神经网络模型的训练装置和训练方法
文献发布时间:2023-06-19 11:14:36
技术领域
本公开是有关于一种神经网络模型的训练装置和训练方法。
背景技术
在产业应用人工智能进行自动光学检测(automated optical inspection,AOI)时,往往会因为训练数据中的瑕疵影像数量远小于正常影像数量而导致所训练出的神经网络的效能不佳。另一方面,当存在多个类别的瑕疵时,每种瑕疵影像的数量分布极不均衡也会导致所训练出的神经网络无法准确地辨识出各个类别的瑕疵。
现行神经网络的训练方法往往只依照单一限制条件来筛选适当的模型,例如,根据对应于验证数据集合(validation set)的最小错误率(error rate)来决定最佳的神经网络模型。这种训练方法并无法有效地解决上述之议题。据此,提出一种能从众多神经网络模型中筛选出最适当之神经网络模型的方法,是本领域人员致力的目标之一。
公开内容
本公开提出一种神经网络的训练装置和训练方法,可在训练数据集合中各类瑕疵影像的数量分布极不均衡时,通过多重限制条件筛选出最适合(例如:对各类别瑕疵之辨识的平均效能为最佳的)之模型以作为最终被使用的神经网络模型。
本公开的神经网络模型的训练装置,包括处理器、储存媒体以及收发器。储存媒体储存多个模块。处理器耦接储存媒体和收发器,并且存取和执行多个模块,其中多个模块包括数据收集模块以及训练模块。数据收集模块通过收发器取得数据集合。训练模块根据数据集合完成多次人工智能模型训练以产生分别对应于多次人工智能模型训练的多个模型,根据第一限制条件从多个模型中选出第一模型集合,并且根据第二限制条件从第一模型集合中选出神经网络模型。
本公开的神经网络模型的训练方法,包括:取得数据集合;根据数据集合完成多次人工智能模型训练以产生分别对应于多次人工智能模型训练的多个模型;根据第一限制条件从多个模型中选出第一模型集合;以及根据第二限制条件从第一模型集合中选出神经网络模型。
基于上述,当数据集各类影像的数量分布极不均衡时,通过本公开提出的多重限制条件筛选方法所筛选出的模型的辨识效能将比仅依照单一限制条件筛选而得到模型的辨识效能为佳。
附图说明
图1为根据本公开的一实施例绘示神经网络模型的训练装置的示意图。
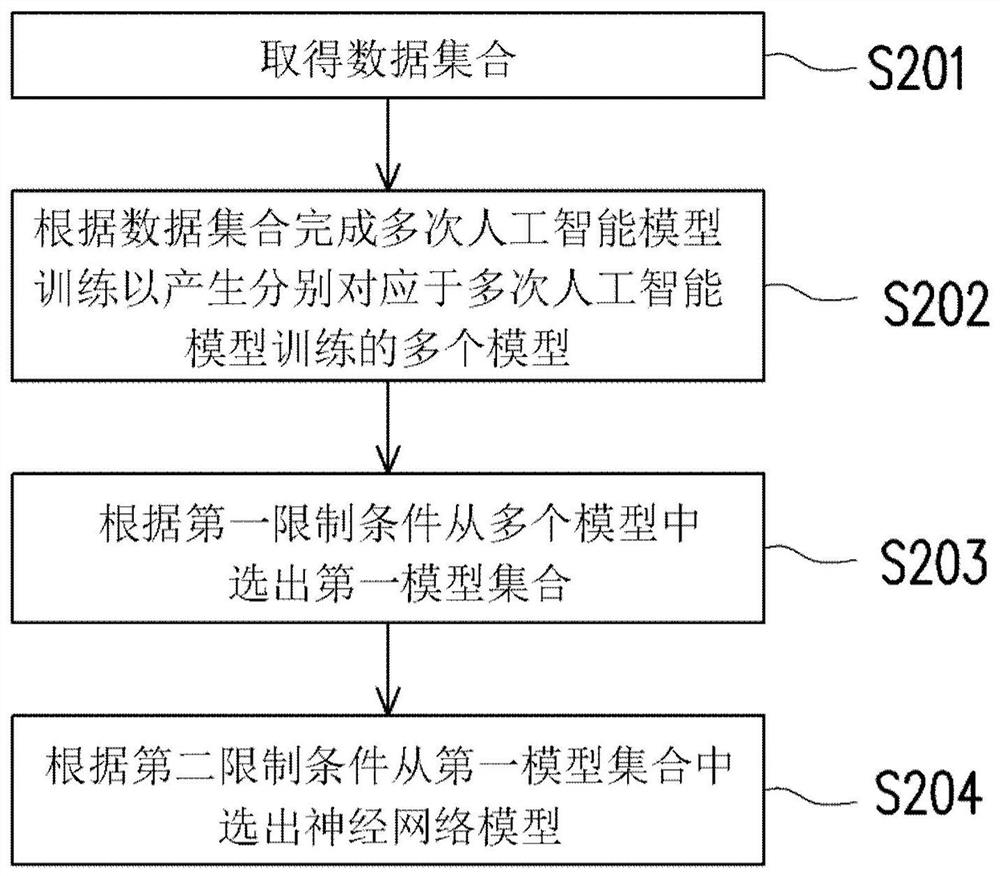
图2为根据本公开的一实施例绘示神经网络模型的训练方法的流程图。
附图标记说明
100:训练装置
110:处理器
120:储存媒体
121:数据收集模块
122:训练模块
130:收发器
140:图形用户界面
S201、S202、S203、S204:步骤
具体实施方式
为使本公开的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本公开进一步详细说明。
现将详细参考本公开的实施例,并在图式中说明所述实施例的实例。另外,凡可能之处,在图式及实施方式中使用相同标号的组件/构件代表相同或类似部分。
本公开提出一种神经网络的训练装置和训练方法,可在训练数据集合中各类瑕疵影像的数量分布极不均衡时,通过多重限制条件筛选出最适合(例如:对各类别瑕疵的辨识的平均效能为最佳的)的模型以作为最终被使用的神经网络模型。
图1为根据本公开的一实施例绘示神经网络模型的训练装置100的示意图。训练装置100可包括处理器110、储存媒体120以及收发器130。在一实施例中,训练装置100还包括图形用户界面140。
处理器110耦接储存媒体120和收发器130,并可用于存取和执行储存于储存媒体120中的多个模块。处理器110例如是中央处理单元(central processing unit,CPU),或是其他可程序化之一般用途或特殊用途的微控制单元(micro control unit,MCU)、微处理器(microprocessor)、数字信号处理器(digital signal processor,DSP)、可程序化控制器、特殊应用集成电路(application specific integrated circuit,ASIC)、图形处理器(graphics processing unit,GPU)、算数逻辑单元(arithmetic logic unit,ALU)、复杂可程序逻辑装置(complex programmable logic device,CPLD)、现场可程序化逻辑门阵列(field programmable gate array,FPGA)或其他类似组件或上述组件的组合。
储存媒体120例如是任何型态的固定式或可移动式的随机存取内存(randomaccess memory,RAM)、只读存储器(read-only memory,ROM)、闪存(flash memory)、硬盘(hard disk drive,HDD)、缓存器(register)、固态硬盘(solid state drive,SSD)或类似组件或上述组件的组合,而用于储存可由处理器110执行的多个模块或各种应用程序。在本实施例中,储存媒体120可储存包括数据收集模块121以及训练模块122等多个模块,其功能将于后续说明。
收发器130以无线或有线的方式传送及接收讯号。收发器130还可以执行例如低噪声放大、阻抗匹配、混频、向上或向下频率转换、滤波、放大以及类似的操作。
图形用户界面140是自用户接收操作并且产生对应于所述操作的命令的输入设备。在产生命令后,图形用户界面140可传送命令至处理器110。
在本实施例中,数据收集模块121可通过收发器130取得用以训练神经网络模型的数据集合。在取得数据集合后,训练模块122可根据数据集合完成多次人工智能模型训练,其中一次人工智能模型训练例如是代表训练人工智能模型的过程中的一次迭代(iteration)。具体来说,训练模块122可将数据集合作为训练数据,以根据神经网络算法(或机器学习算法)和训练数据完成一次又一次的迭代,从而使得每一次迭代的输出往一目标函数逐渐收敛。当每完成一次迭代时,训练模块122将可产生对应于该次迭代的模型。举例来说,若训练模块122将由数据收集模块121取得的数据集合作为训练数据并根据训练数据以及神经网络算法完成了10^6次的迭代,则训练模块122将会产生分别对应于每一次迭代的10^6个模型。训练模块122可从这些模型(即:10^6个模型)之中选出效能最佳(例如:具有最小的错误率)的模型以作为神经网络模型。在一实施例中,训练模块122可通过收发器130将该神经网络模型输出以供用户利用该神经网络模型进行对象辨识。
举例来说,训练模块122所输出的神经网络模型可用以辨识印刷电路板(printedwire board,PCB)或半导体制造晶圆(例如:动态随机存取内存(dynamic random accessmemory,DRAM))的外观瑕疵。据此,作为训练数据的数据集合可例如是由自动光学检测(automated optical inspection,AOI)设备取得的待检测之DRAM或品圆之外观的影像数据,或是由自动外观检测(automated visual inspection,AVI)设备取得的印刷电路板之外观的影像数据,本公开不限于此。另一方面,上述的神经网络模型包括例如是自编码(autoencoder)神经网络、深度学习(deep learning)神经网络、深度残差学习(deepresidual learning)神经网络、受限玻尔兹曼机(Boltzmann machine,RBM)神经网络、递归神经网络(recursive neural network)或多层感知器(multilayer perceptron,MLP)神经网络等,本公开不限于此。
训练模块122可通过多个限制条件来从分别对应于每一次迭代的多个模型之中选出特定模型以作为神经网络模型。在一实施例中,训练模块122可根据两种限制条件(以下称之为“限制条件A”和“限制条件B”)来选择作为神经网络模型的模型。具体来说,训练模块122可根据限制条件A(或称之为“第一限制条件”)从分别对应于每一次迭代的多个模型之中选出第一模型集合,其中第一模型集合包括一或多个符合限制条件A的第一模型。接着,训练模块122可根据限制条件B从第一模型集合中选出符合限制条件A和限制条件B(或称之为“第二限制条件”)的特定模型以作为最终被使用的神经网络模型,其中上述的限制条件A和限制条件B例如关联于下列的至少其中之一:真阴性率(true negative rate,TNR)、真阳性率(true positive rate,TPR)、伪阴性率(false negative rate,FNR)、伪阳性率(falsepositive rate,FPR)、最小错误率(minimum error rate)、平均错误率(average errorrate)、召回率(recall rate)或准确性(accuracy),但本公开不限于此。举例来说,限制条件A和限制条件B可关联于与混淆矩阵(confusion matrix)相关的任一种指标。
由于符合限制条件A的模型可能有多个,因此,由训练模块122根据限制条件A选出的第一模型集合包括多个符合限制条件A的第一模型。为了找出最佳的模型以作为最终被使用的神经网络模型,在一实施例中,训练模块122可根据限制条件B而从第一模型集合(即:符合限制条件A的模型的集合)中选出对应于目标条件的特定模型以作为最终被使用的神经网络模型。举例来说,假设目标函数为TNR,则训练模块122可从第一模型集合中选出具有最大的TNR的特定模型以作为最终被使用的神经网络模型。
在另一实施例中,训练模块122可根据限制条件B而从第一模型集合(即:符合限制条件A的模型的集合)中选出与符合限制条件B的最后一次的迭代相对应的模型以作为最终被使用的神经网络模型。举例来说,假设第一模型集合包括对应于第10^4次迭代的模型X、对应于第10^5次迭代的模型Y以及对应于第10^6次迭代的模型Z,则训练模块122可响应于模型Z对应于最后一次的迭代而选择模型Z以作为最终使用的神经网络模型。
训练装置100还可以根据超过两种限制条件来训练神经网络模型。在一实施例中,训练模块122可根据三种限制条件(以下称之为“限制条件X”、“限制条件Y”和“限制条件Z”)来选择作为神经网络模型的模型。具体来说,训练模块122可根据限制条件X(或称之为“第一限制条件”)从分别对应于每一次迭代的多个模型之中选出第一模型集合,其中第一模型集合包括一或多个符合限制条件X的第一模型。接着,训练模块122可根据限制条件Y(或称之为“第三限制条件”)从第一模型集合中选出第二模型集合,其中第二模型集合包括一或多个符合限制条件X和限制条件Y的第二模型。最后,训练模块122可根据限制条件Z(或称之为“第二限制条件”)从第二模型集合中选出符合限制条件X、限制条件Y和限制条件Z的特定模型以作为最终被使用的神经网络模型。
训练模块122用来筛选模型所使用的限制条件类别和限制条件数量可根据使用者的需求而调整,本公开不限于此。
在一实施例中,数据收集模块121通过收发器130取得关联于PCB的外观的影像数据集合,并且训练模块122根据影像数据集合来训练出可用于辨识PCB之焊接瑕疵的神经网络模型。表1显示上述的关联于PCB的外观的影像数据集合中的焊接瑕疵样本和正常样本的数量。
表1
由表1可知,PCB外观的影像数据集合中对应于焊接瑕疵的样本远少于正常的样本。如此,若根据传统的神经网络训练方法,即以单一限制条件来训练神经网络模型,所训练出的神经网络模型的效能可能不均衡。举例来说,表2和表3显示基于单一种限制条件“最小错误率”而根据表1的训练数据所训练出的神经网络模型的效能。当用户使用如表1所示的验证数据来验证该神经网络模型时,该神经网络模型的效能如表2所示。当用户使用如表1所示的测试数据来测试该神经网络模型时,则该神经网络模型的效能如表3所示。
表2
表3
一般来说,TNR的值越高代表神经网络模型的效能越高,并且FNR的值越低代表神经网络模型的效能越高。如表2和表3所示,基于单一限制条件“最小错误率”以及表1的训练数据所训练的神经网络模型的TNR可能达到100%,但相对地,该神经网络模型的FNR可能达到40%。换句话说,该神经网络模型的TNR表现极佳,但该神经网络模型的FNR表现极差。因此,该神经网络模型对TNR和FNR的表现并不均衡。
在一实施例中,若瑕疵样本(例如:焊接瑕疵样本)和正常样本的数量分布差异过大,即,瑕疵样本的数量远少于正常样本的数量,则数据收集模块121可对由数据收集模块121所收集的数据集合(包括瑕疵样本和正常样本)中的瑕疵样本进行前处理,例如:过采样(over-sampling)、数据合成、SMOTE(synthetic minority oversampling technique)、随机抽样或数据扩增等方式增加训练数据量,以根据过采样后的瑕疵样本和正常样本产生更新的数据集合。具体来说,数据收集模块121可响应于瑕疵样本和正常样本的比率小于阈值而对瑕疵样本的训练数据进行过采样,从而产生更新的数据集合。训练模块122可根据更新的数据集合训练神经网络模型。表4和表5显示对表1的焊接瑕疵样本进行过采样后,基于单一种限制条件“最小错误率”而根据如表1所示的训练数据所训练出的神经网络模型的效能。
表4
表5
如表4和表5所示,过采样的技术虽然有效地降低了FNR,但却使得总体准确率(overall accuracy)下降并使得总体错误率(overall error rate)升高。
为了改善神经网络模型的整体效能(例如包括:总体准确率、总体错误率、FNR和TNR),本公开提出的训练装置100可选择性地对数据集合中的瑕疵样本进行前处理,所述前处理例如包括:过采样、数据合成、SMOTE、随机抽样或数据扩增。而后,训练装置100可根据多个限制条件选择出能改善整体效能的神经网络模型。在本实施例中,所述多个限制条件可包括限制条件α(或称之为“第一限制条件”)和限制条件β(或称之为“第三限制条件”)。在一实施例中,所述多个限制条件还可包括限制条件γ(或称之为“第二限制条件”)。
限制条件α为“TNR大于95%”,并且限制条件β为“FNR的值为最小”。举例来说,训练模块122可根据限制条件α从分别对应于每一次迭代的多个模型中选出第一模型集合,其中第一模型集合是由TNR大于95%的多个模型所组成。接着,训练模块122可根据限制条件β从第一模型集合(即:该些符合限制条件A的多个模型)中选出具有最小的FNR的模型以作为最终被使用的神经网络模型。
由于符合限制条件α和限制条件β的模型可能有多个,因此,由训练模块122根据限制条件β从第一模型集合选出的第二模型集合可包括多个符合限制条件α(即:TNR大于95%)以及限制条件β(即:具有最小的FNR)的第二模型。为了找出最佳的模型以作为最终被使用的神经网络模型,训练模块122可进一步地根据另一个限制条件来对第二模型集合中的模型进行筛选以找出最终被使用的神经网络模型。在一实施例中,训练模块122可根据限制条件γ或一目标条件而从第二模型集合(即:符合限制条件α和限制条件β的模型的集合)中选出对应于限制条件γ或目标条件的特定模型以作为最终被使用的神经网络模型。举例来说,假设目标条件为TNR,则训练模块122可从第二模型集合中选出具有最大的TNR的特定模型以作为最终被使用的神经网络模型,且该神经网络模型的效能可如表6和表7所示。
表6
表7
如表6和表7所示,基于多个限制条件(即:限制条件α“TNR大于95%”、限制条件β“具有最小的FNR”以及限制条件γ“具有最大的TNR”)所取得的神经网络模型的TNR虽然稍微减少了(相较于表2和表3而言),但该神经网络模型的FNR却显著地下降,且总体准确率和总体错误率的表现也十分的优异。换言之,本公开的训练装置100所训练出的神经网络模型可通过牺牲极少的TNR来达到最佳的FNR、总体准确率和总体错误率。
在另一实施例中,训练模块122可根据限制条件γ而从第二模型集合(即:符合限制条件α和限制条件β的模型的集合)中选出与符合限制条件γ的迭代中的的最后一次迭代相对应的模型以作为最终被使用的神经网络模型。举例来说,假设第二模型集合包括对应于第10^4次迭代的模型I、对应于第10^5次迭代的模型J以及对应于第10^6次迭代的模型K,则训练模块可响应于模型K对应于最后一次的迭代而选择模型K以作为最终使用的神经网络模型。
在一实施例中,数据收集模块121通过收发器130取得关联于PCB之外观的影像数据集合,并且训练模块122根据影像数据集合来训练出可用于辨识PCB之外观瑕疵类别的神经网络模型。表8显示上述的关联于PCB之外观的影像数据集合中的各类型瑕疵之样本的数量,其中所述各类型瑕疵可关联于例如防焊(solder mask,S/M)杂质(inclusion)、防焊刮伤(scratch of S/M)、防焊污染(pollution of S/M)、防焊露铜(copper exposure ofS/M)、防焊油墨不均(uneven printing ofS/M)、防焊跳印(skip printing ofS/M)、显影不良(poor developing)、防焊板损(board damage ofS/M)、防焊沾锡(wetting of S/M)、焊垫有机保焊膜(organic solderability preservative,OSP)杂质、焊垫有机保焊膜氧化(oxidation of S/M OSP)、焊垫镀金层污染(pollution ofPAD gold plating)、焊垫镀金层氧化(oxidation of PAD gold plating)、焊垫镀金层露铜(cooper exposure of PADgold plating)、文字模糊(blur text)或焊垫沾锡(wetting of PAD),但本公开不限于此。
表8
表9显示对表8中样本数量较少的瑕疵类别进行过采样后,基于单一种限制条件“最小错误率”而根据表8的训练数据所训练出的神经网络模型的效能。如表9所示,对应表9的神经网络模型的平均误差偏高(超过5%),且错误率超过10%的瑕疵类别的数量偏多(超过4种瑕疵类别)。
表9
为了改善神经网络模型的整体效能(例如:降低平均误差和错误率超过10%的瑕疵类别的数量),本公开提出的训练装置100可选择性地对数据集合中的瑕疵样本进行过采样。而后,训练装置100可根据多个限制条件选择出能改善整体效能的神经网络模型。在本实施例中,所述多个限制条件包括限制条件α和限制条件β,其中限制条件α为“总体准确率大于95%”,并且限制条件β为“平均误差为最小”。举例来说,训练模块122可根据限制条件α从分别对应于每一次迭代的多个模型中选出第一模型集合,其中第一模型集合是由总体准确率大于95%的多个模型所组成。接着,训练模块122可根据限制条件β从第一模型集合(即:该些符合限制条件α的多个模型)中选出具有最小的平均误差的模型以作为最终被使用的神经网络模型。由于符合限制条件β的模型可能有多个,因此,由训练模块122根据限制条件β从第一模型集合选出第二模型集合可包括多个符合限制条件α(即:总体准确率大于95%)以及限制条件β(即:具有最小的平均误差)的模型。
为了找出最佳的特定模型,训练模块122可进一步地根据限制条件γ来对第二模型集合中的模型进行筛选。在一实施例中,训练模块122可根据限制条件γ而从第二模型集合中选出对应于目标条件的特定模型以作为最终被使用的神经网络模型。举例来说,假设目标条件为总体准确率,则训练模块122可从第二模型集合中选出具有最大的总体准确率的特定模型以作为最终被使用的神经网络模型,且该神经网络模型的效能如表10所示。由表10可知,“平均误差”和“错误率超过10%的瑕疵类别的数量”等指标都被改善了。
表10
在一实施例中,数据收集模块121通过收发器130取得关联于DRAM之外观的影像数据集合,并且训练模块122根据影像数据集合来训练出可用于辨识DRAM之外观瑕疵类别的神经网络模型。表11、表12和表13显示上述的关联于DRAM之外观的影像数据集合中的各类型瑕疵的样本的数量,其中所述各类型瑕疵可关联于例如刮伤(scratch)、箭影(arrow)、微粒(particle)或变色(discolor),但本公开不限于此。
表11
表12
表13
表14显示基于单一种限制条件“最小错误率”而根据表13的训练数据所训练出的神经网络模型的效能。如表14所示,对应表13的神经网络模型在辨识刮伤或箭影时的错误率都偏高。
表14
为了改善神经网络模型的整体效能(例如:辨识刮伤或箭影的错误率),本公开提出的训练装置100可选择性地对数据集合中的瑕疵样本进行过采样。而后,训练装置100可根据多个限制条件选择出能改善整体效能的神经网络模型。由于对DRAM的5种瑕疵而言,刮伤和箭影是最影响DRAM质量的瑕疵类别,因此在设定神经网络模型的筛选限制条件时,训练模块121可将限制条件(或目标条件)设为与特定类别的瑕疵(例如:刮伤或箭影)有关,且单一个限制条件可关联于多个瑕疵类别。
在本实施例中,限制条件α为“总体准确率大于95%”,并且限制条件β为“刮伤和箭影的错误率为最小”。举例来说,训练模块122可根据限制条件α从分别对应于每一次迭代的多个模型中选出第一模型集合,其中第一模型集合是由总体准确率大于95%的多个模型所组成。接着,训练模块122可根据限制条件β从第一模型集合(即:该些符合限制条件β的多个模型)中选出具有最小的刮伤错误率和箭影错误率的模型以作为最终被使用的神经网络模型。由于符合限制条件β的模型可能有多个,因此,由训练模块122根据限制条件β从第一模型集合选出第二模型集合可包括符合限制条件α(即:总体准确率大于95%)以及限制条件β(即:具有最小的刮伤错误率和箭影错误率)的多个模型。为了找出最佳的特定模型,训练模块122可进一步地根据限制条件γ来对第二模型集合中的模型进行筛选。
在一实施例中,训练模块122可根据限制条件γ而从第二模型集合中选出对应于目标条件的特定模型以作为最终被使用的神经网络模型。举例来说,假设目标函数为总体准确率,则训练模块122可从第二模型集合中选出具有最大的总体准确率的特定模型以作为最终被使用的神经网络模型,且该神经网络模型的效能如表15所示。
表15
如表14和表15所示,相较于根据单一种限制条件所训练出的神经网络模型,根据多种限制条件所训练出的神经网络模型显著地改善了总体错误率、对刮伤类别的错误率以及对箭影类别的错误率。
图2为根据本公开的一实施例绘示神经网络模型的训练方法的流程图,其中该训练方法可由如图1所示的训练装置100实施。在步骤S201,取得数据集合。在步骤S202,根据数据集合完成多次人工智能模型训练以产生分别对应于多次人工智能模型训练的多个模型。在步骤S203,根据第一限制条件从多个模型中选出第一模型集合。在步骤S204,根据第二限制条件从第一模型集合中选出神经网络模型。
在一实施例中,本公开中提到的任何限制条件可由外部电子装置所产生。处理器110可通过收发器130以从外部电子装置取得限制条件。
在一实施例中,本公开中提到的任何限制条件可由用户的操作而产生。举例来说,用户可在图形用户界面140上进行操作,并且图形用户界面140可产生与所述操作相对应的限制条件。在产生限制条件后,图形用户界面140可将所述限制条件传送至处理器110。
综上所述,本公开的训练装置可利用多种限制条件来从分别对应于多个迭代的多个模型之中,选出能满足应用需求及改善辨识效能的各种指标(例如:与混淆矩阵相关的任一种指针)的模型以作为最终被使用的神经网络模型。
以上所述的具体实施例,对本公开的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本公开的具体实施例而已,并不用于限制本公开,凡在本公开的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。
- 神经网络模型的训练装置和训练方法
- 适配训练设备资源的神经网络模型训练方法及装置