一种面向设定策略的中文拼音自动生成方法及装置
文献发布时间:2023-06-19 10:32:14
技术领域
本发明涉及拼音生成技术领域,尤其涉及一种面向设定策略的中文拼音自动生成方法及装置。
背景技术
为普及国学经典类著作,人们在微信公众号开设国学经典栏目,搜罗各类国学经典书籍,提供阅读及在线朗诵功能,并在书籍中给每个汉字标上拼音。其中需要解决的核心问题,是如何准确的将国学经典中的汉字自动转拼音。针对该问题,现有的技术主要是借助汉语拼音词典去匹配相应的拼音,存在如下的明显缺陷:
1)在处理多音字时,转拼音容易出错;
2)在处理通假字时(绝大部分不同音),转出的拼音往往是错的。
而国学经典书籍或文章中,多音字和通假字是比较常见的,采用现有的中文转拼音技术,会导致拼错的概率非常大,需要进行人工干预,但效果不理想:
1)人工纠错的工作量过大,无法在短期内完成大批量的国学经典书籍的处理;
2)人工纠错的效率极低,主要体现在“找错”效率低,需要逐一核对。
基于以上背景,本领域人员亟需寻找一种新的技术方案来解决上述的问题。
发明内容
针对现有技术中的技术问题,本发明提供一种面向设定策略的中文拼音自动生成方法及装置。
本发明提供一种面向设定策略的中文拼音自动生成方法,包括:
构造多音字词组词典,多音字词组词典中包含有多音字在不同词组中的发音;
构造通假字词典,通假字词典中包含通假字以及其出处、所在句子、通假的字以及发音;
录入设定策略文章,并对照汉语词典为设定策略文章中的汉字匹配拼音,生成初始文件;
对照多音字词组词典识别初始文件中的多音字以及词组,对多音字及其词组的拼音进行修正,生成第一修正文件;
对照通假字词典识别第一修正文件中的通假字,并根据通假字的前后文对其拼音进行修正,生成第二修正文件。
进一步地,方法还包括对第一修正文件中的多音字以及词组进行标记,以及对第二修正文件中的通假字进行标记。
进一步地,方法还包括:
对第二修正文件进行人工审核,将新多音字以及词组和新通假字分别保存至多音字词组词典和通假字词典中,并记录新多音字以及词组和新通假字的出现次数。
进一步地,方法还包括:
对第一修正文件中的各个多音字以及词组出现的次数进行计数,并记录在多音字词组词典中;
对第二修正文件中的各个通假字出现的次数进行计数,并记录在通假字词典中。
进一步地,方法还包括:
根据多音字以及词组出现的次数计算其出现概率,并作为对初始文件进行修正时的参考因素;
根据通假字出现的次数计算其出现概率,并作为对第一修正文件进行修正时的参考因素。
本发明还提供一种面向设定策略的中文拼音自动生成装置,装置包括多音字词组词典构造模块、通假字词典构造模块、设定策略文章录入模块、初始文件生成模块、第一修正模块以及第二修正模块,其中:
多音字词组词典构造模块,与第一修正模块相连接,用于构造多音字词组词典;
通假字词典构造模块,与第二修正模块相连接,用于构造通假字词典;
设定策略文章录入模块,与初始文件生成模块相连接,用于录入设定策略文章;
初始文件生成模块,与设定策略文章录入模块、第一修正模块相连接,用于对照汉语词典为设定策略文章中的汉字匹配拼音并生成初始文件;
第一修正模块,与多音字词组词典构造模块、初始文件生成模块、第二修正模块相连接,用于对照多音字词组词典识别初始文件中的多音字以及词组,对多音字及其词组的拼音进行修正,生成第一修正文件;
第二修正模块,与通假字词典构造模块、第一修正模块相连接,用于对照通假字词典识别第一修正文件中的通假字,并根据通假字的前后文对其拼音进行修正,生成第二修正文件。
进一步地,装置还包括多音字以及词组标记模块和通假字标记模块,其中:
多音字以及词组标记模块,与第一修正模块相连接,用于对第一修正文件中的多音字以及词组进行标记;
通假字标记模块,与第二修正模块相连接,用于对第二修正文件中的通假字进行标记。
本发明还提供一种电子设备,包括存储器和处理器,其中,
存储器,存储有计算机指令;
处理器,配置为运行计算机指令以使计算机设备执行上述方法。
本发明还提供一种存储介质,其上存储有计算机程序,其特征在于,计算机程序被处理器执行时运行上述方法中的步骤。
本发明实施例的一种面向设定策略的中文拼音自动生成方法、装置、电子设备及存储介质,构造多音字词组词典和通假字词典,在对照汉语词典为设定策略文章中的汉字匹配拼音之后,对照多音字词组词典对多音字及其词组的拼音进行修正,以及对照通假字词典对通假字的拼音进行修正,解决了多音字和通假字的转换错误率问题,解决人工审核和纠错效率低的问题,也实现了多音字词组词典和通假字词典的内容更新和自我学习功能,进一步提高了拼音转化正确率,也提高人了工审核和纠错效率。
附图说明
为了更清楚的说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见的,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
图1为本发明实施例的一种面向设定策略的中文拼音自动生成方法的步骤流程图(一);
图2为本发明实施例的一种面向设定策略的中文拼音自动生成方法的步骤流程图(二);
图3为本发明实施例的一种面向设定策略的中文拼音自动生成方法的步骤流程图(三);
图4为本发明实施例的一种面向设定策略的中文拼音自动生成方法的步骤流程图(四);
图5为本发明实施例的一种面向设定策略的中文拼音自动生成方法的步骤流程图(五);
图6为本发明实施例的一种面向设定策略的中文拼音自动生成装置的结构组成图;
图7为本发明实施例的一种面向设定策略的中文拼音自动生成装置的另一结构组成图;
图8为本发明实施例的一种电子设备的结构组成图。
具体实施方式
下面将结合本发明中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通的技术人员在没有做出创造性劳动的前提下所获得的所有其它实施例,都属于本发明的保护范围。
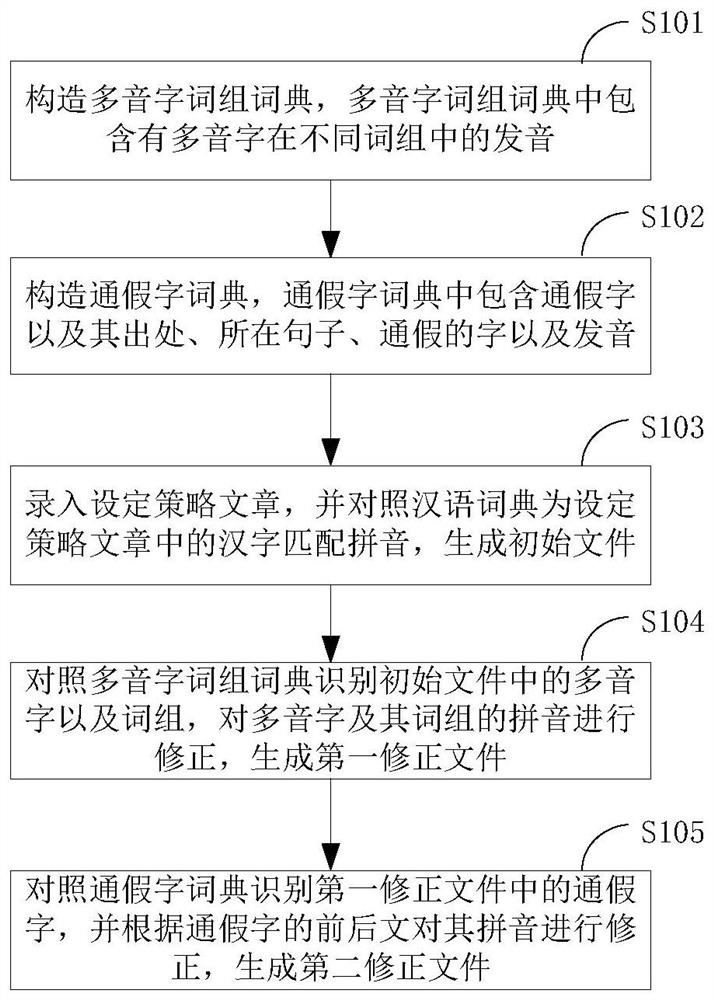
如图1所示,本发明实施例的一种面向设定策略的中文拼音自动生成方法,包括以下步骤:
步骤S101:构造多音字词组词典,多音字词组词典中包含有多音字在不同词组中的发音。多音字包含有多种发音,例如“更”的读音有“(gēng)”和“(gèng)”,读“(gēng)”时有词组“更新”、“变更”、“更正”、“更迭”、“少不更事”、“改弦更张”、“自力更生”等,读“(gèng)”时有词组“更好”、“更加”、“更多”、“更其”、“更胜一筹”、“更待何时”、“更进一步”等词语,将多音字的发音以及对应词组均存储在多音字词组词典中。
步骤S102:构造通假字词典,通假字词典中包含通假字以及其出处、所在句子、通假的字以及发音。
通假字“说”在“学而时习之,不亦说乎?”中,通悦(yuè),出处《论语》;通假字“女”在“诲女知之乎?”中,通汝(rǔ),出处《论语》。将通假字、出处、所在句子以及发音均存储于通假字词典。
步骤S103:录入设定策略文章,并对照汉语词典为设定策略文章中的汉字匹配拼音,生成初始文件。
本方法实施例中的设定策略文章可为国学类的经典文章,从而实现对国学文章的普及,同时,本领域技术人员也可选择其他中文文章,实现全文拼音的匹配。
本步骤根据汉语词典将设定策略文章中的汉字一一匹配拼音,只需要按照常用读音进行转换即可,生成的初始文件中每个汉字都匹配有对应的拼音。
步骤S104:对照多音字词组词典识别初始文件中的多音字以及词组,对多音字及其词组的拼音进行修正,生成第一修正文件。
将初始文件中的多音字以及相关词组识别出,并匹配多音字正确的读音,完成修正后生成第一修正文件。
步骤S105:对照通假字词典识别第一修正文件中的通假字,并根据通假字的前后文对其拼音进行修正,生成第二修正文件。
再将第一修正文件中的通假字对照通假字词典进行识别,并匹配通假字正确的读音,完成修正后生成第二修正文件。
具体的,如图2所示,本发明实施例还包括:
步骤S106:对第一修正文件中的多音字以及词组进行标记。
执行步骤S104后,将第一修正文件中的所有多音字进行标记。
步骤S107:对第二修正文件中的通假字进行标记。
执行步骤S105后,将第二修正文件中的所有通假字进行标记。
具体的,如图3所示,本发明实施例还包括:
步骤S108:对第二修正文件进行人工审核,将新多音字以及词组和新通假字分别保存至多音字词组词典和通假字词典中,并记录新多音字以及词组和新通假字的出现次数。
通过上述两个步骤的修正过程,为了使第二修正文件中多音字以及通假字的拼音正确,可再执行步骤S108,对第二修正文件进行人工审核,最终输出设定策略文章全文的中文及拼音结果。由于之前的修正步骤,此步骤中的人工审核工作量大大降低,从而大大提升中文拼音生成的效率,能够高效完成设定策略文章的批量拼音生成任务。
在人工审核的过程中,将多音字词组词典和通假字词典未存储的多音字和通假字进行添加,同时将新多音字和新通假字出现的次数也进行记录。
具体的,如图4所示,本发明实施例还包括:
步骤S109:对第一修正文件中的各个多音字以及词组出现的次数进行计数,并记录在多音字词组词典中。
执行步骤S106对第一修正文件中的多音字以及词组进行标记后,统计第一修正文件中多音字及相关词组出现的次数,并进行记录。
步骤S110:对第二修正文件中的各个通假字出现的次数进行计数,并记录在通假字词典中。
执行步骤S107对第二修正文件中的通假字进行标记后,统计第二修正文件中通假字出现的次数,并进行记录。
具体的,如图5所示,本发明实施例还包括:
步骤S111:根据多音字以及词组出现的次数计算其出现概率,并作为对初始文件进行修正时的参考因素。
步骤S112:根据通假字出现的次数计算其出现概率,并作为对第一修正文件进行修正时的参考因素。
根据大数据计算分析经验,出现历史次数高的多音字和通假字也会有更大概率出现在新的文章中,即某些多音字的其中一个读音使用率更高,在修正时若无法根据现存的多音字词组词典内容进行拼音的匹配,则优先匹配使用次数多的这个读音,通假字拼音匹配同理,从而实现本方法的自我完善和学习过程。
本发明还提供一种面向设定策略的中文拼音自动生成装置100,如图6所示,装置包括多音字词组词典构造模块101、通假字词典构造模块102、设定策略文章录入模块103、初始文件生成模块104、第一修正模块105以及第二修正模块106,其中:
多音字词组词典构造模块101,与第一修正模块105相连接,用于构造多音字词组词典;
通假字词典构造模块102,与第二修正模块106相连接,用于构造通假字词典;
设定策略文章录入模块103,与初始文件生成模块104相连接,用于录入设定策略文章;
初始文件生成模块104,与设定策略文章录入模块103、第一修正模块105相连接,用于对照汉语词典为设定策略文章中的汉字匹配拼音并生成初始文件;
第一修正模块105,与多音字词组词典构造模块101、初始文件生成模块104、第二修正模块106相连接,用于对照多音字词组词典识别初始文件中的多音字以及词组,对多音字及其词组的拼音进行修正,生成第一修正文件;
第二修正模块106,与通假字词典构造模块102、第一修正模块105相连接,用于对照通假字词典识别第一修正文件中的通假字,并根据通假字的前后文对其拼音进行修正,生成第二修正文件。
具体的,如图7所示,装置还包括多音字以及词组标记模块107和通假字标记模块108,其中:
多音字以及词组标记模块107,与第一修正模块105相连接,用于对第一修正文件中的多音字以及词组进行标记;
通假字标记模块108,与第二修正模块106相连接,用于对第二修正文件中的通假字进行标记。
本发明还提供一种电子设备200,如图8所示,包括存储器201和处理器202,其中,存储器201,存储有计算机指令;处理器202,配置为运行计算机指令以使计算机设备执行上述实施例的方法。
本发明还提供一种存储介质,其上存储有计算机程序,计算机程序被处理器执行时运行上述方法中的步骤。
本发明实施例的一种面向设定策略的中文拼音自动生成方法、装置、电子设备及存储介质,构造多音字词组词典和通假字词典,在对照汉语词典为设定策略文章中的汉字匹配拼音之后,对照多音字词组词典对多音字及其词组的拼音进行修正,以及对照通假字词典对通假字的拼音进行修正,解决了多音字和通假字的转换错误率问题,解决人工审核和纠错效率低的问题,也实现了多音字词组词典和通假字词典的内容更新和自我学习功能,进一步提高了拼音转化正确率,也提高人了工审核和纠错效率。
以上借助具体实施例对本发明做了进一步描述,但是应该理解的是,这里具体的描述,不应理解为对本发明的实质和范围的限定,本领域内的普通技术人员在阅读本说明书后对上述实施例做出的各种修改,都属于本发明所保护的范围。
- 一种面向设定策略的中文拼音自动生成方法及装置
- 一种面向复杂数据仓库环境的优化策略自动生成方法