一种公共交通乘客出行行为时空语义相似性度量方法
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及一种公共交通乘客出行行为时空语义相似性度量方法,属于公共交通数据挖掘应用领域。
背景技术
公共交通乘客个体的出行行为具有较强的周期性和可预测性,同时也存在受当天活动需求以及其他外部环境的影响而发生变化产生的随机性。随着居民多任务出行比例的增加、工作方式的变化,多样化的活动需求可能会导致个体的出行决策过程更加复杂。研究乘客每天出行行为相似性,揭示个体重复出行行为在中长期时间内变化程度和规律性,可以为掌握出行者的精细化出行需求提供支撑。
目前基于多源公共交通智能卡数据的乘客个体出行行为研究中,通常采用序列比对模型(Sequence Alignment Model,SAM)进行个体多天出行行为的相似性度量。例如LiuS等在“Exploring travel pattern variability ofpublic transport users throughsmart card data:role of gender and age”(IEEE Transactions on IntelligentTransportation Systems,vol.23,no.5,pp.4247-4256)以及林鹏飞等在“公共交通乘客个体活动链的日相似性研究”(交通运输系统工程与信息,2020,20(6):178-183,204)分别构建一个多维序列刻画出行行为,以反映刷卡数据中丰富的信息和相互依赖,出行序列通常由出发时间、出行目的和出行方式、同伴等属性构成;在此基础上,采用Levenshtein距离、PrefixSpan算法等度量乘客出行行为的相似性。但Levenshtein距离等只能反映出行行为序列的结构、类别相似性,无法反映出行属性间的时空相关性,导致两个出行序列相似性度量的准确性降低。因此,考虑出行行为属性的时空语义相关性将有助于更好地刻画乘客每天的出行行为相似性。
在自然语言处理领域,为了度量两个句子的相似性,通常利用词嵌入技术将句子中的每个词表示为一个含有语义的词向量,利用距离函数即可度量两个句子的相似性。目前自然语言处理技术已被应用于交通领域,通过将连续轨迹的经纬度坐标转化为词向量嵌入空间语义信息,进而度量两条轨迹的空间相似性。考虑到出行序列与文本数据具有类似的结构和特点,每一条出行序列反映了活动与出行、相邻活动之间的相互关联和时空约束,而这种关系和自然语言的结构特征类似,即上下文相同的词语其语义也相似。因此,本发明采用自然语言处理技术度量乘客每天出行行为的时空语义相似性。
发明内容
本发明的目的是为了提供一种公共交通乘客出行行为时空语义相似性度量方法,用于分析乘客的长期出行行为规律,便于了解个体在不同时空条件下出行行为决策机制和复杂性。以乘客的公共交通刷卡数据为基础,从多个维度提取出行属性信息,进而构建公共交通乘客个体多维出行序列;利用Word2vec模型捕获出行属性不同粒度之间的时空语义相关性;采用改进的词移距离度量出行序列之间的时空语义相似性,刻画乘客每天出行行为的变化。
本发明的技术方案:一种公共交通乘客出行行为时空语义相似性度量方法,包括以下技术方案:
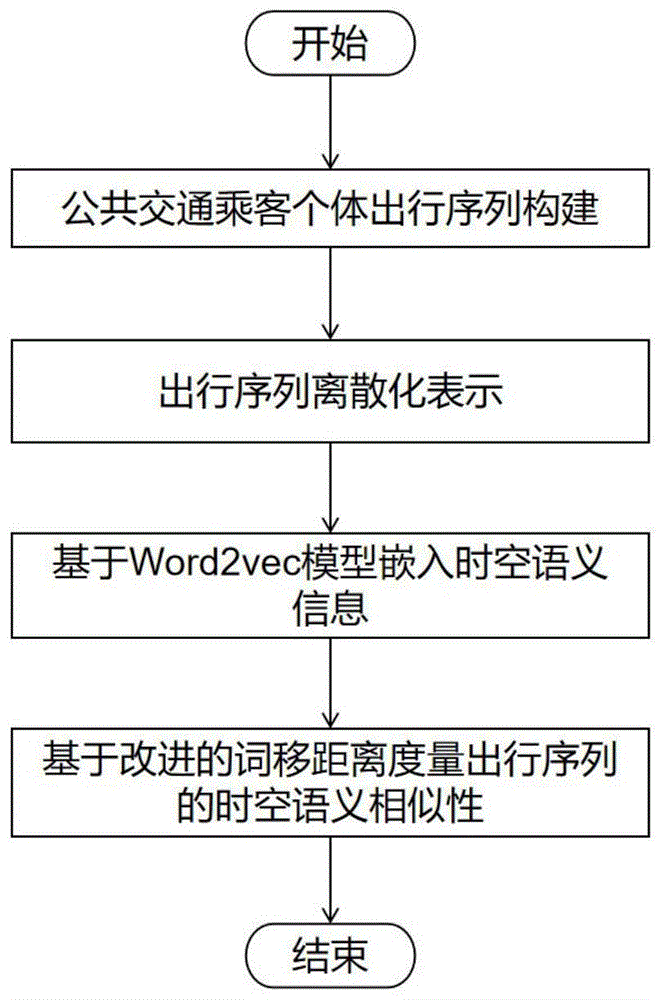
步骤1:公共交通乘客个体出行序列构建。
步骤1.1乘客个体出行链构建
基于乘客的公交、地铁、公共自行车的智能卡交易数据、站点线路的空间矢量数据、车辆运行数据等多源数据,采用多源数据融合构建乘客个体出行链,个体出行链应包含乘客的卡号、智能卡类型、出行方式、出行开始和结束时间、出行起点和终点的站点名和站点经纬度、出行距离等信息。
步骤1.2活动地提取
将乘客的出行链数据按出发时间顺序进行排序,提取出每次出行的起点和终点的站点,构成该名乘客的活动地站点集合。利用DBSCAN算法将每一位乘客的活动地站点集合分别聚类,即将活动地附近的空间位置相邻的站点聚类处理。本发明中DBSCAN算法的距离计算方式采用Haversine距离,邻域半径r和最小样本分别设置为500米和1。
步骤1.3居住地位置识别
考虑到大多数乘客的出行行为具有对称性,即乘客一天内最后一次出行的目的地与当天第一次出行的出发地相同;当天第一次出行的出发地与前一天最后一次出行的目的地相同,且均位于其居住地附近。因此,本发明利用乘客每天第一次出行和最后一次出行的起终点位置识别乘客的居住地位置,具体步骤如下:
S1.选取1名乘客的出行链数据,按出发时间升序排序。
S2.该乘客当天的出行链条数大于等于2时,将第一条出行链和最后一条出行链分别视为当天第一次出行和最后一次出行;出行链条数若为1,则将出发时间早于12:00的出行链定义为当天第一次出行,晚于12:00的出行链定义为最后一次出行。
S3.提取该乘客研究周期内所有第一次出行的出发地和最后一次出行的目的地,将出行最频繁的活动地点定义为该乘客居住地。
S4.重复上述步骤直至所有出行者均被遍历,结束算法。
步骤1.4活动类型推断
首先基于乘客的当前出行链t、相邻出行链t+1的起点和相邻出行链t-1的终点位置对乘客是否处于活动状态进行识别,并计算活动起止时间,具体步骤如下:
S1.提取1名出行者的出行链数据,按出发时间升序排序。当出行链t为周期内第一次出行,或出行链t与出行链t-1的间隔大于1天,则认为出行者在出行链t出发时间之前在t的起点处于活动状态。
S2.当出行链t和出行链t-1发生在同一天,或者在出行链t-1之后的第2天,并且出行链t-1的终点与出行链t的起点相同,则认为乘客处于活动状态;若不同,则认为乘客在该期间采用了非公共交通方式出行。
S3.当出行链t与出行链t+1在同一天,或者在出行链t-1的前一天,则按S2处理。
S4.当出行链t与出行链t+1间隔大于1天,或者出行链t是乘客在周期内最后一次出行,则认为从出行链t的结束时刻到当天结束,乘客在行程t的终点处于活动状态。
S5.重复上述步骤直至所有出行者的出行链均被遍历,结束算法。
然后根据乘客的智能卡类型、活动地点的访问频率和活动起止时间对乘客每次出行的活动类型进行推断,推断步骤如下:
S1.居住地以外访问频率最高的活动地定义为第一活动地,将“居住地”、“第一活动地”之外的剩余活动地定义为“其他活动地”。
S2.若出行目的地位于第一活动地,且活动起止时间在5:00-23:00之间,则分别针对普通卡、学生卡和老年卡定义为“工作”、“学习”和“生活外出”。
S3.若出行的目的地为乘客“居住地”,则活动类型定义为“居家”。
S4.若出行的目的地为“其他活动地”,则活动类型定义为“其他”。
总结活动类型的推断规则如表1所示。
表1乘客活动类型的推断规则
基于上述步骤,提取每位乘客每条出行链的出行起点、出行方式、出发时间、活动类型和目的地5类出行属性。将乘客1天中所有出行链按出发时间先后顺序进行首尾拼接,得到乘客一天的出行序列,即Sequence
步骤2出行序列的离散化表示。
针对出行序列中的出行起点、出行方式、出发时间、活动类型和目的地5类出行属性,均采用离散化变量表示,具体步骤如下:
S1.将出发地和目的地站点的经纬度使用6位Geohash地理编码表示。
S2.针对无换乘的出行链,采用字符串“bus”、“subway”和“bike”分别表示公交、地铁和公共租赁自行车三种出行方式。针对有换乘的出行链,采用“to”将两种方式进行连接,如公交换乘地铁、地铁换乘公交、公交换乘公交分别被表示为“bustosubway”、“subwaytobus”和“bustobus”。
S3.将一天按小时粒度划分为24个时间段,采用字符串“hour”与时段标签拼接构成的字符串表示,例如乘客在6:00至6:59时间段出发,则表示为“hour06”。
S4.将“回家”、“上班”、“上学”、“生活外出”以及“其他”5种活动类型分别表示为“home”,“work”,“study”,“main”和“other”5个字符串。
步骤3:基于Word2vec模型嵌入时空语义信息。
为了使出行序列更好地反映活动与出行、相邻活动之间的相互关联和时空约束,将出行行为属性和出行序列分别类比为单词和句子,乘客的所有出行序列的集合构成一个文档。文档中所有的出行属性构成词汇表,词汇表的长度为V。每个出行属性都采用长度为N的One-hot编码表示。
利用Word2vec模型中的Skip-gram框架将出行属性训练为词向量,捕获每个属性不同粒度之间的时空语义相关性。Skip-gram框架是由输入层、隐藏层和输出层构成的神经网络结构。对于词汇表中索引为i的出行属性,分别使用v
u
式中,w
模型的参数为词汇表中所有出行属性的中心词向量和上下文词向量。通过最大化似然函数训练模型的参数,即最小化损失函数Loss:
最终训练得到的中心词向量即为出行属性的词向量表示。将出行序列中所有出行属性均采用词向量表示,即得到出行序列的词向量表示。
步骤4:基于改进的词移距离计算出行序列的时空语义相似性。
假设乘客p的任意两天的出行活动序列Sequence
词移距离采用欧氏距离度量词向量的差异,由于欧氏距离是一个无上限的量,不便于直观的感知相似性,因此本发明采用余弦距离表示将出行属性w
式中,v
为了得到两个序列的全局最小移动距离,将其转化为线性规划问题求解:
式中,γ
将计算得到两个序列的最小词移距离,转化为序列相似度
本发明的有益效果主要表现在:
本发明基于公共交通智能卡数据等多源数据,采用多维出行序列准确表征乘客每天的出行行为,反映出行与活动之间、相邻两次活动之间的相互依赖和时空约束。基于自然语言处理技术,将时空语义相关性嵌入到出行属性中,利用改进的词移距离度量乘客出行行为相似性,解决了传统出行行为相似性度量模型中无法考虑时空语义相关性的缺陷,可以为公共交通出行需求建模、市场细分或政策评估等提供支撑。
附图说明
图1为本发明所述方法的流程图;
图2为基于t-SNE的词向量可视化结果;
具体实施方式
下面结合附图和实例对本发明做进一步说明。公共交通乘客出行行为时空语义相似性度量方法,包括以下步骤:
步骤1:公共交通乘客个体出行序列构建。
步骤1.1乘客个体出行链构建
基于多模式公共交通出行数据,包括乘客智能卡数据和站线属性数据,参考申请号为CN201510068077.7的中国发明专利中公开的“基于多模式公交数据匹配的公共交通出行特征提取方法”,根据换乘时间阈值和换乘步行距离阈值,将多个具有相同出行目的的出行阶段按出发时间的先后顺序进行整合,获得了北京市2018年4月至5月的个体出行链数据,数据样例如表2所示。
表2乘客个体出行链数据样例
步骤1.2:活动地提取
步骤1.3:居住地位置识别
步骤1.3:活动类型推断
基于上述步骤,提取每位乘客每条出行链的出行起点、出行方式、出发时间、活动类型和目的地5类出行属性。将乘客1天中所有出行链按出发时间先后顺序进行首尾拼接,得到乘客一天的出行序列。例如,卡号为***50000603***的乘客在2018年4月2日的出行序列为{(“大白楼”,“公交”,“2018-04-0209:33:01”,“上班”,“和义农场”),(“和义农场”,“公交”,“2018-04-0218:26:01”,“居家”,“大白楼”)}。
步骤2出行序列的离散化表示。
针对出行序列中的出行起点、出行方式、出发时间、活动类型和目的地5类出行属性,均采用离散化变量表示,最后得到乘客一天的出行序列,出行序列数据的离散化表示示例见表3所示。
表3乘客出行序列离散化表示示例
步骤3:基于Word2vec模型嵌入时空语义信息
将出行行为属性和出行序列分别类比为单词和句子,乘客的所有出行序列的集合构成一个文档。文档中所有的出行属性构成词汇表,词汇表由3051个单词组成。每个出行属性都采用长度为100维的One-hot编码表示。本发明采用genism包的Word2Vec训练词向量,上下文窗口设置为3,最终训练得到的中心词向量即为出行属性的词向量表示。采用t-SNE降维技术对词向量由100维降维至2维进行可视化,如附图2所示。由图2可知,具有相同语义属性的单词被识别并分组成若干簇;同时,在每个簇中,具有相似语义的单词之间的距离也越小。以出发时间为例,图2中7点与8点两个相邻时段的距离较小,而7点与17点两个时间段距离相对较大,即时间段的距离会随着时间间隔的增加而逐渐增大。
步骤4:基于改进的词移距离计算出行序列的时空行为相似性。
利用改进的词移距离计算得到每位乘客任意两天的出行序列相似性。以卡号为“***50000603***”、“***52384710***”、“***50001026***”的三名乘客为例,每名乘客一周内任意两天的出行序列时空语义相似性如表4所示。
表4乘客任意两天出行序列时空语义相似性
假设出发时间、出行方式、活动类型3种变化场景,将本发明提出的模型与SAM模型进行比较,对比结果见表5。由表5可知,本发明提到的模型能够很好地捕捉到出行属性之间的时空语义相关性。
表5模型对比结果
出行序列1、2和3具有不同的出发时间,分别用SAM模型和本发明提出的方法计算序列1和序列2、序列1和序列3的相似性,SAM模型的结果均为0.8,而对于基于词移距离的方法,随着出发时间从7点变化到9点,相似性从0.940降到0.810,表明本发明提出的方法能够更好地捕捉时间相关性。
序列1和序列4具有不同的出行方式,但序列1中的地铁站(北工大西门站)和序列4中的公交站(北京工业大学站)在空间上是相邻的,均位于乘客的出发地附近,SAM模型将两个站点视为独立的两个站点,忽视了站点之间的空间邻近关系;而本发明提出的方法通过引入站点的Geohash编码并训练为词向量,能够更好地捕捉站点之间的空间相关性。
基于词移距离的相似性度量方法也反映了出行行为属性的相对重要性,例如序列1和序列4、序列1和序列5都有两个不同的属性,SAM模型计算的相似性均为0.6,即出行方式和活动类型对相似性的贡献是等价的,但是,本发明的计算结果表明,活动类型的改变对出行行为相似性的影响大于出行方式的改变。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。