数据成本计算方法、系统、计算机设备和存储介质
文献发布时间:2023-06-19 09:38:30
技术领域
本发明涉及数据处理技术领域,特别是涉及数据成本计算方法、系统、计算机设备和存储介质。
背景技术
现有数据血缘分析程序或系统多用于数据溯源、依赖引用分析等方面,尚未找到与数据成本计算结合使用的案例。当前企业加工存储的数据越来越多,大数据技术获得了广泛的应用,数据加工和存储也消耗了大量的资源,但对应的成本并未能够有效的计算及展示。当前企业内部对于数据成本的计算粒度较大,并不能从更细粒度上体现数据成本的差异,供企业内部管理及相关决策使用。
当前数据的成本大多都是按照加工过程和占用存储资源整体进行统计计算,无法获得表级、字段级或记录级别的成本。在数据成本清晰的情况下,才能在企业内部或外部使用数据时进行合理定价或成本结算。
数据的成本可通过使用相关资源所产生的费用进行计算,但数据加工过程中用到的其它数据也应该算作当前数据的成本,可以有更多视角来评定数据的成本或价值。
发明内容
基于此,本发明提供了一种数据成本计算方法、系统、计算机设备和存储介质,以能够更细粒度的计算和展现数据的成本,同时,能使数据应用的计价方式更为合理。
为实现上述目的,本发明提供一种基于数据血缘的数据成本计算方法,所述数据成本计算方法包括:
获取数据加工过程中使用的SQL语句或者数据加工过程中使用的脚本,并通过SQL语句或加工脚本中所包含的SQL语句生成数据血缘关系,所述数据血缘关系形成有向无环图;
获取数据平台任务执行的统计信息和频率信息,并对应到有向无环图中
计算有向无环图中目标数据相关的节点的成本和边的成本;
获取所述边和节点的成本,并进行累加以得到目标数据总成本。
优选的,所述统计信息包括每次任务的资源使用量,所述资源使用量包括存储用量、CPU用量和内存用量;所述频率信息包括任务的历史执行次数和执行的起止时间。
优选的,根据数据平台的不同,引入数据平台资源使用量的单价参数;在数据成本的计算过程中,所述节点的成本为存储成本,所述边的成本为CPU和内存的成本。
优选的,所述计算有向无环图中目标数据相关的节点的成本包括:∑
优选的,所述获取所述边和节点的成本,并进行累加以得到目标数据总成本,包括:
优选的,所述加工脚本中所包含的SQL语句生成数据血缘关系,所述数据血缘关系形成有向无环图包括:
从含有SQL代码的脚本文件中提取得到规则化的SQL语句,完成对SQL语句的清洗;
对规则化的SQL语句进行词法分析,生成数据血缘关系,并根据数据血缘关系生成有向无环图。
优选的,所述得到目标数据总成本之后,将所述目标数据总成本上传至区块链中,以使得所述区块链对所述目标数据总成本进行加密存储。
为实现上述目的,本发明还提供一种基于数据血缘的数据成本计算系统,所述数据成本计算系统包括:
数据集模块,用于获取数据加工过程中使用的SQL语句或者数据加工过程中使用的脚本,并通过SQL语句或加工脚本中所包含的SQL语句生成数据血缘关系,所述数据血缘关系形成有向无环图;
信息模块,用于获取数据平台任务执行的统计信息和频率信息,并对应到有向无环图中;
第一计算模块,用于计算有向无环图中目标数据相关的节点的成本和边的成本;
第二计算模块,用于获取所述边和节点的成本,并进行累加以得到目标数据总成本。
为实现上述目的,本发明还提供一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,使得所述处理器执行如上所述数据成本计算方法的步骤。
为实现上述目的,本发明还提供一种存储介质,存储有能够实现如上所述数据成本计算方法的程序文件。
上述本发明提供了一种数据成本计算方法、系统、计算机设备和存储介质,其中,所述数据成本计算方法通过获取数据加工过程中使用的SQL语句或者数据加工过程中使用的脚本,并通过SQL语句或加工脚本中所包含的SQL语句生成数据血缘关系,所述数据血缘关系形成有向无环图;获取数据平台任务执行的统计信息和频率信息,并对应到有向无环图中;计算有向无环图中目标数据相关的节点的成本和边的成本;获取所述边和节点的成本,并进行累加以得到目标数据总成本。因此,本发明所述数据成本计算方法在结合数据血缘关系后,能够更细粒度的计算和展现数据的成本,同时,能够使数据应用的计价方式更为合理,这样,为企业对于数据价值的评定可以提供更加详细和合理的参考依据。
附图说明
图1为一个实施例中提供的数据成本计算方法的实施环境图;
图2为一个实施例中计算机设备的内部结构框图;
图3为一个实施例中数据成本计算方法的流程图;
图4为一个实施例中有向无环图的示意图;
图5为一个实施例中有向无环图中节点和边计算的流程图;
图6为一个实施例中SQL语句为多进多出的有向无环图的示意图;
图7为一个实施例中数据成本计算系统的示意图;
图8为一个实施例中的计算机设备的结构示意图;
图9为一个实施例中的存储介质的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
可以理解,本申请所使用的术语“第一”、“第二”等可在本文中用于描述各种元件,但这些元件不受这些术语限制。这些术语仅用于将第一个元件与另一个元件区分。
图1为一个实施例中提供的基于数据血缘的数据成本计算方法的实施环境图,如图1所示,在该实施环境中,包括计算机设备110和显示设备120。
计算机设备110可以为用户使用的电脑等计算机设备,计算机设备110上安装有基于数据血缘的数据成本计算系统。当计算时,用户可以在计算机设备110依照基于数据血缘的数据成本计算方法进行计算,并通过显示设备120显示计算结果。
需要说明的是,计算机设备110和显示设备120组合起来可以为智能手机、平板电脑、笔记本电脑、台式计算机等,但并不局限于此。
图2为一个实施例中计算机设备的内部结构示意图。如图2所示,该计算机设备包括通过系统总线连接的处理器、非易失性存储介质、存储器和网络接口。其中,该计算机设备的非易失性存储介质存储有操作系统、数据库和计算机可读指令,数据库中可存储有控件信息序列,该计算机可读指令被处理器执行时,可使得处理器实现一种基于数据血缘的数据成本计算方法。该计算机设备的处理器用于提供计算和控制能力,支撑整个计算机设备的运行。该计算机设备的存储器中可存储有计算机可读指令,该计算机可读指令被处理器执行时,可使得处理器执行一种基于数据血缘的数据成本计算方法。该计算机设备的网络接口用于与终端连接通信。本领域技术人员可以理解,图2中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
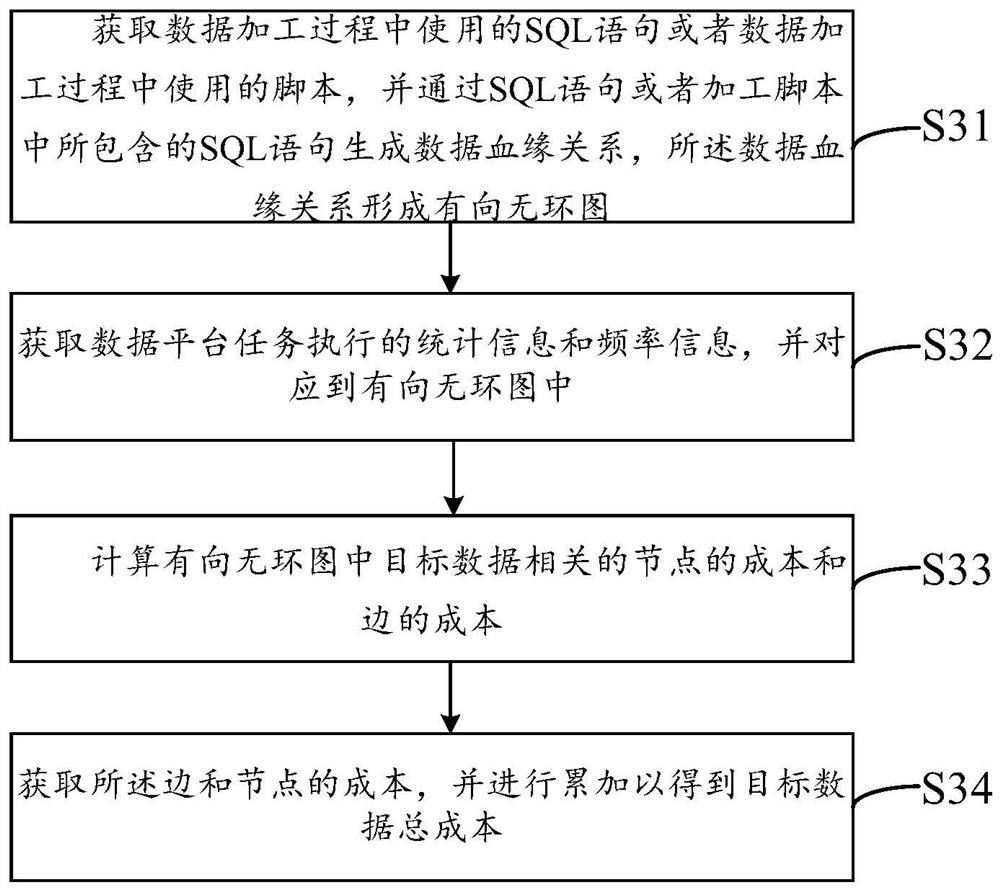
如图3所示,在一个实施例中,提出了一种基于数据血缘的数据成本计算方法,其中,所述数据成本是指企业对数据的获取、传递、表达、存储、搜索、处理等直接或间接的支出与费用。所述数据成本计算方法可以应用于上述的计算机设备110和显示设备120中,具体可以包括以下步骤:
步骤31,获取数据加工过程中使用的SQL语句或者数据加工过程中使用的脚本,并通过SQL语句或加工脚本中所包含的SQL语句生成数据血缘关系,所述数据血缘关系形成有向无环图。
具体的,数据仓库中数据加工过程和数据量类似金字塔结构,自底向上加工存储,底层的数据量和加工用到的资源相对提供使用的数据量要大的多。处于金字塔顶层的数据,其加工存储成本并不能反映其真实的制造成本,还应包含与其加工相关的下层数据的制造存储成本更为合理。因此,基于数据血缘能够较为简便的计算出数据的累积成本。累积成本的计算可以有两种方式:一种方式是计算出数据血缘中每个节点的一般成本,然后根据血缘关系逐级递归进行累加,直到满足限定条件终止;第二种方式是根据数据血缘关系生成的有向无环图分别计算图中节点的成本和边的成本,再根据计算目标及相关的边和节点成本进行累加。本方法选择第二种方式进行,以能正确计算数据成本。下面具体举例进行说明,例如,客户日均存款余额相关指标的计算步骤如下:
步骤1、从本币活期账户表读取数据(A,存储本币活期账号与余额数据),写入本币日均存款余额表(E),计算每日客户本币活期存款余额(A->E);
步骤2、从本币定期账户表读取数据(B,存储本币定期账号与余额数据),写入本币日均存款余额表(E),计算每日客户本币定期存款余额(B->E);
步骤3、从外币活期账户表读取数据(C,存储外币活期账号与余额数据),写入外币日均存款余额表(F),计算每日客户外币活期存款余额(C->F);
步骤4、从外币定期账户表读取数据(D,存储外币定期账号与余额数据),写入外币日均存款余额表(F),计算每日客户外币定期存款余额(D->F);
步骤5、从本币日均存款余额表中读取数据(E,存储用户ID与本币存款余额数据),从外币日均存款余额表中读取数据(F,存储用户ID与外币存款余额数据),写入客户日均存款余额表(G,存储用户ID与余额数据),计算客户日均存款余额(E->G,F->G)。
其中,步骤1-4都需要读取客户账户关系表(Z,存储用户ID和账号的对应关系),将客户信息同步写入目标表中,每个步骤都是执行对应的SQL语句,将数据从源表读取加工后写入到目标表中。进一步的,数据血缘是根据执行的SQL语句分析生成表与表和字段与字段之间的关系,该等关系可以采用二维表格的形式存储,每条血缘数据都记录着一条数据间的关系,如字段A->字段E,因此,基于多条血缘关系数据可以绘制如图4所示的有向无环图(DAG)。
请进一步参考图4,图中的节点表示数据的存储,节点间的连线表示数据的加工过程;节点可以表示数据表、记录或单个字段,节点间带有方向的边表示相关数据加工过程所占用的计算资源。具体的,图中所有的边都是有向边,由数据源表或字段指向数据目标表或字段。数据血缘相关的成本计算主要涉及到存储和加工过程中使用的计算资源成本,其中,人力、场地、电力等资源成本不在所述数据成本计算方法考虑之内,即所述数据成本计算方法主要关注数据的存储和加工过程中使用到的存储和计算资源的相关成本,其他成本不在该数据成本计算方法考虑之内。需要说明的是,该数据成本计算方法主要使用数据血缘的结果,其生成方式并不关注,即使是人工编写的血缘关系结果也可使用。
进一步的,一个实施例中,通过加工脚本中所包含的SQL语句生成数据血缘关系,并通过数据血缘关系生成有向无环图,具体包括:
S311、从含有SQL代码的脚本文件中提取得到规则化的SQL语句,完成对SQL语句的清洗;
进一步的,所述S311包括:
S3111、获取含有SQL代码的脚本文件,并寻找SQL代码的标志位;
优选的,脚本文件可为perl等脚本。
S3112、利用标志位过滤脚本文件中的无关内容,保留得到规则化的SQL代码语句。
S312、对规则化的SQL语句进行词法分析,生成数据血缘关系,并根据数据血缘关系生成有向无环图。
步骤32,获取数据平台任务执行的统计信息和频率信息,并对应到有向无环图中。
其中,所述统计信息包括每次任务的资源使用量,所述资源使用量包括存储用量、CPU用量和内存用量等信息;所述频率信息包括任务的历史执行次数和执行的起止时间等信息。
具体的,数据平台的任务可以是一条SQL语句,每条SQL都对应有向无环图中的一条到多条边,在建立映射关系后,可在计算过程中引用各条边对应的资源使用量。
具体的,可按照任务执行的不同时间段分别统计每个不同时间段指定数据的加工成本,例如某个任务每月执行一次,可以统计每个季度或每半年相关加工的资源用量和成本。如此,根据统计信息和频率信息就能清楚知道目标数据的相关信息,可以方便每个时间段的数据成本计算。
步骤33,计算有向无环图中目标数据相关的节点的成本和边的成本。
根据累积成本的两种计算方式,所述第一种方式可能会对多重引用的节点造成重复计算,计算结果误差会较大,例如图4中节点A、节点B、节点C以及节点D会累计节点Z的成本。第二种方式分别计算各个节点的成本,再计算每条边的成本,最后取二者之和作为目标数据的成本,计算结果较为准确,即本发明所述的数据成本计算方法。
进一步的,在大数据环境批处理生成的数据的过程中,主要占用资源为存储、CPU和内存(MEM);存储的计量单位为字节,根据冗余数量乘以倍数;CPU计量单位为秒*核心数量,内存的计量单位为秒*MB。其中,在云环境的计算相对简便,购买的资源都可转换为对应计量单位便于计算,而传统环境则需要合理的方式将软硬件成本转换为对应计量单位后进行计算。简单的说,就是根据数据平台的不同,引入数据平台资源使用量的单价参数,即不同的数据平台的资源使用量的单价可能存在不同,根据数据的成本决策数据的加工和存储所使用的技术和硬件类型来完成数据成本的计算。进一步的,在同一企业中,其数据交换过程中可根据数据的成本形成合理的、统一的计价方式。
具体的,下面举例进行说明,在当前大数据加工环境资源成本如下:
1000个CPU核心,每年费用为100万元,每core*s的价格约为1000000/1000(核心数量)/(365*86400)=0.0000317元;
5TB内存每年费用50万元,则每GB每秒的费用约为500000/(5*1024)/(365*86400)=0.0000030966元;
存储20TB,每年费用为5万元,每GB每年的价格约为500000/(20*1024)=2.4414元。
根据图4,假设前述SQL(加工指令)执行过程使用的计算资源为:CPU2000core*s,MEM 500GB*s,节点A相关数据占用存储10GB,节点Z占用相关存储2GB,节点E相关数据占用存储3GB,则基于这部分有向无环图计算数据的加工和存储成本为(CPU单价)0.0000317*2000+(内存单价)0.0000030966*500+(存储单价)2.4414*(10+2+3)=0.0634+0.0015483+36.621=36.6859483元,可以准确和快捷的计算出该部分的数据成本。
进一步的,在一个实施例中,假设计算数据节点(表)K的成本C
331、计算有向无环图中节点的成本;
具体的,所述节点的成本就是存储成本,根据以上描述,所述节点的计算公式为:∑
332、计算有向无环图中边的成本。
具体的,所述边的成本是CPU和MEM的成本,根据以上描述,所述边的计算公式:
步骤34,获取所述边和节点的成本,并进行累加以得到目标数据总成本。
当SQL语句为多进一出(insert…from…)时,N
据此,可以总结目标数据总成本,即节点(表)K的总数据成本C
进一步的,举例进行说明,例如,以图4中节点G的数据加工为例,SQL语句为多进一出,共涉及到5条SQL语句,分别为:
A+Z→E为X
insert into table_E
select z.cust_id,a.bal
from table_A a
join table_Z z
on a.acct_no=z.acct_no。
根据此SQL可以生成表级数据血缘关系:
A→E标记为L
X
E+F→G为X
insert into table_G
select nvl(e.cust_id,f.cust_id)as cust_id,
sum(nvl(e.bal,0)+nvl(f.bal,0))as bal
from table_E e
full outer join table_F f
on e.cust_id=f.cust_id
group by nvl(e.cust_id,f.cust_id);
X
表G的数据来源于表A、B、C、D、Z、E、F,其中,节点Z在DAG中出现多次,在计算成本时应对多次出现节点的存储成本进行去重,因此distinct{S
进一步的,在当前的大数据环境下,数据的加工都是表级的,根据以上描述可以计算出表级的数据成本。例如图4中表G如果包含11个数据字段,可以将表G的数据除以11的结果作为每个字段的成本;例如表G中每条记录共存储20字节,其中10个字段都只存储1字节数据,剩余一个字段存储10字节,那么存储10字节的字段占用的存储成本就是表G存储成本的50%,其他每个字段的存储成本是表G的5%。记录级的成本计算方式类似,例如表G包含10万条记录,那么每条记录的成本为C
在另一实施例中,当SQL语句为多进多出时,另有示例如下,其中多进多出图例请参考图6,其加工相关SQL如下:
From table_Aa
join table_B b
On a.id=b.id
Insert into table_C
Select a.id,a.bal+b.bal
Where a.type=1and b.type=2
Insert into table_D
Select b.id,a.bal+b.bal
Where a.type=3and b.type=4;
此SQL会生成如图6所示的4条边,假设此SQL单次执行所消耗资源成本为X
根据以上描述,所述步骤1至3描述了基于数据血缘的数据成本计算方法,该数据成本计算方法可应用于表级、字段级数据的成本计算,记录级的成本则是根据表级或字段级成本,按照记录数量取均值计算。具体的,数据的加工过程(SQL)对应图中的边,因批量加工每条边对应一张表中的多条记录,对于同一张表中多个批次加工的数据可以采用均值的方式计算成本。
进一步的,在一实施例中,每次相同SQL可能因数据数量的变化导致使用资源的数量可能不同,例如图4的A->E,假设第一次加工使用资源的成本是10元,对应产生10000条记录,第二次将使用资源成本是12元对应产生14000条记录,那么这24000条记录的平均加工成本就是(10+12)/24000约为0.091元。
在一个可选的实施方式中,还可以:将所述基于数据血缘的数据成本计算方法的计算结果上传至区块链中。
具体地,基于所述基于数据血缘的数据成本计算方法的计算结果得到对应的摘要信息,具体来说,摘要信息由所述基于数据血缘的数据成本计算方法的计算结果进行散列处理得到,比如利用sha256s算法处理得到。将摘要信息上传至区块链可保证其安全性和对用户的公正透明性。用户可以从区块链中下载得该摘要信息,以便查证所述基于数据血缘的数据成本计算方法的计算结果是否被篡改。本示例所指区块链是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链(Blockchain),本质上是一个去中心化的数据库,是一串使用密码学方法相关联产生的数据块,每一个数据块中包含了一批次网络交易的信息,用于验证其信息的有效性(防伪)和生成下一个区块。区块链可以包括区块链底层平台、平台产品服务层以及应用服务层等。
本发明提供了一种基于数据血缘的数据成本计算方法,通过定义数据集,获取根据数据血缘关系生成有向无环图;计算有向无环图中目标数据相关的节点的成本和边的成本;获取所述边和节点的成本,并进行累加以得到目标数据总成本。由此,在结合数据血缘关系后,能够更细粒度的计算和展现数据的成本,同时,能够使数据应用的计价方式更为合理。进一步的,企业内外对数据价值的评定提供更加详细、合理的参考,便于最细粒度计算数据的成本,使每条数据的成本都可以被精确量化。同时,本发明还涉及区块链技术。
如图7所示,本发明还提供了一种基于数据血缘的数据成本计算系统,该数据成本计算系统可以集成于上述的计算机设备110中,具体可以包括数据集模块20、信息模块30、第一计算模块40以及第二计算模块50。
所述数据集模块20,用于获取数据加工过程中使用的SQL语句或者数据加工过程中使用的脚本,并通过SQL语句或加工脚本中所包含的SQL语句生成数据血缘关系,所述数据血缘关系形成有向无环图;
信息模块30,用于获取数据平台任务执行的统计信息和频率信息,并对应到有向无环图中;
所述第一计算模块40,用于计算有向无环图中目标数据相关的节点的成本和边的成本;
所述第二计算模块50,用于获取所述边和节点的成本,并进行累加以得到目标数据总成本。
在一个实施例中,所述统计信息包括每次任务的资源使用量,所述资源使用量包括存储用量、CPU用量和内存用量等信息;所述频率信息包括任务的历史执行次数和执行的起止时间等信息。
在一个实施例中,所述第一计算模块40用于计算有向无环图中目标数据相关的节点的成本和边的成本。
其中,一个实施例中,计算有向无环图中节点的成本,具体的,所述节点的成本就是存储成本,根据以上描述,所述节点的计算公式为:∑
其中,计算有向无环图中边的成本,具体的,所述边的成本是CPU和MEM的成本,根据以上描述,所述边的计算公式:
进一步的,在一个实施例中,所述第二计算模块50用于获取所述边和节点的成本,并进行累加以得到目标数据总成本。
其中,当SQL语句为多进一出(insert…from…)时,N
据此,可以总结目标数据总成本,即节点(表)K的总数据成本C
在一个实施例中,所述数据成本计算系统还包括显示模块(未图示),用于显示计算结果,所述显示模块可以是台式电脑的显示器,也可以是其他计算机设备的显示装置。
请参考图8,图8为本发明实施例的设备的结构示意图。如图8所示,该设备200包括处理器201及和处理器201耦接的存储器202。
存储器202存储有用于实现上述任一实施例所述基于数据血缘的数据成本计算方法的程序指令。
处理器201用于执行存储器202存储的程序指令。
其中,处理器201还可以称为CPU(Central Processing Unit,中央处理单元)。处理器201可能是一种集成电路芯片,具有信号的处理能力。处理器201还可以是通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现成可编程门阵列(FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
参阅图9,图9为本发明实施例的存储介质的结构示意图。本发明实施例的存储介质存储有能够实现上述所有方法的程序文件301,其中,该程序文件301可以以软件产品的形式存储在上述存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本申请各个实施方式所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-OnlyMemory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质,或者是计算机、服务器、手机、平板等终端设备。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、装置、物品或者方法不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、装置、物品或者方法所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、装置、物品或者方法中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
- 数据成本计算方法、系统、计算机设备和存储介质
- 产品人力成本计算方法及装置、计算机设备和存储介质