一种针对智能体的自适应最优合作博弈控制方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于多智能体控制领域,涉及一种针对智能体的自适应最优合作博弈控制方法。
背景技术
多智能体系统是多个智能体组成的集合,它的目标是将大而复杂的系统建设成小的、彼此相互通信和协调的,易于管理的系统。目前,根据多智能体的优化目标不同,可以将智能体的学习任务分为三种类型:完全协作、完全竞争和混合环境。本发明以车辆稳定性控制系统为例,将驾驶员与车辆控制系统视作完全协作的两个智能体,共同保持车辆的稳定。
车辆稳定控制系统,可以帮助驾驶员在多种情况下保持车辆的稳定。在车速过快时,无论是紧急制动或者转向都可能会发生侧滑、甩尾以及侧翻问题。此时车辆稳定控制就会发挥作用,辅助驾驶员控制车辆平衡稳定以避免可能的安全事故。因此车辆稳定性控制研究有着十分重要的意义。
目前,车辆稳定控制算法的研究按照控制目标分类有以下几种:
1)以横摆运动和质心侧偏角为控制目标。
该方法根据方向盘传感器测出驾驶员目标转弯状态,根据车辆实际运行状态与期望值进行比较,如果存在偏差则按照预先设计好的算法分配车轮驱动力,得到期望的横摆力矩,使实际运行状态跟踪上期望运行状态。使用的控制算法有滑模控制、模糊控制、二次线性最优控制等。
2)以滑移率为控制目标。
规定车辆处于驱动或制动状态时,将保证车辆安全行驶的滑移率范围称为正常区域,其他情况称为紧急区域。车辆行驶过程中,实时监控车辆滑移率变化,当滑移率处于紧急区域时,控制器按照设定好的控制律进行控制。该方式主要防止车辆的侧滑以保证稳定行驶。
3)以侧倾运动为控制目标。
该方法将横向载荷转移率用作评价车辆侧倾方向是否稳定的指标。当横向载荷转移率大于0.8时视作车辆有侧翻的风险,并引入预测控制算法对车辆运动进行控制。
从上述方法中可以看出,目前车辆控制系统主要目的是保障车辆正常行驶的稳定以及对车辆预期行驶轨迹的跟踪,但是未考虑到驾驶员与车辆系统之间完全合作博弈的优化控制问题。
发明内容
本发明针对车辆系统中的稳定性问题,将驾驶员与车辆控制器视为两个完全合作博弈的智能体,运用直接横摆控制的策略,在保证系统稳定的前提下同时使共同协作的性能指标达到最优。
为实现上述的目的,本发明的技术方案如下:
本发明提出了一种自适应最优合作博弈控制方法,该方法能够使车辆系统在运动过程中保持稳定的同时使协作的性能指标最优。首先,对合作博弈中的两个控制器施加噪声信号,并收集一定时间段内的车辆状态数据。然后,找到一对可以使系统稳定的控制策略作为初始控制。最后,利用自适应动态规划方法进行策略迭代,以求得能使协作的性能指标达到最优的合作博弈控制策略。
本发明具体包括以下步骤:
一种针对智能体的自适应最优合作博弈控制方法,步骤如下:
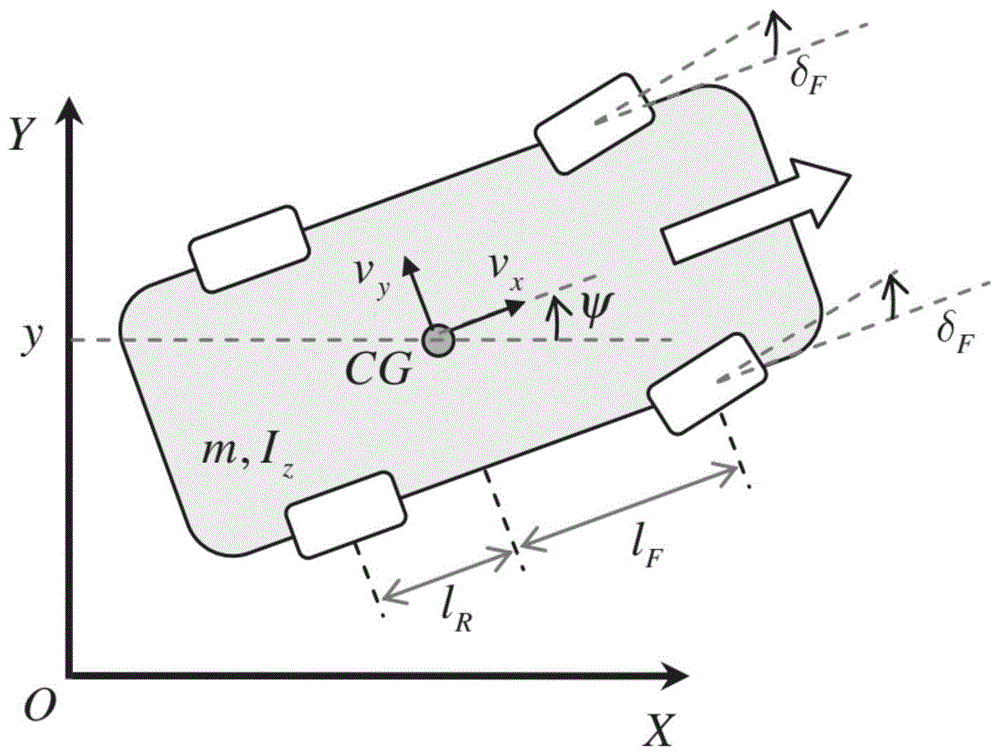
步骤1:构建一个车辆系统合作博弈问题,如附图1所示。
考虑到一个系统方程
其中u为驾驶员施加于方向盘的控制输入,v为车辆横摆控制器的控制输入,f(x)为已知的系统矩阵,g
其中,m为车辆自身质量,v
步骤2:运用自适应动态规划中策略迭代的方法求得博弈控制器最优解。对于系统方程(1),其中的两个控制器u,v双方共同优化一个性能指标J如下:
其中r(x(t),u(t),v(t))=q(x)+u
其中值函数V为在最优控制律u
步骤3:对于施加探测噪声的系统方程
对于任意的i≥0,值函数的导数
以当前时刻t,积分时间段T,对(7)式在时间段[t,t+T]中进行积分可以得到下式:
分别使用三个基函数近似的替代值函数V以及控制策略u、v。
其中φ
其中t
步骤4:首先将采集到的状态变量以时间间隔T分为N组,根据公式(15)的需要处理数据,然后以四阶以内的多项式函数作为基函数的基底,并确定控制策略的初始权重ω
本发明的有益效果如下:
本发明可以对合作博弈问题求解,计算时间少,可以保证系统稳定,并且为全局最优。
附图说明
图1是本发明研究的所采用的汽车动力学模型。
图2是最优控制器u的响应曲线。
图3是最优控制器v的响应曲线。
图4是车辆质心的横向位置y在自适应控制器输入与无控制输入下的响应曲线。
图5是车辆质心的横向速度v
图6是横摆角ψ在自适应控制器输入与无控制输入下的响应曲线。
图7是横摆率
图8是将状态变量x
具体实施方式
实施例1:
步骤1:对于一个简化的汽车模型
选择如下的性能指标:
步骤2:选取探测信号u
u
v
然后收集系统3.7s内的状态变量数据
步骤3:确定三个基函数的初始权重,权重ω、σ均为拥有24个元素的列向量,权重c为拥有20个元素的列向量,注意ω与σ的权重选择应该能够使系统达到稳定。其初始化分别如下:
ω=[-1,0,0,-3,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
σ=[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
c=[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
将采集的状态变量分为以T=0.01s为时间间隔,N=370组数据。根据公式(15)的需要,利用所采集的数据以及初始化的基函数权重计算在0.01s的时间间隔内各项的积分。公式(15)可以视为AX=B,其中X是由c、ω、σ组成的拥有68个元素的列向量。公式(15)的左侧可以构成含有370行68列的矩阵A,公式(15)的右侧可以构成含有370行1列的矩阵B。随后利用最小二乘法求得三个基函数的权值。
此时完成了第一次迭代,随后利用更新的控制律基函数权重ω、σ重新计算公式(15),得到第二次迭代的控制律基函数权重,直至值函数基函数权重c收敛,认为在两次迭代间,权重向量c的欧几里得范数之差小于0.00001,则权重向量c收敛。收敛后所得到两个控制器的控制律即为最优控制律。
步骤4:此方法可以实现在线学习,本文首先采取了3.7s内的数据计算控制律,然后在3.7s时刻立即施加控制律,如附图2、附图3所示。所得到的状态变量曲线如附图4、附图5、附图6、附图7所示。根据值函数权重c可以得到在不同初始条件下性能指标的数值。选用首次迭代后得到的值函数与最后迭代得到的值函数绘制图8。
实施结果
1)从附图2、附图3、附图4、附图5中可以看出,在3.7s前系统在探测噪声下运动。在3.7s后,虚线为无控制输入下状态变量的变化曲线,呈发散状态。实线为施加控制后的状态变量曲线,可以收敛到原点。证明所得的控制律可以使系统稳定。
2)从附图6中可以看出,使用本方法多次迭代并达到稳定点后。系统的值函数在每一个初始状态均小于初始的值函数。证明本方法可以在双人合作博弈条件下使系统的性能指标达到最优。