一种联邦学习的虚拟化共享模型传输方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明涉及一种模型传输方法,尤其是涉及一种联邦学习的虚拟化共享模型传输方法。
背景技术
当今的AI仍然面临两个主要挑战。一是在大多数行业中,数据以孤立的孤岛形式存在。另一个是加强数据隐私和安全性。因此为这些挑战提出了一种可能的解决方案:安全的联邦学习。联邦学习是多个实体(客户端)协作解决机器学习问题的机器学习设置,它在一个中央服务器或服务提供商的协调下进行。每个客户端的原始数据存储在本地,无法交换或迁移,联邦学习利用局部更新(用于立即聚合(immediate aggregation))来实现学习目标。局部更新(focused update)是仅限于包含特定学习任务最少必需信息的更新。聚合应在数据最小化服务中尽可能早地执行。
联邦学习框架,其中包括横向联邦学习,纵向联邦学习和联邦迁移学习。联邦学习数学定义:定义N个数据所有者{F1,...FN},他们所有人都希望通过合并各自的数据{D1,...DN}来训练机器学习模型。一种常规方法是将所有数据放在一起,并使用D=D1 UD2 U...DN来训练模型Msum。联邦学习是一种学习过程,其中数据所有者共同训练一个模型Mfed,在该过程中,任何数据所有者Fi都不会将其数据Di暴露给其他人。
隐私是联邦学习的基本属性之一。这就需要安全模型和分析来提供有意义的隐私保证。
安全多方计算(SMC)。SMC安全模型自然包含多个参与方,并在定义明确的仿真框架中提供安全证明,以确保完全零知识,也就是说,每个参与方除了其输入和输出外一无所知。零知识是非常需要的,但是这种期望的属性通常需要复杂的计算协议,并且可能无法有效实现。在某些情况下,如果提供了安全保证,则可以认为部分知识公开是可以接受的。可以在较低的安全性要求下用SMC建立安全性模型,以换取效率。
差异隐私。另一种工作方式是使用差分隐私或k-匿名技术保护数据隐私。差异隐私,k匿名和多样化的方法涉及给数据添加噪声,或者使用归纳方法掩盖某些敏感属性,直到第三方无法区分个人为止,从而使数据无法恢复以保护用户隐私。但是,这些方法的根源仍然要求将数据传输到其他地方,并且这些工作通常需要在准确性和隐私之间进行权衡。
同态加密。在机器学习过程中,还采用同态加密来通过加密机制下的参数交换来保护用户数据隐私。与差异隐私保护不同,数据和模型本身不会被传输,也不会被对方的数据猜中。最近的工作采用同态加密来集中和训练云上的数据。
作为一种创新的建模机制,它可以针对来自多方的数据训练统一模型而又不损害这些数据的隐私和安全性,因此联邦学习在销售,金融和许多其他行业中很有前途的应用,在这些行业中,不能直接聚合数据进行训练由于诸如知识产权,隐私保护和数据安全之类的因素而导致的机器学习模型。
以智能零售为例。其目的是使用机器学习技术为客户提供个性化服务,主要包括产品推荐和销售服务。
智能零售业务涉及的数据特征主要包括用户购买力,用户个人喜好和产品特征。在实际应用中,这三个数据特征可能分散在三个不同的部门或企业中。例如,用户的购买力可以从她的银行储蓄中推断出来,而她的个人喜好可以从她的社交网络中进行分析,而产品的特征则由电子商店来记录。
在这种情况下,我们面临两个问题。首先,为了保护数据隐私和数据安全,很难打破银行,社交网站和电子购物网站之间的数据障碍。结果,数据不能直接聚合以训练模型。其次,存储在三方中的数据通常是异构的,并且传统的机器学习模型无法直接在异构数据上工作。目前,这些问题尚未通过传统的机器学习方法得到有效解决,这阻碍了人工智能在更多领域的普及和应用。
联邦学习和迁移学习是解决这些问题的关键。首先,通过利用联邦学习的特征,我们可以为三方构建机器学习模型而无需导出企业数据,不仅可以充分保护数据隐私和数据安全,还可以为客户提供个性化和针对性的服务,从而实现互惠互利。同时,我们可以利用迁移学习来解决数据异质性问题,并突破传统人工智能技术的局限性。因此,联合学习为我们构建大数据和人工智能的跨企业,跨数据和跨域生态圈提供了良好的技术支持。
发明内容
本发明提供了一种联邦学习的虚拟化共享模型传输方法,解决了训练数据通过虚拟化共享模型实现联邦学习的问题,其技术方案如下所述:
一种联邦学习的虚拟化共享模型传输方法,包括以下步骤:
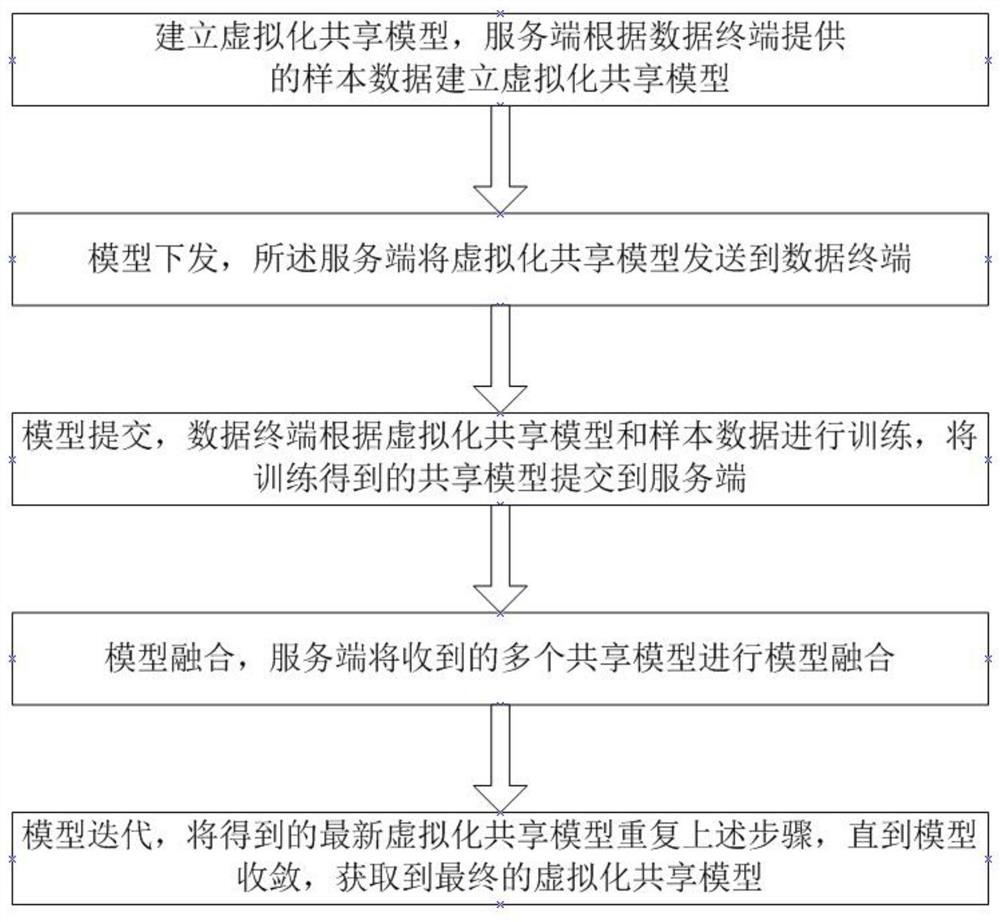
S1:建立虚拟化共享模型:第一终端和第二终端选择都信任的同一服务端,所述服务端接收第一终端发送的第一样本数据,以及第二终端发送的第二样本数据,所述服务端根据第一样本数据和第二样本数据建立虚拟化共享模型;
S2:模型下发:所述服务端将虚拟化共享模型发送到第一终端,确认第一终端收到后,所述服务端将虚拟化共享模型发送到第二终端,并确认第一终端收到;
S3:模型提交:所述第一终端和第二终端都接受虚拟化共享模型后,所述第一终端根据虚拟化共享模型和第一样本数据进行训练,获取第一共享模型,并提交到服务端;所述第二终端根据虚拟化共享模型和第二样本数据进行训练,获取第二共享模型,并提交到服务端;
S4:模型融合:服务端根据收到的第一共享模型和第二共享模型,进行模型融合,融合成最新虚拟化共享模型;
S5:模型迭代:将最新虚拟化共享模型重复步骤S2-S4,多次迭代下,直到模型收敛,获取到最终的虚拟化共享模型。
进一步的,步骤S1中,所述虚拟化共享模型根据第一样本数据与第二样本数据的交集特征,以及第一样本数据与第二样本数据的映射规则得到。
所述服务端每次依次接收第一终端和第二终端的数据,以及每次依次发送数据到第一终端和第二终端,由第一终端和第二终端全部确认后执行,确认方法通过组合密码实现,初始时第一终端和第二终端分别获取到服务端下发的组合密码的一半,在接收和发送时,第一终端和第二终端都需要向服务端输入密码,完成密码确认,服务官再进行下一步动作。
进一步的,步骤S3中,第一终端和第二终端的训练过程为加载本地中的训练样本数据,根据虚拟化共享模型的映射模型,对训练样本数据缺失的特征进行预测,获取补全样本数据,进而生成共享模型。
进一步的,步骤S5中,在每轮迭代过程中,后面虚拟化共享模型利用第一终端和第二终端的目标用户及其他用户的参数更新,来替代前面虚拟化共享模型的类别任务的训练。
进一步的,步骤S5中,在每轮迭代过程中,虚拟化共享模型表示为
M
进一步的,步骤S4中,模型融合以全局优化函数为目标进行训练,每一次迭代过程中的融合使用两个终端提供的更新共享模型,整个过程在服务端内部进行。
进一步的,有第三终端参与时,将第一终端和第二终端的最终的虚拟化共享模型作为第一待融合虚拟化共享模型,将第一终端与第三终端对应得到的最终的虚拟化共享模型作为第二待融合虚拟化共享模型,将第二终端与第三终端对应得到的最终的虚拟化共享模型作为第三待融合虚拟化共享模型,三组待融合虚拟化共享模型在服务端经过模型融合得到三个终端的虚拟化共享模型。
所述联邦学习的虚拟化共享模型传输方法将模型融合和模型迭代进行了管理,联邦学习中提高了处理效率,确保在数据共享中,用户的原始数据不被传播,而只传播模型参数,以保护用户隐私,鼓励各工作节点积极参与;保证数据共享过程中用户隐私信息的安全,同时将提高联邦学习任务的效率。
附图说明
图1是所述联邦学习的虚拟化共享模型传输方法的流程示意图;
图2是多终端进行时的流程示意图。
具体实施方式
如图1所示,所述联邦学习的虚拟化共享模型传输方法,引入虚拟化共享模型传输机制,包括模型下发、模型提交、模型融合和模型迭代四个部步骤,具体如下所述:
一种联邦学习的虚拟化共享模型传输方法,包括以下步骤:
S1:建立虚拟化共享模型:第一终端和第二终端选择都信任的同一服务端,所述服务端接收第一终端发送的第一样本数据,以及第二终端发送的第二样本数据,所述服务端根据第一样本数据和第二样本数据建立虚拟化共享模型;
所述虚拟化共享模型根据第一样本数据与第二样本数据的交集特征,以及第一样本数据与第二样本数据的映射规则得到。
S2:模型下发:所述服务端将虚拟化共享模型发送到第一终端,确认第一终端收到后,所述服务端将虚拟化共享模型发送到第二终端,并确认第一终端收到;
S3:模型提交:所述第一终端和第二终端都接受虚拟化共享模型后,所述第一终端根据虚拟化共享模型和第一样本数据进行训练,获取第一共享模型,并提交到服务端;所述第二终端根据虚拟化共享模型和第二样本数据进行训练,获取第二共享模型,并提交到服务端;
第一终端和第二终端的训练过程为加载本地中的训练样本数据,根据虚拟化共享模型的映射模型,对训练样本数据缺失的特征进行预测,获取补全样本数据,进而生成共享模型。
S4:模型融合:服务端根据收到的第一共享模型和第二共享模型,进行模型融合,融合成最新虚拟化共享模型;
模型融合以全局优化函数为目标进行训练,每一次迭代过程中的融合使用两个终端提供的更新共享模型,整个过程在服务端内部进行。
S5:模型迭代:将最新虚拟化共享模型重复步骤S2-S4,多次迭代下,直到模型收敛,获取到最终的虚拟化共享模型。
在每轮迭代过程中,后面虚拟化共享模型利用第一终端和第二终端的目标用户及其他用户的参数更新,来替代前面虚拟化共享模型的类别任务的训练。
在每轮迭代过程中,虚拟化共享模型表示为
M
在上述过程中,所述服务端每次依次接收第一终端和第二终端的数据,以及每次依次发送数据到第一终端和第二终端,由第一终端和第二终端全部确认后执行,确认方法通过组合密码实现,初始时第一终端和第二终端分别获取到服务端下发的组合密码的一半,在接收和发送时,第一终端和第二终端都需要向服务端输入密码,完成密码确认,服务官再进行下一步动作。
如图2所示,有第三终端参与时,将第一终端和第二终端的最终的虚拟化共享模型作为第一待融合虚拟化共享模型,将第一终端与第三终端对应得到的最终的虚拟化共享模型作为第二待融合虚拟化共享模型,将第二终端与第三终端对应得到的最终的虚拟化共享模型作为第三待融合虚拟化共享模型,三组待融合虚拟化共享模型在服务端经过模型融合得到三个终端的虚拟化共享模型。
所述联邦学习的虚拟化共享模型传输方法将模型融合和模型迭代进行了管理,联邦学习中提高了处理效率,确保在数据共享中,用户的原始数据不被传播,而只传播模型参数,以保护用户隐私,鼓励各工作节点积极参与;保证数据共享过程中用户隐私信息的安全,同时将提高联邦学习任务的效率。
- 一种联邦学习的虚拟化共享模型传输方法
- 一种联邦学习模型训练方法、装置及联邦学习系统