一种轨道车辆的数据处理方法及装置
文献发布时间:2023-06-19 10:43:23
技术领域
本申请涉及列车领域,特别涉及一种轨道车辆的数据处理方法及装置。
背景技术
在轨道车辆工作过程中,轨道车辆故障预测与健康管理系统(Prognostics andHealth Management系统,PHM系统)成为保障列车安全运行的重要技术手段,PHM系统通过接收列车运行状态数据,利用大数据、人工智能等技术手段,综合分析列车运行数据、检修数据、环境数据,实现列车状态监控、故障诊断、故障预测预警和健康评估。
传统的PHM系统都是基于大数据分布式集群构建,其硬件投入比较大,若针对少量轨道车辆采用分布式集群搭建PHM系统,投入成本高,易造成资源浪费。
同时,对少量轨道车辆的运行状态评估通常需要满足时效性要求,以公务车为例,两列一天的运行数据需要在1.5个小时内处理完成。然而,轨道车辆运行状态数据包括多种格式的数据,例如SDR、MVB、DBT、SBV格式的数据,这些数据的数据量通常较大,采用传统RMDBS关系型数据库存储技术很难按时完成解析和存储处理。举例来说,SDR数据记录频率为每100毫秒约2000个字段,MVB数据记录频率为每200毫秒约6000个字段,每列轨道车辆每天(按16小时计算)产生3.6GB的原始数据。
因此,如何搭建适用于少量轨道车辆的PHM系统对少量轨道车辆的大体量的运行数据的进行快速存储和处理,是本领域亟待解决的技术问题。
发明内容
为了解决上述技术问题,本申请提供了一种轨道车辆的数据处理的方法和装置,搭建了一种能够适用于少量轨道车辆的PHM系统,实现了对少量轨道车辆的大体量数据的快速存储和处理,满足了轨道车辆运行状态监测的时效性要求。
为实现上述目的,本申请有如下技术方案:
一方面,本申请实施例提供了一种轨道车辆的数据处理的方法,所述方法包括:
从目标存储位置获取轨道车辆的多个运行数据;
基于预先配置的解析规则,对所述多个运行数据进行多线程解析,得到对应的解析数据;
对所述解析数据进行异步存储,以写入MongoDB数据库;
利用预先设置的数据处理模型,对所述MongoDB数据库中所述数据处理模型需要的目标数据进行处理,得到所述目标数据对应的处理结果,以获取所述轨道车辆的运行状态。
可选的,在对所述解析数据进行异步存储之前,所述方法还包括:
基于预先配置的加工规则,对所述解析数据中的部分数据进行数据预加工;所述数据预加工包括字段压缩、数值转换、函数计算、标签计算的至少一种。
可选的,所述方法还包括:
响应于数据查询请求,从MongoDB数据库中获取所述数据查询请求对应的数据或处理结果。
可选的,对所述多个运行数据进行解析的线程数根据所述Docker容器的计算资源和/或内存资源确定;对所述解析数据进行异步存储的线程数根据所述MongoDB数据库的连接数、所述Docker容器的计算资源和内存资源中的至少一项确定。
可选的,所述运行数据的格式包括以下非结构化数据类型的至少一种:MVB、SBR、DBT、SBV,解析数据为JsonObject数据对象。
另一方面,本申请实施例提供了一种轨道车辆的数据处理的装置,应用于Docker容器中,所述装置包括:
运行数据获取单元,用于从目标存储位置获取轨道车辆的多个运行数据;
解析单元,用于基于预先配置的解析规则,对所述多个运行数据进行多线程解析,得到对应的解析数据;
存储单元,用于对所述解析数据进行异步存储,以写入MongoDB数据库;
处理单元,用于利用预先设置的数据处理模型,对所述MongoDB数据库中所述数据处理模型需要的目标数据进行处理,得到所述目标数据对应的处理结果,以获取所述轨道车辆的运行状态。
可选的,所述装置还包括:
预加工单元,用于在对所述解析数据进行异步存储之前,基于预先配置的加工规则,对所述解析数据中的部分数据进行数据预加工;所述数据预加工包括字段压缩、数值转换、函数计算、标签计算的至少一种。
可选的,所述装置还包括:
获取单元,用于响应于数据查询请求,从MongoDB数据库中获取所述数据查询请求对应的数据或处理结果。
可选的,对所述多个运行数据进行解析的线程数根据所述Docker容器的计算资源和/或内存资源确定;对所述解析数据进行异步存储的线程数根据所述MongoDB数据库的连接数、所述Docker容器的计算资源和内存资源中的至少一项确定。
可选的,所述运行数据的格式包括以下非结构化数据类型的至少一种:MVB、SBR、DBT、SBV,解析数据为JsonObject数据对象。
由上述技术方案可以看出,本申请实施例提供了一种数据处理方法及装置,应用于Docker容器中,可以从目标存储位置获取轨道车辆的多个运行数据,基于预先设置的解析规则,对多个运行数据进行多线程解析,得到对应的解析数据,对解析数据进行异步存储以写入MongoDB数据库,利用预先设置的数据处理模型,对MongoDB数据库中所述数据处理模型需要的目标数据进行处理,得到目标数据对应的处理结果,以获取轨道车辆的运行状态。也就是说,采用分布式列式数据库MongDB及多线程技术,解决多字段、大批次、大体量数据的快速存储与读取问题;采用Docker容器技术和微服务架构,解决了系统资源隔离、调度问题,实现数据多线程解析、异步存取以及诊断模型自动运行;采用Docker容器封装并与工作站CPU序列号绑定方法,实现了数据加密,保障数据安全。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
图1为本申请实施例提供的一种轨道车辆的数据处理方法的流程图;
图2为本申请实施例提供的一种轨道车辆的数据处理装置的示意图。
具体实施方式
为使本申请的上述目的、特征和优点能够更加明显易懂,下面结合附图对本申请的具体实施方式做详细的说明。
在下面的描述中阐述了很多具体细节以便于充分理解本申请,但是本申请还可以采用其它不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本申请内涵的情况下做类似推广,因此本申请不受下面公开的具体实施例的限制。
正如背景技术中的描述,目前,在轨道车辆工作过程中,需要对轨道车辆的运行数据进行处理,从而对轨道车辆进行PHM,对轨道车辆运行状态评估通常需要满足时效性要求,以公务车为例,两列一天的运行数据需要在1.5个小时内处理完成。然而,轨道车辆离线数据分析需要使用多种格式的数据,例如SDR、MVB、DBT、SBV格式的数据,这些数据的数据量通常较大,采用传统RMDBS关系型数据库存储技术很难按时完成解析和存储处理。举例来说,SDR数据记录频率为每100毫秒约2000个字段,MVB数据记录频率为每200毫秒约6000个字段,每列轨道车辆每天(按16小时计算)产生3.6GB的原始数据。
对于轨道车辆的大体量的运行数据的快速存储和处理,是本领域亟待解决的技术问题。目前轨道车辆PHM系统都是基于分布式计算集群搭建的,然而针对较少量轨道车辆采用分布式集群搭建PHM系统,投入成本高,易造成资源浪费,同时当前服务站基于Windows系统,考虑到运维服务站人员的使用习惯,单机PHM系统需要在Windows操作系统下搭建部署,直接部署对主机资源开销很大,此外,关系型数据库的聚合类查询效率非常低下无法满足业务查询统计要求。
为了解决上述问题,在本申请实施例中,提供了一种轨道车辆的数据处理的方法和装置,应用于Docker容器中,可以从目标存储位置获取轨道车辆的多个运行数据,基于预先设置的解析规则,对多个运行数据进行多线程解析,得到对应的解析数据,对解析数据进行异步存储以写入MongoDB数据库,利用预先设置的数据处理模型,对MongoDB数据库中所述数据处理模型需要的目标数据进行处理,得到目标数据对应的处理结果,以获取轨道车辆的运行状态。也就是说,采用分布式列式数据库MongDB及多线程技术,解决多字段、大批次、大体量数据的快速存储与读取问题;采用Docker容器技术和微服务架构,解决了系统资源隔离、调度问题,实现数据多线程解析、异步存取以及诊断模型自动运行;采用Docker容器封装并与工作站CPU序列号绑定方法,实现了数据加密,保障数据安全。
下面结合附图,详细说明本申请的各种非限制性实施方式。
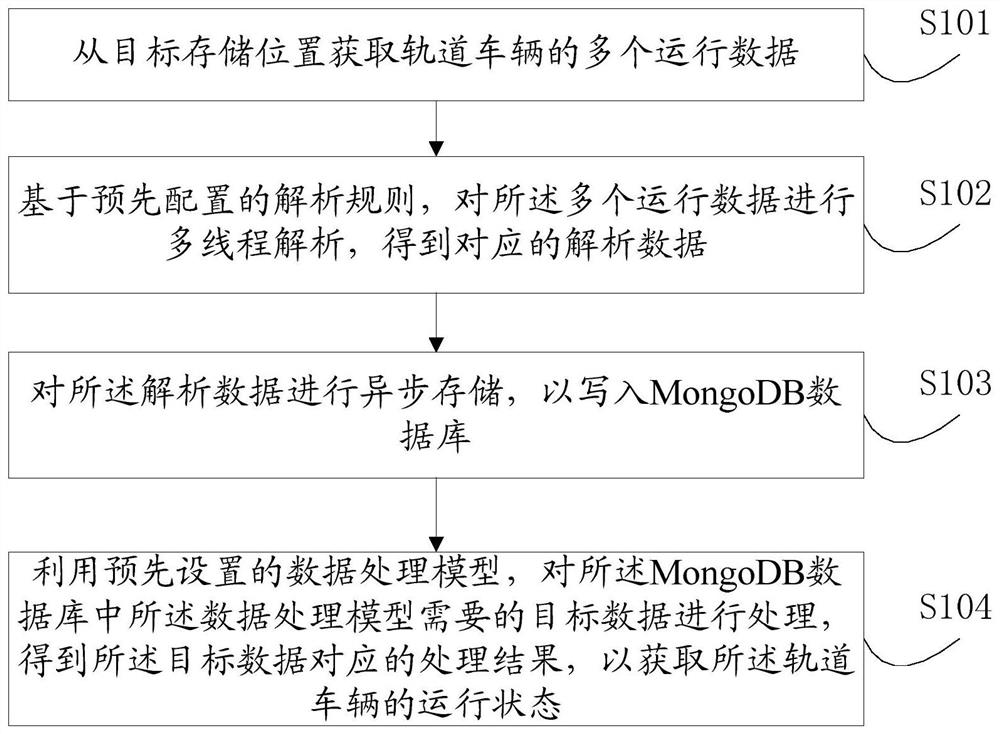
参考图1所示,为本申请实施例提供的一种轨道车辆的数据处理方法的流程图,该方法可以应用于Docker容器,包括以下步骤:
S101,从目标存储位置获取轨道车辆的多个运行数据。
目前,某些轨道车辆(如公务车)由于承担运行任务的特殊性,其运行数据不能实时回传,无法对其运行状态进行实时监控和评估。
因此,在本申请实施例中,检修人员使用加密U盘从轨道车辆列车上下载轨道车辆的运行数据,将其存储至目标存储位置,保证运行数据的快速拷贝和安全性。轨道车辆的运行数据的格式可以包括以下非结构化数据类型的至少一种:MVB、SBR、DBT、SBV,运行数据大概包括每天160多个数据文件。
目标存储位置可以为Docker容器对应的存储位置,Docker容器可以运行在单机版PC Server服务器上,目标存储位置可以为单机版PC Server服务器的指定目录,其中,PCServer服务器可以基于Windows操作系统,这样工作人员无需转换操作习惯即可进行操作,提高操作便利性。Docker容器运行在单机版PC Server服务器上,可以封装代码和数据,同时可以与该服务器的序列号绑定,实现数据加密,保障数据安全。Docker容器可以在windows环境中调用image镜像文件,不需要二次环境部署即可实现自动部署和运行,提高便利性。
Docker容器中可以具有采集程序,可以在PC Server主机启动后自动不间断的扫描目标存储位置,从目标存储位置获取到运行数据。具体的,Docker容器中可以有一个线程扫描目标存储位置,将运行数据的目录列表缓存到缓存控制器中,而后根据目标列表异步读取运行数据到缓存中,异步读取运行数据可以使用Spring-Boot微服务程序架构,异步读取运行数据可以利用二分法算法,在异步读取完成时,记录读取时间日志到Docker日志容器中。
S102,基于预先配置的解析规则,对多个运行数据进行多线程解析,得到对应的解析数据。
在本申请实施例中,通过算法规则预先配置的解析规则,对获取到的运行数据进行多线程解析,得到对应的解析数据,预先配置的解析规则可以为Xml文件,xml文件可以配置在缓存中。在预先配置的解析规则下对运行数据解析,可以提高解析的效率和准确性。举例来说,二进制数据01这个值,通过预先配置算法,就可以一对一找到运行数据的解析函数,迅速确定运行数据的解析方法,无需通过遍历方式来匹配运行数据对应的解析函数,提高解析效率,特别是在轨道车辆包括解析函数的参数时,能够极大的提高解析效率。
对运行数据可以采用多线程解析,多个线程之间并发对运行数据按照预先配置的解析规则进行解析,无需额外的等待时间,可以极大的提高解析的效率和准确性。同时,采用多线程技术对运行数据进行解析能够最大化的有效利用硬件的资源,保证没有空闲的资源,充分发挥了硬件资源的潜力。其中,对多个运行数据进行解析的线程数可以根据Docker容器的计算资源和/或内存资源确定。其中,计算资源包括CPU核数,内存资源包括缓存。
运行数据可以预先被读取到缓存中,则在对运行数据进行解析时,可以对缓存中的运行数据进行解析。在确定对多个运行数据进行解析的线程数后,可以按照运行数据的文件名分配线程,从而利用多线程进行运行数据的解析处理,得到多个运行数据对应的解析数据,解析数据的格式可以为JsonObject数据对象,对运行数据的解析处理可以为大数据文件和多字段的解析处理。
本申请实施例中,缓存的存储和释放可以通过缓存控制逻辑实现,线程的执行和销毁可以通过线程控制逻辑实现,从而调度线程任务。多线程解析运行数据可以使用Spring-Boot微服务程序架构,可以在运行数据的解析后生成日志。
S103,对解析数据进行异步存储,以写入MongoDB数据库。
在本申请实施例中,可以对解析数据进行异步存在,以写入MongoDB数据库,对解析数据的异步存储可以采用多线程执行,多个线程之间并发对多个解析数据进行存储,无需额外的等待时间,可以极大的提高数据存储的效率和准确性。同时,采用多线程技术对解析数据进行存储能够最大化的有效利用硬件的资源,保证没有空闲的资源,充分发挥了硬件资源的潜力。其中,对多个运行数据进行解析的线程数可以根据Docker容器的计算资源确定,也可以根据Docker容器的计算资源和内存资源确定。其中,计算资源包括CPU核数,内存资源包括缓存。其中,对解析数据进行异步存储的线程数根据MongoDB数据库的连接数、Docker容器的计算资源和内存资源中的至少一项确定。
作为一种可能的实现方式,可以获取到解析数据,将解析数据分配到可进行异步存储的线程,利用预先配置的存储规则,该线程将解析数据转换为MongoDB数据库需要的文件对象,并将生成的MongoDB数据库中需要的文件对象写入MongoDB数据库中。具体的,可以监听数据解析后得到的JsonObject数据对象,并对JsonObject数据对象通过循环生成MongoDB数据库需要的文件对象,并将生成的MongoDB数据库中需要的文件对象写入MongoDB数据库中。其中,预先配置的存储规则可以为xml文件,可以配置在缓存中。
作为另一种可能的实现方式,在对解析数据进行异步存储之前,HIA可以基于预先配置的加工规则,对解析数据中的部分数据进行数据预加工,具体的,可以获取到解析数据,将解析数据分配到可进行预加工的线程,利用预先配置的加工规则,该线程可以对解析数据进行预加工,而后将解析数据转换为MongoDB数据库需要的文件对象,并将生成的MongoDB数据库中需要的文件对象写入MongoDB数据库中。其中,预先配置的加工规则可以为xml文件,可以配置在缓存中。数据预加工可以包括字段压缩、数值转换、函数计算、标签计算中的至少一种。预处理后的解析数据通常具有更小的数据量,易于实现数据的快速存储。
多线程存储解析数据可以使用Spring-Boot微服务程序架构,可以在存储解析数据后生成日志。MongoDB数据库是基于分布式文件存储的数据库,可以提高数据查询效率。
S104,利用预先设置的数据处理模型,对MongoDB数据库中数据处理模型需要的目标数据进行处理,得到目标数据对应的处理结果,以获取轨道车辆的运行状态。
在本申请实施例中,数据处理模型可以由Python语言构建,可以用Xml语言进行算法规则的配置。数据处理模型中可以有多个模型,如转向架轴温模型、空调状态模型、电机状态模型等多种工况机理模型,以便实现轴温均值预警、空调故障提醒、电机故障提醒等功能。
目标数据是各个模型对应的执行数据,一个模型可以调用多个数据,但通常不会调用MongoDB数据库中所有的数据,使用数据处理模型对模型对应的目标数据进行计算处理,得到目标数据对应的处理结果,并将处理结果存入到MongoDB数据库的预测结果表中,以获取轨道车辆的运行状态,运行状态可以包括正常或者异常的结果,从而实现了对运行状态的监控,在获取到轨道车辆的运行状态后,可以生成分析报告。
此外,当检修人员需要对数据或者处理结果进行查询或分析使用时,响应于数据查询请求,可以从MongoDB数据库中获取数据查询请求对应的数据或处理结果,以便利用web应用服务器显示数据或处理结果,从而向业务人员提供数据展示、数据分析和数据挖掘功能,提供用户体验。为保障前端业务使用的时候,不被后台数据处理程序占用过多CPU和内存,因此web应用服务器可以使用Docker容器进行部署。
其中,目标数据例如转向架轴温模型对应的转向架轴温数据,空调状态模型对应的空调的运行数据,电机状态模型对应的电机运行数据等,当然,对于转向架轴温模型,只需转向架轴温数据用于执行,其他的数据例如空调、电机温度等数据都是不需要的,因此通过模型执行的数据是经过筛选的,模型只需要对特定的数据执行,需要执行的数据较少,这样可以提高模型的执行效率。
对目标数据进行处理可以使用Spring-Boot微服务程序架构,可以在对目标数据处理之后生成日志。
此外,预先配置的解析规则、存储规则、加工规则等可以实现二次数据配置开发,提高数据处理的灵活性。微服务程度、web应用服务器、MongoDB都使用Docker容器可以进行计算资源和内存的隔离,保障各个组件独立运行。此外,Docker容器和其中的各个程序可以加入Windows的开机启动项中,主机开机后自动启动,降低使用人员的使用难度。
本申请实施例提供了一种轨道车辆的数据处理方法,应用于Docker容器中,可以从目标存储位置获取轨道车辆的多个运行数据,基于预先设置的解析规则,对多个运行数据进行多线程解析,得到对应的解析数据,对解析数据进行异步存储以写入MongoDB数据库,利用预先设置的数据处理模型,对MongoDB数据库中所述数据处理模型需要的目标数据进行处理,得到目标数据对应的处理结果,以获取轨道车辆的运行状态。也就是说,采用分布式列式数据库MongoDB及多线程技术,解决多字段、大批次、大体量数据的快速存储与读取问题;采用Docker容器技术和微服务架构,解决了系统资源隔离、调度问题,实现数据多线程解析、异步存取以及诊断模型自动运行;采用Docker容器封装并与工作站CPU序列号绑定方法,实现了数据加密,保障数据安全。
参见图2,为本申请实施例提供的一种轨道车辆的数据处理装置的示意图。轨道车辆的数据处理装置,可以包括:
运行数据获取单元201,用于从目标存储位置获取轨道车辆的多个运行数据;
解析单元202,用于基于预先配置的解析规则,对所述多个运行数据进行多线程解析,得到对应的解析数据;
存储单元203,用于对所述解析数据进行异步存储,以写入MongoDB数据库;
处理单元204,用于利用预先设置的数据处理模型,对所述MongoDB数据库中所述数据处理模型需要的目标数据进行处理,得到所述目标数据对应的处理结果,以获取所述轨道车辆的运行状态。
在一些实施方式中,所述装置还包括:
预加工单元,用于在对所述解析数据进行异步存储之前,基于预先配置的加工规则,对所述解析数据中的部分数据进行数据预加工;所述数据预加工包括字段压缩、数值转换、函数计算、标签计算的至少一种。
在一些实施方式中,所述装置还包括:
获取单元,用于响应于数据查询请求,从MongoDB数据库中获取所述数据查询请求对应的数据或处理结果。
在一些实施方式中,对所述多个运行数据进行解析的线程数根据所述Docker容器的计算资源和/或内存资源确定;对所述解析数据进行异步存储的线程数根据所述MongoDB数据库的连接数、所述Docker容器的计算资源和内存资源中的至少一项确定。
在一些实施方式中,所述运行数据的格式包括以下非结构化数据类型的至少一种:MVB、SBR、DBT、SBV,解析数据为JsonObject数据对象。
本申请实施例提供了一种轨道车辆的数据处理装置,应用于Docker容器中,可以从目标存储位置获取轨道车辆的多个运行数据,基于预先设置的解析规则,对多个运行数据进行多线程解析,得到对应的解析数据,对解析数据进行异步存储以写入MongoDB数据库,利用预先设置的数据处理模型,对MongoDB数据库中所述数据处理模型需要的目标数据进行处理,得到目标数据对应的处理结果,以获取轨道车辆的运行状态。也就是说,采用分布式列式数据库MongoDB及多线程技术,解决多字段、大批次、大体量数据的快速存储与读取问题;采用Docker容器技术和微服务架构,解决了系统资源隔离、调度问题,实现数据多线程解析、异步存取以及诊断模型自动运行;采用Docker容器封装并与工作站CPU序列号绑定方法,实现了数据加密,保障数据安全。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其它实施例的不同之处。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。
以上所述仅是本申请的优选实施方式,虽然本申请已以较佳实施例披露如上,然而并非用以限定本申请。任何熟悉本领域的技术人员,在不脱离本申请技术方案范围情况下,都可利用上述揭示的方法和技术内容对本申请技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。因此,凡是未脱离本申请技术方案的内容,依据本申请的技术实质对以上实施例所做的任何的简单修改、等同变化及修饰,均仍属于本申请技术方案保护的范围内。
- 一种轨道车辆的数据处理方法及装置
- 一种带凸锥的轨道车辆连接装置、车体连接件及轨道车辆