基于用户活动调整显示刷新率
文献发布时间:2023-06-19 12:14:58
技术领域
实施例涉及显示设备,更具体而言涉及控制显示设备中的刷新率。
背景技术
数字技术的进步已允许在与电子设备相关联的屏幕上显示视频图像。例如,智能电话可在所包括的屏幕上呈现视频图像。在另一示例中,桌面型计算机可在附接的显示设备(例如,监视器)上呈现视频图像。在一些示例中,计算设备可包括显示引擎,以处理由计算设备显示的视频图像。
附图说明
图1是根据本发明的实施例的系统的一部分的框图。
图2是根据本发明的实施例的处理器的框图。
图3是根据本发明的另一实施例的多域处理器的框图。
图4是包括多个核心的处理器的实施例。
图5是根据本发明的一个实施例的处理器核心的微体系结构的框图。
图6是根据另一实施例的处理器核心的微体系结构的框图。
图7是根据又一实施例的处理器核心的微体系结构的框图。
图8是根据另外一个实施例的处理器核心的微体系结构的框图。
图9是根据本发明的另一实施例的处理器的框图。
图10是根据本发明的实施例的代表性SoC的框图。
图11是根据本发明的实施例的另一示例SoC的框图。
图12是可与实施例一起使用的示例系统的框图。
图13是可与实施例一起使用的另一示例系统的框图。
图14是代表性计算机系统的框图。
图15A-15B是根据本发明的实施例的系统的框图。
图16是根据实施例图示出IP核心开发系统的框图,该IP核心开发系统被用于制造集成电路以执行操作。
图17A-17B是根据本发明的实施例图示出通用向量友好指令格式及其指令模板的框图。
图18A-18D是根据本发明的实施例图示出示范性特定向量友好指令格式的框图。
图19是根据本发明的一个实施例的寄存器体系结构的框图。
图20A是根据本发明的实施例图示出示范性有序管线和示范性寄存器重命名、无序发出/执行管线两者的框图。
图20B是根据本发明的实施例图示出要被包括在处理器中的有序体系结构核心的示范性实施例和示范性寄存器重命名、无序发出/执行体系结构核心两者的框图。
图21A-21B图示出更具体的示范性有序核心体系结构的框图,该核心体系结构将是芯片中的若干个逻辑块(包括相同类型和/或不同类型的其他核心)之一。
图22是根据本发明的实施例的处理器的框图,该处理器可具有多于一个核心、可具有集成的存储器控制器并且可具有集成的图形。
图23-图24是示范性计算机体系结构的框图。
图25是根据本发明的实施例与使用软件指令转换器来将源指令集中的二进制指令转换成目标指令集中的二进制指令相对比的框图。
图26是根据一个或多个实施例的示例系统的图。
图27是根据一个或多个实施例的示例方法的流程图。
图28是根据一个或多个实施例的示例事件的图。
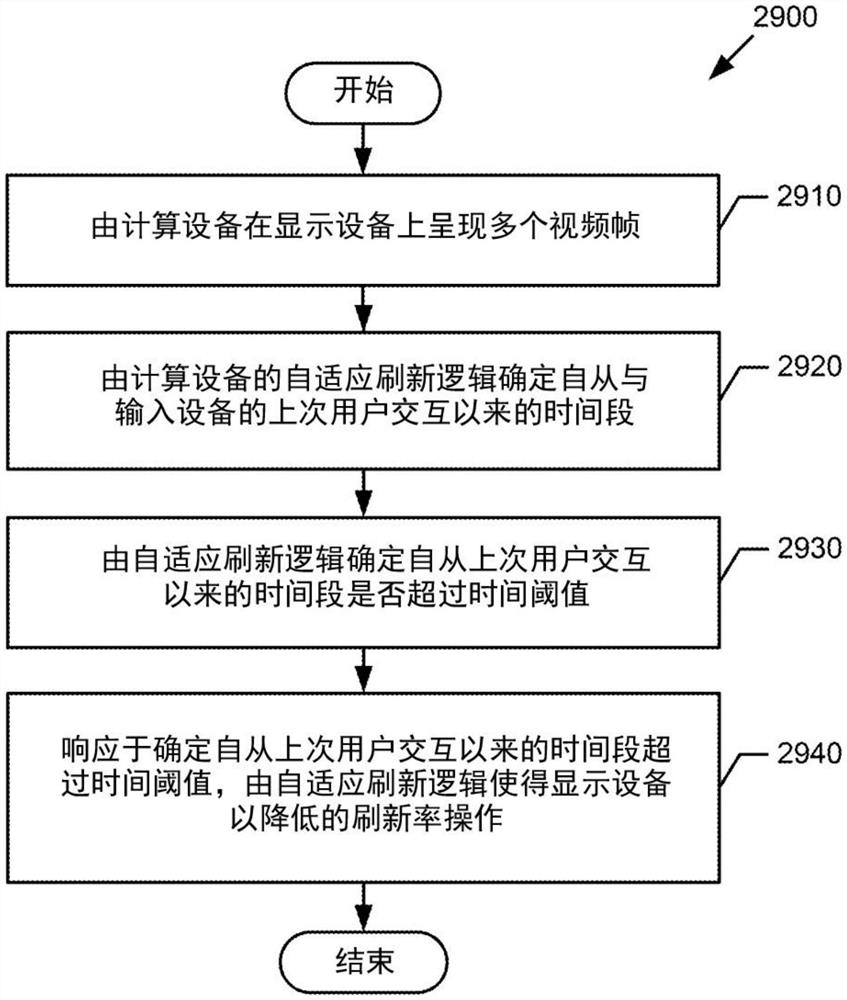
图29是根据一个或多个实施例的示例方法的流程图。
图30是根据一个或多个实施例的示例方法的流程图。
图31是根据一个或多个实施例的示例方法的流程图。
图32是根据一个或多个实施例的示例计算设备的图。
图33是根据一个或多个实施例的存储指令的示例机器可读存储介质的图。
具体实施方式
计算机或其他电子设备可使用显示设备来呈现视频图像。显示设备可以是能够以多个刷新率呈现视频内容的监视器。刷新率是单独的图像帧可被显示的频率。例如,显示设备可使用48Hz的刷新率,从而每秒显示48帧。相对较高的刷新率可能比相对较低的刷新率提供更好的观看体验。因此,一些显示设备可默认使用在给定情形中可支持的最大刷新率。然而,与使用更低的刷新率相比,使用更高的刷新率可能会导致更多的总功率消耗。因此,使用更高的刷新率可能与减少电池运行时间、增大热负荷和/或增大功率成本相关联。
根据一个或多个实施例,可以在检测到表明更低的刷新率对观看体验将会具有很少或者没有影响的状况时,动态地调整显示设备的刷新率。在一些示例中,如果自上次用户输入以来的时间超过了时间阈值,如果被更新的帧部分低于尺寸阈值,如果帧更新的频率低于刷新率,或者如果发生这些的任何组合,则刷新率可被降低。另外,如果不再检测到这样的(一个或多个)状况,则可增大刷新率。以这种方式,可动态地调整刷新率,同时尽量减小对观看体验的影响。因此,一些实施例可提供计算设备的功率消耗的降低。一些实施例的各种细节在下文参考图26-图33进一步被描述。另外,示范性系统和体系结构在下文参考图1-图25来被描述。
示范性系统和体系结构
虽然参考特定实现方式描述了以下实施例,但实施例在这个方面不受限制。具体地,设想到了本文描述的实施例的类似技术和教导可被应用到其他类型的电路、半导体器件、处理器、系统,等等。例如,公开的实施例可被实现在任何类型的计算机系统中,包括服务器计算机(例如塔式、机架式、刀片式、微服务器等等),通信系统、存储系统、任何配置的桌面型计算机、膝上型计算机、笔记本、和平板计算机(包括2:1平板、平板手机等等)。
此外,公开的实施例也可用在其他设备中,例如手持设备、片上系统(systems onchip,SoC)和嵌入式应用。手持设备的一些示例包括诸如智能电话之类的蜂窝电话、互联网协议设备、数字相机、个人数字助理(personal digital assistant,PDA)和手持PC。嵌入式应用通常可包括微控制器、数字信号处理器(digital signal processor,DSP)、网络计算机(NetPC)、机顶盒、网络集线器、广域网(wide area network,WAN)交换机、可穿戴设备、或者能够执行下面教导的功能和操作的任何其他系统。另外,实施例可被实现在具有标准语音功能的移动终端中,例如移动电话、智能电话和平板手机,和/或被实现在没有标准无线语音功能通信能力的非移动终端中,例如许多可穿戴设备、平板设备、笔记本电脑、桌面电脑、微服务器、服务器等等。
现在参考图1,示出了根据本发明的实施例的系统的一部分的框图。如图1中所示,系统100可包括各种组件,其中包括处理器110,该处理器110如图所示是多核心处理器。处理器110可经由外部电压调节器160耦合到电力供应150,该外部电压调节器160可执行第一电压转换以向处理器110提供主调节电压Vreg。
可以看出,处理器110可以是包括多个核心120a-120n的单管芯处理器。此外,每个核心可与集成电压调节器(integrated voltage regulator,IVR)125a-125n相关联,该集成电压调节器接收主调节电压并且生成要被提供给与该IVR相关联的处理器的一个或多个代理的操作电压。因此,可提供IVR实现方式来允许对电压进行细粒度控制并从而允许对每个个体核心的功率和性能进行细粒度控制。这样,每个核心可按独立的电压和频率操作,这使能了很大的灵活性并且提供了很宽的机会来平衡功率消耗与性能。在一些实施例中,对多个IVR的使用使得能够将组件分组到分开的电力平面中,使得电力被IVR调节并且只供应给群组中的那些组件。在功率管理期间,一个IVR的给定电力平面在处理器被置于某个低功率状态中时可被掉电或断电,而另一IVR的另一电力平面保持活跃或者被完全供电。类似地,核心120可包括独立的时钟生成电路(例如,一个或多个锁相环(phase lock loop,PLL))或者与独立的时钟生成电路相关联,来独立地控制每个核心120的操作频率。
仍参考图1,额外的组件可存在于处理器内,包括输入/输出接口(interface,IF)132、另一接口134、以及集成存储器控制器(integrated memory controller,IMC)136。可以看出,这些组件中的每一者可由另一集成电压调节器125
还示出了功率控制单元(power control unit,PCU)138,该PCU 138可包括电路,该电路包括硬件、软件和/或固件来执行关于处理器110的功率管理操作。可以看出,PCU138经由数字接口162向外部电压调节器160提供控制信息,以使得电压调节器生成适当的经调节电压。PCU 138还经由另一数字接口163向IVR 125提供控制信息以控制生成的操作电压(或者使得相应的IVR在低功率模式中被禁用)。在各种实施例中,PCU 138可包括多种功率管理逻辑单元来执行基于硬件的功率管理。这种功率管理可以是完全受处理器控制的(例如,由各种处理器硬件控制,并且可由工作负载和/或功率约束、热约束或其他处理器约束所触发),和/或功率管理可响应于外部源(例如,平台或功率管理源或系统软件)而被执行。
在图1中,PCU 138被示为作为处理器的单独逻辑而存在。在其他情况下,PCU 138可在核心120中给定的一个或多个上执行。在一些情况下,PCU 138可实现为被配置为执行其自己的专用功率管理代码(有时称为P代码)的微控制器(专用或通用)或者其他控制逻辑。在另外的其他实施例中,PCU 138要执行的功率管理操作可在处理器外部被实现,例如借由单独的功率管理集成电路(power management integrated circuit,PMIC)或者在处理器外部的另一组件来被实现。在另外的其他实施例中,PCU 138要执行的功率管理操作可在BIOS或其他系统软件内被实现。
实施例可尤其适合于多核心处理器,其中多个核心中的每一者可在独立的电压和频率点操作。就本文使用的而言,术语“域”用于意指在相同的电压和频率点操作的硬件和/或逻辑的集合。此外,多核心处理器还可包括其他非核心处理引擎,例如固定功能单元、图形引擎,等等。这种处理器可包括除了核心以外的独立域,例如,与图形引擎相关联的一个或多个域(本文中称为图形域),以及与非核心电路相关联的一个或多个域(本文中称为系统代理)。虽然多域处理器的许多实现方式可被形成在单个半导体管芯上,但其他实现方式可由多芯片封装实现,在该多芯片封装中,不同的域可存在于单个封装的不同半导体管芯上。
虽然为了图示的容易而没有示出,但要理解在处理器110内可存在额外的组件,例如非核心逻辑,以及诸如内部存储器之类的其他组件,例如缓存存储器层次体系的一个或多个级别,等等。此外,虽然在图1的实现方式中是用集成电压调节器示出的,但实施例不限于此。例如,可从外部电压调节器160或者调节电压的一个或多个额外的外部源向片上资源提供其他调节电压。
注意,本文描述的功率管理技术可独立于基于操作系统(operating system,OS)的功率管理(operating system-based power management,OSPM)机制并且与其互补。根据一个示例OSPM技术,处理器可按各种性能状态或水平——所谓的P状态——操作,即从P0至PN。一般而言,P1性能状态可对应于OS可请求的最高保证性能状态。除了这个P1状态以外,OS还可请求更高的性能状态,即P0状态。这个P0状态因而可以是机会模式、超频模式、或极速(turbo)模式状态,在这些模式状态中,当功率和/或热预算可用时,处理器硬件可将处理器或者其至少一些部分配置为按高于保证频率的频率进行操作。在许多实现方式中,处理器可包括高于P1保证最大频率的、超出到特定处理器最大峰值频率的多个所谓的分段频率(bin frequency),这些分段频率在制造期间被烧熔或以其他方式写入到处理器中。此外,根据一个OSPM机制,处理器可按各种功率状态或水平操作。关于功率状态,OSPM机制可指定不同的功率消耗状态,一般称为C状态,C0、C1至Cn状态。当核心活跃时,该核心按C0状态运行,并且当核心空闲时,其可被置于核心低功率状态中,也被称为核心非零C状态(例如,C1-C6状态),其中每个C状态处于更低的功率消耗水平(使得C6是比C1更深的低功率状态,等等依此类推)。
要理解,许多不同类型的功率管理技术在不同的实施例中可被单独或者组合使用。作为代表性示例,功率控制器可控制处理器按某种形式的动态电压频率缩放(dynamicvoltage frequency scaling,DVFS)来被功率管理,在该动态电压频率缩放中,一个或多个核心或其他处理器逻辑的操作电压和/或操作频率可被动态地控制以在某些情形中降低功率消耗。在一示例中,DVFS可利用可从加州圣克拉拉的英特尔公司获得的增强型英特尔SpeedStep
在某些示例中可使用的另一种功率管理技术是工作负载在不同计算引擎之间的动态调换。例如,处理器可包括以不同的功率消耗水平操作的非对称核心或其他处理引擎,使得在功率受约束的情形中,一个或多个工作负载可被动态切换来在更低功率的核心或其他计算引擎上执行。另一种示范性功率管理技术是硬件工作周期循环(hardware dutycycling,HDC),其可使得核心和/或其他计算引擎根据工作周期被周期性地启用和禁用,使得一个或多个核心可在工作周期的非活跃时段期间被设为不活跃并且在工作周期的活跃时段期间被设为活跃。
当在操作环境中存在约束时也可使用功率管理技术。例如,当遇到功率约束和/或热约束时,可通过降低操作频率和/或电压来降低功率。其他功率管理技术包括扼制指令执行速率或者限制指令的调度。此外,给定的指令集体系结构的指令有可能包括关于功率管理操作的明确或隐含指引。虽然是利用这些特定示例来描述的,但要理解在特定实施例中可使用许多其他功率管理技术。
实施例可被实现在针对各种市场的处理器中,包括服务器处理器、桌面处理器、移动处理器等等。现在参考图2,示出了根据本发明的实施例的处理器的框图。如图2中所示,处理器200可以是包括多个核心210
此外,通过接口250a-250n,可进行到各种芯片外组件的连接,例如外围设备、大容量存储装置等等。虽然在图2的实施例中是利用这个特定实现方式示出的,但本发明的范围在这个方面不受限制。
现在参考图3,示出了根据本发明的另一实施例的多域处理器的框图。如图3的实施例中所示,处理器300包括多个域。具体而言,核心域310可包括多个核心310
一般而言,核心310a-310n中的每一者除了各种执行单元和额外的处理元件以外还可包括低级别缓存。进而,各种核心可耦合到彼此并且耦合到由最后一级缓存(lastlevel cache,LLC)340a-340n的多个单元形成的共享缓存存储器。在各种实施例中,LLC340可被共享于核心和图形引擎,以及各种媒体处理电路之间。可以看出,环状互连330从而将核心耦合在一起,并且在核心、图形域320和系统代理域350之间提供互连。在一个实施例中,互连330可以是核心域的一部分。然而,在其他实施例中,环状互连可以是其自己的域的。
还可以看出,系统代理域350可包括显示控制器352,该显示控制器352可提供对关联的显示器的控制和到关联的显示器的接口。还可以看出,系统代理域350可包括功率控制单元355,该功率控制单元355可包括逻辑来执行本文描述的功率管理技术。
从图3中还可看出,处理器300还可包括集成存储器控制器(integrated memorycontroller,IMC)370,该IMC 370可提供到诸如动态随机访问存储器(dynamic randomaccess memory,DRAM)之类的系统存储器的接口。多个接口380a-380n可存在来使能处理器和其他电路之间的互连。例如,在一个实施例中,可提供至少一个直接媒体接口(directmedia interface,DMI)接口,以及一个或多个PCIe
参考图4,图示了包括多个核心的处理器的实施例。处理器400包括任何处理器或处理设备,例如微处理器、嵌入式处理器、数字信号处理器(digital signal processor,DSP)、网络处理器、手持处理器、应用处理器、协处理器、片上系统(system on a chip,SoC)、或者用于执行代码的其他设备。处理器400在一个实施例中包括至少两个核心——核心401和402,它们可包括非对称核心或对称核心(图示的实施例)。然而,处理器400可包括可以是对称或非对称的任何数目的处理元件。
在一个实施例中,处理元件指的是用于支持软件线程的硬件或逻辑。硬件处理元件的示例包括:线程单元、线程槽、线程、处理单元、上下文、上下文单元、逻辑处理器、硬件线程、核心、和/或能够为处理器保持状态(例如执行状态或体系结构状态)的任何其他元件。换言之,处理元件在一个实施例中指的是能够独立地与诸如软件线程、操作系统、应用或其他代码之类的代码相关联的任何硬件。物理处理器通常指的是可能包括任何数目的其他处理元件(例如核心或硬件线程)的集成电路。
核心经常指能够维持独立体系结构状态的、位于集成电路上的逻辑,其中每个被独立维持的体系结构状态与至少一些专用执行资源相关联。与核心形成对比,硬件线程通常指能够维持独立体系结构状态的、位于集成电路上的任何逻辑,其中被独立维持的体系结构状态共享对执行资源的访问。可以看出,当某些资源被共享并且其他资源被专用于体系结构状态时,硬件线程和核心的命名法之间的界线会重叠。然而经常,核心和硬件线程被操作系统看作单独的逻辑处理器,其中操作系统能够单独调度每个逻辑处理器上的操作。
如图4中所示,物理处理器400包括两个核心,即核心401和402。这里,核心401和402被认为是对称核心,即具有相同的配置、功能单元和/或逻辑的核心。在另一实施例中,核心401包括无序处理器核心,而核心402包括有序处理器核心。然而,核心401和402可以是单独从任何类型的核心中选择的,例如,原生核心、受软件管理的核心、被适配为执行原生指令集体系结构(instruction set architecture,ISA)的核心、被适配为执行经转化的ISA的核心、共同设计的核心,或者其他已知的核心。再进一步讨论,下文更详细描述在核心401中图示的功能单元,因为核心402中的单元以类似的方式操作。
如图所描绘的,核心401包括两个体系结构状态寄存器401a和401b,它们可与两个硬件线程(也称为硬件线程槽)相关联。因此,软件实体(例如操作系统)在一个实施例中可能将处理器400视为四个分开的处理器,即,能够同时执行四个软件线程的四个逻辑处理器或处理元件。如上文提到的,第一线程与体系结构状态寄存器401a相关联,第二线程与体系结构状态寄存器401b相关联,第三线程可与体系结构状态寄存器402a相关联,并且第四线程可与体系结构状态寄存器402b相关联。这里,体系结构状态寄存器(401a、401b、402a和402b)可与处理元件、线程槽或者线程单元相关联,如上所述。如图所示,体系结构状态寄存器401a被复制在体系结构状态寄存器401b中,因此能够为逻辑处理器401a和逻辑处理器401b存储个体的体系结构状态/上下文。在核心401中,也可针对线程401a和401b复制其他更小的资源,例如分配器和重命名器块430中的指令指针和重命名逻辑。通过分区可共享一些资源,例如重排序/引退单元435中的重排序缓冲器、分支目标缓冲器和指令转化后备缓冲器(BTB和I-TLB)420、加载/存储缓冲器、以及队列。其他资源(例如,通用内部寄存器、(一个或多个)页表基址寄存器、低级别数据缓存和数据TLB 450、(一个或多个)执行单元440、以及重排序/引退单元435的一些部分)可能被完全共享。
处理器400经常包括其他资源,这些资源可被完全共享、通过分区被共享、或者被处理元件专用或者专用于处理元件。在图4中,图示了具有处理器的说明性逻辑单元/资源的纯示范性处理器的实施例。注意,处理器可包括或者省略这些功能单元中的任何一者,以及包括没有描绘的任何其他已知的功能单元、逻辑或者固件。如图所示,核心401包括简化的、代表性无序(out-of-order,OOO)处理器核心。但在不同的实施例中可利用有序处理器。
核心401还包括耦合到取得单元的解码模块425以对取得的元素解码。取得逻辑在一个实施例中包括分别与线程槽401a、401b相关联的个体定序器。通常核心401与第一ISA相关联,该第一ISA定义/指定在处理器400上可执行的指令。经常,作为第一ISA的一部分的机器代码指令包括指令的一部分(称为操作码),该部分引用/指定要执行的指令或操作。解码模块425包括这样的电路:该电路从这些指令的操作码识别这些指令并且在管线中传递经解码的指令来按第一ISA所定义的那样进行处理。例如,解码器模块425在一个实施例中包括被设计或适配为识别诸如事务性指令之类的特定指令的逻辑。作为解码器模块425进行的识别的结果,体系结构或核心401采取特定的预定义动作来执行与适当的指令相关联的任务。注意以下这点是重要的:本文描述的任何任务、块、操作和方法可响应于单个或多个指令而被执行;这些指令中的一些可以是新的或者旧的指令。
在一个示例中,分配器和重命名器块430包括分配器来预留资源,例如预留寄存器文件来存储指令处理结果。然而,线程401a和401b可能能够进行无序执行,其中分配器和重命名器块430也预留其他资源,例如预留重排序缓冲器来跟踪指令结果。重命名器块430还可包括寄存器重命名器,以将程序/指令引用寄存器重命名到在处理器400内部的其他寄存器。重排序/引退单元435包括组件(例如,上文提及的重排序缓冲器、加载缓冲器和存储缓冲器),来支持对被无序执行的指令进行的无序执行和之后的有序引退。
(一个或多个)调度器和执行单元块440在一个实施例中包括调度器单元来调度执行单元上的指令/操作。例如,在执行单元的端口上调度浮点指令,其中该执行单元具有可用的浮点执行单元。也包括与执行单元相关联的寄存器文件来存储信息指令处理结果。示范性执行单元包括浮点执行单元、整数执行单元、跳转执行单元、加载执行单元、存储执行单元、和其他已知的执行单元。
较低级别数据缓存和数据转化后备缓冲器(data translation lookasidebuffer,D-TLB)450耦合到(一个或多个)执行单元440。数据缓存还用于存储最近使用/操作的元素(例如数据操作对象),这些元素可能被保持在存储器一致性状态中。D-TLB用于存储最近的虚拟/线性到物理地址转化。作为具体示例,处理器可包括页表结构来将物理存储器分解成多个虚拟页。
这里,核心401和402共享对更高级别或更远缓存410的访问,该缓存用于缓存最近取得的元素。注意,更高级别或者更远指的是缓存级别增大或者变得更远离(一个或多个)执行单元。在一个实施例中,更高级别缓存410是最后一级数据缓存——处理器400上的存储器层次体系中的最后缓存——例如第二或第三级别数据缓存。然而,更高级别缓存410不限于此,因为其可与指令缓存相关联或者包括指令缓存。取而代之,踪迹缓存(一种类型的指令缓存)可被耦合在解码器模块425之后来存储最近解码的踪迹。
在描绘的配置中,处理器400还包括总线接口405和功率控制单元460,其可根据本发明的实施例执行功率管理。在此场景中,总线接口405用于与在处理器400外部的设备(例如,系统存储器和其他组件)通信。
存储器控制器470可与诸如一个或许多存储器之类的其他设备相接口。在一示例中,总线接口405包括环状互连,该环状互连具有用于与存储器相接口的存储器控制器和用于与图形处理器相接口的图形控制器。在SoC环境中,甚至更多的设备(例如,网络接口、协处理器、存储器、图形处理器、和任何其他已知的计算机设备/接口)可被集成在单个管芯或集成电路上,以提供具有高功能和低功率消耗的小外形参数。
现在参考图5,示出了根据本发明的一个实施例的处理器核心的微体系结构的框图。如图5中所示,处理器核心500可以是多阶段管线式无序处理器。核心500可基于接收到的操作电压来按各种电压操作,其中接收到的操作电压可以是从集成电压调节器或者外部电压调节器接收的。
从图5中可见,核心500包括前端单元510,前端单元510可用于取得要执行的指令并且使它们为以后用在处理器管线中做好准备。例如,前端单元510可包括取得单元501、指令缓存503、和指令解码器505。在一些实现方式中,前端单元510还可包括踪迹缓存,连同微代码存储以及微操作存储。取得单元501可取得宏指令(例如从存储器或指令缓存503取得)并且将它们馈送到指令解码器505来将其解码成基元(即,供处理器执行的微操作)。
耦合在前端单元510和执行单元520之间的是无序(OOO)引擎515,该OOO引擎515可用于接收微指令并且使它们为执行做好准备。更具体而言,OOO引擎515可包括各种缓冲器,用于重排序微指令流并且分配执行所需要的各种资源,并且用于提供逻辑寄存器到(诸如寄存器文件530和扩展寄存器文件535之类的)各种寄存器文件内的存储位置上的重命名。寄存器文件530可包括用于整数操作和浮点操作的分开的寄存器文件。为了配置、控制和额外的操作,一组特定于机器的寄存器(machine specific register,MSR)538也可存在并且是核心500内(以及核心外部)的各种逻辑可访问的。
各种资源可存在于执行单元520中,包括例如各种整数、浮点、和单指令多数据(single instruction multiple data,SIMD)逻辑单元,以及其他专门的硬件。例如,这种执行单元可包括一个或多个算术逻辑单元(arithmetic logic unit,ALU)522以及一个或多个向量执行单元524,以及其他这种执行单元。
来自执行单元的结果可被提供到引退逻辑,即,重排序缓冲器(reorder buffer,ROB)540。更具体而言,ROB 540可包括各种阵列和逻辑以接收与被执行的指令相关联的信息。此信息随后被ROB 540考查来确定是否指令可被有效地引退并且结果数据可被提交给处理器的体系结构状态,或者确定是否发生了阻止指令的适当引退的一个或多个异常。当然,ROB 540可应对与引退相关联的其他操作。
如图5中所示,ROB 540耦合到缓存550,缓存550在一个实施例中可以是低级别缓存(例如,L1缓存),不过本发明的范围在这个方面不受限制。另外,执行单元520可直接耦合到缓存550。从缓存550,数据通信可与更高级别缓存、系统存储器等等发生。虽然在图5的实施例中是以这个高级别示出的,但要理解本发明的范围在这个方面不受限制。例如,虽然图5的实现方式是关于诸如
现在参考图6,示出了根据另一实施例的处理器核心的微体系结构的框图。在图6的实施例中,核心600可以是不同微体系结构的低功率核心,例如,基于
浮点管线630包括浮点(floating point,FP)寄存器文件632,该浮点寄存器文件632可包括具有诸如128、256或512比特之类的给定比特宽度的多个体系结构寄存器。管线630包括浮点调度器634来调度指令以供在管线的多个执行单元之一上执行。在示出的实施例中,这种执行单元包括算术逻辑单元(arithmetic logic unit,ALU)635、打乱单元636、和浮点(FP)加法器638。进而,在这些执行单元中生成的结果可被提供回到寄存器文件632的缓冲器和/或寄存器。当然要理解,虽然是以这几个示例执行单元示出的,但在另一实施例中可存在额外的或者不同的浮点执行单元。
也可提供整数管线640。在示出的实施例中,管线640包括整数(INT)寄存器文件642,该整数寄存器文件642可包括具有诸如128或256比特之类的给定比特宽度的多个体系结构寄存器。管线640包括整数执行(integer execution,IE)调度器644来调度指令以供在管线的多个执行单元之一上执行。在示出的实施例中,这种执行单元包括ALU 645、移位器单元646、和跳转执行单元(jump execution unit,JEU)648。进而,在这些执行单元中生成的结果可被提供回到寄存器文件642的缓冲器和/或寄存器。当然要理解,虽然是以这几个示例执行单元示出的,但在另一实施例中可存在额外的或者不同的整数执行单元。
存储器执行(memory execution,ME)调度器650可调度存储器操作以在地址生成单元(address generation unit,AGU)652中执行,该地址生成单元652也耦合到TLB 654。可以看出,这些结构可耦合到数据缓存660,数据缓存660可以是L0和/或L1数据缓存,该L0和/或L1数据缓存进而耦合到缓存存储器层次体系的额外级别,包括L2缓存存储器。
为了提供对无序执行的支持,除了重排序缓冲器680以外还可提供分配器/重命名器670,该重排序缓冲器680被配置为对被无序执行的指令重排序以便有序引退。虽然在图6的图示中是以这个特定的管线体系结构示出的,但要理解许多变化和替换是可能的。
注意,在(例如根据图5和图6的微体系结构)具有非对称核心的处理器中,可出于功率管理原因在核心之间动态地调换工作负载,因为这些核心虽然具有不同的管线设计和深度,但可具有相同或相关的ISA。这种动态的核心调换可以按对于用户应用而言透明(并且可能对于内核也透明)的方式来被执行。
参考图7,示出了根据又一实施例的处理器核心的微体系结构的框图。如图7中所示,核心700可包括多阶段有序管线来以非常低的功率消耗水平执行。作为一个这种示例,核心700可具有微体系结构,该微体系结构根据可从加州森尼维尔市的ARM控股有限公司获得的ARM Cortex A53设计。在一种实现方式中,可提供被配置为既执行32比特代码也执行64比特代码的8阶段管线。核心700包括取得单元710,该取得单元710被配置为取得指令并将它们提供给解码单元715,其中解码单元715可对指令(例如,诸如ARMv8 ISA之类的给定ISA的宏指令)进行解码。还要注意,队列730可耦合到解码单元715以存储经解码的指令。经解码的指令被提供到发出逻辑725,其中在发出逻辑725处,经解码的指令可被发出到多个执行单元中的给定一个。
还参考图7,发出逻辑725可将指令发出到多个执行单元之一。在示出的实施例中,这些执行单元包括整数单元735、乘法单元740、浮点/向量单元750、双重发出单元760、以及加载/存储单元770。这些不同执行单元的结果可被提供到写回(WB)单元780。要理解,虽然为了图示的容易而示出了单个写回单元,但在一些实现方式中,分开的写回单元可与每个执行单元相关联。此外,要理解虽然图7中所示的每个单元和逻辑是以高级别表示的,但特定的实现方式可包括更多的或不同的结构。利用一个或多个(如图7中所示的)具有管线的核心来设计的处理器可被实现在许多不同的最终产品中,从移动设备延伸到服务器系统。
参考图8,示出了根据另外一个实施例的处理器核心的微体系结构的框图。如图8中所示,核心800可包括多阶段多发出无序管线以按非常高的性能水平执行(这可以按比图7的核心700更高的功率消耗水平发生)。作为一个这种示例,处理器800可具有根据ARMCortex A57设计的微体系结构。在一种实现方式中,可提供被配置为既执行32比特代码也执行64比特代码的15(或更多)阶段管线。此外,管线可提供3宽(或更宽)和3发出(或更多发出)操作。核心800包括取得单元810,取得单元810被配置为取得指令并且将它们提供给耦合到缓存820的解码器/重命名器/调遣器单元815。单元815可对指令(例如,ARMv8指令集体系结构的宏指令)进行解码,对指令内的寄存器引用进行重命名,并且(最终)将指令调遣到所选择的执行单元。经解码的指令可被存储在队列825中。注意,虽然在图8中为了图示的容易而示出了单个队列结构,但要理解可针对多个不同类型的执行单元中的每一者提供分开的队列。
图8中还示出了发出逻辑830,其中,被存储在队列825中的经解码指令可从该发出逻辑830被发出到所选择的执行单元。发出逻辑830也可被实现特定实施例中,其中,针对发出逻辑830所耦合到的多种不同类型的执行单元中的每一者有单独的发出逻辑。
经解码的指令可被发出到多个执行单元中的给定一个。在示出的实施例中,这些执行单元包括一个或多个整数单元835、乘法单元840、浮点/向量单元850、分支单元860、以及加载/存储单元870。在一实施例中,浮点/向量单元850可被配置为应对128或256比特的SIMD或向量数据。此外,浮点/向量执行单元850可执行IEEE-754双精度浮点操作。这些不同执行单元的结果可被提供到写回单元880。注意,在一些实现方式中,分开的写回单元可与执行单元中的每一者相关联。此外,要理解虽然图8中所示的每个单元和逻辑是以高级别表示的,但特定的实现方式可包括更多的或不同的结构。
注意在(例如根据图7和图8的微体系结构)具有非对称核心的处理器中,可出于功率管理原因而动态地调换工作负载,因为这些核心虽然具有不同的管线设计和深度,但可具有相同或相关的ISA。这种动态的核心调换可以按对于用户应用而言透明(并且可能对于内核也透明)的方式来被执行。
利用一个或多个(如图5-图8中的任何一个或多个图中所示的)具有管线的核心来设计的处理器可被实现在许多不同的最终产品中,从移动设备延伸到服务器系统。现在参考图9,示出了根据本发明的另一实施例的处理器的框图。在图9的实施例中,处理器900可以是包括多个域的SoC,每个域可被控制来按独立的操作电压和操作频率操作。作为具体的说明性示例,处理器900可以是可从英特尔公司获得的基于
在图9中所示的高级别视图中,处理器900包括多个核心单元910
每个核心单元910还可包括接口(例如,总线接口单元),来使得能够互连到处理器的额外电路。在一实施例中,每个核心单元910耦合到可充当主缓存一致片上互连的一致架构,该互连进而耦合到存储器控制器935。进而,存储器控制器935控制与诸如DRAM之类的存储器(在图9中为了图示的容易而没有示出)的通信。
除了核心单元以外,还有额外的处理引擎存在于处理器内,包括至少一个图形单元920,该图形单元920可包括一个或多个图形处理单元(graphics processing unit,GPU)来执行图形处理以及可能执行图形处理器上的通用操作(所谓的GPGPU操作)。此外,至少一个图像信号处理器925可存在。信号处理器925可被配置为处理从在SoC内部或者在片外的一个或多个捕捉设备接收的传入图像数据。
其他加速器也可存在。在图9的图示中,视频编码器950可执行编码操作,这些操作包括对视频信息的编码和解码,例如为高清晰度视频内容提供硬件加速支持。还可提供显示控制器955来加速显示操作,包括为系统的内部和外部显示器提供支持。此外,安全性处理器945可存在来执行诸如安全引导操作、各种密码操作等等之类的安全性操作。
每个单元可让其功率消耗经由功率管理器940来被控制,该功率管理器940可包括控制逻辑来执行本文描述的各种功率管理技术。
在一些实施例中,处理器900还可包括耦合到一致架构的非一致架构,其中各种外围设备可耦合到该一致架构。一个或多个接口960a-960d使能与一个或多个片外设备的通信。这种通信可经由各种通信协议,例如PCIe
现在参考图10,示出了代表性SoC的框图。在示出的实施例中,SoC 1000可以是多核心SoC,该多核心SoC被配置用于低功率操作以针对包含到智能电话或(诸如平板计算机或其他便携式计算设备之类的)其他低功率设备中而被优化。作为示例,SoC 1000可利用非对称的或不同类型的核心来被实现,例如更高功率和/或低功率核心的组合,例如无序核心和有序核心。在不同的实施例中,这些核心可基于
从图10中可看出,SoC 1000包括具有多个第一核心1012
进一步参考图10,还提供了图形域1030,该图形域1030可包括被配置为独立地执行(例如,由核心域1010和1020的一个或多个核心提供的)图形工作负载的一个或多个图形处理单元(GPU)。作为示例,除了提供图形和显示渲染操作以外,GPU域1030还可用于为各种屏幕大小提供显示支持。
可以看出,各种域耦合到一致互连1040,该一致互连1040在一实施例中可以是缓存一致互连架构,该缓存一致互连架构进而耦合到集成存储器控制器1050。在一些示例中,一致互连1040可包括共享缓存存储器,例如L3缓存。在一实施例中,存储器控制器1050可以是直接存储器控制器以提供与片外存储器的通信的多个通道,例如DRAM的多个通道(在图10中为了图示的容易没有示出)。
在不同的示例中,核心域的数目可变化。例如,对于适合于包含到移动计算设备中的低功率SoC,例如图10中所示的有限数目的核心域可存在。此外,在这种低功率SoC中,包括更高功率核心的核心域1020可具有更少数目的这种核心。例如,在一个实现方式中,可提供两个核心1022来使得能够以降低的功率消耗水平进行操作。此外,不同的核心域也可耦合到中断控制器,以使得能够在不同的域之间进行对工作负载的动态调换。
在另外的其他实施例中,更大数目的核心域以及额外的可选IP逻辑可存在,因为SoC可被缩放到更高性能(以及功率)水平,以便包含到其他计算设备中(例如,桌面型电脑、服务器、高性能计算系统、基站等等)。作为一个这种示例,可提供4个核心域,每个具有给定数目的无序核心。此外,除了可选的GPU支持以外(其作为示例可采取GPGPU的形式),也可提供一个或多个加速器来提供对特定功能(例如,web服务、网络处理、交换等等)的优化硬件支持。此外,输入/输出接口也可存在来将这种加速器耦合到片外组件。
现在参考图11,示出了另一示例SoC的框图。在图11的实施例中,SoC 1100可包括各种电路来针对多媒体应用、通信和其他功能使能高性能。这样,SoC 1100适合于包含到各种各样的便携设备和其他设备中,例如智能电话、平板计算机、智能TV等等。在示出的示例中,SoC 1100包括中央处理器单元(central processor unit,CPU)域1110。在一实施例中,多个个体处理器核心可存在于CPU域1110中。作为一个示例,CPU域1110可以是具有4个多线程核心的四核心处理器。这种处理器可以是同构或异构处理器,例如低功率和高功率处理器核心的混合。
进而,提供GPU域1120来在一个或多个GPU中执行高级图形处理以应对图形并计算API。除了可发生在多媒体指令的执行期间的高级计算以外,DSP单元1130还可提供一个或多个低功率DSP来应对低功率多媒体应用,例如音乐重放、音频/视频等等。进而,通信单元1140可包括各种组件来经由各种无线协议提供连通性,例如,蜂窝通信(包括3G/4G LTE)、诸如Bluetooth
此外,多媒体处理器1150可用于执行对高清晰度视频和音频内容的捕捉和重放,包括对用户姿态的处理。传感器单元1160可包括多个传感器和/或传感器控制器来接口到存在于给定平台中的各种片外传感器。图像信号处理器(image signal processor,ISP)1170可执行关于来自平台的一个或多个相机(包括静态相机和视频相机)的捕捉内容的图像处理。
显示处理器1180可提供对到给定像素密度的高清晰度显示器的连接的支持,包括无线地传输内容以便在这种显示器上重放的能力。此外,位置单元1190可包括全球定位系统(Global Positioning System,GPS)接收器,该GPS接收器带有对多个GPS星座的支持以向应用提供利用这种GPS接收器获得的高度准确的定位信息。要理解,虽然在图11的示例中是以这组特定的组件示出的,但许多变化和替换是可能的。
现在参考图12,示出了可与实施例一起使用的示例系统的框图。可以看出,系统1200可以是智能电话或其他无线通信器。基带处理器1205被配置为关于要从系统发送或者被系统接收的通信信号执行各种信号处理。进而,基带处理器1205耦合到应用处理器1210,应用处理器1210可以是系统的主CPU,以执行OS和其他系统软件,以及诸如许多公知的社交媒体和多媒体app之类的用户应用。应用处理器1210还可被配置为针对设备执行各种其他计算操作。
进而,应用处理器1210可耦合到用户界面/显示器1220,例如触摸屏显示器。此外,应用处理器1210可耦合到存储器系统,该存储器系统包括非易失性存储器(即,闪速存储器1230)以及系统存储器(即,动态随机访问存储器(DRAM)1235)。还可看出,应用处理器1210还耦合到捕捉设备1241,例如可记录视频和/或静态图像的一个或多个图像捕捉设备。
仍参考图12,通用集成电路卡(universal integrated circuit card,UICC)1246也耦合到应用处理器1210,该通用集成电路卡1246包括订户身份模块并且可能包括安全存储及密码处理器。系统1200还可包括安全性处理器1250,该安全性处理器1250可耦合到应用处理器1210。多个传感器1225可耦合到应用处理器1210以使得能够输入各种感测到的信息,例如加速度计和其他环境信息。音频输出设备1295可提供接口来输出声音,例如以语音通信、播放的或流媒体音频数据等等的形式。
如还图示的,提供了近场通信(near field communication,NFC)无接触接口1260,其经由NFC天线1265在NFC近场中通信。虽然在图12中示出了分开的天线,但要理解在一些实现方式中,可提供一个天线或者不同组天线来使能各种无线功能。
功率管理集成电路(power management integrated circuit,PMIC)1215耦合到应用处理器1210以执行平台级功率管理。为此,PMIC 1215可向应用处理器1210发出功率管理请求以根据需要进入某些低功率状态。此外,基于平台约束,PMIC 1215也可控制系统1200的其他组件的功率水平。
为了使得通信能够被发送和接收,各种电路可被耦合在基带处理器1205和天线1290之间。具体而言,射频(radio frequency,RF)收发器1270和无线局域网(wirelesslocal area network,WLAN)收发器1275可存在。一般而言,RF收发器1270可用于根据给定的无线通信协议(例如3G或4G无线通信协议)接收和发送无线数据和呼叫,例如根据码分多路接入(code division multiple access,CDMA)、全球移动通信系统(global system formobile communication,GSM)、长期演进(long term evolution,LTE)或其他协议。此外,GPS传感器1280可存在。也可提供其他无线通信,例如对无线电信号(例如AM/FM)和其他信号的接收或发送。此外,经由WLAN收发器1275,也可实现本地无线通信。
现在参考图13,示出了可与实施例一起使用的另一示例系统的框图。在图13的图示中,系统1300可以是移动低功率系统,例如,平板计算机、2:1平板设备、平板手机或其他可转换的或独立的平板系统。如图所示,SoC 1310存在并且可被配置为作为设备的应用处理器进行操作。
各种设备可耦合到SoC 1310。在示出的图示中,存储器子系统包括耦合到SoC1310的闪速存储器1340和DRAM 1345。此外,触摸面板1320耦合到SoC 1310以提供显示能力和经由触摸的用户输入,包括在触摸面板1320的显示器上提供虚拟键盘。为了提供有线网络连通性,SoC 1310耦合到以太网接口1330。外设中枢(peripheral hub)1325耦合到SoC1310以使能与各种外围设备相接口,例如可通过各种端口或其他连接器中的任何一者耦合到系统1300。
除了SoC 1310内的内部功率管理电路和功能以外,PMIC 1380也耦合到SoC 1310以提供基于平台的功率管理,例如基于系统是被电池1390供电还是经由AC适配器1395被AC电力供电。除了这个基于电源的功率管理以外,PMIC 1380还可基于环境和使用状况来执行平台功率管理活动。此外,PMIC 1380可向SoC 1310传达控制和状态信息以引起SoC 1310内的各种功率管理动作。
仍参考图13,为了提供无线能力,WLAN单元1350耦合到SoC 1310并且进而耦合到天线1355。在各种实现方式中,WLAN单元1350可根据一个或多个无线协议提供通信。
如还图示的,多个传感器1360可耦合到SoC 1310。这些传感器可包括各种加速度计、环境和其他传感器,包括用户姿态传感器。最后,音频编解码器1365耦合到SoC 1310以提供到音频输出设备1370的接口。当然要理解,虽然在图13中是以这个特定实现方式示出的,但许多变化和替换是可能的。
现在参考图14,示出了诸如笔记本、Ultrabook
处理器1410在一个实施例中与系统存储器1415通信。作为说明性示例,系统存储器1415是经由多个存储器设备或模块实现的,以提供给定量的系统存储器。
为了提供对诸如数据、应用、一个或多个操作系统等等之类的信息的持续性存储,大容量存储装置1420也可耦合到处理器1410。在各种实施例中,为了使能更薄和更轻的系统设计以及为了改善系统响应能力,这个大容量存储装置可经由SSD来被实现或者该大容量存储装置可主要利用硬盘驱动器(hard disk drive,HDD)来被实现,其中较小量的SSD存储充当SSD缓存来使得能够在掉电事件期间对上下文状态和其他这种信息进行非易失性存储,从而使得在系统活动重发起时可发生快速加电。图14中还示出的是,闪速设备1422可耦合到处理器1410,例如经由串行外围接口(serial peripheral interface,SPI)。这个闪速设备可提供对系统软件的非易失性存储,包括基本输入/输出软件(basic input/outputsoftware,BIOS)以及系统的其他固件。
各种输入/输出(I/O)设备可存在于系统1400内。具体而言,在图14的实施例中示出的是显示器1424,其可以是还提供触摸屏1425的高清晰度LCD或LED面板。在一个实施例中,显示器1424可经由显示互连耦合到处理器1410,该显示互连可被实现为高性能图形互连。触摸屏1425可经由另一互连耦合到处理器1410,该另一互连在一实施例中可以是I
为了感知计算和其他目的,各种传感器可存在于系统内并且可按不同的方式耦合到处理器1410。某些惯性和环境传感器可通过传感器中枢1440(例如经由I
在图14中还可看出,各种外围设备可经由低引脚数(low pin count,LPC)互连耦合到处理器1410。在示出的实施例中,各种组件可通过嵌入式控制器1435被耦合。这种组件可包括键盘1436(例如,经由PS2接口耦合)、风扇1437、和热传感器1439。在一些实施例中,触摸板1430也可经由PS2接口耦合到EC 1435。此外,诸如可信平台模块(trusted platformmodule,TPM)1438之类的安全性处理器也可经由这个LPC互连耦合到处理器1410。
系统1400可通过各种方式与外部设备进行通信,包括无线地进行通信。在图14所示的实施例中,存在各种无线模块,其中每一者可对应于被配置用于特定的无线通信协议的无线电装置。用于诸如近场之类的短距离中的无线通信的一种方式可经由NFC单元1445,该NFC单元1445在一个实施例中可经由SMBus与处理器1410通信。注意,经由此NFC单元1445,彼此近邻的设备可通信。
从图14中还可看出,额外的无线单元可包括其他短距离无线引擎,包括WLAN单元1450和Bluetooth
此外,(例如,根据蜂窝或其他无线广域协议的)无线广域通信可经由WWAN单元1456发生,该WWAN单元1456进而可耦合到订户身份模块(subscriber identity module,SIM)1457。此外,为了使能对位置信息的接收和使用,GPS模块1455也可存在。注意,在图14所示的实施例中,WWAN单元1456和诸如相机模块1454之类的集成捕捉设备可经由给定的链路通信。
为了提供音频输入和输出,音频处理器可经由数字信号处理器(digital signalprocessor,DSP)1460被实现,该DSP 1460可经由高清晰度音频(high definition audio,HDA)链路耦合到处理器1410。类似地,DSP 1460可与集成编码器/解码器(CODEC)及放大器1462通信,该集成CODEC及放大器1462进而可耦合到输出扬声器1463,该输出扬声器1463可被实现在机壳内。类似地,放大器及CODEC 1462可被耦合以从麦克风1465接收音频输入,该麦克风1465在一实施例中可经由双阵列麦克风(例如,数字麦克风阵列)来被实现,以提供高质量音频输入,从而使能对系统内的各种操作的由语音激活的控制。还要注意,音频输出可从放大器/CODEC 1462被提供到耳机插孔1464。虽然在图14的实施例中是以这些特定组件示出的,但要理解本发明的范围在这个方面不受限制。
实施例可被实现在许多不同的系统类型中。现在参考图15A,示出了根据本发明的实施例的系统的框图。如图15A中所示,多处理器系统1500是点到点互连系统,并且包括经由点到点互连1550耦合的第一处理器1570和第二处理器1580。如图15A中所示,处理器1570和1580中的每一者可以是多核心处理器,包括第一和第二处理器核心(即,处理器核心1574a和1574b以及处理器核心1584a和1584b),不过可能多得多的核心可以在处理器中存在。每个处理器可包括PCU或其他功率管理逻辑来执行如本文所述的基于处理器的功率管理。
仍参考图15A,第一处理器1570还包括集成存储器控制器(integrated memorycontroller,IMC)1572和点到点(point-to-point,P-P)接口1576和1578。类似地,第二处理器1580包括IMC 1582和P-P接口1586和1588。如图15中所示,IMC 1572和1582将处理器耦合到相应的存储器,即存储器1532和存储器1534,存储器1532和存储器1534可以是在本地附接到相应处理器的系统存储器(例如,DRAM)的一部分。第一处理器1570和第二处理器1580可分别经由P-P互连1562和1564耦合到芯片组1590。如图15A中所示,芯片组1590包括P-P接口1594和1598。
此外,芯片组1590包括接口1592,用于通过P-P互连1539将芯片组1590与高性能图形引擎1538耦合。进而,芯片组1590可经由接口1596耦合到第一总线1516。如图15A中所示,各种输入/输出(I/O)设备1514可以与总线桥1518一起耦合到第一总线1516,其中总线桥1518将第一总线1516耦合到第二总线1520。各种设备可耦合到第二总线1520,例如包括键盘/鼠标1522、通信设备1526和数据存储单元1528(例如,盘驱动器或者其他大容量存储设备),其中该数据存储单元1528在一个实施例中可包括代码1530。另外,音频I/O 1524可耦合到第二总线1520。实施例可被包含到其他类型的包括移动设备的系统中,该移动设备比如是智能蜂窝电话、平板计算机、上网本、Ultrabook
现在参考图15B,示出了根据本发明的实施例的第二更具体示范性系统1501的框图。图15A和图15B中的相似元素带有相似的标号,并且图15A的某些方面被从图15B中省略以避免模糊图15B的其他方面。
图15B图示出处理器1570、1580可分别包括集成存储器和I/O控制逻辑(“CL”)1571和1581。从而,控制逻辑1571和1581包括集成存储器控制器单元并且包括I/O控制逻辑。图15B图示出不仅存储器1532、1534耦合到控制逻辑1571和1581,而且I/O设备1513也耦合到控制逻辑1571和1581。传统I/O设备1515耦合到芯片组1590。
至少一个实施例的一个或多个方面可由存储在机器可读介质上的代表性代码实现,该代表性代码表示和/或定义诸如处理器之类的集成电路内的逻辑。例如,机器可读介质可包括表示处理器内的各种逻辑的指令。当被机器读取时,指令可使得该机器制作逻辑来执行本文描述的技术。这种被称为“IP核心”的表现形式是针对集成电路的逻辑的可重复使用单元,这些单元可作为描述该集成电路的结构的硬件模型被存储在有形机器可读介质上。该硬件模型可被提供给各种客户或制造设施,它们在制造集成电路的制作机器上加载该硬件模型。可以制作集成电路,使得该电路执行与本文描述的任何实施例关联描述的操作。
图16是图示出IP核心开发系统1600的框图,该IP核心开发系统1600可用于制造集成电路来执行根据实施例的操作。IP核心开发系统1600可用于生成模块化的、可重复使用的设计,这些设计可被包含到更大的设计中或者被用于构造整个集成电路(例如,SoC集成电路)。设计设施1630可以以高级别编程语言(例如,C/C++)生成IP核心设计的软件模拟1610。软件模拟1610可用于设计、测试和验证IP核心的行为。然后可从模拟模型创建或合成寄存器传送级(register transfer level,RTL)设计。RTL设计1615是对硬件寄存器之间的数字信号的流动进行建模的集成电路的行为的抽象,其包括利用经建模的数字信号执行的关联逻辑。除了RTL设计1615以外,也可创建、设计或者合成在逻辑级或晶体管级的更低级别设计。从而,初始设计和模拟的具体细节可变化。
RTL设计1615或等同物还可被设计设施合成为硬件模型1620,该硬件模型1620可采取硬件描述语言(hardware description language,HDL)或者物理设计数据的某种其他表现形式。HDL可被进一步模拟或测试来验证IP核心设计。IP核心设计可被存储来利用非易失性存储器1640(例如,硬盘、闪速存储器、或者任何其他非易失性存储介质)输送到第三方制作设施1665。或者,IP核心设计可通过有线连接1650或无线连接1660(例如,经由互联网)被传输。制作设施1665随后可制作至少部分基于该IP核心设计的集成电路。制作出的集成电路可被配置为根据本文描述的组件和/或过程来执行操作。
下文描述的图17A-图25详述了用于实现本文描述的组件和/或过程的实施例的示范性体系结构和系统。在一些实施例中,本文描述的一个或多个硬件组件和/或指令被如下详述那样来仿真,或者被实现为软件模块。
上文详述的(一个或多个)指令的实施例可按下文详述的“通用向量友好指令格式”来被实现。在其他实施例中,这种格式不被利用并且另一指令格式被使用,然而,下面对于写入掩码寄存器、各种数据变换(调配、广播等等)、寻址等等的描述一般适用于对以上(一个或多个)指令的实施例的描述。此外,下文详述了示范性系统、体系结构和管线。以上(一个或多个)指令的实施例可在这种系统、体系结构和管线上被执行,但不限于详述的那些。
指令集可包括一个或多个指令格式。给定的指令格式可定义各种字段(例如,比特的数目、比特的位置)来指定要执行的操作(例如,操作码)和要在其上执行该操作的(一个或多个)操作对象和/或其他(一个或多个)数据字段(例如,掩码),等等。一些指令格式通过指令模板(或子格式)的定义被进一步分解。例如,给定的指令格式的指令模板可被定义为具有该指令格式的字段的不同子集(包括的字段通常是按相同顺序的,但至少一些具有不同的比特位置,因为包括的字段更少)和/或被定义为具有以不同方式被解读的给定字段。从而,ISA的每个指令利用给定的指令格式被表达(并且如果定义了的话,以该指令格式的指令模板中的给定一个指令模板来被表达)并且包括用于指定操作和操作对象的字段。例如,示范性ADD指令具有特定的操作码和指令格式,该指令格式包括操作码字段来指定该操作码并且包括操作对象字段来选择操作对象(源1/目标和源2);并且此ADD指令出现在指令流中将在选择特定操作对象的操作对象字段中具有特定内容。被称为高级向量扩展(Advanced Vector Extension,AVX)(AVX1和AVX2)并且使用向量扩展(Vector Extension,VEX)编码方案的SIMD扩展的集合已被发布和/或发表(例如,参见
示范性指令格式
本文描述的(一个或多个)指令的实施例可按不同的格式被实现。此外,下文详述了示范性系统、体系结构和管线。(一个或多个)指令的实施例可在这种系统、体系结构和管线上被执行,但不限于详述的那些。
通用向量友好指令格式
向量友好指令格式是适合于向量指令的指令格式(例如,有某些特定于向量操作的字段)。虽然描述了其中向量和标量操作两者通过向量友好指令格式受到支持的实施例,但替换实施例只使用向量友好指令格式的向量操作。
图17A-17B是根据本发明的实施例图示出通用向量友好指令格式及其指令模板的框图。图17A是根据本发明的实施例图示出通用向量友好指令格式及其类别A指令模板的框图;而图17B是根据本发明的实施例图示出通用向量友好指令格式及其类别B指令模板的框图。具体而言,针对通用向量友好指令格式1700定义了类别A和类别B指令模板,这两个指令模板都包括无存储器访问1705指令模板和存储器访问1720指令模板。术语“通用”在向量友好指令格式的情境中指的是该指令格式不被绑定到任何特定的指令集。
虽然将描述其中向量友好指令格式支持以下项目的本发明的实施例:64字节向量操作对象长度(或大小),其具有32比特(4字节)或64比特(8字节)的数据元素宽度(或大小)(从而,64字节向量由16个双字大小的元素或者8个四字大小的元素构成);64字节向量操作对象长度(或大小),其具有16比特(2字节)或8比特(1字节)的数据元素宽度(或大小);32字节向量操作对象长度(或大小),其具有32比特(4字节)、64比特(8字节)、16比特(2字节)、或者8比特(1字节)的数据元素宽度(或大小);以及16字节向量操作对象长度(或大小),其具有32比特(4字节)、64比特(8字节)、16比特(2字节)、或者8比特(1字节)的数据元素宽度(或大小);但替换实施例可支持具有更多、更少或不同的数据元素宽度(例如,128比特(16字节)的数据元素宽度)的更多、更少和/或不同的向量操作对象大小(例如,256字节向量操作对象)。
图17A中的类别A指令模板包括:1)在无存储器访问1705指令模板内,示出了无存储器访问、完全舍入控制型操作1710指令模板和无存储器访问、数据变换型操作1715指令模板;以及2)在存储器访问1720指令模板内,示出了存储器访问、暂态1725指令模板和存储器访问、非暂态1730指令模板。图17B中的类别B指令模板包括:1)在无存储器访问1705指令模板内,示出了无存储器访问、写入掩码控制、部分舍入控制型操作1712指令模板和无存储器访问、写入掩码控制、vsize型操作1717指令模板;以及2)在存储器访问1720指令模板内,示出了存储器访问、写入掩码控制1727指令模板。
通用向量友好指令格式1700包括下面按图17A-17B中所示的顺序列出的以下字段。
格式字段1740-此字段中的特定值(指令格式标识符值)唯一地标识向量友好指令格式,从而标识出采取向量友好指令格式的指令出现在指令流中。这样,此字段是可选的,因为它对于只具有通用向量友好指令格式的指令集而言是不需要的。
基本操作字段1742-其内容区分不同的基本操作。
寄存器索引字段1744-其内容直接地或者通过地址生成指定源和目标操作对象的位置,无论它们在寄存器中还是在存储器中。这些包括充分数目的比特来从PxQ(例如,32x512、16x128、32x1024、64x1024)寄存器文件中选择N个寄存器。虽然在一个实施例中N可以是多达三个源和一个目标寄存器,但替换实施例可支持更多或更少的源和目标寄存器(例如,可支持多达两个源,其中这些源之一也充当目标;可支持多达三个源,其中这些源之一也充当目标;可支持多达两个源和一个目标)。
修饰字段1746-其内容区分通用向量指令格式中指定存储器访问的指令与那些不指定存储器访问的指令的出现;也就是说,区分无存储器访问1705指令模板与存储器访问1720指令模板。存储器访问操作读取和/或写入到存储器层次体系(在一些情况下利用寄存器中的值指定源和/或目标地址),而非存储器访问操作不读取和/或写入存储器层次体系(例如,源和目标是寄存器)。虽然在一个实施例中这个字段也在执行存储器地址计算的三种不同方式之间进行选择,但替换实施例可支持更多、更少或不同的方式来执行存储器地址计算。
增强操作字段1750-其内容区分除了基本操作以外还要执行各种不同操作中的哪一种。此字段是依情境而定的。在本发明的一个实施例中,此字段被划分成类别字段1768、阿尔法字段1752和贝塔字段1754。增强操作字段1750允许了在单个指令而不是2、3或4个指令中执行共同的操作群组。
缩放比例字段1760-其内容允许了缩放索引字段的内容以进行存储器地址生成(例如,对于使用2
位移字段1762A-其内容被用作存储器地址生成的一部分(例如,对于使用2
位移因子字段1762B(注意,将位移字段1762A并列在位移因子字段1762B的正上方表明一者或另一者被使用)-其内容被用作地址生成的一部分;其指定要被存储器访问的大小(N)缩放的位移因子-其中N是存储器访问中的字节的数目(例如,对于使用2
数据元素宽度字段1764-其内容区分若干个数据元素宽度中的哪一个要被使用(在一些实施例中是对于所有指令;在其他实施例中只对于指令中的一些)。此字段是可选的,因为在只有一个数据元素宽度受到支持和/或数据元素宽度是利用操作码的某个方面来受到支持的情况下,则不需要该字段。
写入掩码字段1770-其内容基于每数据元素位置来控制目标向量操作对象中的该数据元素位置是否反映基本操作和增强操作的结果。类别A指令模板支持合并-写入掩蔽,而类别B指令模板支持合并-写入掩蔽和归零-写入掩蔽两者。当合并时,向量掩码允许了目标中的任何元素集合被保护免于在(由基本操作和增强操作指定的)任何操作的执行期间的更新;在其他的一个实施例中,保留目标的相应的掩码比特具有0的每个元素的旧值。与之不同,归零向量掩码允许了目标中的任何元素集合在(由基本操作和增强操作指定的)任何操作的执行期间被归零;在一个实施例中,目标的元素在相应的掩码比特具有0值时被设置到0。此功能的子集是控制被执行的操作的向量长度(即,被修改的元素的跨度,从第一个到最后一个)的能力;然而,被修改的元素不是必须要连续。从而,写入掩码字段1770允许了部分向量操作,包括加载、存储、算术、逻辑等等。虽然描述了其中写入掩码字段1770的内容选择了若干个写入掩码寄存器中包含要使用的写入掩码的一个写入掩码寄存器(从而写入掩码字段1770的内容间接标识了那个要执行的掩蔽)的本发明实施例,但替换实施例作为替代或附加而允许掩码写入字段1770的内容直接指定要执行的掩蔽。
即时字段1772-其内容允许对即时(immediate)的指定。此字段是可选的,因为在不支持即时的通用向量友好格式的实现方式中该字段不存在并且在不使用即时的指令中该字段不存在。
类别字段1768-其内容区分指令的不同类别。参考图17A-17B,此字段的内容在类别A和类别B指令之间进行选择。在图17A-17B中,圆角方形被用于表明特定的值存在于一字段中(例如,分别在图17A-17B中针对类别字段1768的类别A 1768A和类别B 1768B)。
类别A的指令模板
在类别A的非存储器访问1705指令模板的情况下,阿尔法字段1752被解读为RS字段1752A,其内容区分不同的增强操作类型中的哪一个要被执行(例如,对于无存储器访问舍入型操作1710和无存储器访问数据变换型操作1715指令模板分别指定舍入1752A.1和数据变换1752A.2),而贝塔字段1754区分指定类型的操作中的哪一个要被执行。在无存储器访问1705指令模板中,缩放比例字段1760、位移字段1762A、和位移缩放比例字段1762B不存在。
无存储器访问指令模板-完全舍入控制型操作
在无存储器访问完全舍入控制型操作1710指令模板中,贝塔字段1754被解读为舍入控制字段1754A,其(一个或多个)内容提供静态舍入。虽然在本发明的描述实施例中舍入控制字段1754A包括抑制所有浮点异常(suppress all floating point exceptions,SAE)字段1756和舍入操作控制字段1758,但替换实施例可支持可将这两个概念都编码到同一字段中或者可只具有这些概念/字段中的一者或另一者(例如,可只具有舍入操作控制字段1758)。
SAE字段1756-其内容区分是否禁用异常事件报告;当SAE字段1756的内容指示抑制被启用时,给定的指令不报告任何种类的浮点异常标志并且不引发任何浮点异常处理程序。
舍入操作控制字段1758-其内容区分要执行一组舍入操作中的哪一个(例如,向上舍入、向下舍入、朝零舍入和朝最近舍入)。从而,舍入操作控制字段1758允许了基于每指令改变舍入模式。在其中处理器包括用于指定舍入模式的控制寄存器的本发明的一个实施例中,舍入操作控制字段1750的内容覆写该寄存器值。
无存储器访问指令模板-数据变换型操作
在无存储器访问数据变换型操作1715指令模板中,贝塔字段1754被解读为数据变换字段1754B,其内容区分若干个数据变换中的哪一个要被执行(例如,无数据变换、调配、广播)。
在类别A的存储器访问1720指令模板的情况下,阿尔法字段1752被解读为逐出提示字段1752B,其内容区分要使用逐出提示中的哪一个(在图17A中,对于存储器访问暂态1725指令模板和存储器访问非暂态1730指令模板分别指定暂态1752B.1和非暂态1752B.2),而贝塔字段1754被解读为数据操纵字段1754C,其内容区分若干个数据操纵操作(也称为基元)中的哪一个要被执行(例如,无操纵;广播;源的向上转换;以及目标的向下转换)。存储器访问1720指令模板包括缩放比例字段1760,并且可选地包括位移字段1762A或者位移缩放比例字段1762B。
向量存储器指令执行从存储器的向量加载和向存储器的向量存储,带有转换支持。与常规向量指令一样,向量存储器指令以按数据元素的方式从/向存储器传送数据,其中被实际传送的由元素向量掩码的内容来规定,该元素向量掩码被选择作为写入掩码。
存储器访问指令模板-暂态
暂态数据是可能很快就被再使用、快到足以受益于缓存的数据。然而,这是一提示,并且不同的处理器可按不同的方式实现它,包括完全忽略该提示。
存储器访问指令模板-非暂态
非暂态数据是这样的数据:该数据不太可能快到足以受益于在第1级缓存中进行缓存地被再使用,并且应当被赋予针对逐出的优先级。然而,这是一提示,并且不同的处理器可按不同的方式实现它,包括完全忽略该提示。
类别B的指令模板
在类别B的指令模板的情况下,阿尔法字段1752被解读为写入掩码控制(Z)字段1752C,其内容区分由写入掩码字段1770控制的写入掩蔽应当是合并还是归零。
在类别B的非存储器访问1705指令模板的情况下,贝塔字段1754的一部分被解读为RL字段1757A,其内容区分不同增强操作类型中的哪一个要被执行(例如,对于无存储器访问、写入掩码控制、部分舍入控制型操作1712指令模板和无存储器访问、写入掩码控制、VSIZE型操作1717指令模板分别指定舍入1757A.1和向量长度(VSIZE)1757A.2),而贝塔字段1754的其余部分区分所指定类型的操作中的哪一个要被执行。在无存储器访问1705指令模板中,缩放比例字段1760、位移字段1762A和位移缩放比例字段1762B不存在。
在无存储器访问、写入掩码控制、部分舍入控制型操作1710指令模板中,贝塔字段1754的其余部分被解读为舍入操作字段1759A并且异常事件报告被禁用(给定的指令不报告任何种类的浮点异常标志并且不引发任何浮点异常处理程序)。
舍入操作控制字段1759A-正如舍入操作控制字段1758一样,其内容区分要执行一组舍入操作中的哪一个(例如,向上舍入、向下舍入、朝零舍入和朝最近舍入)。从而,舍入操作控制字段1759A允许了基于每指令改变舍入模式。在其中处理器包括用于指定舍入模式的控制寄存器的本发明的一个实施例中,舍入操作控制字段1750的内容覆写该寄存器值。
在无存储器访问、写入掩码控制、VSIZE型操作1717指令模板中,贝塔字段1754的其余部分被解读为向量长度字段1759B,其内容区分要在若干个数据向量长度中的哪一个上执行(例如,128、256或512字节)。
在类别B的存储器访问1720指令模板的情况下,贝塔字段1754的一部分被解读为广播字段1757B,其内容区分是否要执行广播型数据操纵操作,而贝塔字段1754的其余部分被解读为向量长度字段1759B。存储器访问1720指令模板包括缩放比例字段1760,并且可选地包括位移字段1762A或者位移缩放比例字段1762B。
关于通用向量友好指令格式1700,完整操作码字段1774被示为包括格式字段1740、基本操作字段1742和数据元素宽度字段1764。虽然示出了其中完整操作码字段1774包括所有这些字段的一个实施例,但完整操作码字段1774在不支持所有这些字段的实施例中包括比所有这些字段更少的字段。完整操作码字段1774提供操作代码(操作码)。
增强操作字段1750、数据元素宽度字段1764、和写入掩码字段1770允许了这些特征在通用向量友好指令格式中基于每指令被指定。
写入掩码字段和数据元素宽度字段的组合创建了类型化指令,因为它们允许基于不同的数据元素宽度来应用掩码。
在类别A和类别B内找到的各种指令模板在不同的情形中是有益的。在本发明的一些实施例中,不同的处理器或处理器内不同的核心可只支持类别A、只支持类别B、或者支持两个类别。例如,打算用于通用计算的高性能通用无序核心可只支持类别B,打算主要用于图形和/或科学(吞吐量)计算的核心可只支持类别A,并且打算用于两者的核心可支持这两个类别(当然,具有来自两个类别的模板和指令的某种混合、但不具有来自两个类别的所有模板和指令的核心是在本发明的范围内的)。另外,单个处理器可包括多个核心,所有这些核心支持相同类别或者其中不同的核心支持不同的类别。例如,在具有分开的图形和通用核心的处理器中,打算主要用于图形和/或科学计算的图形核心之一可只支持类别A,而通用核心中的一个或多个可以是只支持类别B的、打算用于通用计算的高性能通用核心(具有无序执行和寄存器重命名)。不具有单独的图形核心的另一处理器可包括支持类别A和类别B两者的一个或多个通用有序或无序核心。当然,在本发明的不同实施例中,来自一个类别的特征也可被实现在另一类别中。以高级别语言编写的程序将被置于(例如,被及时编译或静态编译到)各种不同的可执行形式中,包括:1)只具有受到目标处理器支持的(一个或多个)类别的指令以便执行的形式;或者2)具有利用所有类别的指令的不同组合编写的替换例程并且具有控制流程代码的形式,该控制流程代码基于当前在执行代码的处理器所支持的指令来选择要执行的例程。
示范性特定向量友好指令格式
图18A-18C是根据本发明的实施例图示出示范性特定向量友好指令格式的框图。图18A示出了在如下意义上特定的特定向量友好指令格式1800:其指定字段的位置、大小、解读、和顺序,以及这些字段中的一些的值。特定向量友好指令格式1800可被用于扩展x86指令集,从而字段中的一些与现有的x86指令集及其扩展(例如,AVX)中使用的那些相似或相同。此格式与带有扩展的现有x86指令集的前缀编码字段、真实操作码字节字段、MOD R/M字段、SIB字段、位移字段、和即时字段保持一致。图示出了来自图18A-18C的字段所映射到的来自图17A-17B的字段。
应当理解,虽然出于说明的目的在通用向量友好指令格式1700的情境中参考特定向量友好指令格式1800描述本发明的实施例,但除非有声明,否则本发明不限于特定向量友好指令格式1800。例如,通用向量友好指令格式1700对于各种字段设想了各种可能的大小,而特定向量友好指令格式1800被示为具有特定大小的字段。作为具体示例,虽然数据元素宽度字段1764在特定向量友好指令格式1800中被示为一比特字段,但本发明不限于此(也就是说,通用向量友好指令格式1700设想了数据元素宽度字段1764的其他大小)。
通用向量友好指令格式1700包括按图18A中所示的顺序的下面列出的以下字段。
EVEX前缀(字节0-3)1802-被编码为四字节形式。
格式字段1740(EVEX字节0,比特[7:0])-第一字节(EVEX字节0)是格式字段1740并且其包含0x62(在本发明的一个实施例中用于区分向量友好指令格式的唯一值)。
第二-第四字节(EVEX字节1-3)包括提供特定能力的若干个比特字段。
REX字段1805(EVEX字节1,比特[7-5])-由EVEX.R比特字段(EVEX字节1,比特[7]-R)、EVEX.X比特字段(EVEX字节1,比特[6]-X)、和EVEX.B字节1,比特[5]-B)构成。EVEX.R、EVEX.X和EVEX.B比特字段提供与相应的VEX比特字段相同的功能,并且被利用反码(1scomplement)形式来编码,即,ZMM0被编码为1111B,ZMM15被编码为0000B。指令的其他字段如本领域中已知的那样对寄存器索引的较低三个比特进行编码(rrr、xxx和bbb),从而Rrrr、Xxxx和Bbbb可通过添加EVEX.R、EVEX.X和EVEX.B来被形成。
REX'字段1810-这是REX'字段1810的第一部分并且是用于对扩展32寄存器集合的高16或低16进行编码的EVEX.R'比特字段(EVEX字节1,比特[4]-R')。在本发明的一个实施例中,此比特以及如下所示的其他比特被以比特反转格式来存储以与BOUND指令相区分(在公知的x86 32比特模式中),BOUND指令的真实操作码字节是62,但不在MOD R/M字段(下文描述)中接受MOD字段中的11的值;本发明的替换实施例不以反转格式存储这个比特和下面指示的其他比特。值1被用于对低16寄存器编码。换言之,R'Rrrr是通过组合EVEX.R'、EVEX.R和来自其他字段的其他RRR来被形成的。
操作码映射字段1815(EVEX字节1,比特[3:0]-mmmm)-其内容编码了所暗示的主导操作码字节(0F、0F 38、或0F 3)。
数据元素宽度字段1764(EVEX字节2,比特[7]-W)-由符号EVEX.W表示。EVEX.W被用于定义数据类型的粒度(大小)(32比特数据元素或64比特数据元素)。
EVEX.vvvv 1820(EVEX字节2,比特[6:3]-vvvv)-EVEX.vvvv的作用可包括以下的:1)EVEX.vvvv编码了以反转(反码)形式指定的第一源寄存器操作对象,并且对于具有2个或更多个源操作对象的指令是有效的;2)EVEX.vvvv编码了对于某些向量移位以反码形式指定的目标寄存器操作对象;或者3)EVEX.vvvv不编码任何操作对象,该字段被预留并且应当包含1111b。从而,EVEX.vvvv字段1820编码了以反转(反码)形式存储的第一源寄存器指定符的4个低阶比特。取决于指令,一额外的不同EVEX比特字段被用于将指定符大小扩展到32寄存器。
EVEX.U 1768类别字段(EVEX字节2,比特[2]-U)-如果EVEX.U=0,则其指示类别A或EVEX.U0;如果EVEX.U=1,则其指示类别B或者EVEX.U1。
前缀编码字段1825(EVEX字节2,比特[1:0]-pp)-为基本操作字段提供额外比特。除了针对采取EVEX前缀格式的传统SSE指令提供支持以外,这还具有使SIMD前缀紧缩的益处(EVEX前缀只要求2个比特,而不是要求一字节来表达SIMD前缀)。在一个实施例中,为了支持使用采取传统格式和采取EVEX前缀格式两者的SIMD前缀(66H、F2H、F3H)的传统SSE指令,这些传统SIMD前缀被编码到SIMD前缀编码字段中;并且在运行时被扩展成传统SIMD前缀,然后才被提供到解码器的PLA(因此PLA可执行这些传统指令的传统和EVEX格式两者,而无需修改)。虽然较新的指令可直接使用EVEX前缀编码字段的内容作为操作码扩展,但某些实施例为了一致性以类似的方式扩展,但允许这些传统SIMD前缀指定不同的含义。替换实施例可重设计PLA来支持2比特SIMD前缀编码,从而不要求扩展。
阿尔法字段1752(EVEX字节3,比特[7]-EH;也称为EVEX.EH、EVEX.rs、EVEX.RL、EVEX.写入掩码控制、以及EVEX.N;也用α来图示)-如前所述,此字段是依情境而定的。
贝塔字段1754(EVEX字节3,比特[6:4]-SSS;也称为EVEX.S
REX'字段1810-这是REX'字段的剩余部分并且是可用于对扩展32寄存器集合的高16或低16进行编码的EVEX.V'比特字段(EVEX字节3,比特[3]-V')。此比特被以比特反转格式来存储。值1被用于对低16寄存器编码。换言之,V'VVVV是通过组合EVEX.V'、EVEX.vvvv来被形成的。
写入掩码字段1770(EVEX字节3,比特[2:0]-kkk)-其内容指定如前所述的写入掩码寄存器中的寄存器的索引。在本发明的一个实施例中,特定值EVEX.kkk=000具有暗示对于特定指令没有使用写入掩码的特殊行为(这可通过各种方式来实现,包括使用被硬连线到全一的写入掩码或者绕过掩蔽硬件的硬件)。
真实操作码字段1830(字节4)也被称为操作码字节。操作码的一部分在此字段中被指定。
MOD R/M字段1840(字节5)包括MOD字段1842、Reg字段1844、和R/M字段1846。如前所述,MOD字段1842的内容区分存储器访问和非存储器访问操作。Reg字段1844的作用可被总结成两个情形:编码目标寄存器操作对象或者源寄存器操作对象,或者被作为操作码扩展来对待并且不被用于编码任何指令操作对象。R/M字段1846的作用可包括以下的:编码引用存储器地址的指令操作对象,或者编码目标寄存器操作对象或源寄存器操作对象。
缩放比例、索引、基数(Scale,Index,Base,SIB)字节(字节6)-如前所述,缩放比例字段1850的内容被用于存储器地址生成。SIB.xxx 1854和SIB.bbb 1856-先前已关于寄存器索引Xxxx和Bbbb提及了这些字段的内容。
位移字段1762A(字节7-10)-当MOD字段1842包含10时,字节7-10是位移字段1762A,并且其工作方式与传统32比特位移(disp32)相同并且以字节粒度工作。
位移因子字段1762B(字节7)-当MOD字段1842包含01时,字节7是位移因子字段1762B。此字段的位置与传统x86指令集8比特位移(disp8)的相同,其以字节粒度工作。由于disp8被符号扩展,所以其只能在-128和127字节偏移量之间寻址;就64字节缓存线而言,disp8使用8个比特,这8个比特可被设置到仅四个真正有用的值-128、-64、0和64;由于经常需要更大的范围,所以使用disp32;然而,disp32要求4个字节。与disp8和disp32不同,位移因子字段1762B是对disp8的重解读;当使用位移因子字段1762B时,实际位移由位移因子字段的内容乘以存储器操作对象访问的大小(N)来确定。这种类型的位移被称为disp8*N。这减小了平均指令长度(单个字节被用于位移,但具有大得多的范围)。这种压缩的位移是基于如下假设的:有效位移是存储器访问的粒度的倍数,并且因此,地址偏移量的冗余低阶比特不需要被编码。换言之,位移因子字段1762B代替了传统x86指令集8比特位移。从而,位移因子字段1762B被按与x86指令集8比特位移相同的方式编码(因此在ModRM/SIB编码规则中没有变化),唯一例外是disp8被超载到disp8*N。换言之,在编码规则或编码长度方面没有变化,而只在硬件对位移值的解读方面有变化(硬件需要按存储器操作对象的大小来缩放位移以获得按字节的地址偏移量)。即时字段1772如前所述那样操作。
完整操作码字段
图18B是根据本发明的一个实施例图示出构成完整操作码字段1774的特定向量友好指令格式1800的字段的框图。具体而言,完整操作码字段1774包括格式字段1740、基本操作字段1742、和数据元素宽度(W)字段1764。基本操作字段1742包括前缀编码字段1825、操作码映射字段1815、和真实操作码字段1830。
寄存器索引字段
图18C是根据本发明的一个实施例图示出构成寄存器索引字段1744的特定向量友好指令格式1800的字段的框图。具体而言,寄存器索引字段1744包括REX字段1805、REX'字段1810、MODR/M.reg字段1844、MODR/M.r/m字段1846、VVVV字段1820、xxx字段1854、和bbb字段1856。
增强操作字段
图18D是根据本发明的一个实施例图示出构成增强操作字段1750的特定向量友好指令格式1800的字段的框图。当类别(U)字段1768包含0时,其表示EVEX.U0(类别A 1768A);当其包含1时,其表示EVEX.U1(类别B 1768B)。当U=0并且MOD字段1842包含11时(表示无存储器访问操作),阿尔法字段1752(EVEX字节3,比特[7]-EH)被解读为rs字段1752A。当rs字段1752A包含1时(舍入1752A.1),贝塔字段1754(EVEX字节3,比特[6:4]-SSS)被解读为舍入控制字段1754A。舍入控制字段1754A包括一比特SAE字段1756和两比特舍入操作字段1758。当rs字段1752A包含0时(数据变换1752A.2),贝塔字段1754(EVEX字节3,比特[6:4]-SSS)被解读为三比特数据变换字段1754B。当U=0并且MOD字段1842包含00、01或10时(表示存储器访问操作),阿尔法字段1752(EVEX字节3,比特[7]-EH)被解读为逐出提示(eviction hint,EH)字段1752B并且贝塔字段1754(EVEX字节3,比特[6:4]-SSS)被解读为三比特数据操纵字段1754C。
当U=1时,阿尔法字段1752(EVEX字节3,比特[7]-EH)被解读为写入掩码控制(Z)字段1752C。当U=1并且MOD字段1842包含11时(表示无存储器访问操作),贝塔字段1754的一部分(EVEX字节3,比特[4]-S
示范性寄存器体系结构
图19是根据本发明的一个实施例的寄存器体系结构1900的框图。在图示的实施例中,存在32个512比特宽的向量寄存器1910;这些寄存器被称为zmm0至zmm31。低16zmm寄存器的低阶256比特被覆盖在寄存器ymm0-16上。低16zmm寄存器的低阶128比特(ymm寄存器的低阶128比特)被覆盖在寄存器xmm0-15上。特定向量友好指令格式1800如以下表格中所示在这些覆盖的寄存器文件上进行操作。
换言之,向量长度字段1759B在最大长度和一个或多个其他更短长度之间做出选择,其中每个这种更短长度是前一长度的一半长度;并且没有向量长度字段1759B的指令模板按最大向量长度进行操作。另外,在一个实施例中,特定向量友好指令格式1800的类别B指令模板在紧缩或标量单/双精度浮点数据和紧缩或标量整数数据上进行操作。标量操作是在zmm/ymm/xmm寄存器中的最低阶数据元素位置上执行的操作;更高阶数据元素位置或者被保持与其在该指令之前相同,或者被归零,这取决于实施例。
写入掩码寄存器1915-在图示的实施例中,有8个写入掩码寄存器(k0至k7),每个的大小是64比特。在替换实施例中,写入掩码寄存器1915的大小是16比特。如前所述,在本发明的一个实施例中,向量掩码寄存器k0不能被用作写入掩码;当通常将会指示k0的编码被用于写入掩码时,其选择硬连线的写入掩码0xFFFF,这实际上针对该指令禁用了写入掩蔽。
通用寄存器1925-在图示的实施例中,有十六个64比特通用寄存器,它们与现有的x86寻址模式一起被用于寻址存储器操作对象。这些寄存器被用名称RAX、RBX、RCX、RDX、RBP、RSI、RDI、RSP以及R8至R15来引用。
标量浮点堆栈寄存器文件(x87堆栈)1945(MMX紧缩整数平坦寄存器文件1950在其上被化名)-在图示的实施例中,x87堆栈是用于利用x87指令集扩展在32/64/80比特浮点数据上执行标量浮点操作的八元素堆栈;而MMX寄存器被用于在64比特紧缩整数数据上执行操作,以及针对在MMX和XMM寄存器之间执行的一些操作保持操作对象。
本发明的替换实施例可使用更宽或更窄的寄存器。此外,本发明的替换实施例可使用更多、更少或不同的寄存器文件和寄存器。
示范性核心体系结构、处理器和计算机体系结构
处理器核心可按不同的方式、为了不同的目的、在不同的处理器中被实现。例如,这种核心的实现方式可包括:1)打算用于通用计算的通用有序核心;2)打算用于通用计算的高性能通用无序核心;3)主要打算用于图形和/或科学(吞吐量)计算的专用核心。不同处理器的实现方式可包括:1)包括打算用于通用计算的一个或多个通用有序核心和/或打算用于通用计算的一个或多个通用无序核心的CPU;以及2)包括主要打算用于图形和/或科学(吞吐量)的一个或多个专用核心的协处理器。这样的不同处理器导致不同的计算机系统体系结构,这些体系结构可包括:1)协处理器在与CPU分开的芯片上;2)协处理器在与CPU相同的封装中、分开的管芯上;3)协处理器与CPU在同一管芯上(在此情况下,这种协处理器有时被称为专用逻辑,例如集成图形和/或科学(吞吐量)逻辑,或者被称为专用核心);以及4)片上系统,其可在同一管芯上包括所描述的CPU(有时称为(一个或多个)应用核心或者(一个或多个)应用处理器)、上述的协处理器以及额外的功能。接下来描述示范性核心体系结构,然后是对示范性处理器和计算机体系结构的描述。
示范性核心体系结构
有序和无序核心框图
图20A是根据本发明的实施例图示出示范性有序管线和示范性寄存器重命名、无序发出/执行管线两者的框图。图20B是根据本发明的实施例图示出要被包括在处理器中的有序体系结构核心的示范性实施例和示范性寄存器重命名、无序发出/执行体系结构核心两者的框图。图20A-20B中的实线框图示了有序管线和有序核心,而虚线框的可选添加图示了寄存器重命名、无序发出/执行管线和核心。考虑到有序方面是无序方面的子集,将描述无序方面。
在图20A中,处理器管线2000包括取得阶段2002、长度解码阶段2004、解码阶段2006、分配阶段2008、重命名阶段2010、调度(也称为调遣或发出)阶段2012、寄存器读取/存储器读取阶段2014、执行阶段2016、写回/存储器写入阶段2018、异常处理阶段2022和提交阶段2024。
图20B示出了处理器核心2090包括耦合到执行引擎单元2050的前端单元2030,并且两者都耦合到存储器单元2070。核心2090可以是精简指令集计算(reduced instructionset computing,RISC)核心、复杂指令集计算(complex instruction set computing,CISC)核心、超长指令字(very long instruction word,VLIW)核心、或者混合或替换核心类型。作为另外一个选项,核心2090可以是专用核心,例如,网络或通信核心、压缩引擎、协处理器核心、通用计算图形处理单元(general purpose computing graphics processingunit,GPGPU)核心、图形核心,等等。
前端单元2030包括分支预测单元2032,其耦合到指令缓存单元2034,指令缓存单元2034耦合到指令转化后备缓冲器(translation lookaside buffer,TLB)2036,该TLB2036耦合到指令取得单元2038,该指令取得单元2038耦合到解码单元2040。解码单元2040(或解码器)可对指令解码,并且生成一个或多个微操作、微代码入口点、微指令、其他指令或其他控制信号作为输出,这些微操作、微代码入口点、微指令、其他指令或其他控制信号是从原始指令解码来的,或者以其他方式反映原始指令,或者是从原始指令得出的。解码单元2040可利用各种不同的机制来被实现。适当机制的示例包括但不限于查找表、硬件实现、可编程逻辑阵列(programmable logic array,PLA)、微代码只读存储器(read onlymemory,ROM),等等。在一个实施例中,核心2090包括微代码ROM或其他介质,其为某些宏指令存储微代码(例如,在解码单元2040中或者以其他方式在前端单元2030内)。解码单元2040耦合到执行引擎单元2050中的重命名/分配器单元2052。
执行引擎单元2050包括耦合到引退单元2054和一组一个或多个调度器单元2056的重命名/分配器单元2052。(一个或多个)调度器单元2056表示任何数目的不同调度器,包括预留站、中央指令窗口等等。(一个或多个)调度器单元2056耦合到(一个或多个)物理寄存器文件单元2058。物理寄存器文件单元2058中的每一者表示一个或多个物理寄存器文件,这些物理寄存器文件中的不同物理寄存器文件存储一个或多个不同的数据类型,例如标量整数、标量浮点、紧缩整数、紧缩浮点、向量整数、向量浮点、状态(例如,作为要执行的下一指令的地址的指令指针),等等。在一个实施例中,物理寄存器文件单元2058包括向量寄存器单元、写入掩码寄存器单元、和标量寄存器单元。这些寄存器单元可提供体系结构式向量寄存器、向量掩码寄存器、和通用寄存器。(一个或多个)物理寄存器文件单元2058与引退单元2054重叠以示出可用来实现寄存器重命名和无序执行的各种方式(例如,利用(一个或多个)重排序缓冲器和(一个或多个)引退寄存器文件;利用(一个或多个)未来文件、(一个或多个)历史缓冲器、和(一个或多个)引退寄存器文件;利用寄存器图谱和寄存器的池;等等)。引退单元2054和(一个或多个)物理寄存器文件单元2058耦合到(一个或多个)执行集群2060。(一个或多个)执行集群2060包括一组一个或多个执行单元2062和一组一个或多个存储器访问单元2064。执行单元2062可在各种类型的数据(例如,标量浮点、紧缩整数、紧缩浮点、向量整数、向量浮点)上执行各种操作(例如,移位、加法、减法、乘法)。虽然一些实施例可包括专用于特定功能或功能集合的若干个执行单元,但其他实施例可只包括一个执行单元或者全部执行所有功能的多个执行单元。(一个或多个)调度器单元2056、(一个或多个)物理寄存器文件单元2058、和(一个或多个)执行集群2060被示为可能是多个,因为某些实施例为某些类型的数据/操作创建单独的管线(例如,标量整数管线、标量浮点/紧缩整数/紧缩浮点/向量整数/向量浮点管线和/或存储器访问管线,它们各自具有其自己的调度器单元、物理寄存器文件单元和/或执行集群-并且在单独的存储器访问管线的情况下,实现了某些实施例,其中只有此管线的执行集群具有(一个或多个)存储器访问单元2064)。还应当理解,在使用分开管线的情况下,这些管线中的一个或多个可以是无序发出/执行,并且其余的是有序的。
存储器访问单元2064的集合耦合到存储器单元2070,存储器单元2070包括数据TLB单元2072,数据TLB单元2072耦合到数据缓存单元2074,数据缓存单元2074耦合到第2级(L2)缓存单元2076。在一个示范性实施例中,存储器访问单元2064可包括加载单元、存储地址单元和存储数据单元,它们中的每一者耦合到存储器单元2070中的数据TLB单元2072。指令缓存单元2034进一步耦合到存储器单元2070中的第2级(L2)缓存单元2076。L2缓存单元2076耦合到一个或多个其他级别的缓存并且最终耦合到主存储器。
作为示例,示范性寄存器重命名、无序发出/执行核心体系结构可实现管线2000如下:1)指令取得2038执行取得和长度解码阶段2002和2004;2)解码单元2040执行解码阶段2006;3)重命名/分配器单元2052执行分配阶段2008和重命名阶段2010;4)(一个或多个)调度器单元2056执行调度阶段2012;5)(一个或多个)物理寄存器文件单元2058和存储器单元2070执行寄存器读取/存储器读取阶段2014;执行集群2060执行执行阶段2016;6)存储器单元2070和(一个或多个)物理寄存器文件单元2058执行写回/存储器写入阶段2018;7)在异常处理阶段2022中可涉及各种单元;并且8)引退单元2054和(一个或多个)物理寄存器文件单元2058执行提交阶段2024。
核心2090可支持一个或多个指令集(例如,x86指令集(带有已随着较新版本添加的一些扩展);加州森尼维尔市的MIPS技术公司的MIPS指令集;加州森尼维尔市的ARM控股公司的ARM指令集(带有可选的额外扩展,例如NEON)),包括本文描述的(一个或多个)指令。在一个实施例中,核心2090包括逻辑来支持紧缩数据指令集扩展(例如,AVX1、AVX2),从而允许了被许多多媒体应用使用的操作被利用紧缩数据来执行。
应当理解,核心可支持多线程处理(执行操作或线程的两个或更多个并行集合),并且可按各种方式来支持多线程处理,包括时间切片式多线程处理、同时多线程处理(其中单个物理核心针对该物理核心在同时多线程处理的每个线程提供逻辑核心),或者这些的组合(例如,时间切片式取得和解码,然后是同时多线程处理,例如像
虽然寄存器重命名是在无序执行的情境中描述的,但应当理解寄存器重命名可用在有序体系结构中。虽然处理器的图示实施例还包括分开的指令和数据缓存单元2034/2074和共享的L2缓存单元2076,但替换实施例可针对指令和数据两者具有单个内部缓存,例如,第1级(L1)内部缓存或者多级别的内部缓存。在一些实施例中,系统可包括内部缓存与在核心和/或处理器外部的外部缓存的组合。或者,所有缓存可在核心和/或处理器外部。
具体示范性有序核心体系结构
图21A-21B图示出更具体的示范性有序核心体系结构的框图,该核心将是芯片中的若干个逻辑块(包括相同类型和/或不同类型的其他核心)之一。逻辑块通过高带宽互连网络(例如,环状网络)与某些固定功能逻辑、存储器I/O接口和其他必要I/O逻辑通信,这取决于应用。
图21A是根据本发明的实施例的单个处理器核心及其与片上互连网络2102以及与其第2级(L2)缓存本地子集2104的连接的框图。在一个实施例中,指令解码器2100支持具有紧缩数据指令集扩展的x86指令集。L1缓存2106允许低时延访问以将存储器缓存到标量和向量单元中。虽然在一个实施例中(为了简化设计),标量单元2108和向量单元2110使用分开的寄存器集合(分别是标量寄存器2112和向量寄存器2114)并且在它们之间传送的数据被写入到存储器,然后被从第1级(L1)缓存2106读回,但本发明的替换实施例可使用不同的方案(例如,使用单个寄存器集合或者包括允许数据在两个寄存器文件之间传送而不被写入和读回的通信路径)。
L2缓存的本地子集2104是全局L2缓存的一部分,全局L2缓存被划分成单独的本地子集,每处理器核心有一个。每个处理器核心具有到其自己的L2缓存本地子集2104的直接访问路径。处理器核心所读取的数据被存储在其L2缓存子集2104中并且可被迅速访问,所述访问与其他处理器核心访问其自己的本地L2缓存子集并行进行。处理器核心所写入的数据被存储在其自己的L2缓存子集2104中并且在必要时被从其他子集冲刷出。环状网络确保了共享数据的一致性。环状网络是双向的,以允许诸如处理器核心、L2缓存和其他逻辑块之类的代理在芯片内与彼此通信。每个环状数据路径在每方向上是1012比特宽的。
图21B是根据本发明的实施例的图21A中的处理器核心的一部分的扩展视图。图21B包括L1缓存2104的L1数据缓存2106A部分,以及关于向量单元2110和向量寄存器2114的更多细节。具体而言,向量单元2110是16宽向量处理单元(vector processing unit,VPU)(参见16宽ALU2128),其执行整数、单精度浮点和双精度浮点指令中的一个或多个。VPU支持利用调配单元2120调配寄存器输入,利用数值转换单元2122A-B进行的数值转换,以及利用复制单元2124对存储器输入进行的复制。写入掩码寄存器2126允许断言结果向量写入。
图22是根据本发明的实施例的处理器2200的框图,处理器2200可具有多于一个核心,可具有集成的存储器控制器并且可具有集成的图形。图22中的实线框图示了具有单个核心2202A、系统代理2210和一组一个或多个总线控制器单元2216的处理器2200,而虚线框的可选添加图示了具有多个核心2202A-N、系统代理单元2210中的一组一个或多个集成存储器控制单元2214、以及专用逻辑2208的替换处理器2200。
从而,处理器2200的不同实现方式可包括:1)其中专用逻辑2208是集成图形和/或科学(吞吐量)逻辑(其可包括一个或多个核心)并且核心2202A-N是一个或多个通用核心(例如,通用有序核心、通用无序核心或者两者的组合)的CPU;2)其中核心2202A-N是大量的主要打算用于图形和/或科学(吞吐量)的专用核心的协处理器;以及3)其中核心2202A-N是大量的通用有序核心的协处理器。从而,处理器2200可以是通用处理器、协处理器或专用处理器,例如,网络或通信处理器、压缩引擎、图形处理器、GPGPU(通用图形处理单元)、高吞吐量集成众核(many integrated core,MIC)协处理器(包括30个或更多个核心)、嵌入式处理器,等等。处理器可被实现在一个或多个芯片上。处理器2200可以是一个或多个基片的一部分和/或可利用若干个工艺技术中的任何一者被实现在一个或多个基片上,这些技术例如是BiCMOS、CMOS或NMOS。
存储器层次体系包括核心内的一级或多级缓存、一组或一个或多个共享缓存单元2206、以及耦合到该组集成存储器控制器单元2214的外部存储器(未示出)。该组共享缓存单元2206可包括一个或多个中间级别缓存(例如第2级(L2)、第3级(L3)、第4级(4)或其他级别的缓存),最后一级缓存(last level cache,LLC),和/或这些的组合。虽然在一个实施例中基于环的互连单元2212互连集成图形逻辑2208、该组共享缓存单元2206和系统代理单元2210/(一个或多个)集成存储器控制器单元2214,但替换实施例也可使用任何数目的公知技术来互连这种单元。在一个实施例中,在一个或多个缓存单元2206和核心2202A-N之间维持一致性。
在一些实施例中,核心2202A-N中的一个或多个能够进行多线程处理。系统代理2210包括协调和操作核心2202A-N的那些组件。系统代理单元2210可包括例如功率控制单元(power control unit,PCU)和显示单元。PCU可以是或者可以包括对核心2202A-N和集成图形逻辑2208的功率状态进行调节所需要的逻辑和组件。显示单元用于驱动一个或多个外部连接的显示器。
核心2202A-N就体系结构指令集而言可以是同构的或者异构的;也就是说,核心2202A-N中的两个或更多个可以能够执行同一指令集,而其他的核心可以能够只执行该指令集的子集或者不同的指令集。
示范性计算机体系结构
图23-图24是示范性计算机体系结构的框图。本领域中已知的用于膝上型计算机、桌面型计算机、手持PC、个人数字助理、工程工作站、服务器、网络设备、网络集线器、交换机、嵌入式处理器、数字信号处理器(digital signal processor,DSP)、图形设备、视频游戏设备、机顶盒、微控制器、蜂窝电话、便携式媒体播放器、手持设备、和各种其他电子设备的其他系统设计和配置也是适当的。总之,能够包含本文公开的处理器和/或其他执行逻辑的各种各样的系统或电子设备一般是适当的。
现在参考图23,示出了根据本发明的一个实施例的系统2300的框图。系统2300可包括一个或多个处理器2310、2315,它们耦合到控制器中枢2320。在一个实施例中,控制器中枢2320包括图形存储器控制器中枢(graphics memory controller hub,GMCH)2390和输入/输出中枢(Input/Output Hub,IOH)2350(它们可在分开的芯片上);GMCH 2390包括与存储器2340和协处理器2345耦合的存储器和图形控制器;IOH2350将输入/输出(I/O)设备2360耦合到GMCH 2390。或者,存储器和图形控制器中的一者或两者被集成在处理器内(如本文所述),存储器2340和协处理器2345直接耦合到处理器2310,并且控制器中枢2320与IOH 2350在单个芯片中。
额外的处理器2315的可选性在图23中用虚线表示。每个处理器2310、2315可包括本文描述的处理核心中的一个或多个并且可以是处理器2200的某个版本。
存储器2340可例如是动态随机访问存储器(dynamic random access memory,DRAM)、相变存储器(phase change memory,PCM)、或者两者的组合。对于至少一个实施例,控制器中枢2320经由多点分支总线(例如前端总线(frontside bus,FSB))、点到点接口(例如QuickPath互连(QuickPath Interconnect,QPI))、或者类似的连接2395与(一个或多个)处理器2310、2315通信。
在一个实施例中,协处理器2345是专用处理器,例如,高吞吐量MIC处理器、网络或通信处理器、压缩引擎、图形处理器、GPGPU、嵌入式处理器,等等。在一个实施例中,控制器中枢2320可包括集成的图形加速器。
在物理资源2310、2315之间,就包括体系结构特性、微体系结构特性、热特性、功率消耗特性等等在内的价值度量的范围而言可以有各种差异。
在一个实施例中,处理器2310执行控制一般类型的数据处理操作的指令。嵌入在这些指令内的可以是协处理器指令。处理器2310将这些协处理器指令识别为应当由附接的协处理器2345执行的类型。因此,处理器2310在协处理器总线或其他互连上向协处理器2345发出这些协处理器指令(或者表示协处理器指令的控制信号)。(一个或多个)协处理器2345接受并执行接收到的协处理器指令。
现在参考图24,其中示出了根据本发明的实施例的SoC 2400的框图。图22中的相似元素带有相似的标号。另外,虚线框是更先进SoC上的可选特征。在图24中,(一个或多个)互连单元2402耦合到:应用处理器2410,其包括一组一个或多个核心202A-N和(一个或多个)共享缓存单元2206;系统代理单元2210;(一个或多个)总线控制器单元2216;(一个或多个)集成存储器控制器单元2214;一组或一个或多个协处理器2420,其可包括集成图形逻辑、图像处理器、音频处理器、和视频处理器;静态随机访问存储器(static random accessmemory,SRAM)单元2430;直接存储器访问(direct memory access,DMA)单元2432;以及显示单元2440,用于耦合到一个或多个外部显示器。在一个实施例中,(一个或多个)协处理器2420包括专用处理器,例如网络或通信处理器、压缩引擎、GPGPU、高吞吐量MIC处理器、嵌入式处理器,等等。
本文公开的机制的实施例可以用硬件、软件、固件或者这种实现方案的组合来实现。本发明的实施例可被实现为在包括至少一个处理器、存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备、和至少一个输出设备的可编程系统上执行的计算机程序或程序代码。
程序代码可被应用到输入指令以执行本文描述的功能并且生成输出信息。输出信息可按已知的方式被应用到一个或多个输出设备。对于本申请而言,处理系统包括任何具有处理器的系统,例如;数字信号处理器(digital signal processor,DSP)、微控制器、专用集成电路(application specific integrated circuit,ASIC)或者微处理器。
程序代码可以用高级过程式或面向对象的编程语言来被实现以与处理系统通信。如果希望,程序代码也可以用汇编或机器语言来实现。实际上,本文描述的机制在范围上不限于任何特定的编程语言。在任何情况下,该语言可以是经编译或者解译的语言。
至少一个实施例的一个或多个方面可由被存储在机器可读介质上的表示处理器内的各种逻辑的代表性指令实现,这些代表性指令当被机器读取时使得该机器制作逻辑来执行本文描述的技术。这种被称为“IP核心”的表现形式可被存储在有形机器可读介质上并且被提供到各种客户或制造设施以加载到实际制作该逻辑或处理器的制作机器中。
这种机器可读存储介质可包括但不限于由机器或设备制造或形成的物品的非暂态有形布置,包括诸如以下项之类的存储介质:硬盘,任何其他类型的盘(包括软盘、光盘、致密盘只读存储器(compact disk read-only memory,CD-ROM)、可改写致密盘(compactdisk rewritable,CD-RW)、和磁光盘),半导体设备(诸如,只读存储器(read-only memory,ROM),诸如动态随机访问存储器(dynamic random access memory,DRAM)、静态随机访问存储器(static random access memory,SRAM)之类的随机访问存储器(random accessmemory,RAM),可擦除可编程只读存储器(erasable programmable read-only memory,EPROM),闪速存储器,电可擦除可编程只读存储器(electrically erasable programmableread-only memory,EEPROM),相变存储器(phase change memory,PCM)),磁卡或光卡,或者适合用于存储电子指令的任何其他类型的介质。
因此,本发明的实施例还包括非暂态有形机器可读介质,其包含指令或者包含定义本文描述的结构、电路、装置、处理器和/或系统特征的设计数据,例如硬件描述语言(Hardware Description Language,HDL)。这种实施例也可被称为程序产品。
仿真(包括二进制转化、代码变形等等)
在一些情况下,指令转换器可用于将指令从源指令集转换到目标指令集。例如,指令转换器可将指令转化(例如,利用静态二进制转化、包括动态编译的动态二进制转化)、变形、仿真或以其他方式转换到要被核心处理的一个或多个其他指令。指令转换器可以用软件、硬件、固件或者其组合来实现。指令转换器可以在处理器上、在处理器外、或者一部分在处理器上一部分在处理器外。
图25是根据本发明的实施例与使用软件指令转换器来将源指令集中的二进制指令转换成目标指令集中的二进制指令相对比的框图。在图示的实施例中,指令转换器是软件指令转换器,虽然可替换地,指令转换器可以用软件、固件、硬件或者其各种组合来被实现。图25示出了高级别语言2502的程序可被利用x86编译器2504来编译以生成x86二进制代码2506,x86二进制代码2506可由具有至少一个x86指令集核心2516的处理器原生执行。具有至少一个x86指令集核心2516的处理器表示任何这样的处理器:这种处理器可通过兼容地执行或以其他方式处理(1)英特尔x86指令集核心的指令集的实质部分或者(2)目标为在具有至少一个x86指令集核心的英特尔处理器上运行的应用或其他软件的目标代码版本,来执行与具有至少一个x86指令集核心的英特尔处理器基本上相同的功能,以便实现与具有至少一个x86指令集核心的英特尔处理器基本上相同的结果。x86编译器2504表示可操作来生成x86二进制代码2506(例如,目标代码)的编译器,x86二进制代码2506在带有或不带有额外的链接处理的情况下可在具有至少一个x86指令集核心的处理器2516上被执行。类似地,图25示出了高级别语言2502的程序可被利用替换指令集编译器2508来编译以生成替换指令集二进制代码2510,替换指令集二进制代码2510可由没有至少一个x86指令集核心的处理器2514(例如,具有执行加州森尼维尔市的MIPS技术公司的MIPS指令集和/或执行加州森尼维尔市的ARM控股公司的ARM指令集的核心的处理器)原生执行。指令转换器2512用于将x86二进制代码2506转换成可由没有x86指令集核心的处理器2514原生执行的代码。这个转换后的代码不太可能与替换指令集二进制代码2510相同,因为能够做到这一点的指令转换器是难以制作的;然而,转换后的代码将实现一般操作并且由来自替换指令集的指令构成。从而,指令转换器2512表示通过仿真、模拟或任何其他过程允许不具有x86指令集处理器或核心的处理器或其他电子设备执行x86二进制代码2506的软件、固件、硬件或者其组合。
用于调整显示设备的刷新率的逻辑
现在参考图26,示出了根据一个或多个实施例的系统2600的框图。在一些实施例中,系统2600可以是电子设备或组件的全部或一部分。例如,系统2600可以是蜂窝电话、计算机、服务器、网络设备、片上系统(SoC)、控制器、无线收发器、可穿戴设备,等等。此外,在一些实施例中,系统2600可以是相关的或互连的设备的分组的一部分,例如数据中心、计算集群,等等。
如图26所示,系统2600可包括与(一个或多个)输入设备2640和显示设备2650耦合的计算设备2610。另外,虽然在图26中没有示出,但系统2600可包括其他组件。(一个或多个)输入设备2640可允许用户向计算设备2610(例如,键盘、计算机鼠标、操纵杆、触摸屏、语音界面、手势界面,等等)提供输入。显示设备2650可以是可呈现视频和其他图像内容的设备(例如,监视器、电视、投影仪,等等)。如图所示,在一些实施例中,(一个或多个)输入设备2640和显示设备2650可以在计算设备2610的外部。然而,在其他实施例中,(一个或多个)输入设备2640和/或显示设备2650可被包括在计算设备2610中。
在一个或多个实施例中,计算设备2610可包括一个或多个处理器2620和存储器2630。存储器2630可以用任何(一个或多个)类型的计算机存储器(例如,动态随机访问存储器(DRAM)、静态随机访问存储器(SRAM)、非易失性存储器(NVM)、DRAM和NVM的组合,等等)来实现。处理器2620可以是硬件处理设备(例如,中央处理单元(CPU)、片上系统(SoC),等等)。
在一个或多个实施例中,存储器2630可包括自适应刷新逻辑2635,以动态地调整显示设备2650的刷新率。例如,自适应刷新逻辑2635可在检测到(一个或多个)输入设备2640至少在最小时间段内都没有接收到任何用户输入时降低显示设备2650的刷新率。另外,自适应刷新逻辑2635可在检测到被显示在显示设备2650上的帧的被更新部分低于最小尺寸时降低刷新率。此外,自适应刷新逻辑2635可在检测到所显示的帧被更新的率小于刷新率时降低刷新率。下面参考图27-33进一步描述自适应刷新逻辑2635的功能。
在一些实施例中,自适应刷新逻辑2635可被实现为软件指令(例如,可由(一个或多个)处理器2620执行)。例如,自适应刷新逻辑2635可在计算设备2610的操作系统中被实现。然而,实施例在这个方面不受限制。例如,在一些实施例中,自适应刷新逻辑2635可被实现在其他软件(例如,图形驱动、应用)、硬件(例如,处理器2620、计算设备2610、显示设备2650、显示引擎、图形处理器、外部设备)等等中。
现在参考图27,示出了根据一个或多个实施例的方法2700的流程图。在各种实施例中,方法2700可由处理逻辑来执行,处理逻辑可包括硬件(例如,处理设备、电路、专用逻辑、可编程逻辑、微代码,等等)、软件(例如,在处理设备上运行的指令)、或者其组合。在一些实现方式中,方法2700可利用图26中所示的一个或多个组件(例如,自适应刷新逻辑2635、(一个或多个)处理器2620,等等)来被执行。在固件或软件实施例中,方法2700可由存储在非暂态机器可读介质(例如光学、半导体或磁性存储设备)中的计算机执行指令来实现。为了说明起见,下文可参考图26和图28来描述方法2700中涉及的动作,图26和图28示出了根据一个或多个实施例的示例。然而,本文论述的各种实施例的范围在这个方面不受限制。
方框2710可包括确定自从上次用户交互以来所经过的时间。例如,参考图26,自适应刷新逻辑2635可确定自从经由(一个或多个)输入设备2640接收的上次输入(例如,键盘输入、鼠标移动、语音命令,等等)以来所经过的时间。在一个或多个实施例中,自适应刷新逻辑2635可在计算设备2610的操作系统中实现。
方框2720可包括确定帧中的被更新区域的尺寸。例如,参考图26,自适应刷新逻辑2635可确定显示设备2650上的正在帧之间被改变的图像区域或部分的尺寸。在一个或多个实施例中,被更新区域的尺寸可被定义为绝对值(例如,10乘20像素)或者相对比例(例如,百分之25、四分之一、0.25,等等)。
方框2730可包括确定屏幕更新的均一(uniform)频率。例如,参考图26,自适应刷新逻辑2635可确定如下的均一频率(即,以相同的间隔被重复):显示设备2650上所显示的帧以该频率被修改以包括新的图像内容。
菱形2740可包括确定自从上次用户交互以来所经过的时间是否超过时间阈值。例如,参考图26,自适应刷新逻辑2635可确定自从经由(一个或多个)输入设备2640接收的上次输入以来所经过的时间是否大于所存储的时间阈值(例如,100毫秒)。如果在菱形2740处确定自从上次用户交互以来所经过的时间不超过时间阈值,则方法2700在菱形2780处继续进行(如下所述)。然而,如果在菱形2740处确定所经过的时间超过了时间阈值,则方法2700在菱形2750处继续。
菱形2750可包括确定被更新区域的尺寸是否低于尺寸阈值。在一些实施例中,尺寸阈值可被指定为全帧尺寸的百分比。例如,参考图26,自适应刷新逻辑2635可确定所显示图像的在帧之间被更新的部分是否小于尺寸阈值(例如,一定义的百分比)。如果在菱形2750处确定被更新区域的尺寸低于尺寸阈值,则方法2700在菱形2770处继续(如下所述)。然而,如果在菱形2750处确定被更新区域的尺寸不低于尺寸阈值,则方法2700在菱形2760处继续。
菱形2760可包括确定屏幕更新的均一频率是否低于当前刷新率。例如,参考图26,自适应刷新逻辑2635可确定显示帧正以低于显示设备2650的当前刷新率的均一率被更新。
如果在菱形2760处确定屏幕更新的均一频率低于当前刷新率,或者如果在菱形2750处确定被更新区域的尺寸低于尺寸阈值,那么在菱形2770处,确定显示设备当前是否处于目标降低刷新率。如果在菱形2770处确定显示设备当前不处于目标降低刷新率,那么在方框2775处,刷新率被设置为目标降低刷新率。在设置目标降低刷新率之后,方法2700返回到方框2710(即,重复确定自从上次用户交互以来所经过的时间)。然而,如果在菱形2770处确定显示设备当前处于目标降低刷新率,则方法2700返回到方框2710而不改变刷新率。
注意,如方框/菱形2740-2775所示,当确定上次输入经过时间大于时间阈值并且更新区域尺寸低于尺寸阈值时,或者确定上次输入经过时间大于时间阈值并且均一更新频率低于刷新率时,可降低刷新率。
现在参考图28,示出了根据一个或多个实施例的时间线图2800。具体而言,时间线图2800说明了在各种时间点(从左到右增大)处图形中断2810的发生。如图28的最左边部分所示,中断2810最初按第一周期2820被分开,该第一周期对应于默认刷新率(例如,60Hz)。在一些实施例中,中断2810可以是垂直空白间隔(Vertical Blank Interval,VBI)中断。
假设事件2830说明了所监视的状况在一些实施例中导致刷新率减小的时间点。例如,事件2830可说明对于上次输入经过时间大于时间阈值并且更新区域尺寸低于尺寸阈值的确定,或者对于上次输入经过时间大于时间阈值并且均一更新频率低于刷新率的确定(即,在图27所示的方框/菱形2740-2775中)。因此,在事件2830之后,中断2810按与降低的刷新率(例如,30Hz)相对应的第二周期2840被分开。注意,在降低的刷新率被使用的情况下的周期会减少中断的数目。因此,一些实施例可降低与视频处理相关联的功率消耗。
再次参考图27,如果在菱形2740处确定自从上次用户交互以来所经过的时间不超过时间阈值,或者如果在菱形2760处确定屏幕更新的均一频率不低于当前刷新率,则在菱形2780处确定显示设备当前是否处于默认刷新率。如果在菱形2780处确定显示设备当前不处于默认刷新率,那么在方框2785处,刷新率被设置为默认刷新率。在设置默认降低的速率之后,方法2700返回到方框2710。然而,如果在菱形2780处确定显示设备当前处于默认刷新率,则方法2700返回到方框2710而不改变刷新率。
注意,在降低刷新率之后(如上面参考方框/菱形2740-2775所论述的那样),当确定自从用户输入(例如,在刷新率降低之后的用户输入)以来的时间段不大于时间阈值时,或者当确定更新区域尺寸不低于尺寸阈值并且均一更新频率不低于刷新率时,可将刷新率返回到默认刷新率。
再次参考图28,事件2850说明了所监视的状况在一些实施例中导致刷新率增大的时间点。例如,事件2850可说明对于上次输入经过时间不大于时间阈值的确定,或者对于更新区域尺寸不低于尺寸阈值并且均一更新频率不低于刷新率的确定(即,在图27所示的方框/菱形2740-2785中)。因此,在事件2850之后,中断2810再次按与默认刷新率(例如,60Hz)相对应的第一周期2820被分开。
再次参考图27,在一些实施例中,方法2700可循环重复,以持续监视上次输入经过时间、更新区域尺寸、和均一更新频率,并且根据这些监视的参数向上和向下调整刷新率。另外,在一些实施例中,方法2700可以用多个级别的降低刷新率来被执行。例如,菱形2740-2750可在多个级别的时间/尺寸阈值上被评估,这样,在每个级别上的肯定确定导致将刷新率设置为越来越低的刷新率。在这样的示例中,刷新率可向下按多阶被降低,对应于越来越大的时间阈值和/或越来越小的尺寸阈值。另外,可在与刷新率的多个降低相对应的多个级别评估菱形2760。
现在参考图29,示出了根据一个或多个实施例的方法2900的流程图。方框2910可包括由计算设备在显示设备上呈现多个视频帧。方框2920可包括由计算设备的自适应刷新逻辑确定自从上次用户与输入设备的交互以来的时间段。例如,参考图26,当视频图像被呈现在显示设备2650上时,自适应刷新逻辑2635可确定自从经由(一个或多个)输入设备2640接收的上次输入以来所经过的时间。
方框2930可包括由自适应刷新逻辑确定自从上次用户交互以来的时间段是否超过时间阈值。方框2940可包括,响应于确定自从上次用户交互以来的时间段超过时间阈值,由自适应刷新逻辑使得显示设备以降低的刷新率操作。例如,参考图26,自适应刷新逻辑2635可确定自从经由(一个或多个)输入设备2640接收的上次输入以来所经过的时间大于所存储的时间阈值,并且作为响应可降低显示设备2650的刷新率。在一些实施例中,自适应刷新逻辑可在计算设备的操作系统中被实现。在方框2940之后,方法2900完成。
现在参考图30,示出了根据一个或多个实施例的方法3000的流程图。方框3010可包括在显示设备上呈现多个视频帧。方框3020可包括确定自从上次用户交互以来的时间段是否超过时间阈值。方框3030可包括确定视频帧的更新区域尺寸是否低于尺寸阈值。方框3040可包括,响应于确定自从上次用户交互以来的时间段超过时间阈值并且更新区域尺寸低于尺寸阈值,使得显示设备以降低的刷新率操作。在方框3040之后,方法3000完成。
现在参考图31,示出了根据一个或多个实施例的方法3100的流程图。方框3110可包括以第一刷新率在显示设备上呈现多个视频帧。方框3120可包括确定自从上次用户输入以来的时间段是否超过时间阈值。方框3130可包括确定视频帧的更新频率是否低于第一刷新率。方框3040可包括,响应于确定自从上次用户交互以来的时间段超过时间阈值并且视频帧的更新频率低于第一刷新率,使得显示设备以降低的刷新率操作。在方框3140之后,方法3100完成。
在各种实施例中,方法2900、方法3000和/或方法3100可由处理逻辑来执行,该处理逻辑可包括硬件(例如,处理设备、电路、专用逻辑、可编程逻辑、微代码,等等)、软件(例如,在处理设备上运行的指令)或者其组合。在一些实现方式中,方法2900、方法3000和/或方法3100可利用图26中所示的一个或多个组件(例如,自适应刷新逻辑2635、(一个或多个)处理器2620,操作系统2632等等)来被执行。在固件或软件实施例中,方法2900、方法3000和/或方法3100可由存储在非暂态机器可读介质(例如光学、半导体或磁性存储设备)中的计算机执行指令来实现。为了说明起见,可参考图26-图28来描述方法2900、方法3000和/或方法3100中涉及的动作,图26-图28示出了根据一个或多个实施例的示例。然而,本文论述的各种实施例的范围在这个方面不受限制。
现在参考图32,示出了示例计算设备3200的示意图。在一些示例中,计算设备3200可大体上对应于图26中所示的计算设备2610。如图所示,计算设备3200可包括用户输入设备3201、显示设备3203、(一个或多个)硬件处理器3202、以及机器可读存储介质3206。机器可读存储介质3206可以是非暂态介质,并且可存储指令3210-3230。指令3210-3230可被(一个或多个)硬件处理器3202执行。
指令3210可被执行来在以处于第一水平的刷新率在显示设备上呈现视频帧期间监视用户输入设备。指令3220可被执行以确定自从上次用户与用户输入设备的交互以来的时间段超过时间阈值。指令3230可被执行以响应于确定自从上次用户交互以来的时间段超过时间阈值而将显示设备的刷新率降低到第二水平。在一些实施例中,刷新率的第一水平是刷新率的第二水平的至少两倍。在一些实施例中,上次用户交互是使用输入设备(例如,键盘、鼠标、触摸板、触摸屏,等等)的用户输入。
现在参考图33,示出了根据一些实现方式的存储指令3310-3130的机器可读存储介质3300。指令3310-3130可由任何数目的处理器(例如,图26中所示的(一个或多个)处理器2620)执行。机器可读存储介质3300可以是任何非暂态计算机可读介质,例如光学、半导体或磁性存储设备。
指令3310可被执行以在显示设备上呈现多个视频帧。指令3320可被执行以确定自从上次用户与输入设备的交互以来的时间段是否超过时间阈值。指令3330可被执行以响应于确定自从上次用户交互以来的时间段超过时间阈值,使得显示设备以降低的刷新率操作。
以下条款和/或示例属于进一步实施例。
在示例1中,一种用于降低刷新率的计算设备包括处理器和存储指令的机器可读存储介质。所述指令可被硬件处理器执行来:在以处于第一水平的刷新率在显示设备上呈现视频帧期间,监视用户输入设备;确定自从与所述用户输入设备的上次用户交互以来的时间段是否超过时间阈值;并且响应于确定自从上次用户交互以来的时间段超过所述时间阈值而将所述显示设备的刷新率降低到第二水平。
在示例2中,示例1的主题可以可选地包括指令,所述指令可执行来响应于确定自从用户交互以来的时间段低于所述时间阈值而将所述显示设备的刷新率返回到所述第一水平。
在示例3中,示例1-2的主题可以可选地包括指令,所述指令可执行来确定视频帧的更新区域尺寸是否低于尺寸阈值;并且响应于以下情况而降低所述显示设备的刷新率:确定自从上次用户交互以来的时间段超过所述时间阈值;并且确定所述视频帧的更新区域尺寸低于所述尺寸阈值。
在示例4中,示例1-3的主题可以可选地包括指令,所述指令可执行来响应于确定所述视频帧的更新区域尺寸不低于所述尺寸阈值而将所述显示设备的刷新率返回到所述第一水平。
在示例5中,示例1-4的主题可以可选地包括指令,所述指令可执行来确定所述视频帧的更新频率是否低于所述刷新率;并且响应于以下情况而降低所述显示设备的刷新率:确定自从上次用户交互以来的时间段超过所述时间阈值;并且确定所述视频帧的更新频率低于所述刷新率。
在示例6中,示例1-5的主题可以可选地包括指令,所述指令可执行来响应于确定所述视频帧的更新频率不低于所述刷新率而将所述显示设备的刷新率返回到所述第一水平。
在示例7中,示例1-6的主题可以可选地包括所述尺寸阈值被指定为全帧尺寸的特定百分比。
在示例8中,示例1-7的主题可以可选地包括所述上次用户交互包括使用输入设备的用户输入。
在示例9中,一种用于降低刷新率的方法可包括:由计算设备在显示设备上呈现多个视频帧;由所述计算设备的自适应刷新逻辑确定自从与输入设备的上次用户交互以来的时间段;由所述自适应刷新逻辑确定自从上次用户交互以来的时间段是否超过时间阈值;并且响应于确定自从上次用户交互以来的时间段超过所述时间阈值,由所述自适应刷新逻辑使得所述显示设备以降低的刷新率操作。
在示例10中,示例9的主题可以可选地包括,在使得所述显示设备以降低的刷新率操作之后:确定自从上次用户交互以来的时间段低于所述时间阈值;并且响应于确定自从上次用户交互以来的时间段低于所述时间阈值而使得所述显示设备以默认刷新率操作,其中所述默认刷新率高于所述降低的刷新率。
在示例11中,示例9-10的主题可以可选地包括确定视频帧的更新区域尺寸是否低于尺寸阈值;并且响应于以下情况而使得所述显示设备以降低的刷新率操作:确定自从上次用户交互以来的时间段超过所述时间阈值;并且确定所述视频帧的更新区域尺寸低于所述尺寸阈值。
在示例12中,示例9-11的主题可以可选地包括,在使得所述显示设备以降低的刷新率操作之后,响应于确定所述视频帧的更新区域尺寸不低于所述尺寸阈值而使得所述显示设备以默认刷新率操作。
在示例13中,示例9-12的主题可以可选地包括确定所述视频帧的更新频率是否低于所述刷新率;并且响应于以下情况而使得所述显示设备以降低的刷新率操作:确定自从上次用户交互以来的时间段超过所述时间阈值;并且确定所述视频帧的更新频率低于所述刷新率。
在示例14中,示例9-13的主题可以可选地包括,在使得所述显示设备以降低的刷新率操作之后,响应于确定所述视频帧的更新频率不低于所述刷新率而使得所述显示设备以默认刷新率操作。
在示例15中,示例9-14的主题可以可选地包括:所述自适应刷新逻辑被实现在所述计算设备的操作系统中。
在示例16中,一种用于降低刷新率的计算设备可包括:一个或多个处理器;以及存储器,其中存储有多个指令,所述多个指令当被所述一个或多个处理器执行时,使得所述计算设备执行示例9至15中的任一项所述的方法。
在示例17中,至少一个机器可读介质在其上可存储有数据,所述数据如果被至少一个机器使用,则使得所述至少一个机器执行示例9至15中的任一项所述的方法。
在示例18中,一种电子设备包括用于执行示例9至15中的任一项所述的方法的装置。
在示例19中,一种物品,包括存储用于降低刷新率的指令的非暂态机器可读存储介质,所述指令在执行时使得处理器:在显示设备上呈现多个视频帧;确定自从与输入设备的上次用户交互以来的时间段是否超过时间阈值;并且响应于确定自从上次用户交互以来的时间段超过所述时间阈值,使得所述显示设备以降低的刷新率操作。
在示例20中,示例19的主题可以可选地包括指令,所述指令可执行来响应于确定自从用户交互以来的时间段低于所述时间阈值而将所述显示设备的刷新率返回到默认水平,其中所述默认刷新率高于所述降低的刷新率。
在示例21中,示例19-20的主题可以可选地包括指令,所述指令可执行来:确定视频帧的更新区域尺寸是否低于尺寸阈值;并且响应于以下情况而降低所述显示设备的刷新率:确定自从上次用户交互以来的时间段超过所述时间阈值;并且确定所述视频帧的更新区域尺寸低于所述尺寸阈值。
在示例22中,示例19-21的主题可以可选地包括指令,所述指令可执行来:确定所述视频帧的更新频率是否低于所述刷新率;并且响应于以下情况而降低所述显示设备的刷新率:确定自从上次用户交互以来的时间段超过所述时间阈值;并且确定所述视频帧的更新频率低于所述刷新率。
在示例23中,示例19-22的主题可以可选地包括所述尺寸阈值是全帧尺寸的特定百分比。
在示例24中,一种用于降低刷新率的设备包括:用于在显示设备上呈现多个视频帧的装置;用于确定自从与输入设备的上次用户交互以来的时间段的装置;用于确定自从上次用户交互以来的时间段是否超过时间阈值的装置;以及用于响应于确定自从上次用户交互以来的时间段超过所述时间阈值而使得所述显示设备以降低的刷新率操作的装置。
在示例25中,示例24的主题可以可选地包括用于进行以下操作的装置:在使得所述显示设备以降低的刷新率操作之后:确定自从上次用户交互以来的时间段低于所述时间阈值;并且响应于确定自从上次用户交互以来的时间段低于所述时间阈值而使得所述显示设备以默认刷新率操作,其中所述默认刷新率高于所述降低的刷新率。
在示例26中,示例24-25的主题可以可选地包括用于确定视频帧的更新区域尺寸是否低于尺寸阈值的装置;以及用于响应于以下情况而使得所述显示设备以降低的刷新率操作的装置:确定自从上次用户交互以来的时间段超过所述时间阈值;并且确定所述视频帧的更新区域尺寸低于所述尺寸阈值。
在示例27中,示例24-26的主题可以可选地包括:用于在使得所述显示设备以降低的刷新率操作之后响应于确定所述视频帧的更新区域尺寸不低于所述尺寸阈值而使得所述显示设备以默认刷新率操作的装置。
在示例28中,示例24-27的主题可以可选地包括用于确定所述视频帧的更新频率是否低于所述刷新率的装置;以及用于响应于以下情况而使得所述显示设备以降低的刷新率操作的装置:确定自从上次用户交互以来的时间段超过所述时间阈值;并且确定所述视频帧的更新频率低于所述刷新率。
在示例29中,示例24-28的主题可以可选地包括:用于在使得所述显示设备以降低的刷新率操作之后响应于确定所述视频帧的更新频率不低于所述刷新率而使得所述显示设备以默认刷新率操作的装置。
根据一个或多个实施例,可以基于表明对观看体验的影响降低的状况而动态地调整显示刷新率。在一些示例中,如果自从上次用户输入以来的时间超过了时间阈值,如果被更新的帧部分低于尺寸阈值,如果帧更新的频率低于刷新率,或者这些的组合,则刷新率可被降低。因此,一些实施例可降低与显示视频帧相关联的功率消耗。
注意,虽然图26-图33图示了各种示例实现方式,但其他变化是可能的。例如,设想到了一个或多个实施例可利用参考图1-图25描述的示例设备和系统中的一些或全部来被实现。注意,在图1-图33中示出的示例是为了举例说明而提供的,而并不打算限制任何实施例。具体而言,虽然为了清晰起见可以以简化形式示出实施例,但实施例可包括任何数目和/或布置的处理器、核心和/或额外组件(例如,总线、存储介质、连接器、电力组件、缓冲器、接口,等等)。例如,设想到了一些实施例除了示出的那些以外还可包括任何数目的组件,并且示出的组件的不同布置在某些实现方式中可发生。此外,设想到了图1-图33中示出的示例中的具体细节可用在一个或多个实施例中的任何地方。
要理解上述示例的各种组合是可能的。实施例可用于许多不同类型的系统中。例如,在一个实施例中,通信设备可被布置为执行本文描述的各种方法和技术。当然,本发明的范围不限于通信设备,而是其他实施例可指向其他类型的用于处理指令的装置,或者包括指令的一个或多个机器可读介质,这些指令响应于在计算设备上被执行而使得该设备实现本文描述的一个或多个方法和技术。
本说明书中各处提及“一个实施例”或“一实施例”的意思是联系该实施例描述的特定特征、结构或特性被包括在本发明内涵盖的至少一个实现方式中。从而,短语“一个实施例”或者“在一实施例中”的出现不一定指的是同一实施例。此外,特定的特征、结构或特性可被设置为除了图示的特定实施例以外的其他适当形式,并且所有这种形式都可被涵盖在本申请的权利要求内。
虽然已关于有限数目的实施例描述了本发明,但本领域技术人员将会明白从这些实施例进行的许多修改和变化。希望所附权利要求覆盖落在本发明的真实精神和范围内的所有这种修改和变化。
- 基于用户活动调整显示刷新率
- 基于用户的网络活动动态调整计算机安全的方法和系统