从PDF文档中提取页眉或者页脚的方法、装置和存储介质
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及文本处理技术领域,具体涉及一种从PDF文档中提取页眉或者页脚的方法、装置和存储介质。
背景技术
PDF是目前使用最广泛的文档格式之一,主要用于文件交换与打印等,无法与其他计算机程序进行交互。随着PDF在金融、科研、教育等领域的广泛应用,自动进行PDF文档识别并从中提取有用数据,并将其重构为容易编辑的WORD文档成为一个备受关注的问题。PDF文档主要由文本、图像、表格、公式等内容组成,其中,作为一种主要的表现形式,文本内容的还原质量对PDF文档整体的还原效果有着重要影响。在文本内容的还原中,不同于正文内容,页眉页脚信息的提取和还原对整个页面的排版效果有着重要影响,然而其还原难度却大大增加。针对上述问题,本发明主要关注于如何从PDF文档中提取出文本中的页眉或者页脚信息,进一步实现在WORD文档中进行还原,从而使目标文档的排版尽量与原始文档保持一致。
发明内容
本发明的目的在于克服上述技术不足,提供一种从PDF文档中提取页眉或者页脚的方法、装置和存储介质,解决现有技术中如何从PDF文档中提取出文本中的页眉或者页脚信息的技术问题。
为达到上述技术目的,本发明的技术方案提供一种从PDF文档中提取页眉或者页脚的方法,包括以下步骤:
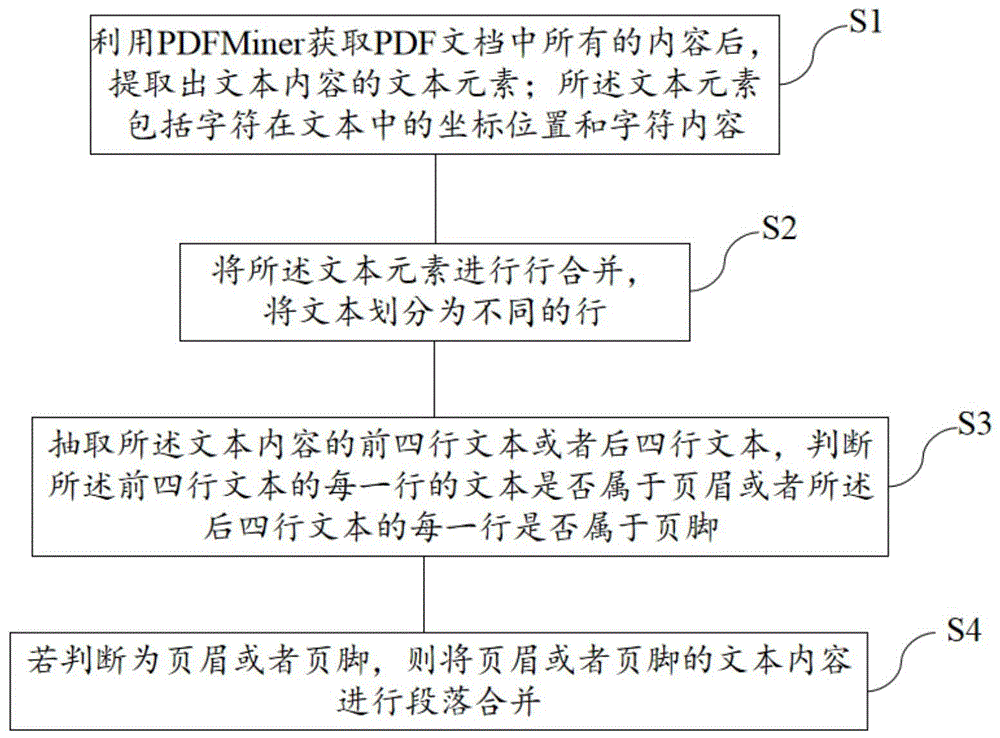
S1、利用PDFMiner获取PDF文档中所有的内容后,提取出文本内容的文本元素;所述文本元素包括字符在文本中的坐标位置和字符内容;
S2、将所述文本元素进行行合并,将文本划分为不同的行;
S3、抽取所述文本内容的前四行文本或者后四行文本,判断所述前四行文本的每一行的文本是否属于页眉或者所述后四行文本的每一行是否属于页脚;
S4、若判断为页眉或者页脚,则将页眉或者页脚的文本内容进行段落合并。
进一步地,在步骤S4之后,还包括:S5、将所述页眉或者所述页脚的内容插入到文档中的对应位置。
进一步地,在步骤S2中,所述将文本划分为不同的行是根据文本中字符的底部的坐标位置进行划分,若字符之间底部的坐标位置的差值小于第一阈值,则这两个字符处于同一行。
进一步地,在步骤S3中,判断所述前四行文本的每一行的文本是否属于页眉或者所述后四行文本的每一行是否属于页脚包括:将所有文本内容每一页的同一行文本的底部坐标进行比较,若同一行文本的所有字符的底部坐标的均值的差值小于第二阈值,且该行文本满足页眉或者页脚的任意一种或多种类型,则该行属于页眉或者页脚。
进一步地,在步骤S3中,所述判断所述前四行文本的每一行的文本是否属于页眉包括:从第一行到第四行依次进行比较,若在某行开始不满足同一行文本的所有字符的底部坐标的均值的差值小于第二阈值或者该行文本不满足页眉的任意一种或多种类型,则返回前面所有行的页眉文本内容和类型。
进一步地,在步骤S3中,所述判断所述后四行文本的每一行的文本是否属于页脚包括:从倒数第一行到倒数第四行依次进行比较,若在某行开始不满足同一行文本的所有字符的底部坐标的均值的差值小于第二阈值或者该行文本不满足页脚的任意一种或多种类型,则返回前面所有行的页脚文本内容和类型。
进一步地,在步骤S3中,所述页眉类型包括:1)所有页面具有相同的页眉内容;2)奇数页具有相同的页眉内容;偶数页具有相同的页眉内容;3)奇数页和偶数页分别具有相同的页眉内容,首页具有单独的页眉内容;
所述页脚的类型包括:1)所有页面具有相同的页脚内容;2)奇数页具有相同的页脚内容;偶数页具有相同的页脚内容;3)奇数页和偶数页分别具有相同的页脚内容,首页具有单独的页脚内容。
进一步地,在步骤S4中,将页眉或者页脚的文本内容进行段落合并包括:从第二行或者倒数第二行开始分别检查每一行的最右侧字符的最右侧坐标值与前面一行右侧字符的最右侧坐标值是否有明显的缩进,若有明显缩进,则该行为段落的最后一行,从下一行开始重启一个段落;如果没有明显缩进,则继续检查下一行,到最后一行停止。
此外,本发明还提出一种从PDF文档中提取页眉或者页脚的装置,包括:
提取单元,用于利用PDFMiner获取PDF文档中所有的内容后,提取出文本内容的文本元素;
划分单元,用于将所述文本内容进行行合并,将文本内容划分为不同的行;
判断单元,用于抽取所述文本内容的前四行文本或者后四行文本,判断所述前四行文本的每一行的文本是否属于页眉或者所述后四行文本的每一行是否属于页脚;
合并单元,若判断为页眉或者页脚,则将页眉或者页脚的文本内容进行段落合并。
另外,本发明还提出一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述从PDF文档中提取页眉或者页脚的方法的步骤。
与现有技术相比,本发明的有益效果包括:本发明提出的从PDF文档中提取页眉或者页脚的方法,利用PDFMiner获取PDF文档中所有的内容后,提取出文本内容的文本元素;所述文本元素包括字符在文本中的坐标位置和字符内容,将所述文本内容进行行合并,将文本内容划分为不同的行,抽取所述文本内容的前四行文本或者后四行文本,判断所述前四行文本的每一行的文本是否属于页眉或者所述后四行文本的每一行是否属于页脚,若判断为页眉或者页脚,则将页眉或者页脚的文本内容进行段落合并,该方法可以自动检测和提取文档中的页眉和页脚内容,便于后续在文档中的对应位置还原,从而可以使目标文档的排版尽量与原始文档保持一致。
附图说明
图1是本发明具体实施方式中从PDF文档中提取页眉或者页脚的方法的流程图;
图2是本发明具体实施方式中从PDF文档中提取页眉或者页脚的装置结构框图。
具体实施方式
结合图1,本具体实施方式提供一种从PDF文档中提取页眉或者页脚的方法,包括以下步骤:
S1、利用PDFMiner获取PDF文档中所有的内容后,提取出文本内容的文本元素;所述文本元素包括字符在文本中的坐标位置和字符内容;所述将文本内容划分为不同的行是根据文本中字符的底部的坐标位置进行划分,如果字符之间底部的坐标位置的差值小于第一阈值,则这两个字符处于同一行;
S2、将所述文本元素进行行合并,将文本划分为不同的行;所述将文本划分为不同的行是根据文本中字符的底部的坐标位置进行划分,若字符之间底部的坐标位置的差值小于第一阈值,则这两个字符处于同一行;
S3、抽取所述文本内容的前四行文本或者后四行文本,判断所述前四行文本的每一行的文本是否属于页眉或者所述后四行文本的每一行是否属于页脚;判断所述前四行文本的每一行的文本是否属于页眉或者所述后四行文本的每一行是否属于页脚包括:将所有文本内容每一页的同一行文本的底部坐标进行比较,若同一行文本的所有字符的底部坐标的均值的差值小于第二阈值,且该行文本满足页眉或者页脚的类型,则该行属于页眉或者页脚;
所述判断所述前四行文本的每一行的文本是否属于页眉包括:从第一行到第四行依次进行比较,若在某行开始不满足同一行文本的所有字符的底部坐标的均值的差值小于第二阈值或者该行文本不满足页眉的任意一种或多种类型,则返回前面所有行的页眉文本内容和类型;
所述判断所述后四行文本的每一行的文本是否属于页脚包括:从倒数第一行到倒数第四行依次进行比较,若在某行开始不满足同一行文本的所有字符的底部坐标的均值的差值小于第二阈值或者该行文本不满足页脚的任一类型,则返回前面所有行的页脚文本内容和类型;
所述页眉类型包括:1)所有页面具有相同的页眉内容;2)奇数页具有相同的页眉内容;偶数页具有相同的页眉内容;3)奇数页和偶数页分别具有相同的页眉内容,首页具有单独的页眉内容;
所述页脚的类型包括:1)所有页面具有相同的页脚内容;2)奇数页具有相同的页脚内容;偶数页具有相同的页脚内容;3)奇数页和偶数页分别具有相同的页脚内容,首页具有单独的页脚内容;
S4、若判断为页眉或者页脚,则将页眉或者页脚的文本内容进行段落合并;将页眉或者页脚的文本内容进行段落合并包括:从第二行或者倒数第二行开始分别检查每一行的最右侧字符的最右侧坐标值与前面一行右侧字符的最右侧坐标值是否有明显的缩进,若有明显缩进,则该行为段落的最后一行,从下一行开始重启一个段落;如果没有明显缩进,则继续检查下一行,到最后一行停止。
在某些实施例中,在步骤S4之后还包括:步骤S5、将所述页眉或者所述页脚的内容插入到文档中的对应位置。
结合图2,本具体实施方式还提出一种从PDF文档中提取页眉或者页脚的装置,包括:
提取单元,用于利用PDFMiner获取PDF文档中所有的内容后,提取出文本内容的文本元素;
划分单元,用于将所述文本内容进行行合并,将文本内容划分为不同的行;
判断单元,用于抽取所述文本内容的前四行文本或者后四行文本,判断所述前四行文本的每一行的文本是否属于页眉或者所述后四行文本的每一行是否属于页脚;
合并单元,若判断为页眉或者页脚,则将页眉或者页脚的文本内容进行段落合并。
本具体实施方式还提出一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述从PDF文档中提取页眉或者页脚的方法的步骤。
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明的方法进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例1
本实施例提出一种从PDF文档中提取页眉或者页脚的方法,包括以下步骤:
S1、利用PDFMiner获取PDF文档中所有的内容后,提取出文本内容的文本元素;所述文本元素包括字符在文本中的坐标位置和字符内容;PDFMiner是一个基于PDFMiner库的PDF文件解析系统,该系统可以解析出PDF文档中所有图片、表格和文本的内容及其在页面中的坐标位置信息。特别地,对于文本,该系统还可以获取字体的大小、颜色、字体类型、是否加粗等信息。在提取时,元素类型为“char”的元素即为文本所对应的内容。通过该方法,我们可以获取文本中所有的字符内容(例如中文中的字、英文中的字母),以及该字符的在文档中的坐标位置(x0,y0,x1,y1)、字符的字体大小(fontsize)、字符的颜色(color)、字符是否是斜体、字符是否加粗等。其中,字符的坐标x0表示字符最左侧的坐标位置、x1表示字符最右侧坐标位置、y0表示字符底部的坐标位置、y1表示字符顶部的坐标位置,坐标的单位为像素值。
S2、将所述文本元素进行行合并,将文本划分为不同的行;合并时,我们首先按照字符底部的坐标位置y0对不同页面中的所有字符分别进行排序。在排序后,我们按照第一阈值α=6将所有字符划分为不同的行,即如果字符之间y0坐标的差值小于6,则这两个字符处于同一行;
S3、抽取所述文本内容的前四行文本或者后四行文本,判断所述前四行文本的每一行的文本是否属于页眉或者所述后四行文本的每一行是否属于页脚;由于页眉通常出现在每一页的前四行,因此抽取出每一页的前四行文本;由于页脚通常出现在每一页的后四行,因此抽取出每一页的后四行文本;
按照页眉内容的区别,页眉可以划分为不同的类型:1)所有页面具有相同的页眉;2)奇数页具有相同的页眉;偶数页具有相同的页眉;3)奇数页和偶数页分别相同,首页具有单独的页眉内容。按照上述分类依次对抽取出来的所有页面的前四行文本进行比较,具体过程如下:
步骤1:对所有页的第一行文本进行比较,如果第一行文本的y0坐标基本相同(不同页面文本行中所有字符y0坐标的均值avg_y0之间的差值小于第二阈值3个像素值),且文本内容满足三种类型中的任意一种或多种,则第一行文本属于页眉,继续比较第二行;如果第一行不满足上述条件,则直接返回结果,即该文档不存在页眉。
步骤2:按照步骤1中判定的页眉类型对第二行文本的内容进行比较,看第二行文本在不同页面的坐标y0是否基本相同(不同页面文本行中所有字符y0坐标的均值avg_y0之间的差值小于第二阈值3个像素值),且文本类型是否满足步骤1中所判定的任意一种或多种类型。如果不满足,则只有第一行为页眉,直接返回第一行的内容及页眉类型;如果满足,则第二行也是页眉内容,继续对第三行进行比较。
步骤3:按照步骤1中判定的页眉类型对第三行文本的内容进行比较,看第三行文本在不同页面的坐标是否基本相同,且文本类型是否满足步骤1中所判定的类型。如果不满足,则只有前两行为页眉,直接返回前两行的内容及页眉类型;如果满足,则第三行也是页眉内容,继续对第三行进行比较。
步骤4:按照步骤1中判定的页眉类型对第四行文本的内容进行比较,看第四行文本在不同页面的坐标是否基本相同,且文本类型是否满足步骤1中所判定的任意一种或多种类型。如果不满足,则只有前三行为页眉,直接返回前三行的内容及页眉类型;如果满足,则第四行也是页眉内容,返回四行的所有文本内容及页眉类型。
步骤5:在判定出PDF文档的页眉内容后,我们将进一步对文档的页脚信息进行判定。由于页脚通常出现在每一页的最后四行,因此抽取出每一页的最后四行文本。
与页眉的划分相同,按照页脚内容的区别,页脚也可以划分为不同的类型:1)所有页面具有相同的页脚;2)奇数页具有相同的页脚;偶数页具有相同的页脚;3)奇数页和偶数页分别相同,首页具有单独的页脚内容。按照上述分类依次对抽取出来的所有页面的最后四行文本进行比较,具体过程如下:
步骤1:对所有页的倒数第一行文本进行比较,如果倒数第一行文本的y0坐标基本相同(不同页面文本行中所有字符y0坐标的均值avg_y0之间的差值小于3个像素值),且文本内容满足三种类型中的任意一种或多种,则倒数第1行文本属于页脚,继续比较倒数第2行;如果倒数第1行不满足上述条件,则直接返回结果,即该文档不存在页脚。
步骤2:按照步骤1中判定的页脚类型对倒数第二行文本的内容进行比较,看倒数第二行文本在不同页面的坐标是否基本相同,且文本类型是否满足步骤1中所判定的任意一种或多种类型。如果不满足,则只有倒数第1行为页脚,直接返回倒数第1行的内容及页脚类型;如果满足,则倒数第二行也是页脚内容,继续对倒数第三行进行比较。
步骤3:按照步骤1中判定的页脚类型对倒数第三行文本的内容进行比较,看倒数第三行文本在不同页面的坐标是否基本相同,且文本类型是否满足步骤1中所判定的任意一种或多种类型。如果不满足,则只有倒数第一行和倒数第二行为页脚,直接返回最后二行的内容及页脚类型;如果满足,则倒数第三行也是页脚内容,继续对倒数第四行进行比较。
步骤4:按照步骤1中判定的页脚类型对倒数第四行文本的内容进行比较,看倒数第四行文本在不同页面的坐标是否基本相同,且文本类型是否满足步骤1中所判定的类型。如果不满足,则只有最后三行为页脚,直接返回最后三行的内容及页脚类型;如果满足,则倒数第四行也是页脚内容,则返回最后四行的所有文本及页脚类型。
S4、若判断为页眉或者页脚,则将页眉或者页脚的文本内容进行段落合并。在对页眉的文本行进行段落合并时,对于文字是从左向右的文档,例如中文和英文,从第2行开始分别检查每一行的最右侧字符的x1坐标值与前面一行是否有明显的缩进。如果有则该行为段落的最后一行,从下一行开始重启一个段落;如果没有则继续检查下一行,到最后一行停止。页脚内容的段落合并方法与页眉的合并方法相同。
S5、通过前面的步骤我们得到了页眉和页脚的类型以及其对应的文本内容,依照对应的类型将页眉和页脚的内容插入到DOCX文档中的对应位置。
本发明提供了一种PDF文档中页眉和页脚内容的提取和还原方法,可以自动检测和提取文档中的页眉和页脚内容,然后依据页眉和页脚的类型间对应文本插入到DOCX文件中的对应位置,从而使目标文档的排版尽量与原始文档保持一致。
以上所述本发明的具体实施方式,并不构成对本发明保护范围的限定。任何根据本发明的技术构思所做出的各种其他相应的改变与变形,均应包含在本发明权利要求的保护范围内。