一种基于Flink的探地雷达数据SVD分布式算法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明涉及探地雷达数据处理领域,尤其涉及一种基于Flink的探地雷达数据SVD分布式算法。
背景技术
近年来,随着数据采集手段的飞速发展以及数据来源的多样丰富,尤其是互联网激增的大规模用户行为数据,我们所能获得的数据规模已经从十年前的数万、数十万到今天的动辄上千万、甚至是数亿。在此大数据背景下,越来越多的应用或算法向分布式系统或平台扩展,如何优化算法使其能够并行化实现,如何选择并行处理技术、大数据框架以及如何针对具体工具研制高效并行算法成为了高效处理海量数据的关键。
雷达数据处理属于现代雷达系统中的重要组成部分,通过接收雷达信号处理后的原始点迹进行处理,得到目标的位置、速度等状态,最终形成目标运动轨迹。随着现代信息化战争武器的不断革新,雷达技术及其体制不断完善,相应地对雷达数据处理系统也提出了更高的要求,需要处理的数据越来越复杂,数据量越来越大,使得加快雷达数据处理的速度成为必要。
SVD算法在探地雷达数据噪声分离方面有着广泛的应用。其中心思想是用正交变换将原矩阵化为双对角线矩阵,然后再对双对角线矩阵用变形的QR算法进行迭代。目前SVD算法主要分为QR算法、Jacobi算法等,上述算法虽然可以达到一定精度,但由于其O(n
发明内容
为了解决上述问题,本发明提供了一种基于Flink的探地雷达数据SVD分布式算法,实现分布式存储数据的同时,也能提高计算效率。
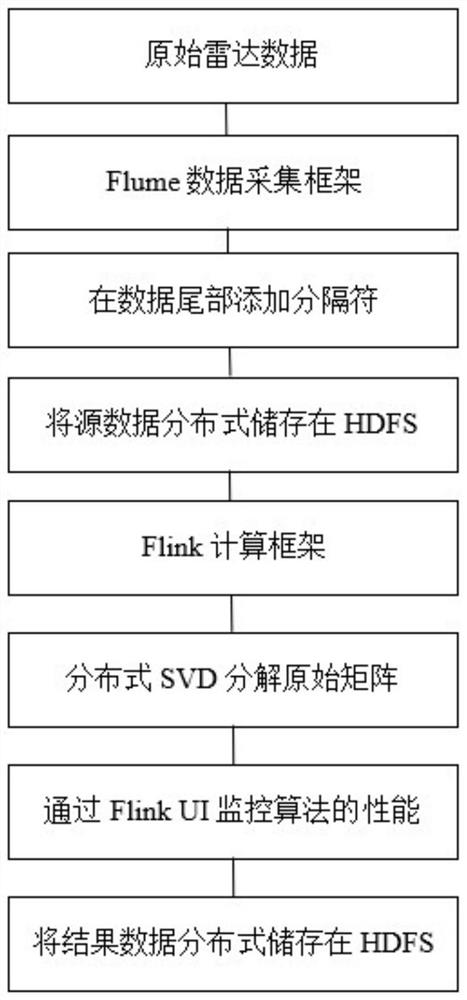
本发明提供的技术方案是:一种基于Flink的探地雷达数据SVD分布式算法,包括如下步骤:
1)采集数据,使用Flume数据采集框架,读取原始雷达数据文件,按照文件头中的元数据来切分数据道,记录在文本文件中;
2)收集文本文件,随后用HDFS存储数据,将数据以分块的方式分布式存储在集群的不同节点中;
3)在Flink计算框架中对数据进行分布式计算,首先从HDFS中读取数据,将步骤1)中的每行数据解析为原始矩阵A
U是A的左奇异向量组,是A*A
4)建立大数据框架,首先建立大数据集群,集群一共7台机器,其中4台为Hadoop集群,1台namenode,3台datanode,3台为Flume集群,4台为Flink集群(与Hadoop集群共用),1台JobManager,3台TaskManager,大数据计算框架Flink在SVD分解的过程中,提供了分布式计算的物理节点和数据分发策略,最后利用HDFS进行分布式存储,将U、E、V分布式的存储在集群不同的节点上。
优选,所述步骤1)中,在切分后的每一条数据尾部增加“\n”分隔符。
进一步优选,所述步骤2)中,使用textCollector将步骤1)中的数据源统一进行收集。
进一步优选,所述步骤3)计算SVD的过程中,将矩阵分成子矩阵块,按照计算规则分布式的分发到集群的不同节点,通过Map算子进行子矩阵块的基本运算以及初等行变换,计算之后再根据特征值进行排序,提取前n个非零的特征值,剩下的置为零,对子矩阵块进行聚合,将矩阵复原,将结果数据存储到HDFS中,既可以减小数据规模,又可以对数据去噪。
进一步优选,所述步骤3)中,所述U矩阵中向量为正交,称为左奇异向量,Σ矩阵除了对角线的元素都是0,对角线上的元素称为奇异值,V
进一步优选,所述步骤3)中,特征值的计算方法如下:
计算A和A
进一步优选,所述步骤3)中,特征向量的计算方法如下:
首先选取非零特征值,通过公式(M-λE)x=0进一步求得特征向量,对特征向量进行标准化,得到A*A
进一步优选,所述步骤4)中,通过Flink提供的监控页面,来监控SVD算法在集群上的性能表现及计算效率,与直接使用Matlab进行SVD计算的速度做对比。
进一步优选,所述步骤4)中,监控分布式SVD算法在速度上的提升与数据规模和集群节点数量的关系,在探地雷达数据规模和集群配置之间取得平衡,给出探地雷达数据在大数据分布式处理领域的规范流程及监控方式。
进一步优选,所述步骤4)的大数据计算框架Flink在SVD分解的过程中,首先采用分块矩阵的乘法,将每一组需要参与计算的矩阵块分发到集群不同节点进行计算,通过减少每一个并发执行的数据量来提高计算速度,随后进行GAUSS消元过程,需要消元的数据可以分块进行分布式行变换,最后为求解特征向量的过程,所有特征向量可以分发到集群的不同节点进行特征向量的计算,并发提高计算的速度。
本发明提供了一种基于Flink的探地雷达数据SVD分布式算法,使用Flume抽取海量探地雷达数据,利用分布式文件系统HDFS存储数据文件,再通过基于分布式计算引擎Flink的分布式SVD计算,建立一套规范的大数据框架处理探地雷达数据的基本流程,分析集群在计算时的性能及数据质量,在保证SVD滤波效果一致的前提下,通过Flink计算框架提高计算的效率,同时应用实际探地雷达数据,给出大数据集群的处理方案和基本流程,同时本发明有如下几个优点:
1)使用Flume框架对探地雷达数据进行格式化和网格化操作,统一了探地雷达的数据格式,使得大规模的探地雷达数据可以使用分布式文件系统HDFS进行存储,降低了数据的存储成本;
2)利用Flink分布式计算框架,实现了SVD分布式算法,提高了SVD算法的计算速度;
3)给出探地雷达数据在大数据分布式处理领域的规范流程及监控方式。
附图说明
图1为本发明提供的一种基于Flink的探地雷达数据SVD分布式算法的流程图;
图2为简单模型加了高斯噪声的图像;
图3为简单模型的Matlab的SVD去噪效果;
图4为简单模型的Flink框架的分布式SVD去噪效果;
图5为简单模型的单节点和集群多节点的计算速度提升比;
图6为实际数据的原始图像;
图7为实际数据的Matlab的SVD去噪效果;
图8为实际数据的Flink框架的分布式SVD去噪效果;
图9为实际数据的单节点和集群多节点的计算速度提升比。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供了一种基于Flink的探地雷达数据SVD分布式算法,包括如下步骤:
1)采集数据,使用Flume数据采集框架,读取原始雷达数据文件,按照文件头中的元数据来切分数据道,记录在文本文件中;
2)收集文本文件,随后用HDFS存储数据,将数据以分块的方式分布式存储在集群的不同节点中;
3)在Flink计算框架中对数据进行分布式计算,首先从HDFS中读取数据,将步骤1)中的每行数据解析为原始矩阵A
U是A的左奇异向量组,是A*A
4)建立大数据框架,首先建立大数据集群,集群一共7台机器,其中4台为Hadoop集群,1台namenode,3台datanode,3台为Flume集群,4台为Flink集群,Fink集群与Hadoop集群共用,1台JobManager,3台TaskManager,大数据计算框架Flink在SVD分解的过程中,提供了分布式计算的物理节点和数据分发策略,最后利用HDFS进行分布式存储,将U、E、V分布式的存储在集群不同的节点上。
优选,所述步骤1)中,在切分后的每一条数据尾部增加“\n”分隔符,使之便于Flume程序对输入数据进行切割。
进一步优选,所述步骤2)中,使用textCollector将步骤1)中的数据源统一进行收集。
进一步优选,所述步骤3)计算SVD的过程中,将矩阵分成子矩阵块,按照计算规则分布式的分发到集群的不同节点,通过Map算子进行子矩阵块的基本运算以及初等行变换,计算之后再根据特征值进行排序,提取前n个非零的特征值,剩下的置为零,对子矩阵块进行聚合,将矩阵复原,将结果数据存储到HDFS中,既可以减小数据规模,又可以对数据去噪。
进一步优选,所述步骤3)中,所述U矩阵中向量为正交,称为左奇异向量,Σ矩阵除了对角线的元素都是0,对角线上的元素称为奇异值,V
进一步优选,所述步骤3)中,特征值的计算方法如下:
计算A和A
进一步优选,所述步骤3)中,特征向量的计算方法如下:
首先选取非零特征值,通过公式(M-λE)x=0进一步求得特征向量,对特征向量进行标准化,得到A*A
进一步优选,所述步骤4)中,通过Flink提供的监控页面,来监控SVD算法在集群上的性能表现及计算效率,与直接使用Matlab进行SVD计算的速度做对比。
进一步优选,所述步骤4)中,监控分布式SVD算法在速度上的提升与数据规模和集群节点数量的关系,在探地雷达数据规模和集群配置之间取得平衡,给出探地雷达数据在大数据分布式处理领域的规范流程及监控方式。
进一步优选,所述步骤4)的大数据计算框架Flink在SVD分解的过程中,首先,由于计算复杂度近似为O(n
实施例
首先搭建大数据计算集群,集群一共7台机器,其中4台为Hadoop集群,1台namenode,3台datanode,3台为Flume集群,4台为Flink集群(与Hadoop集群共用),1台JobManager,3台TaskManager,处理的原始探地雷达数据为100G。
随后选择简单模型进行试算,设置4层地质模型,采用主频1GHZ雷克子波,采样间隔为2ns,加入信噪比为30dB的高斯白噪声,数据大小为8.69MB,先使用一个节点进行计算,将数据通过textFile方法读取到Flink计算平台,通过map算子进行数据转换,将模型的行数据转换为矩阵,接着对矩阵中的数据进行SVD分解,先对数据进行去噪,然后计算过程中选择矩阵的前n行和前n列,分发到集群中不同的计算节点,分布式的求得矩阵的特征值和特征向量。选取最大的奇异值做模型还原,去噪效果明显,当增加集群数量为3时,可以保证SVD去噪效果的一致,随着集群数量的增加,运算效率能提升1.3倍左右,如图2至5所示。
选择实际数据试算,选用25MHz非屏蔽天线,测线物理点数6037,测线总长920m,设定采样时窗为1000ns,采样点数1018个,采样频率为409.09MHz,道间距30cm,数据大小为12.8MB,在数据转换时与模型数据不同,需要在Flume框架中对数据添加“/n”换行符,将数据转换为可读取的格式,随后将数据存储到HDFS中;使用同样的计算方法,只是在选择特征值时选择前五个做模型还原,保证SVD去噪效果的一致,单机计算的时间增加了3秒,但是在3台集群处理的时间和小数据量模型的处理时间差别不大,说明数据量在一定的范围内,应用集群处理的效率近似,整体speedup提高的幅度比数据量较小时大,提升1.5倍左右,如图6至9所示。
综上所述,本发明解决了探地雷达模型数据的转换、存储及分布式计算的问题,在保证数据处理结果正确性的前提下,通过调整集群的数量,提高计算的效率。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本申请旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本发明未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由权利要求指出。
应当理解的是,本发明并不局限于上面已经描述中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制。
- 一种基于Flink的探地雷达数据SVD分布式算法
- 一种基于flink实现的数据开发平台的预警系统