部件连接验证装置和方法
文献发布时间:2023-06-19 12:21:13
技术领域
本公开涉及对两个或更多个部件的连接进行验证的装置和方法。具体地,本公开涉及保证连接的部件正确地配合。本公开特别适合于电子电路组装和线束连接的领域。
背景技术
在一些情况下,可能难以保证在组件的制造期间正确地连接部件。这通常是电子部件的情况下的特定问题,诸如线束与其它引脚和插座端子的连接。具体地,未能正确地将连接引脚与其对应插座配合通常将导致电路不能正常工作和/或可能降低其整体可靠性。此外,故障可能直到组装完所有部件后才变得明显。
常规电连接器有时可以设置有诸如闩锁的配合机构,一旦两个部件彼此正确地接合,该配合机构就将所述两个部件闩锁在一起。当闩锁已接合时,闩锁机构还可以产生机械振动以指示部件的连接,该机械振动可以作为可听指示(诸如咔哒声)被接收。然而,这种连接声音很难听见,尤其是在连接的部件被组件的其它零件遮挡的情况下。例如,这是在汽车制造领域中的常见问题,在汽车制造领域中,线束通常用手绕着部分组装的车辆内的其它零件连接。在商业生产线上这种情况更加严重,因为技术人员可能由于背景工厂噪声而无法听到连接声音。
WO2017/0062124试图通过提供一种手套形式的连接器配合保证系统来解决上述问题,该手套将在技术人员将部件连接在一起时由技术人员佩戴,并且该手套包括用于检测连接声音的一个或更多个麦克风。在使用中,可以用戴手套的手握持部件,然后将该部件连接至对应连接点。随后使用手套上的一个或更多个麦克风在连接部件时感测连接声音,并确定该声音是否与期望连接的所存储的音频特征匹配。
WO2017/0062124意识到用其麦克风拾取背景噪声的问题,并提出了各种滤波技术来减轻背景噪声的影响。例如,在实施方式中,WO2017/0062124描述了对来自两个或更多个麦克风的输入使用波束成形技术以滤除被确定是从目标方向之外的方向发生的声音。还公开了使用单独的麦克风来检测背景噪声并从主麦克风信号消除该噪声。
然而,由于缺乏可靠性,如WO2017/0062124中公开的常规连接器配合保证系统未被广泛采用。具体地,已证明以任何一致性从可听连接信号滤除背景噪声是不可行的。例如,仅当麦克风在传感器阵列中的相对位置和传感器阵列相对于连接器的位置固定时,波束成形定向滤波才有效。然而,在现实场景中,技术人员对各个连接器的握持可能会略有不同,并且不同技术人员之间也会有所不同。因此相对位置不是固定的,并且为了允许变化,需要保持宽广的阵列聚焦。这继而意味着这种类型的滤波提供有限的信号改进。此外,涉及噪声消除的其它数字滤波通常导致整个信号的明显劣化。即,构成音频信号的所有源声音通常会在某种程度上减小,包括构成目标连接声音本身的频率分量。此外,虽然滤波可以允许提取包含目标连接声音的信号,但是这无助于基于提取的信号对连接进行分类。因此常规连接器配合保证系统在商业应用中并不是有效的。
因此本公开试图解决现有技术的上述问题。
发明内容
根据第一方面,提供了一种通过夹持器对部件的连接进行验证的装置,其中,连接两个或更多个部件产生连接声音,所述装置包括:多个音频传感器;紧固件,该紧固件将多个音频传感器固定在夹持器上的不同位置;以及控制器,该控制器包括:输入端,该输入端接收来自多个音频传感器的音频信号;神经网络,该神经网络基于根据在受控环境中进行的多个训练连接期间接收的音频信号获得的训练音频数据,使用独立分量分析从接收自多个音频传感器的音频信号中分离连接声音;以及输出端,该输出端基于所分离的连接声音指示期望的连接状态。
以这种方式,装置可以固定至夹持器,在部件与配合对象配合时,该夹持器用于保持部件。由此,在两个或更多个部件连接在一起时,音频传感器(诸如麦克风或振动传感器)位于配合区域附近,从而允许所述音频传感器在部件连接时检测声音。然后,神经网络能够对这些声音进行分析,集中于连接声源并将连接声源与背景噪声源分离。因此由神经网络采用的机器学习算法模仿了所谓的“鸡尾酒聚会效应”中的由人脑采用的声源分离类型,在所谓的“鸡尾酒聚会效应”中,单个声音集中在嘈杂房间中。重要的是,与通过有效地从接收到的音频信号中减去数据来进行滤波的常规数字滤波技术不同,所要求保护的分析涉及将作为独立分量分析的一部分处理的数据最大化。这不仅允许保持检测到的连接声音的保真度,而且还意味着信号与音频传感器阵列的几何形状无关。即,该算法可以自动适应由于音频传感器之间的不同相对位置而导致的声景(sound scape)变化。实施方式还可以提供基于人工智能(AI)的信号分类,以便生成指示已进行良好连接还是较差连接的输出信号。
在实施方式中,神经网络应用鸡尾酒聚会算法。在这方面,该算法先前已在人工智能研究中用作将个体人类声音与背景噪声分离的方法。因此实施方式将该算法应用于新的实际应用中,以分离与部件的组装相关联的连接声音。
在实施方式中,由神经网络进行的独立分量分析包括:基于由训练音频数据标识的差异,分析从多个音频传感器中的至少两个音频传感器接收的音频信号之间的相位延迟和组成上的差异。以这种方式,神经网络能够分析从两个或更多个几何上分离的音频传感器接收的信号之间的共性和差异的模式,以便提供双耳无遮蔽型效果(binauralunmasking type effect)。
在实施方式中,夹持器是用户的手和机器人操纵器中的一者。因此实施方式可以用于手动连接操作以及机器人臂代替人类用户的自动系统。
在实施方式中,多个音频传感器包括第一音频传感器和第二音频传感器,所述第一音频传感器和所述第二音频传感器在被紧固件固定时定位在夹持器上的第一位置和第二位置,其中,所述第一位置和所述第二位置被定位成使得:在使用中,当两个或更多个部件在连接期间被夹持器保持时,第一音频传感器和第二音频传感器两者同时接触所述两个或更多个部件中的至少一个部件。以这种方式,可以通过与第一音频传感器和第二音频传感器的物理接触直接检测作为振动通过部件本身发送的音频信号。还将理解,在实施方式中,可以提供另外的音频传感器以同时将另外的音频信号传送至神经网络。因此可以使用音频传感器的不同组合,其中一些音频传感器直接物理接触,而另一些音频传感器依靠通过空中的传输。神经网络基于比较多个分离的音频信号来识别连接声音。因此,尽管可以同时分析的音频信号的数量将受到神经网络处理能力的限制,但更多数量的音频传感器通常将提供连接声音的改进的分辨率。
在实施方式中,神经网络还包括另外的训练音频数据,所述另外的训练音频数据是根据在通过在受控环境中连接不同的两个或更多个部件而进行的不同的多个训练连接期间接收的音频信号获得的。以这种方式,可以使用同一装置来验证不同类型部件的连接状态,这些不同类型部件可能具有与其相关联的不同连接声音。
在实施方式中,输出端包括音频输出端,该音频输出端连接至扬声器,以输出所分离的连接声音。以这种方式,可以向用户提供他们正进行的连接的可听反馈,以允许用户基于连接声音的增强的回放来评估该连接的有效性。在实施方式中,装置可以包括用于输出所分离的连接声音的耳机。
在实施方式中,控制器还将所分离的连接声音与期望的连接声音所关联的简档进行比较,以识别何时形成了期望的连接状态。以这种方式,控制器可以自动确定是否已进行有效连接。在实施方式中,可以通过人工智能算法来执行信号分类。
在实施方式中,输出端包括视觉指示器。以这种方式,向用户提醒何时进行了连接。
在实施方式中,输出端还包括基于所分离的连接声音来指示不良连接状态的指示器。以这种方式,向用户提醒何时连接不充分。
在实施方式中,所述装置还包括存储由用户连接的部件的连接状态的日志的存储部。以这种方式,可以监测影响连接的用户或机器人系统的准确度。
在实施方式中,可佩戴的紧固件是手套。因此实施方式可以被设置成用户佩戴的传感器单元,该用户佩戴的传感器单元被配置成佩戴在用户的手上。因此如组装厂中的技术人员的用户可以通过戴上手套来将装置固定至他们的手上,音频传感器的位置取决于它们在手套材料上的位置。
在实施方式中,两个或更多个部件是电子连接器。实施方式特别适合于诸如电缆束的电子连接器的连接。这样的电子连接器可以包括具有多个引脚(例如,80个或更多个)的插头以及容纳插头的对应插座。
根据第二方面,提供了一种通过夹持器对部件的连接进行验证的方法,其中,连接两个或更多个部件产生连接声音,所述方法包括以下步骤:使用紧固件将多个音频传感器固定在夹持器上的不同位置;在使用夹持器连接两个或更多个部件时,将来自多个音频传感器的音频信号接收到控制器输入端;由神经网络基于根据在受控环境中进行的多个训练连接期间接收的音频信号获得的训练音频数据,使用独立分量分析从接收自多个音频传感器的音频信号中分离连接声音;以及基于所分离的连接声音输出指示期望的连接状态的信号。
根据第三方面,提供了一种训练通过夹持器对部件的连接进行验证的装置的方法,其中,连接两个或更多个部件产生连接声音,所述方法包括以下步骤:使用紧固件将多个音频传感器固定在夹持器上的不同位置;建立环境噪声被降至最低的第一受控环境;在第一受控环境下执行第一训练连接序列,在第一训练连接序列中,使用夹持器将两个或更多个部件连接至期望的连接状态;在第一训练连接序列期间,将来自多个音频传感器的音频信号接收到控制器输入端;建立环境噪声与使用环境相对应的第二受控环境;在第二受控环境下执行第二训练连接序列,在第二训练连接序列中,使用夹持器将两个或更多个部件连接至期望的连接状态;在第二训练连接序列期间,将来自多个音频传感器的音频信号接收到控制器输入端;以及由神经网络使用独立分量分析来处理在第一训练连接序列和第二训练连接序列期间从多个音频传感器接收的音频信号。
在实施方式中,训练过程可以包括收集n个音频信号样本以用于不同条件下的训练连接。不同条件可以包括有噪声和无噪声的操作,以及暴露于不同声音失真和不同连接场景(例如,引脚断裂、低张力弹簧和不合适的张力)。然后可以将各个音频信号样本手动分类,以将其指定为实现期望的连接状态或导致不期望的连接状态。然后可以将样本分为两个随机组,第一组用于训练神经网络,第二组用于验证训练。然后继续训练,直到实现所需的关键性能指标为止,如连接分类准确度高于指定级别。
附图说明
现在将参照附图描述例示性实施方式,在附图中:
图1示出了根据第一实施方式的装置;以及
图2示出了根据第二实施方式的装置。
具体实施方式
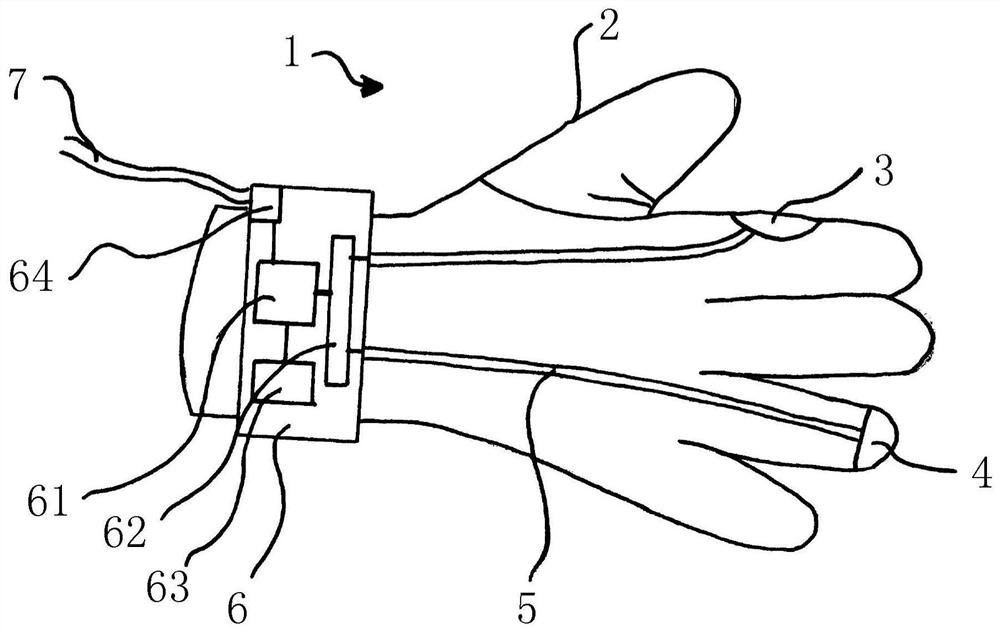
图1示出了根据第一实施方式的连接保证装置1。在该实施方式中,该装置被提供为可佩戴手套2的形式,以供用户(诸如在组装厂工作的技术人员或组装线员工)佩戴。
手套2在装置的袖口处设置有控制器6,该控制器6通过连接电线5连接至第一麦克风3和第二麦克风4。第一麦克风3和第二麦克风4分别在第一位置和第二位置固定至手套2。这些位置被配置成使得当用户的戴手套的手握持部件(未示出)时,第一麦克风3和第二麦克风4与部件直接物理接触。然后当将部件装配至其配对部件时,来自连接的声音振动通过部件本身以及通过空气传导。在其它实施方式中,也可以使用其它类型的音频传感器(诸如振动传感器)。此外,可以提供超过两个的音频传感器,并且尽管实施方式可以使这些音频传感器中的至少两个音频传感器与部件直接接触,但是可以将音频传感器中的一个或更多个音频传感器定位成使得它们在使用中与部件相距一定距离。
在该实施方式中,控制器6被设置成处理器组件,该处理器组件包括微处理器61、微处理器61可存取的存储器62以及经由电线5从麦克风3、4接收信号的输入接口62和经由音频输出端7输出信号的输出接口64。
使用控制器6来使用存储在控制器的存储器63中并由控制器的微处理器61执行的神经网络处理来自麦克风3、4的音频信号。神经网络应用鸡尾酒聚会算法来对接收到的信号执行独立分量分析。
音频输出端7连接至控制器6,并为由用户佩戴的一组耳机(未示出)提供音频馈送。
在商业用途之前,通过在不同受控条件下执行多个训练连接操作来对装置的神经网络进行训练。针对各个训练连接,用户将一个部件握持在戴手套的手中,并执行将部件与其配合对象接合的操作。因此当执行连接操作时,用户的手用作夹持器,以保持部件中的一个部件。连接操作也会在不同声景条件下重复进行,以使神经网络暴露于在存在背景噪声和不存在背景噪声的情况下生成的音频信号。在实施方式中,还按照不同级别和不同类型的背景噪声来执行训练。例如,可以在存在分离的样本背景噪声的情况下以及在模拟的运行工厂环境和故障的情况下进行操作。
控制器的神经网络对传递给它的音频信号应用独立分量分析。即,由于第一麦克风3和第二麦克风4位于不同位置,因此由各个麦克风生成的音频信号将由相同声音的不同比例和相位延迟组成,这取决于各个麦克风关于那些部件中的各个部件的相应源的相对位置。例如,如果第一麦克风3相对更靠近设置在所连接的部件上的可听指示机构,则该麦克风将更快且更响亮地接收到音频指示声音。相比之下,第二麦克风4也将接收音频指示声音,但是稍晚并且以较低的音量接收,其中背景噪声在其接收的信号特征中占相对较高的比例。因此,通过训练,神经网络能够使用鸡尾酒聚会算法来执行独立分量分析,以便基于所接收的多个音频信号之间的相位延迟和信号组成的差异来将连接声音与背景噪声分离。
一旦经训练,控制器6就能够对传入音频信号进行分析,以将构成连接声音的分量与构成背景噪声的其它声音分量分离。在使用中,分离的连接声音然后通过音频输出端7输出至耳机,从而允许用户确定部件是否已以期望的方式成功连接。
在商业使用场景中,用户将装置1佩戴在手上并佩戴连接至输出端7的一组耳机。在用户执行现实连接操作时,控制器6将处理来自多个音频传感器的传入音频信号,并从剩余的背景噪声输出分离的连接声音。因此通过耳机向用户提供了可听反馈,这允许用户确定何时成功进行了部件之间的连接。以这种方式,即使在嘈杂的工厂生产线上,用户也能够确保正确地连接诸如线束的部件。
图2示出了根据第二实施方式的连接保证装置1。在该实施方式中,装置1以可附接的线束2的形式提供,该线束2将被装配到设在生产线机器人13的臂的远端上的夹持器8。
装置1设置有使用固定带2分别固定至夹持器8的各个手指的第一麦克风3和第二麦克风4。第一麦克风3和第二麦克风4通过电线3连接至控制器6。
图2还示出了夹持器8,该夹持器8保持线束的端子连接器11以连接至设置在组件9中的连接端口或插座10中。端子连接器11由捆绑的电缆干线12馈送,并且连接器壳体的顶板包括闩锁,该闩锁接合至形成在连接插座10的壳体中的凹部中。连接插座10包括多个引脚,所述多个引脚被容纳在设置在端子连接器11中的孔中。当端子连接器11正确地插入连接插座10中时,引脚接合至孔中,并且闩锁接合至凹部中以释放可听“咔哒”声。这确认了引脚已被充分插入以建立与线束的电连接。在使用中,生产线机器人13被编程为执行将端子连接器11插入连接插座10中的重复连接操作。
在该实施方式中,训练阶段类似地涉及神经网络在不同受控条件下暴露于多个训练连接操作。然而,另外地,训练阶段还包括导致不同连接状态的连接操作。具体地,以此方式记录导致成功连接(其中将部件以期望方式配合在一起)的操作。相比之下,还记录导致不成功连接(其中部件未正确地装配在一起)的操作以及部分连接的实例。
在使用中,该实施方式中的控制器6使用如第一实施方式中所述的神经网络对音频信号执行类似的独立分量分析。然而,另外地,在该实施方式中,控制器6还能够基于不同连接声音对连接状态进行分类。即,系统能够基于所接收的声音确定是否已实现了期望的连接,而不仅仅是部分连接或不成功连接。
控制器6使用反馈机制输出连接状态数据,以验证机器人是否正常运行。例如,在进行进一步的组装操作之前,可以手动检查和纠正已被识别成与线束仅部分连接的组件。
控制器6还可以包括用于记录各个连接的存储器。以这种方式,根据第二实施方式的装置允许随着时间监测机器人的准确度,以便识别例如何时需要维护。
因此,即使在存在高级别的背景噪声的实例中,实施方式也能够在两个部件被连接时提供是否已实现期望的连接状态的指示。因此这允许在随后的组装操作发生之前较早识别两个部件可能尚未成功连接的实例。因此实施方式在除非产品已被完全组装否则无法检测到连接故障的组装生产线上特别有利。
将理解,以上例示的实施方式仅出于例示的目的示出了应用。在实践中,可以以许多不同配置来应用实施方式,其细节对于本领域技术人员而言是容易实现的。
例如,尽管图1所示的上述用户操作实施方式采用了经由耳机的可听反馈,但是在其它实施方式中,可以提供视觉指示。例如,可以使用LED显示器来指示已实现期望的连接状态。此外,还可以在视觉上识别连接状态,例如以向用户提醒已进行了部分或不成功的连接的实例。
此外,尽管在以上实施方式中处理是在本地进行的,但是将理解,在其它实施方式中,控制器6可以采用分布式处理并将音频信号数据发送至诸如服务器的永久处理资源。在这样的实施方式中,本地控制器6部件可以包括例如用于通过无线接入点与服务器进行通信的Wi-Fi收发器。
- 部件连接验证装置和方法
- 引导部件、基板、基板筒、基板处理装置、引导部件连接方法、显示元件的制造方法及显示元件的制造装置