用于分析生物油品质的模型训练方法及分析方法
文献发布时间:2023-06-19 11:44:10
技术领域
本发明涉及能源与环境交叉领域,具体地,涉及一种用于分析生物油品质的模型训练方法及分析方法。
背景技术
生物质作为唯一能够直接转化为液体燃料的一种可再生能源,其有着产量巨大、可循环和碳循环等优点,而且能够大幅度减少污染物和温室气体的排放,改善环境,保护生态。
通过多种热化学技术,可将生物质转化为生物油产品。生物质转化为具有高附加值的航空燃油,其中就需要合成航空燃油中的芳烃组分,而热解、水热液化制油是由生物质制备芳烃类化合物最高效的方式。
但是生物油的品质会随着原料和制油工艺的变化而变化,因此,许多现有研究会以提高生物油品质为目标对原料和工艺进行优化,在这个过程中,就需要经常检测分析实验制备的生物油的品质。而且,在实际生产中,由于生物质原料不稳定,会导致最后生产出的生物油的品质会上下波动,这也需要技术人员实时对生物油产品进行品质检测分析。因此,无论从科学研究还是工程生产的角度来看,对生物油品质进行经常性检测分析是非常有必要的。
目前,用于检测分析生物油品质的测试方法有很多,例如,氧弹量热仪(测热值)、卡氏含水量分析仪(测含水量)、元素分析仪(测H、O元素含量和C/H比等)等。但是,需要这些测试方法结合起来才能得到与生物油品质相关的所有测试结果,这也是目前用来检测分析生物油品质的最常见的方式。但是,这种检测分析方式会存在检测分析时间长,检测分析周期往往长达数小时,而且步骤很复杂,需要多种仪器手段配合才能够得出可靠结果。
发明内容
有鉴于此,为了能够实现生物油品质的快速、便捷、无样品损失的分析方法,本发明提出一种用于分析生物油品质的模型训练方法及分析方法。
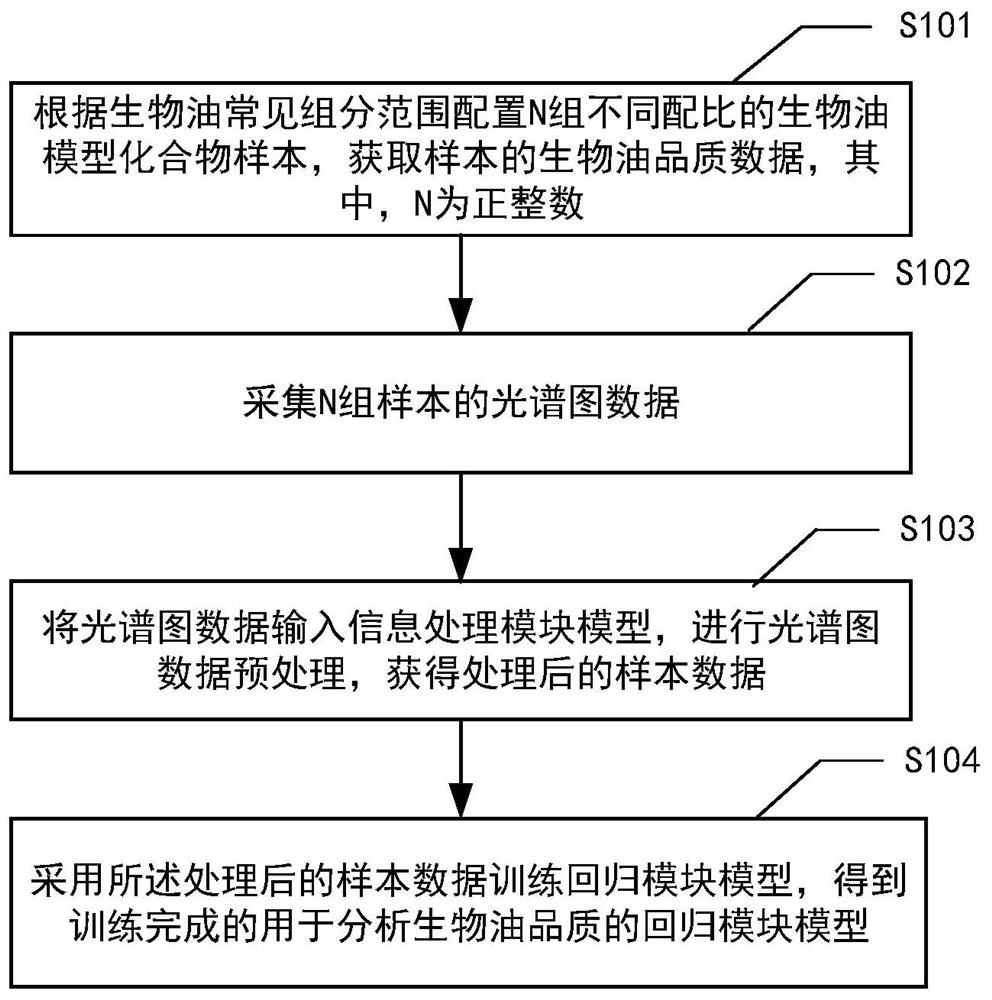
为了实现上述目的,本发明提出了一种用于分析生物油品质的模型训练方法及分析方法。其中,该模型训练方法包括:根据生物油常见组分范围配置N组不同配比的生物油模型化合物样本,获取样本的生物油品质数据,其中,N为正整数;采集N组样本的光谱图数据;将光谱图数据输入信息处理模块模型,进行光谱图数据预处理,获得处理后的样本数据;采用处理后的样本数据训练回归模块模型,得到训练完成的用于分析生物油品质的回归模块模型。
根据本发明的实施例,其中,获取样本的生物油品质数据,包括:调研收集多个生物油组分范围,将多个生物油组分范围按照不同配比配置N组生物油模型化合物样本;根据每组生物油模型化合物样本的组分含量,利用生物油品质的相关计算公式,得出生物油品质数据。
根据本发明的实施例,其中,采用处理后的样本数据训练回归模块模型,包括:将N组样本的光谱图数据划分为训练集、验证集和测试集;根据训练集和验证集对回归模块模型进行迭代训练;根据测试集对迭代训练后的回归模块模型进行性能测试。
根据本发明的实施例,其中,根据训练集和验证集对回归模块模型进行迭代训练,包括:将训练集输入到回归模块模型中进行训练;根据验证集,对训练后的回归模块模型进行验证,若验证结果不符合迭代停止条件,则继续对回归模块模型进行迭代训练和验证;若验证结果复合迭代停止条件,则输出迭代训练好的回归模块模型。
根据本发明的实施例,其中,生物油品质包括以下至少之一:不饱和度、有效碳氢比、热值、溶液的C、H、O的质量分数。
根据本发明的实施例,其中,每种生物油品质分别对应于一种回归模块模型。
根据本发明的实施例,其中,信息处理模块模型的学习算法包括以下至少之一:主成分分析算法、局部线性嵌入算法、拉普拉斯特征映射算法。
根据本发明的实施例,其中,回归模块模型包括以下至少之一:支持向量回归、人工神经网络、随机森林。
根据本发明的实施例,其中,支持向量回归采用支持向量机算法,支持向量机算法包括以下之一核函数:线性核函数、径向基核函数、多项式核函数。
本发明还提出了一种分析生物油品质的分析方法,包括:获取待分析生物油的光谱图数据;将待分析生物油的光谱图数据输入信息处理模块模型,进行光谱图数据预处理,获得处理后的数据;将处理后的数据输入回归模块模型,输出生物油品质数据;其中,回归模块模型是通过上述模型训练方法中任一项的训练方法训练得到。
根据本发明的实施例,通过本发明提供的用于生物油品质的模型训练方法和分析方法,该方法基于光谱法和机器学习算法,构建大量生物油品质和光谱图数据库、建立光谱图与生物油品质指标之间的机器学习模型的方式,解决了现有技术中检测分析生物油品质时间长、步骤复杂、检测分析效率低、在测试过程中样品损失的技术问题,实现了生物油品质的快速、高效、便捷、无样品损失的检测分析;且该方法还可以用于生物油冶炼厂,用作一种油品实时监测仪器仪表系统等领域,提高生产效率与能源利用效率。
附图说明
图1示意性示出了根据本发明实施例的用于生物油品质的模型训练方法的流程示意图;
图2示意性示出了根据本发明实施例的生物油品质的分析方法的流程示意图;
图3示意性示出了根据本发明实施例一的生物油模型化合物溶液的不同模型下的热值准确率曲线图;
图4示意性示出了根据本发明实施例二的生物油模型化合物溶液的不同模型下的不饱和度准确率曲线图;
图5示意性示出了根据本发明实施例三的生物油模型化物溶液的不同模型下的有效碳氢比准确率曲线图;
图6示意性示出了根据本发明实施例四的生物油模型化物溶液的不同模型下的碳质量分数准确率曲线图;
图7示意性示出了根据本发明实施例五的生物油模型化物溶液的不同模型下的氢质量分数准确率曲线图;
图8示意性示出了根据本发明实施例六的生物油模型化物溶液的不同模型下的氧质量分数准确率曲线图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明作进一步的详细说明。
图1示意性示出了根据本发明实施例的用于生物油品质的模型训练方法的流程示意图。
如图1所示,该模型训练方法包括操作S101~S104。
在操作S101,根据生物油常见组分范围配置N组不同配比的生物油模型化合物样本,获取样本的生物油品质数据,其中,N为正整数。
在本发明的实施例中,获取样本的生物油品质数据,包括:调研收集多个生物油组分范围,将多个生物油组分范围按照不同配比配置N组生物油模型化合物样本;根据每组生物油模型化合物样本的组分含量,利用生物油品质的相关计算公式,得出生物油品质数据。
根据本发明的实施例,调研收集多个生物油组分范围,可以包括:技术人员通过读取大量的相关文献或大量实验得到常见生物油的多个组分含量范围,例如,生物油组分可以包括酸、酚、酮、醇等。
根据本发明的实施例,将多个生物油组分范围按照不同配比配置N组生物油模型化合物样本包括:将多个不同组分含量范围的生物油组分进行自由配比配置,可以配置N组生物油模型化合物样本,其中,N为正整数,例如,为了能够说明分析数据的准确性,N可以大于等于100。
根据本发明的实施例,生物油品质可以包括以下至少之一:不饱和度、有效碳氢比、热值、溶液的C、H、O的质量分数。
根据本发明的实施例,每组生物油模型化合物样本含有不同浓度的组分,根据各项相关生物油品质的计算公式,可以得出各项生物油品质相关数据。
在操作S102,采集N组样本的光谱图数据。
根据本发明的实施例,可以通过采用光谱仪或者光谱相机作为数据采集模块分别获得N组样本的光谱图数据,
根据本发明的实施例,光谱类型包括但不限于红外光谱、紫外光谱、激光光谱,光谱生成方法包括但不限于光谱仪、光谱相机。
在操作S103,将光谱图数据输入信息处理模块模型,进行光谱图数据预处理,获得处理后的样本数据。
根据本发明的实施例,信息处理模块模型的学习算法包括以下至少之一:主成分分析算法、局部线性嵌入算法、拉普拉斯特征映射算法。
根据本发明的实施例,主成分分析算法是一种多变量统计方法,它是最常用的降维方法之一,通过正交变换将一组可能存在相关性的变量数据转换为一组线性不相关的变量,转换后的变量被称为主成分。
根据本发明的实施例,通过对光谱图数据进行降维和降噪等预处理,可以得到若干个包含原有数据信息且彼此互不相关的主成分,能够将光谱图数据的目标特征更为明显,更加便于模型训练。
在操作S104,采用处理后的样本数据训练回归模块模型,得到训练完成的用于分析生物油品质的回归模块模型。
在本发明的实施例中,采用处理后的样本数据训练回归模块模型可以包括:将N组样本的光谱图数据划分为训练集、验证集和测试集;根据训练集和验证集对回归模块模型进行迭代训练;根据测试集对迭代训练后的回归模块模型进行性能测试。
根据本发明的实施例,根据生物油模型化合物样本N组预设数据占比对光谱图数据样本进行划分为训练集、验证集和测试集,例如占比可以为3:1:1。
根据本发明的实施例,使用训练集对回归模块模型进行训练,使用验证集对训练后的回归模块模型进行验证,并根据验证结果判断是否停止迭代训练。在使用训练集对回归模块模型进行训练时,以训练集中的光谱图作为输入,以光谱图中关联的每一种生物油品质数据标签作为输出对回归模块模型进行训练。
根据本发明的实施例,使用测试集测试迭代训练后的回归模块模型的准确率,当迭代训练后的回归模块模型的准确率大于预设准确阈值时,输出迭代训练后的回归模块模型并存储,以用于后续对待分析生物油模型化合物的光谱图数据进行分析。
在本发明的实施例,上述的根据训练集和验证机对回归模块模型进行迭代训练,该过程可以包括:将训练集输入到回归模块模型中进行训练;根据验证集,对训练后的回归模块模型进行验证,若验证结果不符合迭代停止条件,则继续对回归模块模型进行迭代训练和验证;若验证结果复合迭代停止条件,则输出迭代训练好的最优回归模块模型。
根据本发明的实施例,用于回归模块模型包括以下至少之一:支持向量回归、人工神经网络、随机森林等。其中,支持向量回归采用支持向量机算法,该算法包括但不限于以下之一函数:线性核函数(linear)、径向基核函数(rbf)、多项式核函数(poly)。
根据本发明的实施例,例如,回归模块模型为支持向量回归模型时,支持向量回归模型核函数采用线性核函数时,回归模块模型的效果最优,支持向量回归模型的核函数优选采用线性核函数。
根据本发明的实施例,每种生物油品质分别对应于一种回归模块模型,若要对每一种生物油品质进行分析,则需要训练多个不同的回归模块模型。
根据本发明的实施例,通过构建大量生物油品质和光谱图数据库,建立光谱图与生物油品质指标之间的机器学习模型,训练出能够用于分析生物油品质的最优回归模块模型,解决传统分析方法分析效率低、过程复杂、样品损失等问题,实现生物油品质的快速、便捷、高效的生物油品质监测分析。
本发明还提供了一种分析生物油品质的分析方法,利用上述训练方法得到的最优回归模块模型实现对生物油品质的快速检测分析。
图2示意性示出了根据本发明实施例的生物油品质的分析方法的流程示意图。
如图2所示,该分析方法包括操作S201~S203。
在操作S201,获取待分析生物油的光谱图数据。
在操作S202,将待分析生物油的光谱图数据输入信息处理模块模型,进行光谱图数据预处理,获得处理后的数据。
在操作S203,将处理后的数据输入回归模块模型,输出生物油品质数据。
根据本发明的实施例,通过构建大量生物油品质和光谱图数据库,建立光谱图与生物油品质指标之间的机器学习模型,训练出能够用于分析生物油品质的最优回归模块模型,利用该训练完成的最优回归模块解决传统分析方法的检测时间长、检测步骤复杂、效率低、准确度不高的技术问题,实现对生物油品质的快速、高效、便捷、准确率高的检测分析。
为了能够更清楚的说明本发明的固态氧离子导体基场效应晶体管的制备方法,本发明提供了具体实施例做进一步具体说明。需要说明的是,这些具体实施例的描述只是示例性的,而并非要限制本发明的保护范围。
本发明通过读取大量的文献和实验,调研收集了大量的生物油组范围,根据生物油常见的组分范围配置类不同配比的样本,以配置生物油模型化合物来有效代替各地区不同生物油的成分含量,通过不同成分不同浓度来配置出124组模型化合物进行深入研究。下面提供几个具体实施例,用该方法来预测生物油模型化合物的不饱和度、有效碳氢比、热值以及溶液的C/H/O质量分数。
实施例1:针对生物油模型化合物溶液的热值
S11、通过读取大量的文献和实验,调研收集了大量的生物油组范围,根据生物油常见的组分范围配置N组不同配比的样本,同时通过相关计算提前获得这些生物油模型化合物样品的热值数据。常温干燥条件下用密封袋保存。预先通过实验或数据库检索的方式获得这些生物油模型化合物样本的热值数据,并打乱排序以说明实验数据样本的随机性。表1为生物油模型化合物样本低位发热量。如表1所示。
表1
S12、由光谱仪或光谱相机构成的数据采集模块获得样品的光谱数据。
本实施例中,采用衰减全反射红外光谱仪来采集样品的红外吸收光谱,扫描波数范围为400-4000cm
S13、将步骤12获得的光谱数据分成训练集:交叉验证集:测试集=3:1:1,输入信息提取模块模型,使用主成分分析算法对数据进行降噪和降维等处理,获得若干个包含原有数据信息且彼此互不相关的主成分,提取前20个主成分用于后续分析与计算。
S14、采用步骤13得到的数据训练支持向量回归模型,以平均相对误差为优化目标函数,得到该模块模型的最佳参数条件,生成最优的用于预测低位发热量的回归模块模型图。
例如,图3示意性示出了根据本发明实施例一的生物油模型化合物溶液的不同模型下的热值准确率曲线图。
如图3所示,当信息处理模块的主成分分析模型数低于8时,几乎所有曲线都表现出上升趋势。这反映出前8个信息处理模块的主成分包含了溶液的热值的大部分量化数据,以及信息提取模块从原始红外光谱中获取的数据随着主成分个数的增多而增加。当信息处理模块的主成分分析模型个数大于8时,平均相对误差处于一个较小的稳定值。
支持向量回归模型核函数为线性核函数时,回归模块模型的效果最优,信息处理模块主成分分析模型数为8左右时,低位发热量预测准确率为96.4022793%。因此回归预测模块时,支持向量机模型的核函数采用线性核函数,信息处理模块主成分数选为8。
将上述得到预测准确率较高的生物油模型化合物参数的样品提取数据通过回归预测模块进行测试集计算,得到生物油模型化合物样品的热值与元素分析等结果。
经过实际分析计算,采用上述方法进行未知生物油模型化合物样品的热值预测计算,通过测试集数据进行计算得出其准确率为96.062245091608%,对比交叉验证集的准确率下降0.4%,几乎持平。因此加以验证了当回归预测模块时,支持向量机模型的核函数采用线性核函数多项式核函数,信息处理模块主成分数选为8的可靠性。
以上所说的回归模块模型的优化模型:主成分个数为8,核函数选取线性核函数模型的优化回归模型。
实施例2:针对生物油模型化合物溶液的不饱和度
S21、通过读取大量的文献和实验,调研收集了大量的生物油组范围,根据生物油常见的组分范围配置N组不同配比的样本,同时通过相关计算提前获得这些生物油模型化合物样品的不饱和度数据。常温干燥条件下用密封袋保存。预先通过实验或数据库检索的方式获得这些生物油模型化合物样本的不饱和度数据,并打乱排序以说明实验数据样本的随机性。表2为生物油模型化合物溶液的不饱和度。如表2所示。
表2
S22、由光谱仪或光谱相机构成的数据采集模块获得样品的光谱数据。
本实施例中,采集光谱图数据所用的光谱仪以及采集方法均与实施例1中的S12相同,在此不再赘述。
S23、将步骤22获得的光谱数据分成训练集:交叉验证集:测试集=3:1:1,输入信息提取模块模型,使用主成分分析算法对数据进行降噪和降维等处理,获得若干个包含原有数据信息且彼此互不相关的数据量,提取前20个主成分用于后续分析与计算。
S24、采用步骤23得到的数据训练支持向量回归模型,以平均相对误差为优化目标函数,得到该模块模型的最佳参数条件,生成最优的用于预测生物油的不饱和度的回归模块模型图。
例如,图4示意性示出了根据本发明实施例二的生物油模型化合物溶液的不同模型下的不饱和度准确率曲线图。
如图4所示,当信息处理模块的主成分分析模型数大于12时,平均相对误差处于一个较小的稳定值。支持向量回归模型核函数为线性核函数时,回归模块模型的效果最优,信息处理模块主成分分析模型数为12左右时,不饱和浓度预测准确率为91.9731207%。因此回归预测模块时,支持向量机模型的核函数采用线性核函数,信息处理模块主成分数选为12。
将上述得到预测准确率较高的生物油模型化合物参数的样品提取数据通过回归预测模块进行测试集计算,得到生物油模型化合物样品的不饱和度浓度的结果。
经过实际分析计算,采用上述方法进行未知生物油模型化合物样品的不饱和浓度计算,通过测试集数据进行计算得出其准确率为91.7%,对比交叉验证集的准确率下降0.3%,几乎持平。因此加以验证了当回归预测模块时,支持向量机模型的核函数采用线性核函数,信息处理模块主成分数选为12的可靠性。
以上所说的回归模块模型的优化模型:主成分个数为12,核函数选取线性核函数模型的优化回归模型。
实施例3,针对生物油模型化合物溶液的有效碳氢比
S31、通过读取大量的文献和实验,调研收集了大量的生物油组范围,根据生物油常见的组分范围配置N组不同配比的样本,同时通过相关计算提前获得这些生物油模型化合物样品的有效碳氢比数据。常温干燥条件下用密封袋保存。预先通过实验或数据库检索的方式获得这些生物油模型化合物样本的有效碳氢比数据,并打乱排序以说明实验数据样本的随机性。表3为生物油模型化合物溶液的有效碳氢比。如表3所示。
表3
S32、由光谱仪或光谱相机构成的数据采集模块获得样品的光谱数据。
本实施例中,采集光谱图数据所用的光谱仪以及采集方法均与实施例1中的S12相同,在此不再赘述。
S33,将步骤32获得的光谱数据分成训练集:交叉验证集:测试集=3:1:1,输入信息提取模块模型,使用主成分分析算法对数据进行降噪和降维等处理,获得若干个包含原有数据信息且彼此互不相关的数据量,提取前20个主成分用于后续分析与计算。
S34、采用步骤33得到的数据训练支持向量回归模型,以平均相对误差为优化目标函数,得到该模块模型的最佳参数条件,生成最优的用于预测生物油的有效碳氢比的回归模块模型图。
例如,图5示意性示出了根据本发明实施例二的生物油模型化合物溶液的不同模型下的有效碳氢比的准确率曲线图。
如图5所示,当信息处理模块的主成分分析模型数低于8时,几乎所有曲线都表现出上升趋势。这反映出前8个信息处理模块的主成分包含了溶液的有效碳氢比的大部分量化数据,以及信息提取模块从原始红外光谱中获取的数据随着主成分个数的增多而增加。当信息处理模块的主成分分析模型个数大于8时,平均相对误差处于一个较小的稳定值。
支持向量回归模型核函数为线性核函数时,回归模块模型的效果最优,信息处理模块主成分分析模型数为8左右时,有效碳氢比预测准确率为97.4%。因此回归预测模块时,支持向量机模型的核函数采用线性核函数,信息处理模块主成分数选为8。
将上述得到预测准确率较高的生物油模型化合物参数的样品提取数据通过回归预测模块进行测试集计算,得到生物油模型化合物样品的有效碳氢比结果。
经过实际分析计算,采用上述方法进行未知生物油模型化合物样品的有效碳氢比计算,通过test测试集数据进行计算得出其准确率为97.7%,对比交叉验证集的准确率上升0.2%,几乎持平。因此加以验证了当回归预测模块时,支持向量机模型的核函数采用线性核函数,信息处理模块主成分数选为8的可靠性。
以上所说的回归模块模型的优化模型:主成分个数为8,核函数选取线性核函数的优化回归模型。
在本发明的实施例中,每个回归模块模型只针对一种生物油品质进行检测分析,如针对生物油热量、不饱和度、有效碳氢比、碳质量分数、氢质量分数、氧质量分数。若要对每一种项目进行检测分析,则需要训练多个不同的回归模块模型。
针对生物油模型化合物溶液的碳、氢、氧质量分数的最优回归模块模型的训练方法与上述实施例1-3类似,在此不再赘述。
图6-图8分别是根据本发明实施例的生物油模型化物溶液的不同模型下的碳、氢、氧质量分数准确率曲线图。
如图6-图8所示,针对生物油模型化物溶液的碳、氢、氧质量分数的回归模块模型的优化模型均可以为:主成分个数为8,核函数选取线性核函数模型的优化回归模型。
需要说明的是,除非上下文明确要求,否则整个说明书和权利要求书中的“包括”、“包含”等类似词语应当解释半酣的含义而不是排他或穷举的含义,也就是“包含但不限于”的含义。
以上的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 用于分析生物油品质的模型训练方法及分析方法
- 情感分析模型的训练方法、情感分析方法、装置和设备