一种古籍文献识别方法、系统、终端及介质
文献发布时间:2024-01-17 01:27:33
技术领域
本申请涉及文字识别技术的领域,尤其是涉及一种古籍文献识别方法、系统、终端及介质。
背景技术
传统的古籍文献是珍贵的历史文化遗产,蕴藏着我国五千年历史的智慧精髓,具有重要的科学与文化价值。古籍文献属于不可再生性的文化资源,因而古籍的数字化是文献保护和文化传承的重要途径。
目前在进行古籍数字化时,首先是将古籍扫描成电子图像,然后采用单字检测识别技术对该图像中的古文字进行识别,得到古籍的识别结果。但是由于古籍版式复杂,除了不同于如今书籍的先从左到左、再从上到下的常规排版方式外,这使得现有的图像识别方法对古籍图像的识别效果不佳且识别结果不利于现代读者的阅读习惯。
发明内容
第一方面,为了能使古籍识别结果适应现代读者的阅读习惯,将古籍进行重新排版以便于现代读者的习惯,本申请提供一种古籍文献识别方法、系统、终端及介质。
本申请提供的一种古籍文献识别方法,采用如下的技术方案:
一种古籍文献识别方法、系统、终端及介质,包括:
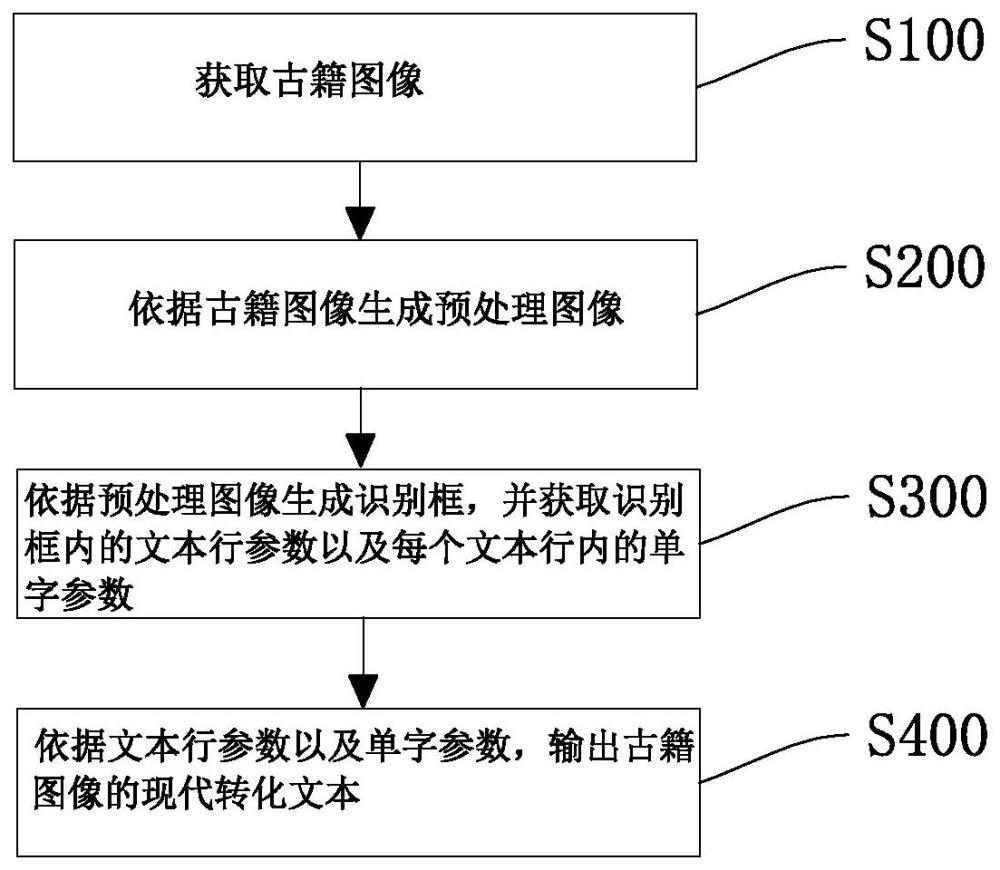
获取古籍图像;
依据古籍图像生成预处理图像;
依据预处理图像生成识别框,并获取识别框内的文本行参数以及每个文本行内的单字参数,所述文本行参数包括文本行数以及文本行位置,所述单字参数包括单字内容以及单字位置;
依据文本行参数以及单字参数,将古籍图像中的文本行进行重新排列生成现代文本行,并将文本行内的单字以其在文本行内的顺序填入现代文本行内,输出古籍图像的现代转化文本。
通过采用上述技术方案,用户上传古籍图像,先将古籍图像转化为预处理图像,依据预处理图像的大小和种类生成识别框,并获取识别框内的文本行参数,再识别文本行内的单字参数,从而得到单字位置以及文本行位置,从而将文本行内的文字依照现代阅读习惯进行排列,从而得到古籍文献的识别结果,进而能使古籍识别结果适应现代读者的阅读习惯。
优选的,所述依据预处理图像生成识别框的方法包括:
获取预处理图像特征参数,预处理图像特征参数包括预处理图像的位置、预处理图像的图像大小以及图像形状;
依据预处理图像特征参数获取预处理图像四周的图像边界点;
依据图像边界点生成矩形闭合图形;
依据矩形闭合图形生成识别框;
于所述识别框上显示缩放控件,缩放控件用于响应于触发指令调整识别框的尺寸;
基于触发指令,重新确定识别框。
通过采用上述技术方案,古籍图像经过二值化生成预处理图像,获取预处理图像的图像大小以及图像形状,再依据预处理图像特征参数获取预处理图像四周的图像边界点,将预处理图像四周的图像边界点为预处理图像上下左右最突出的点,再以图像边界点生成矩形识别框,另外缩放控件可实现识别框的手动调整,避免发生预处理图像有部分在识别框外。
优选的,所述依据图像边界点生成矩形闭合图形的方法包括:
依据预处理图像特征建立坐标系,其中坐标原点可选取预处理图像中的一点;
依据坐标系获取图像边界点的坐标;
依据图像边界点的坐标获取矩形闭合图形的四个顶点的坐标参数;
依据四个顶点的坐标参数生成矩形闭合图形。
通过采用上述技术方案,依据预处理图像特征建立坐标系,其中坐标原点可选取预处理图像中的一点,再依据坐标系获取图像边界点的坐标,在获取矩形闭合图形的四个顶点的坐标参数,每个顶点的横纵坐标可取边界点的横纵坐标的绝对值的最大值,再依据四个顶点的坐标参数生成矩形闭合图形,从而使识别框能全部框选预处理图像。
优选的,所述依据预处理图像生成识别框,并获取识别框内的文本行参数以及每个文本行内的单字参数的方法包括:
依据预处理图像以及识别框于识别框内生成至少一个的定位框,所述定位框用于框选纵向连续排列的、具有同样字体样式的文本行内容;
依据定位框生成定位框参数,定位框参数包括定位框的数量、大小以及位置;
依据定位框参数生成文本行参数;
依据定位框的文本行内容识别生成文本行内的单字参数。
通过采用上述技术方案,对识别框内的预处理图像中的文本行进行定位,并对每个定位框内的文本行内容进行单独识别,从而获取每个文本行内的单子参数,进而方便后续填入现代文本行,减少人工干预。
优选的,所述依据定位框生成定位框参数的步骤后,还包括:
依据定位框参数判断定位框的数量是否大于一;
若大于,则计算获取每两个定位框之间的间距;
依据每两个定位框之间的间距生成第一设定区,并判断每两个定位框之间的间距是否位于第一设定区内;
若位于第一设定区内,则判定涉及的两个定位框内的文本行识别结果为古籍正文。
通过采用上述技术方案,由于每页古籍文献中除了正文还有注释,通过计算获取每两个定位框之间的间距,并根据所有间距生成第一设定区间,若每两个定位框之间的间距位于第一设定区内,则判定涉及的两个定位框内的文本行识别结果为古籍正文,从而区分正文还有注释,避免正文与注释相互发生混淆,影响读者阅读。
优选的,所述判定涉及的两个定位框内的文本行识别结果为古籍正文的步骤后,还包括:
基于古籍正文生成颜色标识;
依据颜色标识获取对应颜色标记的定位框,对该定位框进行颜色标记。
通过采用上述技术方案,将带有古籍正文内容的定位框标记成对应的颜色,从而方便区分正文,避免正文与注释相互发生混淆,影响读者阅读。
优选的,所述判定涉及的两个定位框内的文本行识别结果为古籍正文的步骤后,还包括:
获取古籍正文显示指令;
依据古籍正文显示指令于人机交互界面生成正文区域;
依据正文区域以及古籍正文确定古籍正文的显示区域;
依据古籍图像的现代转化文本输出古籍正文的现代转化图像。
通过采用上述技术方案,用户想要显示古籍正文时用户可以在人机交互界面触发古籍正文显示指令,从而显示古籍正文,进而方便用户单独阅读古籍正文。
第二方面,本申请提供一种古籍文献识别系统,采用如下的技术方案:
一种古籍文献识别系统,包括:
古籍图像获取模块,用于获取古籍图像;
预处理图像生成模块,用于依据古籍图像生成预处理图像;
识别模块,用于依据预处理图像生成识别框,并获取识别框内的文本行参数以及每个文本行内的单字参数,所述文本行参数包括文本行数以及文本行位置,所述单字参数包括单字内容以及单字位置;
图像输出模块,用于依据文本行参数以及单字参数,将古籍图像中的文本行进行重新排列生成现代文本行,并将文本行内的单字以其在文本行内的顺序填入现代文本行内,输出古籍图像的现代转化文本。
通过采用上述技术方案,古籍图像获取模块可获取古籍图像,预处理图像生成模块可将古籍图像转化为预处理图像,识别模块可以生成识别框,并获取识别框内的文本行参数以及每个文本行内的单字参数,图像输出模块可以输出古籍图像的现代转化文本,适应现代读者的阅读习惯。
第三方面,本申请提供一种智能终端,采用如下的技术方案:
一种智能终端,包括存储器和处理器,所述存储器上存储有能够被处理器加载并执行上述的古籍文献识别方法的计算机程序。
第四方面,本申请提供一种计算机可读存储介质,采用如下的技术方案:
一种计算机可读存储介质,存储有能够被处理器加载并执行上述任一种古籍文献识别方法的计算机程序。
综上所述,本申请包括以下至少一种有益技术效果:
1.用户上传古籍图像,先将古籍图像转化为预处理图像,依据预处理图像的大小和种类生成识别框,并获取识别框内的文本行参数,再识别文本行内的单字参数,从而得到单字位置以及文本行位置,从而将文本行内的文字依照现代阅读习惯进行排列,从而得到古籍文献的识别结果,进而能使古籍识别结果适应现代读者的阅读习惯;
2.古籍图像经过二值化生成预处理图像,获取预处理图像的图像大小以及图像形状,再依据预处理图像特征参数获取预处理图像四周的图像边界点,将预处理图像四周的图像边界点为预处理图像上下左右最突出的点,再以图像边界点生成矩形识别框,另外缩放控件可实现识别框的手动调整,避免发生预处理图像有部分在识别框外;
3.依据预处理图像特征建立坐标系,其中坐标原点可选取预处理图像中的一点,再依据坐标系获取图像边界点的坐标,在获取矩形闭合图形的四个顶点的坐标参数,每个顶点的横纵坐标可取边界点的横纵坐标的绝对值的最大值,再依据四个顶点的坐标参数生成矩形闭合图形,从而使识别框能全部框选预处理图像。
附图说明
图1是本申请实施例的一种古籍数据库管理方法的方法流程图,主要展示步骤是S100-S400。
图2是本申请实施例的一种古籍数据库管理方法的方法流程图,主要展示步骤是SA1-SA6。
图3是本申请实施例的一种古籍数据库管理方法的方法流程图,主要展示步骤是SB1-SB4。
图4是本申请实施例的一种古籍数据库管理方法的方法流程图,主要展示步骤是SC1-SC4。
图5是本申请实施例的一种古籍数据库管理方法的方法流程图,主要展示步骤是SC2-SD4。
图6是本申请实施例的一种古籍数据库管理方法的方法流程图,主要展示步骤是SD5-SD6。
图7是本申请实施例的一种古籍数据库管理方法的方法流程图,主要展示步骤是SE1-SE4。
具体实施方式
以下结合全部附图对本申请作进一步详细说明。
本申请实施例公开一种古籍文献识别方法。一种古籍文献识别方法:
参照图1,步骤S100:获取古籍图像。
具体的,古籍图像可由用户扫描拍照古籍上传或联网下载获得,古籍图像可以是jpg,png,pdf等格式的图像文件。
步骤S200:依据古籍图像生成预处理图像。
具体的,可以将古籍图像进行二值化处理,图像的二值化处理就是将256个亮度等级的灰度图像通过适当的预设阈值选取而获得仍然可以反映图像整体和局部特征的二值化图像,将图像上的像素点的灰度值转化为0或255,整个图像会呈现出明显的黑白效果,除了二值化还可以利用图像处理技术配合HSV色彩空间法和亮度均衡处理算法对图像进行初级降噪,生成预处理图像。
步骤S300:依据预处理图像生成识别框,并获取识别框内的文本行参数以及每个文本行内的单字参数,所述文本行参数包括文本行数以及文本行位置,所述单字参数包括单字内容以及单字位置。
参照图2,其中依据预处理图像生成识别框的具体步骤为SA1-SA6:
步骤SA1:获取预处理图像特征参数,预处理图像特征参数包括预处理图像的位置、预处理图像的图像大小以及图像形状;
步骤SA2:依据预处理图像特征参数获取预处理图像四周的图像边界点;
具体的,预处理图像的位置可以为预处理图像在识别的古籍文献页面内的位置,预处理图像的图像可以由空白间隙以及黑白图像组成的块状图像,预处理图像四周的图像边界点为预处理图像在识别平面上下左右最突出的点。
步骤SA3:依据图像边界点生成矩形闭合图形;
参照图3,其中,依据图像边界点生成矩形闭合图形的具体步骤为SB1-SB4:
步骤SB1:依据预处理图像特征建立坐标系,其中坐标原点可选取预处理图像中的一点;
步骤SB2:依据坐标系获取图像边界点的坐标;
步骤SB3:依据图像边界点的坐标获取矩形闭合图形的四个顶点的坐标参数;
步骤SB4:依据四个顶点的坐标参数生成矩形闭合图形.
具体的,选取预处理图像内的一点为坐标原点,其中最佳点可以选取古籍文献识别页面的中心点,确立坐标原点后生成坐标系,从而获得图像边界点的坐标,再依据图像边界点的坐标获取矩形闭合图形的四个顶点的坐标参数,每个顶点的横纵坐标可取相邻两个边界点的横纵坐标的绝对值的最大值,例如上下左右各有一个边界点,四个边界点的坐标分别为(0,2)、(2,0)、(-2,0)、(0,-2),四个顶点坐标分别为(2,2)、(2,-2)、(-2,-2)、(-2,2)。
步骤SA4:依据矩形闭合图形生成识别框;
步骤SA5:于所述识别框上显示缩放控件,缩放控件用于响应于触发指令调整识别框的尺寸;
步骤SA6:基于触发指令,重新确定识别框。
具体的,识别框上显示有缩放控件,识别框用于框选矩形闭合图形,识别框可以为圆形或方形,例如识别框为圆形时,可在鼠标指针悬停于识别框上时显示缩放控件的图标,通过点击该图标并拉动图标可调整识别框的半径,调整框选范围。例如识别框为方形时,则可在识别各个识别区域,生成对应各个字符的形状特征鼠标指针悬停于识别框上时在识别框的四条边上均显示缩放控件的图标,通过点击该图标并拉动图标可调整识别框的长度及宽度。识别框范围的手动修改可以实现程序的精准识别,提升识别精度。而在识别框范围选定后,用户可通过操控鼠标指针或按键等方式输入触发指令,以确认手动修改的操作,此时程序重新识别经调整过的识别框内的预处理图像。
参照图4,其中获取获取识别框内的文本行参数以及每个文本行内的单字参数的具体方法包括:
步骤SC1: 依据预处理图像以及识别框于识别框内生成至少一个的定位框,所述定位框用于框选纵向连续排列的、具有同样字体样式的文本行内容;
具体的,可以预先建立文字数据库,文字数据库存储着不同字体样式的文字模型组以及其对应的现代文字,文字数据库内的素材可由联网获得或用户自己上传,由于每个朝代有不同的字体样式,可根据文字样式在预设的文字数据库中查找对应样式的文字,以此可根据文字样式确认文字图像中的文字字体,例如隶书、楷书、行书等字体,定位框可以为矩形框,用于框选纵向连续排列的、具有同样字体样式的文本行内容。
步骤SC2: 依据定位框生成定位框参数,定位框参数包括定位框的数量、大小以及位置;
具体的,定位框的位置可以由定位框的从左往右或从右往左的顺序决定。
步骤SC3: 依据定位框参数生成文本行参数;
具体的,文本行参数为文本行数以及文本行位置,文本行位置可以由文本行从左往右或从右往左的顺序决定。
步骤SC4: 依据定位框的文本行内容识别生成文本行内的单字参数。
具体的,确定了所使用的字体类型后,可以从对应的文字模型组中查找对应的高清字符,再查找高清字符对应的现代文字,单字内容为单字对应的现代文字,单字位置为单字在文本行内从上往下的顺序位置。
步骤S400:依据文本行参数以及单字参数,将古籍图像中的文本行进行重新排列生成现代文本行,并将文本行内的单字以其在文本行内的顺序填入现代文本行内,输出古籍图像的现代转化文本。
具体的,现代文本行可以由显示框确定,显示框与定位框的大小以及顺序相同,再将文本行内的单字以其在文本行内的顺序以从左往右的顺序填入显示框内的现代文本行内,最后输出古籍图像的现代转化文本。
参照图5、图6,其中可以区分古籍的正文与注释,具体方法包括;
步骤SD1: 依据定位框参数判断定位框的数量是否大于一;
步骤SD2: 若大于,则计算获取每两个定位框之间的间距;
步骤SD3: 依据每两个定位框之间的间距生成第一设定区,并判断每两个定位框之间的间距是否位于第一设定区内;
步骤SD4: 若位于第一设定区内,则判定涉及的两个定位框内的文本行识别结果为古籍正文.
具体的,文本行识别结果为文本行对应的现代文本行,由于每页古籍文献中除了正文还有注释,且注释的行间距小于正文的行间距,通过计算获取每两个定位框之间的间距,并根据所有间距生成第一设定区间,例如多个间距分别为7.1、7.2、7.3、5,第一设定区间为7.1至7.3,若每两个定位框之间的间距位于第一设定区内,则判定涉及的两个定位框内的文本行识别结果为古籍正文,从而区分正文还有注释,避免正文与注释相互发生混淆,影响读者阅读。
步骤SD5: 基于古籍正文生成颜色标识;
步骤SD6: 依据颜色标识获取对应颜色标记的定位框,对该定位框进行颜色标记;
具体的,可以将带有古籍正文内容的定位框标记成蓝色或黄色,从而可以由用户人工核对定位框是否标记正确,重新确认古文正文,避免机器识别错误。
参照图7,用户还可以单独阅读古籍正文,具体方法包括:
步骤SE1: 获取古籍正文显示指令。
具体的,用户可通过在终端的人机交互界面触发的方式获取古籍正文显示指令。
步骤SE2: 依据古籍正文显示指令于人机交互界面生成正文区域;
具体的,用户点击古籍正文显示指令后,在电脑或手机的人机交互界面会生成多个空模版,用户可预先选定一个空模板作为正文区域的版面用于显示每一页的古籍正文内容。
步骤SE3: 依据正文区域以及古籍正文确定古籍正文的显示区域;
具体的,依据古籍正文的数量以及大小确定在正文区域的显示位置,机选为正文区域的中部显示,也可以由用户人工通过点击或触摸选择确定古籍正文的显示区域。
步骤SE4: 依据古籍图像的现代转化文本输出古籍正文的现代转化图像。
具体的,古籍正文的现代转化图像可以由多页的显示每一页的古籍正文内容的正文区域版面组成,用户可以提供点击或触摸翻页。
本申请实施例还公开了一种古籍文献识别系统:包括:
古籍图像获取模块,用于获取古籍图像;
预处理图像生成模块,用于依据古籍图像生成预处理图像;
识别模块,用于依据预处理图像生成识别框,并获取识别框内的文本行参数以及每个文本行内的单字参数,所述文本行参数包括文本行数以及文本行位置,所述单字参数包括单字内容以及单字位置;
图像输出模块,用于依据文本行参数以及单字参数,将古籍图像中的文本行进行重新排列生成现代文本行,并将文本行内的单字以其在文本行内的顺序填入现代文本行内,输出古籍图像的现代转化文本。
本申请实施例还公开一种智能终端,包括存储器和处理器,处理器可采用CPU或MPU等中央处理部件或以CPU或MPU为核心所构建的主机系统,存储器可采用RAM、ROM、EPROM、EEPROM、FLASH、磁盘、光盘等存储设备。存储器上存储有能够被处理器加载并执行上述古籍文献识别方法的计算机程序。
本实施例还提供一种计算机可读存储介质,可采用U盘、移动硬盘、只读存储器(Read-Only Memory,ROM)、随机存取存储器(Random Access Memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。该计算机可读存储介质内存储有能够被处理器加载并执行上述古籍文献识别方法的计算机程序。
本申请实施例一种古籍文献识别方法、系统、终端及介质的实施原理为:古籍图像获取模块可获取古籍图像,预处理图像生成模块可将古籍图像转化为预处理图像,识别模块可以生成识别框,并获取识别框内的文本行参数以及每个文本行内的单字参数,图像输出模块可以输出古籍图像的现代转化文本,适应现代读者的阅读习惯。
以上均为本申请的较佳实施例,并非依此限制本申请的保护范围,故:凡依本申请的结构、形状、原理所做的等效变化,均应涵盖于本申请的保护范围之内。
- 一种无人驾驶车辆内物体识别方法、系统、终端和存储介质
- 一种车辆铭牌全信息识别方法、系统、终端及介质
- 一种身份识别方法、计算机可读存储介质及终端设备
- 一种黑暗中人脸识别方法、装置、处理终端及存储介质
- 一种方言语音识别方法、装置、终端及其存储介质
- 一种古籍数据库管理方法、系统、终端及介质
- 一种气体嗅觉智能识别方法、系统、介质、设备及终端