语音唤醒方法、设备、存储介质及程序产品
文献发布时间:2023-06-19 11:03:41
技术领域
本发明涉及人机交互技术领域,特别是涉及一种语音唤醒方法、设备、存储介质及程序产品。
背景技术
随着物联网的发展和智能设备的普及,语音交互系统变得越来越普遍,语音唤醒技术作为语音交互的入口已然成为各类设备中必不可少的功能。因此,需要设计一个能够持续监听特定唤醒词的系统来启动语音输入,并能在现代移动设备等计算受限的环境中运行,以降低与远程服务器通信的延迟并保障信息安全。这就要求该系统必须具有高精度、低延迟、低内存消耗和低功耗的特点。
目前常规的语音唤醒系统在AEC和远场嘈杂环境下,激活性能较差。在满足激活要求的条件下,唤醒系统的误激活较高。时域卷积神经网络(TCNN)在音频合成、字符级语言建模和中文翻译等领域较RNN结构有杰出的表现,但尚未应用到语音唤醒等领域。
发明内容
本发明的目的在于提供一种新的语音唤醒方法、设备、存储介质及程序产品。
本发明的目的采用以下技术方案来实现。依据本发明提出的语音唤醒方法,包括以下步骤:获取用户输入的语音信息;对所述语音信息提取声学特征;根据预先训练得到的时域卷积神经网络识别模型,对所述声学特征进行识别;根据唤醒策略,对识别结果进行决策,以确定是否进行唤醒。
本发明的目的还可以采用以下的技术措施来进一步实现。
前述的语音唤醒方法,所述基于所述语音信息提取声学特征包括:采用LOG-FBANK特征。
前述的语音唤醒方法,所述根据预先训练得到的时域卷积神经网络识别模型,对所述声学特征进行识别包括:对所述声学特征中的每一维特征进行全局均值方差标准化处理;经过卷积层后,提取局部特征;然后经过TCN层进行处理,所述TCN层由多个TCN块堆叠而成,所述TCN块采用Resnet连接;然后经过全连接层进行处理,之后经过激励函数输出识别结果。
前述的语音唤醒方法,在所述获取用户输入的语音信息的步骤之前,还包括:采用Focal loss、CE loss或NCE loss方式来进行训练,用以预先训练得到所述时域卷积神经网络识别模型。
前述的语音唤醒方法,所述采用Focal loss方式来进行训练包括:采用最小代价的Focal loss方式来进行训练。
前述的语音唤醒方法,所述采用最小代价的Focal loss方式来进行训练包括:利用最小代价的Focal loss函数
FL(p
来进行训练;其中,α∈[0,1]为类别1的权重因子,1-α为类别0的权重因子,与类别的先验概率成反比,γ是可调参数,β
前述的语音唤醒方法,所述根据唤醒策略,对识别结果进行决策包括:采用多帧平滑唤醒策略来对识别结果进行决策。
前述的语音唤醒方法,所述采用多帧平滑唤醒策略来对识别结果进行决策包括:
如果
其中,λ
Minp
前述的语音唤醒方法,在所述对所述语音信息提取声学特征的步骤之前,还包括:对所述语音信息进行数据格式标准化和带通滤波。
前述的语音唤醒方法,在所述对所述语音信息提取声学特征的步骤之前,还包括:对所述语音信息进行幅值变换、线性加噪、语速变换、加混响的一个或多个。
前述的语音唤醒方法,在所述对所述语音信息提取声学特征的步骤之前,还包括:通过VAD或者预先训练好的DNN模型,进行数据对齐。
前述的语音唤醒方法,所述时域卷积神经网络识别模型的激活函数包括ReLU函数、PRelu函数或Gelu函数。
本发明的目的还采用以下的技术方案来实现。依据本发明提出的一种设备,包括:存储器,用于存储非暂时性计算机可读指令;以及处理器,用于运行所述计算机可读指令,使得所述计算机可读指令被所述处理器执行时实现:获取用户输入的语音信息;对所述语音信息提取声学特征;根据预先训练得到的时域卷积神经网络识别模型,对所述声学特征进行识别;根据唤醒策略,对识别结果进行决策,以确定是否进行唤醒。
本发明的目的还可以采用以下的技术措施来进一步实现。
前述的设备,当所述计算机可读指令被所述处理器执行时实现上述任一方面任一项可能的语音唤醒方法。
本发明的目的还采用以下的技术方案来实现。依据本发明提出的一种计算机存储介质,包括计算机指令,当计算机指令在设备上运行时,使得设备执行上述任一方面任一项可能的语音唤醒方法。
本发明的目的还采用以下的技术方案来实现。依据本发明提出的一种计算机程序产品,当计算机程序产品在设备上运行时,使得设备执行上述任一方面任一项可能的语音唤醒方法。
本发明与现有技术相比具有明显的优点和有益效果。借由上述技术方案,本发明提出的语音唤醒方法、设备、存储介质及程序产品至少具有下列优点及有益效果:
(1)本发明提出的基于TCNN的语音唤醒系统,模型结构简单,避免了梯度爆炸/消失问题,计算量以及占用系统内存非常小,适用于小型移动设备等资源受限设备端铺设;
(2)本发明能够使用非常小的训练数据集,通过并行训练,在4张基于Titan X的GPU上,几十分钟即可训练出满足行业标准的模型,节约大量采集数据和时间成本;
(3)本发明在唤醒决策方面,采用多帧平滑唤醒策略,能够一定程度上压制误激活的产生;
(4)本发明通过Focal loss处理正反样本失衡、相似音等hard example容易误判问题,提高了模型的鲁棒性以及语音唤醒的性能;
(5)本发明通过结合数据预处理与数据增强,提高了模型的鲁棒性以及语音唤醒的性能。
上述说明仅是本发明技术方案的概述,为了能更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
图1是本发明一个实施例的语音唤醒方法的流程框图;
图2是本发明一个实施例提供的TCNN模型的示意图;
图3是本发明一个实施例提供的TCN块结构的示意图;
图4是本发明一个实施例提供的扩张卷积的示意图;
图5是本发明一个实施例提供的基于最小代价的Focal loss的ROC曲线图;
图6是本发明一个实施例提供的每n次判断出现1次错误和误唤醒随阈值变化的曲线的示意图;
图7是本发明一个实施例提供的数据预处理的流程图;
图8是本发明一个实施例提供的数据增强的示意图;
图9是本发明一个实施例提供的深度关键词识别系统的示意图;
图10是本发明一个实施例的设备的硬件框图;
图11是本发明一个实施例的设备的结构示意图。
具体实施方式
为更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的语音唤醒方法、设备、存储介质及程序产品的具体实施方式、结构、特征及其功效,详细说明如后。
传统的语音唤醒解决方案主要有“基于隐马尔科夫模型的关键词/过滤器系统”(Keyword/Filter Hidden Markov Model System,基于HMM的Keyword and Filter系统)和“深度关键词识别系统”(Deep KWS System,Deep Keyword spotting System)两种。
基于HMM的Keyword and Filter系统是将语音唤醒看作语音识别问题,将关键词以外的词汇放入Filter路径中,有针对性地对关键词进行解码以提高解码速度。但是该系统基于HMM的音素级别建模单元,模型参数量大,需要占用大量的系统内存;并且该系统依赖序列搜索算法,计算量大。因此该系统不适用于存储资源和计算资源受限的小型移动设备。
Deep KWS System是将语音唤醒看作是一个二分类问题,直接生成最终的置信度得分,不需要序列搜索算法,计算量和内存占用与HMM方法相比更小,且在少量训练数据的情况下,激活性能仍优于HMM标准系统。因此,该方法对于低内存、低功耗和低延迟的设备运行上非常有吸引力。
之后,基于Deep KWS System的一系列改善,例如CNN(卷积神经网络)、RNNs(递归神经网络,循环神经网络)、以及CRNN(卷积循环神经网络),激活性能均有一定程度的提高,同时在训练数据的处理、模型结构的设计、激活函数的选择、模型参数量和计算量的权衡上也总结了宝贵的经验。
采用CNN体系结构的系统,对低信噪比(SNR)信号的适应能力没有CRNN好;对于语音这种上下文强相关性拟合能力弱。采用RNN体系结构的系统,在实际应用中占用较大内存;无法实现并行运算,降低了模型训练速度,增加了模型训练和迭代的时间成本;无法实现计算复用,每次进行唤醒判决时,都需要重新进行计算,大大增加模型的计算量;RNN结构上等效于IIR滤波器(无限脉冲响应滤波器),容易产生梯度消失/梯度爆炸问题,容易产生误激活,需要大量的反样本压制误激活。另外,判定唤醒的策略为单阈值决策,容易收到噪声干扰引发误唤醒。
从模型结构来看,CRNN相比较CNN对于低信噪比(SNR)具有更好的适应能力,而CNN需要更宽的滤波器或更深的深度实现这一级别的信息传播。尽管RNN结构对上下文相关性的拟合较强,但相对于DNN/CNN更容易陷入过拟合,容易因为训练数据的局部不鲁棒现象而带来额外的异常识别错误。从信号处理的角度来看,RNN的结构可视为一阶IIR滤波器,而一阶IIR滤波器可以通过高阶FIR滤波器(有限长单位冲激响应滤波器)近似。
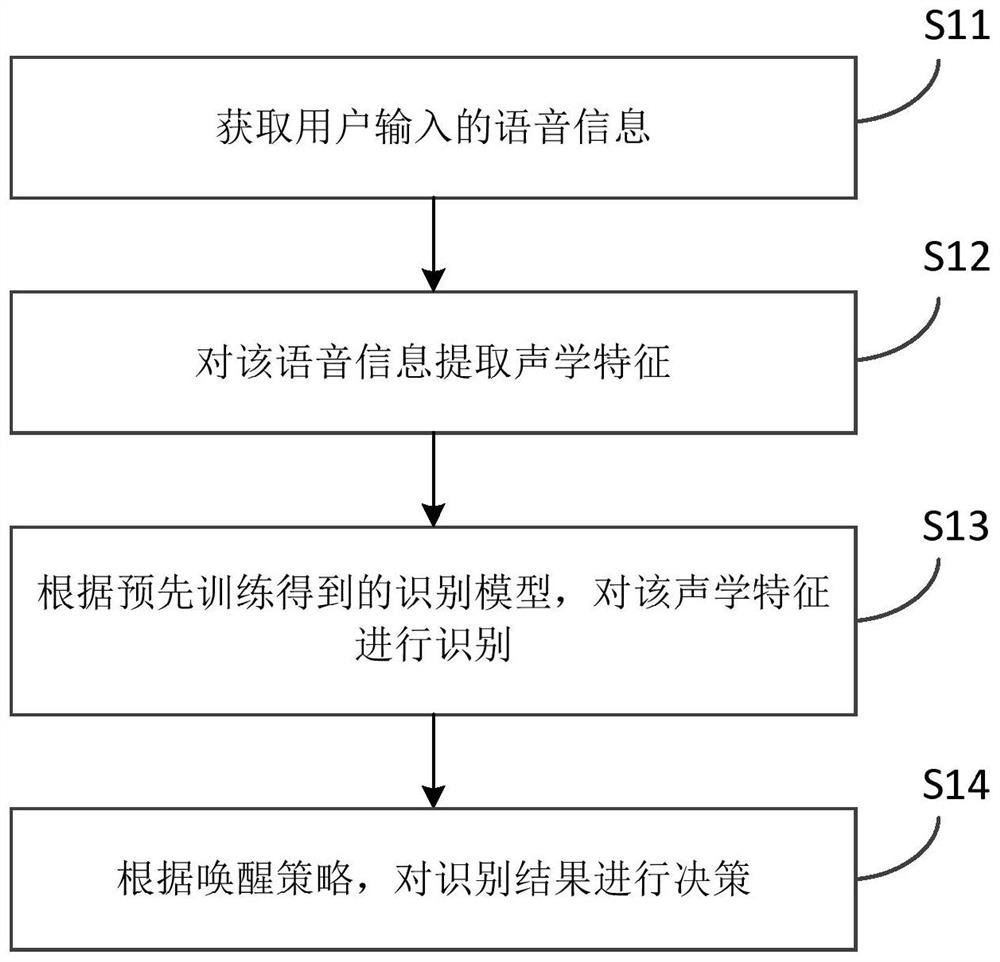
图1为本发明的语音唤醒方法一个实施例的示意性流程框图。请参阅图1,本发明示例的语音唤醒方法主要包括以下步骤:
步骤S11,获取用户输入的语音信息。
可选地,语音流按照T秒作为一个时间窗送入模型。
步骤S12,对该语音信息提取声学特征。
步骤S13,根据预先训练得到的识别模型,对该声学特征进行识别。具体地,该识别模型是深度神经网络(Deep Neural Network,简称为DNN),主要包括DNN/CNN/RNN等神经网络结构及其变形,可选地,可以是时域卷积神经网络(temporal convolutional neuralnetwork,简称为TCNN,也可称为TCN(temporal convolutional network),时域卷积网络,时间卷积网络)识别模型、CRNN结构的识别模型、或CNN+DNN结构的识别模型。
步骤S14,根据唤醒策略,对识别结果进行决策,以确定是否进行唤醒。可选地,通过唤醒策略得到并输出静止/唤醒信号。
在一些实施例中,在前述的步骤S12中,常用的特征提取包括MFCC、FBANK、LPCC等特征。作为一个可选的具体示例,该步骤S12包括:采用25ms的帧长和10ms的帧移构造和堆叠40维LOG-FBANK特征(简称为LFBE)。窗长的选择可根据唤醒词持续时间分布进行调整。
图2为本发明的语音唤醒方法一个实施例提供的TCNN(时域卷积神经网络)模型示意图,其中TCNN模型中包含TCN层。图3为本发明的语音唤醒方法一个实施例提供的TCN块(时域卷积网络块,其堆叠形成TCN层)结构示意图。请参阅图2和图3,在一些实施例中,在前述的步骤S13中,利用TCNN结构的识别模型来对声学特征进行识别,具体包括:
对声学特征中的每一维特征进行CMVN(全局均值方差标准化)处理;
经过卷积层后,提取局部特征,通过设置卷积步长降低模型计算量和特征图的大小,其中,卷积层的滤波数是N
然后经过TCN层(时域卷积网络层)进行处理,该TCN层由多个TCN块(时域卷积网络块)堆叠而成,该TCN块采用Resnet(Residual Neural Network)连接,从而能够实现非常深的网络,其中,TCN层的滤波数是N
然后经过全连接层进行处理,之后经过激励函数输出识别结果。可选地,该激励函数是Softmax函数。
作为一个可选实施例,如图3所示,一个TCN块包含Dilated Causal Conv(空洞因果卷积,扩张因果卷积)、ReLU(Rectified Linear Unit,线性整流函数,修正线性单元)、Dropout(随机失活)。可选地,TCN块还包含Norm(标准化)和1×1Conv(1×1卷积)。
表1为TCNN模型结构的一种示例参数。作为一个具体示例,数据特征图大小为240×40,定义时间帧数为m,特征维度为r,步长为s,通道数为n,扩张卷积系数为d,前述的步骤S13具体包括以下步骤:
首先采用两层步长s=2的一维卷积来学习局部特征,同时降低特征图和模型的计算量;
然后通过一个TCN块用于增加模型的表达能力;
接下来经过一个步长s=2的一维卷积,进一步降低特征图和模型的计算量;
然后通过扩张卷积系数d=2和扩张卷积系数d=5的TCN块,增大模型的感受野并获取更长的有效历史信息;
最后经过一层全连接层和softmax函数后输出0/1的概率,作为识别结果。整个模型的参数量为16.7k,计算量为0.33M/s。
表1 TCNN模型示例参数
需要说明的是,本发明提出的语音唤醒方法,通过采用TCNN识别模型进行识别,至少具有以下优点:
TCNN模型结构简单,参数量小(低至10k);
由于TCN只采用CNN网络结构,它是一种非递归神经网络结构,使得计算结果可以复用,因此可以实现对训练的并行和低内存要求,大大节约计算资源;
如图4所示的扩张卷积示意图,扩张卷积可以大大提高模型的感受野,获得更长的有效历史信息,并且随着扩张卷积系数d的增大以及模型深度不断加深,模型的感受野不断加大,相同深度下模型的感受野相比较普通CNN网络结构更大;TCNN网络结构采用扩张卷积的结构,使得模型在相同深度下可以看到更长的上下文信息;
TCN块采用Resnet连接,可以实现非常深的网络,可以学习和处理很长的上下文信息;
可选地,采用1×1卷积,从而保证了输入张量和输出张量具有相同的形状;
采用一维因果卷积,使得模型可以并行训练,大大节约训练和模型迭代的时间成本,避免了RNN引起的梯度消失/梯度爆炸问题。
在一些实施例中,TCNN识别模型的激活函数包括ReLU(修正线性单元)函数、PRelu(参数化修正线性单元)函数或Gelu(高斯误差线性单元)函数。
在一些实施例中,在进行前述的步骤S11之前,预先训练得到步骤S13提及的识别模型。具体地,采用Focal loss(焦点损失)、CE loss(cross_entropy_loss,交叉熵损失)或NCE loss(Noise-Constrastive Estimation Loss)方式来进行训练,用以预先训练得到TCNN识别模型。
进一步地,可以采用最小代价的Focal loss方式来进行训练。
具体地,在KWS任务中,正样本和负样本(或称为反样本)的分布极不平衡,并且负样本的数量往往比正样本大得多。同时,在训练语料库中,相似发音等hard examples对模型的贡献更大,需要分配更大的权重。
Focal loss可以用公式(1)表示,其中α∈[0,1]为类别1的权重因子,1-α为类别0的权重因子。在实践中,α可以通过类频率反比设置,与类别的先验概率成反比,或者作为交叉验证设置的超参数处理。γ是可调参数,默认为2。Focal loss通过α实现平衡语料库,通过(1-p
FL(p
然而在实践中,误唤醒的代价通常高于未唤醒。同时,训练集中正样本的先验概率估计往往高于实际情况。因此,有必要将式(1)乘以代价系数β
FL(p
其中,α由类别的先验概率的反比设置。β
图5为本发明的语音唤醒方法一个实施例提供的基于最小代价的Focal loss的ROC曲线(接收者操作特征曲线)图。请参阅图5,其中图示上的比值为反样本的代价权重与正样本的代价权重的比值。图中ROC曲线越靠下表示模型性能越好,可以看出,最小代价的Focal loss相比较原始Focal loss(1∶1)的模型性能要好。
在一些实施例中,前述的步骤S13中的识别模型的输入是声学特征,输出是各个关键词和非关键词的后验概率。而由于该识别模型是以帧为单位输出后验值的,就需要对后验值以一定的窗长进行平滑,平滑后的后验值如果超过一定的阈值会被认为是唤醒了。
在一些实施例中,前述的步骤S14包括:采用多帧平滑唤醒策略(或者称为多阈值决策的唤醒策略、k帧平滑唤醒策略、多帧唤醒策略)来对识别结果进行决策。
需注意,对于图像等孤立样本的分类问题,一种简单的方法是根据神经网络计算出的置信度是否高于某个预先确定的阈值进行判断。然而,对于上下文依赖的序列建模问题,基于单个样本的置信水平由于原始后验噪声的存在,往往会导致错误的判断,并且我们往往不能容忍误唤醒。一个经过训练的模型实际上仍然不可能通过阈值完全分离这两个类别。因此,有必要实时采集信息,并采用K帧平滑算法来降低误判断的概率。
不妨将原始样本的标签定义为S,神经网络预测的结果定义为P,神经网络模型每秒做出n个决策,也就是说n表示单位时间模型判断是否激活的次数。使用0表示静默,使用1表示激活。则虚警率为p(P=1|S=0),虚拒率为p(P=0|S=1),模型犯错的概率为p(P=1|S=0)+p(P=0|S=1)。在KWS问题中,可以将错误警报的频率预设为每小时e次。
对于单帧决策算法,也就是说没有做任何平滑处理,t时刻的决策算法需要满足以下条件:
Min p
s.t.p
图6为本发明的语音唤醒方法提供的每n次判断出现1次错误和误唤醒随阈值变化的示意图。请参阅图6,其中的实线表示每1/p(P=1|S=0)次判断就有1次判断错误随阈值λ的变化曲线,虚线表示每1/[p(P=0|S=1)+p(P=1|S=0)]次判断就有1次误唤醒随阈值λ的变化曲线。显然,总能找到唯一阈值λ
对于两帧而言,相同的模型在连续的时间帧上独立的做了两次判断,因此可以基于上述两次预测结果作出判断:
p
虽然从图6中看出1/p(P=1|S=0)和λ并不呈现线性关系,然而由于P
其中,e表示预设的每小时误激活次数,n表示单位时间(每秒)模型判断是否激活的次数。
显然,总能找到唯一阈值λ
同理,可以得到K帧唤醒策略:
利用本发明的语音唤醒方法,通过采用多帧唤醒策略,采用多个相邻时间窗的输出概率进行平滑处理,多阈值判决输出,能够降低误判断的概率。
需注意,本发明提出的基于TCNN的语音唤醒方法将语音唤醒看作是一个二分类问题,直接生成最终的置信度得分,不需要序列搜索算法,计算量和内存占用与Keyword/Filter Hidden Markov Model System方法相比更小。在本发明的一些实施例中,基于TCNN的语音唤醒方法可以分为6个部分:(1)数据预处理及数据增强(2)数据对齐(3)特征提取(4)TCNN模型(5)Focal loss(6)唤醒策略。
图7为本发明的语音唤醒方法一个实施例提供的数据预处理流程图。请参阅图7,在一些实施例中,在进行前述步骤S12的提取声学特征之前,本发明示例的语音唤醒方法还包括:对语音信息进行数据预处理。数据预处理主要包括两个部分:数据格式标准化和带通滤波。数据格式标准化是将不同采样率和数据类型的原始音频数据转化为标准采样率和数据类型。例如16kHz/16bit、8kHz/16bit等等。带通滤波则是通过设置带通滤波器将非语音频带的低频/高频噪声信号滤波,从而达到提升信号SNR(信噪比),降低噪声干扰,提高数据对齐精度的作用。在对语音信息进行数据预处理之后,可以再进行数据增强。
图8为本发明的语音唤醒方法一个实施例提供的数据增强示意图。请参阅图8,在一些实施例中,在进行前述步骤S12的提取声学特征之前,本发明示例的语音唤醒方法还包括:对语音信息进行数据增强,包括进行幅值变换、线性加噪、语速变换、加混响的一个或多个。数据增强可以有效的在有限数据基础上扩充数据集,提高模型的鲁棒性。
在一些实施例中,在进行前述步骤S12的提取声学特征之前,本发明示例的语音唤醒方法还包括:进行数据对齐。具体地,可以通过VAD(Voice Activity Detection,静音抑制,又称语音活动侦测)或者预先训练好的DNN模型进行数据对齐。如果原始音频SNR较高并且文本信息已知,可通过VAD进行对齐,否则应采用DNN进行数据对齐。数据对齐的好坏直接影响模型的性能。
图9为本发明的语音唤醒方法一个实施例提供的深度关键词识别系统(Deep KWSSystem)的示意图。请参阅图9,一个Deep KWS System可以分为3个部分,特征提取、DNN神经网络、后验概率处理。常用的特征提取包括MFCC、FBANK、LPCC等特征。DNN神经网络主要包括DNN/CNN/RNN等神经网络结构及其变形。后验概率处理是针对模型单帧输出概率的波动性,在每个时间窗口内的时间帧输出概率进行平滑处理。在本发明的一些实施例中,DNN网络结构采用TCNN网络结构。多帧唤醒策略是采用多个相邻时间窗的输出概率进行平滑处理,多阈值判决输出。
可选地,可以将前述实施例中的TCNN结构替换为CRNN结构,其余数据准备及训练流程和唤醒策略等流程不变。这时语音唤醒效果略差,由于RNN结构造成计算结果无法复用、无法并行计算导致模型计算量和训练时长大大提升。
可选地,可以将前述实施例中的TCNN结构替换为CNN+DNN结构,其余数据准备及训练流程和唤醒策略等流程不变。这时模型的深度和感受野受限,语音唤醒效果略差。
可选地,前述实施例中的模型结构和数据准备以及唤醒策略等流程不变,将训练流程中Focal loss变为CE loss。这时无法解决语音唤醒中正负样本严重失衡的问题,导致模型阈值很高,语音唤醒效果略差。
可选地,前述实施例中的模型结构和数据准备以及唤醒策略等流程不变,将训练流程中Focal loss变为NCE loss。这时无法缓解语音唤醒中相似音等hard example容易导致误激活的问题,导致模型阈值很高,语音唤醒效果略差。
可选地,前述实施例中的数据准备和模型结构以及训练流程等流程不变,将唤醒策略替换为单阈值唤醒。这时模型容易受到模型输出概率波动等影响导致误激活,同时阈值选择方面,通过暴力搜索的方式选择阈值,消耗一定的时间成本。
可选地,可以将前述实施例中的模型的激活函数,从ReLU替换成PRelu/Gelu。这时唤醒效果会更好,但是会带来额外的参数量和计算量。其中,Gelu激活函数在计算机视觉,自然语言处理和语音任务上相比较Elu和Relu具有更好的性能,并且能够实现更快的收敛。
需注意,在本发明的各个实施例中,本发明不限制交互界面的具体呈现效果,具体的呈现效果可以根据开发需求及用户使用需求做出相应调整。
可选地,本发明提出的语音唤醒方法可以利用应用程序(Application,简称为APP)、或是运行在设备后台的服务等软件来实施。相关设备安装有用于实现本发明提出的语音唤醒方法的应用或服务,从而能够利用该设备进行交互。
图10是图示根据本发明的一个实施例的设备的硬件框图。如图10所示,根据本发明实施例的设备100包括存储器101和处理器102。该设备100中的各组件通过总线系统和/或其它形式的连接机构(未示出)互连。本发明的设备100可以以各种形式来实施,包括但不限于诸如手机等手持移动设备、车载系统、智能音箱、智能眼镜、电视机、空调、扫地机器人等物联网设备。
该存储器101用于存储非暂时性计算机可读指令。具体地,存储器101可以包括一个或多个计算机程序产品,该计算机程序产品可以包括各种形式的计算机可读存储介质,例如易失性存储器和/或非易失性存储器。该易失性存储器例如可以包括随机存取存储器(RAM)和/或高速缓冲存储器(cache)等。该非易失性存储器例如可以包括只读存储器(ROM)、硬盘、闪存等。
该处理器102可以是中央处理单元(CPU)或者具有数据处理能力和/或指令执行能力的其它形式的处理单元,并且可以控制该设备100中的其它组件以执行期望的功能。在本发明的一个实施例中,该处理器102用于运行该存储器101中存储的该计算机可读指令,使得该设备100执行前述的本发明各实施例的语音唤醒方法的全部或部分步骤。
可以理解的是,设备为了实现上述功能,其包含了执行各个功能相应的硬件和/或软件模块。结合本文中所公开的实施例描述的各示例的算法步骤,本申请能够以硬件或硬件和计算机软件的结合形式来实现。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用和设计约束条件。本领域技术人员可以结合实施例对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
本实施例可以根据上述方法示例对设备进行功能模块的划分,例如,可以对应各个功能划分各个功能模块,也可以将两个或两个以上的功能集成在一个处理模块中。
上述集成的模块可以采用硬件的形式实现。需要说明的是,本实施例中对模块的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。
在采用对应各个功能划分各个功能模块的情况下,图11示出了上述实施例中涉及的设备的一种可能的组成示意图,如图11所示,设备200主要包括:获取模块201、特征提取模块202、识别模块203和唤醒决策模块204。
其中,获取模块201可以用于支持设备200执行上述步骤S11等,和/或用于本文所描述的技术的其他过程。
特征提取模块202可以用于支持设备200执行上述步骤S12等,和/或用于本文所描述的技术的其他过程。
识别模块203可以用于支持设备200执行上述步骤S13等,和/或用于本文所描述的技术的其他过程。
唤醒决策模块204可以用于支持设备200执行上述步骤S14等,和/或用于本文所描述的技术的其他过程。
需要说明的是,上述方法实施例涉及的各步骤的所有相关内容均可以援引到对应功能模块的功能描述,在此不再赘述。
本实施例提供的设备,用于执行上述语音唤醒方法,因此可以达到与上述实现方法相同的效果。
本发明的实施例还提供一种计算机存储介质,该计算机存储介质中存储有计算机指令,当该计算机指令在设备上运行时,使得设备执行上述相关方法步骤实现上述实施例中的语音唤醒方法。
本发明的实施例还提供一种计算机程序产品,当该计算机程序产品在计算机上运行时,使得计算机执行上述相关步骤,以实现上述实施例中的语音唤醒方法。
另外,本发明的实施例还提供一种装置,这个装置具体可以是芯片,组件或模块,该装置可包括相连的处理器和存储器;其中,存储器用于存储计算机执行指令,当装置运行时,处理器可执行存储器存储的计算机执行指令,以使芯片执行上述各方法实施例中的语音唤醒方法。
其中,本发明提供的设备、计算机存储介质、计算机程序产品或芯片均用于执行上文所提供的对应的方法,因此,其所能达到的有益效果可参考上文所提供的对应的方法中的有益效果,此处不再赘述。
以上所述,仅是本发明的较佳实施例而已,并非对本发明做任何形式上的限制,虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明,任何熟悉本专业的技术人员,在不脱离本发明技术方案范围内,当可利用上述揭示的技术内容做出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 语音唤醒方法、设备、存储介质及程序产品
- 智能设备、语音唤醒方法、语音唤醒装置及存储介质