一种基于YOLOv5n的物流违规作业检测报警方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及物流违规检测和报警技术领域,特别涉及一种基于YOLOv5n的物流违规作业检测报警方法。
背景技术
在物流仓储公司中,由于存储物品的特殊性和易碎性,有关部门要求相应的工作人员不得踩踏、或坐在存储货物的纸箱上,避免货物破损,以及不得将货物堆放至不合规区域。针对以上违规作业问题,基于目前的手段主要通过人工监督方法进行监督。该方法不仅效率低,而且浪费大量人力和物力,因此可以通过人工智能的方法来进行监督,以此来降低人力、物力的损耗,提高企业高质量发展。
综上所述,现有技术的仍存在的不足:
针对物流仓储的违规作业的相关研究较少,更多是通过人工的方式进行监督,该方法效率低下,浪费较大人力和物力。基于目前的研究,并未公开关于物流仓储违规作业检测的数据集。其次,随着深度学习的发展,开始使用基于深度学习的目标检测算法对违规作业进行监测,但是现有目标检测算法如YOLO算法,其在对图像进行监测时,对图像的特征提取和处理需要使用大量的数据进行计算,导致现有模型检测速度缓慢,在复杂环境中导致工作难度巨大。
发明内容
本发明的目的在于针对上述现有技术的不足,提供一种基于YOLOv5n的物流违规作业检测报警方法,以解决现有技术中现有目标检测算法效率低下,浪费较大人力和物力的问题。
本发明具体提供如下技术方案:一种基于YOLOv5n的物流违规作业检测报警方法,包括以下步骤:
采集及制作物流仓储违规作业数据,并对所述物流仓储违规作业数据进行预处理,获得增强后的图像;
将YOLOv5n模型主干部分中下采样的标准卷积替换为轻量级GhostConv模块,作为特征提取网络,并将增强后的图像输入所述特征提取网络后,输出n个特征图;
将CBAM注意力机制和GSConv引入YOLOv5n模型的特征融合网络,通过所述特征融合网络将输入的n个特征图进行处理,输出特征融合后的特征图;
通过所述特征融合后的特征图获得物流仓储违规作业的分类及定位结果,并基于分类及定位结果获得检测到的违规目标图像;
将监测到的违规目标图像自动发送至工作平台,进行报警。
优选的,所述采集及制作物流仓储违规作业数据,包括如下步骤:
通过物流仓储录像机所存储的视频及爬虫手段对图像数据进行获取、拆帧、挑选、清洗、打标签处理,并将处理后的数据划分为数据集。
优选的,所述对所述物流仓储违规作业数据进行预处理,获得增强后的图像,包括如下步骤:
使用Mosic、Copy-Paste或Mixup方式对数据集中的数据进行数据增强;
通过自适应图像缩放对所有数量类别的数据样本进行关注,并使用所有数量类别的数据样本统一进行模型参数调整;
使用K-means锚框聚类方法,在锚点和目标尺寸差异大的情况下进行数据处理。
优选的,所述使用K-means锚框聚类方法包括如下步骤:
将所述数据集分成k个簇时,随机选择k个数据点作为初始簇中心;
将每个数据点分配到距离其最近的簇中心,每个数据点只能属于一个簇;
根据分配的数据点更新簇中心点,通过计算属于每个簇数据点的平均值;
重复更新簇中心点的步骤,直到簇中心点不再发生变化,或者达到预定的迭代次数时,得到k个簇和每个簇的中心点;
其中,K-measn算法中会有K个簇,因此就要使每个簇内的数据点到质心的距离都达到最小,获得总和最小的距离;K个簇共同组成了一个集合A,在A集合中每个簇的样本点到各自质心的距离都是最小的,表达式如下:
其中,x
优选的,对经过主干部分替换的所述YOLOv5n模型进行训练,包括如下步骤:
对数据集进行预处理,将数据集中的图像缩放至640×640尺寸;
对所述数据集中的数据进行增强处理、自适应图像缩放、锚框聚类;
将用于多目标检测的训练数据集输入到YOLOv5n模型主干部分、目标分类和定位分支中对模型进行训练,获得物流仓储违规作业的分类及定位结果;
将用于物流仓储违规作业测试数据集中的数据输入到训练好的模型中,进行测试,获得测试结果。
优选的,所述将用于多目标检测的训练数据集输入到主干部分、目标分类和定位分支中对模型进行训练,包括步骤:
将每帧图像输入到特征提取网络,经过1/8、1/16和1/32的下采样后得到三张不同尺寸大小的特征图;
对所述特征图输入特征融合网络,使用由下至上,再由上至下的多尺度特征融合方式进行多尺度的融合;
将融合后的特征图分别输入预测不同大小目标的分类分支与检测嵌入特征提取分支中,获得不同大小目标的预测信息,所述预测信息包括目标的类别和位置。
优选的,所述将融合后的特征图分别输入预测不同大小目标的分类分支与检测嵌入特征提取分支,得到不同大小目标的预测信息,包括如下步骤:
将融合后的特征图通过检测器中的卷积层运算,获得预测结果;
通过NMS方法去除预测结果中冗余的预测框,检测出目标。
优选的,所述对模型进行训练时,采用的损失函数包括BCE Loss损失函数和CIoULoss损失函数,具体表达式分别为:
Loss(p,t)=-t*log(p)-(1-t)log(1-p)
其中,p表示预测值,t表示真实值,b,b
优选的,所述将监测到的违规行为图像自动发送至工作平台,包括步骤:
当监测到违规目标时,将监测到的目标区域进行截图;
将所述截图反馈至检测平台,协助相关工作人员进行监督。
优选的,所述通过所述特征融合网络将输入的n个特征图进行处理,包括步骤,包括步骤:
将输入的n个特征图使用GSConv进行处理;
使用CBAM将使用GSConv进行处理后的输入特征F进行池化操作,对池化操作后的输入特征F输入多层感知机MLP,并对多层感知机MLP输出的特征进行逐元素加和及Sigmoid激活,获得通道注意力特征图M
其中σ为Sigmiod激活函数,
对所述特征图M
对所述输入特征图F′进行全局最大池化和全局平均池化,获得两个H×W×1的特征图;
将两个特征图进行通道拼接,对拼接后的特征图经过一个7×7卷积,降维至1个通道,即H×W×1;
通过Sigmoid激活生成空间特征图M
将特征图M
与现有技术相比,本发明具有如下显著优点:
本发明提供的一种轻量级物流仓储违规作业自动监测与报警的方法,通过对YOLOv5n模型的主干部分中下采样的标准卷积替换为轻量级GhostConv模块,作为特征提取网络,提取图像的多个特征图,并使用CBAM注意力机制和GSConv作为特征融合网络对多个特征图进行融合,通过融合后的特征图获得物流仓储违规作业的分类及定位结果,根据分类及定位结果获得物流仓储违规作业中的违规目标图像,并自动发送至工作平台进行报警。本发明使用人工智能的方法代替传统人工监督的方法,该方法管理方便,检测速度更快,并通过轻量级的模块减少硬件占用资源,对特征图中的目标信息充分利用,提高模型在复杂背景下的鲁棒性,极大降低人力和物力,提高工作效率,促进工业高质量发展。
附图说明
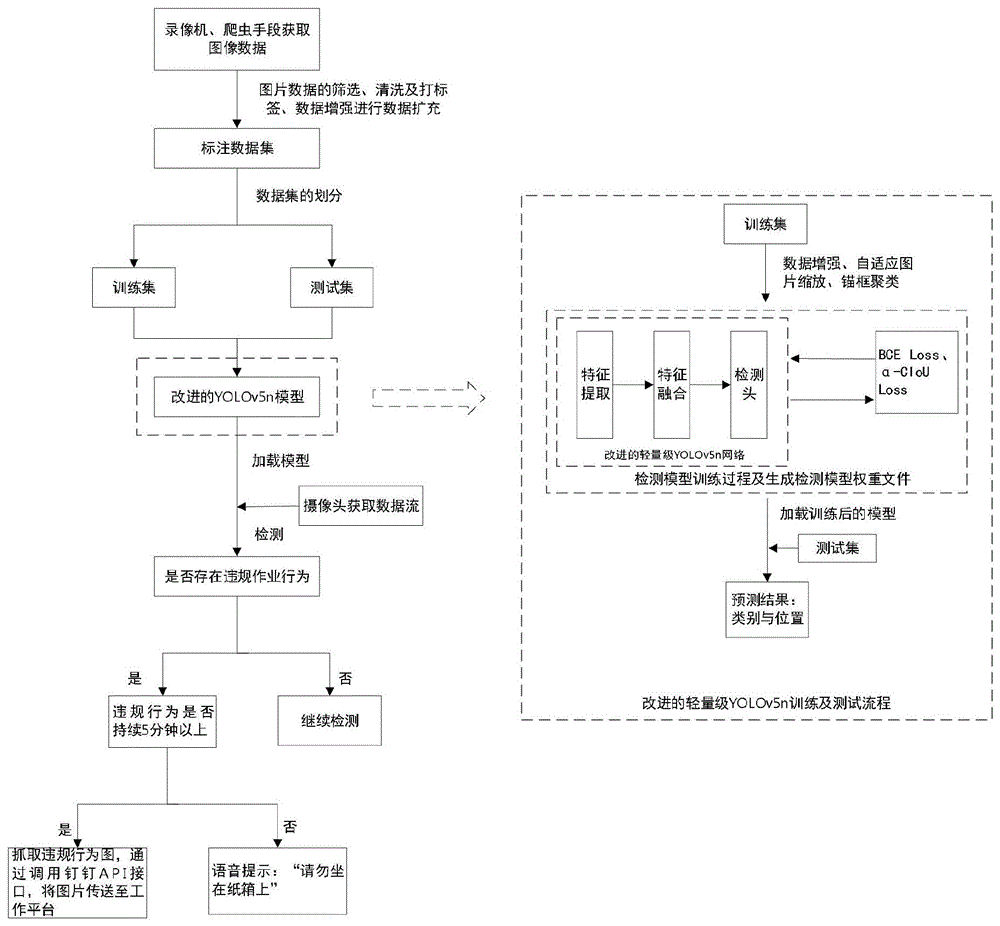
图1为本发明提供的一种物流仓储违规作业自动检测与报警的技术流程图;
图2为本发明提供的轻量级YOLOv5n网络结构图;
图3为本发明提供的Ghost-C3网络结构图。
具体实施方式
下面结合本发明中的附图,对本发明实施例的技术方案进行清楚、完整的描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
本发明的目的在于提供一种基于YOLOv5n的物流违规作业检测报警方法,能够自动进行检测物流违规行为的监测与报警的功能,代替传统人工的监测,提高工作效率,降低人工监督的误检和漏检的问题,促进企业高质量发展。
为了便于理解和说明,如附图1-2所示,本发明提供了一种基于YOLOv5n的物流违规作业检测报警方法,包括以下步骤:
步骤S1:采集及制作物流仓储违规作业数据,并对物流仓储违规作业数据进行预处理,获得获取增强后的图像。
步骤S2:将将YOLOv5n模型主干部分中下采样的标准卷积替换为轻量级GhostConv模块,作为特征提取网络,并将增强后的图像输入特征提取网络后,输出n个特征图。
步骤S3:将CBAM注意力机制和GSConv引入YOLOv5n模型的特征融合网络,通过特征融合网络将输入的n个特征图进行处理,输出特征融合后的特征图。
步骤S4:通过特征融合后的特征图获得物流仓储违规作业的分类及定位结果,并基于分类及定位结果获得检测到的违规目标图像。
步骤S5:将监测到的违规目标图像自动发送至工作平台,进行报警。
下面进行详细说明:
一种轻量级物流仓储违规作业自动监测与报警的方法,该方法包括:
1、物流仓储违规作业数据采集及制作。
2、对数据集进行预处理。
3、将增强后的图像输入到改进的轻量级YOLOv5n模型中进行物流仓储违规作业的模型训练,得出训练后的模型权重,接着将训练后的模型进行测试。不断重复以上流程,选出测试效果最佳的模型。
4、加载训练好的模型进行检测,根据检测的结果对待检测图像进行定位和分类,以此表示检测到目标。
5、报警功能,将监测到的违规行为图像,自动发送至我们的工作平台,方便相关工作人员进行管理。
上述方法1中对数据集采集过程主要包括:通过物流仓储录像机所存储的视频及爬虫手段进行图像数据的获取、拆帧、挑选、清洗、打标签并划分数据集。其中爬虫手段主要是使用Requset库,该库可以利用http1.1协议在内存中快速请求并访问对应URL,完成URL请求后快速解析对应的返回结果。行人坐在纸箱的图像及货物箱图像的爬取过程如下:
(1)通过网络API调用百度图像搜索入口。
(2)利用搜索入口结果返回快速获取关键字相关图像链接。
(3)根据图像链接在本地批量下载对应图像。
(4)判断系统本地是否创建了存储图像的目录,如果没有,系统自建一个。
(5)将图像文件流转为本地文件图像,同时对图像命名标记,并保存。
上述方法1中,数据集的制作过程如下:
(1)确保已经安装了Python环境。
(2)使用pip install LabelImg指令安装LabelImg。
(3)在命令行里输入LabelImg启动LabelImg。
(4)将需要标注的图像,存放至一个固定文件夹中。
(5)进入命令窗口转到LabelImg,点击Open Dir打开该文件夹。
(6)点击左侧Save下方的按钮,直到该标签变为YOLO。
(7)双击打开右下侧的图像,开始对一个图像进行标注。
(8)点击Create RectBox,在图像上拖拽画出矩形框,在弹出的对话框里输入标签名称然后点击OK。
(9)相同的步骤对目标物体进行标注,使用过的标签再下一次可直接选择不必重新输入,已经标注的框可在右侧看到,可以在图像中进行二次拖拽调整。
(10)点击右侧的Save,将标注的数据保存到相同文件夹下。本地可见新出现了两个txt文件。
(11)然后点击NextImage,对下一个图像进行标注。
上述方法2中对数据集进行预处理过程包括:
①数据增强;②自适应图像缩放和③K-means锚框聚类。
上述预处理过程①中的数据增强主要包括:Mosic、Copy-Paste、Mixup等数据增强方式,以此加强模型在复杂背景下的鲁棒性;其中马赛克的数据增强方法特征在于,上述预处理过程中的②中过程的自适应图像缩放主要包括主要用于解决模型训练时样本过少的类别的参考性较小,可能会使模型更关注样本较多的类别,模型参数也主要根据样本多的类别的损失进行调整,最终导致少样本类别精度有所下降的问题。
上述预处理过程中的③中过程K-means锚框聚类方法,主要是在锚点和目标尺寸差异较大的情况下,采用K-means算法对训练集的包围盒进行聚类,k个簇共同组成了一个A集合,该集合中每个簇的样本点到各自质心的距离都是最小的,因此可得如下公式(1)所示。其中,x
其中,K-means锚框聚类流程如下:
首先,选择要将数据集分成k个簇,然后随机选择k个数据点作为初始簇中心。
其次,将每个数据点分配到距离其最近的簇中心,每个数据点只能属于一个簇。
接着,根据分配的数据点更新簇中心点,这是通过计算属于每个簇的数据点的平均值来实现的。
之后,重复步骤b和c,直到簇中心点不再发生变化,或者达到预定的迭代次数。
最后,得到k个簇和每个簇的中心点。
通过该方法,自动生成的先验锚点更适用、更高效,可以学习到更有效的先验知识,加快模型收敛速度。
上述方法3中对检测模型进行训练的过程包括:
(1)对数据集进行预处理,将数据进行图像缩放至640×640尺寸。
(2)对多标签多分类数据集中的数据进行增强处理、自适应图像缩放、锚框聚类。
(3)将用于多目标检测的训练数据集输入到主干部分的网络、目标分类和定位分支中,得到物流仓储违规作业的分类及定位结果。
(4)将用于物流仓储违规作业测试数据集中的数据输入到训练好的模型中,进行测试,得出测试结果,最终验证改进模型的有效性。
上述过程(3)图像输入网络中的具体步骤如下所示:
①将每帧图像输入到特征提取网络,经过1/8、1/16和1/32的下采样后得到三张不同尺寸大小的特征图。
②接着通过特征融合先对图像进行由下至上,再由上至下的多尺度特征融合方式对目标进行多尺度的融合。
③将融合后的特征图分别输入预测大、中、小目标的分类分支与检测嵌入特征提取分支,得到大、中、小目标的预测信息,包括目标的类别和位置。
其中步骤③在检测器经过卷积层运算,得出预测结果,最后通过NMS方法去除冗余的预测框,检测出我们的目标。其中对模型的训练过程中所采用的损失函数包括通过BCELoss(Binary CrossEntropy Loss)损失函数、CIoU Loss损失函数。其中,BCE Loss损失函数作为计算目标和分类的损失函数,可以有效减少模型训练的时间成本,CIoU作为边框回归的损失函数,加快模型收敛。BCE Loss、CIoU Loss公式(2)、(3)所示。其中,公式(2)中p表示预测值,t表示真实值,公式(3)中b,b
Loss(p,t)=-t*log(p)-(1-t)log(1-p)(2)
其中,p(b,b
上述方法4中,RTSP视频流的获取过程如下:
1)获取摄像机的IP地址、配置的用户名和密码,按照格式写出RTSP协议地址码。
2)用VLC工具连接,测试是否可以取出视频流。
3)Python中通过OpenCV读取视频流。
上述方法5中报警过程包括:当监测到目标,将监测到的目标区域进行截图,并将图反馈至我们的检测平台,协助相关工作人员进行监督。
(1)当检测到违规行为目标,截取检测框内的目标图像。
(2)将抓取的违规行为图像,传送至工作的钉钉平台上,以实现报警功能,协助相关人员管理。
其中,上述报警方式步骤(2)中,将违规图像传送至钉钉的流程如下:
创建钉钉小程序并配置相关权限参数,创建小程序,权限/参数配置,获取指定群聊的ChatID,编写Python脚本。
具体实施2:改进YOLOv5n模型算法主要改进步骤如下,其结构图,见图2。
本发明的第二个目的,是设计检测轻量级、检测效果较好的物流仓储违规作业检测器,其主要是对YOLOv5n检测模型进行改进,其中对于改进YOLOv5n模型算法主要改进步骤如下:
首先,为了设计检测速度更快,减少硬件占用资源小的网络结构。由于在YOLOv5n模型主干部分中的下采样卷积产生较大的参数量和计算量,因此,首先将YOLOv5n的主干部分下采样的标准卷积替换为轻量级GhostConv模块作为特征提取网络,在检测效果几乎无影响的情况下,降低模型的参数量和计算量,提高模型的推理速度;为了设计在不影响检测效果的前提下,提高模型的推理速度,减少硬件占用资源小的网络结构。将主干C3模块替换为轻量级Ghost-C3模块,并将主干下采样的标准卷积替换为轻量级GhostConv模块作为特征提取网络,降低模型的参数量和计算量,在检测效果影响不大的情况下,提高模型的推理速度。
其次,将特征融合网络中的标准卷积替换为GSConv,可实现降低模型的复杂度同时保持精度,并在特征融合引入CBAM注意力机制,降低无关区域的干扰。
最后,将边框损失函数CIoU替换为α-CIoU。此外,使用自适应图像采样策略缓解数据不均衡的问题。同时使用马赛克数据增强,对特征图中的目标信息充分利用,提高模型在复杂背景下的鲁棒性。
设备装置与构件:
硬件开发环境:海康威视摄像头、显存容量:8GB、CPU主频:2.60GHz,GPU:NVIDIAGeForce RTX 3090。
软件开发环境:GPU:NVIDIA GeForce RTX 3090(24GB显存,用于模型的训练。),Ubuntu(20.04.1),Cuda(11.3),Torch(1.12.1),Pycharm(2021)。
软件运行环境:Windows1064位操作系统、显存容量:8GB、CPU主频:2.60GHz。
其中上述改进步骤1中,将原YOLOv5n主干部分下采样的标准卷积替换为轻量级GhostConv模块作为特征提取网络,目的是为了降低模型的参数量和计算量,提高模型的推理速度,其中GhostConv操作过程分为三步,由于对于普通卷积操作的计算量和输入输出特征映射的维度相关,而输出特征里面有很多特征是相似的“幻影”特征,因此没有必要使用大量的计算和参数生成这些冗余的特征图。所以选取输入X中m个有效信息X’,首先对输入X’(存在n个特征图)的部分特征进行常规的卷积操作,其公式如公式4所示:
Y′=X*f′(4)
其中,f′∈R
式中,y′
通过使用廉价操作,我们可以获得n=m*s个特征图Y=[y
GhostConv相比于标准卷积可有效降低模型的参数量和计算量,且在模型检测效果几乎无影响的情况下,降低模型的计算量和参数量提高模型的推理速度,该模块从理论上证实了GhostNet的轻量化效力,故而将GhostNet中的瓶颈结构模块网络融入C3模块形成新的Ghost-C3模块,其具体结构如下附图3所示。
上述改进步骤2中,由于CNN中的馈送图像几乎必须在Backbone中经历类似的转换过程:空间信息逐步向通道传输。并且每次特征图的空间压缩和通道扩展都会导致语义信息的部分丢失。密集卷积计算最大限度地保留了每个通道之间的隐藏连接,而稀疏卷积则完全切断了这些连接。GSConv会尽可能地保留这些连接。但是如果在模型的所有阶段都使用它,模型的网络层会更深,深层的网络会加剧对数据流的阻力,显著增加推理时间。当这些特征图走到Neck时,它们已经变得细长(通道维度达到最大,宽高维度达到最小),不再需要进行变换。因此,更好的选择是仅在Neck使用GSConv。在这个阶段,使用GSConv处理Concatenatedfeature maps刚刚好,其冗余、重复信息会有所降低。因此,在本发明中主要在特征融合中将标准卷积替换为GSConv,降低计算量,依旧能取得较好的检测的效果。并在特征融合部分引入CBAM网络结构。由于CBAM注意力机制结合了卷积和注意力机制,可以从空间和通道两个方面上对图像进行关注。且在参数量和计算量增加可忽略不计的情况下提升模型的整体检测性能。CBAM注意力机制由空间注意力模块(Spatial Attention Module,SAM)和通道注意力模块(Channel Attention Module,CAM)组成。其中输入特征F传至通道注意力模块,分别经过全局最大池化(Global max pooling)和全局平均池(Globalaverage pooling)后输入共享M LP(Multilayer Percep-tron,多层感知机)。将MLP输出的特征进行逐元素加和,再经过Sigmoid激活,生成最终的通道注意力特征图M
其中σ为Sigmiod激活函数,
将经过通道注意力模块得到的特征图M
上述步骤3中,α-IoU损失函数是从现有的基于IoU的损失推广而来的一个新的损失族,而α-IoU是从CIoU推广而来的损失函数之一。α-IoU损失函数具有幂IoU项和具有单个幂参数α的附加幂正则化项,其显著超过现有的基于IoU的损失,并且对轻量级模型和噪声边界框更鲁棒。
L
其中,α参数可作为调节αIoU损失的超参数以满足不同水平的Bounding box回归精度,训练会取得比较好的效果.因此对原有改造得到α-CIoU损失函数,理论上会加快模型的收敛,提高模型的检测效果。α-CIoU损失函数公式如公式9所示。
其中,公式(4)中b,b
以上内容是结合具体优选实施方式对本发明做进一步详细说明,对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。