语料筛选方法和装置
文献发布时间:2023-06-19 11:54:11
技术领域
本申请涉及自然语言处理技术,尤其涉及一种语料筛选方法和装置。
背景技术
自然语言处理(natural language processing,NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法,实现人机间自然语言通信意味着要使计算机既能理解自然语言文本的意义,也能以自然语言文本来表达给定的意图、思想等。因此,自然语言处理是一门融语言学、计算机科学、数学于一体的科学。当前自然语言处理的研究方向包括词法分析、句法分析和语义分析。词法分析的作用是从句子中划分出目标词,句法分析的作用是了解这些词之间的关系,因此句法分析的输入是一个词串(可能含词性等属性),输出是句子的句法结构。语义分析是在词法分析和句法分析基础上完成更为贴近语义的形式化表达。
现有技术大多聚焦于语料的句长、关键词、实义词等特征上,在深度学习发展的基础上,渴望使用一劳永逸的监督学习模型,使用词向量等黑盒方法自动表达文本特征。但黑盒特征很难给出合理解释,且一般不符合中文语言习惯。
相关语料筛选方法中,将大规模语料库随机划分为N个子集,给每个子集人工打上标签,构建第一语料集合。选取部分子集A,按照K-Fold交叉检验方式输入模型进行训练,当模型预测结果满足预设条件时,将A加入标准语料库,否则按照预设的主题词典对A进行增/删,直至用A训练的模型满足预设条件为止,将最终得到的A加入标准语料库。经过上述迭代,标准语料库即为从大规模语料库中筛选出的子集。
但是上述方法依赖大量的人工标注,且随机选择语料构建子集,没有统一标准,成本高、效率低,不利于监督学习模型的高效创建和更新。
发明内容
本申请提供一种语料筛选方法和装置,以提高语料库的创建效率,降低成本,进而利于监督学习模型的高效创建和迭代。
第一方面,本申请提供一种语料筛选方法,包括:
获取N个语料,每个所述语料为一个自然句,N为正整数;对第一语料进行自然语言处理得到M个标签,所述第一语料为所述N个语料中的任意一个,所述自然语言处理包括词法分析、句法分析和语义分析中的一个或多个,所述M个标签包括词性标签、句法角色标签和语义角色标签中的一个或多个,M为正整数;根据所述M个标签计算所述第一语料的语义特征,所述语义特征用于表示所述第一语料的文本语义特征;根据所述第一语料的语义特征计算所述第一语料的贡献度,所述第一语料的贡献度用于表示所述第一语料在所述N个语料中的语义权重;根据所述N个语料的贡献度对所述N个语料进行筛选得到语料库。
本申请利用NLP技术获取语料的一种或多种标签,并基于这些标签计算各个待筛选的语料的语义贡献度,再根据语义贡献度对语料进行筛选得到语料库,使得语料库从句法和语义层面覆盖较多的全集信息,并且使语料筛选有了统一的标准,不但可以帮助标注人员从庞大的语料库中筛选出子集,还可以提高效率,降低成本,进而利于监督学习模型的高效创建和迭代。
在一种可能的实现方式中,所述对第一语料进行自然语言处理得到M个标签之前,还包括:对所述第一语料进行分词处理得到K个目标词;所述对第一语料进行自然语言处理得到M个标签,包括以下一种或多种方法:对所述K个目标词进行词性标注得到K个词性标签,每个所述目标词对应一个所述词性标签;对所述K个目标词进行依存句法分析得到K个句法角色标签,每个所述目标词对应一个所述句法角色标签;以及,对所述K个目标词进行语义角色标注得到L个语义角色标签,每个所述语义角色标签对应一个短语,所述短语包括一个或多个所述目标词,L为正整数。
在一种可能的实现方式中,所述语义特征包括所述第一语料的语义角色内句法角色特征和语义角色内词性特征;所述根据所述M个标签计算所述第一语料的语义特征,包括:根据所述K个句法角色标签和所述L个语义角色标签计算所述语义角色内句法角色特征;根据所述K个词性标签和所述L个语义角色标签计算所述语义角色内词性特征。
在一种可能的实现方式中,所述根据所述第一语料的语义特征计算所述第一语料的贡献度,包括:根据所述语义角色内句法角色特征和所述语义角色内词性特征计算第一目标词的贡献度,所述第一目标词为所述K个目标词中与第一句法角色标签对应的目标词,所述第一句法角色标签为所述K个句法角色标签中的任意一个;根据所述第一目标词的贡献度计算第一短语的贡献度,所述第一短语包括所述第一目标词且为所述第一语料中与第一语义角色标签对应的短语,所述第一语义角色标签为所述L个语义角色标签的其中之一;根据所述第一短语的贡献度计算所述第一语料的贡献度。
本申请利用NLP技术获取语料的一种或多种标签,并基于这些标签先计算语料中目标词的贡献度,再计算包含了目标词的短语的贡献度,最后计算包含了短语的语料的语义贡献度,根据各个语料的语义贡献度对语料进行筛选得到语料库,使得语料库从句法和语义层面覆盖较多的全集信息,并且使语料筛选有了统一的标准,不但可以帮助标注人员从庞大的语料库中筛选出子集,还可以提高效率,降低成本,进而利于监督学习模型的高效创建和迭代。
在一种可能的实现方式中,所述根据所述N个语料的贡献度对所述N个语料进行筛选得到语料库,包括:按照贡献度从高到低的顺序对所述N个语料进行排序,取前n个语料组成所述语料库,n为预先设定值。
在一种可能的实现方式中,所述根据所述N个语料的贡献度对所述N个语料进行筛选得到语料库,包括:获取所有第二目标词的权重,所述第二目标词为所述N个语料中被标注为设定谓词的目标词;针对每个所述第二目标词,按照贡献度从高到低的顺序对包括所述第二目标词的所有第二语料进行排序,所述N个语料包括所述所有第二语料;根据所述第二目标词的权重从所述包括所述第二目标词的所有第二语料中提取相关数量的所述第二语料加入所述语料库。
在一种可能的实现方式中,所述根据所述N个语料的贡献度对所述N个语料进行筛选得到语料库,包括:获取所有第二短语的权重,所述第二短语为所述N个语料中被标注为设定语义角色标签的短语;针对每个所述第二短语,按照贡献度从高到低的顺序对包括所述第二短语的所有第三语料进行排序,所述N个语料包括所述所有第三语料;根据所述第二短语的权重从所述包括所述第二短语的所有第三语料中提取相关数量的所述第三语料加入所述语料库。
在一种可能的实现方式中,所述根据所述K个句法角色标签和所述L个语义角色标签计算所述语义角色内句法角色特征,包括:计算第一目标词集合包括的目标词数量在第二目标词集合包括的目标词数量中的第一占比作为所述语义角色内句法角色特征,所述第二目标词集合包括所述第一语料中的且与第二语义角色标签对应的短语中的所有目标词,所述第二语义角色标签为所述L个语义角色标签中的任意一个,所述第一目标词集合包括所述第二目标词集合中的且与第一句法角色标签对应的所有目标词,所述第一句法角色标签为所述第二目标词集合中的所有目标词分别对应的句法角色标签中的任意一个。
在一种可能的实现方式中,所述根据所述K个词性标签和所述L个语义角色标签计算所述语义角色内词性特征,包括:计算第三目标词集合包括的目标词数量在第二目标词集合包括的目标词数量中的第二占比作为所述语义角色内词性特征,所述第二目标词集合包括所述第一语料中的且与第二语义角色标签对应的短语中的所有目标词,所述第二语义角色标签为所述L个语义角色标签中的任意一个,所述第三目标词集合包括所述第二目标词集合中的且与第一词性标签对应的所有目标词,所述第一词性标签为所述第二目标词集合中的所有目标词分别对应的词性标签中的任意一个。
在一种可能的实现方式中,所述语义特征还包括谓词数量特征;所述根据所述M个标签计算所述第一语料的语义特征,还包括:计算第四目标词集合包括的目标词数量在第五目标词集合包括的目标词数量中的第三占比作为所述谓词数量特征,所述第四目标词集合包括所述N个语料中的且被标注为第一谓词的所有目标词,所述第五目标词集合包括所述N个语料中的且被标注为任意一种谓词的所有目标词,所述第一谓词为所述谓词中的任意一种;所述根据所述N个语料的贡献度对所述N个语料进行筛选得到语料库之前,还包括:根据所述谓词数量特征和所述N个语料的贡献度计算所述N个语料中的且被标注为任意一种谓词的所有目标词的贡献度;所述根据所述N个语料的贡献度对所述N个语料进行筛选得到语料库,包括:按照贡献度从高到低的顺序对所述N个语料中的且被标注为任意一种谓词的所有目标词进行排序,取包括前n个所述目标词的语料组成所述语料库。
本申请基于语料中被标注为谓词的目标词的贡献度,结合各个语料的语义贡献度,从语料中包含的谓词的角度对语料进行筛选得到语料库,使得语料库从句法和语义层面覆盖较多的全集信息,并且使语料筛选有了统一的标准,不但可以帮助标注人员从庞大的语料库中筛选出子集,还可以提高效率,降低成本,进而利于监督学习模型的高效创建和迭代。
在一种可能的实现方式中,所述语义特征还包括语义角色特征;所述根据所述M个标签计算所述第一语料的语义特征,还包括:计算所述N个语料中的第一语义角色标签的数量在所述N个语料中的所有语义角色标签的数量中的第四占比作为所述语义角色特征,所述第一语义角色标签为所述所有语义角色标签中的任意一个;所述根据所述N个语料的贡献度对所述N个语料进行筛选得到语料库之前,还包括:根据所述语义角色特征和所述N个语料的贡献度计算所述N个语料中的任意一个语义角色标签对应的短语的贡献度;所述根据所述N个语料的贡献度对所述N个语料进行筛选得到语料库,包括:按照贡献度从高到低的顺序对所述N个语料中的所有语义角色标签对应的短语进行排序,取包括前n个所述短语的语料组成所述语料库。
本申请基于语料中被标注为谓词的目标词的贡献度,结合各个语料的语义贡献度,从语料中包含的语义角色的角度对语料进行筛选得到语料库,使得语料库从句法和语义层面覆盖较多的全集信息,并且使语料筛选有了统一的标准,不但可以帮助标注人员从庞大的语料库中筛选出子集,还可以提高效率,降低成本,进而利于监督学习模型的高效创建和迭代。
第二方面,本申请提供一种语料筛选装置,包括:
获取模块,用于获取N个语料,每个所述语料为一个自然句,N为正整数;处理模块,用于对第一语料进行自然语言处理得到M个标签,所述第一语料为所述N个语料中的任意一个,所述自然语言处理包括词法分析、句法分析和语义分析中的一个或多个,所述M个标签包括词性标签、句法角色标签和语义角色标签中的一个或多个,M为正整数;根据所述M个标签计算所述第一语料的语义特征,所述语义特征用于表示所述第一语料的文本语义特征;根据所述第一语料的语义特征计算所述第一语料的贡献度,所述第一语料的贡献度用于表示所述第一语料在所述N个语料中的语义权重;筛选模块,用于根据所述N个语料的贡献度对所述N个语料进行筛选得到语料库。
在一种可能的实现方式中,所述处理模块,还用于对所述第一语料进行分词处理得到K个目标词;对所述K个目标词进行词性标注得到K个词性标签,每个所述目标词对应一个所述词性标签;对所述K个目标词进行依存句法分析得到K个句法角色标签,每个所述目标词对应一个所述句法角色标签;以及,对所述K个目标词进行语义角色标注得到L个语义角色标签,每个所述语义角色标签对应一个短语,所述短语包括一个或多个所述目标词,L为正整数。
在一种可能的实现方式中,所述语义特征包括所述第一语料的语义角色内句法角色特征和语义角色内词性特征;所述处理模块,具体用于根据所述K个句法角色标签和所述L个语义角色标签计算所述语义角色内句法角色特征;根据所述K个词性标签和所述L个语义角色标签计算所述语义角色内词性特征。
在一种可能的实现方式中,所述处理模块,具体用于根据所述语义角色内句法角色特征和所述语义角色内词性特征计算第一目标词的贡献度,所述第一目标词为所述K个目标词中与第一句法角色标签对应的目标词,所述第一句法角色标签为所述K个句法角色标签中的任意一个;根据所述第一目标词的贡献度计算第一短语的贡献度,所述第一短语包括所述第一目标词且为所述第一语料中与第一语义角色标签对应的短语,所述第一语义角色标签为所述L个语义角色标签的其中之一;根据所述第一短语的贡献度计算所述第一语料的贡献度。
在一种可能的实现方式中,所述筛选模块,具体用于按照贡献度从高到低的顺序对所述N个语料进行排序,取前n个语料组成所述语料库,n为预先设定值。
在一种可能的实现方式中,所述筛选模块,具体用于获取所有第二目标词的权重,所述第二目标词为所述N个语料中被标注为设定谓词的目标词;针对每个所述第二目标词,按照贡献度从高到低的顺序对包括所述第二目标词的所有第二语料进行排序,所述N个语料包括所述所有第二语料;根据所述第二目标词的权重从所述包括所述第二目标词的所有第二语料中提取相关数量的所述第二语料加入所述语料库。
在一种可能的实现方式中,所述筛选模块,具体用于获取所有第二短语的权重,所述第二短语为所述N个语料中被标注为设定语义角色标签的短语;针对每个所述第二短语,按照贡献度从高到低的顺序对包括所述第二短语的所有第三语料进行排序,所述N个语料包括所述所有第三语料;根据所述第二短语的权重从所述包括所述第二短语的所有第三语料中提取相关数量的所述第三语料加入所述语料库。
在一种可能的实现方式中,所述处理模块,具体用于计算第一目标词集合包括的目标词数量在第二目标词集合包括的目标词数量中的第一占比作为所述语义角色内句法角色特征,所述第二目标词集合包括所述第一语料中的且与第二语义角色标签对应的短语中的所有目标词,所述第二语义角色标签为所述L个语义角色标签中的任意一个,所述第一目标词集合包括所述第二目标词集合中的且与第一句法角色标签对应的所有目标词,所述第一句法角色标签为所述第二目标词集合中的所有目标词分别对应的句法角色标签中的任意一个。
在一种可能的实现方式中,所述处理模块,具体用于计算第三目标词集合包括的目标词数量在第二目标词集合包括的目标词数量中的第二占比作为所述语义角色内词性特征,所述第二目标词集合包括所述第一语料中的且与第二语义角色标签对应的短语中的所有目标词,所述第二语义角色标签为所述L个语义角色标签中的任意一个,所述第三目标词集合包括所述第二目标词集合中的且与第一词性标签对应的所有目标词,所述第一词性标签为所述第二目标词集合中的所有目标词分别对应的词性标签中的任意一个。
在一种可能的实现方式中,所述语义特征还包括谓词数量特征;所述处理模块,还用于计算第四目标词集合包括的目标词数量在第五目标词集合包括的目标词数量中的第三占比作为所述谓词数量特征,所述第四目标词集合包括所述N个语料中的且被标注为第一谓词的所有目标词,所述第五目标词集合包括所述N个语料中的且被标注为任意一种谓词的所有目标词,所述第一谓词为所述谓词中的任意一种;根据所述谓词数量特征和所述N个语料的贡献度计算所述N个语料中的且被标注为任意一种谓词的所有目标词的贡献度;所述筛选模块,还用于按照贡献度从高到低的顺序对所述N个语料中的且被标注为任意一种谓词的所有目标词进行排序,取包括前n个所述目标词的语料组成所述语料库。
在一种可能的实现方式中,所述语义特征还包括语义角色特征;所述处理模块,还用于计算所述N个语料中的第一语义角色标签的数量在所述N个语料中的所有语义角色标签的数量中的第四占比作为所述语义角色特征,所述第一语义角色标签为所述所有语义角色标签中的任意一个;根据所述语义角色特征和所述N个语料的贡献度计算所述N个语料中的任意一个语义角色标签对应的短语的贡献度;所述筛选模块,还用于按照贡献度从高到低的顺序对所述N个语料中的所有语义角色标签对应的短语进行排序,取包括前n个所述短语的语料组成所述语料库。
第三方面,本申请提供一种设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上述第一方面中任一项所述的方法。
第四方面,本申请提供一种计算机可读存储介质,包括计算机程序,所述计算机程序在计算机上被执行时,使得所述计算机执行上述第一方面中任一项所述的方法。
第五方面,本申请提供一种计算机程序,当所述计算机程序被计算机执行时,用于执行上述第一方面中任一项所述的方法。
附图说明
图1示出了NLP技术的研究方向的一个示意图;
图2示出了本申请提供的语料筛选框架的一个示例性的框图;
图3为本申请提供的服务器300的一个示例性的结构框图;
图4示出了终端设备400的一个示例性的结构示意图;
图5为本申请语料筛选方法实施例的流程图;
图6为本申请语料筛选装置实施例的结构示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请中的附图,对本申请中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
本申请的说明书实施例和权利要求书及附图中的术语“第一”、“第二”等仅用于区分描述的目的,而不能理解为指示或暗示相对重要性,也不能理解为指示或暗示顺序。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元。方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
应当理解,在本申请中,“至少一个(项)”是指一个或者多个,“多个”是指两个或两个以上。“和/或”,用于描述关联对象的关联关系,表示可以存在三种关系,例如,“A和/或B”可以表示:只存在A,只存在B以及同时存在A和B三种情况,其中A,B可以是单数或者复数。字符“/”一般表示前后关联对象是一种“或”的关系。“以下至少一项(个)”或其类似表达,是指这些项中的任意组合,包括单项(个)或复数项(个)的任意组合。例如,a,b或c中的至少一项(个),可以表示:a,b,c,“a和b”,“a和c”,“b和c”,或“a和b和c”,其中a,b,c可以是单个,也可以是多个。
本申请提供了一种语料筛选框架,遵从汉语语言习惯,基于NLP技术,从词法分析、句法分析和语义分析三个角度出发,得到语料的语义特征。图1示出了NLP技术的研究方向的一个示意图,如图1所示,NLP技术包括词法分析、句法分析和语义分析三个研究方向,其中,词法分析包括分词、词性标签和命名实体识别;句法分析包括短语结构句法分析、依存句法分析和深层文法句法分析;语义分析包括词汇级语义分析、句子级语义分析和篇章级语义分析,词汇级语义分析包括词义消歧、词义表示和学习,句子级语义分析包括语义角色标签和深层语义分析,深层语义分析又包括语义依存分析和其他,篇章级语义分析包括篇章连接词识别、论元识别、显式篇章关系识别和隐式篇章关系识别。本申请提供的语料筛选框架主要涉及上述分词、词性标签、依存句法分析和语义角色标签四项技术,分词技术主要是从语料(即语言材料。语料是构成语料库的基本单元,可以用文本作为替代,并把文本中的上下文关系作为现实世界中语言的上下文关系的替代品。通常把一个文本集合称为语料库(corpus),当有多个文本集合时,可以称为语料库集合(corpora))中划分出目标词;词性标签技术主要是分析语料中的目标词的词性,对每个目标词标注出其词性;依存句法分析技术主要是分析语料中的目标词之间的关系,对每个目标词标注出其句法角色;语义角色标签技术主要是分析语料中短语的语义角色,对每个具有语义的短语标出其语义角色,短语包括一个或多个目标词。通常语料中的每个目标词都可以被标注为某一句法角色,但并不是每个目标词都可以被标注为某一语义角色,这与语义角色标签技术的具体实现有关,此处不再赘述。基于图1所示的NLP技术,本申请对待筛选的语料进行自然语言处理,得到语料包括的目标词,以及在上述四项技术处理后得到的多种标注(包括词性标签、句法角色标签和/或语义角色标签)。
本申请将上述多种标注作为语料筛选框架的输入,得到语料的语义特征,该语义特征是语料更为贴近语义的形式化表达,再根据语料的语义特征计算语料的语义贡献度,最后根据语义贡献度对语料进行筛选得到语料库。语料库是经科学取样和加工的大规模电子文本库。基于语料库,再借助计算机分析工具,研究者可以开展相关的语言理论及应用研究。语料库是语料库语言学研究的基础资源,也是经验主义语言研究方法的主要资源,可以应用于词典编纂、语言教学、传统语言研究、NLP中基于统计或实例的研究等方面。语料库中存放的是在语言的实际使用中真实出现过的语言材料,以电子计算机为载体承载语言知识的基础资源,真实语料需要经过加工(分析和处理)才能成为有用的资源。
图2示出了本申请提供的语料筛选框架的一个示例性的框图,如图2所示,该框架包括特征层、贡献层和策略层,其中,特征层包括谓词数量特征、语义角色特征、语义角色内句法角色特征和语义角色内词性特征四个模块;贡献层包括句法角色贡献度、语义角色贡献度和语义贡献度三个模块;策略层包括数据筛选策略模块。特征层基于分词、词性标签、依存句法分析和语义角色标签四项技术的处理结果(即语料包括的目标词,以及在上述四项技术处理后得到的多种标注(包括词性标签、句法角色标签和/或语义角色标签)),定量描述语料的语义特性,该语义特征可以包括谓词数量特征、语义角色特征、语义角色内句法角色特征和语义角色内词性特征中的一个或多个。贡献层先定义句法角色贡献度(其实际意义为语料中打上了句法角色标签和语义角色标签后,针对每种语义角色标签,计算其覆盖范围内的每种句法角色的贡献度),基于句法角色贡献度再定义语义角色贡献度(其实际意义为针对每种语义角色标签,根据该语义角色标签覆盖范围内的各种句法角色的贡献度计算该语义角色的贡献度),再基于语义角色贡献度定义语义贡献度(其实际意义为针对每个语料,根据其包括的语义角色的贡献度计算该语料的贡献度)。贡献层也可以在得到上述语义贡献度的基础上,定义所有语料中的全局谓词贡献度或全局语义角色贡献度。策略层定义了语料筛选策略,该策略可以根据监督学习模型的应用场景进行个性化定制,提供了基于语义贡献度、全局谓词贡献度和/或全局语义角色贡献度的筛选策略。
本申请提供的语料筛选框架可以由语料筛选装置实现,该语料筛选装置可以由服务器实现,服务器实现上述功能完成语料收集和筛选,创建语料库。语料筛选装置也可以由服务器和终端设备联合实现,终端设备收集语料并传输给服务器,服务器对语料进行NLP,实现上述功能完成语料筛选,创建语料库;或者,服务器收集语料对语料进行NLP后,将带标注的语料传输给服务器,服务器基于带标注的语料完成语料筛选,创建语料库。服务器和终端设备之间可以通过通信网络实现数据传输。
需要说明的是,上述通信网络可以是局域网,也可以是通过中继(relay)设备转接的广域网,或者包括局域网和广域网。当该通信网络为局域网时,示例性的,该通信网络可以是wifi热点网络、wifi P2P网络、蓝牙网络、zigbee网络或近场通信(near fieldcommunication,NFC)网络等近距离通信网络。当该通信网络为广域网时,示例性的,该通信网络可以是第三代移动通信技术(3rd-generation wireless telephone technology,3G)网络、第四代移动通信技术(the 4th generation mobile communication technology,4G)网络、第五代移动通信技术(5th-generation mobile communication technology,5G)网络、未来演进的公共陆地移动网络(public land mobile network,PLMN)或因特网等,本申请实施例对此不作限定。
图3为本申请提供的服务器300的一个示例性的结构框图。如图3所示,服务器300包括天线301、射频装置302和基带装置303。天线301与射频装置302连接。在上行方向上,射频装置302通过天线301接收来自终端设备的信号,并将接收到的信号发送给基带装置303进行处理。在下行方向上,基带装置303生成需要发送给终端设备的信号,并将生成的信号发送给射频装置302。射频装置302通过天线301将该信号发射出去。
基带装置303可以包括一个或多个处理单元3031。处理单元3031具体可以为处理器。
此外,基带装置303还可以包括一个或多个存储单元3032以及一个或多个通信接口3033。存储单元3032用于存储计算机程序和/或数据。通信接口3033用于与射频装置302交互信息。存储单元3032具体可以为存储器,通信接口3033可以为输入输出接口或者收发电路。
可选地,存储单元3032可以是和处理单元3031处于同一芯片上的存储单元,即片内存储单元,也可以是与处理单元3031处于不同芯片上的存储单元,即片外存储单元。本申请对此不作限定。
终端设备又可称之为用户设备(user equipment,UE),可以部署在陆地上,包括室内或室外、手持或车载;也可以部署在水面上(如轮船等);还可以部署在空中(例如飞机、气球和卫星上等)。终端设备可以是手机(mobile phone)、平板电脑(pad)、具备无线通讯功能的可穿戴设备(如智能手表)、具有定位功能的位置追踪器、带无线收发功能的电脑、虚拟现实(virtual reality,VR)设备、增强现实(augmented reality,AR)设备、工业控制(industrial control)中的无线设备、无人驾驶(self driving)中的无线设备、远程医疗(remote medical)中的无线设备、智能电网(smart grid)中的无线设备、运输安全(transportation safety)中的无线设备、智慧城市(smart city)中的无线设备、智慧家庭(smart home)中的无线设备等,本申请对此不作限定。
图4示出了终端设备400的一个示例性的结构示意图。如图4所示,终端设备400包括:应用处理器401、微控制器单元(microcontroller unit,MCU)402、存储器403、调制解调器(modem)404、射频(radio frequency,RF)模块405、无线保真(Wireless-Fidelity,简称Wi-Fi)模块406、蓝牙模块407、传感器408、输入/输出(input/output,I/O)设备409、定位模块410等部件。这些部件可通过一根或多根通信总线或信号线进行通信。本领域技术人员可以理解,终端设备400可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
下面结合图4对终端设备400的各个部件进行具体的介绍:
应用处理器401是终端设备400的控制中心,利用各种接口和总线连接终端设备400的各个部件。在一些实施例中,处理器401可包括一个或多个处理单元。
存储器403中存储有计算机程序,诸如图4所示的操作系统411和应用程序412。应用处理器401被配置用于执行存储器403中的计算机程序,从而实现该计算机程序定义的功能,例如应用处理器401执行操作系统411从而在终端设备400上实现操作系统的各种功能。存储器403还存储有除计算机程序之外的其他数据,诸如操作系统411和应用程序412运行过程中产生的数据。存储器403为非易失性存储介质,一般包括内存和外存。内存包括但不限于随机存取存储器(random access memory,RAM),只读存储器(read-only memory,ROM),或高速缓存(cache)等。外存包括但不限于闪存(flash memory)、硬盘、光盘、通用串行总线(universal serial bus,USB)盘等。计算机程序通常被存储在外存上,处理器在执行计算机程序前会将该程序从外存加载到内存。
存储器403可以是独立的,通过总线与应用处理器401相连接;存储器403也可以和应用处理器401集成到一个芯片子系统。
MCU 402是用于获取并处理来自传感器408的数据的协处理器,MCU 402的处理能力和功耗小于应用处理器401,但具有“永久开启(always on)”的特点,可以在应用处理器401处于休眠模式时持续收集以及处理传感器数据,以极低的功耗保障传感器的正常运行。在一个实施例中,MCU 402可以为sensor hub芯片。传感器408可以包括光传感器、运动传感器。具体地,光传感器可包括环境光传感器及接近传感器,其中,环境光传感器可根据环境光线的明暗来调节显示器4091的亮度,接近传感器可在终端设备400移动到耳边时,关闭显示屏的电源。作为运动传感器的一种,加速计传感器可检测各个方向上(一般为三轴)加速度的大小,静止时可检测出重力的大小及方向;传感器408还可以包括陀螺仪、气压计、湿度计、温度计、红外线传感器等其它传感器,在此不再赘述。MCU 402和传感器408可以集成到同一块芯片上,也可以是分离的元件,通过总线连接。
modem 404以及射频模块405构成了终端设备400通信子系统,用于实现无线通信标准协议的主要功能。其中,modem 404用于编解码、信号的调制解调、均衡等。射频模块405用于无线信号的接收和发送,射频模块405包括但不限于天线、至少一个放大器、耦合器、双工器等。射频模块405配合modem 404实现无线通信功能。modem 404可以作为单独的芯片,也可以与其他芯片或电路在一起形成系统级芯片或集成电路。这些芯片或集成电路可应用于所有实现无线通信功能的终端设备,包括:手机、电脑、笔记本、平板、路由器、可穿戴设备、汽车、家电设备等。
终端设备400还可以使用Wi-Fi模块406,蓝牙模块407等来进行无线通信。Wi-Fi模块406用于为终端设备400提供遵循Wi-Fi相关标准协议的网络接入,终端设备400可以通过Wi-Fi模块406接入到Wi-Fi接入点,进而访问互联网。在其他一些实施例中,Wi-Fi模块406也可以作为Wi-Fi无线接入点,可以为其他终端设备提供Wi-Fi网络接入。蓝牙模块407用于实现终端设备400与其他终端设备(例如手机、智能手表等)之间的短距离通信。本申请实施例中的Wi-Fi模块406可以是集成电路或Wi-Fi芯片等,蓝牙模块407可以是集成电路或者蓝牙芯片等。
定位模块410用于确定终端设备400的地理位置。可以理解的是,定位模块410具体可以是全球定位系统(global position system,GPS)或北斗卫星导航系统、俄罗斯GLONASS等定位系统的接收器。
Wi-Fi模块406,蓝牙模块407和定位模块410分别可以是单独的芯片或集成电路,也可以集成到一起。例如,在一个实施例中,Wi-Fi模块406,蓝牙模块407和定位模块410可以集成到同一芯片上。在另一个实施例中,Wi-Fi模块406,蓝牙模块407、定位模块410以及MCU 402也可以集成到同一芯片中。
输入/输出设备409包括但不限于:显示器4091、触摸屏4092,以及音频电路4093等等。
其中,触摸屏4092可采集终端设备400的用户在其上或附近的触摸事件(比如用户使用手指、触控笔等任何适合的物体在触摸屏4092上或在触控屏触摸屏4092附近的操作),并将采集到的触摸事件发送给其他器件(例如应用处理器401)。其中,用户在触摸屏4092附近的操作可以称之为悬浮触控;通过悬浮触控,用户可以在不直接接触触摸屏4092的情况下选择、移动或拖动目的(例如图标等)。此外,可以采用电阻式、电容式、红外线以及表面声波等多种类型来实现触摸屏4092。
显示器(也称为显示屏)4091用于显示用户输入的信息或展示给用户的信息。可以采用液晶显示屏、有机发光二极管等形式来配置显示器。触摸屏4092可以覆盖在显示器4091之上,当触摸屏4092检测到触摸事件后,传送给应用处理器401以确定触摸事件的类型,随后应用处理器401可以根据触摸事件的类型在显示器4091上提供相应的视觉输出。虽然在图4中,触摸屏4092与显示器4091是作为两个独立的部件来实现终端设备400的输入和输出功能,但是在某些实施例中,可以将触摸屏4092与显示器4091集成而实现终端设备400的输入和输出功能。另外,触摸屏4092和显示器4091可以以全面板的形式配置在终端设备400的正面,以实现无边框的结构。
音频电路4093、扬声器4094、麦克风4095可提供用户与终端设备400之间的音频接口。音频电路4093可将接收到的音频数据转换后的电信号,传输到扬声器4094,由扬声器4094转换为声音信号输出;另一方面,麦克风4095将收集的声音信号转换为电信号,由音频电路4093接收后转换为音频数据,再通过modem 404和射频模块405将音频数据发送给比如另一终端设备,或者将音频数据输出至存储器403以便进一步处理。
另外,终端设备400还可以具有指纹识别功能。例如,可以在终端设备400的背面(例如后置摄像头的下方)配置指纹采集器件,或者在终端设备400的正面(例如触摸屏4092的下方)配置指纹采集器件。又例如,可以在触摸屏4092中配置指纹采集器件来实现指纹识别功能,即指纹采集器件可以与触摸屏4092集成在一起来实现终端设备400的指纹识别功能。在这种情况下,该指纹采集器件配置在触摸屏4092中,可以是触摸屏4092的一部分,也可以以其他方式配置在触摸屏4092中。本申请实施例中的指纹采集器件的主要部件是指纹传感器,该指纹传感器可以采用任何类型的感测技术,包括但不限于光学式、电容式、压电式或超声波传感技术等。
进一步地,终端设备400搭载的操作系统411可以为
以搭载
在一个实施例中,操作系统411包括内核,硬件抽象层(hardware abstractionlayer,HAL)、库和运行时(libraries and runtime)以及框架(framework)。其中,内核用于提供底层系统组件和服务,例如:电源管理、内存管理、线程管理、硬件驱动程序等;硬件驱动程序包括Wi-Fi驱动、传感器驱动、定位模块驱动等。硬件抽象层是对内核驱动程序的封装,向框架提供接口,屏蔽低层的实现细节。硬件抽象层运行在用户空间,而内核驱动程序运行在内核空间。
库和运行时也叫做运行时库,它为可执行程序在运行时提供所需要的库文件和执行环境。在一个实施例中,库与运行时包括安卓运行时(android runtime,ART),库,以及场景包运行时。ART是能够把应用程序的字节码转换为机器码的虚拟机或虚拟机实例。库是为可执行程序在运行时提供支持的程序库,包括浏览器引擎(比如webkit)、脚本执行引擎(比如JavaScript引擎)、图形处理引擎等。场景包运行时是场景包的运行环境,主要包括页面执行环境(page context)和脚本执行环境(script context),其中,页面执行环境通过调用相应的库解析html、css等格式的页面代码,脚本执行环境通过调用相应的功能库解析执行JavaScript等脚本语言实现的代码或可执行文件。
框架用于为应用层中的应用程序提供各种基础的公共组件和服务,比如窗口管理、位置管理等等。在一个实施例中,框架包括地理围栏服务,策略服务,通知管理器等。
以上描述的操作系统411的各个组件的功能均可以由应用处理器401执行存储器403中存储的程序来实现。
所属领域的技术人员可以理解终端设备400可包括比图4所示的更少或更多的部件,图4所示的该终端设备仅包括与本申请实施例所公开的多个实现方式更加相关的部件。
基于上述语料筛选框架,本申请提供了一种语料筛选方法,解决相关技术需要依赖大量的人工标注,且无统一标准随机选择语料用于构建子集的问题。
图5为本申请语料筛选方法实施例的流程图,如图5所示,本实施例的方法可以由上述语料筛选装置执行。该语料筛选方法,可以包括:
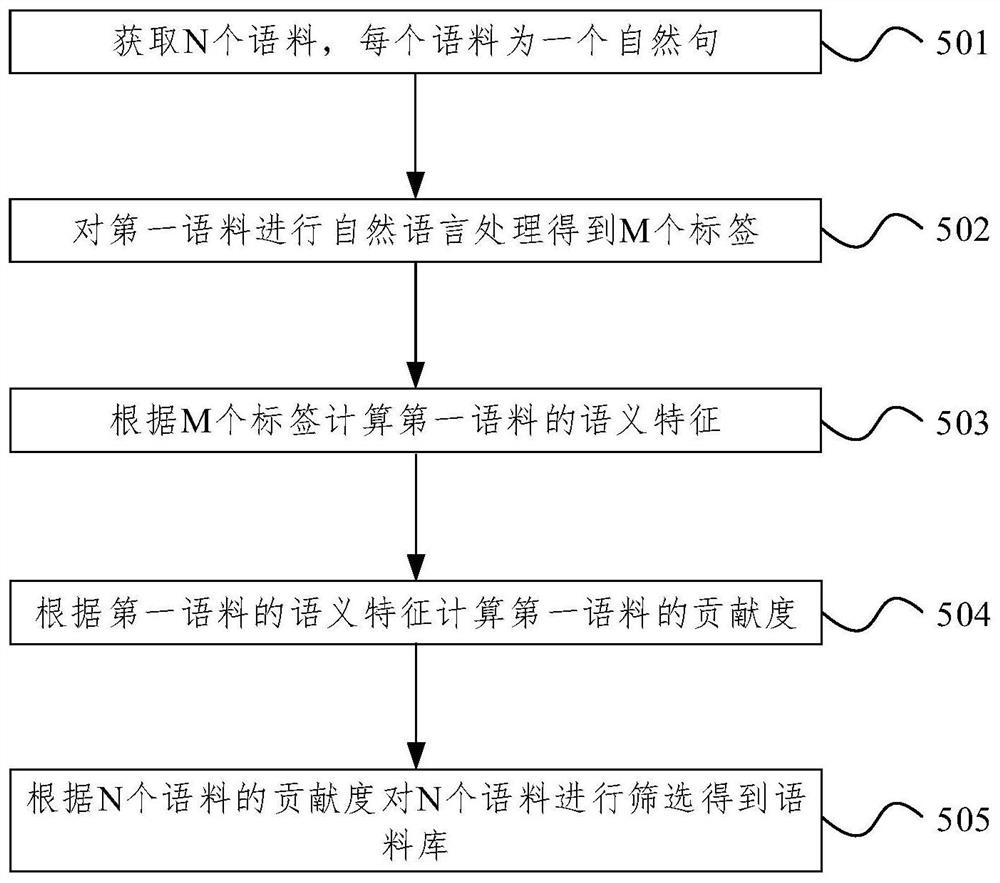
步骤501、获取N个语料,每个语料为一个自然句。
N为正整数。自然句就是一个以句号、感叹号、问号或省略号结尾的可以完整表达一个意思的句子。本申请待筛选的语料可以通过多种途径获取,例如,自动爬虫,即按照一定的规则,自动地抓取万维网信息的程序或者脚本。或者从数据平台(包括数据堂、搜狗实验室、自然语言处理与信息检索共享平台以及聚数力等)下载。或者人工收集。本申请对于语料的获取方法不作具体限定。
步骤502、对第一语料进行自然语言处理得到M个标签。
M为正整数。第一语料为上述N个语料中的任意一个。如上所述,NLP包括词法分析、句法分析和语义分析中的一个或多个,本申请主要涉及词法分析中的分词、词性标签,句法分析中的依存句法分析,以及语义分析中的语义角色标签这四项技术,该四项技术可以看做是本申请语料筛选的预处理技术。M个标签包括词性标签(通过词性标签得到)、句法角色标签(通过依存句法分析得到)和语义角色标签(通过语义角色标签得到)中的一个或多个。
分词技术对语料进行拆分得到语料包括的目标词。分词就是将连续的字序列(语料)按照一定的规范重新组合成词序列的过程。例如,语料“帮我打开车内空调”,经分词后得到(帮)(我)(打开)(车)(内)(空调),共六个目标词。
词性标签技术给语料中的每个目标词打上词性标签。现代汉语的词类可以分为实词、虚词、叹词、拟声词四个大类。其中,实词(有实际意义的词,能独立充当句子成分,即有词汇意义和语法意义的词)包括体词、谓词、加词和代词,体词包括名词、数词和量词,谓词包括动词和形容词,加词包括区别词和副词,代词是独立于体词、谓词、加词之外的一类实词,其主要作用是替代,它可以替代名词、数词、量词、动词、形容词和副词,它所替代的对象不同,语法功能就不同。虚词(泛指没有完整意义的词汇,但有语法意义或功能的词。必须依附于实词或语句表示语法意义,不能单独成句,不能单独作语法成分,不能重叠)包括关系词和辅助词,关系词包括连词和介词,辅助词包括助词和语气词。拟声词和叹词既不属于实词,也不属于虚词,是特殊词类,这两类词的特点是在句子中通常不跟其他词发生结构关系。词类是指以词的语法功能划分出来的类别。词性则是指这一类词的语法特征,亦即这一类词所具有的语法功能。例如,对分词结果(帮)(我)(打开)(车)(内)(空调)打上词性标签后得到(帮[v])(我[r])(打开[v])(车[n])(内[nd])(空调[n])。
依存句法分析技术给语料中的每个目标词打上句法角色标签。依存句法是由法国语言学家L.Tesniere最先提出,该技术将一个语料分析成一棵依存句法树,描述出各个目标词之间的依存关系,其指出了目标词之间在句法上的搭配关系。依存句法通过分析语料内成分之间的依存关系解释其句法结构,主张句子中核心动词是支配其他成分的中心成分,而其本身却不受其他任何成分的支配,所有受支配成分都以某种关系从属于支配者。句法角色标签主要可以包括:主谓关系(subject-verb,SBV)、动宾关系(verb-object,VOB)、间宾关系(indirect-object,IOB)、前置宾语(fronting-object,FOB)、兼语(double,DBL)、定中关系(attribute,ATT)、状中关系(adverbial,ADV)、动补结构(complement,CMP)、并列关系(coordinate,COO)、介宾关系(preposition-object,POB)、左附加关系(leftadjunct,LAD)、右附加关系(right adjunct,RAD)、独立结构(independent structure,IS)以及核心关系(head,HED)。例如,对词性标签结果(帮[v])(我[r])(打开[v])(车[n])(内[nd])(空调[n])打上句法角色标签后得到(帮[v][HED])(我[r][DBL])(打开[v][VOB])(车[n][ATT])(内[nd][ATT])(空调[n][VOB])。
语义角色标签技术给语料中的目标词打上语义角色标签。根据一个语料中谓词(用来描述或判定客体性质、特征或者客体之间关系的词项,谓词包括动词和形容词)和变元(与谓词有直接关系并受谓词支配的语义成分。通常是名词性的词语,在句子中充当主语或宾语)之间不同的语义关系,可以把变元分为若干个类型。语义角色标签(semantic rolelabeling,SRL)是一种浅层的语义分析,给定一个句子,SRL的任务是找出句子中谓词的相应语义角色成分,包括核心语义角色(例如施事者、受事者等)和附属语义角色(例如地点、时间、方式等)。语义角色标签主要可以包括:谓词(REL)、施事(A0)、受事(A1)、范围(A2)、动作开始(A3)、动作结束(A4)、其他动词相关(A5)、状语(ADV)、受益人(BNF)、条件(CND)、方向(DIR)、标记语(DIS)、程度(DGR)、范围(EXT)、频率(FRQ)、时间(TMP)、地点(LOC)、方式(MNR)、目的(PRP)以及主题(TPC)。例如,对句法角色标签结果(帮[v][HED])(我[r][DBL])(打开[v][VOB])(车[n][ATT])(内[nd][ATT])(空调[n][VOB])打上语义角色标签后得到(帮[v][HED])A1{(我[r][DBL])}EXT{(打开[v][VOB])(车[n][ATT])(内[nd][ATT])(空调[n][VOB])}。
需要说明的是,上述四项技术可以只执行其中的一个或多个,例如,在分词后不做词性标签,直接进行依存句法分析。或者,在分词后先进行依存句法分析,再进行词性标签。对此本申请不做具体限定。能顶住三次1%的下跌
步骤503、根据M个标签计算第一语料的语义特征。
语义特征可以定量描述语料的语义特性。本申请中,语义特征可以包括谓词数量特征、语义角色特征、语义角色内句法角色特征和语义角色内词性特征中的一个或多个。以下对各个特征的计算方法进行描述。
(1)谓词数量特征
语料中被标注为谓词的目标词组成谓词集合,谓词集合又可以划分成多个谓词子集,每个谓词子集对应一个目标词。谓词数量特征针对所有待筛选语料,是各个谓词子集包括的目标词数量分别在谓词集合包括的目标词数量中的占比,该占比亦即被标注为谓词的某一目标词在被标注为谓词的所有目标词中的占比。可以采用如下公式计算谓词数量特征:
其中,
例如,
语料一:他叫汤姆去拿外衣。
语料二:这件衣服被拿来了。
上述两个语料中加粗的目标词“叫”和“拿”被标注为谓词,可以得到N
其中,“叫”是第一个谓词,可得到其谓词数量特征为
“拿”是第二个谓词,可得到其谓词数量特征为
(2)语义角色特征
语料中一个语义角色标签的覆盖范围内的一个或多个目标词组成短语,同一语义角色标签可能标注了一个或多个短语。语义角色特征针对所有待筛选语料,是各个语义角色标签的数量分别在所有语义角色标签的数量中的占比,该占比亦即被标注为某一语义角色的短语数量在被标注为语义角色的所有短语数量中的占比。可以采用如下公式计算语义角色特征:
其中,
例如,
语料:进入新世纪后,经济全球化成为非洲国家面临的一个重大而严峻的挑战
预处理后:TMP{进入[ATT]新[ATT]世纪[VOB]后[ADV],[WP]}A0{经济[ATT]全球化[SBV]}成为[HED]A1{A0{非洲[ATT]国家[SBV]}面临[ATT]的[RAD]一个[ATT]重大[ATT]而[LAD]严峻[COO]的[RAD]挑战[VOB]}
上述语料中加粗的目标词“成为”被标注为谓词。根据预处理后的标注,可以看到该语料总共被打了4个语义角色标签(即TMP、A0、A1和A0),可以得到N
其中,TMP为第一个语义角色标签,共1个,可以得到其语义角色特征为
A0为第二个语义角色标签,共2个,可以得到其语义角色特征为
A1为第三个语义角色标签,共1个,可以得到其语义角色特征为
(3)语义角色内句法角色特征
语料中一个语义角色标签的覆盖范围内的一个或多个目标词组成短语,短语中的目标词均可以被标注句法角色。语义角色内句法角色特征逐个针对待筛选的每一个语料中的每一个语义角色,是对应语义角色标签的覆盖范围内被标注为某一个句法角色的目标词数量在该语义角色标签的覆盖范围内的目标词数量中的占比,该占比亦即计算每个语料中,被标注了同一个语义角色的一个或多个短语中,各个句法角色标签的数量分别在该语义角色标签的覆盖范围内的所有目标词数量中的占比。可以采用如下公式计算语义角色内句法角色特征:
其中,
例如,语料:进入新世纪后,经济全球化成为非洲国家面临的一个重大而严峻的挑战
预处理后:TMP{进入[ATT]新[ATT]世纪[VOB]后[ADV],[WP]}A0{经济[ATT]全球化[SBV]}成为[HED]A1{A0{非洲[ATT]国家[SBV]}面临[ATT]的[RAD]一个[ATT]重大[ATT]而[LAD]严峻[COO]的[RAD]挑战[VOB]}
上述语料中加粗的目标词“成为”被标注为谓词。根据预处理后的标注,可以看到该语料总共被打了4个语义角色标签(即TMP、A0、A1和A0)。
其中,TMP对应的短语为{进入[ATT]新[ATT]世纪[VOB]后[ADV],[WP]},共有5个目标词被标注了句法角色标签。可以得到:
ATT在TMP中的语义角色内句法角色特征为
VOB在TMP中的语义角色内句法角色特征为
ADV在TMP中的语义角色内句法角色特征为
WP在TMP中的语义角色内句法角色特征为
A0对应的短语包括{经济[ATT]全球化[SBV]}和{非洲[ATT]国家[SBV]},共有4个目标词被标注了句法角色标签。可以得到:
ATT在A0中的语义角色内句法角色特征为
SBV在A0中的语义角色内句法角色特征为
A1对应的短语为{A0{非洲[ATT]国家[SBV]}面临[ATT]的[RAD]一个[ATT]重大[ATT]而[LAD]严峻[COO]的[RAD]挑战[VOB]},共有10个目标词被标注了句法角色标签。可以得到:
ATT在A1中的语义角色内句法角色特征为
SBV在A1中的语义角色内句法角色特征为
RAD在A1中的语义角色内句法角色特征为
LAD在A1中的语义角色内句法角色特征为
COO在A1中的语义角色内句法角色特征为
VOB在A1中的语义角色内句法角色特征为
(4)语义角色内词性特征
语料中一个语义角色标签的覆盖范围内的一个或多个目标词组成短语,短语中的目标词均具有词性。语义角色内词性特征逐个针对待筛选的每一个语料中的每一个语义角色,是对应语义角色标签的覆盖范围内被标注为某一词性的目标词数量在该语义角色标签的覆盖范围内的目标词数量中的占比,该占比亦即计算每个语料中,被标注了同一个语义角色的一个或多个短语中,各个词性标签的数量分别在该语义角色标签的覆盖范围内的所有目标词数量中的占比。可以采用如下公式计算语义角色内词性特征:
其中,
例如,语料:进入新世纪后,经济全球化成为非洲国家面临的一个重大而严峻的挑战预处理后:TMP{进入[v]新[a]世纪[n]后[nd],[wp]}A0{经济[n]全球化[v]}成为[v]A1{A0{非洲[ns]国家[n]}面临[v]的[u]一个[m]重大[a]而[c]严峻[a]的[u]挑战[v]}
上述语料中加粗的目标词“成为”被标注为谓词。根据预处理后的标注,可以看到该语料总共被打了4个语义角色标签(即TMP、A0、A1和A0)。
其中,TMP对应的短语为{进入[v]新[a]世纪[n]后[nd],[wp]},共有5个目标词被标注了词性标签。可以得到:
v在TMP中的语义角色内词性特征为
a在TMP中的语义角色内词性特征为
n在TMP中的语义角色内词性特征为
nd在TMP中的语义角色内词性特征为
wp在TMP中的语义角色内词性特征为
A0对应的短语包括{经济[n]全球化[v]}和{非洲[ns]国家[n]},共有4个目标词被标注了词性标签。可以得到:
n在A0中的语义角色内词性特征为
v在A0中的语义角色内词性特征为
ns在A0中的语义角色内词性特征为
A1对应的短语为{A0{非洲[ns]国家[n]}面临[v]的[u]一个[m]重大[a]而[c]严峻[a]的[u]挑战[v]},共有10个目标词被标注了词性标签。可以得到:
ns在A1中的语义角色内词性特征为
n在A1中的语义角色内词性特征为
v在A1中的语义角色内词性特征为
u在A1中的语义角色内词性特征为
m在A1中的语义角色内词性特征为
a在A1中的语义角色内词性特征为
c在A1中的语义角色内词性特征为
需要说明的是,本申请可以根据实际需要计算上述谓词数量特征、语义角色特征、语义角色内句法角色特征和语义角色内词性特征中的一个或多个,即上述四个语义特征可以全部计算,也可以只计算其中部分,对此不作具体限定。另外本申请的语义特征除了上述四个外,还可以包括其他特征,只要为后续计算贡献度和/或语料筛选策略所需要,均可以作为本申请的语义特征进行计算,本申请对此亦不做具体限定。
步骤504、根据第一语料的语义特征计算第一语料的贡献度。
本申请可以基于步骤503计算得到的一个或多个语义特征,先计算目标词级别(对应句法角色标签)的贡献度,再计算短语级别(对应语义角色标签)的贡献度,最后计算整个语料的贡献度。以下对贡献度的计算方法进行说明。
先定义句法角色贡献度(其实际意义为语料中打上了句法角色标签和语义角色标签后,针对每种语义角色标签,计算其覆盖范围内的每种句法角色的贡献度),句法角色贡献度针对待筛选的每一个语料中的每一个语义角色,可以采用如下公式计算对应语料中的对应语义角色包括的各个句法角色的平均句法角色贡献度:
其中,
基于句法角色贡献度再定义语义角色贡献度(其实际意义为针对每种语义角色标签,根据该语义角色标签覆盖范围内的各种句法角色的贡献度计算该语义角色的贡献度),语义角色贡献度针对待筛选的每一个语料,可以采用如下公式计算对应语料包括的各个语义角色的平均语义角色贡献度:
其中,
基于语义角色贡献度定义语义贡献度(其实际意义为针对每个语料,根据其包括的语义角色的贡献度计算该语料的贡献度)。语义贡献度针对待筛选的每一个语料,可以采用如下公式计算对应语料的语义贡献度:
其中,
例如,语料:进入新世纪后,经济全球化成为非洲国家面临的一个重大而严峻的挑战预处理后:TMP{进入[v][ATT]新[a][ATT]世纪[n][VOB]后[nd][ADV],[wp][WP]}A0{经济[n][ATT]全球化[v][SBV]}成为[v][HED]A1{A0{非洲[ns][ATT]国家[n][SBV]}面临[v][ATT]的[u][RAD]一个[m][ATT]重大[a][ATT]而[c][LAD]严峻[a][COO]的[u][RAD]挑战[v][VOB]}
上述语料中加粗的目标词“成为”被标注为谓词。根据预处理后的标注,可以看到该语料总共被打了4个语义角色标签(即TMP、A0、A1和A0)。
其中,TMP对应的短语为{进入[v][ATT]新[a][ATT]世纪[n][VOB]后[nd][ADV],[wp][WP]},共有5个目标词被标注了词性标签和句法角色标签。可以得到:
ATT在TMP中的句法角色贡献度为
VOB在TMP中的句法角色贡献度为
ADV在TMP中的句法角色贡献度为
WP在TMP中的句法角色贡献度为
A0对应的短语包括{经济[n][ATT]全球化[v][SBV]}和{非洲[ns][ATT]国家[n][SBV]},共有4个目标词被标注了词性标签和句法角色标签。可以得到:
ATT在A0中的句法角色贡献度为
SBV在A0中的句法角色贡献度为
A1对应的短语为{A0{非洲[ns][ATT]国家[n][SBV]}面临[v][ATT]的[u][RAD]一个[m][ATT]重大[a][ATT]而[c][LAD]严峻[a][COO]的[u][RAD]挑战[v][VOB]},共有10个目标词被标注了词性标签和句法角色标签。可以得到:
ATT在A1中的句法角色贡献度为
SBV在A1中的句法角色贡献度为
RAD在A1中的句法角色贡献度为
LAD在A1中的句法角色贡献度为
COO在A1中的句法角色贡献度为
VOB在A1中的句法角色贡献度为
基于上述句法角色贡献度,可以得到:
TMP的语义角色贡献度为
A0的语义角色贡献度为
A1的语义角色贡献度为
基于上述语义角色贡献度,可以得到:
示例中的语料的语义贡献度为
可选的,本申请还可以在上述语义贡献度的基础上,定义所有语料中的全局谓词贡献度。可以采用如下公式计算全局谓词贡献度:
其中,
可选的,本申请还可以在上述语义贡献度的基础上,定义所有语料中的全局语义角色贡献度。可以采用如下公式计算全局语义角色贡献度:
其中,
步骤505、根据N个语料的贡献度对N个语料进行筛选得到语料库。
本申请中可以按照步骤504计算得到的语义贡献度从高到低的顺序对待筛选的N个语料进行排序,取前n个语料组成语料库,n是一个预先设定的值,可以根据语料库的用途、大小等设置n,本申请对此不做具体限定,
可选的,本申请可以根据待筛选的N个语料中被标注为谓词的目标词的使用频率给这些目标词设置权重。然后针对每一个被标注为谓词的目标词,按照语义贡献度从高到低的顺序对包括了对应目标词的所有语料进行排序。最后按照对应目标词的权重,从与其对应的所有语料中取排名靠前的权重相关数量的语料加入语料库。
可选的,本申请可以根据待筛选的N个语料中被标注了语义角色的短语的使用频率给这些短语设置权重。然后针对每一个被标注了语义角色的短语,按照语义贡献度从高到低的顺序对包括了对应短语的所有语料进行排序。最后按照对应短语的权重,从与其对应的所有语料中取排名靠前的权重相关数量的语料加入语料库。
可选的,本申请可以采用步骤504中计算得到的被标注为谓词的各个目标词在所有语料中的全局谓词贡献度,按照全局谓词贡献度从高到低的顺序对包括了对应目标词的所有语料进行排序,取前n个语料组成语料库。
可选的,本申请可以采用步骤504中计算得到的各个语义角色在所有语料中的全局语义角色贡献度,按照全局语义角色贡献度从高到低的顺序对包括了对应语义角色标签的所有语料进行排序,取前n个语料组成语料库。
除上述策略外,本申请还可以采用其他语义特征的组合对语料进行筛选,本申请对此不作具体限定。
本申请的语料筛选方法从语料的语义层面提供了筛选方案,使语料库可以表达较多的全集信息,因此将语料库中的语料标注后输入模型训练,可以达到更好地效果。从包含51723条训练数据的语料库中以0.3为比例筛选出15517条作为训练集,如表1所示,每个子领域中序号为0的行代表随机筛选,序号为1的行代表使用本申请的语料筛选方法,序号为2的行代表不筛选语料,使用所有语料。将筛选出的语料应用至自然语言理解模型中,在测试集上进行测试。发现使用本申请的语料筛选方法得到的语料库训练后的模型大幅优于随机筛选训练模型,并且接近全集训练模型的结果。表2示出了随机筛选、本申请的语料筛选方法和不筛选三种方法分别得到的语义贡献度。
表1
表2
本申请的语料筛选方法,利用NLP技术获取语料的一种或多种标签,并基于这些标签计算各个待筛选的语料的语义贡献度,再根据语义贡献度对语料进行筛选得到语料库,使得语料库从句法和语义层面覆盖较多的全集信息,并且使语料筛选有了统一的标准,不但可以帮助标注人员从庞大的语料库中筛选出子集,还可以提高效率,降低成本,进而利于监督学习模型的高效创建和迭代。
图6为本申请语料筛选装置实施例的结构示意图,如图6所示,本实施例的装置可以包括:获取模块601、处理模块602和筛选模块603,其中,获取模块601,用于获取N个语料,每个所述语料为一个自然句,N为正整数;处理模块602,用于对第一语料进行自然语言处理得到M个标签,所述第一语料为所述N个语料中的任意一个,所述自然语言处理包括词法分析、句法分析和语义分析中的一个或多个,所述M个标签包括词性标签、句法角色标签和语义角色标签中的一个或多个,M为正整数;根据所述M个标签计算所述第一语料的语义特征,所述语义特征用于表示所述第一语料的文本语义特征;根据所述第一语料的语义特征计算所述第一语料的贡献度,所述第一语料的贡献度用于表示所述第一语料在所述N个语料中的语义权重;筛选模块603,用于根据所述N个语料的贡献度对所述N个语料进行筛选得到语料库。
在一种可能的实现方式中,所述处理模块602,还用于对所述第一语料进行分词处理得到K个目标词;对所述K个目标词进行词性标注得到K个词性标签,每个所述目标词对应一个所述词性标签;对所述K个目标词进行依存句法分析得到K个句法角色标签,每个所述目标词对应一个所述句法角色标签;以及,对所述K个目标词进行语义角色标注得到L个语义角色标签,每个所述语义角色标签对应一个短语,所述短语包括一个或多个所述目标词,L为正整数。
在一种可能的实现方式中,所述语义特征包括所述第一语料的语义角色内句法角色特征和语义角色内词性特征;所述处理模块602,具体用于根据所述K个句法角色标签和所述L个语义角色标签计算所述语义角色内句法角色特征;根据所述K个词性标签和所述L个语义角色标签计算所述语义角色内词性特征。
在一种可能的实现方式中,所述处理模块602,具体用于根据所述语义角色内句法角色特征和所述语义角色内词性特征计算第一目标词的贡献度,所述第一目标词为所述K个目标词中与第一句法角色标签对应的目标词,所述第一句法角色标签为所述K个句法角色标签中的任意一个;根据所述第一目标词的贡献度计算第一短语的贡献度,所述第一短语包括所述第一目标词且为所述第一语料中与第一语义角色标签对应的短语,所述第一语义角色标签为所述L个语义角色标签的其中之一;根据所述第一短语的贡献度计算所述第一语料的贡献度。
在一种可能的实现方式中,所述筛选模块603,具体用于按照贡献度从高到低的顺序对所述N个语料进行排序,取前n个语料组成所述语料库,n为预先设定值。
在一种可能的实现方式中,所述筛选模块603,具体用于获取所有第二目标词的权重,所述第二目标词为所述N个语料中被标注为设定谓词的目标词;针对每个所述第二目标词,按照贡献度从高到低的顺序对包括所述第二目标词的所有第二语料进行排序,所述N个语料包括所述所有第二语料;根据所述第二目标词的权重从所述包括所述第二目标词的所有第二语料中提取相关数量的所述第二语料加入所述语料库。
在一种可能的实现方式中,所述筛选模块603,具体用于获取所有第二短语的权重,所述第二短语为所述N个语料中被标注为设定语义角色标签的短语;针对每个所述第二短语,按照贡献度从高到低的顺序对包括所述第二短语的所有第三语料进行排序,所述N个语料包括所述所有第三语料;根据所述第二短语的权重从所述包括所述第二短语的所有第三语料中提取相关数量的所述第三语料加入所述语料库。
在一种可能的实现方式中,所述处理模块602,具体用于计算第一目标词集合包括的目标词数量在第二目标词集合包括的目标词数量中的第一占比作为所述语义角色内句法角色特征,所述第二目标词集合包括所述第一语料中的且与第二语义角色标签对应的短语中的所有目标词,所述第二语义角色标签为所述L个语义角色标签中的任意一个,所述第一目标词集合包括所述第二目标词集合中的且与第一句法角色标签对应的所有目标词,所述第一句法角色标签为所述第二目标词集合中的所有目标词分别对应的句法角色标签中的任意一个。
在一种可能的实现方式中,所述处理模块602,具体用于计算第三目标词集合包括的目标词数量在第二目标词集合包括的目标词数量中的第二占比作为所述语义角色内词性特征,所述第二目标词集合包括所述第一语料中的且与第二语义角色标签对应的短语中的所有目标词,所述第二语义角色标签为所述L个语义角色标签中的任意一个,所述第三目标词集合包括所述第二目标词集合中的且与第一词性标签对应的所有目标词,所述第一词性标签为所述第二目标词集合中的所有目标词分别对应的词性标签中的任意一个。
在一种可能的实现方式中,所述语义特征还包括谓词数量特征;所述处理模块602,还用于计算第四目标词集合包括的目标词数量在第五目标词集合包括的目标词数量中的第三占比作为所述谓词数量特征,所述第四目标词集合包括所述N个语料中的且被标注为第一谓词的所有目标词,所述第五目标词集合包括所述N个语料中的且被标注为任意一种谓词的所有目标词,所述第一谓词为所述谓词中的任意一种;根据所述谓词数量特征和所述N个语料的贡献度计算所述N个语料中的且被标注为任意一种谓词的所有目标词的贡献度;所述筛选模块603,还用于按照贡献度从高到低的顺序对所述N个语料中的且被标注为任意一种谓词的所有目标词进行排序,取包括前n个所述目标词的语料组成所述语料库。
在一种可能的实现方式中,所述语义特征还包括语义角色特征;所述处理模块602,还用于计算所述N个语料中的第一语义角色标签的数量在所述N个语料中的所有语义角色标签的数量中的第四占比作为所述语义角色特征,所述第一语义角色标签为所述所有语义角色标签中的任意一个;根据所述语义角色特征和所述N个语料的贡献度计算所述N个语料中的任意一个语义角色标签对应的短语的贡献度;所述筛选模块603,还用于按照贡献度从高到低的顺序对所述N个语料中的所有语义角色标签对应的短语进行排序,取包括前n个所述短语的语料组成所述语料库。
本实施例的装置,可以用于执行图5所示方法实施例的技术方案,其实现原理和技术效果类似,此处不再赘述。
在实现过程中,上述方法实施例的各步骤可以通过处理器中的硬件的集成逻辑电路或者软件形式的指令完成。处理器可以是通用处理器、数字信号处理器(digital signalprocessor,DSP)、特定应用集成电路(application-specific integrated circuit,ASIC)、现场可编程门阵列(field programmable gate array,FPGA)或其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。本申请实施例公开的方法的步骤可以直接体现为硬件编码处理器执行完成,或者用编码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成上述方法的步骤。
上述各实施例中提及的存储器可以是易失性存储器或非易失性存储器,或可包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(read-onlymemory,ROM)、可编程只读存储器(programmable ROM,PROM)、可擦除可编程只读存储器(erasable PROM,EPROM)、电可擦除可编程只读存储器(electrically EPROM,EEPROM)或闪存。易失性存储器可以是随机存取存储器(random access memory,RAM),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的RAM可用,例如静态随机存取存储器(static RAM,SRAM)、动态随机存取存储器(dynamic RAM,DRAM)、同步动态随机存取存储器(synchronous DRAM,SDRAM)、双倍数据速率同步动态随机存取存储器(double data rateSDRAM,DDR SDRAM)、增强型同步动态随机存取存储器(enhanced SDRAM,ESDRAM)、同步连接动态随机存取存储器(synchlink DRAM,SLDRAM)和直接内存总线随机存取存储器(directrambus RAM,DR RAM)。应注意,本文描述的系统和方法的存储器旨在包括但不限于这些和任意其它适合类型的存储器。
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统、装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
在本申请所提供的几个实施例中,应该理解到,所揭露的系统、装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。
所述功能如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(read-only memory,ROM)、随机存取存储器(random access memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。
- 一种语料筛选方法和装置
- 一种多音字待标语料的筛选方法、装置、设备及存储介质