一种基于图像识别的施工警戒区监测预警系统及方法
文献发布时间:2023-06-19 09:32:16
技术领域
本发明涉及信息监测预警技术领域,尤其涉及一种基于图像识别的施工警戒区监测预警系统及方法。
背景技术
在工程施工区域内,例如在国家及行业标准或指南要求的吊装作业(包括架桥机塔吊)、机械作业、液压滑模、爆破作业、主塔施工、料仓墙体外围、张拉作业应设置警戒区的区域,和挂篮、移动模架施工等高处作业下方应设置施工警戒区的区域,通常会设置铁丝网围栏以阻挡无关技术人员进入施工区域,防止不安全事件发生。但是对于一个很大范围的施工区域,直接设置围栏不仅会影响施工人员进出,也会出现漏检的情况。同时由于施工区域大且随着工程进程推进,施工区域需要变化,采用铁丝网围栏的方式会造成资源和人力浪费,因此需要寻找一种更安全有效的、方便的监测预警方法。
发明内容
本发明的目的在于提供一种基于图像识别的施工警戒区监测预警系统及方法,从而解决现有技术中存在的前述问题。
为了实现上述目的,本发明采用的技术方案如下:
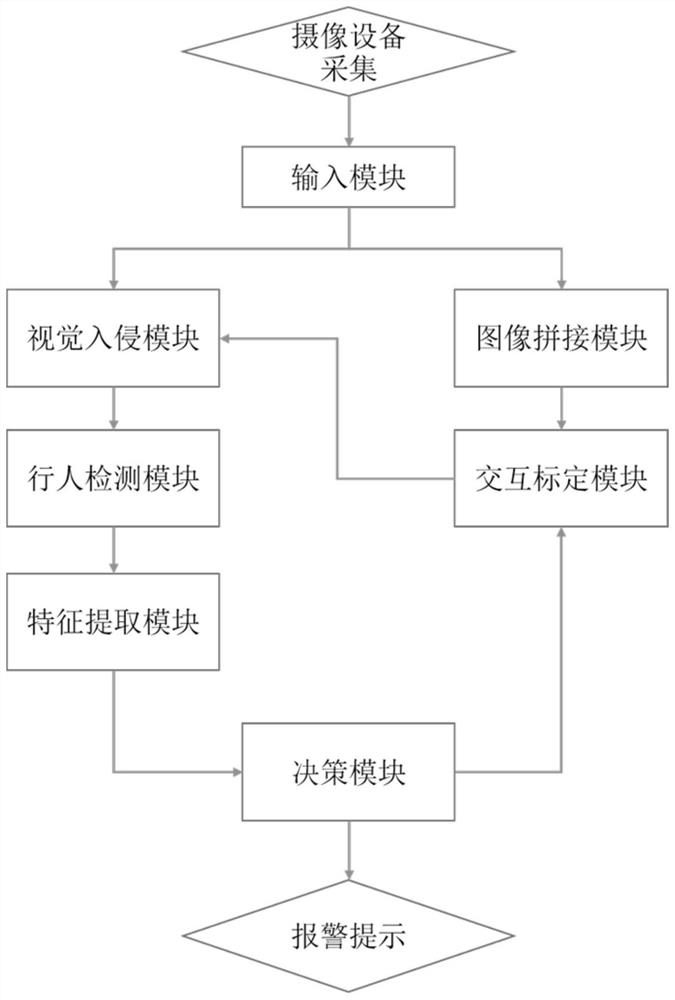
一种基于图像识别的施工警戒区监测预警系统,包括设置在施工警戒区外侧的多个摄像机、互联网和终端设备,还包括图像输入模块、图像拼接模块、交互标定模块、行人检测模块、视觉入侵模块、特征提取模块和决策模块,
所述图像输入模块用于获取公路工程施工警戒区周边各个摄像机的同步视频图像,并将收集到的同步视频图像发送给所述图形拼接模块,所述拼接模块用于将多个同步视频图像拼接得到作业区域内的全景图像;
所述交互标定模块用于在全景图像上进行交互标定预警触发区域,同时激活所述视觉入侵模块:
所述视觉入侵模块激活后,获取标定的预警触发区域,实时观测预警触发区域内的视频图像信息,若所述预警触发区域内有入侵信息向行人检测模块发出预警;
所述行人检测模块接收到所述视觉入侵模块发来的预警后,对所述预警触发区域内的入侵行人目标进行检测,确定入侵行人基本信息;
所述特征提取模块用于提取预警触发区域中入侵行人的特征,并将提取到的特征信息传递给所述决策模块,所述决策模块将获取得到的特征信息与系统中记载的作业人员特征信息进行对比,判断是否需要发出警示信息。
优选地,所述图像输入模块包括初始化状态的输入处理和运作状态下的输入处理;
所述初始化状态的输入处理是将各个摄像机的视频图像直接传输给图像拼接模块时,输入模块按照摄像机顺序编号提取同一时刻不同机位的视频帧,确保相邻编号的视频帧内容可拼接;
所述运作状态下的输入处理是指对于已经设定预警触发区域后,将覆盖预警触发区域边界的视频帧实时传入所述视觉入侵模块;对于已经激活入侵响应的区域,将该区域的全部视频帧直接传入所述行人检测模块。
优选地,所述图像拼接模块包括视频特征提取子模块,视频特征匹配子模块和矩阵回归子模块,所述视频特征提取子模块采用高分辨率网络提取相邻两个摄像机同一时刻输入的视频图像特征;所述视频匹配子模块首先对提取得到的两个视频图像特征进行L2标准化处理,然后对两个标准化处理之后的视频图像特征进行特征匹配继而得到相似性得分矩阵;所述矩阵回归子模块采用卷积神经网络对相似性得分矩阵进行处理得到全局单应性矩阵,根据全局单应性矩阵,通过映射变化将图像进行视觉对齐,完成两张图像拼接。
优选地,所述交互标定模块用于通过用户标定的多个顶点坐标,根据图像拼接模块计算得到的单应性矩阵映射到原始多个视频帧中,将多个顶点连线所围成的区域作为预警触发区域。
优选地,所述视觉入侵模块通过调用vibi函数实现视觉入侵检测,具体包括:
1)通过设计GetImMask模块获取预警触发区域,预警触发区域可以根据实际需要进行设置,包括横线、竖线斜线、矩形框和不规则四边形构成的区域;
2)通过vibe方法类及其成员函数,对预警触发区域内的视频数据实现资源初始化、动态背景建模、背景更新、实时前景获取等功能;
3)通过isOverLapWithBorder模块,实现对与预警触发区域边界线或区域不邻接的检出框的滤除,去除误检;
4)通过dup_rect_eliminate模块,消除检测框绘制时会重复出现或有重叠的检测框。
优选地,所述特征提取模块通过构建孪生神经网络的方式训练生成用于提取特征的卷积神经网络,具体包括三元组数据构建、损失设计和人物特征提取网络;
所述三元组数据构建用于构建作业人员特征的三元组数据训练集,每组三元组数据包括一对“相似”图像和一个“不相似”图像,即将采集的同一个作业人员处于不同时刻不同摄像机位的图像记为一类样本a
所述损失设计具体为:
选择一组三元组训练数据,包括从样本a
L
其中margin是边界超参数,D(a,p)表示图片a和图片p之间的相似度距离,D(a,n)表示图片a和图片n之间的相似度距离;
所述人物特征提取网络子模块采用三分支输入结构网络输入样本特征数据,统一输入样本特征图的尺寸大小,并对样本数据进行类别划分和样本识别,获取得到人物特征。
本发明的另一个目的在于提供一种基于图像识别的施工警戒区监测预警方法,具体包括以下骤:
S1,部署摄像机组覆盖工程施工作业及周边警示区域;通过多个摄像机采集的图像输入到图像拼接模块中拼接得到作业区域的全景图像;
S2,通过交互标定模块在获取得到的全景图像上标记预警触发区域,同时对允许进入该预警触发区域的作业人员记录特征和人数;
S3,视觉入侵模块实时监测预警触发区域内的视频图像,当有入侵人员进入预警触发区域内,发出预警信号激活行人检测模块;
S4,当行人检测模块得到视觉入侵模块的预警后,对预警触发区域内的行人目标进行检测,统计行人数目,并从视频图像中截取出行人所在区域,同时依据报警位置信息,确定入侵行人所在区域具体位置;
S5,特征提取模块将获取得到的入侵行人图像进行特征提取,提取得到特征与步骤S2中已记载的作业人员特征的度量距离,从而确定预警触发区域内是否存在非作业人员,并给出相应的警示信号。
优选地,步骤S3中具体包括:
S31,所述视觉入侵模块获取实时视频流,并对视频数据流拆分得到单帧图像,通过GetImMask模块获取预警触发区域;
S32,对获取得到的预警触发区域分别进行越界检测和区域检测;
所述越界检测在于检测预警触发区域边界线的上/下/左/右是否存在人员入侵信号,若存在,则发出报警信号;若没有,则回到步骤S31,再次获取单帧图像;
所述区域检测是指预警触发区域内部是否具有人员入侵信号,若存在,则发出报警信号;若没有,则回到步骤S31,再次获取单帧图像。
优选地,步骤S4中还包括:当入侵行人数目大于已记载的作业人员人数,则直接发出警示信息;步骤S4和S5可采用定时启动或特定时间启动。
优选地,步骤S5中具体包括:
S51,构建三元组数据训练集:每组三元组数据包括一对“相似”图像和一个“不相似”图像,即将采集的同一个作业人员处于不同时刻不同摄像机位的图像记为一类样本a
S52,采用三元组损失训练三元组数据训练集:
在训练的过程中,将一次读入训练图像的数量设置为P×K,即每次随机选择P个类别的图像,每个类别随机选择K张图像用于训练网络;采用以下公式计算每次读入训练图像内的三元组损失:
其中,
S53,采用三分支输入结构网络输入样本特征数据,采用特征聚集方式使用ROIAlign将不同大小的输入样本特征图聚集为统一尺寸大小的特征图,同时在压缩图像时聚集保留有效特征;
S54,采用多任务学习方法分别对统一尺寸的样本特征图进行类别划分和样本识别,将同一区域内人员在同一时段不同机位的图像划为一类并编号,使用三元组损失建模,用cos相似度度量不同人员图像之间的距离,最终,通过度量的样本对之间的相似度距离进行样本对识别。
本发明的有益效果是:
本发明提供一种基于图像识别的施工警戒区监测预警系统及方法,该系统及方法结合视觉入侵检测、目标检测和重识别技术,通过在施工警戒区周围或者危险施工设备周围设置摄像头实时采集获取周围环境信息和进出人物信息,作业人员可以随时更换预警触发区域以及作业人员登记信息,实时更新预警触发区域中是否有人员入侵信号,当存在人员入侵信号时,则激活那么会发出警报以提醒违规人员禁止进入该区域,保证施工警戒区域的安全性。
此外,为了节省资源,一般情况下只保留视觉入侵模块,只有当视觉入侵模块发出信号时才会激活其他模块;但是对于重点时段,例如中午、傍晚或可能出现人员的时段激活全部模块,同时也可以通过定时间隔的激活全部模块,以防止视觉入侵模块的漏报情况。
附图说明
图1是一种基于图像识别的施工警戒区监测预警系统组成图;
图2是视觉入侵模块的整体算法流程图;
图3是视觉入侵模块中的函数关系图;
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
实施例1
本实施例提供一种基于图像识别的施工警戒区监测预警系统,包括设置在施工警戒区外侧的多个摄像机、互联网和终端设备,还包括图像输入模块、图像拼接模块、交互标定模块、行人检测模块、视觉入侵模块、特征提取模块和决策模块,如图1所示;
所述图像输入模块用于获取公路工程施工警戒区周边各个摄像机的同步视频图像,并将收集到的同步视频图像发送给所述图形拼接模块,所述拼接模块用于将多个同步视频图像拼接得到作业区域内的全景图像;
所述交互标定模块用于在全景图像上进行交互标定预警触发区域,同时激活所述视觉入侵模块:
所述视觉入侵模块激活后,获取标定的预警触发区域,实时观测预警触发区域内的视频图像信息,若所述预警触发区域内有入侵信息向行人检测模块发出预警;
所述行人检测模块接收到所述视觉入侵模块发来的预警后,对所述预警触发区域内的入侵行人目标进行检测,确定入侵行人基本信息;
所述特征提取模块用于提取预警触发区域中入侵行人的特征,并将提取到的特征信息传递给所述决策模块,所述决策模块将获取得到的特征信息与系统中记载的作业人员特征信息进行对比,判断是否需要发出警示信息。
具体的,输入模块主要分为两部分功能:初始化状态的输入处理和运作状态下的输入处理。
初始化状态:在初始化状态主要考虑人机交互体验需要应用图像拼接技术展示作业区域的全景图像。输入模块需要从输入数据中,提取同一时刻的不同机位的视频帧,并对于不同机位顺序编号,确保相邻编号的视频帧内容是可拼接的。
运作状态:运作状态下,对于视觉入侵模块,实时的提供覆盖边界区域的视频帧,对于激活入侵响应的视频帧,将全部视频帧送入行人检测模块。
图像拼接任务的重点在于图像配准。图像配准部分拟设计一个由特征提取模块,特征匹配模块和矩阵回归模块组成的卷积神经网络。通过使用端到端的神经网络训练优化方式,克服了传统方法不同模块之间优化目标的差异,同时使得图像配准的方法变得更加鲁棒和稳定。整个网络的输入是两张图像,输出是8个回归值,继而通过8个回归值得到单应性矩阵。具体来说,使用特征提取模块对两张输入图像提取特征。利用特征匹配模块计算特征之间的相似关系,最后通过矩阵回归模块来的预测得到8个回归值。
特征提取模块考虑到在图像拼接任务中,需要保留更多的空间细节信息,用来感知两幅图之间细小差异,所以拟采用HRNet高分辨率网络,来保证特征图保留足够的空间细节信息。
特征匹配模块主要用于计算两个特征之间的相关性系数。在本模块,首先对两幅图像得到的特征进行L2标准化。然后进行特征匹配,继而得到相似性得分矩阵。
矩阵回归模块,拟尝试利用卷积神经网络计算单应性矩阵,首先对特征匹配模块得到的相似得分矩阵进行Relu操作,消除负相关的部分。之后通过搭建多个卷积+Relu+Batchnorm的卷积模块提取特征,最后通过两个全连接层得到用于生成单应性矩阵的8个回归值,继而得到全局单应性矩阵。最后根据得到的全局单应性矩阵,通过映射变化将得到两张图像进行视觉上的对齐,最后将两张图像拼接在一起。
交互标定模块的主要功能是给用户提供作业区域的全景画面并进行交互标注,工作人员可以在笔记本电脑、平板电脑等设备上选择预警区域范围。标定模块根据用户标定的4个顶点坐标,根据单应性矩阵映射到原始多个视频帧中,作为视觉入侵模块的标定信息。同时在标定过程完成后,程序会自动启动行人检测和特征提取模块,记录场内作业人员的特征信息。
视觉入侵模块的整体算法流程如图2所示,报警信号指代的是激活后续模块的信号,具体内容为:
首先所述视觉入侵模块获取实时视频流,并对视频数据流拆分得到单帧图像,通过GetImMask函数获取预警触发区域;
然后对获取得到的预警触发区域分别进行越界检测和区域检测;
所述越界检测在于检测预警触发区域边界线的上/下/左/右是否存在人员入侵信号,若存在,则发出报警信号;若没有,则回到步骤S31,再次获取单帧图像;
所述区域检测是指预警触发区域内部是否具有人员入侵信号,若存在,则发出报警信号;若没有,则再次获取单帧图像,重复上述步骤。
视觉入侵检模块中函数的关系如图3所示。首先,主程序main通过调用vibi函数,实现视觉入侵检测。vibi函数中主要有四个功能模块:1)通过GetImMask模块获取监控区域,可支持横线、竖线、斜线、矩形框和不规则四边形等多种形状的监控区域;2)通过vibe类及其成员函数,实现资源初始化、动态背景建模、背景更新、实时前景获取等功能;3)通过isOverLapWithBorder模块,实现对与监控线或区域不邻接的检出框的滤除,去除误检;4)通过dup_rect_eliminate模块,消除检测框绘制时重复出现或有重叠的检测框。
值得注意到的是,vibi算法是一种像素级视频背景建模或前景检测的算法,效果优于所熟知的几种算法,对硬件内存占用也少。ViBe是一种像素级的背景建模、前景检测算法,该算法主要不同之处是背景模型的更新策略,随机选择需要替换的像素的样本,随机选择邻域像素进行更新。在无法确定像素变化的模型时,随机的更新策略,在一定程度上可以模拟像素变化的不确定性。
本实施例中的行人检测模块,使用的是经典的SSD(Single Shot MultiBoxDetector)检测网络,在每个摄像机位捕获的视频帧中快速的定位出行人的位置和人员数目。SSD是Single Shot Detector的缩写,能够在不影响太多检测精度的前提下实现实时的检测速度,SSD的三大特点包括:多尺度、设置了多种宽高比的锚点框以及数据增强策略。它有效地结合了Faster R-CNN、YOLO和多尺度卷积特性中的思想,能够在达到与当时最先进的两阶段的检测方法相当的检测精度的同时,达到了实时检测的要求。
本实施例中的特征提取模块主要是基于三元组损失通过构建孪生神经网络的方式训练生成用于提取特征的卷积神经网络,主要包括三元组数据构建、损失设计和人物特征提取网络。三元组数据构建的主要目的是提供高质量三元组数据为接下来高辨识度特征学习网络提供训练数据。训练过程中每组三元组数据要求包含三张图像数据,其中一对为“相似”图像,另外一张为与这两张“不相似”的图像。具体的,将采集的同一个作业人员处于不同时刻不同摄像机位的图像记为一类样本a
三元组损失是一种被广泛应用的度量学习损失,它相比其它损失(分类损失,对比损失)有着端到端、带有聚类属性、特征高度嵌入等优势。三元组损失训练数据每组需要三张输入图片。一个输入的三元组(Triplet)包括一对正样本对和一对负样本对。三张图片分别命名为固定图片(Anchor)a、正样本图片(Positive)p和负样本图片(Negative)n。图片a和图片p为一对正样本对,图片a和图片n为一对负样本对。三元组损失表示为:
L
其中margin是边界超参数,D(a,p)表示图片a和图片p之间的距离,D(a,n)表示图片a和图片n之间的距离。
但是三元组损失网络在训练的过程中,可以组合生成大量的负样本对,会导致正负样本对的数量不均衡,出现训练堵塞,收敛结果不佳的情况,因此针对人员图像的训练策略的设计会直接影响深度网络学习的性能。因此在训练的过程中,训练的Batch size(一次读入图像的数量)设置为P×K,即每次随机选择P个类别的图像,每个类别随机选择K张图像用于训练网络。采用以下公式计算每个Batch size内的三元组损失:
其中,
通过这种训练方式,每次选择每个batch size中最不相似的正样本对和最不易区分的相似负样本对来计算损失,来减少训练的数据,同时解决训练样本不均衡的问题,使网络学习到的特征表示能力更强。
本部分针对作业场景的特点、结合特征表示的学习任务,设计合理的深度网络结构,提取表示能力强,鲁棒性强的特征。
特征提取网络包括特征表示、特征聚集以及多任务构建三个内容,对于特征表示:根据三元组损失的特性,本实施例中的网络拟设计为三分支输入结构,分别对应一组正样本对(X
特征聚集:兼具考虑到预警对速度需求和计算量的限制以及计算度量距离对特征维度的要求,经过骨干网络提取得到的特征图通道数量不应过高,例如Vgg生产512维度的特征图、Resnet生产1024维度的特征图、Inception生产1024维度的特征图会影响到图像检索速度以及计算度量距离的可用性,在骨干网络之后添加参数共享的1×1的卷积同时压缩三张图像特征图的通道数。同时经过骨干网络得到的三个图像的特征图,由于输入的图像的大小尺寸并不一致,只在通道上保持一致。在计算距离度量和进行分类特征提取时需要保持特征图的大小一致,因此设计ROI Align统一特征图的大小。ROI Align通过使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。通过ROI Align操作将不同大小的特征图聚集为同样尺寸大小的特征图,在压缩特征图大小的同时,聚集保留有效的特征。
多任务构建:多任务学习(Multitask Learning)是一种推导迁移学习方法,深度网络把多个相关的任务放在一起学习,学习过程中通过一个在浅层的共享表示来互相分享、互相补充学习到的领域相关的信息,互相促进学习,提升泛化的效果。在特征表示学习网络中,同时采用分类任务跟样本对的识别任务,分类任务作为一个辅助任务,有助于网络的特征学习和加速网络的收敛,在分类任务中,对所有样本数据进行粗略的类别划分,同一人员的图像认定为一类,以1~N(N为所有类别数目)编号。对每张图像经过ROI Align提取得到的特征图,经过ReLU函数激活后,连接一个全连接层(Fully Connected Layer)。通过全连接层后特征图被拉伸成一个一维的特征向量,经过ReLU函数激活后输入到分类层,采用softmax逻辑回归(softmax regression)进行分类。在样本对识别任务中,使用三元组损失来指导网络学习,同时也是特征表示建模的核心思想。首先,在特征空间上用过cos相似度度量不同人员图像之间的距离。最终,通过度量的样本对之间的距离进行样本对识别。
本实施例中的决策模块的主要功能是决策是否发出警示信息或是否需要录入新出现的作业人员信息。除此之外决策模块还会在重点时段(中午、傍晚或可能出现人员的时段激活全部模块(一般情况下只保留视觉入侵模块)),同时还会间隔的激活全部模块,以防止视觉入侵模块的漏报情况。
具体的,决策模块会对得到的区域内人员特征与已存的全部人员特征计算cos相似度距离,对于相似度小于预设阈值的情况不做出警示信息,对于大于预设阈值的情况发出预警,提醒该人员离开。
同时当决策模块发现监控区域内检测得到的人员数目大于记录人员数目,会直接触发预警。
实施例2
本实施例提供一种基于图像识别的公路工程施工警戒区监测预警,具体包括以下骤:
S1,部署摄像机组覆盖工程施工作业及周边警示区域;通过多个摄像机采集的图像输入到图像拼接模块中拼接得到作业区域的全景图像;
S2,通过交互标定模块在获取得到的全景图像上标记预警触发区域,同时对允许进入该预警触发区域的作业人员记录特征和人数;
S3,视觉入侵模块实时监测预警触发区域内的视频图像,当有入侵人员进入预警触发区域内,发出预警信号激活行人检测模块;
S4,当行人检测模块得到视觉入侵模块的预警后,对预警触发区域内的行人目标进行检测,统计行人数目,并从视频图像中截取出行人所在区域,同时依据报警位置信息,确定入侵行人所在区域具体位置;
S5,特征提取模块将获取得到的入侵行人图像进行特征提取,提取得到特征与步骤S2中已记载的作业人员特征的度量距离,从而确定预警触发区域内是否存在非作业人员,并给出相应的警示信号。
步骤S3中具体包括:
S31,所述视觉入侵模块获取实时视频流,并对视频数据流拆分得到单帧图像,通过GetImMask模块获取预警触发区域;
S32,对获取得到的预警触发区域分别进行越界检测和区域检测;
所述越界检测在于检测预警触发区域边界线的上/下/左/右是否存在人员入侵信号,若存在,则发出报警信号;若没有,则回到步骤S31,再次获取单帧图像;
所述区域检测是指预警触发区域内部是否具有人员入侵信号,若存在,则发出报警信号;若没有,则回到步骤S31,再次获取单帧图像。
步骤S4中还包括:当入侵行人数目大于已记载的作业人员人数,则直接发出警示信息;步骤S4和S5可采用定时启动或特定时间启动。
步骤S5中具体包括:
S51,构建三元组数据训练集:每组三元组数据包括一对“相似”图像和一个“不相似”图像,即将采集的同一个作业人员处于不同时刻不同摄像机位的图像记为一类样本a
S52,采用三元组损失训练三元组数据训练集:
在训练的过程中,训练的Batch size(一次读入图像的数量)设置为P×K,即每次随机选择P个类别的图像,每个类别随机选择K张图像用于训练网络。采用以下公式计算每个Batch size内的三元组损失:
S53,采用三分支输入结构网络输入样本特征数据,采用特征聚集方式使用ROIAlign将不同大小的输入样本特征图聚集为统一尺寸大小的特征图,同时在压缩图像时聚集保留有效特征;
S54,采用多任务学习方法分别对统一尺寸的样本特征图进行类别划分和样本识别,将同一区域内人员在同一时段不同机位的图像划为一类并编号,使用三元组损失建模,用cos相似度度量不同人员图像之间的距离,最终,通过度量的样本对之间的距离进行样本对识别。
通过采用本发明公开的上述技术方案,得到了如下有益的效果:
本发明提供一种基于图像识别的施工警戒区监测预警系统及方法,该系统及方法结合视觉入侵检测、目标检测和重识别技术,通过在施工警戒区周围或者危险施工设备周围设置摄像头实时采集获取周围环境信息和进出人物信息,作业人员可以随时更换预警触发区域以及作业人员登记信息,实时更新预警触发区域中是否有人员入侵信号,当存在人员入侵信号时,则激活那么会发出警报以提醒违规人员禁止进入该区域,保证施工警戒区域的安全性。
此外,为了节省资源,一般情况下只保留视觉入侵模块,只有当视觉入侵模块发出信号时才会激活其他模块;但是对于重点时段,例如中午、傍晚或可能出现人员的时段激活全部模块,同时也可以通过定时间隔的激活全部模块,以防止视觉入侵模块的漏报情况。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
- 一种基于图像识别的施工警戒区监测预警系统及方法
- 一种基于AIS/GPRS的施工船舶作业区虚拟警戒标系统及方法