基于模型预测和强化学习的主动汽车悬架控制系统及方法
文献发布时间:2024-04-18 19:59:31
技术领域
本发明涉及汽车工程技术领域,具体为基于模型预测和强化学习的主动汽车悬架控制系统及方法。
背景技术
现有汽车悬架稳定控制领域,已经存在多种技术:其中传统的PID控制算法是一种基于比例、积分、微分三个因素的控制算法,可以通过调整这三个参数来控制汽车悬架稳定性,但是该算法只能适用于一些单输入单输出场景,且参数难以调节,容易出现超调;
现有基于模型预测控制的算法使用状态空间模型对系统未来状态进行描述和预测,并使用有限时域内预测的结果来优化控制参数,以实现悬架稳定性控制;该算法提高了控制的准确性和鲁棒性,但是计算速度较慢,会带来延迟问题;
现有基于强化学习的算法使用模拟整个状态动态过程的方法,逐步调整控制策略,并通过奖励函数来评估控制策略的优劣,最终实现悬架稳定性控制;该方法具有较好的自适应性和鲁棒性,但是需要消耗较多的计算资源,训练时间较长;
因此设计基于模型预测和强化学习的主动汽车悬架控制系统及方法利用传感器和摄像头等技术收集汽车悬架在行驶过程中的数据,并使用模型预测和强化学习等技术,通过优化汽车悬架减震器的阻尼输出来降低车身垂向加速度、俯仰角加速度和侧倾角加速度等状态指标,提高汽车的悬架稳定性是很有必要的。
发明内容
本发明的目的在于提供基于模型预测和强化学习的主动汽车悬架控制系统及方法,以解决上述背景技术中提出的问题。
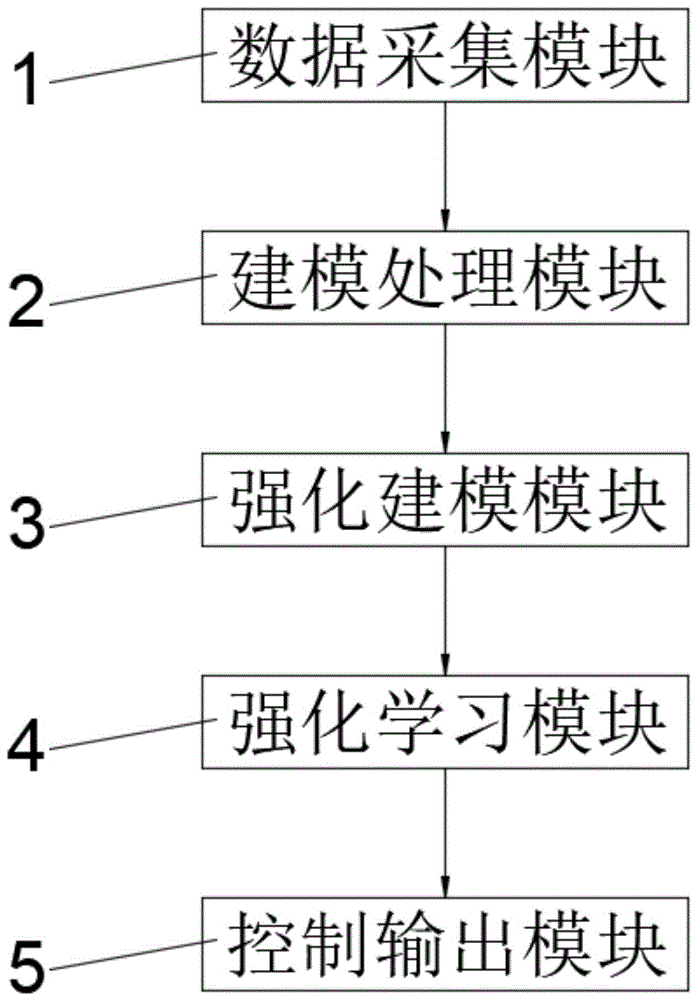
为实现上述目的,本发明提供如下技术方案:基于模型预测和强化学习的主动汽车悬架控制系统,包括数据采集模块、建模处理模块、强化建模模块、强化学习模块和控制输出模块,所述数据采集模块控制连接建模处理模块,建模处理模块控制连接强化建模模块,强化建模模块控制连接强化学习模块,强化学习模块控制连接控制输出模块。
基于模型预测和强化学习的主动汽车悬架控制方法,包括以下步骤:步骤一,数据采集;步骤二,模型建立;步骤三,强化学习建模;步骤四,强化学习处理;步骤五,控制器实现;步骤六,实验验证;
其中上述步骤一中,首先使用传感器收集汽车悬架在行驶过程中的真实数据,同时使用双目摄像头采集路面高度信息,并对数据进行处理;
其中上述步骤二中,在获得足够的数据之后,该算法会基于这些数据调整汽车的七自由度数学模型,使其接近于真实情况,并将此模型作为前向预测模型;
其中上述步骤三中,将当前状态和未来预测状态作为状态空间,以汽车悬架减震器的阻尼输出作为动作空间,其中将未来预测信息加入到状态空间中,并设计奖励函数;
其中上述步骤四中,使用基于PPO算法的强化学习算法,并结合合理的奖励函数,利用预处理后的数据进行训练,得到控制策略;
其中上述步骤五中,将训练好的控制策略输出至为悬架减震器控制器,以将其应用到实际的汽车悬架系统中;
其中上述步骤六中,在测试台架或实际道路环境中进行实验验证,评估该方法在各种路况下的控制效果和性能表现,并根据实验结果对方法进行优化和改进。
优选的,所述步骤一中,传感器的采集数据为二十维数据,且采集数据包括车辆加速度Az_SM;俯仰角加速度AAx;侧倾角加速度AAy;侧偏角加速度AAz;悬架动行程SD;四组轮胎动位移Z_L;四组轮胎垂向位移速度TDV;和四组悬架相对位移速度SDV。
优选的,所述步骤一中,在获得数据后,需要对其进行预处理,包括滤波、降噪和校准等操作,以获得可靠的数据。
优选的,所述步骤二中,七自由度数学模型用于预测汽车的未来运动趋势,模型的标准形式为
优选的,所述步骤三中,在建立预测模型之后,将使用强化学习技术来进行优化,且奖励函数为负的各状态指标的加权平方和,取负号表示最大程度地降低这三个状态指标;即r
优选的,所述步骤四中,PPO算法需要进行多轮迭代,每一轮迭代从数据中随机采样一个批次,然后使用该批次数据来更新模型参数,PPO算法包括以下步骤:S1,生成数据:从当前策略中生成一些经验数据,包括状态、动作和奖励;S2,计算优势函数:使用当前策略评估状态动作对的优劣程度,计算出优势函数,即当前动作相对于当前状态下所有动作的平均水平;S3,计算Policy Loss:计算策略损失,也是目标函数;它是当前策略和过去策略产生者效应之比和对抗损失之和的最小值,其中对抗损失是当前策略和过去策略产生者效应之比和一个门限的较小值;S4,计算Value Loss:计算价值函数损失,它是当前状态的价值函数估计值与目标值之间的均方误差;S5,更新策略:根据总损失执行随机梯度下降优化策略的参数;S6:这些步骤将迭代执行多次,直到找到合适的策略参数,使得智能体在环境中表现最佳。
优选的,所述步骤五中,通过采用传感器和摄像头等技术收集真实的汽车数据,并进行数据处理,获得当前状态集合,并且通过预测模型获取未来时刻的状态集,将这些数据输入训练好的强化学习策略模型中,输出四个阻尼力,以实现汽车悬架稳定性控制的目的。
与现有技术相比,本发明的有益效果是:该基于模型预测和强化学习的主动汽车悬架控制系统及方法,通过在路面状况预瞄的基础上将模型预测和强化学习相结合,建立有机的模型与算法集成框架;在模型预测方面,使用七自由度数学模型对悬架未来运动状态趋势进行预测,从而为后续的控制决策提供准确的参考;在强化学习方面,使用PPO算法进行动态化车辆控制,提高了控制策略的优化处理速度,通过优化汽车悬架减震器的阻尼输出来降低车身垂向加速度、俯仰角加速度和侧倾角加速度等状态指标,提高汽车的悬架稳定性。
附图说明
图1为本发明的系统流程图;
图2为本发明的控制输出流程图;
图3为本发明的方法流程图;
图4为本发明中PPO的算法流程图;
图中:1、数据采集模块;2、建模处理模块;3、强化建模模块;4、强化学习模块;5、控制输出模块。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明提供的一种实施例:基于模型预测和强化学习的主动汽车悬架控制系统,包括数据采集模块1、建模处理模块2、强化建模模块3、强化学习模块4和控制输出模块5,数据采集模块1控制连接建模处理模块2,建模处理模块2控制连接强化建模模块3,强化建模模块3控制连接强化学习模块4,强化学习模块4控制连接控制输出模块5。
请参阅图2-4,本发明提供的一种实施例:基于模型预测和强化学习的主动汽车悬架控制方法,包括以下步骤:步骤一,数据采集;步骤二,模型建立;步骤三,强化学习建模;步骤四,强化学习处理;步骤五,控制器实现;步骤六,实验验证;
其中上述步骤一中,首先使用传感器收集汽车悬架在行驶过程中的真实数据,同时使用双目摄像头采集路面高度信息,传感器的采集数据为二十维数据,且采集数据包括车辆加速度Az_SM;俯仰角加速度AAx;侧倾角加速度AAy;侧偏角加速度AAz;悬架动行程SD;四组轮胎动位移Z_L;四组轮胎垂向位移速度TDV;和四组悬架相对位移速度SDV;在获得数据后,需要对其进行预处理,包括滤波、降噪和校准等操作,以获得可靠的数据;
其中上述步骤二中,在获得足够的数据之后,该算法会基于这些数据调整汽车的七自由度数学模型,使其接近于真实情况,并将此模型作为前向预测模型;七自由度数学模型用于预测汽车的未来运动趋势,模型的标准形式为
其中上述步骤三中,将当前状态和未来预测状态作为状态空间,以汽车悬架减震器的阻尼输出作为动作空间,其中将未来预测信息加入到状态空间中,并设计奖励函数,奖励函数为负的各状态指标的加权平方和,取负号表示最大程度地降低这三个状态指标;即r
其中上述步骤四中,使用基于PPO算法的强化学习算法,并结合合理的奖励函数,利用预处理后的数据进行训练,得到控制策略;其中PPO算法需要进行多轮迭代,每一轮迭代从数据中随机采样一个批次,然后使用该批次数据来更新模型参数,PPO算法包括以下步骤:S1,生成数据:从当前策略中生成一些经验数据,包括状态、动作和奖励;S2,计算优势函数:使用当前策略评估状态动作对的优劣程度,计算出优势函数,即当前动作相对于当前状态下所有动作的平均水平;S3,计算Policy Loss:计算策略损失,也是目标函数;它是当前策略和过去策略产生者效应之比和对抗损失之和的最小值,其中对抗损失是当前策略和过去策略产生者效应之比和一个门限的较小值;S4,计算Value Loss:计算价值函数损失,它是当前状态的价值函数估计值与目标值之间的均方误差;S5,更新策略:根据总损失执行随机梯度下降优化策略的参数;S6:这些步骤将迭代执行多次,直到找到合适的策略参数,使得智能体在环境中表现最佳;
其中上述步骤五中,通过采用传感器和摄像头等技术收集真实的汽车数据,并进行数据处理,获得当前状态集合,并且通过预测模型获取未来时刻的状态集,将这些数据输入训练好的强化学习策略模型中,输出四个阻尼力,以实现汽车悬架稳定性控制的目的;
其中上述步骤六中,在测试台架或实际道路环境中进行实验验证,评估该方法在各种路况下的控制效果和性能表现,并根据实验结果对方法进行优化和改进。
基于上述,本发明的优点在于,本发明,将模型预测和强化学习相结合、基于预瞄的汽车悬架稳定控制方法,建立七自由度的汽车动力学模型作为预测模型,并根据传感器和摄像头等设备收集汽车在行驶过程中的悬架数据,对此模型进行微调,使其能够准确描述真实的汽车悬架运动状态,然后,该方法将强化学习算法应用于汽车悬架稳定控制中,以降低车身垂向加速度、俯仰角加速度和侧倾角加速度等状态指标,提高汽车的悬架稳定性;在强化学习的训练过程中,不仅对当前状态的车辆稳定性进行优化,还使用预测模型预测未来的汽车悬架状态,将未来的车辆稳定性也作为优化目标的一部分,这样使得强化学习算法有了对未来的规划能力。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。