于消息的多于一个的部分中。可以(有条件地)或必须(强制地)在各个部分中使用的片段以及片段的允许重复次数是针对具体应用而限定的。在一些应用中,片段的集作为组进行重复,并且被称为组。片段和/或组可被嵌套。对各个片段进行命名(其中EDIFACT片段名称是三个字母数字式字符)。各个片段具有一个或多个元素,其可以是具有单一值的简单元素或其可以是复合元素。复合元素由两个或更多个定界值组成。片段内以及复合体内的元素被明确地定界(例如,用单独的定界字符(例如“+”以及“:”)),并且各个片段被明确地终止(例如,用终止字符“′”)。
数据库系统往往以表格的形式存储数据,其中各个行对应于一个记录,并且各个列与不同的字段相关联,如果该字段在记录中是可选的,则该列可以是空的。如果存在很多可能的但可选的字段,记录的列中的很多列可以是空的(例如,空值(Null))。高效索引编制方法可用于这种数据库系统,例如形成用于一个或多个列的索引,其允许基于表的列中的值来检索满足条件(例如查询)的记录。
发明内容
在常规方面,一种结构化记录检索方法允许以本机简明格式传输及存储记录,而无需解译并以表格形式存储记录。这种以表格形式(例如以“平面(flat)”或关系数据库)的记录存储可以使所需的空间加倍,并且更通常地,在存在很多可选元素的应用中需要实质上更多的空间。在一些实施例中,各个消息包括结构化记录,其中根据消息结构的规范(例如根据消息的“语法”)来解析该结构化记录,并且在解析期间,提取结构中的预定义位置中的字段值并添加到索引结构,该索引结构使记录标识符与(位置,值)对相关联。在一些示例中,各个(位置,值)对用作与位向量相关联的关键字,在该位向量中在指定位置处具有该值的记录具有对应位集。在特定位置中具有指定值的记录的检索使用检索到的位向量来识别并访问以本机格式存储的原始记录。满足指定字段中的值的布尔查询的记录的检索可以在识别并访问满足查询的记录之前使用与布尔查询的不同部分(例如项)相关联的位向量的布尔组合。
在一个方面,一般而言,一种方法涉及在存储多个结构化记录(或包括这些结构化记录的消息)的数据存储区中定位记录。访问数据存储区中所存储的所述多个结构化记录。所访问的所述多个结构化记录中的至少一些记录各自包括相应记录的多个片段,并且相应记录的所述多个片段中的各个片段在片段嵌套层次结构中具有位置(例如上下文位置)。记录的所述多个片段中的至少一些片段与一个或多个对应值相关联。对所述多个结构化记录进行索引编制。该索引编制包括形成索引数据结构,该索引数据结构使所述多个结构化记录中的记录与多个关键字相关联。各个关键字包括对应于片段的值以及该片段在片段嵌套层次结构中的位置。索引中的各个关键字与对应指示符相关联,该指示符使关键字与相关联记录相关联。在索引数据结构中,所述多个结构化记录中的至少一些结构化记录中的各个记录与对应的一个或多个关键字相关联。将第一记录与第一关键字相关联包括:解析第一记录以识别与第一记录的第一片段相对应、且与第一片段在片段嵌套层次结构中的第一位置相对应的第一值;以及更新与包括第一值和第一位置的第一关键字相关联的在索引数据结构中的特定指示符。处理查询以使用索引数据结构来检索所述多个结构化记录中与查询匹配的记录。该处理包括处理查询以确定包括至少第一关键字的一个或多个关键字的集合。第一关键字包括第一查询值和第一查询位置。确定与查询匹配的所述多个结构化记录的子集的指示符。确定指示符包括:基于第一关键字从索引数据结构检索第一指示符;以及基于第一指示符确定所述多个结构化记录的指示符。根据指示符来从数据存储区检索(或使得检索)所述多个结构化记录的子集。
方面可以包括一个或多个以下特征。
访问结构化记录包括接收来自数据存储区的结构化记录,并且执行结构化记录的索引编制而无需在索引编制之后维持数据存储区的副本。例如,不必将记录摄取到本地平面或关系数据库中以用于索引编制及检索。该方法的优点在于,除了接收到的结构化记录所来自的数据存储区之外,无需为了索引编制及检索而维持结构化记录的永久或长期副本。由于需要较少的存储,因而这是有利的,并且可以减少在本地副本与数据存储区之间具有不一致性的可能性。
访问结构化记录包括接收结构化记录以及以接收到的记录的格式或以压缩格式存储结构化记录。结构化记录的索引编制不需要形成数据存储区的表格表示。特征的优点在于,结构化记录的存储至少如它们被接收到的形式一样紧凑。
使用片段的语法,例如使用短语结构语法和/或BNF语法,来表示片段嵌套层次结构。
解析第一记录包括根据第一记录内的片段嵌套来使用语法以识别第一位置。
片段嵌套层次结构中片段的各个不同位置由不同的编号表示。
各个指示符与对应关键字相关联,并包括与所述关键字相关联的所述多个记录中的一个或多个记录的位向量表示。
对于所述多个关键字中的各个关键字,嵌套层次结构中的位置被表示为嵌套层次结构中的路径。可选地,嵌套层次结构中的位置被表示为数字标识符。可选地,嵌套层次结构中的位置被表示为元组。
查询还包括第二关键字,第二关键字包括第二查询值和第二查询位置,并且确定所述多个结构化记录的指示符还包括基于第二关键字从索引数据结构检索第二指示符。还基于第二指示符来确定所述多个记录的子集的指示符。
查询限定项的布尔组合,这些项包括与第一关键字相关联的第一项以及与第二关键字相关联的第二项,并且其中确定所述多个记录的子集是基于第一指示符和第二指示符的布尔组合(例如作为位向量指示符的逐位布尔组合)的。
至少一些记录片段与多于一个的对应值相关联,各个值在片段中具有不同的偏移,并且查询还包括偏移,该偏移表示与片段相关联的多个值内的偏移。
偏移识别片段的组件。
偏移还识别片段内的值。
偏移将组件识别为对片段组件的列举的数字基准,并且偏移将片段内的值识别为对组件中的值的列举的数字基准。
在另一方面,一般而言,一种以非暂时性形式存储在计算机可读介质上的软件包括用于使计算系统执行上述任一方法的所有步骤的指令。
在另一方面,一般而言,一种用于定位数据存储区中的多个结构化记录中的与查询匹配的记录的计算系统被配置为执行上述任一方法的所有步骤。
在又一方面,一般而言,一种数据结构存储在非暂时性机器可读介质上。该数据结构包括与保存多个结构化记录的数据存储区相关联的片段嵌套层次结构的表示,所述多个结构化记录中的至少一些记录各自包括该记录的多个片段。数据结构还包括将所述多个结构化记录中的记录与多个关键字相关联的索引数据结构,各个关键字包括与片段相对应的值以及与数据存储区相关联的在嵌套层次结构中的位置,各个关键字与对应指示符相关联,该指示符使关键字与和关键字相关联的记录相关联。数据结构可用于向用于从数据存储区进行数据检索的系统赋予功能性。
在又一方面,一般而言,一种用于针对计算机存储器进行数据检索的系统包括用于根据片段嵌套层次结构的表示和索引数据结构来配置所述存储器的部件。片段嵌套层次结构的表示与保存多个结构化记录的数据存储区相关联,所述多个结构化记录中的至少一些记录各自包括该记录的多个片段。索引数据结构使所述多个结构化记录中的记录与多个关键字相关联,各个关键字包括对应于片段的值以及与数据存储区相关联的在嵌套层次结构中的位置,各个关键字与对应指示符相关联,该指示符使关键字与和关键字相关联的记录相关联。
各方面可以包括一个或多个以下优点。
基于值的位置上下文而形成索引提供了用于识别记录以进行检索而无需以传统表格形式存储记录数据库的时间及空间高效方法。无需转换为表格形式,由此维持数据的紧凑存储,同时还能提供具有时效性的查询执行以识别想要的记录。在至少一些实施例中,索引的预计算(其随后用于处理查询)可以随着记录被添加到数据存储区而进行更新,而不必重建索引结构。
根据下面的描述以及权利要求书,本发明的其他特征及优点将会变得显而易见。
附图说明
图1是存储及检索系统。
图2是示出了图1的解析器/索引器的框图。
图3是消息处理的第一示例性示例。
图4是消息处理的第二示例性示例。
图5是在处理图3及图4的消息之后的索引存储区的图。
图6是查询处理的示例性示例。
图7是基于EDIFACT的语法的一部分的图。
具体实施方式
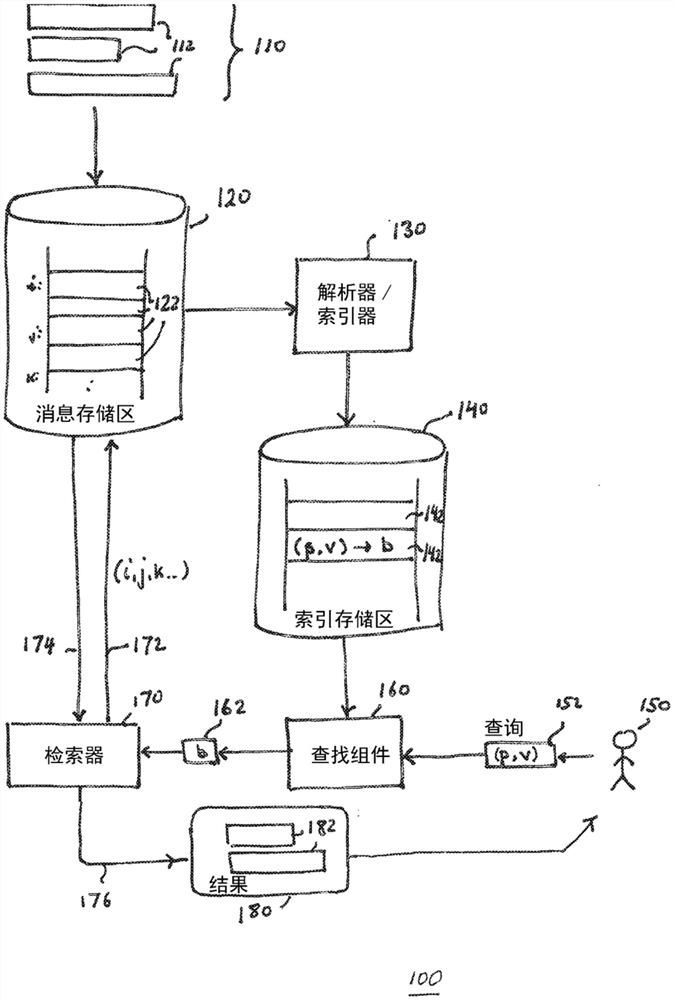
参照图1,存储及检索系统100包括消息存储区120,该消息存储区用于存储消息112(一起输入的消息110)。例如,消息存储区可以包括保持有消息112的集中式或分布式电子数据存储设施。各个消息包括结构化记录。在下面的讨论中,消息存储区120还可以被称为数据存储区,其存储对应于消息的结构记录。在一些示例中,消息存储区通过数据通信链路(例如通过计算机网络)接收来自多个源的消息,并且保存各个消息的副本以供数据处理系统访问。一般而言,系统100的一个功能是向用户150(或等效地,自动化数据处理系统)提供能力来请求存储区120中的满足基于内容的查询的任何消息并且为用户识别并访问来自存储区120的这些消息,例如向用户提供这些消息作为响应。
不局限于任何具体应用,在一个示例中,消息112是以EDIFACT消息的形式。根据EDIFACT标准(ISO 9735(1988)),各个消息可以具有在用于表示该消息的字节或字符的数量以及在各个消息中所表示的基本数据元素(例如数字、字符、字符串)的数量这两个方面可变的大小。数据消息具有层次句法,其中多于一个的基本数据元素可以在消息的区段内组合,并且这些区段本身可以嵌套。在EDIFACT消息的特定上下文中,这些区段可以被称为片段,并且基本数据元素可以形成多个元素的复合体,且片段集合可以形成组,这些组本身可以包括在消息的层次结构中。
作为更具体的应用,同样并非旨在限制于该应用,将该方法应用于飞行旅行信息处理,例如包括机票预订处理。在该上下文中,与在特定飞机上在特定时间的特定单独旅行相关联的各个旅游通常将与多个消息相关联。例如,同一旅游可以具有与订票相关联的消息、与用餐请求相关联的另一消息、与飞机上的乘客登机相关联的另一消息等等。旅行信息处理中的各种功能可能会需要由个人(例如旅行代理商)和自动化系统(例如向旅客提供信息访问的基于Web的应用)这两者提出的各种类型的查询、以及可能定期需要访问消息的数据处理系统(例如支付处理系统、旅行优惠计划等等)。
返回到图1,消息112作为记录122被存储在存储区120中。这些记录具有与输入消息相同的格式,或者可选地,这些记录具有作为消息的直接转换的格式,其可以例如通过消息的压缩而减小大小。在任何情况下,一般而言,记录的元素(例如基值)并非位于消息内的固定位置,因为它们可能以行和列表格布置。
如上文所介绍,输入消息可以包括具有各种层次结构的各种内容。因此,消息的元素可以出现在多种不同的上下文中。例如,可以存在数百、数千或更多的不同上下文。如果使用各个上下文与表的不同列相关联的表格布置,则结果将会是由于任一特定记录具有仅来自相对少的数量的上下文的元素,因此表中的大多数条目将是未使用的(即为空值或空的)。
尽管所存储的记录122具有所述格式,但是系统100提供基于索引的数据访问能力。为了支持该能力,系统100包括索引存储区140,该索引存储区通常存储与消息存储区120中所存储的消息相关联的索引信息。
该系统使用解析器/索引器130对数据存储区的消息进行索引编制,该解析器/索引器在其到达(或通过通信路径到达)消息存储区120时扫描各个消息112,或者可选地,在其到达存储区120之后扫描对应于各个输入消息的各个记录122,并且更新索引存储区140中的索引数据。索引存储区140提供关键字和与该关键字匹配的消息的集合的表示之间的映射,各个关键字表示唯一的(位置,值)对。
在操作中,通常在已经形成索引存储区140之后,用户150提供查询152,该查询被传送到查找组件160。查找组件访问索引存储区140中的索引数据以确定与该查询匹配的记录的表示(例如列表或位向量)。该表示或等效表示被传送到检索器170,该检索器将请求172传送到消息存储区120并接收来自消息存储区的对应消息174作为回复。检索器170将这些消息提供给用户150,例如捆扎成结果180,该结果包括具有与消息112相同的格式的满足查询150的消息。可选地,当消息变得可用时,检索器会将它们发送到用户,或者又一可选地,检索器指示消息存储区将所请求的消息直接发送到用户。
索引存储区140中的索引数据布置在记录142的集合中。各个记录与包括元素的“位置”和元素的值(即值对)的关键字相关联,并且具有记录122的位置的表示,这些记录在消息的指定位置中具有指定值。元素的位置唯一地识别元素的类型、以及正在使用该系统的应用的可能消息的集合内的特定层次上下文。例如,在旅行信息处理应用中,一些消息具有与预订相关联的区段。在这种用于预订的区段内,一些预订具有与乘客相关联的区段,并且一些预订可以具有与旅行代理商相关联的区段。针对乘客的区段可以具有针对地址的区段,该针对地址的区段可以进而具有针对街道地址(例如“1Main Street”(1主街道))的区段。针对旅行代理商的区段也可以具有针对地址的区段,该针对地址的区段也可以具有针对街道地址(例如“1Commercial Way”(1商业路))的区段。在该简化示例中,不管地址区段是乘客区段还是旅行代理商区段的一部分,它的结构可以是相同的。然而,预订-乘客-地址上下文中的地址具有与预订-代理商-地址上下文中的地址不同的“位置”。如下面所述,将唯一标识符(例如整数)分派给可能会被查询的元素的所有可能上下文,这些唯一标识符是根据用于应用的有效消息结构的规范而确定。例如,可以将位置值158分派给预订-乘客-地址上下文的地址,而将位置值247分派给预订-代理商-地址上下文的地址。可以采取各种方式来分派这些值,例如在想要索引条目的上下文的集合的列举中按顺序来分派,或者可选地,基于通过通常为不同输入上下文提供唯一编号的函数而将上下文转换为整数的散列函数方法来分派。
可以使用记录122的位置的各种类型的表示。在提供紧凑存储的一个实现中,表示是位向量,其中与对应(位置,值)关键字相关联的索引记录具有位向量,该位向量针对各个匹配记录具有一个位集合,该位集合位于与记录122在消息存储区中的位置相关联的位置中。例如,如果记录1003处的消息与该位置和值匹配,则设置该索引记录142的位向量的第1003位。在一些实施例中,例如利用零游程被压缩成游程长度的计数的游程长度编码方法来压缩位向量,或者作为另一示例,使用与置位(set bit)相对应的位置的有序列表来压缩位向量。在任何情况下,在各种实施例中,索引存储区140包括数据结构,该数据结构提供从(位置,值)关键字(例如位置=175,值=“1Main St.”)至记录的表示的高效映射,其中该值出现在被分派了标识符175的位置(即上下文)处的记录中。
参照图2,解析器/索引器130(在图1中进行了介绍)的实现使用消息的语法212。通常,该语法提供限定允许的消息的集合的功能,并且特别地,限定消息中所表示的片段、组、复合体和基本元素的允许的嵌套的集合。在一些示例中,该语法可以表示为短语结构语法,其中消息的一部分(例如非终止部分、命名片段等)的转换(例如“改写”)可以表示为非终止符、片段、元素等的可能序列。例如,这种语法可以采用类似于巴科斯-诺尔范式(Backus-Naur Form,BNF)的形式来表示。用于特定应用的消息可以在各种类别的语法内形成序列,包括上下文无关以及上下文相关的语言。然而,应理解,本文所述的方法并不限于任何特定形式的语法或消息“语言”。
语法的第二功能是将消息的分析(即解析)中各个元素的位置与所有消息的可能解析的空间中该元素的位置索引相关联。通常,仅存在消息的单个完整解析,因此解析的处理是确定性的,并且消息中的各个元素仅与语法的单个可能短语上下文相关联。例如,语法的一部分可以标记有位置索引,或者可以存在使元素的上下文与位置索引相匹配的单独的表(例如列举或散列表)。如上文所介绍,这意味着,作为预订消息的上下文中的乘客信息的上下文中的街道地址的元素将具有同一位置索引,而与消息中是否存在其他信息无关,并且将具有与不同上下文中的该同一元素不同的位置索引。
继续参照图2,从解析器214可以通用于多种不同应用(例如使用EDIFACT格式的多种不同应用)的消息的意义上来说,语法212在解析器214上赋予功能性,但语法212赋予处理应用的任何特定消息122所需的特定功能性,其中语法212是根据该应用而指定。通常,如下面在示例性示例的上下文中进一步论述,解析器214产生可以被认为是解析树416的东西,该解析树识别消息的成分及其在彼此内的嵌套,并且消息的一部分(或该部分的值)对应于这些成分中的各个成分(或至少不具有进一步嵌套并由此为消息的基本元素的终止成分)。如上文所介绍,这些成分与其全局唯一位置索引相关联,这些位置索引可以已在语法212中经过编码,或者可以在基于消息成分的嵌套上下文来构造解析树之后确定。在后一情况下,对于要进行索引编制的各个成分,可以在语法的表中查找该成分的上下文,该表将该上下文映射到位置索引。
通过索引器218处理解析器216的输出,该索引器使消息的一部分(例如终止元素)的值(至少要进行索引编制的那些部分的值)与其位置索引和消息索引(例如序列号)组合以形成元组(p,v,n),其中p是位置索引,v是消息的与成分相关联的部分的值,并且n是消息的索引。例如在位向量表示的情况下,索引器然后使用该元组以通过在与(p,v)对相关联的位向量中设置第n位来更新这些成分中各个成分的索引记录142。
参照图3,在第一示例性示例中,消息122具有索引n=1003(例如它是接收到的第1003个消息),并且具有整体内容“预订12345,乘客Smith,John,1Main St(1主街道),Boston MA(马萨诸塞州波士顿)”。该示例未使用EDIFACT格式,但是应理解,使用该格式的类似示例将遵循相同或类似的处理步骤。在该示例中,解析器214使用该应用的语法212产生解析树216,该解析树可以如图3所示。即,消息的解析具有“Reservation”的顶层成分,其具有两部分:预订编号(其为基本元素)和乘客信息部分。乘客信息部分进而具有姓名部分和地址部分,姓名部分具有名部分和姓部分,并且地址部分具有街道地址部分和市-州部分。在该示例中,各个部分被注释(圆括号内)有该部分的位置索引。例如,预订编号被注释有部分索引117,其中,该部分索引被普遍地分派给顶层“Reservation”的上下文中的“编号”,而与可能出现该上下文的特定消息无关。
可以使用解析器214的各种实现。例如,可以使用自底向上解析器(例如,确定性解析器,例如LR(自左向右)解析器,或CYK(Cocke-Younger-Kasami)解析器的图表)。
在该示例中,索引器218产生(p,v,n)元组220的集合。例如,对于预订编号,元组为(117,12345,1003),这意味着值12345出现在消息编号1003中的位置117中。图3中示出了这种元组。
参照图4,在第二示例性示例中,具有消息索引1205的消息122也涉及预订并且具有与图3所示消息共同的一些元素。在该消息中,预订部分具有编号元素(在该示例中,与图3中相同的预订编号),并且该消息具有代理商部分而不是乘客部分。解析器214使用语法212来形成解析树216(或等效数据结构),包括消息的成分的位置索引。如先前参照图3所论述,索引器218处理解析树以形成(p,v,n)元组。
在该示例中,预订编号同样位于位置117处。即,顶层预订内的编号的上下文与图3的消息中的上下文相同,因此位置编号相同。该编号的元组是(117,12345,1205)。另一方面,具有值“1Commercial Way”(1商业路)的地址的街道部分位于预订内、代理商部分内、地址内的与街道部分相对应的位置索引285处。这与图3中的街道部分“1Main St.”相反,该街道部分“1主街道”位于预订内、乘客部分内、地址内的与街道部分相对应的位置175处。如图所示,索引器218产生(p,v,n)元组的集合。
参照图5,如上文所介绍,索引存储区140包括多个记录142,各个记录与位置值(p,v)对相关联。如果索引存储区已经接收到来自索引器的元组(p,v,n),则通过设置各个消息编号n至1的位来将(p,v,n)元组存储在索引存储区140中。如图所示,对应于图3及图4中所示的示例,(117,12345)记录(即,任一预订编号12345的记录)至少具有位1003和1205集合。类似地,与预订片段中乘客的姓相对应的(165,“Smith”)记录具有位1003集合(对应于图3),但不具有位1205集合(对应于图4,其中不存在乘客部分)。类似地,(236,“AcmeTravel”)具有位1205集合,但不具有位1003。
如上文所介绍,图2至图5中所示的过程可以在消息到达消息存储区120时执行,或者可以成批地执行,例如对于在一小时或一天等等中添加的所有消息。在任何情况下,在任何时间,消息存储区120中的一些或所有消息已经进行了索引编制并且在索引存储区140中被表示(如果它们确实具有可以进行索引编制的字段)。应注意,在上面的论述中,对所有元素进行索引编制。然而,可以优选的是将索引编制仅限于元素的子集或位置的子集。例如,或许对预订编号进行索引编制,但没有对街道地址进行索引编制。尽管这种选择可能会限制涉及街道地址的查询的效率,但是这种选择可以提供合适的空时权衡(space-timetradeoff)。作为使用索引查找特定街道地址(例如“1Main St.”)的另一选择,另一选择是解析消息存储区中的各个记录122以定位在街道地址中具有想要的值的那些记录。
参照图6,在基于单个位置(特定上下文中的元素)的值进行的查询处理的示例中,用户150发出例如对预订编号12345的所有消息的查询。查找组件160访问索引存储区140以识别与这种查询匹配的消息记录122。为此,首先确定编号元素的位置,在这种情况下,将预订上下文中的编号映射到位置117。为了作出这种映射,查找组件160访问与解析器/索引器120的语法212一致的数据(例如,通过直接访问由解析器使用的相同数据或直接访问不同但一致的数据结构)。已经确定了关注的位置-值(p,v)对是(117,12345),该查找组件访问对应的位向量162,该位向量具有位1003和1205集合。该位向量(或具有等效信息的数据结构)被发送到检索器170,该检索器请求来自消息存储区120的记录1003和1205、接收这些对应记录并将它们捆扎成针对用户的响应180。
更复杂的布尔查询的情况未在图6中示出。对于这种布尔查询,查找组件针对该查询的各个项访问位向量,然后执行逐位布尔运算以得出与满足布尔查询的消息相对应的组合位向量。
在一些实现中,可以将查询处理并行化。例如,在布尔查询的情况下,可以并行地访问针对查询中不同项的记录142。这可以通过例如基于位置将记录142分隔为单独的数据区段而变得更加高效,由此避免并行查找的数据冲突。并行性的另一选择在于,随着对来自消息存储区的记录的请求,根据布尔表达对来自索引存储区或位组合的位向量的通信进行流水线操作。例如,就瓶颈是对消息存储区120本身的访问而言,这种流水线操作可以提供可能的最佳整体检索速度。
上面的论述有限地引用了EDIFACT消息结构的详情。基于上面所提供的EDIFACT消息格式的描述,应该显而易见,EDIFACT片段、组和复合体可以用作解析树内的成分(即语法的非终止符),而基本元素可以形成解析树的叶子(即语法的终止符)并且被分派了位置索引。在另一选择中,复合体也被分派了位置索引,并且位置索引被表示为由复合体的解析树中的位置以及复合体内元素的索引组成的对(例如在位置137处的复合体的第二元素)。
EDIFACT结构化记录比图3至图4的示例性示例更为复杂。特别地,消息中的基本元素通常位于EDIFACT片段的特定嵌套内,并且在该片段内位于该片段内元素的某序列位置处,并且如果该位置是复合元素,则位于该复合元素内基本元素的某序列位置处。并非如在图3至图4的示例中将“位置”表示为单个列举(例如整数)量,而是在EDIFACT具体实现中,将位置本身表示为元组p=(sp,ep,bp),其中sp是列举量,其对于应用域的可能消息中片段的各个可能嵌套是不同的,ep是基本或复合元素的索引(例如零-原点,使得0是第一元素,1是第二元素等等)。如果元素位于片段中的索引ep处的复合元素内,则bp是该复合元素内的元素的索引。如果元素不位于复合元素内,则该元素是片段中的索引ep处的基本元素,并且bp被任意设置为0。
应注意,用p=(sp,ep,bp)的元组表示替换先前示例中的简单整数位置p不会改变上述方法,这是因为重要的是基本元素的各个可能上下文具有位置的不同值,但是基本上不需要使位置为纯量。该EDIFACT具体实现的另一方面为仅列举片段的上下文,而不分派片段组的上下文,这是因为片段组不直接接触元素。
现在参照图7,特定EDIFACT应用中的语法的示例性示例被表示为片段及其基本和复合元素的可能嵌套的列表。应注意,图7的语法描绘了应用中的有效消息中可能存在的所有元素,而图3至图4的示例是特定消息。图7中所示的语法是树表示,具有用于“Reservation”(预订)片段组的根节点。“Reservation”片段组可以包含(即直接嵌套在其内)“Passenger”(乘客)片段组或“Agent”代理商片段组或者这两者、以及其他片段组或图7中未示出的片段,图7仅示出了语法的一小部分。“Passenger”片段组可以包含“Name”(姓名)片段(命名为“TIF”)和/或“Address”(地址)片段(命名为“ADR”)。“Reservation”组内的“Passenger”组内的“Name”片段被分派了片段位置sp=1,而“Reservation”组内的“Passenger”组内的“Address”片段被分派了片段位置sp=2。
“Name”片段在“Name”片段中的索引ep=0处具有“Traveler Surname andRelated Information”(旅客姓氏及相关信息)部分。该组件在索引bp=0处具有“Familyname”(姓)元素。因此,在“Reservation”组内的“Passenger”组内的“Name”片段内,作为“Traveler Surname and Related Information”组件内的“Family name”元素的姓名(诸如“Smith”)在p=(sp,ep,bp)=(1,0,0)的语法内具有“位置”。因此,如果“Smith”的“Name”出现在消息编号1003中,则索引器产生((1,0,0),“Smith”,1003)形式的记录,并且由(1,0,0),“Smith”)(或等效地(1,0,0,“Smith”))访问的索引记录具有第1003位集合。
以类似的方式,“Address component description”(地址组件描述)元素位于“Address Details”(地址详情)组件中的索引1处,其是“Reservation”组中的“Passenger”组中的“Address”片段中的第二元素(索引1),且因此具有位置p=(2,1,1)。此外以相同的方式,“Address component description”元素位于“Address Details”组件中的索引1处,其是“Reservation”组中的“Agent”组中的“Address”片段中的第二元素(索引1),且因此具有位置p=(3,1,1),因为“Reservation”组中的“Passenger”组中的“Address”片段具有片段上下文sp=3。
尽管在图7所示的语法的一部分中仅示出了三个片段上下文,但是在具有EDIFACT记录结构的该示例应用中,可以出现超过10000个不同的片段上下文,并且因此图7是整个语法的非常小的一部分。
应认识到,索引存储区140的上述索引结构仅仅是一个实现示例。可以使用其他结构(例如平衡树)而非(p,v)寻址位向量。索引结构的特定选择部分地取决于用于处理查询的适当基础结构,其包括例如用于查询处理的可能的并行性以及流水线操作。例如,在并行基于图的处理基础结构的上下文中(例如使用分布式数据流计算架构),根据位置的散列以及位向量表示中所指示的记录处理的流水线操作,对记录和位向量存储区的(p,v)访问可以尤其对于并行化是可修改的。在另一方面,在单处理器(即串行处理)情况下,各个位置的可选择的结构(诸如平衡树)可以是最有效的。
可以例如使用执行适当软件指令的可编程计算系统来实现上述方法,或者可以在适当的硬件(诸如现场可编程门阵列(FPGA))中或以某混合形式实现上述方法。例如,在被编程的方法中,软件可以包括在一个或多个被编程或可编程计算系统(其可以具有各种架构,诸如分布式、客户/服务器、或网格)上执行的一个或多个计算机程序中的过程,各个计算系统包括至少一个处理器、至少一个数据存储系统(包括易失性和/或非易失性存储器和/或存储元件)、至少一个用户接口(用于使用至少一个输入装置或端口接收输入,以及用于使用至少一个输出装置或端口提供输出)。软件可以包括较大程序的一个或多个模块,例如该程序提供与数据流图的设计、构造及执行相关的服务。程序的模块(例如数据流图的元素)可以作为符合数据存储库中所存储的数据模型的数据结构或其他组织数据来实现。
软件可以在一段时间(例如动态存储器(诸如动态RAM)的刷新周期之间的时间)期间利用介质的物理特性(例如表面凹坑及平台、磁畴或电荷)以非暂时性形式(诸如嵌入在易失性或非易失性存储介质或者任何其他非暂时性介质中)来存储。作为加载指令的准备,可以在诸如CD-ROM或其他计算机可读介质(例如可以由通用或专用计算系统或装置读取)的有形非暂时性介质上提供软件,或者可以通过网络的通信介质将软件传递(例如在传播信号中编码)到执行该软件的计算系统的有形非暂时性介质。一些或全部处理可以在专用计算机上执行,或者使用专用硬件(诸如协处理器或现场可编程门阵列(FPGA)或专用的专用集成电路(ASIC))执行。该处理可以采用分布方式来实现,在该分布方式中通过不同的计算元件来执行由软件指定的计算的不同部分。各个这种计算机程序优选地存储在或者下载到可以由通用或专用可编程计算机访问的存储装置的计算机可读存储介质(例如固态存储器或介质、或者磁或光介质)上,以用于在存储装置介质由计算机读取以执行本文所述的处理时配置并操作计算机。本发明系统也可以被认为是作为配置有计算机程序的有形非暂时性介质来实现,其中如此配置的介质会使计算机以特定及预定义的方式工作以执行本文所述的一个或多个处理步骤。
指令可以处于不同等级,包括机器语言指令、虚拟机器指令、高级编程指令和/或编译或解译指令。在一些实现中,某些功能可以完全地或部分地在专用硬件中实现。例如,图2中所示的各种队列可以具有专用硬件,其可以提高效率或减少所实现的排队方法的延迟时间。一些实现使用软件与专用硬件组件的组合。
已描述了本发明的大量实施例。然而,应理解,前述说明旨在例示而并非要限制本发明的范围,本发明的范围是由所附权利要求的范围限定。因此,其他实施例也在所附权利要求的范围内。例如,可以在不脱离本发明范围的情况下进行各种修改。另外,上述某些步骤可以是不依赖于顺序的,从而可按照不同于所描述的顺序执行这些步骤。
- 结构化记录检索
- 信息检索装置、信息检索方法、信息检索程序及记录了信息检索程序的记录介质