面向大规模运动心率序列的代跑检测方法
文献发布时间:2023-06-19 11:05:16
技术领域
本发明涉及一种快速有效的、可并行化的、适用于大规模运动心率序列的自动化代跑检测方法。
背景技术
近年来国内学生整体的体质状况呈现下降的趋势。为改善学生体质,很多中学和高校陆续开始实行“阳光跑步”计划,要求学生开展课外锻炼。为了对学生课外健身跑的情况进行监督以保证学生确实是进行了有效的跑步锻炼,传统方法是规定学生在400米跑道跑步并有专门的监督人员来监督,或者是在校园内设置一些检查点,学生跑步通过这些检查点时以刷卡或者指纹识别的方式来进行身份识别,按时完成规定的行程,以此保证学生锻炼的质量。这些做法的局限性也是明显的:首先,这些传统方法都需要有专门的监督人员负责看管,耗费人力与财力;其次,由于专门人员的监管不是全天的,学生只能在特定的时间和地点进行跑步,无法选择自己最合适的锻炼时间和地点;最重要的是监管具有被动性,监管人员只能获取到每个学生抵达检查点的时间信息,而无法知道学生自身在期间是否真有跑步锻炼。
随着物联网可穿戴设备的发展,以上问题可以得到有效解决。采用运动心率腕表+互联网软件就是一种很好的解决方案,学生每跑步锻炼一次都会产生一条记录,相关管理人员只需要通过软件就能知道哪些当天是否有进行课外健身跑。通过这种方案,学生可以选择合适自己的时间和地点进行课外健身跑;此外,还可以减少监管上的人力投入。当然,这其中也存在一些关键的技术问题需要克服,最重要的就是由于缺少直接监督,可能会出现一人佩戴多个运动腕表替他人代跑的情形,这里称此为“多表代跑”。多表代跑给那些不想跑步锻炼的学生钻了空子,这种现象是违背“阳光跑步”计划的初衷的,为了尽量避免这种情况,非常需要一种合适的方案对其进行检测,进而达到有效的自动化监督,保证学生的课外锻炼质量。但是,一个学校往往都有成千甚至上万的学生,而每个学生每运动跑步一次都会产生一条运动跑步记录和运动心率序列,那么每天所产生的运动数据的规模也是较大的;再者,学生的运动心率序列具有非等长性。因此,从如此大规模的非等长运动心率序列中有效地检测出具有代跑嫌疑的序列对进而得到具有代跑嫌疑的学生是一件急需解决但又极具难度和挑战的问题。
从大规模的运动心率序列中检测出代跑序列对可以简单的视为时间序列相似度计算问题,即计算所有的运动心率序列的两两相似度,如果相似度很高则说明是代跑嫌疑序列对(因为同一个人戴多个运动腕表跑步运动时各个腕表所采集到的心率序列是极度相似的)。传统的曼哈顿距离、欧式距离和切比雪夫距离等相似性度量方法适合于计算等长序列的相似度,但是无法计算非等长时间序列的相似度,一种叫动态时间规整(Dynamic TimeWarping,简称DTW)的技术可以衡量计算非等长时间序列的相度,但是DTW的时间复杂度比传统的马哈顿距离和欧式距离高出一倍,即使是对DTW优化后的变种在处理大规模非等长时间序列时效率也并不乐观。因此,这种最简单暴力的方法仅适用于数据规模较小且时间序列较短的情况下,因为随着数据规模的增大,其所需要的计算量也几乎是指数级地暴增;另外一种方法是将其视为一个时间序列分类的问题,然后使用机器学习方法或深度学习的方法来解决。但是,不同于大多数学者所研究的对单条时间序列分类,代跑检测本质上是时间序列对的分类,因此,当前大多数学者所研究的对单条时间序列分类的方法并不能解决这里的代跑检测问题。本发明拟解决上述提及的如何有效地从大规模的运动心率序列中检测出代跑嫌疑序列对的问题。
发明内容
本发明要克服现有技术上的缺点,解决如何从大规模的运动心率序列中较为快速有效地检测识别出具有代跑(指上述提到的“多表代跑”)嫌疑的序列对的问题,提出一种面向大规模运动心率序列的运动代跑检测方法。
本发明方法具有如下特点:(1)高效、可并行化;(2)准确率较高;(3)适用于大规模时间序列对的分类。
由于本代跑检测方法是对数据库中的某一段时间(如一个学校一天当中所有的运动心率序列)的所有运动心率序列中检测识别出代跑嫌疑的序列对,因此,这里需要根据运动心率序列之间的运动时间上的重叠程度来对大规模的运动心率序列进行初步的分桶和过滤,以避免全局的两两比对,然后利用分而治之和并行计算的思想提高检测效率。
根据上述的问题和数据特点,本发明主要采用基于时间区间的运动序列分桶方法对大规模运动序列进行初步分桶和过滤;采用基于统计特征与时态特征相结合的方法来对运动心率序列对进行特征向量化表示;基于分治和并行化的思想加速代跑检测过程。基于这几项核心技术,本发明所提出的代跑检测方法具体方案步骤如下:
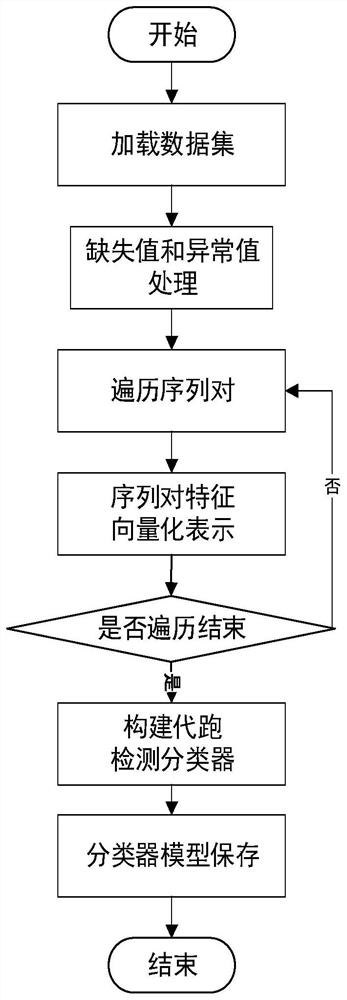
(1)构建代跑检测分类器,具体包含:
1.1)加载数据集D,数据集中的成员是带有标签的序列对,可表示为
1.2)遍历数据集中的每条运动心率序列,并对其进行如下缺失值和异常值的处理,其中缺失值用0表示:
1.2.1)记遍历到的当前运动心率序列为st,遍历st中的每一个心率点,如果当前被遍历到的心率点的值为0,那么就用该心率点前后各两个心率点的平均心率值代替该缺失值(若序列的第一个心率点为缺失值则仅取其后面两个心率点的平均心率值替代该缺失值,若序列的最后一个心率点为缺失值则仅取其前面两个心率点的平均心率值替代);
1.2.2)从st的第2个心率点遍历到倒数第2个心率点,记当前被遍历到的点心率值为HR
1.3)样本集F的生成。对数据集D'进行遍历,并对遍历到的每一个序列对进行如下步骤处理:
1.3.1)记当前被遍历到的序列对为
1.3.2)计算|f1-f2|,即可得到序列对的特征向量,记为X;
1.3.3)将X和序列对的标签lb组成二元组
1.4)将上一步得到的样本集F划分为训练集和测试集;
1.5)构建代跑检测分类器,并保存代跑检测分类器模型;
(2)检测代跑。从大规模运动心率序列中检测出代跑嫌疑序列对,包括如下步骤:
2.1)从数据库中加载某一天内的所有运动序列;
2.2)基于时间区间的运动心率序列分桶。基于时间区间的运动心率序列分桶流程包括如下子步骤:
2.2.1)将一天划分为24个时间区间tz,记为TZ=[tz1,tz2,......tz24],其中tz1所占时间区间为00:00:00至00:59:59、tz2所占时间区间为01:00:00至01:59:59,其余时间区间依次类推;然后初始化24个数据桶(每个时间区间对应一个数据桶)记为B={b1,b2......b24},其中每个bucket中的元素均为运动心率序列;
2.2.2)遍历所加载的这一天内的所有运动心率序列;记当前所遍历到的运动心率序列为st0,如果st0的startTime和endTime均落在同一个时间区间tz中,那么就将该运动序列分配到相应的数据桶中;如果startTime与endTime不落在同一个时间区间tz中,比如startTime落在tz1中,endTime落在tz2中,那么就将该运动序列同时分配到tz1和tz2所对应的数据桶中。
2.3)过滤掉无意义的数据桶。遍历数据桶集合B,并判断每个被遍历到的数据桶的大小(即包含的元素个数),如果小于2则将该数据桶从B中删除;
2.4)并行化处理B中的各个数据桶,生成每个数据桶所对应的子预测样本集。其中并行化处理的流程包括如下子步骤:
2.4.1)运动心率序列数据桶转换成运动心率序列对数据桶。即将bucket中的运动心率序列进行两两组合,转换成运动序列对数据桶。例如,记当前被处理的数据桶b={st1,st2,st3},则经过转化后得到的运动心率序列对数据桶为b
2.4.2)遍历运动序列对数据桶b
2.5)将并行化处理所生成的所有子预测样本集归并,并记为预测样本集Y(Y为心率序列对所对应的特征表示向量的集合);
2.6)使用代跑分类器构建步骤所保存好的代跑检测分类器模型对预测样本集Y中的元素进行二分类(即分类为“代跑”和“非代跑”),最终得到代跑嫌疑序列对;
本发明方法主要可以分为两大步骤:步骤(1)的工作是构建代跑检测分类器,本步骤首先对预先准备好的带标签数据集进行预处理(包括缺失值和异常值的处理),然后将每个心率序列对进行特征向量化表示,进一步得到构建代跑检测分类器所需的样本集,最后构建代跑检测分类器,并将构建好的代跑分类器模型其保存;步骤(2)进行代跑检测,该步骤首先基于时间区间的运动心率序列分桶方法将大规模的运动心率序列进行初步的分桶和过滤,然后并行化处理各个数据桶以生成子预测样本集,接着归并前面并行处理所得到的所有子预测样本集,并将其记为预测样本集,最后使用代跑检测分类器构建步骤所得到的代跑检测分类器对预测样本集中的样本进行是否为代跑的二分类,从而检测识别出代跑嫌疑序列对。本发明使用基于时间区间的大规模运动序列分桶方法和并行化处理来提高代跑检测的效率;使用基于统计特征和时态特征相结合的方法来有效表示运动心率序列对,不仅能够起到降维和降噪的效果,还能减少分类器训练和预测过程的计算量,更能解决运动心率序列的非等长问题。
本发明的优点是:能够从大规模的运动心率序列中较为高效、准确地检测识别出具有代跑嫌疑的运动心率序列对。
附图说明
图1是本发明方法中代跑检测分类器构建流程图。
图2是本发明中代跑检测流程图。
具体实施方式
下面结合附图,对本发明的面向大规模运动心率序列的代跑检测方法作进一步详细说明。
参照图1和图2,一次代跑检测任务需要在计算中执行如下步骤:
(1)加载数据集D,数据集中的成员是带有标签的序列对,可表示为
表1
(2)遍历数据集中的每条运动心率序列,并对其进行如下缺失值和异常值的处理,其中缺失值用0表示:
2.1)记遍历到的当前运动心率序列为st,遍历st中的每一个心率点,如果当前被遍历到的心率点的值为0,那么就用该心率点前后各两个心率点的平均心率值代替该缺失值(若序列的第一个心率点为缺失值则仅取其后面两个心率点的平均心率值替代该缺失值,若序列的最后一个心率点为缺失值则仅取其前面两个心率点的平均心率值替代);
2.2)从st的第2个心率点遍历到倒数第2个心率点,记当前被遍历到的点心率值为HR
(3)样本集F的生成。对数据集D'进行遍历,并对遍历到的每一个序列对进行如下步骤处理:
3.1)记当前被遍历到的序列对为
表2
其中用于表征平均值附近的不对称度HR_SKEW的计算公式为
3.2)计算|f1-f2|,即可得到序列对的特征向量,记为X;
3.3)将X和序列对的标签lb组成二元组
(4)将上一步得到的样本集F划分为训练集和测试集;
(5)构建代跑检测分类器,并保存代跑检测分类器模型;
(6)从数据库中加载某一天内的所有运动序列;
(7)基于时间区间的运动序列分桶。基于时间区间的运动序列分桶需要在计算机中执行如下子步骤:
7.1)将一天划分为24个时间区间tz,记为TZ=[tz1,tz2,......tz24],其中tz1所占时间区间为00:00:00至00:59:59、tz2所占时间区间为01:00:00至01:59:59,其余时间区间依次类推;然后初始化24个数据桶(每个时间区间对应一个数据桶)记为B={b1,b2......b24},其中每个数据桶bucket中的元素均为运动心率序列;
7.2)遍历所加载的这一天内的所有运动心率序列;记当前所遍历到运动序列为st0,如果st0的startTime和endTime均落在同一个时间区间tz中,那么就将该运动心率序列分配到对应的bucket中;如果startTime0与endTime0不落在同一个时间区间tz中,比如startTime落在tz1中,endTime落在tz2中,那么就将该运动心率序列同时分配到tz1和tz2所对应的数据桶中。
(8)过滤掉无意义的数据桶。遍历数据桶集合B,并判断每个被遍历到的bucket的大小(即包含的元素个数),如果小于2则将该bucket从B中删除;
(9)并行化处理B中的各个bucket,生成每个bucket所对应的子预测样本集。其中并行化处理的执行流程包括如下子步骤:
9.1)运动心率序列数据桶转换成运动心率序列对数据桶。即将bucket中的运动序列进行两两组合,转换成运动序列对数据桶。例如,记当前被处理的数据桶b={stl,st2,st3},则经过转化后得到的运动序列对数据桶为b
9.2)遍历运动心率序列对数据桶b
(10)将并行化处理所生成的所有子预测样本集归并,并记为预测样本集Y(Y为心率序列对所对应的特征表示向量的集合);
(11)使用步骤(5)中构建好的代跑检测分类器模型对预测样本集Y中的元素进行二分类(即分类为“代跑”和“非代跑”),最终得到代跑嫌疑序列对;
通过上述步骤即可实现从大规模的运动心率序列中较为快速准确地、全自动化地检测出代跑嫌疑运动心率序列对。
本发明的步骤2.2)和2.3),提出基于时间区间划分及根据运动序列的开始时间和结束时间来将大规模的运动序列分配到若干个数据桶中,然后初步过滤掉无意义的数据桶,从而大大减少代跑检测时的计算量;步骤2.4)采用分治和并行化的思想来处理运动序列数据桶,进而大大地提高代跑检测的效率,并充分利用了分布式并行处理的优势;步骤1.3)通过计算一对心率序列对的两条心率序列各自的统计特征和时态特征而得到两条序列各自的特征向量,然后对这两条序列的特征向量作绝对差,得到的结果即为该序列对的特征向量表示,该序列对表示方法不仅能有效表示运动心率序列对,同时还能适用于非等长运动心率序列,更能减少运动心率序列的噪声给代跑检测结果所带来的负面影响。
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围不应当被视为仅限于实施例所陈述的具体形式,其中各步骤可以有所变化,凡是在本发明技术方案的基础上进行的等同变换和改进,均不应排除在本发明的保护范围之外。
- 面向大规模运动心率序列的代跑检测方法
- 面向大规模高维序列数据的交互特征并行选择方法