一种图文混合文档的查重方法及装置
文献发布时间:2024-04-18 19:57:50
技术领域
本发明涉及文档查重技术领域,尤其涉及一种图文混合文档的查重方法及装置。
背景技术
常用的文档查重方法(如知网查重)一般只检查文档中文本的字面相似度,对于文字的语义及文档中的图片相似度则不会检查,随着反查重意识及技能的增强,通过改写文字、将文字表格代码转成图片等方式来规避查重,特别是随着基于GPT的大语言类模型的应用,传统查重方法面临失效的风险。经过大量观察,对于同一主题下的文字,GPT模型可以多次快速生成字符不太相同但语义却比较接近的文字,传统基于字面的查重方法难以有效发现这类文本的相似性;另外抄袭文档的一个基本特征是经常互相抄袭或者只抄袭有限的几篇文档。通过人工查重或者现有的软件查重,不仅效率低,而且还存在漏查和错误的风险。
发明内容
本发明提供了一种图文混合文档的查重方法及装置,可以有效解决上述问题,提高了查重的准确度和效率。
为了实现本发明的目的,所采用的技术方案是:一种图文混合文档的查重方法,从文档中分离出文字和图片,对文字采用transformer语言模型编码成固定维度的文字向量,对图片采用cnn类模型,编码成图片向量,然后基于向量搜索引擎,运用向量索引及查询技术,分别获得文字及图片向量的语义相似度,最终计算出整篇文档的相似度,进而实现基于语义的图文混合文档的查重。
作为本发明的优化方案,查询技术包括第一轮使用文档级的语义向量查询和第二轮使用句子级向量查询。
作为本发明的优化方案,从文档中分离出的图片,按照如下步骤处理:
A、图片预处理:将图片缩放至指定大小;
B、使用二分类器,判断图片属于文字型还是图片型;若为文字型图片,使用OCR识别技术,识别出图片中的文字,按照文字部分的方法处理;若为图片型图片则转入步骤C;
C、使用CNN类模型,将图片编码成固定维数的图片向量;
D、将步骤C中的向量相加后求均值,得到文档级图片向量;
E、若生成的图片向量、文档级图片向量数达到指定值,根据向量及相关信息,生成批量建立文档级图片向量索引DGI和图片索引GI的请求,提交给向量搜索引擎,由向量搜索引擎建立文档级图片向量索引DGI和图片索引GI。
作为本发明的优化方案,对文字部分的处理步骤如下:
a、文字的预处理:去掉文字中的标点符号和停用词;
b、将文字分成指定字数的文本块,使用嵌入的句子模型,将文本块编码成固定维数的句向量;
c、将整篇文档生成的句向量相加,然后求均值,得到一个文档级的文字向量;
d、若生成的句向量、文档级的文字向量数达到指定值,生成批量建立句子索引SI、文档级文字向量索引DI的请求,提交给向量搜索引擎,由向量搜索引擎建立句子索引SI、文档级文字向量DI向量索引。
作为本发明的优化方案,第一轮使用文档级的语义向量查询,具体步骤为:
1)得到待查询比较的文档的文档级的文字向量和文档级图片向量;
2)分别构建包含文档级文字向量、文档级图片向量的查询,提交至向量搜索引擎,在文档级文字向量索引DI和文档级图片向量索引DGI库中分别查询出若干相似向量的信息,所述的信息包括文档id;
3)对返回的文档id为i的图文向量,计算出文档的相似度Si:
Si=K1*SI+K2*SW
其中:K1为图片相似度的权重系数;
K1的默认值计算:先计算出文档中单位面积平均包含的文字数n,然后计算出文档中图片的面积s,n*s就是图片区域等价包含的文字数N1,设原文档文字数为N2,则K1=N1/(N1+N2),K1最大值不超过0.5;
K2为文字相似度的权重系数,K1+K2=1;
SI为图片的向量相似度;
SW为文字的向量相似度;
4)去除同一作者的高相似度文档;
5)输出相似度由高到低排序的k个相似文档的id。
作为本发明的优化方案,第二轮使用句子级向量查询,具体步骤为:
I、给定待查询文档,待查询文档包括M1个句向量,M2个图片向量,构建一个复合查询:首先根据k个相似文档id,查询出属于k个文档id的W1个句向量、W2个图片向量;然后生成M1:W1、M2:W2的批量查询,在W1和W2的范围内,进行暴力搜索,对于每个被查询的向量,只返回一个与之最相似的向量(相似度需超过指定阈值)”,即返回相似向量有最低相似阈值的要求,如果相似度过低,即使是最相似的也不返回;
II、计算相似度:
待查询文档的文字部分相似度S1为:
S1=Ss1*n1/N+Ss2*n2/N...+Ssk*nk/N
Ssk为第k个句子向量的最大相似度;
nk为第k个句子向量对应的文字数;
N为文档的总文字数;
待查询文档的图片部分相似度S2为:
S2=(Sm1+Sm2+...+Smk)/T Smk为第k个图片向量的最大相似度;
T为文档中图片总数;
待查询文档的总相似度S为:
S=K1*S1+K2*S2
其中:K为图片相似度的权重系数,K2为文字相似度的权重系数,K1+K2=1。
作为本发明的优化方案,在查询时,做增量索引和去重,具体步骤如下:
i、对于新增的批量查询提交的多篇文档,先建立索引,然后进行多文档查询;单文档则直接提交查询;
ii、通过第一轮使用文档级的语义向量查询,找出相似度超过指定值的文档,超过两篇以上,保留提交时间最早的那篇文档,将剩余相似文档id放入待去重的队列中;
iii、在单文档情况下,如果查询返回的文档相似度都低于指定值,则将查询文档相关信息加入增量索引队列中;
iiii、当去重队列中的文档数达到指定值且向量搜索引擎系统较为空闲时,发出批量删除索引的请求,在文字及向量索引库中,删除指定文档id的向量;
iiiii、当增量索引队列中的文档数达到指定值且向量搜索引擎系统较为空闲时,发出批量建立向量索引的请求,在文字及向量索引库中,新增指定文档id的向量。
为了实现本发明的目的,所采用的技术方案是:一种图文混合文档的查重装置,装置包括应用服务器、文字和图片向量生成服务器,向量搜索服务器和文档数据存储服务器,
应用服务器用于提供图文索引向量的增删改查、文档解析、查询报告生成及管理调度,文档解析从文档中提取文字、图片及其位置大小信息;
文字和图片向量生成服务器对外提供restful风格的访问接口,内置多种基于transformer及cnn的图文向量模型,通过合理的搭配,在模型精度和向量生成速度间取得较好的平衡;
向量搜索服务器采用高效的HNSW算法建立索引,进行KNN搜索,搜索时,使用结构化查询和向量搜索相结合的方式,然后使用暴力搜索,在小向量集合中查询计算返回指定的L个相似的文档;
文档数据库服务器使用mongodb,用于存储文档及图片,支持分布式存储及检索。
本发明具有积极的效果:1)本发明支持图文混合文档的语义查重,提高了查重的准确性;对常见的规避查重的方法,提出了针对性措施,提高了查重的精度;
2)本发明有效平衡了大规模文档语义查询中的查询精度和速度的矛盾,兼顾了查重的效率和准确度。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
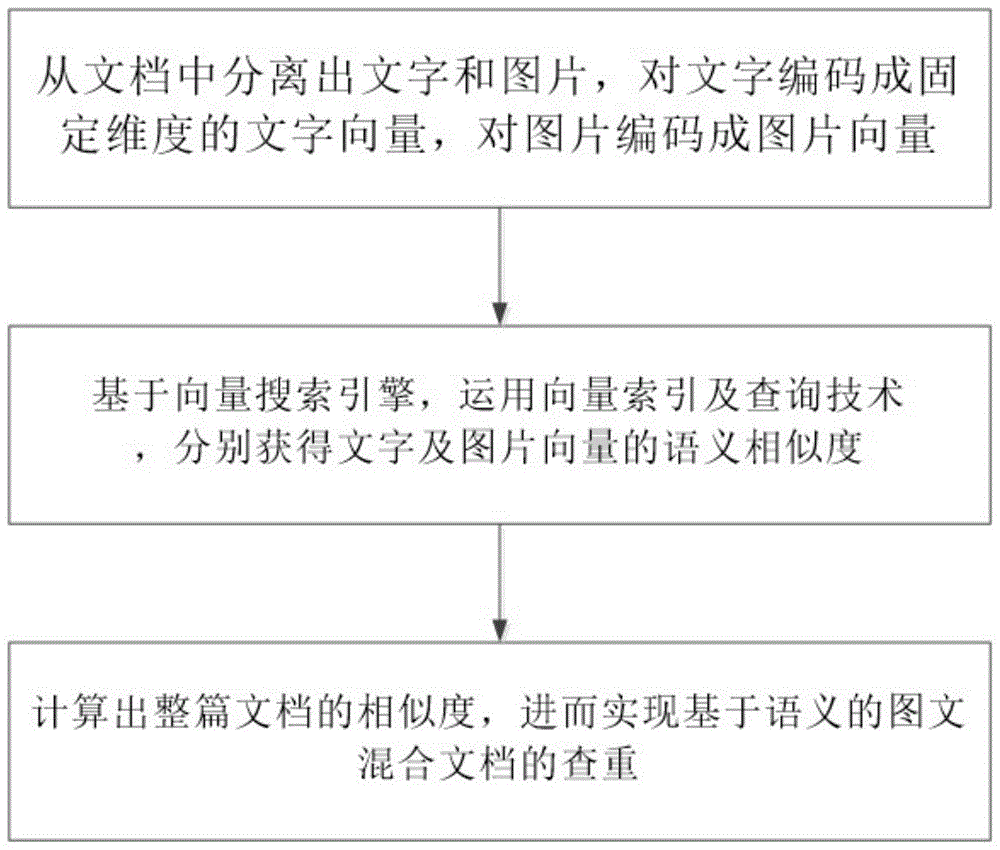
图1是本发明的流程图。
具体实施方式
如图1所示,本发明公开了一种图文混合文档的查重方法,从文档中分离出文字和图片,对文字采用transformer语言模型编码成固定维度的文字向量,对图片采用cnn类模型,编码成图片向量,然后基于向量搜索引擎,运用向量索引及查询技术,分别获得文字及图片向量的语义相似度,最终计算出整篇文档的相似度,进而实现基于语义的图文混合文档的查重。
图文混合文档的查重方法采用两轮查询技术,查询技术包括第一轮使用文档级的语义向量查询和第二轮使用句子级向量查询。其中:文档级的语义向量查询精度不太高,但是速度较快,通过文档级的语义向量查询能返回少量高相似度的文档;使用句子级向量查询在返回的少量高相似度的文档中进行精确查询。使用两轮查询技术能够较好的平衡海量文档语义查重中查重精度和速度的矛盾。
索引建立:
输入:指定目录下的doc文档集合输出:向量搜索引擎中文档级文字向量索引DI、文档级图片向量索引DGI、句子索引SI、图片索引GI。
步骤:
遍历指定目录下的每个文档文件,做如下处理:
读取文档,分离提取出文档中的文字、图片及其位置大小等信息,然后分别处理。
从文档中分离出的图片,按照如下步骤处理:
A、图片预处理:将图片缩放至指定大小;
B、使用二分类器,判断图片属于文字型还是图片型;若为文字型图片,使用OCR识别技术,识别出图片中的文字,按照文字部分的方法处理;若为图片型图片则转入步骤C;
C、使用CNN类模型,将图片编码成固定维数的图片向量;
D、将步骤C中的向量相加后求均值,得到文档级图片向量;
E、若生成的图片向量、文档级图片向量数达到指定值,根据向量及相关信息(如作者、班级、专业、文档id、图片id、提交时间、图片的位置大小等结构化信息),生成批量建立文档级图片向量索引DGI和图片索引GI的请求,提交给向量搜索引擎,由向量搜索引擎建立文档级图片向量索引DGI和图片索引GI。
对文字部分的处理步骤如下:
a、文字的预处理:去掉文字中的标点符号和停用词等;
b、将文字分成指定字数的文本块(默认128个字符),使用嵌入的句子模型(SentenceTransformers),将文本块编码成固定维数的句向量;
c、将整篇文档生成的句向量相加,然后求均值,得到一个文档级的文字向量;
d、若生成的句向量、文档级的文字向量数达到指定值,根据向量及相关信息(如作者、班级、专业、文档id、文字位置等结构化信息)生成批量建立句子索引SI、文档级文字向量索引DI的请求,提交给向量搜索引擎,由向量搜索引擎建立句子索引SI、文档级文字向量DI向量索引。
第一轮查询:
输入:一份待查询比较的doc文档。
输出:按相似度由高到低排序的k个最相似文档id。
第一轮使用文档级的语义向量查询,具体步骤为:
1)将待查询比较的文档做类似于建立索引过程中的处理,通过句子向量和图片向量,分别得到该文档的文档级文字向量和文档级图片向量;
2)分别构建包含文档级文字向量、文档级图片向量的查询(可能含有其它查询相关信息,如相似度阈值、返回相似向量的个数k、专业、作者等信息)提交至向量搜索引擎,在文档级文字向量索引DI和文档级图片向量索引DGI库中分别查询出若干相似向量的信息,信息包括文档id,及相关的图、文向量相似度等;
3)对返回的文档id为i的图文向量,计算出文档的相似度Si:
Si=K1*SI+K2*SW
其中:K1为图片相似度的权重系数;
K1的默认值计算:先计算出文档中单位面积平均包含的文字数n,然后计算出文档中图片的面积s,n*s就是图片区域等价包含的文字数N1,设原文档文字数为N2,则K1=N1/(N1+N2),K1最大值不超过0.5;
K2为文字相似度的权重系数,K1+K2=1;
SI为图片的向量相似度(余弦相似度范围:0-1);
SW为文字的向量相似度(余弦相似度范围:0-1);
4)去除同一作者的高相似度文档;
5)输出相似度由高到低排序的k个相似文档的id。
第二轮查询(接着第一轮查询处理):
输入:一篇待查询文档中M1个句向量,M2个图片向量,k个最相似文档id
输出:查询报告(文档总相似度、文字、图片部分相似度,相似语句、图片信息)
第二轮使用句子级向量查询,具体步骤为:
I、给定待查询文档,待查询文档包括M1个句向量,M2个图片向量,构建一个复合查询:首先根据k个相似文档id,查询出属于k个文档id的W1个句向量、W2个图片向量;然后生成M1:W1、M2:W2的批量查询,在W1和W2的范围内,进行暴力搜索,对于每个被查询的向量,只返回一个与之最相似的向量,所述最相似的向量为超过指定阈值的向量;
II、计算相似度:
待查询文档的文字部分相似度S1为:
S1=Ss1*n1/N+Ss2*n2/N...+Ssk*nk/N
Ssk为第k个句子向量的最大相似度;
nk为第k个句子向量对应的文字数;
N为文档的总文字数;
待查询文档的图片部分相似度S2为:
S2=(Sm1+Sm2+...+Smk)/T
Smk为第k个图片向量的最大相似度;
T为文档中图片总数;
待查询文档的总相似度S为:
S=K1*S1+K2*S2
其中:K为图片相似度的权重系数,K2为文字相似度的权重系数,K1+K2=1。
查重报告包含信息:文档总相似度、文字及图片部分相似度,与其最相似的k篇文档,相似的句子及图片信息。
在历史文档数据及批量提交的查询文档(如一个班级的文档)中,可能包含相似度很高的文档,需要进行去重处理,采用一种惰性去重的方法,不是一般的在建立向量索引前后进行去重,而是在查询的时候,发现重复的文档向量,达到一定条件后,进行去重。新增文档向量索引的建立,也是在查询的时候,发现相似度低于指定值的向量,然后做增量索引的。
在查询时,做增量索引和去重,具体步骤如下:
i、对于新增的批量查询提交的多篇文档,按照前述方法,先建立索引,然后进行多文档查询;单文档则直接提交查询;
ii、通过第一轮使用文档级的语义向量查询,找出相似度超过指定值(默认0.9)的文档,超过两篇以上,保留提交时间最早的那篇文档,将剩余相似文档id放入待去重的队列中;
iii、在单文档情况下,如果查询返回的文档相似度都低于指定值(默认0.3),则将查询文档相关信息(文档id、文字向量、图片向量等)加入增量索引队列中;
iiii、当去重队列中的文档数达到指定值且向量搜索引擎系统较为空闲时,发出批量删除索引的请求,在文字及向量索引库中,删除指定文档id的向量;
iiiii、当增量索引队列中的文档数达到指定值且向量搜索引擎系统较为空闲时,发出批量建立向量索引的请求,在文字及向量索引库中,新增指定文档id的向量。
一种图文混合文档的查重装置包括应用服务器、文字和图片向量生成服务器,向量搜索服务器和文档数据存储服务器,
应用服务器使用java开发,基于springboot及tomcat技术,对外提供restful风格的接口,提供图文索引向量的增删改查、文档解析、查询报告生成及管理调度等功能,文档解析使用Spire.Doc for Java组件从doc文档中提取文字、图片及其位置大小信息。图文向量生成服务器采用python开发,对外提供restful风格的访问接口,内置多种基于transformer及cnn的图文向量模型,通过合理搭配,可以在模型精度和向量生成速度间取得较好的平衡。向量搜索服务器采用elasticseach8.0及以上版本,向量索引及搜索采用高效的HNSW算法建立索引,进行KNN搜索。搜索时,例如在指定班级或专业的情况下,使用结构化查询和向量搜索相结合的方式(复合查询),先查询返回指定班级的语义向量(一般数量较少),然后使用暴力搜索,在小向量集合中查询计算返回指定的k个最相似的文档,这种方法可以极大地提高向量检索的性能。文档数据库服务器使用mongodb,用于存储文档及图片,支持分布式存储及检索。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种文本查重方法、装置及设备
- 一种解析便携式文档格式文档表格的方法及装置
- 一种基于语义分析的文档查重方法和装置
- 一种基于语义分析的文档查重方法和装置