一种提升AI计算芯片超分运算性能的方法
文献发布时间:2023-06-19 19:28:50
技术领域
本申请属于存内超分运算性能领域,具体涉及一种提升AI计算芯片超分运算性能的方法。
背景技术
现主流的超分模型都采用输入为LR图像,对LR图像做特征提取,最后输出Interpolate(插值)为HR,如比较典型的SR模型---Real-ESRGAN,Real ESRGAN的网络结构包含依次连接的输入层、RRDB模块和输出层。其中,如图2所示,RRDB模块(Residual inResidual Dense Block,中文简称残差密集块)的网络结构具体包括多个串联拼接的DenseBlock模块,每个Dense Block 模块中有五层结构,每层结构中均包含conv算子,前四层结构中还设有Lrelu算子。
传统冯·诺依曼架构下存储单元和运算单元分离,数据需在计算和存储单元之间频繁移动,数据搬运的时间甚至会达到计算时间的数百倍,并在此过程造成占比逾60%-90%的功耗。存内计算通过对存储器件进行改造,将存储单元与计算单元融合,使存储器件可直接参与计算,能从根本上突破这些瓶颈。存内计算的方法极大地降低了数据搬运的能耗和延时,提升了计算的能效比。基于ReRAM存算一体的AI计算芯片目前是国内外的研究热点。
基于 ReRAM存算一体的AI计算芯片的计算过程需要精心排布才能充分利用算力,在典型的存算一体架构中,算子在这些硬件上的耗时无法简单地用计算量除以算力获得,更多要看各个组件间的排布情况,相同任务用不同的计算流水排布效率差别巨大,甚至看似相近的计算输入可能要求的计算流水排布也会相差很大。典型的AI存算一体加速架构和CGRA(粗粒度可重构架构)相似,一般包括两个运算单元和一个L1 SRAM单元,第一个运算单元是ReRAM,权重参数在初始化阶段预先写入ReRAM运算单元,静态权重相关的卷积运算都在此单元执行;第二个运算单元是VPU运算单元,所有非静态权重相关的运算都在此运算单元运行;L1SRAM单元配置为两个运算单元的输入/中间/输出三部分。
Real ESRGAN超分模型在存算一体芯片上部署时,出于成本考虑,一般L1 SRAM配置为512K,为提升排布性能,512K 的L1 SRAM须切分为Inputs/Intern/Output(输入/中间/输出)三部分,大概比例为1:4:1,大致的内存空间分配情况(下列划分的内存大小仅仅是示例性划分获得的)如下:
- 输入: 40+40 = 80 KB
- 中间: 160+160 = 320 KB
- 输出: 40+40 = 80 KB
按上面的分配比例,为满足Real ESRGAN超分模型在存算一体芯片中的正常排布,需要将输入1080P的图片切分为48 * 24 = 1152份,切分后图片的分辨率大小为(40, 45),Real ESRGAN超分模型的Input层,RRDB模块及Output层的Tensor Size(张量大小)详见下表 1所示:
表1 超分模型的张量表
表1中内存大小的单位是byte,张量大小通过现有张量计算工具计算可得。由于卷积后面都会带Lrelu,Lrelu算子并未在表1中示出,表1中第一列示出的张量为Real ESRGAN超分模型的主要算子。这样切分后,Input和RRDB模块的张量大小可以正常部署到L1 SRAM中,但从第一个Interpolate1算子到最后HR conv算子运算过程中的输入数据占用的内存空占用的内存空间较大,影响排布的排布效率;
如把这些算子拆分,以放大倍数= 4为例,各算子需要拆分成如下表格2中数量,即220个,才能满足512K L1 SRAM容量的要求以及乒乓缓存的设置。
表2 算子拆分数量结果表
这样算子拆分方式的存在以下缺点:
1、要想充分利用算力,拆分后算子部署需大量的Tile,光拆分部分需要的Tile数量 = 220/4(55个),如每个芯片包含32Tile,则输出部分就需要两颗芯片,芯片之间还需数据交互,存内部署成本高。
2、不仅插值层需拆分,配套的三个Conv算子和三个Lrelu算子也需要配合同步拆分,整个输出部分运算过程的排布较复杂。
3、不同Tile之间的数据通过DMA传输,算子拆分后的运算数据通过DMA传输的次数也会大大增加,数据传输延时的增加也会降低推理运算性能。
发明内容
为此,本申请提供了一种提升AI计算芯片超分运算性能的方法,有助于解决现有AI存内计算芯片进行存内超分运算时,流程排布效率较低,总线传输延时和芯片部署成本较高的问题。
为实现以上目的,本申请采用如下技术方案:
本申请提供一种提升AI计算芯片超分运算性能的方法,包括:
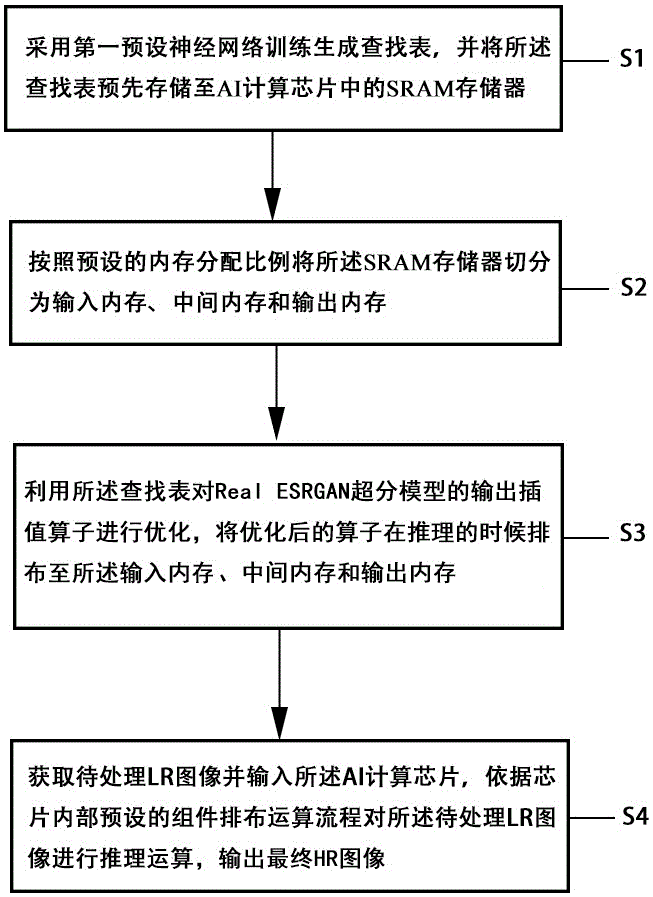
S1:采用第一预设神经网络训练生成查找表,并将所述查找表预先存储至AI计算芯片中的SRAM存储器;
S2:按照预设的内存分配比例将所述SRAM存储器切分为输入内存、中间内存和输出内存;
S3:利用所述查找表对Real ESRGAN超分模型的输出插值算子进行优化,将优化后的算子在推理的时候排布至所述输入内存、中间内存和输出内存;
S4:获取待处理LR图像并输入所述AI计算芯片,依据芯片内部预设的组件排布运算流程对所述待处理LR图像进行推理运算,输出最终的HR图像。
进一步地,所述采用第一预设神经网络训练生成查找表,并将所述查找表预先存储至AI计算芯片中的SRAM存储器具体包括:
先利用预设的训练集对第一预设神经网络进行训练,获得具有小感受野的轻量级深度SR网络;所述第一预设神经网络具体为6个卷积层组成的深度网络;
依据预设的采样间隔对LR训练图像的原始像素输入范围进行下采样处理;
以下采样处理后LR训练图像的像素输入值作为查找表的索引,将预设LR图像的像素输入值输入所述轻量级深度SR网络进行学习,计算出对应的HR输出值并存储至所述查找表。
进一步地,所述利用所述查找表对Real ESRGAN超分模型的输出插值算子进行优化,将优化后的算子在推理的时候排布至所述输入内存、中间内存和输出内存包括:
利用查表法对Real ESRGAN超分模型的输出插值算子进行优化,将输出插值算子的运算方式设置为查表,依据输出插值算子的输入值在所述查找表中查找出对应的输出值,并将查找出的输出值作为输出插值算子的运算结果;所述输出插值算子具体包括第一Lrelu算子、第二Lrelu算子、第三Lrelu算子、第一Upconv算子、第二Upconv算子、HRconv算子、第一Interpolate算子和第二Interpolate算子;
将第一Interpolate算子和第二Interpolate算子进行两次拆分放大优化,并将所述Real ESRGAN超分模型中的TrunkConv算子拆分为两个;
将优化后的算子在推理的时候排布至所述输入内存、中间内存和输出内存,同时将Real ESRGAN超分模型的权重参数预先写入所述AI计算芯片的ReRAM运算单元。
进一步地,所述获取待处理LR图像并输入所述AI计算芯片,依据芯片内部预设的组件排布运算流程对所述待处理LR图像进行推理运算,输出最终的HR图像具体包括:
获取待处理的LR图像并按照预设的切分方式对其进行切分,获得待处理的LR图像的多个输入特征图;
依据芯片内部预设的组件排布运算流程对输入特征图进行推理运算,输出最终的HR图像;
所述预设的组件排布运算流程具体如下:
步骤1:第一个输入特征图首先传输到Tile 0的SRAM存储器;
步骤2:判断算子是否与静态参数相关,若算子为静态参数相关的卷积算子,则输入特征图会通过L1 SRAM存储器传输到ReRAM运算单元中与预先写入的权重参数进行卷积操作;
步骤3:若算子与静态参数不相关,则将与静态参数不相关的卷积算子设置在SIMDVPU单元上推理运算;
步骤4:重复执行步骤1~3,直至Tile0内部的SIMD VPU单元和ReRAM运算单元之间结束并行推理运算;
步骤5:Tile 0推理运算完成后,Tile0 的CPU通过消息触发Tile1 的CPU中断,同时把推理运算完成的输出数据通过DMA传输到Tile1的SRAM存储器;
步骤6:依据步骤1~3,Tile 1开始第一个输入特征图的推理运算,同时将第二个输入特征图传输至Tile 0的SRAM存储器,Tile0开始第二个输入特征图的推理运算;
步骤7:Tile 1推理运算完成后将第一个输入特征图的推理运算结果传输至Tile2,Tile 2开始第一个输入特征图的推理运算;Tile0将第二个输入特征图的推理运算结果传输至Tile 1,Tile 1同时开始第二个输入特征图的推理运算;同时Tile 0开始第三个输入特征图的推理运算;
步骤8:重复执行步骤1~7,直至Tile n完成最后一个输入特征图的推理运算,输出HR图像。
本申请采用以上技术方案,至少具备以下有益效果:
通过本申请提供的一种提升AI计算芯片超分运算性能的方法,方法采用第一预设神经网络训练生成查找表,并将所述查找表预先存储至AI计算芯片中的SRAM存储器;按照预设的内存分配比例将所述SRAM存储器切分为输入内存、中间内存和输出内存;利用所述查找表对Real ESRGAN超分模型的输出插值算子进行优化,将优化后的算子在推理的时候排布至所述输入内存、中间内存和输出内存;获取待处理LR图像并输入所述AI计算芯片,依据芯片内部预设的组件排布运算流程对所述待处理LR图像进行推理运算,输出最终的HR图像。本申请通过生成查找表来对Real ESRGAN超分模型的部分算子进行优化,减少了模型的权重参数,可有效的减少部署时Tile的数量,降低芯片部署成本。同时按照预设的内存分配比例将所述SRAM存储器切分为输入内存、中间内存和输出内存,将优化后的Real ESRGAN超分模型部署到切分的内存空间,并依据芯片内部预设的组件排布运算流程对所述待处理LR图像进行推理运算,可以合理安排芯片内各个组件间的排布,提升计算流水排布效率的同时提升并行运算性能,避免不同Tile之间数据频繁的总线传输,降低了总线传输的延时。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本申请。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
图1是根据一示例性实施例示出的一种提升AI计算芯片超分运算性能的方法流程图;
图2是根据一示例性实施例示出的RRDB模块网络结构图;
图3是根据一示例性实施例示出的传统放大方式拆分算子后输出插值层的排布流程图;
图4是根据一示例性实施例示出的采用本申请放大方式拆分算子后输出插值层的排布流程图;
图5是根据一示例性实施例示出的AI计算芯片的切分和运算流程图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将对本申请的技术方案进行详细的描述。
请参阅图1,图1是根据一示例性实施例示出的一种提升AI计算芯片超分运算性能的方法流程图。如图1所示,方法包括:
S1:采用第一预设神经网络训练生成查找表,并将所述查找表预先存储至AI计算芯片中的SRAM存储器;
S2:按照预设的内存分配比例将所述SRAM存储器切分为输入内存、中间内存和输出内存;
S3:利用所述查找表对Real ESRGAN超分模型的输出插值算子进行优化,将优化后的算子在推理的时排布至所述输入内存、中间内存和输出内存;
S4:获取待处理LR图像并输入所述AI计算芯片,依据芯片内部预设的组件排布运算流程对所述待处理LR图像进行推理运算,输出最终的HR图像。
进一步地,在一个实施例中,进一步地,所述采用第一预设神经网络训练生成查找表,并将所述查找表预先存储至AI计算芯片中的SRAM存储器具体包括:
先利用预设的训练集对第一预设神经网络进行训练,获得具有小感受野的轻量级深度SR网络;所述第一预设神经网络具体为6个卷积层组成的深度网络;
依据预设的采样间隔对LR训练图像的原始像素输入范围进行下采样处理;
以下采样处理后LR训练图像的像素输入值作为查找表的索引,将预设LR图像的像素输入值输入所述轻量级深度SR网络进行学习,计算出对应的HR输出值并存储至所述查找表。
其中,查找表(Look Up Table,,简称LUT)相当于一个离散函数,给定一个输入值,通过查找表来得到一个输出值。
具体实践过程中,查找表的实现过程具体为:
Step1:先通过训练一个具有小感受野的轻量级深度SR网络。
比如一个由六个Conv层组成的深度网络,激活层采用Relu,通过一个pixelshuffle(像素重组)操作,将网络的输出调整为所需的大小。
Step2:将学习到的深度模型输出值传递给LUT。
对于Full Size(全尺寸)的LUT,对所有可能的输入值计算学习的深度网络的输出值,并将它们保存到LUT中。输入值用作LUT的索引,相应的输出值存储在该位置。表3中展示了不同尺寸感受野所产生LUT的大小。当感受野(Upscale)为2,放大倍率为4时,SR-LUT的全尺寸为1MB。当感受野分别为3、4时,LUT的全尺寸变为256M、64G。
表3 LUT大小结果表
LUT的大小会随感受野指数增加,全尺寸的LUT尺寸太大,所以在实践中必须对原始输入范围进行下采样,当感受野为2时,使用均匀采样后生成的LUT,将原始输入空间的2
已经过验证,间隔大小为 2
对于感受野为3时,间隔大小为 2
Step3:AI存内计算芯片进行推理运算时,从LUT中查询LR输入像素预先计算的HR输出值。
下采样后的LUT性能见表 4,其中Ours-V表示感受野为2,Ours-F的感受野为3,Ours-S为4。
表4 下采样后的LUT性能表
进一步地,在一个实施例中,所述按照预设的内存分配比例将所述SRAM存储器切分为输入内存、中间内存和输出内存具体包括:
依据所述SRAM存储器的内存大小,按照预设的内存分配比例将所述SRAM存储器内存空间切分为输入内存、中间内存和输出内存;所述预设的内存分配比例为1:4:1。
进一步地,所述按照预设的内存分配比例将所述SRAM存储器切分为输入内存、中间内存和输出内存具体包括:
依据所述SRAM存储器的内存大小,按照预设的内存分配比例将所述SRAM存储器内存空间切分为输入内存、中间内存和输出内存;所述预设的内存分配比例为1:4:1。
进一步地,在一个实施例中,所述利用所述查找表对Real ESRGAN超分模型的输出插值算子进行优化,将优化后的算子在推理的时候排布至所述输入内存、中间内存和输出内存包括:
利用查表法对Real ESRGAN超分模型的输出插值算子进行优化,将输出插值算子的运算方式设置为查表,依据输出插值算子的输入值在所述查找表中查找出对应的输出值,并将查找出的输出值作为输出插值算子的运算结果;所述输出插值算子具体包括第一Lrelu算子、第二Lrelu算子、第三Lrelu算子、第一Upconv算子、第二Upconv算子、HRconv算子、第一Interpolate算子和第二Interpolate算子;
将第一Interpolate算子和第二Interpolate算子进行两次拆分放大优化,并将所述Real ESRGAN超分模型中的TrunkConv算子拆分为两个;
将优化后的算子在推理的时候排布至所述输入内存、中间内存和输出内存,同时将Real ESRGAN超分模型的权重参数预先写入所述AI计算芯片的ReRAM运算单元。
具体实践过程中,第一Interpolate算子和第二Interpolate算子对应模型输出部分的两个插值层(即表1中的Interpolate1和Interpolate2),第一Upconv算子、第二Upconv算子、HRconv算子对应模型输出部分的三个conv算子(即表1中的Output upconv1、Outputupconv2和HRconv)。而在模型中,conv算子后面都会带有Lrelu算子(表1中未示出),因此第一Lrelu算子、第二Lrelu算子、第三Lrelu算子与模型输出部分conv算子带有的三个Lrelu算子相对应。
其中,参照表2,在利用传统的算子拆分优化方法对超分模型的算子进行拆分后,Output/Interpolate(插值)的排布流程如图3所示 ,此时AI计算芯片内部的内存切分和运算流程参考如下:
Tile n:
- ReRAM TrunkConv-1 - current cycle - 56 KB
- ReRAM TrunkConv-1 - next cycle - 56 KB
- SIMD VPU LRelu output - current cycle - 56 KB
- SIMD VPU LRelu output - next cycle - 56 KB
- SIMD VPU Interpolate1 4-1 output - current cycle - 56 KB
- SIMD VPU Interpolate1 4-1 output - next cycle - 56 KB
- ReRAM UpConv1 4-1 - current cycle - 56 KB
- ReRAM UpConv1 4-1 - next cycle - 56 KB
Tile n+1:
- SIMD VPU LRelu output - current cycle - 56 KB
- SIMD VPU LRelu output - next cycle - 56 KB
- SIMD VPU Interpolate1 16-1 output - current cycle - 56 KB
- SIMD VPU Interpolate1 16-1 output - next cycle - 56 KB
- ReRAM UpConv2 16-1 - current cycle - 56 KB
- ReRAM UpConv2 16-1 - next cycle - 56 KB
- SIMD VPU LRelu output - current cycle - 56 KB
- SIMD VPU LRelu output - next cycle - 56 KB
Tile n+2:
- ReRAM HRConv 16-1 - current cycle - 56 KB
- ReRAM HRConv 16-1 - next cycle - 56 KB
- SIMD VPU LRelu output - current cycle - 56 KB
- SIMD VPU LRelu output - next cycle - 56 KB
- ReRAM ConvLast 16-1 - current cycle - 56 KB
- ReRAM ConvLast 16-1 - next cycle - 56 KB
而在采用本申请提供的算子优化方式后,输出部分原来的两个Interpolate(插值)层和配套的三个Conv算子和三个Lrelu算子全部采用查表来实现,优化后张量大小如下表5所示:
表5 优化后的模型张量表
在表5中,最后一行中张量Interpolate其对应的算子(即第一Interpolate算子和第二Interpolate算子)已经优化为查表实现,表5中示出的Interpolate的张量大小和内存大小仅代表模型查表实现后输出所占用的张量大小和内存大小。张量大小是一个数组,内存大小是根据张量大小计算获得的,例如张量大小为[1,64,45,40],则对应的内存大小为1*64*45*40=57600*2。
模型的Interpolate(插值)部分需168K的数据存储空间,因此只需其对应的算子拆分两次,TrunkConv算子也拆分为两个算子,拆分后算子的排布流程如图4所示,芯片内部的切分和运算流程如图5所示,其主要包括:
Tile n:
Step 1:- ReRAM TrunkConv-1 - 56 KB
T=1时刻,在ReRAM运算单元进行Input0的TrunkConv1(卷积)运算,运算的输入占用了56KB的L1 SRAM;
Step 2:
- ReRAM TrunkConv-1 - 56 KB
- SIMD VPU LRelu - 56 KB
T=2时刻,Step1运算结束,输出占用了56KB,开始在SIMD VPU运算单元进行Input0的Relu/Lrelu运算;同时在ReRAM单元进行Input1的TrunkConv1(卷积)运算,输入同样占用了56KB的L1 SRAM;
Step 3:
- ReRAM ConvLast - 10.5KB
- SIMD VPU LRelu - 56 KB
T=3时刻,Step2的Relu/Lrelu运算结束,输出占用了56KB,开始在ReRAM单元进行Input0的ConvLast(卷积)运算;同时在SIMD VPU运算单元进行Input1的Relu/Lrelu运算,输入占用了56KB的L1 SRAM;
Step 4:
- SIMD VPU Interpolate1 - 84 KB
- ReRAM ConvLast - 10.5KB
T=4时刻,Step3的ConvLast(卷积)运算结束,输出占用了10.5KB,开始在SIMD VPU运算单元进行Interpolate1运算;同时在ReRAM单元进行Input1的ConvLast(卷积)运算,输入占用了56KB的L1 SRAM;
Step 5:
- SIMD VPU Interpolate1 - 84 KB
- ReRAM ConvLast - 10.5KB
T=5时刻,Input0的Interpolate1运算结束,Tile n开始重复Step1的运算,输入为Input2;同时在SIMD VPU进行Input1的Interpolate1运算;
Tile n+1:
- ReRAM TrunkConv-2 - current cycle - 56 KB
- ReRAM TrunkConv-2 - next cycle - 56 KB
- SIMD VPU LRelu output - current cycle - 56 KB
- SIMD VPU LRelu output - next cycle - 56 KB
- ReRAM ConvLast - current cycle - 10.5KB
- ReRAM ConvLast - next cycle - 10.5KB
- SIMD VPU Interpolate1 output - current cycle - 84 KB
- SIMD VPU Interpolate1 16-1 output - next cycle - 84 KB
具体实践过程中,由于权重参数(Weight)在执行神经网络推理运算的过程中无需进行参数更新,因此只需在推理运算之前,一次性把参数写入ReRAM(MatMul Engine)阵列单元中,无需再修改不同图片所需的权重参数,这样可以避免反复执行擦写操作带来的能耗开销,以及延长芯片中ReRAM器件的寿命。
进一步地,在一个实施例中,所述获取待处理LR图像并输入所述AI计算芯片,依据芯片内部预设的组件排布运算流程对所述待处理LR图像进行推理运算,输出最终的HR图像具体包括:
获取待处理的LR图像并按照预设的切分方式对其进行切分,获得待处理的LR图像的多个输入特征图;其中,预设的切分方式具体为:将LR图像切分为1152份图像,这里默认LR图像的分辨率为1080p。
依据芯片内部预设的组件排布运算流程对输入特征图进行推理运算,输出最终的HR图像;
所述预设的组件排布运算流程具体如下:
步骤1:第一个输入特征图首先传输到Tile 0的SRAM存储器;
步骤2:判断算子是否与静态参数相关,若算子为静态参数相关的卷积算子,则输入特征图会通过L1 SRAM存储器传输到ReRAM运算单元中与预先写入的权重参数进行卷积操作;
步骤3:若算子与静态参数不相关,则将与静态参数不相关的卷积算子设置在SIMDVPU单元上推理运算;
步骤4:重复执行步骤1~3,直至Tile0内部的SIMD VPU单元和ReRAM运算单元之间结束并行推理运算;
步骤5:Tile 0推理运算完成后,Tile0 的CPU通过消息触发Tile1 的CPU中断,同时把推理运算完成的输出数据通过DMA传输到Tile1的SRAM存储器;
步骤6:依据步骤1~3,Tile 1开始第一个输入特征图的推理运算,同时将第二个输入特征图传输至Tile 0的SRAM存储器,Tile0开始第二个输入特征图的推理运算;
步骤7:Tile 1推理运算完成后将第一个输入特征图的推理运算结果传输至Tile2,Tile 2开始第一个输入特征图的推理运算;Tile 0将第二个输入特征图的推理运算结果传输至Tile 1,Tile1同时开始第二个输入特征图的推理运算;同时Tile 0开始第三个输入特征图的推理运算;
步骤8:重复执行步骤1~7,直至Tile n完成最后一个输入特征图的推理运算,将所有输入特征图进组合,输出最终的HR图像。
其中,静态参数是指Real ESRGAN超分模型训练好后不会更改的权重数据,这部分权重数据会提前部署到ReRAM运算单元中,除此之外的权重参数统称为非静态参数。本申请中,静态参数即预先写入ReRAM运算单元的权重参数。
具体实践过程中,正如本申请背景技术中所提到的,按照本申请设置的1:4:1的切分比例,需要将1080p的输入图片切分为1152份图片,Real ESRGAN超分模型才能在存算一体芯片正常排布,即模型的输入+输出+中间全部都可以部署在512K空间内。
1080p图像的输入分辨率为1920*1080,采用预设的切分方式对图像进行切分并计算出切分后图像的分辨率:1920/48=40,1080/24=45;由此可以得出,切分后图像的分辨率为40*45,分辨率就是切分后的图片大小。
此外,预设的切分方式也可以根据实际输入图像的分辨率大小进行调整,只需满足Real ESRGAN超分模型能在存算一体芯片中正常排布即可,本申请在此不再赘述。
本申请具有以下技术效果:
1)运算速度提升
Conv/Lrelu等算子优化为LUT,只需从L1 SRAM上的LUT检索预先计算的值,运算量大大降低;
整个输出部分运算过程的排布变得简单,可合理安排各个组件间的排布,提升计算流水排布效率,提升并行运算性能。
2)降低总线传输延时
查表和插值都在SIMD VPU上实现,避免不同Tile之间数据频繁的总线传输,降低了总线传输的延时。
3)降低部署成本
输出部分的几个Conv层优化成查表实现,减少了权重参数,可有效的减少部署时Tile的数量,降低部署成本。
为方便理解本申请方案,本申请中相关技术名词的定义如下表6所示:
表6,中英文技术名词定义对照表
可以理解的是,上述各实施例中相同或相似部分可以相互参考,在一些实施例中未详细说明的内容可以参见其他实施例中相同或相似的内容。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本申请的至少一个实施例或示例中。尽管上面已经示出和描述了本申请的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本申请的限制,本领域的普通技术人员在本申请的范围内可以对上述实施例进行变化、修改、替换和变型。
- 一种智能茶艺机AI芯片版图设计方法
- 针对游戏感兴趣目标的实时AI超分方法、系统及计算机可读存储介质
- 智能终端、应用于该智能终端的游戏实时AI超分方法、系统及计算机可读存储介质