基于增强现实的界面显示方法、装置、设备、介质和产品
文献发布时间:2023-06-19 19:23:34
技术领域
本申请涉及增强现实领域,特别涉及一种基于增强现实的界面显示方法、装置、设备、介质和产品。
背景技术
增强现实(Augmented Reality,AR)技术是一种将虚拟信息与真实世界巧妙融合的技术,广泛应用于秀场直播中,实现用户和虚拟对象之间的互动。
相关技术中,使用增强现实技术,通过直播流直接推送虚拟对象的形象到直播间中,用户可以根据直播流的画面来感知虚拟对象之间的位姿情况,并与虚拟对象进行互动。
然而,上述方式中,用户需要实时观察直播流的画面与虚拟对象进行互动,不能实感的与虚拟对象进行互动,造成用户体验感差和观众观感差的问题。
发明内容
本申请实施例提供了一种基于增强现实的界面显示方法、装置、设备、介质和产品,可以用于解决无法与虚拟对象进行直接交互的问题。所述技术方案如下:
一个方面,提供了一种基于增强现实的界面显示方法,所述方法包括:
获取直播视频帧,所述直播视频帧是所述终端中的直播应用程序通过摄像头采集得到的场景视频中的图像帧,所述直播视频帧中包括场景元素;
基于对所述直播视频帧中所述场景元素的位姿识别结果,在所述直播视频帧中显示与所述位姿识别结果对应的三维虚拟对象。
另一方面,提供了一种基于增强现实的界面显示装置,所述装置包括:
获取模块,用于获取直播视频帧,所述直播视频帧是所述终端中的直播应用程序通过摄像头采集得到的场景视频中的图像帧,所述直播视频帧中包括场景元素;
显示模块,用于基于对所述直播视频帧中所述场景元素的位姿识别结果,在所述直播视频帧中显示与所述位姿识别结果对应的三维虚拟对象。
另一方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现如上述本申请实施例中任一所述的基于增强现实的界面显示方法。
另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现如上述本申请实施例中任一所述的基于增强现实的界面显示方法。
另一方面,提供了一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述本申请实施例中任一所述的基于增强现实的界面显示方法。
本申请实施例提供的技术方案带来的有益效果至少包括:
通过训练位姿识别模型,获取直播视频帧,将直播视频帧输入位姿识别模型后,输出对直播视频帧中场景元素的位姿识别结果,并基于位姿识别结果在直播视频帧中显示与位姿识别结果对应的三维虚拟对象,能够使用户在直播时通过直接驱动场景元素,与场景元素之间互动,来实现与虚拟对象实时的互动,提高了用户直播时的体验感和观众观看直播时的观感。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本申请一个示例性实施例提供的基于增强现实的界面显示方法的示意图;
图2是本申请一个示例性实施例提供的电子设备的结构框图;
图3是本申请一个示例性实施例提供的基于增强现实的界面显示方法的流程图;
图4是本申请一个示例性实施例提供的一个直播视频帧中包括的场景元素示意图;
图5是本申请另一个示例性实施例提供的位姿识别模型的训练方法的流程图;
图6是本申请另一个示例性实施例提供的基于增强现实的界面显示方法的流程图;
图7是本申请一个示例性实施例提供的选中目标场景元素并进行替换的示意图;
图8是本申请一个示例性实施例提供的界面显示方法的应用示意图;
图9是本申请另一个示例性实施例提供的界面显示方法的应用示意图;
图10是本申请另一个示例性实施例提供的对三维虚拟对象进行控制的方法的流程图;
图11是本申请一个示例性实施例提供的基于增强现实的界面装置的结构框图;
图12是本申请另一个示例性实施例提供的基于增强现实的界面装置的结构框图;
图13是本申请一个示例性实施例提供的计算机设备的结构框图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。
首先,针对本申请实施例中涉及的名词进行简单介绍。
人工智能(Artificial Intelligence,AI):是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大图像识别模型的训练技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
机器学习(Machine Learning,ML):是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、示教学习等技术。
增强现实(Augmented Reality,AR)技术是一种将虚拟信息与真实世界巧妙融合的技术,广泛运用了多媒体、三维建模、实时跟踪及注册、智能交互、传感等多种技术手段,将计算机生成的文字、图像、三维模型、音乐、视频等虚拟信息模拟仿真后,应用到真实世界中,两种信息互为补充,从而实现对真实世界的“增强”。
增强现实技术也被称为扩增现实,AR增强现实技术是促使真实世界信息和虚拟世界信息内容之间综合在一起的较新的技术内容,其将原本在现实世界的空间范围中比较难以进行体验的实体信息在电脑等科学技术的基础上,实施模拟仿真处理,叠加将虚拟信息内容在真实世界中加以有效应用,并且在这一过程中能够被人类感官所感知,从而实现超越现实的感官体验。真实环境和虚拟物体之间重叠之后,能够在同一个画面以及空间中同时存在。
增强现实技术可以应用于多个领域,如:直播领域、艺术教学领域、项目可视化领域等。
首先,本实施例中以直播领域为例进行说明。
AR直播是直播的一种形式,通过在直播间中推送虚拟对象的三维形象,使用户直播时基于虚拟对象的位姿情况进行互动,来实现虚实结合的直播效果。
其中,位姿是指位置和姿态,任何一个物体在空间坐标系中都可以用位置和姿态来精确、唯一表示其位置状态。
为了确定空间中任意一点的位置,需要在空间中引进坐标系,最常用的坐标系是空间直角坐标系。空间坐标系是指,在空间任意选定一点O,过点O作三条互相垂直的数轴Ox,Oy,Oz,它们都以O为原点且具有相同的长度单位。这三条轴分别称作x轴(横轴),y轴(纵轴),z轴(竖轴)。正方向符合右手规则,即以右手握住z轴,当右手的四个手指x轴的正向以二分之π角度转向y轴正向时,大拇指的指向就是z轴的正向。
示意性地,以正方体为例,选取正方体八个顶点中的任意一个顶点A为原点,以顶点A直接连接的三条边的延长线分别作为x轴(横轴),y轴(纵轴),z轴(竖轴)建立一个空间坐标系。
位置是用物体在空间坐标系中的(x、y、z)坐标来描述,例如:水杯在以墙角为原点建系的空间坐标系中,水杯的坐标数值为(2,3,4)、单位为米时,说明水杯所处的位置与原点的三维距离分别为2米、3米、4米。
姿态是指身体呈现的样子,在空间坐标系中,通常用物体与x轴的夹角rx、物体与y轴的夹角ry、物体与z轴的夹角rz来描述。在AR直播场景下,指虚拟对象的姿势或身体朝向。
相关技术中,通过增强现实技术,将预设的虚拟对象的形象推送到直播间,虚拟对象的动作和位姿在直播时并不受用户实时控制,用户通过观察直播流中的画面实时掌握虚拟对象的位姿状况并与虚拟对象进行互动。
通过上述方法与虚拟对象进行互动时,用户需要实时观察直播流的画面与虚拟对象进行互动,不能实感的与虚拟对象进行互动,造成用户体验感差和观众观感差的问题。
针对上述问题,本申请实施例中提供了一种基于增强现实的界面显示方法,通过驱动实物来实现与虚拟对象进行互动,提高了用户直播时的体验感和观众观看直播时的观感。
在本申请实施例中,示意性的,图1示出了本申请一个示例性实施例提供的基于增强现实的界面显示方法的示意图,如图1所示:
用户通过终端进行直播时,终端获取实时视频流中的直播视频帧,直播视频帧中包括场景空间100,场景空间100中包含场景元素110,用鼠标圈中场景元素110,将其作为目标替换对象。此时,将直播视频帧输入至预先训练好的位姿识别模型,位姿训练模型会输出场景元素110在场景空间100中的三维坐标以及场景元素110对应的翻转角度。对直播视频帧进行元素抠图处理,将场景元素110从当前位置抠图出去,使用渲染引擎,将预设的三维虚拟对象120渲染至场景元素110原来的位置,完成直播时场景元素110和三维虚拟对象120之间的替换。用户在直播时,可以通过驱动场景元素110来实现用户和虚拟对象120之间的互动。
本申请中的终端可以是台式计算机、膝上型便携计算机、手机、平板电脑、电子书阅读器、MP3(Moving Picture Experts Group Audio Layer III,动态影像专家压缩标准音频层面3)播放器、MP4(Moving Picture Experts Group Audio Layer IV,动态影像专家压缩标准音频层面4)播放器等等。该终端中安装和运行有支持推送实时视频流的应用程序,比如支持推送车载摄像头组件采集的实时视频流的应用程序。
图2示出了本申请一个示例性实施例提供的电子设备的结构框图。该电子设备200包括:操作系统210和应用程序220。
操作系统210是为应用程序220提供对计算机硬件的安全访问的基础软件。
应用程序220是支持虚拟场景的应用程序。可选地,应用程序220是支持推送实时视频流的应用程序。
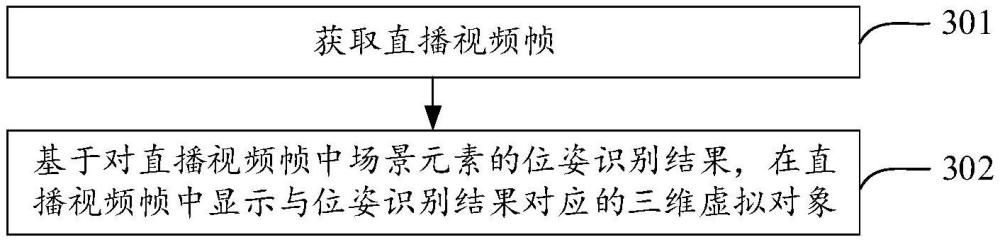
结合上述名词简介以及实施环境说明,对本申请实施例中提供的基于增强现实的界面显示方法进行说明,请参考图3,其示出了本申请一个示例性实施例提供的基于增强现实的界面显示方法的流程图,如图3所示,该方法包括:
步骤301,获取直播视频帧。
用户使用终端中的直播应用程序进行实时直播时,终端摄像头采集到的场景视频作为直播的视频流,并由直播应用程序将视频流推送至直播间中。
其中,直播视频帧是终端中的直播应用程序通过摄像头采集得到的场景视频中的图像帧,直播视频帧中包括场景元素。
可选地,直播应用程序的种类包括但不限于以下种类中的一种:直播软件、直播小程序、直播网站、支持网络直播的浏览器等。
可选地,用户使用直播应用程序进行直播时,可以选择的终端种类包括但不限于以下种类的中的一种:智能手机、笔记本电脑、台式电脑、平板电脑等。
可选地,获取直播视频帧的方式包括但不限于以下方式中的一种:
1、对直播视频流进行截图;
2、保存直播视频流,并使用相关的视频软件进行视频帧的提取。
可选地,直播视频帧中的场景元素包括但不限于以下元素中的至少一种:
1、直播房间设施:桌子、椅子、沙发、空调、床头柜等;
2、直播房间装饰:绿植、装饰摆件、窗帘;
3、直播房间灯光设备:台灯、吊灯、打光设备等;
4、静态对象:玩具、书本、杯子等;
5、动态对象:小动物、直播用户。
示意性的,图4是本申请实施例中一个直播视频帧中包括的场景元素示意图,如图4所示:
用户在直播房间进行直播时,直播应用程序将场景视频的视频流推送至直播间中,截取视频流的直播视频帧400,在直播视频帧400中,包含直播房间装饰、直播房间设施、静态对象:窗帘410,桌子420,床头柜430和玩具440。
值得注意的是,在一些实施例中,用户可以在户外直播也可以在用于直播的室内房间内进行实时直播;若用户在室内直播,则直播视频帧中的场景元素可以包含任意种类的元素,也即,在直播房间内,可以包括任意种类的设施、设备等内容,本实施例对此不加以限定。
值得注意的是,用户使用的直播终端可以是任意的,基于直播终端所使用的直播应用程序的种类可以是任意的,获取直播视频帧的方式可以是任意的,直播视频帧可以是任意时刻基于场景视频获得的图像帧,本实施例对此不加以限定。
步骤302,基于对直播视频帧中场景元素的位姿识别结果,在直播视频帧中显示与位姿识别结果对应的三维虚拟对象。
其中,直播视频帧中的场景元素可以是任意的,所以在直播时,用户可以使用终端配套的设备选定直播视频帧中的目标场景元素,也即在场景元素中选取其中一个作为目标,用于替换为预设的三维虚拟对象。
可选地,直播终端为笔记本电脑时,笔记本电脑上的摄像头采集得到场景视频,将场景视频中的图像帧作为直播视频帧。直播视频帧中包括不同种类的场景元素,如直播房间设施和静态对象。此时,使用与笔记本电脑配套的鼠标设备进行目标场景元素的指定,即,使用鼠标选中直播视频帧中的任意场景元素,作为指定的目标场景元素,进一步将目标场景元素替换成预设的三维虚拟对象。
可选地,直播终端为智能手机时,智能手机上的摄像头采集得到场景视频,将场景视频中的图像帧作为直播视频帧。直播视频帧中包括不同种类的场景元素,如直播房间设施和静态对象。此时,直接使用手指在手机屏幕上进行目标场景元素的指定,即,手指选中直播视频帧中的任意场景元素,作为指定的目标场景元素,进一步将目标场景元素替换成预设的三维虚拟对象。
直播终端开启AR功能,即增强现实(Augmented Reality,AR)功能,使用渲染引擎将预设的三维虚拟对象渲染至目标场景元素的位置,将目标场景元素替换成预设的三维虚拟对象。
其中,三维虚拟对象的类型可以是任意的,包括但不限于三维虚拟人物形象、三维虚拟动物形象、三维虚拟静物形象、三维虚拟动漫形象等中的任意一种。
可选地,将场景元素中的静态对象作为指定的目标场景元素,将三维虚拟动漫形象作为替换的三维虚拟对象。
其中,直播视频帧中场景元素的位姿识别结果是指,经过位姿识别模型对目标场景元素进行分析并输出的结果。
位姿即位置和姿态,是指物体在空间中的位置和它自身的姿态。
可选地,目标场景元素的位姿即目标场景元素在直播视频帧中场景空间中的位置和朝向。
将直播视频帧输入至预设的位姿识别模型中,位姿识别模型会对直播视频帧中已指定的目标场景元素进行位姿识别并分析,位姿识别模型会输出目标场景元素的位姿识别结果。
可选地,位姿识别结果包括:目标场景元素在直播视频帧中场景空间的三维坐标,以及目标场景元素对应的翻转角度。
位姿识别模型输出的位姿识别结果包括目标场景元素的位姿信息,基于位姿识别结果,在直播视频帧中显示与位姿识别结果对应的三维虚拟对象,也即在目标场景元素原有的位置显示预设的三维虚拟对象。
可选地,在直播视频帧中显示与位姿识别结果对应的三维虚拟对象的显示方式包括但不限于以下几种方式中的一种:
1、对直播视频帧中的目标场景元素进行抠图处理,将三维虚拟对象显示在目标场景元素原来的位置;
2、对直播视频帧中的目标场景元素进行覆盖处理,将三维虚拟对象覆盖在目标场景元素上,使目标场景元素原来的位置显示三维虚拟对象。
值得注意的是,用户使用不同终端进行直播时,使用与终端配套的设备对直播视频帧进行目标场景元素的选定的方式是任意的,本实施例对此不加以限定。
值得注意的是,在直播视频帧中所指定目标场景元素的类型可以是任意的,作为替换的三维虚拟对象类型可以是任意的;上述方法中所使用的预设位姿识别模型可以是任意类型的模型,位姿识别模型输出的位姿识别结果可以是任意的,位姿识别结果中包括的信息数量和种类可以是任意的,基于位姿识别结果在直播视频帧中显示与位姿识别结果对应的三维虚拟对象的显示方式可以是任意的,本实施例对此不加以限定。
综上所述,通过获取直播视频帧,将直播视频帧输入位姿识别模型后,输出对直播视频帧中场景元素的位姿识别结果,并基于位姿识别结果在直播视频帧中显示与位姿识别结果对应的三维虚拟对象,能够实现虚实结合的直播效果。使用户在直播时通过直接驱动场景元素,与场景元素之间互动,来实现与虚拟对象实时的互动,提高了用户直播时的体验感和观众观看直播时的观感。
在一些实施例中,位姿识别模型可以使用不同的数据或采用不同的方式训练得到,将直播视频帧输入至位姿识别模型,可以基于位姿识别模型输出的位姿识别结果在直播视频帧中显示与位姿识别结果对应的三维虚拟对象。图5是本申请一个实施例提供的位姿识别模型的训练方法的流程图,如图5所示:
步骤501,获取样本图像。
在样本图像库中选取样本图像,作为训练数据。
样本图像中包括样本场景元素,样本图像标注有样本场景元素对应的参考位姿数据,参考位姿数据中包括样本场景元素在场景空间中的三维坐标,以及样本场景元素对应的翻转角度。
可选地,样本图像为二维图像,样本图像中的内容包含至少一种场景元素,包括但不限于以下元素中的至少一种:静态物品,人物或动物等。
在样本图像中指定一个场景元素作为样本场景元素,样本场景元素主要用于训练位姿识别模型。样本图像标注有样本场景元素对应的参考位姿数据,即样本场景元素在以样本图像为场景空间中的三维坐标,以及样本场景元素对应的翻转角度。
可选地,三维坐标包括三维空间中的(x,y,z)坐标。
可选地,翻转角度包括以下几种角度:俯仰角、偏航角、滚转角。
俯仰角、偏航角、滚转角是基于机体坐标系和惯性坐标系提出的概念。
其中,机体坐标系是指固定在飞行器或者飞机上的遵循右手法则的三维正交直角坐标系,其原点位于飞行器的质心。OX轴位于飞行器参考平面内平行于机身轴线并指向飞行器前方,OY轴垂直于飞行器参考面并指向飞行器右方,OZ轴在参考面内垂直于XOY平面,指向航空器下方。
惯性坐标系是为了简化世界坐标系到物体坐标系的转化而产生的。惯性坐标系的原点与物体坐标系的原点重合,惯性坐标系的轴平行于世界坐标系的轴。引入了惯性坐标系之后,物体坐标系转换到惯性坐标系只需旋转,从惯性坐标系转换到世界坐标系只需平移。
俯仰角是机体坐标系OX轴与水平面的夹角:当机体坐标系的OX轴在惯性坐标系XOY平面上方时,俯仰角为正,否则为负;即,平行于机身轴线并指向飞行器前方的向量与地面的夹角。值得注意的是,此处的机体坐标系和惯性坐标系都是采用右手坐标系。
偏航角是机体轴在水平面上的投影与地轴之间的夹角。
其中,地轴就是地球斜轴,也被称为地球自转轴。具体是指地球自转所绕的轴,其北端与地表的交点是北极,其南端与地表的交点是南极。机体轴是沿飞机机体方向的轴线。
滚转角是机体坐标系OZ轴与通过机体轴的铅垂面间的夹角,机体向右滚为正,反之为负。
在一些实施例中,偏航角、俯仰角和滚转角用于描述飞机或者导弹等飞行器的姿态。在本实施例中,俯仰角、偏航角和滚转角用于表示样本场景元素在样本图像对应的场景空间中的朝向。
值得注意的是,样本图像可以是任意类型的二维图像或其他维度的图像,样本图像的来源可以是任意的;若样本图像来自样本图像库,则样本图像库中的样本图像种类和数量可以是任意的;样本图像中包括的样本场景元素的种类可以是任意的,样本图像中包括的场景元素的数量和种类可以是任意的;样本图像标注的样本场景元素对应的参考位姿数据可以是任意的,参考位姿数据包括但不限于样本场景元素在场景空间中的三维坐标,以及样本场景元素对应的翻转角度,也即参考位姿数据也可以包括其他种类的数据;本实施例对此不加以限定。
步骤502,通过候选位姿识别模型对样本图像中的样本场景元素进行位姿识别,得到预测位姿数据。
候选位姿识别模型是预设的模型,预测位姿数据用于表示样本场景元素的预测位姿情况。
可选地,候选位姿识别模型是一个基于卷积神经网络的模型,由多层卷积层堆叠而成。
其中,卷积神经网络(Convolutional Neural Networks,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deeplearning)的代表算法之一。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariantclassification),因此也被称为“平移不变人工神经网络(Shift-Invariant ArtificialNeural Networks,SIANN)”。
将样本图像输入至候选位姿识别模型后,候选位姿识别模型对样本图像中的样本场景元素进行位姿识别,会得到预测位姿数据。
预测位姿数据包括样本场景元素在以样本图像为场景空间中的预测三维坐标,以及样本场景元素对应的预测翻转角度。
可选地,预测三维坐标包括三维空间中的(x,y,z)坐标。
可选地,预测翻转角度包括以下几种角度:俯仰角、偏航角、滚转角。
值得注意的是,候选位姿识别模型为预设的模型,模型的类型可以是任意的,候选位姿识别模型输出的预测位姿数据包括但不限于样本场景元素在场景空间中的预测三维坐标,以及样本场景元素对应的预测翻转角度,也即预测位姿数据也可以包括其他种类的数据,本实施例对此不加以限定。
步骤503,基于参考位姿数据和预测位姿数据之间的差异,对候选位姿识别模型进行训练,得到位姿识别模型。
参考位姿数据是样本场景元素在样本图像对应的场景空间里的实际位姿信息,而预测位姿数据是候选位姿识别模型对样本场景元素在样本图像对应的场景空间里的预测位姿信息。
计算参考位姿数据和预测位姿数据之间的差异,得到位姿损失值,并基于差异对候选模型进行损失值训练,直到候选位姿识别模型输出的预测位姿数据和参考位姿数据之间的差异不再减少为止。
示意性的,样本场景元素在样本图像对应的场景空间里的位置为P0,参考位姿数据S0为:
1、三维空间的坐标(x0,y0,z0);
2、翻转角度:俯仰角A0、偏航角B0、滚转角C0。
候选位姿识别模型输出的样本场景元素在样本图像对应的场景空间里的位置为P1,预测位姿数据S1为:
1、三维空间的坐标(x1,y1,z1);
2、翻转角度:俯仰角A1、偏航角B1、滚转角C1。
计算参考位姿数据和预测位姿数据之间的差异,得到位姿损失值,位姿损失值包括两个部分:坐标损失值和翻转角度损失值。
示意性的,三维空间的坐标损失值为(x0-x1,y0-y1,z0-z1),翻转角度损失值为:(A0-A1)、(B0-B1)、(C0-C1)。
基于位姿损失值对候选位姿识别模型进行训练的方式包括但不限于以下几种方式中的至少一种:
1、对坐标损失值和翻转角度损失值直接进行融合,得到位姿损失值,基于位姿损失值对候选位姿识别模型进行训练;
2、对坐标损失值和翻转角度损失值进行加权融合,也即采用各自对应的权重对坐标损失值和翻转角度损失值进行融合,计算加权和,得到位姿损失值,基于位姿损失值对候选位姿识别模型进行训练;
可选地,将位姿损失值返回至候选位姿识别模型中进行训练,重复上述过程,直至候选位姿识别模型输出的预测位姿数据与参考位姿数据之间的差值不再变化,则训练完成,得到位姿识别模型。
值得注意的是,计算参考位姿数据和预测位姿数据之间的差异,得到位姿损失值的方式可以是任意的,包括但不限于上述方式;基于位姿损失值对候选位姿识别模型进行训练的方式可以是任意的,包括但不限于上述方式中的至少一种;本实施例对此不加以限定。
值得注意的是,上述方法对候选位姿识别模型进行训练,直至候选位姿识别模型输出的预测位姿数据与参考位姿数据之间的差值不再变化,则训练完成,在一些实施例中,训练完成的标志可以是任意的,也即可以通过其他方式或其他数据指标判断是否完成对候选位姿识别模型的训练。
综上所述,通过获取样本图像,样本图像中包括样本场景元素,样本图像标注有样本场景元素对应的参考位姿数据,使用候选位姿识别模型对样本图像中的样本场景元素进行位姿识别,得到预测位姿数据;基于参考位姿数据和预测位姿数据之间的差异,对候选位姿识别模型进行训练的方法,所得到的位姿识别模型,对样本场景元素的位姿识别结果更准确。
在一些实施例中,用户直播时可以通过基于增强现实的界面显示方法实现和虚拟对象之间的实时互动,图6示出了本申请另一个示例性实施例提供的基于增强现实的界面显示方法的流程图,如图6所示,该方法包括:
步骤601,获取直播视频帧。
同上述步骤301,直播视频帧是终端中的直播应用程序通过摄像头采集得到的场景视频中的图像帧,直播视频帧中包括场景元素。
步骤602,将直播视频帧输入位姿识别模型。
其中,位姿识别模型为上述步骤501至步骤503训练得到的模型。
直播视频帧中包括至少一种类型的场景元素,用户使用终端进行直播时,可以使用终端配套的设备选定直播视频帧中的目标场景元素,用于替换为预设的三维虚拟对象。
可选地,直播终端为笔记本电脑时,使用与笔记本电脑配套的鼠标设备进行目标场景元素的指定。
终端接收元素指定操作,其中,元素指定操作用于对场景视频中被替换的场景元素进行指定。
其中,接收元素指定操作并选中目标场景元素的方式包括但不限于以下方式中的至少一种:
1、接收在场景视频的直播视频帧上的范围框定操作,范围框定操作所框选的图像范围内包括场景元素;如,根据范围框定提示,使用鼠标将目标场景元素框选出来。
2、接收在场景视频的直播视频帧上的长按操作,长按操作对应的目标点为场景元素显示范围内的点;如,长按鼠标左键,将目标场景元素周围的区域圈画出来,该区域仅包括目标场景元素;或者,长按目标场景元素显示范围内的目标点。
值得注意的是,用户使用不同终端进行直播时,使用与终端配套的设备对直播视频帧进行目标场景元素的选定的方式是任意的,也即终端接收元素指定操作的方式可以是任意的,本实施例对此不加以限定。
步骤603,通过位姿识别模型对直播视频帧中的场景元素进行位姿识别,得到位姿识别结果。
终端接收元素指定操作后,选定直播视频帧中的一个场景元素作为目标场景元素,将直播视频帧输入至位姿识别模型后,位姿识别模型会对直播视频帧中的目标场景元素进行位姿识别,得到位姿识别结果。
可选地,位姿识别结果为P,位姿识别结果中包括位姿识别数据S:
1、目标场景元素在三维空间的坐标(x,y,z);
2、目标场景元素的翻转角度:俯仰角A、偏航角B、滚转角C。
值得注意的是,位姿识别模型输出的位姿识别结果可以是任意的,位姿识别数据的种类和数值可以是任意的。
步骤604,对直播视频帧进行元素抠图处理,将场景元素从直播视频帧中抠除。
抠图是图像处理中最常做的操作之一,是把图片或影像的某一部分从原始图片或影像中分离出来成为单独的图层。主要功能是为了后期的合成做准备。方法有套索工具、选框工具、橡皮擦工具等直接选择、快速蒙版、钢笔勾画路径后转选区、抽出滤镜、外挂滤镜抽出、通道、计算、应用图像法等。
本实施例中,对直播视频帧进行元素抠图处理,是基于位姿识别模型输出的位姿识别结果,也即目标场景元素在场景视频中的位置,对原有的目标场景元素进行抠图处理。
值得注意的是,对目标场景元素进行抠图处理的方式可以是任意的,本实施例对此不加以限定。
步骤605,将三维虚拟对象按位姿识别结果显示在直播视频帧中,对场景元素进行替换。
其中,三维虚拟对象是预设的虚拟形象,三维虚拟对象的类型可以是任意的,包括但不限于三维虚拟人物形象、三维虚拟动物形象、三维虚拟静物形象、三维虚拟动漫形象等中的任意一种。
直播终端开启AR功能,即增强现实(Augmented Reality,AR)功能,使用渲染引擎将预设的三维虚拟对象渲染至目标场景元素的位置,将目标场景元素替换成预设的三维虚拟对象。
在计算机领域,渲染在电脑绘图中是指用软件从模型生成图像的过程。模型是用严格定义的语言或者数据结构对于三维物体的描述,它包括几何、视点、纹理以及照明信息。将三维场景中的模型,按照设定好的环境、灯光、材质及渲染参数。
在绘图领域,渲染是计算机动画(Computer Graphics,CG)的最后一道工序,也是最终使图像符合的3D场景的阶段。
渲染引擎则是渲染的工具之一,在原始模型的基础上进行渲染,添加颜色、光照、阴影等内容,最后渲染到屏幕上,最终呈现给观众。
上述步骤604中,基于位姿识别模型输出的位姿识别结果,对原有的目标场景元素进行抠图处理,抠图处理后原有的目标场景元素消失,使用渲染引擎将预设的三维虚拟对象渲染至目标场景元素原来的位置,实现场景元素的替换后,直播流将渲染后的画面推送给直播间的观众,观众观看到的画面则为三维虚拟对象位于场景视频中的画面。
值得注意的是,将三维虚拟对象按位姿识别结果显示在直播视频帧中的方式可以是任意的,包括但不限于使用渲染引擎;若使用渲染引擎将预设的三维虚拟对象渲染至目标场景元素的位置,实现目标场景元素的替换,则渲染引擎的种类可以是任意的;上述方法中对目标场景元素进行抠图来实现目标场景元素的替换,在一些实施例中,也可以使用其他方式来实现替换,本实施例对此不加以限定。
示意性的,图7是本申请一个示例性实施例提供的选中目标场景元素并进行替换的示意图,如图7所示:
终端获取实时视频流中的直播视频帧,直播视频帧中包括场景空间700,场景空间700中包含场景元素710,用鼠标圈中场景元素710,将其作为目标替换对象。此时,将直播视频帧输入至预先训练好的位姿识别模型,位姿训练模型会输出场景元素710在场景空间700中的位姿识别结果720,即场景元素710的位置信息。对直播视频帧进行元素抠图处理,将场景元素710从当前位置抠图出去,使用渲染引擎,将预设的三维虚拟对象730渲染至场景元素710原来的位置,完成直播时场景元素710和三维虚拟对象730之间的替换。
综上所述,通过获取直播视频帧,将直播视频帧输入位姿识别模型后,输出对直播视频帧中场景元素的位姿识别结果,并基于位姿识别结果在直播视频帧中显示与位姿识别结果对应的三维虚拟对象,能够实现虚实结合的直播效果。使用户在直播时通过直接驱动场景元素,与场景元素之间互动,来实现与虚拟对象实时的互动,提高了用户直播时的体验感和观众观看直播时的观感。
本实施例提供的方法,通过将直播视频帧输入位姿识别模型,输出得到场景元素对应的位姿识别结果,将三维虚拟对象按位姿识别结果显示在直播视频帧中的方法,提高了画面的显示效果,能够实现虚实结合的直播效果,提高了用户和观众的体验感。
本实施例提供的方法,将直播视频帧输入位姿识别模型,使位姿识别模型对直播视频帧中的场景元素进行位姿识别,得到位姿识别结果,位姿识别结果中包括场景元素在场景空间中的三维坐标,以及场景元素对应的翻转角度,能够提高位姿识别结果的准确性。
本实施例提供的方法,通过对直播视频帧进行元素抠图处理,将待替换的目标场景元素从直播视频帧中抠除;基于位姿识别结果,将三维虚拟对象按显示在直播视频帧中,对场景元素进行替换,实现了虚实结合的直播效果,提高了用户和观众的体验感。
本实施例提供的方法,通过接收元素指定操作,对直播视频帧对应的场景视频中需要被替换的场景元素进行指定,提高了场景元素替换的准确性和效率。
本实施例提供的方法,接收在场景视频的直播视频帧上的范围框定操作,范围框定操作所框选的图像范围内包括场景元素;或者,接收在场景视频的直播视频帧上的长按操作,长按操作对应的目标点为场景元素显示范围内的点,能够对需要被替换的场景元素进行指定,提高了场景元素替换的准确性和效率。
在一些实施例中,基于增强现实的界面显示方法,可以应用在AR直播时,将现实场景元素替换为虚拟对象,实现主播与虚拟对象的实时互动,图8是本申请一个示例性实施例提供的界面显示方法的应用示意图,如图8所示:
用户进行直播并开启AR功能后,通过上述基于增强现实的界面显示方法,可以将直播视频帧中的目标场景元素替换为预设的三维虚拟对象,并通过驱动目标场景元素,来实现和虚拟对象之间的实时互动。
观众观看直播时,可以看到在直播视频帧对应的场景空间800中,显示了三维虚拟对象820,主播810通过对现实的目标场景元素进行抚摸操作,在直播流中则会显示主播810对三维虚拟对象820进行抚摸操作的实时画面,通过驱动现实的目标场景元素来实现对三维虚拟对象820之间的互动,如图8所示,改变了三维虚拟对象820的位置朝向。也即,三维虚拟对象820可以被主播810的手直接改变方向,实现交互。
综上所述,通过上述方法,将现实的目标场景元素替换成预设好的三维虚拟对象,使观众能够在直播间推送的视频内容中看到不同的虚拟对象,提高了直播的显示效果,可以实现虚实结合的互动,主播直接驱动现实的目标场景元素时,在直播视频中可以看到与三维虚拟对象直接进行互动的画面,而不需要随时观察三维虚拟对象的位姿情况来调整动作,提高了主播直播时的体验感和用户在观看直播时的体验感。
在一些实施例中,基于增强现实的界面显示方法,还可以应用在AR直播时,将现实场景元素替换为虚拟元素,改变直播环境的显示效果,图9是本申请另一个示例性实施例提供的界面显示方法的应用示意图,如图9所示:
观众观看直播时,可以看到在直播视频帧对应的场景空间900中,显示了主播910正在直播的画面,场景空间900中包括一些场景元素,如:目标场景元素920。其中,目标场景元素920是台灯。
主播910开启AR功能后,通过上述基于增强现实的界面显示方法,可以选中目标场景元素920,将其替换成虚拟元素,如:虚拟樱花树930。
观众在直播间观看到的画面即为:主播910在场景空间900中直播,场景空间900中还包括虚拟樱花树930。
可选地,还可以使用不同主题的画面元素、风景元素对场景空间900中的目标场景元素920进行替换,也可将直播间内容易出现违规的物品转换为其他布景。
值得注意的是,通过上述基于增强现实的界面显示方法可以替换场景空间中任意的元素,可以将原有的目标场景元素替换成任意的虚拟元素,本实施例对此不加以限定。
综上所述,基于增强现实的界面显示方法,可以将现实的目标场景元素替换成虚拟元素,改变主播在直播时的背景或环境,实现优化背景的效果;或者,改变直播场景内的物体,优化直播场景内的布局,提高了用户直播时的体验感和观众观看直播时的观感。
在一些实施例中,用户进行AR直播时,与三维虚拟对象进行互动之前还可以指定具体的三维虚拟对象,并控制三维虚拟对象的外观状态和活动状态进行改变。图10是本申请另一个示例性实施例提供的对三维虚拟对象进行控制的方法的流程图,如图10所示,包括如下步骤。
步骤1001,接收虚拟对象选择操作。
虚拟对象选择操作用于在多个候选虚拟对象中对三维虚拟对象进行选择。
可选地,共有5个候选虚拟对象,分别为虚拟对象A、虚拟对象B、虚拟对象C、虚拟对象D、虚拟对象E。
选择虚拟对象A作为互动的三维虚拟对象,虚拟对象A的颜色为红色,虚拟对象A的种类是动物。
值得注意的是,候选虚拟对象的数量可以是任意的,候选虚拟对象的种类可以是任意的,候选虚拟对象的颜色可以是任意的,接收虚拟对象选择操作后可以选择任意一个候选虚拟对象作为互动的三维虚拟对象,本实施例对此不加以限定。
步骤1002,响应于场景元素在场景空间中处于活动状态,在直播视频中显示三维虚拟对象的活动动画。
选中三维虚拟对象后,使用渲染引擎将三维虚拟对象渲染至场景元素在场景空间中的位置,当场景元素进行活动时,对应的也会在直播视频中显示三维虚拟对象的活动动画。
其中,活动动画包括三维虚拟对象的动作和位置变化中的至少一种。
可选地,三维虚拟对象的动作为跑步,其位置随着跑步动作的进行而变化。
其中,场景元素的活动状态包括受控活动状态和自动活动状态中的任意一种。
可选地,当场景元素为静态物体时,即物体无法自身进行活动,场景元素的活动状态为受控活动状态,用户进行直播时驱动场景元素进行活动,则三维虚拟对象也会进行对应的活动。
可选地,当场景元素为动态物体时,即物体可以自身进行活动,场景元素的活动状态为自动活动状态,用户进行直播时不需要驱动场景元素,场景元素就可以自己进行活动,当场景元素活动时,三维虚拟对象也会进行对应的活动。
值得注意的是,场景元素的种类可以是任意的,场景元素的活动状态可以是任意的,场景元素进行活动时,其动作可以是任意的,本实施例对此不加以限定。
步骤1003,接收外观更新操作。
外观更新操作用于控制三维虚拟对象进行表现效果的更新。
可选地,改变三维虚拟对象的颜色外观,三维虚拟对象原来的颜色为红色,将其改变为蓝色。
值得注意的是,接收外观更新操作并控制三维虚拟对象进行表现效果的更新时,其外观更新的方式可以是任意的,包括但不限于改变其颜色外观等;当改变三维虚拟对象的颜色外观时,其颜色可以是任意的,本实施例对此不加以限定。
步骤1004,基于外观更新操作显示三维虚拟对象从第一表现效果切换至第二表现效果。
接收外观更新操作以后,观众和用户通过直播视频观察到的三维虚拟对象的表现效果也会更新,第一表现效果是三维虚拟对象的初始表现效果,第二表现效果是接收外观更新操作以后的表现效果。
值得注意的是,三维虚拟对象的第一表现效果和第二表现效果可以是任意的,可以进行任意次数的表现效果切换,本实施例对此不加以限定。
综上,通过接收虚拟对象选择操作,可以指定三维虚拟对象作为用户直播的互动对象,对三维虚拟对象进行外观更新操作,可以改变三维虚拟对象在直播视频中的表现效果;对场景元素进行驱动使其活动,或场景元素自己活动时,三维虚拟对象也会对应的进行活动,能够提高直播的趣味性,提高用户直播时的互动体验和观众在观看直播时的观看体验。
本实施例提供的方法,通过接收虚拟对象选择操作,在多个候选虚拟对象中对三维虚拟对象进行选择,可以指定虚拟对象进行互动,提高了互动的体验感。
本实施例提供的方法,基于场景元素在场景空间中的活动状态,在直播视频中显示三维虚拟对象的活动动画,其中,活动动画包括三维虚拟对象的动作和位置变化中的至少一种,场景元素的活动状态包括受控活动状态和自动活动状态中的任意一种,增加了直播的趣味性,丰富了三维虚拟对象在直播中的表现力。
本实施例提供的方法,接收外观更新操作,控制三维虚拟对象进行表现效果的更新,基于外观更新操作显示三维虚拟对象从第一表现效果切换至第二表现效果,改变了三维虚拟对象的外观表现效果,增加了直播的趣味性。
图11是本申请一个示例性实施例提供的基于增强现实的界面显示装置的结构框图,如图11所示,该装置包括如下部分:
获取模块1110,用于获取直播视频帧,所述直播视频帧是所述终端中的直播应用程序通过摄像头采集得到的场景视频中的图像帧,所述直播视频帧中包括场景元素;
显示模块1120,用于基于对所述直播视频帧中所述场景元素的位姿识别结果,在所述直播视频帧中显示与所述位姿识别结果对应的三维虚拟对象。
在一个可选的实施例中,如图12所示,所述显示模块1120,包括:
输入单元1121,用于将所述直播视频帧输入位姿识别模型,输出得到所述场景元素对应的所述位姿识别结果,所述位姿识别模型为预先训练得到的模型;
显示单元1122,用于将所述三维虚拟对象按所述位姿识别结果显示在所述直播视频帧中。
在一个可选的实施例中,所述装置还包括:
所述获取模块1110,还用于获取样本图像,所述样本图像中包括样本场景元素,所述样本图像标注有所述样本场景元素对应的参考位姿数据,所述参考位姿数据中包括所述样本场景元素在场景空间中的三维坐标,以及所述样本场景元素对应的翻转角度;
识别模块1130,用于通过候选位姿识别模型对所述样本图像中的所述样本场景元素进行位姿识别,得到预测位姿数据;
训练模块1140,用于基于所述参考位姿数据和所述预测位姿数据之间的差异,对所述候选位姿识别模型进行训练,得到所述位姿识别模型。
在一个可选的实施例中,所述输入单元1121,还用于将所述直播视频帧输入位姿识别模型;通过所述位姿识别模型对所述直播视频帧中的所述场景元素进行位姿识别,得到所述位姿识别结果,所述位姿识别结果中包括所述场景元素在场景空间中的三维坐标,以及所述场景元素对应的翻转角度。
在一个可选的实施例中,所述显示单元1122,还用于对所述直播视频帧进行元素抠图处理,将所述场景元素从所述直播视频帧中抠除;将所述三维虚拟对象按所述位姿识别结果显示在所述直播视频帧中,对所述场景元素进行替换。
在一个可选的实施例中,所述装置还包括:
接收模块1150,用于接收元素指定操作,所述元素指定操作用于对所述场景视频中被替换的所述场景元素进行指定。
在一个可选的实施例中,所述接收模块1150,还用于接收在所述场景视频的直播视频帧上的范围框定操作,所述范围框定操作所框选的图像范围内包括所述场景元素;或者,接收在所述场景视频的直播视频帧上的长按操作,所述长按操作对应的目标点为所述场景元素显示范围内的点。
在一个可选的实施例中,所述接收模块1150,还用于接收虚拟对象选择操作,所述虚拟对象选择操作用于在多个候选虚拟对象中对所述三维虚拟对象进行选择。
在一个可选的实施例中,所述显示模块1120,还用于响应于所述场景元素在场景空间中处于活动状态,在所述直播视频中显示所述三维虚拟对象的活动动画,其中,所述活动动画包括所述三维虚拟对象的动作和位置变化中的至少一种;其中,所述场景元素的活动状态包括受控活动状态和自动活动状态中的任意一种。
在一个可选的实施例中,所述接收模块1150,还用于接收外观更新操作,所述外观更新操作用于控制所述三维虚拟对象进行表现效果的更新;基于所述外观更新操作显示所述三维虚拟对象从第一表现效果切换至第二表现效果。
综上所述,本申请实施例提供的装置,通过训练位姿识别模型,获取直播视频帧,将直播视频帧输入位姿识别模型后,输出对直播视频帧中场景元素的位姿识别结果,并基于位姿识别结果在直播视频帧中显示与位姿识别结果对应的三维虚拟对象,能够使用户在直播时通过直接驱动场景元素,与场景元素之间互动,来实现与虚拟对象实时的互动,提高了用户直播时的体验感和观众观看直播时的观感。
需要说明的是:上述实施例提供的基于增强现实的界面显示装置,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的虚拟对象的生成装置与虚拟对象的生成方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
图13示出了本申请一个示例性实施例提供的计算机设备1300的结构框图。该计算机设备1300可以是:智能手机、平板电脑、MP3播放器(Moving Picture Experts GroupAudio Layer III,动态影像专家压缩标准音频层面3)、MP4(Moving Picture ExpertsGroup Audio Layer IV,动态影像专家压缩标准音频层面4)播放器、笔记本电脑或台式电脑。计算机设备1300还可能被称为用户设备、便携式终端、膝上型终端、台式终端等其他名称。
通常,计算机设备1300包括有:处理器1301和存储器1302。
处理器1301可以包括一个或多个处理核心,比如4核心处理器、8核心处理器等。处理器1301可以采用DSP(Digital Signal Processing,数字信号处理)、FPGA(Field-Programmable Gate Array,现场可编程门阵列)、PLA(Programmable Logic Array,可编程逻辑阵列)中的至少一种硬件形式来实现。处理器1301也可以包括主处理器和协处理器,主处理器是用于对在唤醒状态下的数据进行处理的处理器,也称CPU(Central ProcessingUnit,中央处理器);协处理器是用于对在待机状态下的数据进行处理的低功耗处理器。在一些实施例中,处理器1301可以在集成有GPU(Graphics Processing Unit,图像处理器),GPU用于负责显示屏所需要显示的内容的渲染和绘制。一些实施例中,处理器1301还可以包括AI处理器,该AI处理器用于处理有关机器学习的计算操作。
存储器1302可以包括一个或多个计算机可读存储介质,该计算机可读存储介质可以是非暂态的。存储器1302还可包括高速随机存取存储器,以及非易失性存储器,比如一个或多个磁盘存储设备、闪存存储设备。在一些实施例中,存储器1302中的非暂态的计算机可读存储介质用于存储至少一个指令,该至少一个指令用于被处理器1301所执行以实现本申请中方法实施例提供的虚拟对象的互动方法。
在一些实施例中,计算机设备1300还包括其他组件,本领域技术人员可以理解,图13中示出的结构并不构成对终端1300的限定,可以包括比图示更多或更少的组件,或者组合某些组件,或者采用不同的组件布置。
可选地,该计算机可读存储介质可以包括:只读存储器(ROM,Read Only Memory)、随机存取记忆体(RAM,Random Access Memory)、固态硬盘(SSD,Solid State Drives)或光盘等。其中,随机存取记忆体可以包括电阻式随机存取记忆体(ReRAM,Resistance RandomAccess Memory)和动态随机存取存储器(DRAM,Dynamic Random Access Memory)。上述本申请实施例序号仅仅为了描述,不代表实施例的优劣。
本申请实施例还提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行以实现如上述本申请实施例中任一所述的虚拟对象的互动方法。
本申请实施例还提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由处理器加载并执行以实现如上述本申请实施例中任一所述的虚拟对象的互动方法。
本申请实施例还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述实施例中任一所述的虚拟对象的互动方法。
可选地,该计算机可读存储介质可以包括:只读存储器(ROM,Read Only Memory)、随机存取记忆体(RAM,Random Access Memory)、固态硬盘(SSD,Solid State Drives)或光盘等。其中,随机存取记忆体可以包括电阻式随机存取记忆体(ReRAM,Resistance RandomAccess Memory)和动态随机存取存储器(DRAM,Dynamic Random Access Memory)。上述本申请实施例序号仅仅为了描述,不代表实施例的优劣。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上所述仅为本申请的较佳实施例,并不用以限制本申请,凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 基于网页标签的产品数据推送方法、装置、设备及介质
- 基于区块链的理财产品推荐方法、装置、介质及电子设备
- 基于模板的产品构建方法、装置、计算机设备及存储介质
- 基于模型的产品构建方法、装置、计算机设备及存储介质
- 基于图表的产品构建方法、装置、计算机设备及存储介质
- 基于增强现实的显示方法、设备、存储介质及程序产品
- 基于增强现实的产品展示方法、系统、介质及电子设备