抗列删除攻击的表格数据水印方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及抗列删除攻击的表格数据水印方法,属于计算机与信息科学技术领域。
背景技术
表格数据是医疗诊断、金融决策、工业智能等行业领域的重要数据资源,一旦被窃取滥用,将极大侵害所有者权益。表格数据水印技术是对表格数据进行版权保护和追踪溯源的有效方法,研究表格数据水印技术对于数字资产的安全保护具有重要意义。
当前表格数据水印方法主要可分为三类:
1.唯一主键方法
唯一主键方法是主流水印方法应用的基础。方法使用Hash计算秘钥和主键的散列值以确定水印位置,不同秘钥下水印位置不同,确保非法用户不能获得水印信息。但唯一主键方法应用的前提是表格数据存在唯一主键,若表格数据无主键或主键被删改,水印将无法被检测识别。
2.虚拟主键方法
虚拟主键方法将连续属性值转化为二进制后进行高低位分割,高位使用Hash计算生成虚拟主键,低位进行水印嵌入,从而避免唯一主键方法的缺陷。但虚拟主键方法对所选的连续属性值要求较高,当数据被篡改时将导致水印失效,且该方法无法使用离散属性值生成虚拟主键,难以充分利用数据资源。
3.聚类分组方法
聚类分组方法不再计算Hash散列值,而是基于距离度量直接实现聚类分组,并且可以同时使用连续或离散属性值,相较于虚拟主键方法具有更强的算法安全性。但聚类分组方法同样依赖参与聚类属性值的完整性。若聚类属性值被删除,标识与属性值间的单项映射关联被破坏,将导致水印检测时标识计算错误,水印无法被正确识别。
综上所述,现有表格数据水印方法过于依赖主键或所选取的属性值,抗列删除攻击能力不足,所以本发明提出抗列删除攻击的表格数据水印方法。
发明内容
本发明的目的是针对表格数据水印方法抗列删除攻击能力不足的问题,提出了抗列删除攻击的表格数据水印方法。
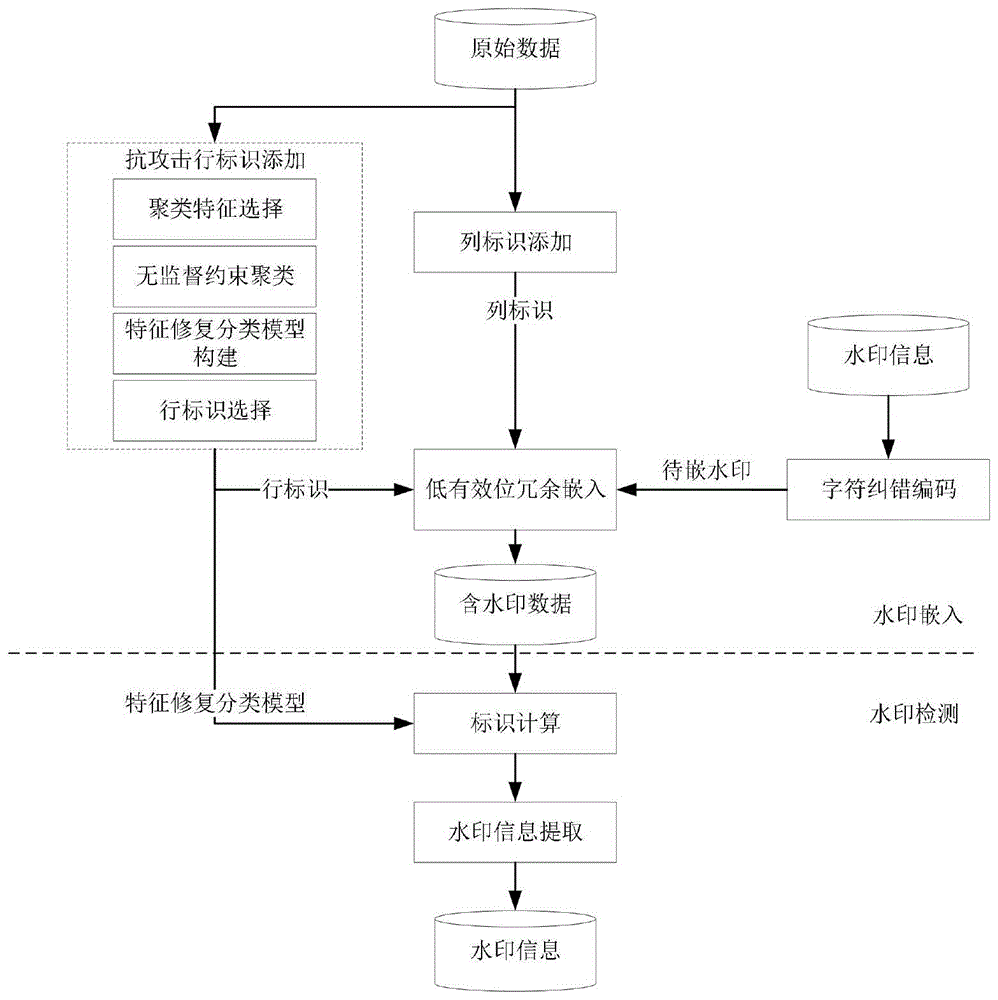
本发明的设计原理为:首先选取重要属性列作为水印列标识;其次使用聚类方法获得行数据聚类标签,构造受损行数据,结合聚类标签和受损行数据构建特征修复分类模型,利用模型对原始数据进行分类并根据类别概率确定水印行标识;然后使用纠错码编码水印信息,根据行标识和列标识确定嵌入位置并冗余嵌入水印信息,获得含水印数据;最后使用特征修复分类模型确定水印位置,提取水印信息并解码,获得嵌入的水印信息。
本发明的技术方案是通过如下步骤实现的:
步骤1,结合属性重要程度及数据失真容忍度选取重要连续变量属性列,确定水印列标识。
步骤2,构建特征修复分类网络模型确定水印行标识。
步骤2.1,使用过滤式特征选择法选取聚类特征。
步骤2.2,基于所选特征使用约束FCM算法进行无监督聚类,获得行数据聚类标签。
步骤2.3,使用掩码向量生成受损行数据,并利用聚类标签和受损行数据训练特征修复分类网络模型。
步骤2.4,使用模型计算各行数据分类类别概率,根据类别概率为原始行数据添加分组标识并选取行数据作为水印行标识。
步骤3,将水印信息冗余嵌入原始数据。
步骤3.1,将水印信息编码为二进制格式,并添加纠错码。
步骤3.2,根据水印行标识和水印列标识确定水印嵌入位置,使用LSB算法冗余嵌入水印编码。
步骤4,对含水印数据进行水印检测。
步骤4.1,使用特征修复分类网络获得水印行标识,结合水印列标识确定水印嵌入位置。
步骤4.2,提取水印编码并解码,恢复水印信息。
有益效果
相比于唯一主键方法,本发明可以在无主键的数据中嵌入水印。
相比于虚拟主键法,本发明通过无监督聚类方法选取水印行标识,可同时使用连续属性值和离散属性值,可充分利用数据资源。
相比于聚类分组法,本发明通过建立特征修复分类模型,利用特征修复编码实现受损数据的正确分类,同时根据分类网络输出的类别概率选取行数据嵌入冗余信息,减少数据统计特征的失真程度。
附图说明
图1为本发明抗列删除攻击的表格数据水印方法原理图。
图2为特征修复分类网络结构图。
具体实施方式
为了更好的说明本发明的目的和优点,下面结合实例对本发明方法的实施方式做进一步详细说明。
实验数据来自真实生物信息数据集Checkup。数据水印实验数据见表1。
表1.数据水印实验数据集
实验采用行标识准确率Acc
其中,r
本次实验在一台计算机和一台服务器上进行,计算机的具体配置为:Inter i9-9900,RAM 32G,操作系统是windows 11,64位;服务器的具体配置为:GeForce GTX 1080Ti,操作系统是Linux Ubuntu 20.04,64位。
本次实验的具体流程为:
步骤1,将连续属性值按照方差σ和均值μ进行降序排列,属性列的排序方式T为:
T=lnμ+log
以排列为参考,结合属性重要程度及数据失真容忍度两种主观因素选取属性列作为待嵌入水印的列标识。
步骤2,构建特征修复分类网络模型并利用模型确定水印行标识。
步骤2.1,使用过滤式特征选择法计算特征之间相关系数和方差,从高方差特征数据中选取高相关系数的特征作为聚类特征以增加聚类属性冗余度,选取特征数为max{0.8k,ca},其中k为聚类数,ca为连续属性列数量。
步骤2.2,基于聚类特征使用约束FCM算法进行无监督聚类,约束FCM模型训练的目标函数为:
其中,c
步骤2.3,使用掩码向量m生成受损行数据
其中,r表示原始行数据,掩码向量m=[m
步骤2.4,将原始数据输入特征修复分类模型,使用Softmax处理特征修复分类模型输出的分类结果,获得各行数据属于每个类别的概率,选取概率最大的类别作为各行数据的分组标识;计算最大类别概率与最小类别概率的差值,选取概率差值大于预设阈值的行数据,确定水印行标识。
步骤3,将水印信息冗余嵌入原始数据。
步骤3.1,使用ASCII编码将水印信息转换为二进制形式,向转换后水印编码中添加RS纠错码,获得水印编码,水印编码长度l应满足:
k×(α-1) 其中,k为聚类类别数,α为列标识数。 步骤3.2,将水印编码以长度k分为α个子串,记为{W y 其中,j.W 步骤4,对含水印数据进行水印检测。 步骤4.1,将含水印数据输入特征修复分类模型,处理模型的输出结果获取水印行标识,具体处理方式与步骤2.4相同,但考虑到数据传输过程中的失真影响,水印检测时概率差值阈值小于水印嵌入时的阈值。根据水印所有者保留的水印列标识获取水印嵌入位置。 步骤4.2,使用投票表决法提取水印编码,提取方式为: j.WB 其中,j.WB 测试结果:实验基于抗列删除攻击的表格数据水印方法,对Checkup数据集进行了水印嵌入、列删除攻击和水印检测。本发明在聚类特征属性被删除50%的情况下达到0.492的行标识准确率,具备良好的抗列删除攻击能力,有效增强表格数据水印的安全性。 以上所述的具体描述,对发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。